一种新的半监督归纳迁移学习框架:Co-Transfer
2023-07-20文益民
文益民 员 喆 余 航
1 (桂林电子科技大学计算机与信息安全学院 广西 桂林 541004)
2 (广西图像图形与智能处理重点实验室(桂林电子科技大学)广西 桂林 541004)
3 (上海大学计算机工程与科学学院 上海 200444)
迁移学习已被广泛应用于将知识从源域迁移到相关的目标域的任务[1-2].根据Pan 等人[1]的工作,迁移学习可分为3 类:归纳迁移学习、直推式迁移学习和无监督迁移学习.有着与前面这3 种迁移学习不同的设置,一种名为“半监督迁移学习”的研究开始被学术界关注[3-6],它被用于解决许多实际应用问题,其学习范式一般是目标域中仅有少量样本被标记,而源域中的所有样本都被标记或者是源域中有一个预训练模型.但是,与这种“半监督迁移学习”不一样,在许多实际应用中,源域和目标域中包含标记和未标记样本的情形则非常常见.例如,在计算机辅助诊断(computer-aided diagnosis,CAD)系统[7]应用中,由于标注大量的医学图像非常耗时且成本昂贵,医学专家仅能够仔细诊断标注少量图像.由于设备的老化或升级,先前采集的医学图像很可能与当前采集的医学图像的分布不再相同[8-9].也就是说,在2 个不同时间间隔内采集的数据分布不相同.因此,接下来的挑战是如何从源域中的标记和未标记样本有效地学习,以实现对目标域中样本的更准确分类?
半监督多任务学习可用于处理上述问题.文献[10]通过Dirichlet 过程的变体在多个分类器参数上使用软共享先验来耦合几个参数化的半监督分类器.文献[11]在高斯过程的协方差中结合了数据的几何形状和任务之间的相似性.文献[12-14]使用深度学习提取多个半监督任务之间共享的特征表示.然而,文献[10-14]所述的这些方法都需要依赖特定类型的分类器.
为应对上述挑战,本文提出一种新的半监督归纳迁移学习框架,称为Co-Transfer,它将半监督学习[15-16]与归纳迁移学习相结合.Co-Transfer 首先生成3 个TrAdaBoost[17]分类器,用于将知识从原始源域迁移到原始目标域,同时生成另外3 个TrAdaBoost 分类器,用于将知识从原始目标域迁移到原始源域.这2 组分类器都使用从原始源域和原始目标域的原有标记样本的有放回抽样来训练.在Co-Transfer 的每一轮迭代中,每组TrAdaBoost 分类器使用新的训练集更新,其中一部分训练集是原有的标记样本,一部分是本组TrAdaBoost 分类器标记的样本,另一部分则由另一组TrAdaBoost 分类器标记.值得强调的是,本文使用Tri-training[18]方式来挑选可靠的伪标记样本.迭代终止后,将从原始源域迁移到原始目标域的3 个TrAdaBoost 分类器集成作为原始目标域的分类器.在4 个UCI 数据集[19]和文本分类数据集[17]上的实验结果表明,Co-Transfer 可以有效地学习标记和未标记样本提升泛化性能.
本文的主要贡献体现在2 点:
1)提出一种源域和目标域都只有部分样本被标记的半监督归纳迁移学习类型.这种学习类型在实际应用中其实很常见.
2)提出一种新的半监督归纳迁移学习框架Co-Transfer.该学习框架在源域和目标域之间进行双向同步的半监督学习和迁移学习,它能很好地适用于源域和目标域都仅有部分样本被标记的迁移学习且不需要特定类型的分类器.
1 相关工作
本节简要回顾半监督学习、基于实例的迁移学习、半监督迁移学习以及半监督多任务学习等相关工作.
1.1 半监督学习
半监督学习[15]的主要思想是学习少量标记样本和大量未标记样本以提高模型泛化能力.半监督学习假设未标记样本与标记样本具有相同分布.已有的半监督学习方法主要分为四大类:生成式模型[20]、包装方法[18,21]、低密度分离模型[22]以及基于图的方法[23]等.其中,包装方法是一类简单且受欢迎的方法,它首先在原有标记样本上训练分类器,然后利用训练好的分类器来预测未标记样本的类别,使用置信的伪标记样本与原有标记样本一起重新训练分类器.
