基于图神经网络的电子设计自动化技术研究进展
2023-10-17田春生婧王卓立庞永江
田春生 陈 雷 王 源 王 硕 周 婧王卓立 庞永江 杜 忠
①(北京微电子技术研究所 北京 100076)
②(北京大学集成电路学院 北京 100871)
1 引言
集成电路电子设计自动化(Electronic Design Automation, EDA)软件依托计算机及相关平台[1,2],实现集成电路的设计、综合、验证、物理设计(包括布局、布线、版图、设计规则检查)、硬件安全检测等功能,极大地提高了集成电路的设计效率,保证了设计的安全性,是整个产业链最上游的核心子区域,贯穿了设计、制造以及封装测试的全部环节[3]。随着集成电路制造工艺尺寸的不断缩小,芯片的复杂度和芯片设计成本不断增加。2001年,国际半导体技术路线图(International Technology Roadmap for Semiconductors, ITRS)曾指出集成电路设计成本是制约半导体发展的最大威胁[4]。EDA与半导体材料、设备共同构成集成电路的3大基础,如今的一颗芯片上面至少包含数亿到数十亿个以上的晶体管,制造和研发的费用也越来越昂贵,多次流片失败直接导致公司倒闭的案例更是数不胜数,所以在芯片设计环节不允许出现丝毫差错。EDA工具的发展极大程度提高了芯片的设计效率,一直以来都是推动芯片设计成本保持在合理范围内的重要方式。实际上,EDA一直都在扮演一种“成本杀手”的角色。根据加州大学圣迭戈分校Andrew Kahng教授在2013年的推测,2011年设计一款消费级处理器芯片的成为约为4×107美元,如果不考虑1993~2009年EDA技术的进步,相关设计成本可能高达7.7×109美元,EDA技术使得设计费用降低了200倍[5]。由此可见,EDA技术的重要性对于整个集成电路产业的发展不言而喻。
EDA工具的工作流程跨越了逻辑综合、布局规划、布局、时钟树综合(Clock Tree Synthesis,CTS)、布线、测试等多个阶段,此外还囊括硬件安全检测等多个步骤[6–11],随着设计复杂度增加、工艺向物理极限推进,EDA工具的设计难度日趋增加。为应对出现的挑战,越来越多的研究将机器学习技术引入到EDA工具的设计流程中,用以提高建模、搜索和优化过程的性能和效率,从而进一步解决设计规模大、设计目标与约束复杂以及设计流程冗长的问题[12,13]。通过机器学习方法对电路设计过程中的关键参数进行提取、可预测性建模以及EDA算法优化可以非常高效地提升芯片设计效率,缩短芯片版图的生成时间,从而达到敏捷设计的目标[2,14]。但为了做出准确的预测或是更好地优化EDA工具的服务质量(Quality of Service, QoS)信息,机器学习算法需要深度依赖代表底层设计的输入向量,并且鉴于电路网表的本质是一种图数据结构,图神经网络(Graph Neural Network, GNN)在EDA流程中的应用正变得越来越普遍。
图是以一种使用节点和边来表示的数据结构,能够用来建模一系列实体间的关系。近年来,基于图的深度学习模型,例如GNN在学术界以及工业界受到了广泛的关注,GNN遵循消息传递方案,其目标是通过递归地聚合和转换初始特征,在整个图或节点级别构建特征的有效表示方法,正是基于上述特性,GNN被普遍应用于社交网络[15]、知识图谱[16]、生物医学[17]等各个领域,并且许多不同的GNN模型也被提出用来执行在图上的学习。尽管GNN在这些领域取得了巨大的成功,但目前尚不明确GNN在EDA领域中取得类似成功的缘由。为此,文献[18]分析了图神经网络在EDA流程中应用的有效性来源,即GNN中隐式地嵌入了与特定的超大规模集成电路设计相关知识与归纳偏差。文献[19]首先回顾了GNN在EDA物理设计中所取得的最新研究进展,在此基础上,作者分析了GNN之所以能够在EDA物理设计领域取得上述成就的原因。文献[20,21]则关注了EDA技术与GNN间的联系,Ma等人[20]的研究首先指出了GNN在EDA问题求解过程中的巨大潜力,相关的研究表明,图结构对于布尔函数、网表以及版图等的表示是非常直观的,并且在结果质量 (Quality of Result, QoR)的改进效果方面能够超过传统的浅层学习或是基于解析式的求解方法,文献最终以测试点的插入和时序模型的选择两种测试用例说明了GNN在EDA技术中应用所具备的优势。文献[21]则是对卷积神经网络在EDA底层的应用进行了回顾,综述了机器学习等相关技术能够通过预测设计空间探索、功耗分析、物理设计等不同阶段的重要指标来提升设计的QoR的方法。文献[20,21]的研究明确说明了在EDA流程中引入GNN是非常重要的,但没有完全给出如何将GNN与EDA两个研究方向进行有效结合,其关注点仍大部分停留在浅层学习方法在EDA领域的应用。
