面向无人驾驶系统的仿真模糊测试:现状、挑战与展望
2023-07-20戴嘉润李忠睿张琬琪
戴嘉润 李忠睿 张琬琪 张 源 杨 珉
(复旦大学计算机科学技术学院 上海 200438)
无人驾驶系统(autonomous driving system, ADS)可通过各类的车载传感器(如相机、激光雷达、超声波雷达等)进行实时的驾驶环境感知,并进一步根据目标驾驶任务进行驾驶行为的规划与决策,以此控制车辆的自动化行进.作为交通领域中的颠覆性智能技术,无人驾驶已展示出广泛的应用场景,如物流配送、军事探勘、公共交通等.鉴于此,众多科技公司、整车厂商与政府部门正积极推动无人驾驶的技术落地,期望实现公开道路的无人驾驶车辆部署.
然而现如今,安全性作为无人驾驶系统重要的预期属性,已然成为了其大规模落地的瓶颈.在无人驾驶车辆的试运行过程中,因无人驾驶系统缺陷导致的交通事故不断发生,造成了严重程度不一的财产损失与人身伤害.例如,截止2023 年1 月6 日,美国加州交管局[1](Department of Motor Vehicles, DMV)已接收并公布了546 件无人驾驶车辆相关的交通事故[2].同时,建立无人驾驶功能安全相关的测评标准已成为国内外标准化组织的重点工作.例如,国际标准化组织发布了ISO 21448[3]以规范无人驾驶的安全测试流程,作为跟进,我国的国家标准计划《道路车辆预期功能安全》[4]也在积极筹备之中.
为有效提高无人驾驶的安全性并满足合规检测需求,各大厂商与监管机构正积极采用2 类测试方案,即道路测试[5-6]和仿真测试[7–10],来挖掘并整治无人驾驶系统中可能导致交通事故的系统缺陷.道路测试指在封闭的真实道路上长久地运行无人驾驶车辆,并监控其驾驶行为.然而,道路测试存在着较大的限制:一方面,布置各种封闭道路场景的成本较高,且测试周期较长;另一方面,道路测试难以验证无人驾驶系统在极端驾驶场景(如极端天气与路况)中的可靠性.与道路测试不同的是,仿真测试指在仿真器中配置虚拟的驾驶场景来验证无人驾驶系统的安全性.相较于传统的道路测试,因仿真测试可任意指定虚拟场景的配置(如天气环境、地图道路和交通车流等),能以更低的成本灵活地验证在真实道路上难以挖掘到的危险驾驶场景.鉴于该优势,仿真测试已被学术界和产业界广泛使用来评估无人驾驶系统的安全性.
显然,仿真测试的有效性直接由虚拟场景配置的质量决定,即安全测试人员能否设计出易导致无人驾驶安全事故的虚拟场景.然而,设计事故场景绝非易事.其原因在于,虚拟场景中包含着种类丰富的待配置要素,包括天气环境、道路地图和交通车流等,这些要素的排列组合将构成难以估量的场景搜索空间.直观地说,从这样庞大的搜索空间中有效挖掘事故场景配置无异于大海捞针.截止当前,这仍然是困扰学术界[11–13]和工业界[14]的棘手难题.
为有效应对该难题,前沿的研究工作[15–20]尝试将模糊测试技术[21-22]与仿真测试相结合,构建出面向无人驾驶系统的仿真模糊测试技术(simulation-based fuzzing).该技术的基本原理是:给定数量有限的初始场景配置(称之为种子场景),通过类模糊测试的变异操作来自动调整种子场景中的可配置要素(如将天气参数由晴天变更为雨天),以此源源不断地生成新的更易导致事故的场景配置.基于此原理,仿真模糊测试技术即可自动化地探索庞大的场景搜索空间,并从中挖掘出易导致无人车事故的驾驶场景.例如,AV-FUZZER[16]提出了与遗传算法相结合的模糊测试方案,通过改变无人车周围车辆的变道行为和驾驶速度,寻找直道上因车距过近而导致的无人车事故场景;AutoFuzz[18]利用神经网络来指导仿真模糊测试,其首先将场景配置向量化,并通过梯度下降算法变异各类场景要素,以此生成导致无人车碰撞的驾驶场景.
尽管已有的仿真模糊测试工作已经在高级别无人驾驶系统(high-level autonomous driving system)的安全测评中展示出了良好的应用成效,即发现了数十乃至数百例主流开源无人驾驶系统Apollo 和Autoware的事故场景,它们仍然存在数个缺陷与不足,直接制约了它们提升无人驾驶系统安全性的能力.例如,现有的仿真模糊测试工作在准备种子场景时,普遍采用手工的方式构建极其简易的驾驶场景,该类质量低下的种子极大地限制了现有工具的事故挖掘能力.又如,现有的仿真模式测试工作的事故分类机制缺乏完善的设计,大量冗余重复的事故为进一步的系统缺陷归因溯源造成巨大阻碍.
鉴于此,本文旨在系统性地总结现有工作的不足,指明完善这些不足之处的技术方向,并最终给出可行的解决方案,以此为该领域的后续工作提供可靠的指导建议.
本文的主要贡献包括3 个方面:
1)调研了面向无人驾驶系统的仿真模糊测试技术,并总结了该类技术的一般架构,该架构分为种子场景生成、事故挖掘、事故分类与事故根源分析四大关键模块.
2)面向这4 个关键模块,剖析了现有工作的不足,以及解决这些不足所面临的技术挑战.
3)针对现有工作的不足提出了可行的优化方案,并在主流无人驾驶系统上进行了可行性的实验论证,以此指明该领域的未来发展方向.
1 背景知识
1.1 无人驾驶系统
为了区分不同自动驾驶系统的能力,国际汽车工程学会(Society of Automotive Engineers, SAE)将无人驾驶系统分为6 个等级[23],从L0(无自动驾驶)到L5(完全自动驾驶).其中,L4 与L5 的无人驾驶系统又称高级别无人驾驶系统.因高级别无人驾驶系统在多样的驾驶场景中都具备自主运行能力,许多制造商正致力于该类系统的开发部署与安全测试.具体地说,高级别无人驾驶系统通常是由多个功能模块组成,这些模块协同工作,以实现实时的自动驾驶.如图1 所示,高级别无人驾驶系统主要包含4 个关键模块:
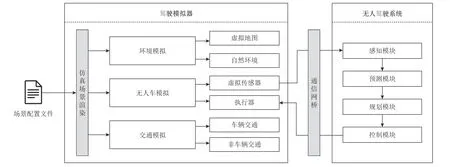
Fig.1 Architecture of simulation testing for autonomous driving systems图1 无人驾驶系统仿真测试架构
1)感知(Perception)模块.通过接收来自摄像头、激光雷达和超声波雷达等车载传感器的数据,基于机器学习算法探知车身周围障碍物的位置和类型.
2)预测(Prediction)模块.基于上述障碍物探知信息,运用机器学习算法进一步预测周边障碍物的未来运动轨迹.
3)规划(Planning)模块.结合目标驾驶任务与驾驶环境的感知预测结果,为无人驾驶车辆规划出可达目的地的安全行驶轨迹.
4)控制(Control)模块.基于规划的轨迹和车辆的当前状态,使用不同的控制算法生成一系列车身控制命令,如加速、刹车和转向等.
这4 类功能模块通常以异步的形式高频运作,并在运行时依赖高性能中间件框架(如Cyber-RT[24]和ROS[25])进行模块间的通信.此外,该框架还负责无人驾驶系统和车载硬件之间的信息交互.