Blum 等人[24]提出了Co-training 算法,它需要数据有2 个充分且冗余的视图.Co-training 分别在2 个不同的视图上训练2 个分类器,并且使用每个分类器置信的伪标记样本来增强另一个分类器.Dasgupta等人[25]证明了当数据具有2 个充分且冗余的视图时,Co-training 训练的分类器可以通过最大化不同组件分类器对未标记样本的一致性来降低分类错误率.在实际应用场景中,由于数据很难满足这一要求,Zhou 等人[18]提出Tri-training 算法,该算法不再要求训练数据有2 个充分且冗余的视图.Tri-training 采用“多数教少数”的方法来避免对分类置信度的估计.Li 等人[21]提出Co-forest 算法将Tri-training 扩展到可使用更多的组件分类器.在Tri-training 和Co-forest 中,使用模糊集理论来确保新的伪标记样本能起到积极效果.Van Engelen 等人[15]综述了一些其他包装方法,如Self-training 与Boosting 系列.此外,Triguero 等人[26]提供了一个关于半监督分类中自标记技术的全面综述.
1.2 基于实例的迁移学习
基于实例的迁移学习方法其直观思想是将源域中部分样本与目标域样本一起训练得到一个更高准确率的分类器.
Dai 等人[17]通过扩展AdaBoost 提出TrAdaBoost迁移学习算法.TrAdaBoost 迭代地重新加权源域和目标域样本以减少“坏”的源域样本的权值,同时增大“好”的目标域样本的权值.此外,Dai 等人[17]还从理论上分析了TrAdaBoost 的可收敛性.Kamishima 等人[27]通过扩展bagging 提出TrBagg 方法.TrBagg 训练过程包括2 个阶段:学习和过滤.在学习阶段,使用源域和目标域的抽样样本来训练弱分类器;在过滤阶段,使用目标域样本来评估这些弱分类器.分类精度低的弱分类器会被丢弃,而分类精度高的弱分类器会被选择来产生最终分类器.Shi 等人[28]通过扩展Cotraining 算法提出COITL 算法.COITL 算法的关键思想是通过将Co-training 算法中给样本打伪标记的操作替换为对源域样本进行加权来扩充训练样本集.在算法COITL 中,首先使用目标域样本训练2 个组件分类器,然后每个分类器使用另一个分类器加权的源域样本进行增强.
1.3 半监督迁移学习
目前半监督迁移学习的工作还非常有限,与本文要解决的问题不同,已有的半监督迁移学习旨在解决源域是监督设置但目标域是半监督设置的问题.根据源域形式的不同,主要分为2 类:源域样本直接可用或源域样本不可用但源域上的预训练模型可用.
Liu 等人[3]提出一种基于Tri-training 的半监督迁移学习方法TriTransfer.在TriTransfer 中,使用从源域抽样的样本与目标域的标记样本一起训练3 个组件分类器,然后使用“多数教少数”的策略来重新训练这3 个组件分类器,最后加权集成这3 个组件分类器来产生最终分类器.
Tang 等人[4]提出一种半监督迁移方法以解决汉字识别问题.首先,使用大量源域样本来训练卷积神经网络;然后使用目标域中少量的标记样本对卷积神经网络模型微调;最后使用目标域中大量的未标记样本和少量的标记样本对微调后的卷积神经网络继续训练以最小化多核最大均值差异(multiple kernel maximum mean discrepancy,MK-MMD)损失.
Abuduweili 等人[5]提出一种半监督迁移学习算法,它可以有效地利用源域的预训练模型以及目标域中的标记和未标记样本.在所提出的算法中利用自适应一致性正则化方法来将预训练模型与目标域的标记和未标记样本结合在一起训练.自适应一致性正则化包括2 个含义:源模型和目标模型之间的自适应一致性;有标记和无标记样本之间的自适应一致性.
Wei 等人[6]提出一种用于图像去雨的半监督迁移网络.该网络经过合成的带雨图像样本训练后可以迁移于真实且不同类型的带雨图像,解决了目标域缺少训练样本及真实图像与合成图像间分布差异的问题.
1.4 半监督多任务学习
半监督多任务学习旨在有效挖掘任务之间的相关性并探索每个任务中未标记样本的有用信息.Liu等人[10]基于Dirichlet 过程的变体使用任务聚簇方法对不同任务进行聚类,且在每个任务中,使用随机游走过程来探索未标记样本中的有用知识.Skolidis 等人[11]使用共区域化的内在模型在高斯过程的框架下编码任务之间的相关性.此外,半监督多任务学习与深度学习被结合用于解决实际任务,如疾病演化[12]、药物间相互作用[13]、语义解析[14]和文本挖掘等[29].