本文针对基于GNN的EDA问题进行讨论,首先对GNN与EDA技术的问题背景与应用框架进行简要介绍,在此基础上,对当前国内外基于GNN的EDA技术(高层次综合、逻辑综合、布图规划与布局、布线、反向工程、硬件木马检测以及测试)的相关工作进行综述,最后总结出基于GNN的EDA设计中所面临的一系列的挑战以及相关的解决途径。
2 GNN与EDA技术概述
2.1 GNN技术概述
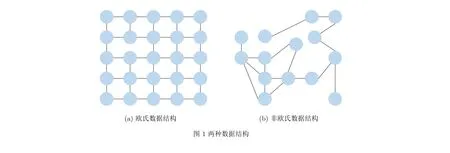
在过去的几年,随着人工智能(Artificial Intelligence, AI)和深度学习的不断发展,深度神经网络(Deep Neural Network, DNN)已成为深度学习的重要计算模型之一,在越来越多的领域取得了突出乃至超过人类专家的表现。为了具备更好的学习与表达能力,DNN“热衷”于堆积多层的神经网络层,这使得DNN能够高效地处理图像、语音、文本等形式的欧几里得(Euclid)数据[22]。图1(a)所示便是一种欧氏数据结构,其特点可表现为数据结构中的节点包含有固定的排列规则和顺序,例如2维网格或是1维序列。但当前越来越多的实际应用中,必须对非欧氏数据加以考虑。例如,作为一类能够描述关系的通用的数据结构表示方法,图能够非常自然地表现出现实场景中实体与实体间的复杂关系,在工业界的应用前景极其广阔,具体如图1(b)所示,在该非欧氏数据结构所表示的图中,节点没有固定的排列规则和顺序,这就使得我们无法将传统的深度学习模型直接应用到非欧氏结构数据的任务中。如果我们强制将卷积神经网络(Convolutional Neural Network, CNN)应用至图1(b)所示的数据结构中,由于非欧氏数据中心节点的邻居节点数量和排列顺序均不固定,并且不满足平移不变性,导致很难在非欧氏数据中定义卷积核[23]。
为了有效解决上述问题,研究学者开始了GNN技术的研究,GNN起源于2005年,通过将深度学习与图数据结构进行融合, GNN概念的提出,使得DNN在与图数据相关的场景中得到了更加广泛的利用。针对GNN的研究工作,最初始的工作主要针对如何将邻居节点的数量固定以及如何对邻居节点进行排序而展开。在完成上述研究工作后,便完成了从非欧氏数据至欧氏数据的转化过程,在此基础上便可以利用CNN对转换后得到的数据进行处理。图是一种具有节点和边的典型的非欧氏数据,一般情形下,图定义为G=(V,E),其中V表示节点的集合,E表示边的集合。VRvw表示两顶点之间关系的集合,它是集合E的 子集,若〈v,w〉∈VRvw,则〈v,w〉表示从v到w的一条弧,且称v为弧头节点,w表示弧尾或终端节点,此时的图称为有向图;若对于任意的 〈v,w〉∈VRvw必有〈w,v〉∈VRvw,即VR是对称的,则以无序对(v, w)代替这两个有序对,表示v和w之间的一条边,此时称此图为无向图。在实际问题中,可以将各种非欧氏数据问题抽象为图结构,例如在一个日常生活中所熟知的交通系统内,利用基于图的学习模型,可以对当前以及未来一段时间内的路况信息进行有效预测。再比如,在计算机视觉模型中,同样可以将人与物的交互当作是一种基于图的数据结构,从而进行有效的检测识别。
研究GNN对于推动EDA技术的发展、深度学习及人类的进步具有重大意义,EDA工具的输入,即电路网表文件便可以抽象为非欧氏结构数据,由于图数据的不规则性,传统的深度学习模型对于这种结构数据的处理显得力不从心,这便亟需研究设计一种新的DNN模型,而GNN所能够处理的数据正是这种具有不规则结构的图数据。此外,图数据的结构和任务是十分丰富的,这种丰富的数据结构和任务也正与EDA流程中要处理的实际问题相贴合。所以,GNN的研究为解决EDA领域中的实际问题找到了一种新的方法和途径。
2.2 EDA技术概述
