基于BERT-BiLSTM-CNN模型的新闻文本分类研究
2023-06-10徐建飞吴跃成
徐建飞, 吴跃成
(浙江理工大学机械及其自动控制学院, 浙江 杭州 310018)
1 引言(Introduction)
在数据爆炸的时代,如何将数据中蕴含的价值提取出来,关键的一个步骤就是对获得的数据文本进行分类。新闻文本分类是自然语言处理领域的一个非常经典的任务,目前常用的文本分类技术[1-2]包含三大类:基于规则的算法、传统机器学习算法及深度学习算法。
基于规则的算法主要是利用人工对文本提取特征进行分类,但由于近年来全球大数据储量呈现爆炸式增长,而且分类方式极易受到标注人的主观认识的影响,所以转而利用机器学习的方法对文本数据特征进行自动标注。基于传统的机器学习算法,如朴素贝叶斯算法(Naive Bayes)[3]、支持向量机(Support Vector Machine,SVM)[4]、K邻近法(K-Nearest Neighbors,KNN)[5]等,主要通过手工提取特征输入分类器进行训练,而基于传统机器学习算法的文本表示通常存在高纬度、稀疏、特征信息提取不全等问题。目前,深度学习神经网络模型在文本分类上表现出很好的分类效果,常用的深度学习模型有卷积神经网络(Convolutional Neural Network,CNN)[6]、长短期记忆网络(Long Short-Term Memory,LSTM)[7]、双向长短期记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)[8],但这些单一的传统神经网络模型在文本分类领域的准确率表现不佳。为提高文本分类的准确率,本文提出了一种基于混合神经网络的文本分类模型(BERT-BiLSTM-CNN)对中文新闻文本进行分类。
2 相关研究(Related research)
深度学习的快速发展使基于深度学习的文本分类模型有了很大的提升。2014年,KIM[6]针对CNN的输入层做了一些变换,提出了用于文本分类的卷积神经网络模型TextCNN,该模型的核心是通过不同的卷积核筛选出文本的局部关键信息,但忽略了上下文语义关联性信息。HOCHREITER等[7]针对RNN(循环神经网络)存在训练时梯度衰减、梯度爆炸,以及只能捕获距离当前位置较近的信息等问题,对RNN网络结构进行了改进和优化,通过控制神经元上的门(gate)开关时间捕获序列长距离和短距离的依赖信息,但LSTM只能沿着一个方向扫描,无法捕获未来的或者下文的语义信息。SCHUSTER等[8]为了更加充分地捕获序列的语义信息,继续对LSTM的网络结构进行优化,从而提出了双向的LSTM模型(BiLSTM),BiLSTM可以同时用LSTM向前和向后对整个序列进行扫描。在单标签分类中,不管是传统的RNN,还是经过改良后的LSTM模型,在单独进行文本分类时,准确率表现不佳,因此引用Google发布的基于Transformer(自注意力模型)的双向编码器表征量BERT[9-10]模型对中文新闻文本进行分类。其中,CNN无法有效提取文本上下文依赖,而LSTM只能捕获整个句子的语义信息,而无法捕获文本的局部关键性的特征信息。针对以上问题,本文提出了一种基于混合神经网络的新闻文本分类模型(BERT BiLSTM-RCNN)对中文新闻文本进行分类。
