基于混沌寻参LSSVM的棉织物靛蓝染色预测模型
2023-08-10王碧峤张梅王静姜晓巍李敏王玲玲张舒畅
王碧峤 张梅 王静 姜晓巍 李敏 王玲玲 张舒畅





摘要: 针对棉织物在靛蓝染色时染色工艺条件对染色深度的非线性影响,导致染色深度难以控制,不符合客户要求的问题,文章选取氢氧化钠浓度、保险粉浓度和靛蓝染料浓度三个主要影响因素作为输入变量,表观颜色深度(K/S值)作为输出变量,采用Python语言进行编程,以混沌算法进行寻参,应用最小二乘支持向量机(LSSVM)算法建立了靛蓝染色预测模型,并对模型的预测性能进行了验证。结果表明:该模型对织物K/S值预测的平均绝对百分比误差为1.759 7%,均方根相对误差为0.029 4%,比网格寻参法的预测误差更小,说明该模型具有较高的精度和良好的预测能力,可以为棉织物靛蓝染色工艺的预测和优化提供参考。
关键词: 混沌算法;最小二乘支持向量机(LSSVM);Python;棉织物;靛蓝;染色预测模型
中图分类号: TS190.9; TP181
文献标志码: A
文章编号: 1001-7003(2023)07-0041
作者简介:
王碧峤(1984),女,讲师,博士,主要从事天然染料染色、功能性纺织品方面的研究。
靛蓝作为一种还原染料,历史悠久,应用广泛。由于靛蓝不能直接上染棉织物,在染色过程中通常要加入碱和还原剂,在碱性环境还原成可以上染的隐色体后进行染色。染料、碱和还原剂的用量对靛蓝染色棉织物的表观颜色深度(K/S值)的影响是非线性的,为了达到想要的K/S值,目前常用单因子实验法和正交实验法来确定最优工艺[1-2]。然而,这些方法有如下缺点:1) 虽然进行了多次实验,但由于所取的工艺参数数值不连续,找到的最优工艺可能并非实际中真正的最优,而是所取工艺参数下的最优;2) 其最优工艺的标准是K/S值达到最大,即表观颜色最深,但在实际生产过程中,最优工艺应该是尽可能贴近客户所要求色深的工艺。因此,一个能够通过染色工艺条件准确预测织物K/S值的模型对于降低成本、提高工艺变换效率具有重要意义。
目前,建立精确的预测模型一般采用机器学习的方法,如神经网络[3]、支持向量机(Support Vector Machine,SVM)[4]和最小二乘支持向量机(Least Squares Support Vector Machine,LSSVM)[5]等。LSSVM是SVM的一种扩展,它降低了计算的复杂性,提高了机器学习的速度,在对小样本、非线性数据的识别和预测中具有独特的优势,在电子、化工、电气等领域的预测模型中得到了广泛应用,但是在染色研究方面仅有几篇应用于活性染料染色棉织物的报道[6-7]。