根据 市场研究公司(Research and Markets)相关数据,2025年全球EDA市场规模将达1.45×1010美元,直接支撑起的半导体制造市场规模达7×1010美元,再向上将是继续支撑起万亿规模的数字经济,杠杆效应接近200倍。现阶段的全球市场上,EDA市场的集中度较高,新思科技(Synopsys)、楷登电子(Cadence)以及Siemens EDA(原Mentor,已被西门子收购)占据了市场的主要份额。在摩尔定律的推动下,5 nm的芯片能够容纳1.25×1010个晶体管,必须依赖EDA工具才能够完成集成电路设计、版图设计、版图验证、性能分析、硬件木马检测等一系列工作[24]。但美国《2022芯片与科学法案》中对5 nm及其以下的最先进制程EDA工具也进行了封锁,由此可见EDA软件工具已经成为集成电路芯片设计制造环节中必不可少的战略支撑要素。
EDA工具的设计流程主要分为前端设计与后端设计两大组成部分[25],具体如图2所示,其中前端设计负责逻辑实现并验证,包含功能设计、系统设计、高层次综合(High Level Synthesis, HLS)、逻辑综合与验证等几个部分,后端设计负责生成相应逻辑设计的物理实现部分,即将逻辑网表数据映射到物理版图上,并确保后续制造过程的鲁棒性。后端的设计环节具体包含物理设计、物理验证、掩模设计与验证以及封装测试等几个重要的步骤。在实际设计实现的过程中,由于前端设计与后端设计的各个流程间的信息需要相互依赖,各个步骤之间需要反复迭代才能够最终实现设计的收敛[25]。此外,硬件安全技术,例如反向工程或是硬件木马检测贯穿了上述的各个流程,用以保证集成电路设计过程的安全可靠。
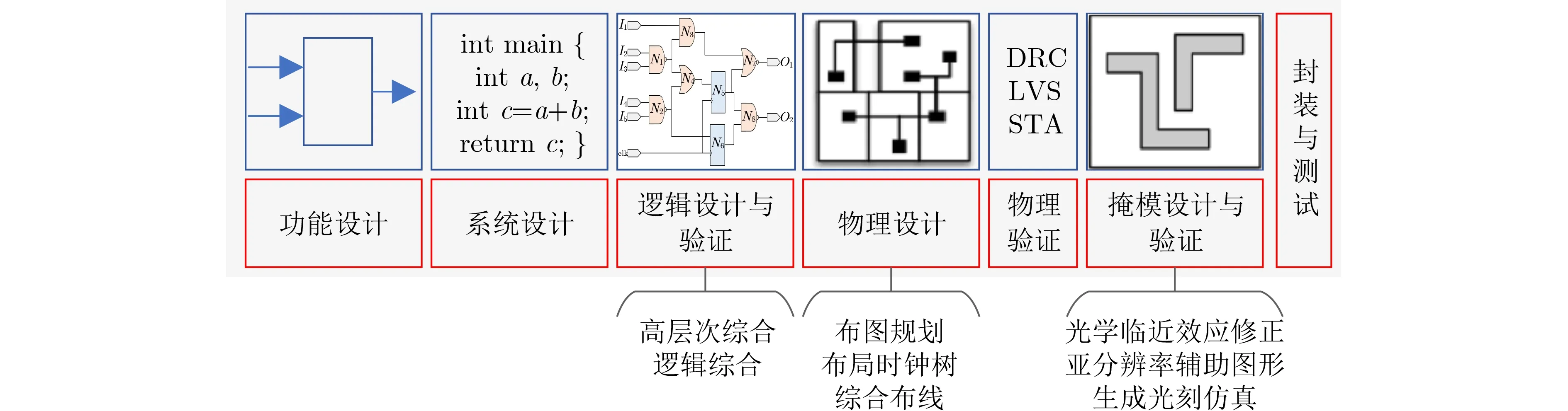
图2 EDA设计流程
随着成本的越来越高、分工越来越复杂,不论是学术界或是工业界都在尝试新的技术与解决方案,试图超越摩尔法则,以此来实现功耗最低、性能表现最佳、成本最优。特别是在超越摩尔定律的先进集成电路技术这条道路上,即新材料、新器件、新架构或是新集成与新工具等对EDA工具不论是从设计效率、对更强复杂功能设计的支撑能力亦或方法学上的创新都提出了更高的要求。只有这样我们才能够在工艺不占优势的情形下,研制出与先进工艺性能相匹配的高端芯片,从而突破被“卡脖子”的不利局面。幸好,GNN技术的出现为EDA技术的发展指明了一条全新的发展思路,走一条电子设计智能化的新赛道是实现“后摩尔时代先进集成电路技术”弯道超车的有效途径。
3 基于GNN的EDA技术研究进展
3.1 高层次综合技术
在逻辑综合阶段,描述硬件设计的寄存器传输级(Register-Transfer Level, RTL)设计代码将被映射为事先定义好的技术映射库中的一系列逻辑单元,与此同时,上述过程必须满足相应的时序约束,以便在考虑面积以及功耗等QoR指标的条件下,在所需要的时钟频率下能够正常运行。因此,逻辑综合是一个可以应用强化学习进行求解的复杂优化问题。在逻辑综合执行的初期进行QoR预测,可以避免多次重复的迭代。例如,为了更加准确地预测现场可编程门阵列(Field Programmable Gate Array, FPGA)中逻辑单元的延迟信息,文献[26]对FPGA中算术运算的映射和聚类模式进行了有效的学习,进一步提出了一种全新的架构D型采样与特征聚合 (D- Sample and AggreGatE, D-SAGE),具体如图3所示,在D-SAGE工作流程中,HLS的中间表示将被映射为数据流图(Data Flow Graph,DFG),并在执行技术映射后将DFG操作与网表对象进行匹配。DFG中节点表示相关的操作信息,例如加法或是乘法。边表示节点间的数据依赖关系,数据的节点类型与位宽信息被视为节点的属性,随后根据端到端的任务将节点和边进行标记即可。即如果节点被映射到DSP模块或是查找表LUT,则可以分别将它们标记为1或0。类似地,如果边的连接点映射到相同的逻辑单元,则相应的边将被标记为1。上述标签信息将被用于GNN模型的训练,模型训练完成后便可以使用训练好的GNN模型从给定的数据流图中推断出相对应的映射模式。D-SAGE可以成功地将操作映射学习到对应的逻辑资源中,从而有效地避免了将HLS子图匹配到FPGA资源的繁琐过程。

图3 算术密集型设计中基于GNN的运算映射与聚类学习