1.2 无人驾驶系统仿真测试
为了提高无人驾驶系统的安全性,许多研究工作着眼于测试单个系统模块(如感知模块[26–31])的鲁棒性,即假设攻击者或罕见的驾驶情况可能导致单个系统模块的故障.例如,攻击者伪造的传感器数据可能会导致错误的障碍物感知结果.然而,因无法从宏观的层面对无人驾驶系统整体进行测试[32],该类工作往往无法发现由多个模块共同导致的系统故障.
与上述工作不同的是,无人驾驶系统仿真测试是面向无人驾驶系统整体而非单点模块的测试方法.在虚拟的仿真环境下,安全分析人员可灵活指定场景的各类要素,并通过待测无人驾驶系统的实时计算来控制仿真无人车在该场景下的运动.图1 描述了无人驾驶系统仿真平台的整体框架.其中,驾驶模拟器通常建立在图形渲染引擎(如Unity[33]和Unreal[34])上,包含3 个用于仿真测试的重要组件:
1)无人车模拟组件.该组件主要负责模拟目标无人车在虚拟场景中的驾驶行为.仿真环境中的无人车配置了各种虚拟传感器,这些虚拟传感器可以产生与仿真环境对应的传感器数据(如摄像头数据、激光雷达数据和GPS 数据).随后,驾驶模拟器会通过通信网桥将这些数据作为输入连续地传输给无人驾驶系统.同样,经过无人驾驶系统计算后生成的车辆控制指令(如油门和转向)也会通过通信网桥实时地发送给驾驶模拟器,进而控制无人车在仿真环境中的运动.
2)环境模拟组件.该组件允许配置多样的驾驶环境,主要包括环境的物理属性和静态的地图元素.这些配置决定了仿真环境的渲染,同时也是虚拟无人车传感器生成实时传感器数据的重要根据.
3)交通模拟组件.该组件旨在模拟无人车周围具有特定动态行为的交通参与者.根据交通行为者的类型,交通模拟可以分为车辆交通模拟(如汽车和公共汽车)和非车辆交通模拟(如自行车和行人).
1.3 仿真场景配置
驾驶模拟器具有3 个重要组件,即无人车模拟组件、环境模拟组件和交通模拟组件.在实际的仿真测试过程中,测试人员须正确配置这3 个组件的必要参数以保证仿真测试的正常开展:
1)环境模拟参数.该参数主要用于定制化场景的自然物理属性和地图元素.最常见的自然物理属性包括天气情况与光照情况.地图元素通常指的是具有特定结构和地理坐标的道路网络,其中包含必要的道路基础设施如交通标志牌与交通信号灯等.
2)无人车模拟参数.该参数主要指定待测无人车的物理学模型与动力学模型.此外,该参数还须指定无人车驾驶的起点、目的地以及初始速度.
3)交通模拟参数.该参数需指定各交通参与方的动态行为.常见的方式是令车辆与行人等沿着给定的轨迹坐标点运动.
为保证这3 个参数配置的可移植性,现有工作普遍采用不同的领域特定语言(domain-specific language,DSL)实例化参数配置.例如,GeoScenario[35]和Open-SCENARIO[36]利用面向对象的语言来描述仿真场景的各项参数.此外,这些DSL 通常会结合其他标准(如OpenDRIVE[37],OSM[38]和Lanelets[39])来描述道路地图.最终,这些格式良好的场景参数配置会被保存为与系统无关的文件格式(如XML 文件或JSON 文件),本文将此类文件统称为场景配置文件.
2 面向无人驾驶系统的仿真模糊测试
2.1 仿真模糊测试架构
现有工作[15–20]在实现面向无人驾驶系统的仿真模糊测试时,主要利用了模糊测试的随机性和仿真测试的灵活性,在仅有少数初始场景配置的情况下,自动化地生成并验证海量未知的仿真驾驶场景.通过对现有工作的系统性总结,本文将仿真模糊测试的一般架构解构为4 个关键模块,分别为种子场景生成模块、事故挖掘模块、事故分类模块和事故归因分析模块,如图2 所示.
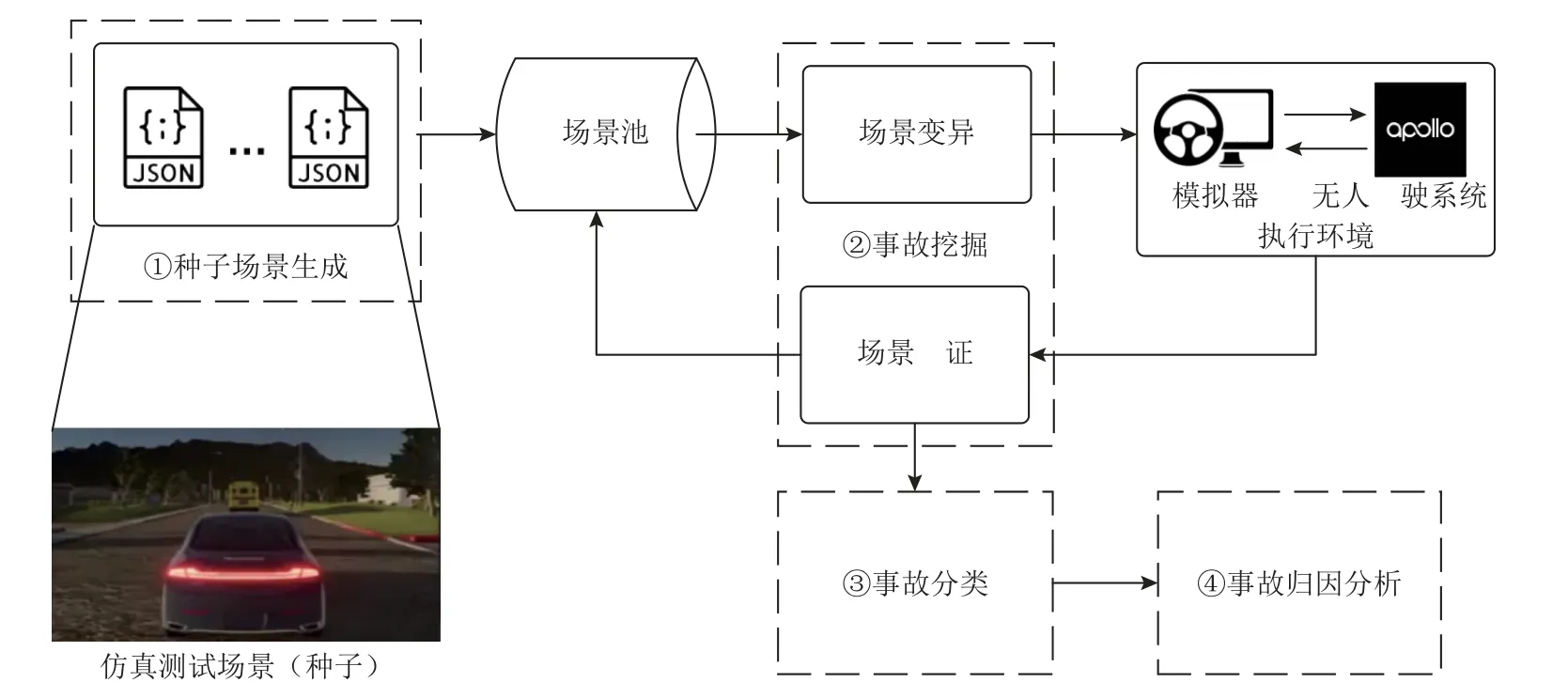
Fig.2 Architecture of simulation-based fuzzing图2 仿真模糊测试框架
1)种子场景生成模块.进行模糊测试的首要条件是准备一定量的初始输入作为种子,从而可以通过种子的变异或调整源源不断地生成新的测试输入.在无人驾驶系统仿真测试的语境下,种子指代的是初始的仿真场景配置文件,其指明了驾驶仿真器在实现无人车模拟、环境模拟以及交通模拟时所依赖的必要参数.