LSSVM的超参数对于模型的精确度有很大影响,因此选择合适的超参数非常重要。目前常用的超参数寻优的方法有网格搜索法[7]、粒子群算法[8]、蚁群算法[9]等。网格搜索法简单易行、应用广泛,可以通过较大的搜索范围及较小的步长,找到全局最优解,但较为耗费计算资源和计算时间,效率较为低下。因此,实际应用时一般先使用较大的搜索范围和步长来寻找全局最优解的位置,再逐渐缩小搜索范围和步长以确定最优值,这样可以节省计算的时间和资源,但对于非凸函数很可能会错过全局最优解。粒子群算法和蚁群算法能够有效地提升模型精度,但也有容易陷入局部最优解的缺点。混沌算法全局搜索能力强、能有效避免陷入局部最优解,且搜索效率较高,有利于建立精确的LSSVM模型[10]。
本文基于Python语言及其扩展模块,利用混沌算法进行超参数寻优,从而建立一个用较小样本量也能够快速、精确预测靛蓝染色棉织物K/S值的LSSVM模型。
1 染色预测模型
1.1 输入变量选取
靛蓝染色过程中,影响染色织物K/S值的因素有很多,如果将所有影响因素都作为输入变量,会大幅增加建模的计算量,所需样本量也会增加,因此需要对输入变量进行选择。通过对靛蓝上染棉织物机理的分析,再结合染色实践的经验,最终筛选出靛蓝染料浓度、氢氧化钠浓度和保险粉浓度这三个影响因素。
这三个因素既是影响靛蓝染色棉织物的K/S值的主要因素,也有较强的交互作用:靛蓝染料浓度直接影响氢氧化钠和保险粉的用量;氢氧化钠浓度太低会造成染液pH值太低,靛蓝无法充分还原成单酚钠离子型隐色体,若氢氧化钠浓度太高则会导致染液pH值过高,保险粉消耗增加,靛藍被过度还原成上染率较低的双酚钠离子型隐色体;保险粉浓度太低会导致靛蓝还原不充分,太高会导致染液pH值下降甚至变成酸性,靛蓝无法充分还原[11]。因此,这三个因素直接影响染液中可上染的靛蓝隐色体的浓度,进而影响染色织物的K/S值。
其他因素如染色温度、染色时间等,虽然也对K/S值有影响,但对染液中靛蓝隐色体的浓度影响不大,为了减少建模的计算量,未选择这些因素,只选择靛蓝染料浓度、氢氧化钠浓度和保险粉浓度这三个因素作为染色预测模型的输入变量,染色后棉织物的K/S值作为输出变量。
1.2 LSSVM染色预测模型
由于选择了三个因素,且三个因素对染色后棉织物的K/S值的影响是非线性的,这要求建立模型的算法应该支持高维运算和非线性样本。同时,为了节省工艺成本,提高工艺变换的效率,应尽可能以较少的样本量达到较高的预测精度。LSSVM算法则能够满足这些要求建立预测模型。
将25组染色数据转换为训练样本集{(xi,yi),xi∈Rn,yi∈R,i=(1,2,…,m)},其中x为n维输入数据,在此模型中即为三个影响因素:氢氧化钠浓度、保险粉浓度和靛蓝染料浓度所组成的3维输入数据;y为一维输出数据,在此模型中即为K/S值;m表示训练用样本量,在此模型中m=25。建模用的LSSVM的算法[12]主要描述如下:
1.3 数据集制作
为对模型进行训练并对模型的预测准确性进行验证,用不同的实验参数对棉织物进行染色,并测量染色后的K/S值。制作数据集时,在较小的样本量下,样本数据要有较好的覆盖性,并具有一定的随机性。首先,在靛蓝染色常用的浓度范围内,分别对氢氧化钠浓度、保险粉浓度和靛蓝染料浓度进行5水平的单因子实验,并剔除重复的实验参数,共得到13组染色数据。