融合标签文本的k-means聚类和矩阵分解算法
2023-06-10居晓媛汪明艳
居晓媛, 汪明艳
(上海工程技术大学管理学院, 上海 201620)
1 引言(Introduction)
推荐算法是以大数据为依托,以用户行为对象,分析用户浏览的历史记录、习惯、偏好,有针对性地为用户推荐符合其喜好的内容。常见的推荐算法包括协同过滤[1]、基于内容的推荐[2]及混合推荐算法等。协同过滤主要包括两种:基于内存的协同过滤(Memory-based CF)和基于模型的协同过滤(Model-based CF)。基于模型的协同过滤通过建模的方式模拟用户对项目的评分行为,其使用机器学习与数据挖掘技术,从训练数据中确定模型并将模型用于预测未知商品评分。作为常见的基于模型的协同过滤方式,矩阵分解已成为降低数据维数、提取数据潜在特征和减少稀疏性的有效方法。根据矩阵分解可以解决数据稀疏的特点,所以矩阵分解被广泛应用于推荐系统中。常用的矩阵分解技术包括奇异值分解(SVD)[3]、主成分分析(PCA)[4]、概率矩阵分解(PMF)[5]和非负矩阵分解(NMF)[6]。YAO等提出了一种基于联合概率矩阵分解的群体推荐方法,能更好地模拟群体推荐问题,在面向群体的推荐问题中取得较好的效果[7]。杨辰等提出一种基于细粒度属性偏好聚类的新型推荐模型,对项目-属性关系和用户-属性偏好进行建模,基于用户簇或项目簇采用协同过滤算法生成推荐列表[8]。YUAN等认为隐语义模型(Latent Factor Model)属于SVD的一种变体,它降低了用户项目评级矩阵的维数,表示评级矩阵中用户和项目的潜在特征,其提出了一种混合方面级的隐语义模型(HALFM)优化了全局方面级潜在因子和本地方面级潜在因子,提高了模型预测效果[9]。李淑芝提出一种评论文本和评分矩阵交互(RTRM)的深度模型,取得了较好的推荐效果[10]。邢长征等在推荐模型中加入用户和项目标签信息,通过标签使用次数反映用户喜好和项目特征,结果表明模型能有效提高跨域推荐的准确性[11]。
尽管学者们从不同的角度改进了矩阵分解算法,在一定程度上提高了算法的准确率和召回率,也有学者关注到项目本身的属性信息,但是忽略了将用户的评论标签与矩阵分解结合使用。本文将矩阵分解算法和k-means聚类算法相结合,首先基于用户评论的标签文本构建项目特征画像和用户兴趣画像,利用k-means算法将其聚类,找出最优聚类数,然后利用隐语义模型进行矩阵分解,将用户-评分矩阵进行分解重构并做出推荐,最后在MovieLens数据集上进行实验,验证该算法的综合表现。
2 算法设计(Algorithm design)
针对推荐系统中依赖用户对项目评分信息的数据稀疏性问题,本文提出一种融合标签文本的k-means聚类和矩阵分解的推荐算法。矩阵分解的痛点在于隐含特征值的确定,本文将k-means聚类算法引入矩阵分解,确定隐含特征值。主要的算法流程包括以下两个模块:一是k-means聚类模块。在项目潜在特征提取方面,通过对电影标签文本进行量化处理,采用TF-IDF(Term Frequency-inverse Document Frequency)统计方法构建电影特征画像,利用k-means聚类方法获取电影的簇,即项目的潜在特征;在用户潜在兴趣提取方面,将用户对电影的点评标签作为用户兴趣标签,构建用户的兴趣画像,利用k-means聚类方法获取用户的潜在兴趣。二是矩阵分解模块。根据找到的项目潜在特征或者用户潜在兴趣将用户-评分矩阵进行分解,主要算法流程如图1所示。