2)事故挖掘模块.在给定种子场景的情况下,事故挖掘模块的预期功能是通过变异种子场景的各项配置来生成新的待测场景,并通过监控各待测场景的仿真执行结果,验证变异后的场景是否会造成无人驾驶车辆的不当行为,如车辆碰撞或交通违规等.在传统的软件模糊测试领域,现有工作[40–45]通常制定“变异-反馈”机制来避免盲目的种子生成与验证,即在变异过程中筛选出高质量的种子,引导种子向更优异的方向持续演进.同样地,这类反馈机制也存在于面向无人驾驶系统的仿真模糊测试中,其旨在遴选出更接近事故发生的仿真驾驶场景.
3)事故分类模块.在传统的软件模糊测试领域,崩溃去重[46-47]是必不可少的重要步骤.在收集完所有能够触发程序崩溃的种子后,该步骤旨在筛除有相似崩溃行为的冗余种子,以此减少安全人员的分析开销.类似地,仿真模糊测试的事故分类模块旨在去除同类的无人车事故场景,以此辅助安全分析人员更快定位和治理无人驾驶系统中的不同缺陷.
4)事故归因分析模块.传统模糊测试通常可依赖内存错误检测工具(如AddressSanitizer[48])来定位导致程序崩溃的代码位置.然而,因无人驾驶系统的碰撞事故通常由逻辑缺陷(如算法设计缺陷或模型运算错误)导致,其不会出现显式的内存崩溃.因此,仿真模糊测试通常需要额外的事故归因步骤来确认导致事故的系统模块、模型或代码片段等.
2.2 现有工作概述
近年来,不少前沿的学术工作[15–20]尝试设计面向无人驾驶系统的仿真模糊测试技术,以挖掘和整治无人驾驶系统的功能安全威胁.如表1 所示,根据2.1 节所述的四大模块,本文尝试对现有工作的技术方案进行模块化拆解,分别介绍这些工作实现的各关键模块的具体方案.

Table 1 Existing Work in Simulation-based Fuzzing for Autonomous Driving Systems表1 现有的面向无人驾驶系统的仿真模糊测试工作
1)针对种子场景生成模块,已有工作主要采用2 类方案,一类是根据人工经验配置简单的驾驶场景,另一类是设计随机算法以生成初始的场景配置.MFT[15]和AV-FUZZER[16]人工构建了1~2 个简单的直道驾驶场景作为初始种子,场景中仅包含少量的动态运行车辆与静态障碍物.其余工作则依据先验知识,通过随机采样的方式生成一定数量的仿真场景作为初始种子.更具体地说,ASF[17]尝试完全随机生成符合场景配置格式的初始场景;AutoFuzz[18]从驾驶模拟器的API 规范中提取出场景配置参数的相关约束,并通过随机采样生成有效的场景配置;DriveFuzz[19]设计了一套可达性分析算法,为无人车在地图上随机选取有效的起点和目的地;MOSAT[20]在指定NPC 的数量和距离范围后随机生成初始场景.
2)针对事故挖掘模块,已有工作基于无人驾驶测试的领域知识,设计了多样且有效的“变异-反馈”机制,以便将初始的种子场景更快地变异为诱发无人驾驶事故的场景.同时,在挖掘事故场景时,已有工作普遍关注车辆碰撞这一严重的安全事故类型.MFT尝试在无人车的行进道路上随机放置新的静态障碍物,通过增加无人车与周边场景元素的交互来提高事故发生的概率.AV-FUZZER 尝试改变无人车周围虚拟车辆 (NPC) 车辆的变道策略和速度,计算NPC车辆和无人车的安全距离作为遗传算法的适应度函数,用于发现更苛刻的行驶场景.MOSAT 则根据NPC 车辆与无人车的位置关系,定义了4 种场景变异模式来增加无人车路径规划的难度,此外还提出了多目标的适应度函数,通过考虑事故的多样性和无人车驾驶行为的不稳定性等来引导变异的流程.ASF 在一定范围内新增NPC 车辆并修改原有NPC车辆的起始位置,以无人车驾驶的轨迹覆盖率为导向,尝试触发更多样的无人车驾驶行为以挖掘不同的事故场景.AutoFuzz 将场景配置参数向量化的同时,创新性地利用梯度下降算法变异参数向量,并使用神经网络分类器来遴选更危险的驾驶场景.DriveFuzz 在场景变异过程中,设计了更多样的NPC车辆驾驶行为(如变道插队),通过观测无人车的危险驾驶操作(如急刹车和急转弯)来量化各场景的危险程度.
3)针对事故分类模块,AV-FUZZER 和MOSAT通过观察所有事故场景的仿真运行流程,根据无人车的驾驶行为特征,以人工的方式主观地将碰撞事故归为不同的类别.更进一步地,AutoFuzz 首次尝试实现自动化的事故场景去重.给定任意2 个事故场景,AutoFuzz 通过判断仿真场景配置文件的差异程度来决定两者是否等价,即当差异程度超过预设的阈值时,则认为2 个事故场景属于不同的类别.
4)针对事故归因分析模块,目前所有的工作都缺乏自动化分析事故场景根源缺陷的能力.ASF 针对一例事故展开了详细的人工归因分析,并最终定位到导致事故的缺陷代码位置.DriveFuzz 以人工分析的方式,将事故的根源归纳为不同的种类,包括仿真器缺陷、系统逻辑缺陷和系统功能不足等.此外,ASF 和DriveFuzz 仅描述了事故归因分析的结果,但并未详细阐释归因分析的方法论与具体步骤.
2.3 现有工作的缺陷
根据2.2 节的阐述不难发现,现有的仿真模糊测试技术主要关注事故挖掘模块的设计,即尝试借鉴传统软件模糊测试的“变异-反馈”机制,融合遗传算法或神经网络等前沿方法,以便更快地挖掘到无人车事故场景.然而,相比之下,种子场景生成模块、事故分类模块与事故归因分析模块的设计则普遍依赖启发式的规则或人工分析来实现.值得注意的是,这4 个关键模块协同工作才能构成仿真模糊测试的闭环,换言之,单个模块的设计缺陷将直接影响到仿真模糊测试的有效性和可靠性.下面本文将详细剖析不同模块的设计缺陷.
1)种子场景的质量低下且依赖个人经验手工构造.长期以来,初始种子的质量已被广泛证明对模糊测试的结果存在显著影响[49-50].然而,在开展面向无人驾驶系统的仿真模糊测试时,现有工作普遍根据专家经验或个人经验,主观地选择数量有限的简单场景作为种子,没有重视或评估种子场景对于测试结果可能存在的影响.其次,现有工作普遍采用手工构造的方式来创建初始场景.正如1.3 节所述,场景的配置涉及种类繁多的参数,且不同参数的格式与内涵相差甚远,即需要耗费可观的人力与时间才能完成参数的逐一配置.虽然部分工作尝试使用随机生成的方式来减少人工开销,但这些工作仍然需要人工总结出场景模板或场景约束来指导场景的生成.
2)缺乏可靠的自动化事故分类.现有的仿真模糊测试工作在各自的实验评估中均成功发现了主流开源无人驾驶系统的多例事故场景.然而,这些工作普遍缺乏自动化的事故分类方法,导致分析人员难以从众多的事故案例中遴选出典型的案例作为进一步分析和诊断的目标.AutoFuzz 虽然尝试提出自动化的聚类方法,但该方法仅通过仿真场景配置的相似度来判断事故是否类似.因缺乏事故相关的分析(如事故主体和事故特性),AutoFuzz 在事故分类中极易产生错误.