其次,根据靛蓝染色的机理,靛蓝染料浓度决定了染液中能够上染的隐色体浓度的上限,也决定了被染织物K/S值的上限,而氢氧化钠和保险粉的用量决定了有多少靛蓝被转化成隐色体,因此以靛蓝染料浓度作为核心,确保每个水平的靛蓝染料浓度都有5组染色数据,氢氧化钠和保险粉的用量尽可能覆盖整个区域,在此前提下,补充了12组实验。最后,为使数据集有一定随机性,随机选择了5组实验参数,共得到30组染色数据。随机抽取25组染色数据,作为训练模型的训练集,剩余5组染色数据用于验证模型预测准确性的测试集。用于制作数据集的染色实验和测试的具体方案如下:
织物:纯棉平纹织物,经纬向密度分别为252、216根/10 cm,平方米质量为129.5 g/m2。
材料:植物靛蓝粉(贵州绣娘文化有限公司),氢氧化钠(分析纯,天津市大茂化学试剂厂),保险粉(分析纯,天津市福晨化学试剂厂),无水碳酸钠(分析纯,天津市天力化学试剂有限公司),皂片(商用,上海市纺织工业技术监督所)。
仪器:Datacolor 200测色配色仪(美国Datacolor公司),HZT-A+200电子天平(华志科学仪器有限公司),HH-S6数显恒温水浴锅(常州国宇仪器制造有限公司)。
染色流程:靛蓝还原(一定量的靛蓝粉、氢氧化钠、保险粉混合液,温度40 ℃,还原20 min)→染色(40 ℃,20 min)→空气氧化(10 min)→水洗→皂洗(皂片3 g/L,纯碱3 g/L,浴比50︰1,温度90 ℃,时间10 min)→水洗→自然晾干。
K/S值测试:使用Datacolor 200测色配色仪以CIE标准照明体D65光源,10°视角测试染色后棉织物在660 nm波长处的K/S值,在每个样品的不同位置测试3次,取平均值。
1.4 染色预测模型的实现
染色预测模型通过Python语言编程实现。Python语言
是一种开源的机器语言,比起科研建模常用的Matlab,它具有免费、不受版权限制、可移植性好的特点,更适合在生产实践中使用。使用Visual Studio Code编译器运行Python 3.0,并导入Numpy、Random和Openpyxl模块。其中,Random模块用来产生(0,1)之间的随机数,进而产生混沌变量;Numpy模块用来将样本转化成高维数组并进行运算;Openpyxl模块用来将输出结果导出为“.xls”文件。
2 结果与分析
2.1 染色预测模型训练
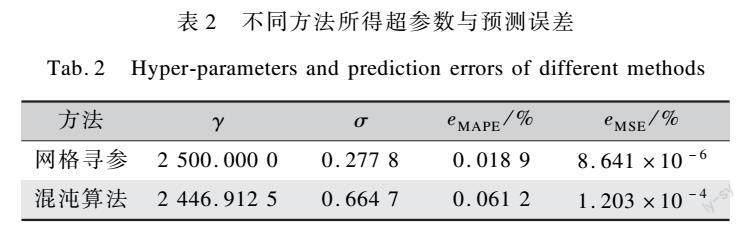
根据混沌优化算法,最终选择的最优超参数(γ,σ)=(2 446.912 5,0.664 7),b=5.997 6。用训练集的25组染色实验数据作为样本进行模型训练,样本的测试值和预测值见表1。其中,预测值保留4位小数。
从表1可以看出,测试值和染色预测模型预测值的相对误差很小,相对误差绝对值最大为0.345%,最小为0.004%。