2 Co-Transfer
在本文中,为了形式化定义所提出的半监督迁移学习框架,我们引入一些符号.
本文假设源域DS和目标域DT具有相同的特征空间但分布不同.X表示特征空间,Y∈{0,1}表示类别空间.DS和DT均包含标记和未标记样本.定义DSL=和DTL=分别表示源域和目标域中的标记样本,其中∈X是源域中的一个实例,∈Y是对应的类别标记,而∈X则是目标域中的一个实例,∈Y是对应{的类别标记.定义DSU=和DTU=,分别表示源域和目标域中的未标记样本.此外,还存在测试数据集DTest=可用,它与目标域分布相同.通常,未标记样本的数量要远大于标记样本的数量,设置m≫l和n≫p.所提出的半监督归纳迁移学习的目标是利用L=[DSL,DTL]和U=[DSU,DTU]在目标域上学习一个函数f:X→Y,使得f能正确预测DTest中样本的类别标记.为简洁起见,本文使用L[0]和L[1]分别表示DSL和DTL,使用U[0]和U[1]分别表示DSU和DTU.
在Co-Transfer 中,需训练2 个集成分类器H0=和H1=.初始时,H0中的每个组件分类器使用目标域与源域的原有标记样本的有放回抽样来训练,采用TrAdaBoost 算法实现从目标域到源域的迁移学习.相对应地,H1中的每个组件分类器也使用源域与目标域的原有标记样本的有放回抽样来训练,采用TrAdaBoost 算法实现从源域到目标域的迁移学习.抽样策略能保持H0和H1各自的组件分类器之间的多样性.像这样的源域和目标域之间的双向同步迁移学习会迭代很多轮,在每一轮中使用各自新增的伪标记样本分别对H0和H1中每个组件分类器进行更新.由于Co-Transfer 在源域和目标域之间实施双向同步迁移学习,本文将原本的源域和目标域分别称为原始源域和原始目标域.在从原始源域到原始目标域的迁移学习中,原始源域仍然是源域,原始目标域仍然是目标域;而在从原始目标域到原始源域的迁移学习中,原始目标域被当成源域,原始源域则被当成目标域.
算法1.Co-Transfer 算法.
更详细地,在Co-Transfer 的每一轮双向同步迁移学习中,将集成分类器Hd(d∈{0,1},d=0对应原始源域,而d=1对应原始目标域)的组件分类器(i∈{1,2,3})作为初始分类器,使用Tri-training 方式从U[d]中选择样本打上标记.具体做法是:若其他2 个组件分类器(j≠k≠i)对未标记样本给出的类别标记相同,则该未标记样本才会被标记,将该伪标记样本添加到数据集(i∈{1,2,3}).另外,若集成分类器Hd(d∈{0,1})中的3 个组件分类器对未标记样本都给出了相同标记,则该未标记样本会被选中作为伪标记样本而添加到数据集Ld.然后,将Ld与原始标记样本L[d]合并作为新的源域数据,再将(i∈{1,2,3})分别与L[(d+1)%2]合并作为新的目标域数据.最后,利用TrAdaBoost 算法进行训练,以实现从源域到目标域的迁移学习,而得到由新的组件分类器(i∈{1,2,3})构成的集成分类器H(d+1)%2.值得注意的是:由Hd和Hid选择的所有未标记样本都不会从U[d]中删除.因此,它们可能会在接下来的迭代中被再次选中.d=0和d=1所对应的2 个迁移学习过程被同步执行.当Hd(d∈{0,1})中的每个组件分类器都不再被重新训练时,迭代结束,将最终得到的H1作为原始目标域上的分类器.
第1 种情况是如何选择U[d]中未标记样本作为目标域样本以重新训练(i∈{1,2,3}).令和表示在第t轮和第t-1 轮迭代中使用Tri-training 方式从U[d]中选择可打标记的样本,大小分别为和和分别表示在第t轮和第t-1 轮迭代中的分类错误率的上界.因此,根据Zhou等人[18]提出的理论,需满足约束:
第2 种情况是如何选择U[(d+1)%2]中未标记的样本作为源域样本以重新训练(i∈{1,2,3}).令Ld,t和Ld,t-1分别表示在第t轮和第t-1轮迭代中从U[d]中选择可打标记的样本,其大小分别为和ed,t和ed,t-1分别表示Hd在第t轮迭代和第t-1 轮迭代中的分类错误率的上界.因此,同样根据Zhou 等人[18]提出的理论,需满足约束:
第2 种情况引入的约束使得标记更可靠的伪标记样本加入源域,使源域数据分布更接近真实数据分布,进而导致更可靠的伪标记样本添加到目标域中,这对于Co-Transfer 中的迭代过程非常重要.