为了尽可能早地从设计阶段加快对电路性能的评估,美国加州大学圣塔芭芭拉分校谢源教授团队[27]提出了一种快速准确的性能建模方法,通过将C/C++程序表示为图从而充分利用图神经网络的特征表示能力,完成性能的预测。本文的具体贡献主要体现为以下3个方面:(1)首先,构建了一个包含40K的C语言可综合的测试基准,其中包括综合程序以及3套来自真实世界的HLS的测试基准,每个程序都在FPGA上进行了实现,用以生成真实的性能指标。(2)在图上对性能预测问题进行了建模,并利用预测及时性(即早期预测或是晚期预测)与准确性之间的不同权重,提出了多种基于GNN的建模策略。(3)进一步对GNN进行了分层处理,在不牺牲性能预测及时性的前提下,大幅度提升性能预测的准确性。通过对不同测试用例的对比评估,在资源使用和时序预测方面,该方法平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)对比HLS方法最高降低了近40倍。
此外文献[27]同时对基于GNN的HLS设计空间探索方法进行了研究,并提出了IRONMAN (Design Space Exploration in High-Level Synthesis via Reinforcement Learning)架构[28],该架构主要由基于GNN的性能预测器(GNN-based Performance Predictor, GPP)、基于强化学习的多目标设计空间探索(RL-based Multi-objective DSE, RLMD)以及代码转换器(Code Transformer, CT) 3个部分构成,具体如图4所示。其中,GPP主要负责HLS设计的性能预测,具体包括逻辑资源(DSP以及LUT)的利用率以及关键路径的时序信息,同时GPP也适用于从DFG中进行性能的预测评估。RLMD主要负责HLS的资源分配,在GPP的协助下,RLMD能够充分完成用户指定约束下的资源优化分配策略,同时还能够提供不同目标之间帕累托最优解决方案,而这正是HLS工具所无法提供的。CT是一个代码转换器,能够从原始的HLS C/C++代码中提取出DFG,并能够在RLMD优化后的HLS指令的基础上,重新生成可综合的代码,CT能够在用户指定的约束下实现灵活且更细粒度的DSE。通过上述3个模块的相辅相成,IRONMAN能够将HLS工具在资源使用上的预测误差降低10.9倍,关键时序信息的预测误差降低5.7倍。相比遗传算法或是模拟退火方法,IRONMAN所获得的帕累托解决方案分别提升了 12.7%与12.9%。并且在实际的测试基准中,IRONMAN能够寻找到满足各种DSP约束的解决方案,与HLS工具相比,DSP的数量减少了2.54倍,延迟缩短了6倍,同时相比启发式方法和HLS工具其求解速度提升了400倍。在上述工作的基础上,文献[29]对IRONMAN作了进一步改进,提出了IRONMAN-PRO (Multi-objective Design Space Exploration in High-Level Synthesis via Reinforcement Learning and Graph Neural Network based Model)架构,GPP, RLMD以及CT的性能都得到了进一步的提升。

图4 IRONMAN体系架构示意图
3.2 逻辑综合技术
逻辑综合是将所设计数字电路的RTL级描述,在满足约束的条件下,将RTL级描述转化为指定的工艺库中单元电路的连接的过程。逻辑综合主要包括翻译、优化与工艺映射3个阶段。在翻译阶段,硬件描述语言(Hardware Description Language,HDL)将被翻译为相应的功能块以及功能块之间的拓扑结构,在此基础上,逻辑综合器将根据所施加的时序和面积约束,按照一定的算法对翻译结果进行逻辑重组并优化,最后便是从目标逻辑资源库中搜索符合条件的逻辑单元来构成实际电路的逻辑网表的过程。因此,逻辑综合是一个非常复杂的设计空间探索的过程。在逻辑综合阶段,电路网表中逻辑单元的位置信息与布线信息并没有事先确定,GNN概念的引入为上述问题的求解指明了方向,在GNN的模型中,整个网表被抽象为一张有向图,节点和边也不再是单个独立的样本,而是通过图结构实现了互联,这样整个图中所包含的信息更加全局化,由此也弥补了在逻辑综合阶段由于电路网表中逻辑单元位置信息和布线信息的缺失而带来的影响。
2022年谢源教授团队[30]研究了GNN在EDA逻辑综合领域的应用,提出了一种全新的性能预测方法,具体如图5所示。针对逻辑综合的工作流程,利用混合图神经网络提供精度更高的结果指令的预测以及更加强大的泛化能力,该方法的关键在于能够利用来自硬件设计和逻辑综合流程的空时信息来预测不同设计上各种逻辑综合流程的性能,主要包括延时以及面积等信息。具体而言,首先使用GNN来提炼出硬件设计内部的结构特征,在此基础上,利用增加的虚拟节点与传统GNN模型相结合的方式,将逻辑综合流程中的时间知识添加到硬件设计上,相关实验结果表明,该方法能够更加快速地预测出不同设计在面积以及延时方面的性能,其平均绝对百分比误差相比现有研究而言分别降低了7倍与15倍。