图1 算法流程图Fig.1 Algorithm flow chart
2.1 基于k-means的项目潜在特征提取
2.1.1 基于TF-IDF的项目标签文本量化
TF-IDF是一种针对关键词的统计分析方法,用于评估一个词对一个文件集或者一个语料库的重要程度。一个词的重要程度跟它在文章中出现的次数成正比,跟它在语料库出现的次数成反比。
首先构建项目特征画像和用户兴趣画像,为将项目的文本标签转化为计算机可以识别处理的数据结构,然后利用TF-IDF分析提取TOP-n个关键词。TF-IDF计算公式如下:
(1)
(2)
(3)
其中,N表示总的文档数,Ni表示包含关键词的文档数,fij表示关键词在文档中出现的次数,fdj表示文档中的词语总数。通过计算每个项目所有标签词的TF-IDF值,进行对比,取TF-IDF值中最大的n个关键词作为目标文档的特征向量,组成项目的特征画像。
2.1.2 项目标签内容的k-means聚类
根据项目特征画像,将属性特征相似的项目聚在同一簇内,k-means聚类首先选取任意样本点作为聚类初始中心点,对于每个样本点,通过计算欧式距离计算该样本点到每个聚类初始中心点的距离,将其划分至距离最近的簇中。计算样本点到中心点的距离公式如下:
(4)
其中,d(mi,ci)表示样本点mi到聚类中心ci的距离,n表示簇内项目个数。计算每个类别中数据点的平均值,并将得到的平均值作为新的聚类中心,再利用上述公式计算样本点到新的聚类中心的距离,重新划分项目簇;经过若干次迭代之后,如果聚类中心不再变化或者变化很小,则可确最终的聚类簇。
对于聚类效果的评估,选择轮廓系数,其公式如下:
(5)
其中,ai表示样本点i与同一簇中其他点的平均距离,即样本点i与同一簇中其他点的相似度;bi表示样本点i到其他簇中所有点的平均距离,即轮廓系数衡量的是内部距离最小化,外部距离最大化。
利用TF-IDF进行关键词量化后,选择TF-TDF值最大的30个关键词,聚类区间选择2—50,观察聚类效果,如图2所示,当聚类数为25—40时,聚类效果较好,为检验聚类数为25—40的模型评估效果,下面的实验中将k值取25—40,观察不同k值的效果。
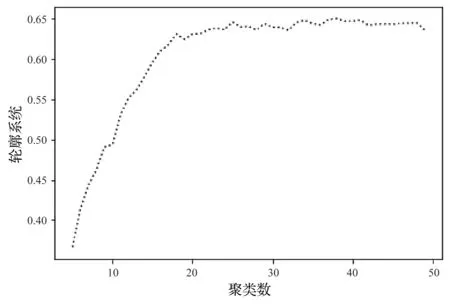
图2 轮廓系数图Fig.2 Diagram of contour coefficient
2.2 基于LFM项目潜在特征矩阵生成
2.2.1 矩阵分解
矩阵分解算法是将用户-项目评分矩阵进行分解,为每一个用户和项目生成一个隐向量,将用户和项目定位到隐向量表示的空间上,如图3所示。将(m×n)维的共现矩阵R分解为(m×k)维的用户矩阵P和(k×n)维的项目矩阵Q相乘的形式,使得Rm×n=Pm×k×Qk×n。其中,m是用户数量,n是项目数量,k是隐向量的维度。k的大小决定了隐向量表达能力的强弱。k的取值越小,隐向量包含的信息越少,模型的泛化程度越高;反之,k的取值越大,隐向量的表达能力越强,但泛化程度相应降低。因此,最终目标是求出用户矩阵P和项目矩阵Q中的每一个值,然后对用户-项目评分矩阵进行预测。

图3 矩阵分解过程图Fig.3 Diagram of matrix decomposition process
基于用户矩阵P和项目矩阵Q,用户u对项目i的预估评分如下:
(6)
其中,Puj是用户u在用户矩阵P中的对应行向量的第j维,Qji是项目i在项目矩阵Q中的对应列向量的第j维,k表示隐向量维度。
2.2.2 随机梯度下降
(7)

损失函数的优化使用随机梯度下降算法,梯度下降的递推公式如下:
(8)
(9)
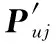
3 实验设计(Experimental design)
3.1 实验数据集描述
本文是以电影推荐为具体场景,构建基于电影潜在特征和用户潜在兴趣的推荐模型。本文采用推荐算法中常用的电影数据集MovieLens中的ml-latest-small数据集,包括用户-电影评分数据集ratings.csv、电影信息数据集movies.csv及电影标签数据集tags.csv。k-means聚类模块使用到电影信息数据集movies,格式包括电影ID、标题、类型;电影标签数据tags.csv包括用户ID、电影ID、用户给电影打的标签、时间戳。矩阵分解模块应用到用户-电影评分数据集ratings。数据集描述如表1所示。

表 1 数据集描述Tab.1 Dataset description
3.2 评估指标
3.2.1 均方根误差(RMSE)和绝对平均误差(MAE)
RMSE是精确度的度量,用于比较特定数据集的不同模型的预测误差,RMSE值越小,说明模型具有更好的精确度。
(10)
(11)
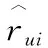
3.2.2 准确率(Precision)和召回率(Recall)
准确率(Precision)和召回率(Recall)的公式如下:
(12)
(13)
其中,TP(True Positive)表示将正类预测为正类;FP(False Positive)表示将负类预测为正类;FN(False Negative)表示将正类预测为负类。
3.3 参数分析
为了得到本文算法的最优参数,首先根据k-means的评估指标轮廓系数选定效果较好的k值为25—40,其余参数的确定进行控制变量实验,测试重要参数对本文算法效果的影响。实验随机选取用户-评分数据集的80%作为训练集,剩余20%作为测试集,为防止每次运行结果不一致,设置随机数种子random_state=1,具体实验过程如下。
3.3.1 不同k值下模型表现
固定学习率是0.005,正则项系数是0.02,设定迭代次数为15—35次,比较不同k值(取值区间为25—40)的效果。图4是ml-latest-small数据集迭代次数在[15,35]范围内,k取不同值对模型效果的影响。由图4(a)可以看出,不同的k值,迭代次数在[15,25]区间,RMSE值呈下降趋势,模型效果变好;在[25,35]区间,RMSE值呈上升趋势,模型效果下降;当k取值为30时,算法的推荐效果最佳。由图4(b)可以看出,迭代次数在[15,25]区间,MAE值呈下降趋势,模型效果变好;在[25,35]区间,MAE值呈上升趋势;k取值为25时,在迭代15次、30次、35次时效果优于k取值为30,但总体而言,k取值为30效果更优,并且在迭代25次时,模型效果最优。因此,根据k-means聚类得出30个聚类时效果最优是成立的,并且此时的最优迭代次数为25次。