采用决策树作为组件分类器的Co-Transfer 算法伪代码在算法1 中给出,其中参数N为TrAdaBoost的迭代次数.行⑤~⑦表示分别从L[(d+1)%2]和L[d]通过函数Bootstrap抽样而得到和.将和分别作为源域和目标域数据,用TrAdaBoost学习得到初始的集成分类器.在行⑮中,函数MeasureEnsemble-Error用于估计集成分类器Hd的分类错误率.在行⑱中,函数MeasureClassifierError则用于估计=的分类错误率.这2 个错误率都是在原有标记数据集L[d]上估计的.详细来说,估算Hd的错误率是通过将Hd的3 个组件分类器(i∈{1,2,3})预测一致但分错的标记样本数与预测一致的标记样本数之比来近似得到.类似地,的错误率是通过将预测一致但被分错的标记样本数与预测一致的标记样本数之比来近似估算.在行⑳中,函数PseudoLabel是从U[d]中选择和给出相同标记的样本打上伪标记.在行㉜中,函数S creenPseudoLabel是从中选择出伪标记相同的样本.函数S ubsample(S,t)从S中随机删除t个样本.行使用新的源域数据和目标域数据来重新训练Hd的每个组件分类器.图1 中的数据流图描述了Co-Transfer 的训练过程.

Fig.1 Data flow diagram of Co-Transfer training process图1 Co-Transfer 训练过程的数据流图
3 实 验
3.1 数据集
本文使用迁移学习研究[17,28]中常用的4 个UCI数据集和文本分类数据集Reuters 进行实验.这些数据集都已被证明原始源域能有效地助力原始目标域的学习.表1 罗列了这些数据集的详细信息.
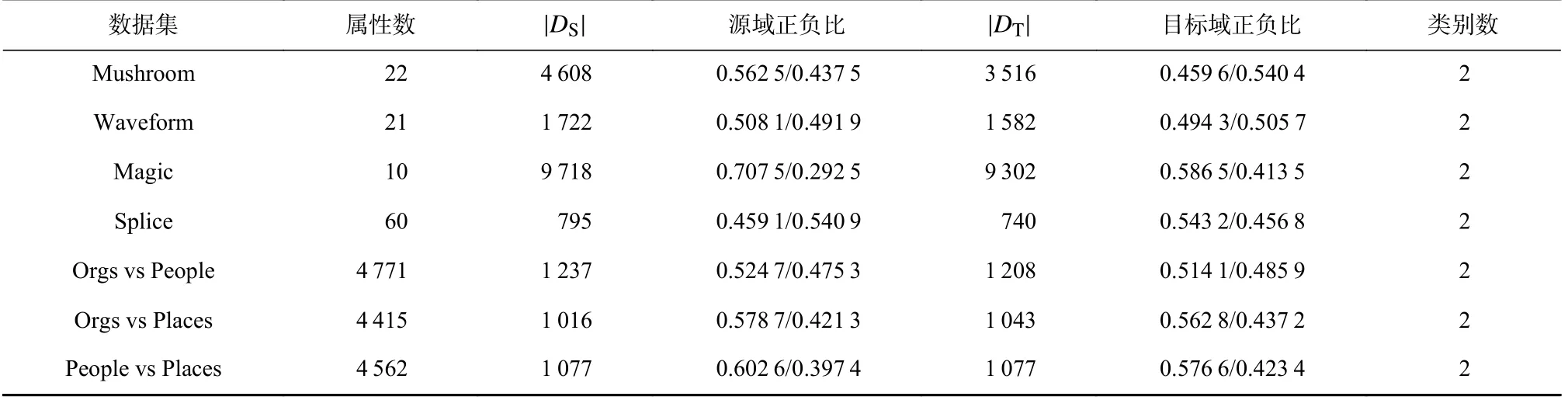
Table 1 Experimental Data Sets表1 实验数据集
3.2 实验设置
对于表1 中每个数据集的目标域数据使用5 折交叉验证进行分类错误率评价.在每折交叉验证中,将目标域中的样本划分为目标域训练数据集DT和测试数据集DTest,而将源域中的全部样本当作训练数据集DS.再根据预设的有标记样本比,随机从源域训练数据集DS和目标域训练数据集DT中挑选样本构成标记样本集DSL和DTL,剩余的样本构成未标记样本集DSU和DTU.为增加样本标记的随机性,在每折交叉验证中,重复2 次对源域训练数据集DS随机划分为DSL和DSU,重复3 次对目标域训练数据集DT随机划分为DTL和DTU.因此,最终的错误率是30(5× 6)次测试结果的平均值.