模型的拟合程度与超参数γ和σ有密不可分的关系,因此超参数寻优非常重要。表2是网格寻参法进行超参数寻优和用混沌算法寻优后对应的超参数,以及对训练集预测的平均绝对百分比误差eMAPE和均方根相对误差eMSE。由表2可以看出,两种寻参法得到的模型都具有较小的误差,其中网格寻参得到的超参数比混沌算法寻优得到的超参数误差小,但误差小并不代表对新样本的预测准确度更高。这是由于γ越大,模型的拟合误差越小,但过大会造成模型的过拟合,会使模型对新样本的预测有很大的误差;σ越小,模型的拟合误差也越小,但过小同样也会造成过拟合现象。因此,要用测试集对训练出的模型进行验证,从而检验模型的准确性。
2.2 染色预测模型性能验证
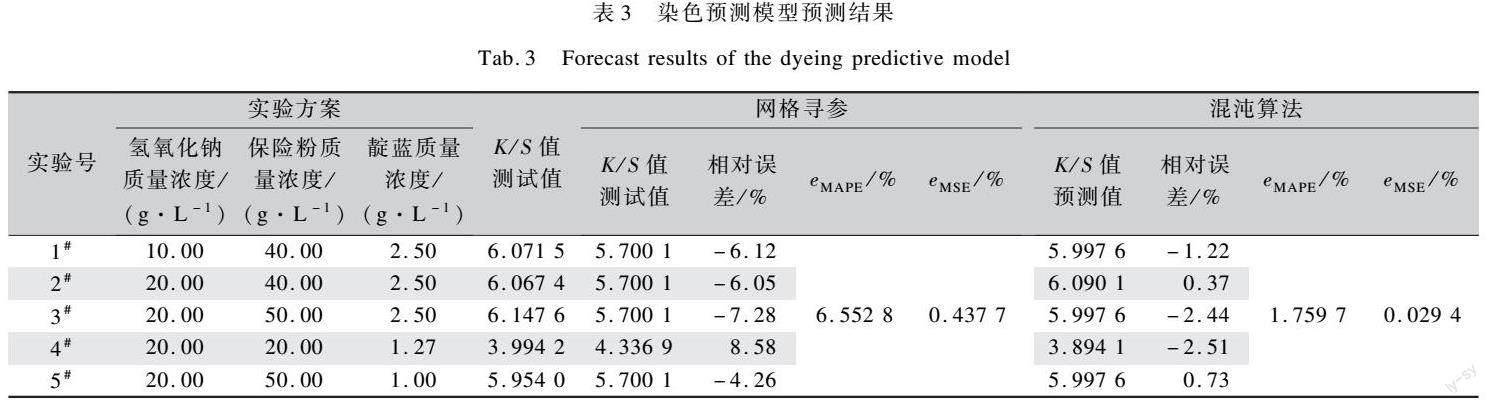
用测试集的5组染色数据代入已经训练好的染色预测模型进行预测,以验证模型预测的准确度,预测结果见表3。其中,计算出的预测值有14小数,在表3中只保留4位小数。
从表3可以看出,虽然混沌算法寻参在训练模型中表现的误差比网格寻参法略高,但对测试集的预测结果的误差明显小于网格寻参法,说明网格寻参法找到的超参数不是全局最优解,而混沌算法寻到的超参数更接近全局最优。
综上所述,混沌算法寻参LSSVM模型预测的eMAPE为1759 7%,eMSE为0.029 4%,預测误差较小,预测效果较好,表明了采用该模型预测靛蓝染色织物K/S值具有一定的可行性,对于降低靛蓝染色生产成本、提高工艺变换效率具有应用价值。
3 结 论
本文为提高靛蓝染色织物的实际色深与需求色深的匹配度,以Python语言为基础,利用Numpy、Random和Openpyxl模块,以靛蓝染料浓度、氢氧化钠浓度和保险粉浓度为输入变量,染色织物的K/S值为输出变量,运用混沌算法进行超参数寻优,用训练集的25组染色数据进行训练,建立了LSSVM靛蓝染色工艺条件预测模型,并用测试集的5组染色数据验证了模型的预测准确性。
1) 该模型对样本具有很高的拟合度,模型的eMAPE为0061 6%,eMSE为0.000 1%,说明通过混沌算法寻优得到的超参数能够有效减少模型的预测误差。
2) 通过混沌算法进行超参数寻优,使模型展现了良好的预测能力,对染色棉织物K/S值预测的eMAPE为1.759 7%,eMSE为0.029 4%,比网格寻参法更有优势。这表明该模型通过小样本的训练就可以达到较好的预测准确度,可用于靛蓝染色棉织物工艺条件的预测和优化。
3) 该模型尚存在一定的局限性,主要体现在为了减少运算量,输入变量的数量受到限制,后续将通过改进算法和模型,在不影响样本量和预测性能的前提下,增加模型的可输入变量,并将进一步扩展模型可预测的染色性能参数。
参考文献:
[1]马俊然, 胡敏干, 周岚, 等. 棉纤维靛蓝染料/液蜡体系染色工艺[J]. 染整技术, 2019, 41(10): 30-35.
MA Junran, HU Mingan, ZHOU Lan, et al. Dyeing process of cotton fiber in indligo dye/liquid paraffin system[J]. Textile Dyeing and Finishing Journal, 2019, 41(10): 30-35.