图5 HLS性能预测方法体系架构示意图
3.3 布图规划与布局技术
集成电路布图规划与布局作为典型的超大规模NP困难组合优化问题,对集成电路的性能指标将产生重大影响。同时由于过去几十年芯片架构的急剧演进,布图规划与布局的流程变得越来越富有挑战性。随着越来越大的设计以及越来越复杂化的设计约束和目标,都使得研究人员越来越追求依托更大的计算量和更多的计算资源来寻找满足所有约束的合法解决方案,但这也导致了更长的物理设计周期以及更慢的性能收敛速度。
基于上述问题,Google公司在2021年提出了一项具有跨时代意义的工作,并将其发表在《Nature》上,Google公司在GNN的基础上,提出了一种基于边的神经网络(Edge-GNN),同时将其纳入到强化学习的架构当中以完成对不同状态的编码过程,并成功将该方法应用于Google自身的张量处理器(Tensor Processing Unit, TPU)的设计流程中,能够在数小时内设计出与人类专家QoR相当的设计结果[31]。
为了进一步加速布局的流程,文献[32]与文献[33]基于图采样与特征聚合(Graph SAmple and aggreGatE, D-SAGE)构建了基于图学习的体系架构,用来辅助布局工具进行有效的决策,从而加速布局流程的收敛。PL-GNN首先将网表转换为一个有向的超图,其中节点和边的特征是基于层次信息以及线网与内存块的关联性而构建的。在此基础上,GNN模型被用来学习节点的嵌入,并通过加权的K-Means算法完成聚类操作,由此产生的聚类解便是一个最佳的布局解决方案。与商业工具相比较,基于图学习的体系架构的线长优化了3.9%、功耗优化了2.8%。
除以上方法,上海交通大学严骏驰教授团队[34]针对大规模集成电路中宏模块与标准单元的布局问题,在2021年提出了一种基于强化学习与GNN的DeepPlace布局框架,即通过强化学习和神经网络所形成的梯度优化分别完成对宏模块与标准单元的布局自动化过程,该工作也是学术界内首篇应用神经网络方法同时考虑宏模块与标准单元布局的研究工作。
在布局的过程中进行设计规则违例的预测同样是一项非常重要的研究工作,因为非法的布局将会造成布线拥塞等设计违例问题的出现,进而使得布线资源紧张,从而降低芯片性能[1]。因此,在布局阶段进行规则违例预测模型的构建变得极其重要。在违例预测模型构建完成后,便能够在布局阶段进行例如布线后拥塞结果的预测,从而方便对布局方案进行实时调整,提前对布局质量进行优化。随着GNN相关研究的兴起,应用GNN来实现设计规则违例的预测正逐步成为一种趋势。
国外在这方面的研究起步相对较早,Nvidia公司研究人员首先在2019年提出了一种基于图的深度学习方法[35],相比于其他方法,拥塞预测准确率提升到了75%。同时,该方法对于大规模的网表文件同样是适用的,例如,对于一个包含1.3×106标准单元的电路而言,该方法能够在19 s内给出较为准确的拥塞预测结果,而其他同类方法的耗时为10~60 min。
除国外上述研究外,国内华为公司诺亚方舟实验室团队首先在2021年提出了一种基于GNN的拥塞预测方法,并在DREAMPlace以及OpenRoad等开源EDA工具中进行了测试,相关结果表明,该方法能够有效提升预测性能,并且能够节省90%以上的运行时间[36]。西南交通大学邸志雄教授团队[37]在2022年提出了基于GraphSAGE的方法,通过训练图神经网络模型来建立布局的特征与详细布线后短路违例的关系,以进一步提高预测的精确性。该方法的具体工作流程如图6所示。整个流程分为物理设计阶段、特征提取阶段以及训练与评估阶段。在物理设计阶段,通过EDA工具的布局器与布线器对指定网表完成布局与布线的操作,在完成布局操作后,文章使用了类似文献[38]中的方法将布局进行了拆分,形成了一块一块的非重叠的正方形的图块(Tile),每个图块的规模均为3×3的全局布线单元(Global Routing Cell, GRC)。随后便可以基于图块间的位置关系建立邻接矩阵,并在每个图块中提取影响可布线性的关键特征因素,例如标准单元的引脚以及线网等信息。