为评测与分析Co-Transfer 是否可以有效学习源域和目标域中的标记样本与未标记样本,引入7 个算法进行对比,包括决策树(decision tree, DT)、TrAda-Boost、Tri-training、TrAdaBoostA、Co-TransferS、TrAda-BoostS、Co-TransferT.
对于应用型本科院校而言,教师专业化就是指根据社会对应用型人才的需求,教师遵循应用型特征的教育教学规律,特别注重专业实践能力。教师专业化发展强调教师的终身学习和终身成长,包括职前培养、新任教师培养和在职培训,在教师的整个专业生涯中,通过学习和专业训练,提高专业素养、专业实践能力和个人职业道德等,促进教师从新手到熟手,从熟手到专家。
算法DT 表示仅在DTL上训练决策树对测试数据进行分类;算法TrAdaBoost 表示在DSL和DTL上使用TrAdaBoost 方法训练分类器对测试数据进行分类;算法Tri-training 表示在DTL和DTU上使用Tri-training方法训练分类器对测试数据进行分类;算法TrAdaBoostA表示在将DS和DT中的全部样本打上标记再使用TrAdaBoost 方法训练分类器对测试数据进行分类;算法Co-TransferS表示采用Co-Transfer 的框架进行学习,但在迭代过程中目标域的样本只使用DTL,也就是说在双向迭代过程中不会在DTL的基础上再增加伪标记样本;算法TrAdaBoostS表示将DS中的全部样本打上标记和DTL使用TrAdaBoost 方法训练分类器对测试数据进行分类;算法Co-TransferT则表示采用Co-Transfer 的框架进行学习,但在迭代过程中源域样本只使用DSL,也就是说在双向迭代过程中不会在DSL的基础上再增加伪标记样本.表2 列出了Co-Transfer 和各对比算法的样本使用策略.

Table 2 Data Strategy Used by the Algorithms表2 各算法的数据使用策略
由表2 可知:当原始源域到原始目标域能实现正迁移时,DT 的分类错误率应该最高,TrAdaBoostA的分类错误率则应该最低.与Co-Transfer 相比较,Co-TransferS不使用DTU,而 Co-TransferT不使用DSU.TrAdaBoost 则既不使用DSU,也不使用DTU.因此,将Co-Transfer 分别与 TrAdaBoost,Co-TransferS,Co-TransferT相比较,可观察Co-Transfer 是否可以有效地从原始源域和原始目标域的未标记样本中学习.与TrAdaBoost 相比,TrAdaBoostS多用了DSU,因此,将TrAdaBoostS与TrAdaBoost 对比可知利用DSU能否辅助原始目标域学习得更好.
本文使用标准t 统计检验检查Co-Transfer 和每个对比算法的泛化能力的区别是否具有95%置信度的显著性.
各算法的参数设置:对于Tri-training,使用C4.5决策树作为组件分类器并且不做剪枝处理;而对于TrAdaBoost,TrAdaBoostA,Co-TransferS,TrAdaBoostS,Co-TransferT,Co-Transfer,使用相同的参数,即对于数据集Mushroom 设置迭代次数N=10,树的深度D=10;对于数据集Waveform 设置N=65,D=4;对于数据集Magic 设置N=35,D=20;对于数据集Splice 设置N=15,D=50;对于数据集Orgs vs People 设置N=50,D=5;对于数据集Orgs vs Places 设置N=20,D=4;对于数据集People vs Places 设置N=50,D=3.
3.3 实验结果和分析
表3~6 显示,当原始源域和原始目标域的标记比率相同时,不同标记比率下Co-Transfer 和所有对比算法在原始目标域测试集上的分类错误率.从表3~6可以观察到:在各种标记比率条件下,DT 的分类错误率最高.当标记比率为10%和20%时,TrAdaBoostA显然要比Co-Transfer 的泛化能力强;而当标记比率为40%和50%时,TrAdaBoostA与Co-Transfer 的泛化能力则变得相当;在各种标记比率条件下,Co-Transfer 的泛化能力比TrAdaBoost,Tri-training,Co-TransferS的泛化能力都要好,这说明Co-Transfer 能有效利用源域的标记样本和目标域的未标记样本.