3)缺乏可靠的自动化事故归因分析.现有的仿真模糊测试在汇报了事故场景后,无法通过可靠的自动化归因分析来定位系统缺陷点(即代码位置).这使得事故的确认与修复受到了极大的阻碍.ASF和DriveFuzz 尝试通过人工的方式进行系统缺陷点的定位.显然,该类方式需要极强的无人驾驶领域知识,以及对目标无人驾驶系统代码实现的深入理解.此外,因ASF 与DriveFuzz 并未阐明人工归因分析的具体流程与方法论,这使得归因分析结果的准确性难以得到保证.
为切实提高仿真模糊测试的可用性和可靠性,本文面向上述3 大缺陷提出针对性的解决思路.具体而言,在第3~5 节中,本文分别剖析了优化种子场景生成模块、事故分类模块与事故归因模块所面临的挑战,并提供了可行的解决思路.为论证这些思路的可行性与先进性,本文尝试在主流开源无人驾驶系统Apollo 和Autoware 开展实验并与现有工作的方案进行对比.此外,本文将根据实验论证的结果进一步展望仿真模糊测试领域的发展方向.
3 种子场景生成:挑战、实践与展望
3.1 挑 战
如2.1 节所述,仿真模糊测试依赖种子场景作为初始输入.然而,现有的无人驾驶相关的公开数据集[51–59]主要提供原始传感器数据(如相机、激光雷达等),这些数据可以用于训练和测试无人驾驶系统内的机器学习算法(如对象检测和追踪),但不能直接用于仿真测试.因此,现有的仿真模糊测试工作中所使用的种子场景普遍是研究者根据自身经验手动或随机构建的简单场景,极大地限制了仿真模糊测试的事故场景挖掘能力.然而,为仿真模糊测试自动化准备高质量的种子场景绝非易事,所构建的种子场景应该满足2 个基本特性:
挑战1.满足高保真性.仿真场景是现实世界驾驶场景的数字化版本,其应当符合真实世界中可能存在的驾驶情况.为了满足该需求,安全测试人员通常需要参考已有的交通事故报告或路测报告,以繁重的人工成本在仿真环境中进行等价的还原.
挑战2.满足语法正确性.对于仿真测试而言,虚拟场景的参数配置应该被编码成规范的格式(如OpenSCENARIO[36]),否则仿真器不能接受其作为输入.这些格式规范往往有着复杂的语法约束,例如,一个简单的变道超车场景需要200 多行格式良好的代码来进行参数配置.
3.2 基本思路
针对3.1 节所述的2 个挑战,本文提出了一种自动化的种子场景构建方法.该方法的核心思路是,从真实世界的交通轨迹数据集[60-61]中收集指定路段上可能出现的交通参与方(车辆或行人)的运动行为,以此作为仿真场景参数配置的数据参考.这类轨迹数据通常由车端或路端记录仪在真实道路上实时捕捉所得,因此可以准确地反映真实世界中可能存在的复杂交通流模式.参考这类数据来配置仿真场景的交通模拟参数可以极大地确保场景的保真性.
交通轨迹数据集主要以带时间戳的GPS 坐标序列来描述各交通参与方的行为:
其中,Entity表示交通参与方,gps表示经纬地理坐标,t表示时间戳.
在构建种子场景时,本文尝试基于现有的地图转换工具[62],将交通轨迹相关的路段地图(如Lanelets格式[39])转换为等价的仿真地图格式(如OpenDrive格式[37]),并在该仿真地图上灵活地布置这些具有特定运动行为的交通参与方,以此完成交通模拟参数的配置.然而,这些轨迹数据通常被存储于自定义格式的CSV 文件中,并不兼容仿真场景参数配置的格式规范(见1.3 节).此外,这些轨迹数据的坐标系通常与仿真场景所需的坐标系不同.因此,为进一步保证仿真场景配置的语法正确性,交通参与方的GPS坐标序列须进行正确的坐标转换(如从UTM 坐标系转换为局部坐标系),并按照仿真场景的语法格式规范进行参数配置.
图3 展示了自动化种子场景构建的一般流程.值得注意的是,除交通模拟参数和地图参数外,本文将随机生成仿真场景的自然环境参数(如天气),使用仿真器和无人驾驶系统提供的无人车物理学和动力学模型,并随机生成其余无人车模拟参数(如驾驶的起始位置).最终,基于仿真场景描述性语言(如OpenSCENARIO[36])的语法模板(如XSD 文件),本文将上述参数实例化为种子场景配置文件(如XML 文件),以作为模糊测试的输入.
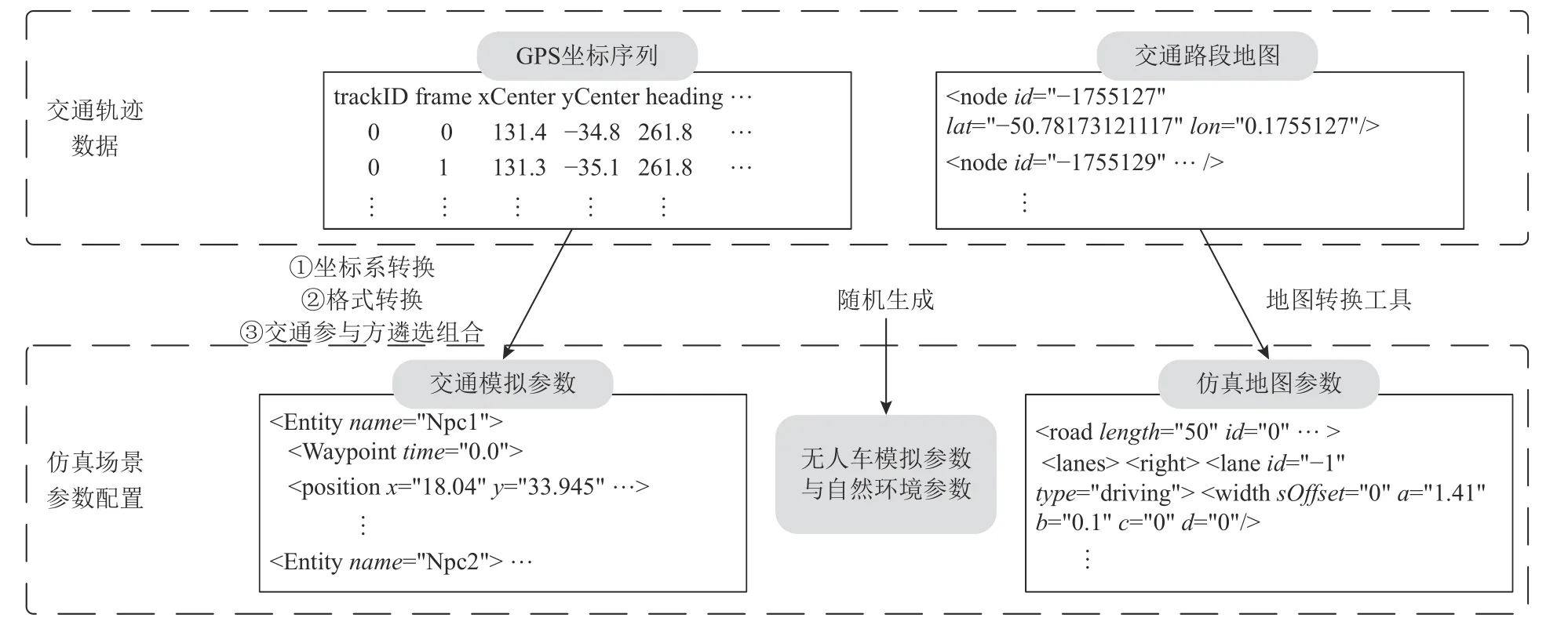
Fig.3 Overview of automated seed scenario construction图3 自动化种子场景构建概览
3.3 实验设计
本文尝试证明3.2 节所述的方法所得的种子场景能够提升仿真模糊测试技术的事故场景挖掘能力.为实现该目标,本文尝试将所得种子场景与现有工作使用的种子场景分别作为同一款仿真模糊测试工具的输入,并面向相同的无人驾驶系统进行事故场景挖掘.