最后,用布线后的短路违例来标记这些图块,其中包含短路的图块标记为正实例(Positive Instance, PI)1,相反则标记为负实例(Negative Instance, NI)0。在此基础上,将邻接矩阵、特征信息以及标记好的数据加载到图神经网络GraphSAGE模型中进行训练。模型训练完成后,将新的布局网表中的邻接矩阵和特征信息输入到训练好的模型中即可快速精确地确定每个图块中是否会出现短路违例。最终的实验结果表明,该预测模型能够在具有更多短路违例的设计中实现更好的2元分类性能,并且在实际应用中的性能也要优于先前的基于归纳学习的相关工作。
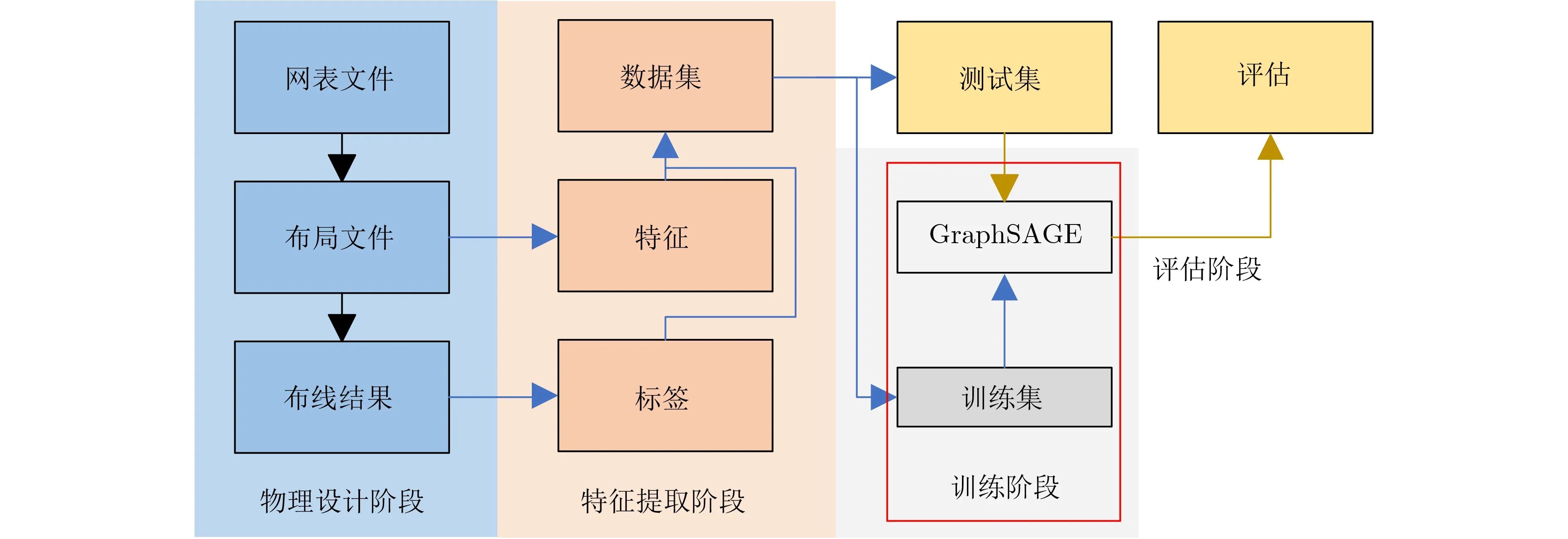
图6 基于GraphSAGE的短路违例预测方法
3.4 布线技术
在超大规模集成电路设计中,布线的目的是在规定的布线区域内实现电路内部各个模块间的物理连接,它是超大规模集成电路物理设计阶段非常关键的步骤之一。随着工艺的不断发展,集成电路变得越来越复杂,单位面积中晶体管的数量呈指数增长,元器件间的连接关系也越来越复杂,从而导致超大规模集成电路的布线任务越来越困难。然而现阶段的自动布线算法布通率较低且速度缓慢,当前在工业应用中仍然需要大量依赖于工程师手动进行布线,导致了大量的时间和人力资源被消耗在布线工作中。因此,亟需一种能够实际应用于现代大规模集成电路设计的智能布线算法来提升EDA工具的设计效率。针对当前EDA工具布线智能化程度低、自动化率低、效果差的问题,文献[34]提出了一种依赖GNN的布线方法。该文提出了两个强化学习的架构DeepPlace和DeepPR,其中DeepPlace仅仅用来优化布局流程,DeepPR则能够同时对布局与布线的流程进行优化。DeepPR使用来自GCN的详细节点嵌入作为强化学习架构的策略网络,相应的实验结果表明,DeepPR可以非常高效地从历史经验中进行学习,布局、布线后的半周线长(Half-Perimeter Wire-Length, HPWL)指标较现有方法而言优化了8.41%。
3.5 硬件安全技术
随着现代信息技术的发展,大规模集成电路的应用范围也越来越广泛,小至各类电子产品,大至航天器、导弹、雷达等国家战略军工产品。集成电路的广泛应用为我们带来信息时代红利的同时,也带来众多不可避免的安全问题。近年来,集成电路芯片受到的恶意攻击和探测出的硬件漏洞层出不穷,甚至集成电路芯片设计流程中,在某些不能做到自主可控的环节链条,还可能被进行反向或恶意植入硬件木马,在国家信息安全被越来越重视的时代,硬件安全引起了国内外研究人员的广泛关注。
在EDA的工作流程中,反向工程是通过分析芯片的每一层来获取知识产权(Intellectual Property,IP)或集成电路设计功能的过程。此类分析的结果往往可被用于功能验证以及安全保护的目的。集成电路的反向工程主要可以分为以下几个阶段,即产品拆解、系统级分析、过程分析以及电路提取[39–42]。产品拆解有助于对集成电路的内部组件进行识别,而系统级分析则有助于完成对底层功能以及逻辑门之间的互连等关系进行分析。过程分析主要是为了对电路的结构和材料进行分析,以此来挖掘出集成电路可制造性方面的信息,最终进行电路提取以完成电路级原理图的构建。近年来,一些研究学者提出了基于GNN的方法来进一步提升数字集成电路反向工程系统的性能,例如,文献[43]提出了一种面向门级网表的基于GNN的反向工程方法GNN-RE,用于进行子电路的提取和分类。具体如图7所示,GNN-RE首先将门级网表映射为一个无向图,图中的节点对应于标准门单元,图中的边则对应于门单元间的连接关系。在无向图中,每个节点的特征向量包括当前节点所连接到的主输入与主输出的数量、按类型划分的两跳连接门的数量以及输入与输出的度。此外,GNN-RE还广泛地比较了不同种类的GNN模型以及计算模块,最终的实验结果表明,通过将GAT与GraphSAINT的采样模块结合使用可以获得最佳的结果,在EPFL与ISCAS-85等70余个基准电路上能够获得98.82%的平均精度。与GNN-RE相类似,为了解决门级网表中算术块识别过程所存在的可扩展性问题,文献[44]提出了一种基于异步双向图神经网络(Asynchronous Bidirectional Graph Neural Network, ABGNN)的方法,专门用于有向无环图的表示学习。对开源RISCV中央处理器设计的实验结果表明,相比于传统方法,该求解方案能够以最快的运行时间实现最高的预测准确度。