(a)不同k值下的RMSE

(b)不同k值下的MAE图4 不同k值下的模型表现Fig.4 Model performance under different k values
3.3.2 不同正则项系数下模型表现
固定迭代次数为25次,k取值为30时,比较不同学习率及不同正则项系数对模型的影响。图5是学习率取值在[0.002,0.04]区间,正则项系数的取值不同对模型效果的影响。由图5(a)可以看出,正则项系数取0.02、学习率在0.005处时,模型效果最优,当学习率大于0.005时,RMSE值呈上升趋势;正则项系数取0.04或0.06、学习率在0.01处时,模型效果达到最优;正则项系数取0.08或0.1、学习率在0.022处时,与其他正则项系数取值相比,模型效果最好。同样,由图5(b)可以看出,正则项系数取0.08或0.1时,模型效果较好。综合考虑认为,正则项系数取0.1、学习率取0.022时,模型效果最优。

(a)不同正则项系数下的RMSE

(b)不同正则项系数下的MAE图5 不同正则项系数下的模型表现Fig.5 Model performance under different regularization coefficient
4 实验结果与分析(Experimental results and analysis)
4.1 比较方法
为了验证本文提出算法的有效性,选取3种推荐算法模型与本文提出算法进行比较。①非负矩阵分解(NMF)基于传统的矩阵分解模型,是一种有效的数据分解方法,将用户-评分矩阵分解为2个非负的小矩阵[12]。②SVD++,在矩阵分解的基础上考虑用户浏览的历史记录,认为用户浏览的历史记录对当前项目的评分有一定的影响,将项目间的关联考虑到模型的评估中[13]。③基于内容的推荐(Baseline)是根据项目本身的标签信息构建项目特征向量,根据项目间的相似性为用户做推荐[14]。
在属性信息层面,非负矩阵分解(NMF)和SVD++两种方法均属于矩阵分解,并且没有考虑项目本身的属性信息,可以在融合标签文本的属性信息层面对本文算法进行有效性验证。在聚类方法层面,基于内容的推荐仅考虑了项目本身的标签属性信息而未引入聚类算法,可以对本文算法引入聚类信息进行有效性验证。
4.2 比较结果
4.2.1 不同模型的RMSE和MAE对比
对比实验选择ml-latest-small数据集,根据控制变量得出的参数结果,选取潜在特征k=30,迭代次数为25,学习率为0.022,正则项系数为0.1。实验结果如表2所示。非负矩阵分解NMF和SVD++都属于矩阵分解,但是没有考虑项目本身的属性信息;而基与内容的推荐(Baseline)仅考虑项目本身的标签信息,根据项目间的相似度推荐,本文模型KLFM采用聚类方法,更好地将属性相似的项目聚类,从而形成项目特征画像和用户兴趣画像,能够更好地为用户做出推荐。由表2可知,本文模型KLFM的RMSE和MAE均表现较好。

表 2 算法性能对比Tab.2 Algorithm performance comparison
4.2.2 不同模型的准确率和召回率对比
本实验采用准确率和召回率对各个推荐算法进行评估,具体结果如图6所示。横轴表示推荐数量,在ml-latest-small数据集上,本文模型KLFM在推荐数量为[5,25]区间上表现优秀,在推荐的准确率和召回率方面都有了较大幅度的提升,较次优算法分别提升了14.5%和20.7%,模型表现较优。

(b)召回率对比结果图6 ml-latest-small数据集上性能对比结果Fig.6 Algorithm performance comparison on ml-latest-small
5 结论(Conclusion)
本文针对推荐系统中用户对项目评分信息的数据稀疏性问题,提出一种融合标签文本的k-means聚类和矩阵分解的推荐算法。该模型首先对项目信息构建项目特征画像,利用k-means聚类找出项目的潜在特征数量;然后根据轮廓系数找出最优的k值,利用隐语义模型LFM进行矩阵分解,将用户-评分矩阵进行分解重构;最后通过实验分析不同参数对模型效果的影响,根据控制变量法找出最优的模型参数。将本文算法KLFM与其他推荐模型算法进行对照实验,得出结论:本文模型的RMSE和MAE表现较好,在ml-latest-small数据集中准确率和召回率上较次优算法分别提升了14.5%和20.7%,有效地改善了推荐算法的效果,可以推广到电商、新闻、社交媒体等其他推荐场景。但是,本文构建项目特征矩阵仅考虑了用户评论标签这一属性,后续研究可以考虑项目的其他属性,能够更好地表征项目潜在特征。