在仿真模糊测试工具方面:本文基于LGSVL 模拟器实现,通过4 000 行左右的Python 代码实现了基本的仿真模糊测试工具.在实现该工具时,本文参考了领域内的前沿工作DriveFuzz[19],并进一步丰富了其场景变异的模式(如变更光照强度等).值得注意的是,该实验的目标是衡量种子质量对于模糊测试结果的影响.因此,参考传统模糊测试领域的实践方式[47],本文禁用了DriveFuzz 的种子调度机制,以免对实验结果造成干扰.
在待测无人驾驶系统方面:本文挑选了2 款主流的高级别无人驾驶系统作为测试对象,Apollo 6.0 和Autoware 1.15.
在待测种子场景方面:实验生成了50 个适用于模拟器LGSVL 的仿真场景作为待测种子.这些种子场景基于数十种地图进行构建,拥有不同的道路结构(如单车道、合并车道、交通路口等)、车流模式(如跟车、转弯、变道超车、紧急停车等)、车辆类型(如汽车、卡车、自行车等)和天气状况(如晴天、雨天、雾天)等.
另外,本文尝试从现有工作中获取可用的种子场景用于实验对比.此处,只有AV-FUZZER 和AutoFuzz开源了可用的场景配置文件.因此,本文最终获取了AV-FUZZER 的2 个种子场景和AutoFuzz 的4 个种子场景,并以这6 个种子场景作为实验的参照组.
为便于理解,图4 直观地展示了来自AV-FUZZER、AutoFuzz 及本文构建的部分场景种子的俯视图(蓝色车辆为无人车,蓝色箭头代表预期驾驶任务).
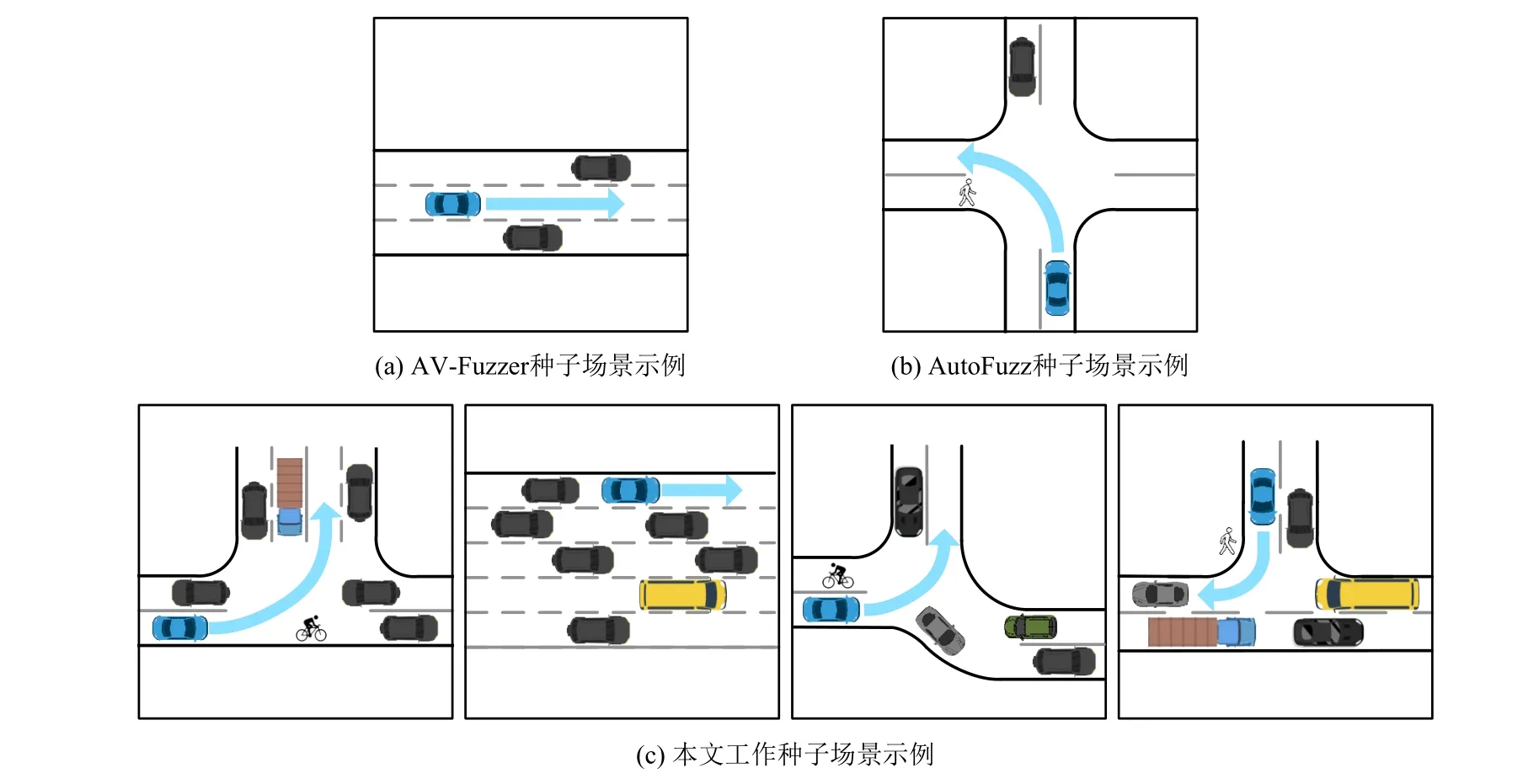
Fig.4 Comparison of seed scenarios from existing works and our work图4 现有工作和本文工作的种子场景对比
在实验设置与环境方面:以各种子场景作为仿真模糊测试工具的输入,本文独立进行时长为3 h 的仿真模糊测试,并收集产生的事故场景数量.所有的实验评估都在Ubuntu 18.04 服务器上进行,该服务器有314 GB 内存、4 个GPU 核心(NVIDIA GeForce RTX 2080 Ti)和40 个 CPU 核心(Intel Xeon Gold 5215,2.50 GHz).
3.4 实验结果与分析
如表2 所示,参照本文思路构建的各种子场景在3 h 内平均可发现Apollo 的80.3 例事故场景和Autoware 的84.9 例事故场景,远高于AV-FUZZER 和AutoFuzz 的种子场景在相同实验配置下产生的事故数量.例如,本文种子场景在Apollo 系统上的碰撞数量相较现有工作的种子场景分别提升了203%和351%.该数据直观地表明本文构建的种子场景更利于事故场景的挖掘.