图7 基于GNN的子电路提取与分类方法示意图
RTL级的第三方IP复杂而灵活,能够支持不同应用程序下的多种配置,但同时也为硬件木马的插入提供了途径。硬件木马在庞大的电路设计中所占面积很小。因此,它可以悄悄地隐藏在集成电路的设计中,人们往往很难通过肉眼或者简单的检测手段发现硬件木马的存在。并且在不可信的第三方IP的情况下,IP的Golden模型是无法获取的,那么便无法使用基于测试或是测信道的方法来进行硬件木马的检测。此外,一些破坏性方法,例如反向工程,虽然能够检查集成电路是否感染了硬件木马,但只能在制造后进行。其他的一些硬件木马检测方法,例如基于图相似性的方法,虽然能够进行硬件木马的检测,但其复杂度偏高并且无法对一些未知的硬件木马进行有效的识别。
为此,文献[45]提出了一种基于GNN的硬件木马检测平台GNN4TJ, GNN4TJ能够在事先不了解设计IP或硬件木马结构的前提下完成硬件木马的检测识别,GNN4TJ首先将RTL设计转换为相应的数据流图DFG,随后将DFG输入到GNN模型内部用以进行特征的提取以及底层设计结构和行为的学习。在此基础上,GNN将执行图形分类任务以进行硬件木马的识别。最后,该文在TrustHub测试基准上对模型进行了验证,相关的实验结果表明,GNN4TJ能够在21.1 ms内以97%的真阳率非常快速地检测到未知的硬件木马。除上述研究外,研究人员也提出了其他基于GNN的硬件木马检测平台[46–49],以进行硬件木马的检测与定位,相关工作流程与GNN4TJ大致相同,这里不再进行赘述。
3.6 测试技术
为了保证芯片设计过程中的性能与可靠性,仅仅关注硬件安全是远远不够的,还需要对芯片设计过程中的测试验证环节进行关注。一般情况下,测试的工作发生在封装的流程之后,设计的规模越大,测试工具的复杂性和执行时间便越高。此外,测试还需保证较高的覆盖率、避免冗余的测试用例,并且测试在很大程度上需要研究人员的专业知识,通常情况下不具备扩展性[50]。为了克服以上问题,有研究学者将GNN的方法引入到了测试的流程中,例如,为了能够在设计中通过提供最佳的测试点来降低测试的复杂性,文献[51]提出了一种高性能的图卷积神经网络(Graph Convolution Neural Networks, GCNNs)模型,用于处理数字逻辑电路的不规则图表示,同时能够最大限度地提高故障覆盖率。为了实现上述目标,文献[51]首先训练了一个GCNNs分类器来预测网表中的候选观测点,随后GCNNs分类器将被用作迭代过程的一部分,基于分类的结果从而进一步给出观测点的插入位置。相关的实验结果表明,该文献所提出的GCNNs模型在一些难以观测的节点的预测方面具有优于典型机器学习模型的精度,与现有商业可测试性分析工具相比较,文献[51]所提出的观测点插入流程实现了类似的故障覆盖,从而进一步将观测点减少了11%,观测模式数量减少了6%。
最后,表1对上述基于GNN的EDA技术进行比较分析。

表1 基于GNN的EDA技术
4 GNN在EDA技术中应用的挑战
基于GNN的EDA技术的主要目标是EDA工具通过自主学习的过程实现无人参与的设计自动化,尽可能减少人工干预以及设计的返工迭代。随着集成电路技术的发展,工艺特征的尺寸也在减小,导致当今芯片设计面临巨大的挑战,基于GNN的EDA技术可以显著地提升集成电路的设计效率,是未来实现无人参与的敏捷设计的重要研究内容[2]。目前,基于GNN的EDA技术的研究尚处于起步发展阶段,其未来的发展方向也存在着很大的不确定性。因此,接下来将从相关的局限性出发,对基于GNN的EDA技术所面临的挑战及其可能的应对措施进行说明。
(1)毋庸置疑,基于GNN的EDA体系架构要明显优于浅层机器学习、深度学习方法或是一些已有的解决方案,这主要是由于GNN能够对拓扑结构以及相应的特征信息进行有效的提取,但这同时也是以构建更大的数据集和更长的模型训练时长为代价的。GNN与其他的神经网络相类似,其表现形式类似一个黑盒。因此,如果想要在真实的EDA流程中应用GNN, GNN预测的安全性以及可解释性是我们不可忽视的一个重要问题。