[2]李栋, 李鑫, 刘今强, 等. 棉纤维的靛蓝染料/D5体系染色[J]. 印染, 2016, 42(4): 9-13.
LI Dong, LI Xin, LIU Jinqiang, et al. Indigo dye/D5 system for cotton fiber dyeing[J]. China Dyeing & Finishing, 2016, 42(4): 9-13.
[3]HUANG J H, LIU H. A hybrid decomposition-boosting model for short-term multi-step solar radiation forecasting with NARX neural network[J]. Journal of Central South University, 2021, 28(2): 507-526.
[4]YU X, WANG H. Support vector machine classification model for color fastness to ironing of vat dyes[J]. Textile Research Journal. 2021, 91(15/16): 1889-1899.
[5]李明飞, 吴军超, 张一驰. 基于最小二乘支持向量机的组合模型在区域似大地水准面拟合中的应用[J]. 大地测量与地球动力学, 2022, 42(9): 971-974.
LI Mingfei, WU Junchao, ZHANG Yichi. Application of combined model based on LSSVM in regional quasi-geoid fitting[J]. Journal of Geodesy and Geodynamics, 2022, 42(9): 971-974.
[6]刘佳, 金福江. 基于LS-SVM的棉针织物染色上染率模型的研究[J]. 福州大学学报(自然科学版), 2010, 38(3): 446-449.
LIU Jia, JIN Fujiang. Study on the model of the uptake rate in dyeing of cotton fabric based on LS-SVM[J]. Journal of Fuzhou University (Natural Science Edition), 2010, 38(3): 446-449.
[7]陶开鑫, 俞成丙, 侯颀骜, 等. 基于最小二乘支持向量机的棉针织物活性染料湿蒸染色预测模型[J]. 纺织学报, 2019, 40(7): 169-173.
TAO Kaixin, YU Chengbing, HOU Qi’ao, et al. Wet-steaming dyeing prediction model of cotton knitted fabric with reactive dye based on least squares support vector machine[J]. Journal of Textile Research, 2019, 40(7): 169-173.
[8]周昆鹏, 白旭芳, 毕卫红. 荧光光谱法检测水质COD时温度、浊度、pH的影响分析[J]. 光谱学与光谱分析, 2019, 39(4): 107-112.
ZHOU Kunpeng, BAI Xufang, BI Weihong. The temperature, turbidity and pH impact analysis of water COD detected by fluorescence spectroscopy[J]. Spectroscopy and Spectral Analysis, 2019, 39(4): 1097-1102.
[9]黄光群, 段宏伟, 何金鸿, 等. 基于红外光声光谱的农作物秸秆导热系数定量分析[J]. 农业机械学报, 2018, 49(7): 342-347.
HUANG Guangqun, DUAN Hongwei, HE Jinhong, et al. Rapid quantitative analysis of crop straws’ thermal conductivity based on infrared photoacoustic spectroscopy[J]. Transactions of the Chinese Society for Agricultural Machinery, 2018, 49(7): 342-347.
[10]王磊, 刘雨, 刘志中, 等. 基于IABC-LSSVM的瓦斯涌出量预测模型研究[J]. 传感器与微系统, 2022, 41(2): 34-38.
WANG Lei, LIU Yu, LIU Zhizhong, et al. Research on prediction model for gas emission based on IABC-LSSVM[J]. Transducer and Microsystem Technologies, 2022, 41(2): 34-38.
[11]PAUK V, MICHALKOV J, JAGOOV K, et al. Origin of indigo colorants revealed by ion mobility spectrometry coupled to mass spectrometry followed by supervised classification[J]. Dyes and Pigments, 2022, 197: 109943.
[12]王建國, 张文兴. 支持向量机建模及其智能优化[M]. 北京: 清华大学出版社, 2015: 32-33.
WANG Jianguo, ZHANG Wenxing. Support Vector Machine Modeling and Intelligent Optimization[M]. Beijing: Tsinghua University Press, 2015: 32-33.