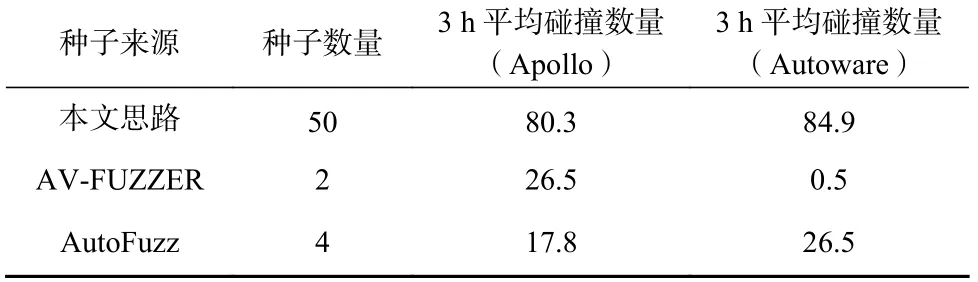
Table 2 Assessment Results on Seed Scenarios Quality表2 种子场景质量的评估结果
经分析,本文发现导致该差异的主要原因是,现有工作使用的初始场景往往交通状况简单且场景元素匮乏,故需要进行繁多的变异操作后才能增加无人车与周围环境或交通参与方的交互频率,以此提高事故发生的概率.然而相比之下,依照本文思路构建的种子场景反映了真实世界的交通路况,其场景元素复杂且交通参与方行为多样,即初始的场景配置就对无人驾驶系统的感知、规划与控制造成了不小的挑战.因此,该类场景仅需少量的变异操作,就极有可能触发无人驾驶系统的缺陷,继而导致事故的发生.
3.5 未来展望
如表2 所示,本文构建的种子场景的平均事故挖掘能力远高于现有工作的种子场景.然而,本文发现,不同种子的事故挖掘能力存在巨大差异.例如,在本文构建的50 个种子场景中,某种子场景在3h 内无法挖掘到任何事故,而某种子场景可成功挖掘到200 余例事故场景.鉴于此,若能在仿真模式测试前对种子场景的事故挖掘能力进行预测,则能够极大地提升测试的有效性.在二进制模糊测试的领域,现有工作[49,63]往往在测试前基于代码覆盖率对种子质量进行预测评估.与此不同的是,无人驾驶仿真测试具有更多可参考的信息要素(如场景语义和系统代码),如何妥当地利用这些要素实现种子场景的遴选是该领域内有待探索的方向之一.
4 事故分类:挑战、实践与展望
4.1 挑 战
在传统的模糊测试领域,长时间的测试极有可能产生大量的程序崩溃,且其中不乏相似的崩溃.为避免不必要的分析开销,相关工作普遍依赖崩溃去重技术[46-47]实现相似崩溃的聚类.类似地,如3.4 节的实验结果所示,面向无人驾驶系统的仿真模糊测试也极有可能挖掘到大量的事故场景,亟需事故分类技术实现相似事故的聚类.
挑战:事故场景元素众多,难以自动确认事故相关要素.在交通领域[64],相关人员通常需要确认事故主体(对事故发生产生直接或间接影响的交通参与方)和事故特性(地点与危害程度)来完成交通事故的分类.然而,在仿真事故场景中,场景元素通常复杂繁多,难以实现对该类信息的提取与甄别,进而导致仿真事故场景的分类困难.
4.2 基本思路
针对4.1 节所述的难点,本文提出了一种自动化的事故要素分析(即事故主体与事故特性)与事故场景分类方案,该方案主要适用于碰撞类事故.首先,当在仿真环境中观测到无人车碰撞事故时,本文会立即通过仿真器所提供的应用程序接口 (API) 记录必要的事故特性.这些特性主要包括:碰撞发生的具体地点(如车辆所在的道路编号)、碰撞的角度(如两车车头的夹角)和碰撞速度.随后,本文尝试分析各交通参与方与事故发生之间的关联性,从而确认事故主体.具体而言,该方法将逐个变更交通参与方的运动行为(随机改变速度和轨迹点),若行为变更后碰撞事故不再发生或事故特性改变,则认为该交通参与方为事故主体之一.通过上述这种“调整-重放”式的分析策略,本文能够可信地确认交通参与方的运动行为与事故发生之间的相关性.
最终,本文根据事故特性和事故主体的一致性,实现碰撞事故的自动化聚类.具体地说,本文提取发生碰撞所在道路序号来标识碰撞地点,以追尾(0°~60°)、侧撞(60°~120°)与对撞(120°~180°)这3 类情况来描述碰撞角度,以低速碰撞(0~30 km/h)、中速碰撞(30~60 km/h)和高速碰撞(60 km/h 以上)这3 类情况来描述碰撞速度.当且仅当碰撞所在的道路序号、碰撞角度情况和碰撞速度情况都相同时,2 例无人车碰撞事故才被认为具有相同的事故特性.对于事故主体的一致性分析,本文主要判断主体类型和主体数量是否一致.
4.3 实验设计
本文尝试证明4.2 节所述的方案能够帮助实现准确的事故分类.因现有的仿真模糊测试工作中仅AutoFuzz 尝试实现自动化的事故分类,本文尝试将本文所提方案与AutoFuzz 进行对比,以体现其优势.
在AutoFuzz 事故分类方案方面:AutoFuzz 提出,如果2 个事故场景配置的参数中至少有x%是不同的(x%是人工设置的阈值),则认为这2 个事故场景不是同一类型.参照AutoFuzz 的原文[18]实现,本文将该阈值设置为10%.与本文所提方案的区别在于,AutoFuzz 并不会区分事故主体,也不会甄别事故特性,其考虑仿真场景中所有的元素作为事故相似性的判断依据.
在待分类事故场景方面:本文从第3 节的仿真模糊测试结果中人工标注并筛选出了50 种不同类型的碰撞事故,每个事故种类包含了10 例事故场景.基于这500 例事故场景,本文尝试开展AutoFuzz 事故分类方案和本文所提方案的对比实验.
在分类评估指标方面:为了评估事故分类的效果,本文主要使用了聚类分析领域的常用指标[65],即平均准确率(又称纯净度)和平均召回率(又称倒纯净度).具体地说,平均准确率可以有效衡量不同类型的事故是否会被错误地分到同一类中,平均召回率可以有效衡量同一类型的事故是否会被错误地分到不同类中.因这2 个指标涵盖了事故分类中所有可能出现的分类错误情况,本文可以客观地衡量不同分类方案的可靠性.基于上述定义,平均准确率和平均召回率的计算方式为:
其中,Cj是第j个实验聚类,Li是第i个基准分类,N是聚类中的元素总数.
在实验设置与环境方面:本文使用3.3 节中介绍的服务器开展该实验.
4.4 实验结果与分析
本实验的评估结果如表3 所示.由该表可知,本文方案的平均准确率和平均召回率远高于AutoFuzz.为了便于理解,下面将通过2 个反例分析AutoFuzz分类效果不佳的根本原因.

Table 3 Assessment Results on Accident Triage表3 事故分类的评估结果
1)AutoFuzz 平均准确率较低.如图5 所示,对于参数配置高度相似但实则代表不同事故的场景,AutoFuzz 会错误地将其归类为同一类型的事故.其根本原因在于,AutoFuzz 无法鉴别事故主体与事故特性.
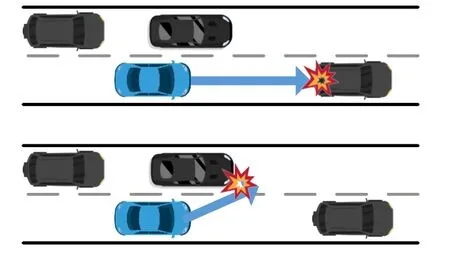
Fig.5 Inequivalent accidents misclassified into the same category图5 不同事故误分为同一类
2)AutoFuzz 平均召回率较低.类似地,如图6 所示,当场景中存在较多事故无关的主体时,AutoFuzz 极有可能认为2 个事故场景代表着不同类型的交通事故.