(2)GNN模型的训练过程通常对运行时间以及对应数据集的大小具有严格的要求,需要针对EDA工具的输出结果对数据进行收集并标记。但现阶段相关数据集的获取是非常困难的,一方面涉及具体商业保密问题,集成电路的设计企业不会主动将这部分数据进行公开。另一方面,开源数据的获取也同样缺乏相关渠道,虽然近年来一些研究团队专门针对基于机器学习的EDA开源数据集进行了研究,例如北京大学林亦波教授团队在2022年发布了针对机器学习的EDA数据集CircuitNet[52],但这并不是为GNN模型而定制的。针对这一问题,可以采用像训练其他神经网络一样事先进行模型的预训练过程,进而采用迁移学习的方式,将已训练好的模型迁移至与之相类似的问题。例如,文献[31]便采用了迁移学习的策略,能够大幅度缩短GNN模型的训练时间以及所需要的训练数据量。再比如,可以采用“共享”与“微调”相结合的方式,即对于某一类基于GNN的EDA方法而言,可以将GNN模型的构建过程划分为“共享层”与“微调层”两个部分,一些EDA求解问题的共性参数可以放到“共享层”中进行训练,对于某些EDA求解问题所独有的参数则可以在“微调层”中进行训练,那么对于一个已预训练好的GNN模型而言,在向另一个EDA求解问题进行迁移的过程中,便只需针对GNN模型的“微调层”参数进行训练即可,这对于降低训练GNN所需要的样本数量以及训练时间是非常有利的。
(3)从EDA的角度来看,输入到GNN模型中的图数据大多是不同抽象级别的电路网表,通常情况下这些电路网表的规模会非常大,这样便导致输入到GNN模型的图数据需要维护一个非常巨大的并且稀疏的邻接矩阵,这对计算量的要求是非常巨大的。与一些简单的有向图或是无向图相比较,EDA工作流程中的电路网表往往表现为一个复杂且有向的超图结构,因此,研究特定的GNN架构以使其能够更好地处理EDA电路网表的超图结构数据仍然是一个非常值得探索的研究方向。
(4)现阶段GNN架构的实现大多依赖图形处理器(Graphics Processing Unit, GPU)及其相关的生态环境,例如PyTorch的PyTorch Geometric(PyG),TensorFlow与Keras的Spektral,以及与架构无关的深度图形库(Deep Graph Library, DGL)。但需要注意的一点在于上述工具生态距离完全自主可控仍存在较大的差距,现阶段仍需依赖国外科技巨头的GPU显卡,还做不到相应国产GPU生态的支持,相应的基于GNN的EDA技术仍存在较大的被“卡脖子”的风险,这一点与传统的基于机器学习的EDA技术相类似,但不同之处在于,传统的机器学习算子库的兼容相对而言较易实现,国内外也出现了许多相似的研究,例如,在半定制的FPGA上实现对普通PyTorch库的兼容,从而可以完美实现对GPU的替代[53]。但GNN相关的研究现阶段仍停留在理论探索阶段,尚未出现实际替代产品。因此,大力发展国产GNN算子库相兼容的生态,构建具有自主可控的软硬件环境是我们下一步需要重点考虑的内容。
(5)上面提到的基于GNN的EDA技术的解决方案最终需要嵌入到实际的EDA工具内部,以此来指导EDA设计流程的优化,依据GNN模型对EDA工具设计流程的影响程度,现阶段主要可以总结为以下3类:EDA工具调用GNN模型、将EDA工具与GNN模型进行有效集成以及基于GNN模型的辅助优化决策,在上述3个层次中,无人参与的程度由低到高不断递进,在最后一个层次中,可以根据EDA工具的输出结果给出合理的性能优化建议,这样可以显著减少EDA设计流程中由于人为参与所导致的一系列的不确定性因素,提供智能化的辅助设计方法。与此同时,GNN模型优化输出结果的可兼容性是非常重要的,如何将GNN模型的优化结果与现有主流EDA工具的中间结果相兼容,是实现上述将GNN逐步融入到EDA工具内部的关键。
5 结束语
将GNN技术应用于解决EDA流程,通过这种方式EDA工具可以从先前的经验中进行学习,并能够更有针对性地解决一些模型构建、性能预测以及最优求解问题。截至目前,GNN技术已在EDA体系的各个流程中得到了应用。本文围绕基于GNN的EDA技术,将GNN在EDA流程中各不同阶段的应用情况进行了综合性的阐述,在此基础上,总结了当前基于GNN的EDA技术所面临的一系列挑战,给出了相对应的发展建议。作为前沿领域最新的发展方向,基于GNN的EDA技术中仍存在许多未知的问题值得进一步研究,这需要集成电路设计及相关领域的专家学者共同携手,共同提升现有EDA工具的结果质量。同时作为先进集成电路技术未来的一个重要发展方向,相信随着相关研究的不断深入,基于GNN的EDA技术将成为未来我国芯片产业突破“卡脖子”问题的重要途径。