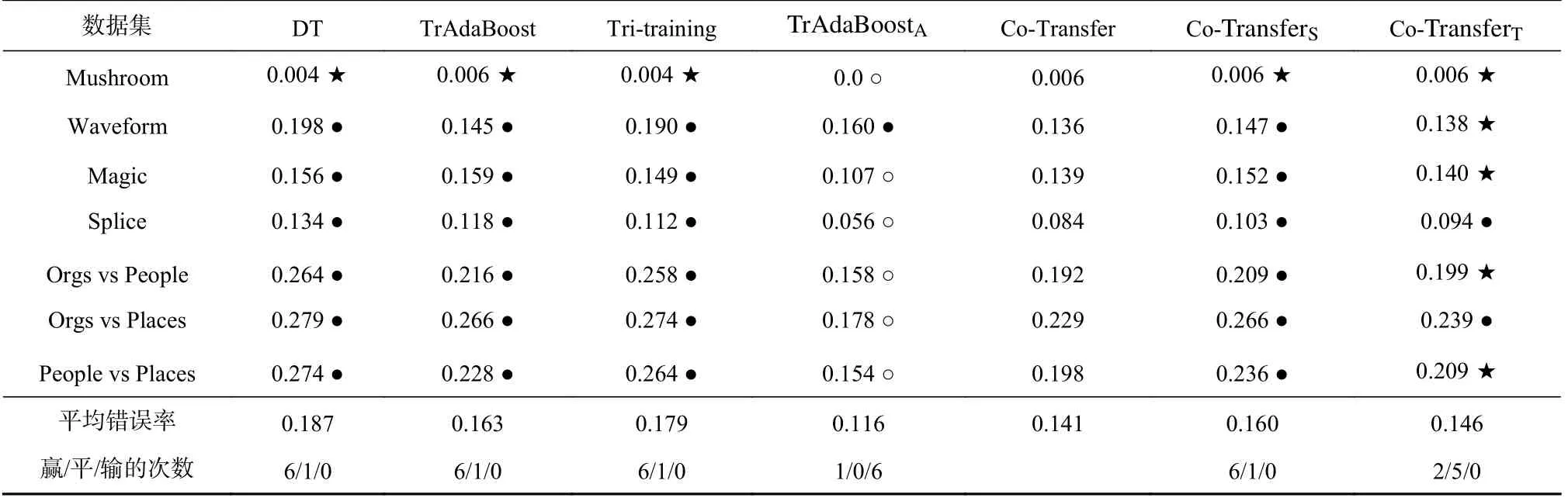
Table 3 Error Rates of the Comparative Algorithms Under the Label Rate 10% of Original Source Domain and Target Domain表3 在原始源域与原始目标域标记比率均为10%下所对比算法的错误率
从表3~6 还可以观察到:Co-Transfer 的泛化能力不比Co-TransferT弱.为分析Co-Transfer 能否有效利用原始源域的未标记样本DSU,我们将TrAdaBoostS与TrAdaBoost 进行了比较,结果如表7 所示.从表7 中可以观察到:1)标记比率超过20%后,提升标记比率不太可能会带来TrAdaBoostS的泛化能力的显著提升;2)在各种标记比率下,对于数据集Mushroom,Waveform,Magic,TrAdaBoostS与TrAdaBoost 在原始目标域上的泛化能力没有显著区别;3)对于数据集Splice,Orgs vs People,Orgs vs Places,People vs Places,增加源域的标记样本数量可能得到正向迁移的效果.再结合表3~6 可知:Co-Transfer 能否有效利用原始源域的未标记样本应该与数据集的自身特性相关.
为更深入观察Co-Transfer 的学习过程,我们平均不同标记比率下各种对比算法在文本分类数据集上每轮迭代的分类错误率.图2 描述了各算法从初始迭代到最终迭代的平均错误率的变化.需要解释的是:1)在与Co-Transfer 对比的算法中,仅有Tritraining,Co-TransferS,Co-TransferT使用了无标记样本,其他算法都只使用标记样本;2)当一个算法提前终止了,我们保持其错误率补齐了数据.从图2 中可以观察到:1)不使用无标记样本的算法无迭代过程,仅有最终分类错误率,DT 错误率最高,其次是TrAdaBoost 和TrAdaBoostS,最后是TrAdaBoostA;2)初始迭代时,Co-Transfer,Co-TransferS,Co-TransferT的平均分类错误率几乎相同但略微低于Tri-training,随着迭代不断进行,Co-Transfer 的平均分类错误率不断降低,并快速收敛.