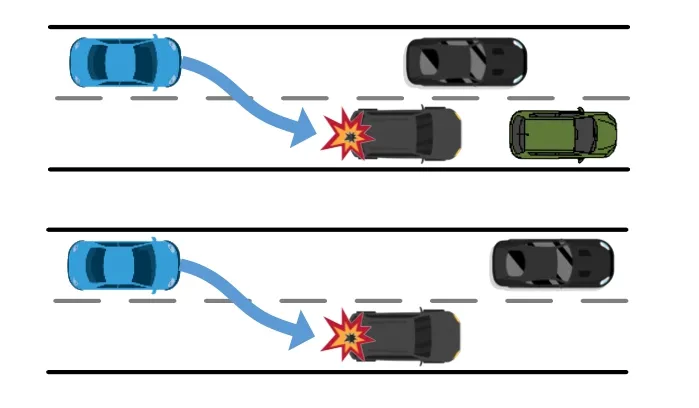
Fig.6 Equivalent accidents misclassified into different categories图6 同种事故误分为不同类
此外,本文方案也存在将同一类型事故错误分到不同类别的情况,即平均召回率并非100%.经过细致的案例分析,本文发现其主要的原因在于,部分无人车相关的碰撞事故是概率性的.如4.2 节所述,本文主要通过多次的事故重放来推断各交通参与方是否为事故主体.因概率性事故的重放结果并不稳定,这极易导致事故主体的判断错误,进而误导事故分类.
4.5 未来展望
值得注意的是,本文在进行事故分类时,仅参考仿真场景的语义信息(事故主体和事故特性),而忽略了无人驾驶系统的内部执行状态.这意味着,不同系统缺陷导致的交通事故有可能被归为同一类,进而在后续的缺陷确认环节中被忽略.因此,如何结合场景的语义信息与系统内部的执行信息来完成鲁棒的事故分类也是亟待探索的课题之一.
5 事故归因分析:挑战、实践与展望
5.1 挑 战
传统的模糊测试工具通常依赖内存错误检测工具(如AddressSanitizer[48])来确认崩溃发生的代码位置,以此辅助程序缺陷的确认与修复.同样地,对于仿真模糊测试而言,定位导致交通事故的系统缺陷位置对无人驾驶安全性的提升至关重要.然而,据现有研究[66]显示,无人驾驶系统中易致使交通事故的缺陷通常为逻辑缺陷,其不会引发显式的内存错误或系统崩溃,因此无法用常规的内存错误检测工具来进行缺陷代码位置的定位.鉴于此,仿真模糊测试亟需定制化的事故归因分析能力来提升其安全应用价值.
挑战:无人驾驶系统的复杂性.无人驾驶系统是代码和模型深度耦合的复杂智能系统,其往往具有庞大的代码量,使得藏匿其中的系统缺陷难以被发现.例如,Apollo 开源无人驾驶系统拥有数十万行的代码.现有的仿真模糊测试工作(如ASF 和DriveFuzz)依赖专家经验进行人工的缺陷定位,这不仅需要对无人驾驶系统的模块架构具有深入的了解,还需要对海量的被执行代码进行准确逻辑语义分析.同时,因这些工作并未提供人工分析的方法论和细节步骤,其可借鉴性十分有限.
5.2 基本思路
尽管不同的高级别无人驾驶系统在代码实现上截然不同,但如1.1 节所述,它们的系统模块结构和各模块的预期功能普遍高度相似.其中,感知模块主要负责确认车身周围障碍物位置;预测模块主要推断障碍物未来的运行轨迹;规划模块主要确定无人车的安全行驶路线;控制模块主要根据规划路线生成对应的车辆控制指令.鉴于此,本文实现了模块级别的自动化缺陷定位,以此提高该方案在不同无人驾驶系统间的可移植性.该类模块级别的缺陷定位可极大地辅助缺陷的诊断与修复.
该方案的核心思路为:实时地监控并比对仿真场景中各元素的真实状态(仅考虑事故主体,见4.2 节)以及无人驾驶系统的模块执行信息,以此判断无人驾驶系统各功能模块实际运行效果与预期功能的差距(简称为模块功能差距),最终将功能差距最大的模块视为事故主责模块(即缺陷模块).为准确地定义模块功能差距,本文归纳了不同系统模块的预期功能,并借助仿真模糊测试可实时观测、可重放的特性实现了模块功能差距的计算,具体为:
1)感知模块功能差距.正常运作的感知模块旨在准确定位无人车周围所有障碍物的具体位置.为计算该模块的功能差距,本文在仿真器中实时观测各障碍物的真实位置信息作为预期数据,同时在无人驾驶系统中截取感知模块计算所得的障碍物位置信息作为实际运行数据,最终计算这2 类信息中各障碍物的位置坐标的平均距离作为感知模块功能差距.
2)预测模块功能差距.正常运作的预测模块旨在准确预测无人车周围物体的未来运动轨迹.为计算该模块的功能差距,本文尝试重放事故场景,记录仿真器中每一时刻各物体的真实未来运动轨迹作为预期数据,同时截取预测模块计算所得的未来轨迹作为实际运行数据,最终计算这2 类信息中平均的轨迹差异作为预测模块功能差距.在衡量轨迹之间的差异时,本文主要计算两轨迹上具有相同时间戳的坐标点之间的平均距离.
3)控制模块功能差距.正常运作的控制模块旨在准确按照无人驾驶系统规划的行驶路径来控制无人车的行进.为计算该模块的功能差距,本文截取规划模块计算所得的行驶路径作为预期数据,同时在仿真器中记录无人车的真实运行轨迹作为实际运行数据,最终计算这2 类信息中无人车的轨迹差异作为控制模块功能差距.类似地,此处仍然计算2 轨迹上具有相同时间戳的坐标点之间的平均距离作为轨迹差异.
4)规划模块缺陷判断.值得注意的是,正常运作的规划模块旨在计算出可达目的地的安全驾驶路径.在没有任何人工分析的辅助下,该模块的预期表现是难以定性的.因此,本文在进行归因分析时,首先依次计算上述3 种模块的功能差距.若这3 种模块的功能差距都小于一定阈值(阈值的设置见5.3 节),即认为缺陷不存在于这3 种模块中,并参考现有工作[67-68]计算各时间节点无人车的可行驶空间,以此判断是否为规划模块缺陷.具体地说,若不存在任何可行驶空间但仍然发生了碰撞(例如堵车时被后车追尾),则认为这不是无人车负主责的事故,即该事故不是由规划模块缺陷导致;反之,本文则认为规划模块是该碰撞事故的主责模块.
5.3 实验设计
现有的仿真模糊测试在汇报了事故场景后,通常仅依靠纯人工的方式进行归因分析.因此,在本实验中,本文尝试将所提归因分析方案与人工分析做对比,以体现本文方案优势.
在人工事故归因分析方面:给定仿真环境下的无人车碰撞事故,本文总计邀请了4 位无人驾驶系统领域的专家来分析事故对应的缺陷模块.他们都曾为主流开源无人驾驶系统Apollo 或Autoware 提交过漏洞修复的commit,对这2 款无人驾驶系统的模块结构与代码实现有着较深的了解.具体地说,为避免人工分析的错误,各事故场景的归因分析结果将由2 位专家进行交叉验证.该人工验证所得的事故主责模块也将作为衡量本文所提方案的基准数据.
在待归因事故场景方面:本文从4.3 节所述的50 类交通事故中,各随机挑选了1 例事故场景作为待归因分析的对象.同类事故中,虽然不同事故场景的场景参数不同,但它们的事故特性和事故主体一致,极大概率是由相同的无人车系统缺陷导致的碰撞.因此,本文仅从每类事故中选取1 例作为归因分析的对象.此外,这50 例碰撞事故涵盖了不同的交通路况、无人车驾驶任务以及环境状态,能够全面且可信地评估事故归因分析方案的可靠性.