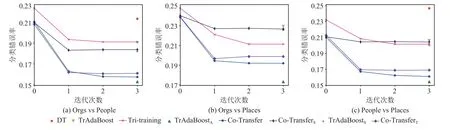
Fig.2 Error rates of the comparative algorithms during their iteration on the text classification tasks图2 文本分类任务上各对比算法在迭代过程中的错误率
此外,还观察了原始源域的标记比率要高于原始目标域的标记比率这一情况.表8 和表9 显示原始源域标记比率为50%,而原始目标域的标记比率分别为10%和20%时,Co-Transfer 与各对比算法的分类错误率.可以观察到:DT 的分类错误率最高;TrAdaBoostA显然要比Co-Transfer 的泛化能力强;在各种标记比率条件下,Co-Transfer 的泛化能力比TrAda Boost,Tri-training,Co-TransferS的泛化能力都要好.这说明:在原始源域的标记比率比原始目标域的标记比率高时,Co-Transfer 还能有效地利用原始源域的标记样本和原始目标域的未标记样本.

Table 8 Error Rates of the Comparative Algorithms Under the Label Rate 50% of the Original Source Domain and 10% of the Original Target Domain表8 在原始源域标记比率为50%、原始目标域标记比率为10%下所有对比算法的错误率
从表8 和表9 中还可观察到:Co-Transfer 的泛化能力不比Co-TransferT弱.为分析Co-Transfer 能否有效利用原始源域的未标记样本DSU,同样将TrAdaBoostS与TrAdaBoost 进行比较,结果如表10 所示.可以观察到:当原始源域标记比率较高时,增加原始源域标记样本的数量很可能不带来原始目标域分类错误率的显著下降.因此,表8~10 中暂不能解释Co-Transfer的泛化能力不比Co-TransferT弱.
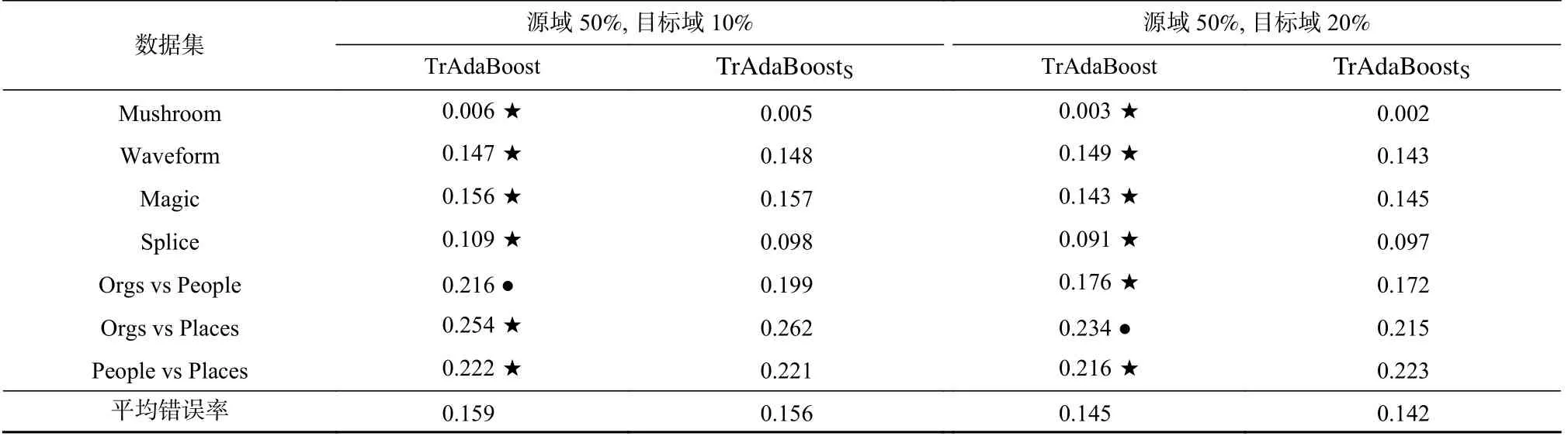
Table 10 Error Rates of TrAdaBoost and TrAdaBoostS Under the Label Rate 50% of the Original Source Domain and 10% and 20% of the Original Target Domain, Respectively表10 在原始源域标记比率为50%、原始目标域标记比率分别为10%和20%下TrAdaBoost 与TrAdaBoostS 的错误率
综合表3~10 中实验结果,可以进一步推测:原始源域和原始目标域的标记比率的同步提升对于Co-Transfer 的学习过程的影响比较复杂.这是因为:仅增加源域标记样本数量并不一定总能提升迁移学习的效果;目标域标记样本数量的增加会掩盖源域标记样本带来的正向迁移.因此,在Co-Transfer 的学习过程中,源域和目标域很可能存在一个博弈过程.