在阈值设置方面:在该实验中,本文统一将感知模块、预测模块以及控制模块的功能差距阈值设置为1 m.特别地,若感知模块或预测模块出现了严重的运行时错误(如完全无法探知某物体的存在与运动轨迹或认为空旷处存在某物体),本文直接将相应的模块视作事故主责模块.
在实验环境方面:本文使用3.3 节和3.4 节中介绍的服务器开展该实验.
5.4 实验结果与分析
表4 展示了本实验的评估结果.本文能够正确分析出44 例事故的主责模块.虽然该准确率(44/50)略低于专家分析,但本文所提的自动化工具不要求测试人员具有丰富的无人驾驶安全领域知识,具有高度的灵活性与可用性.本文分析了6 例归因错误的事故场景,发现错误原因主要有2 类:1)其中4 例由可行驶空间计算的错误导致.具体地说,在计算可行驶空间时,本文并未考虑无人车所在道路是否可以变道或逆行,结果导致无法规避的碰撞事故被错误地认为是由规划模块缺陷导致的事故.2)剩余2 例事故场景中,本文发现功能差距最大的模块并非事故主责模块.这2 例事故均为高速驾驶场景,在碰撞前空旷路段的直线高速行驶过程中,因不可避免的系统延时导致控制模块的功能差距高达2.3 m 以上.然而,碰撞发生的关键原因是,无人驾驶系统没有准确预测前车的减速行为.虽然该预测误差仅为0.9 m 左右,但直接导致了无人车没有及时刹车,造成追尾碰撞.

Table 4 Assessment Results on Accident Root Cause Analysis表4 事故归因分析的评估结果
此外,由表4 可知,本文所提的自动化方案平均仅需0.05 h 就可完成1 例事故场景的归因分析.相比之下,具有丰富领域知识的安全专家需要约4.4 h 才可完成这一分析任务.这直接表明,本文工作能够大幅度地提高事故归因分析的效率,降低事故分析的人工成本.
5.5 案例分析
图7 展示了本文工作从Apollo 6.0 中找到的1 处代码缺陷,场景如图7(b)所示.在无人车经过一处交叉路口时,右侧同时横向驶来一辆速度极慢的灰色车辆,无人车理应观察并预测到该车辆将出现在前方规划的道路上,并做出减速决策.然而,Apollo 系统并没有对该车辆进行任何的轨迹预测,导致无人车径直驶过十字路口,并最终与灰色车辆产生碰撞.
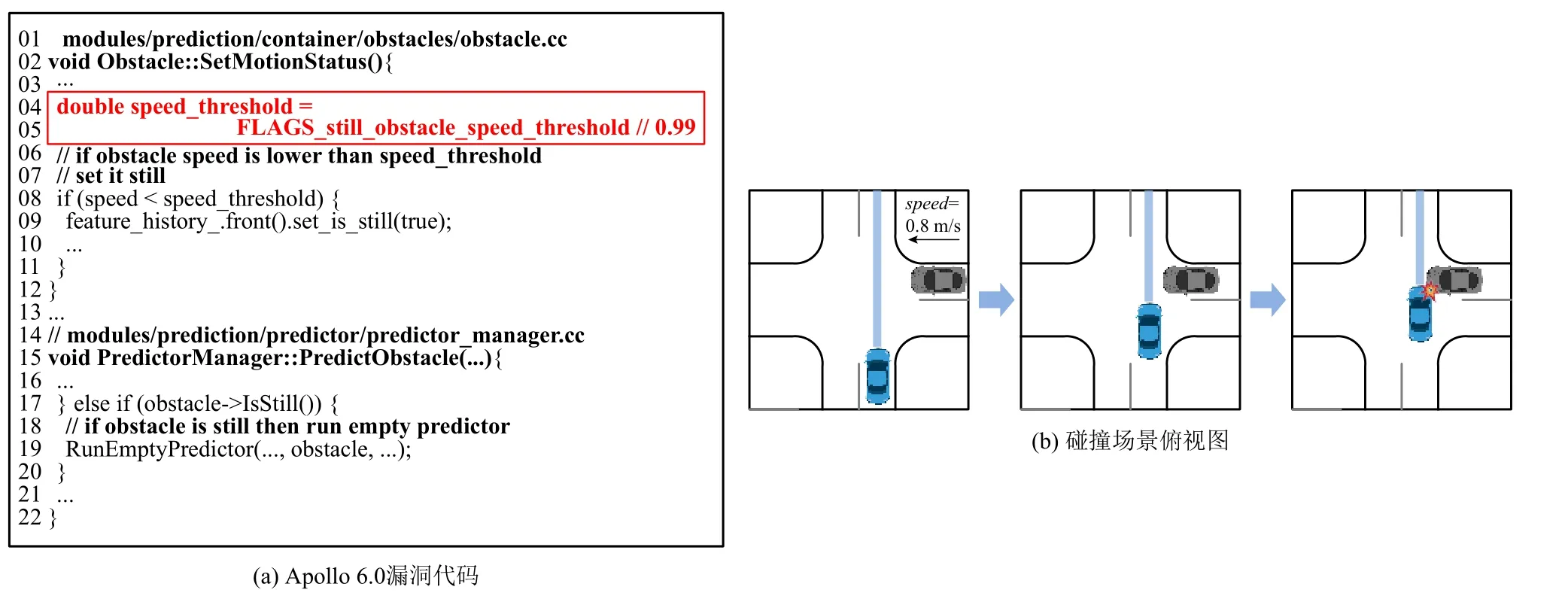
Fig.7 An example design flaw in Apollo 6.0图7 Apollo 6.0 中的设计缺陷示例
本文通过采用所提的事故归因分析方法,将导致该场景的缺陷定位于预测模块.随后,经过人工的模块内代码分析,定位于缺陷代码的位置.如图7(a)所示,在对周围驾驶车辆进行预测时,Apollo 定义了静止障碍物速度阈值来对抗扰动,将低于该速度的车辆统一认定为静止的障碍物.然而,Apollo 关于该阈值的默认值(3.6 km/h)较高.该不合理的设置将导致系统无法对一些低速车辆进行轨迹预测,从而有可能导致交通事故的发生.
5.6 未来展望
本文所提的归因分析方案仅能定位到事故的缺陷模块,而非具体的代码片段.虽然该模块定位信息能够辅助缺陷的确认与修复,但仍然需要较多的人力进行模块内代码的溯源分析.鉴于此,本文认为未来工作可以着眼于模块内的缺陷根源分析,通过充分理解事故场景的语义信息,结合模块内代码执行的控制流与数据流信息,实现更细粒度的缺陷定位.
6 总 结
面向无人驾驶系统的仿真模糊测试技术旨在将传统的模糊测试技术与仿真测试技术结合,自动地挖掘与分析易导致交通事故的无人驾驶系统缺陷.然而,该研究领域仍处于起步阶段,现有工作仍然存在较大缺陷,制约了其安全应用.鉴于此,本文首先尝试构建仿真模糊测试的框架,其包含种子场景生成、事故挖掘、事故分类和事故归因分析四大关键模块.随后,本文系统性地分析了现有工作在实现四大模块时的不足之处.最终,本文尝试提出可行的解决思路,并将这些思路直接用于主流开源无人驾驶系统的安全测评,以体现其可行性和优越性.结合实际的安全测评结果,本文进一步指出该领域未来可能的发展方向,为后续的研究工作提供可靠的指导意见.
作者贡献声明:戴嘉润负责论文的框架设计、实验设计以及论文撰写;李忠睿负责论文初稿撰写、图表绘制和实验数据统计;张琬琪参与了论文的修改润色;张源与杨珉关于论文选题和写作提供了指导性建议.