当Co-Transfer 的分类器采用决策树时,考虑到决策树的深度D和TrAdaBoost 的迭代次数N可能会影响Co-Transfer 的泛化能力.因此,在文本分类数据集上进一步研究了树的深度D和迭代次数N对Co-Transfer 泛化能力的影响.图3 描述了将不同的标记比率条件下的分类错误率平均后Co-Transfer 的变化曲线.从中可以观察到:在文本分类数据集上,参数N和D对Co-Transfer 算法分类错误率有较大影响.当固定D时,随着N的增大Co-Transfer 的分类错误率越来越低;然而当N较小时,Co-Transfer 的分类错误率随参数D的变化较大;随着N的增加,Co-Transfer的分类错误率对参数D的敏感性变小.
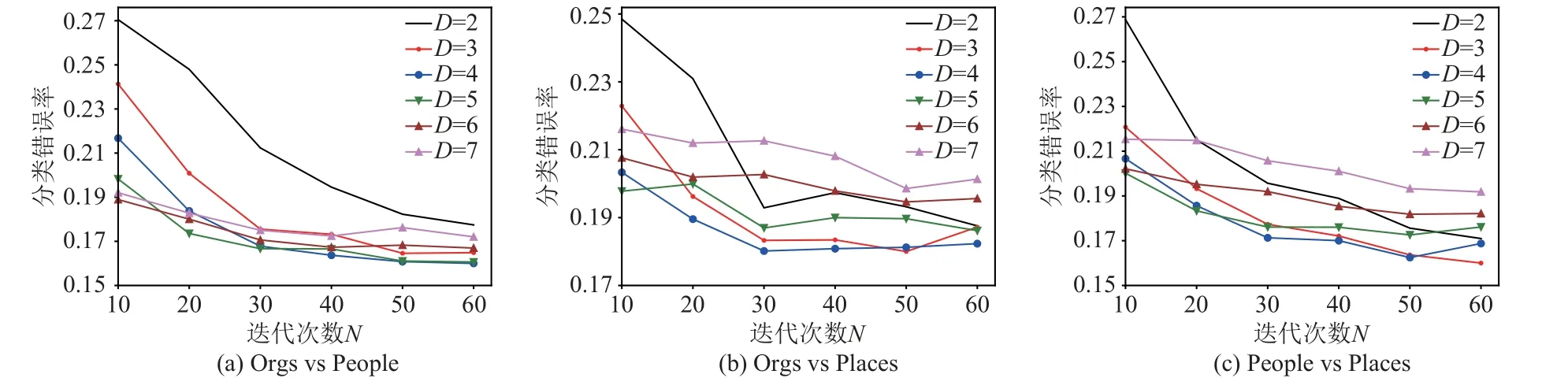
Fig.3 Error rates of Co-Transfer with different N and D图3 不同N 和D 条件下Co-Transfer 的错误率
4 结 论
本文提出了一种半监督归纳迁移学习框架——Co-Transfer.在4 个UCI 和文本分类任务数据集上与7 个算法的对比实验表明:Co-Transfer 的这种双向同步迁移的机制可以有效地学习源域和目标域的标记和未标记样本来提升泛化性能.我们未来的工作包括:使用多种类型的组件分类器来评测Co-Transfer的分类性能,如神经网络、朴素贝叶斯等;源域和目标域之间的双向可迁移性对Co-Transfer 的影响.此外,还应该使用更多的数据集,尤其是实际应用中的数据集来评测Co-Transfer 的泛化能力.本文伪代码可以从 https://gitee.com/ymw12345/co-transfer.git 下载.
作者贡献声明:文益民负责算法研讨、算法设计及论文修改;员喆负责算法设计、论文初稿撰写及论文修改;余航参与算法研讨、论文修改.