3 BERT-BiLSTM-CNN模型设计(BERT-BiLSTM-CNN model design)
3.1 BERT的基础架构
Google提出的BERT(Bidirectional Encoder Representation from Transformers)模型应用在自然语言处理领域的各种任务中都有着非常突出的表现,归结于BERT网络架构能在词向量(Word Embedding)表示中保留更丰富的语义信息。BERT模型利用Transformer架构的编码器部分构造了一个多层双向的网络架构。BERT模型结构图如图1所示。

图1 BERT模型结构图Fig.1 Structural diagram of BERT model
Transformer模型中的编码端是由6个Encoder组成,解码端是由6个Decoder组成。不仅采用多头自注意机制从多个角度捕获更丰富的语义信息,而且采用了残差网络架构缓解模型梯度消失和爆炸的问题。其中,每一个Encoder的结构都是相同的,都由输入、多头自注意力机制(Multi-Head Self-Attention)及全连接神经网络(Feed Forward Network)构成,如图2所示。
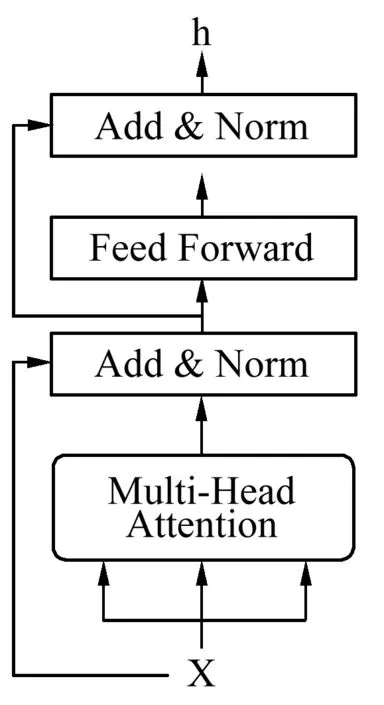
图2 Encoder 模块Fig.2 Encoder block
图3中清楚地展示了“基金上半年业绩排名”这句话的词嵌入过程,Input为中文文本内容,Token Embedding(TE)为字嵌入,Segment Embedding(SE)为段嵌入,Position Embedding(PE)为位置嵌入。三个部分的嵌入向量相加的总和就是BERT编码器的最终输入词向量E。
E=TE+SE+PE
(1)
图3中的BERT输入有2个特殊的标记,[CLS]是文本输入序列的开始标志符,而[SEP]是用于将文本中的句子隔开的标志符,用来区分文本中不同的句子。通过添加“A”或“B”区分句子创建Embedding。词语的语序也非常重要,比如“他欠我100万”和“我欠他100万”,这两句话只是两个字的语序位置不同,但意思天差地别。因此,需要给文本中每个字添加位置编码。图3中,当一个输入序列输入BERT时,它会一直向上移动堆栈。在每一个块中,它会首先通过一个自我注意层再到一个前馈神经网络,之后被传递到下一个编码器,最后每个位置将输出一个大小为隐藏层维数的向量。
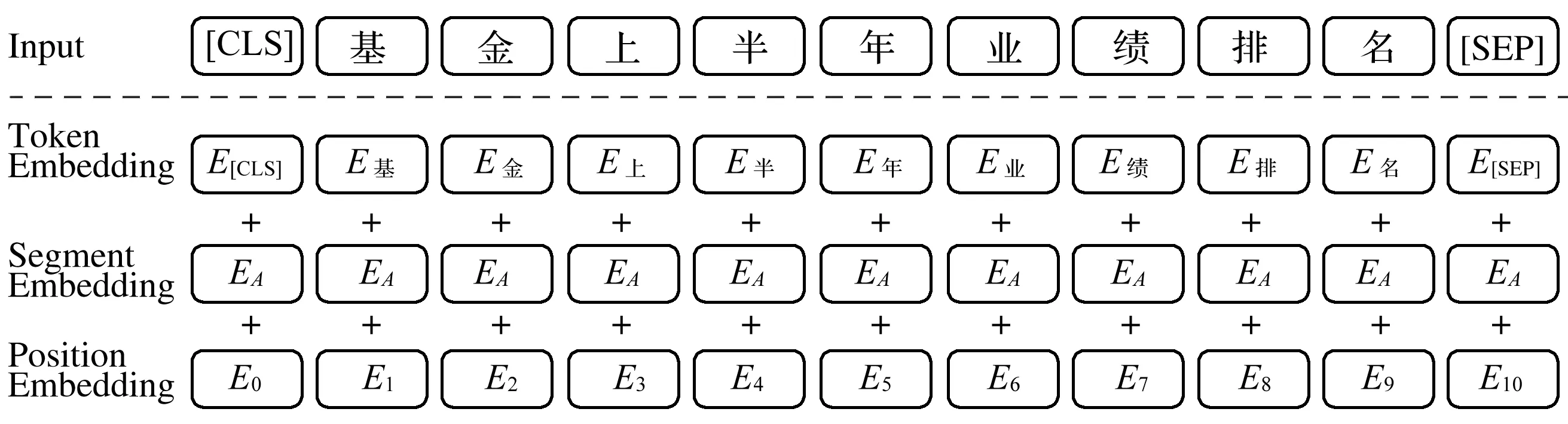
图3 词嵌入过程Fig.3 Token embedding process
3.2 BiLSTM
RNN在处理序列输入数据上效果突出,常用于处理文本数据。该模型考虑了时序因素,通过逐词分析文本,并将先前所有文本的语义存储在固定大小的隐藏层中,能够更好地捕捉上下文信息。由于传统RNN在处理长序列信息时会保留较多的冗余信息和存在梯度消失和爆炸的问题,所以本文采用另一种RNN的改进算法LSTM,它可以利用时间序列对输入进行分析,增加了输入门、遗忘门和输出门,可将短期记忆与长期记忆结合起来控制细胞中信息的增加或丢弃,解决了RNN无法记住距离当前时刻更久的信息和梯度消失的问题。输入门控制的是当前时刻序列的输入,遗忘门控制的是上一时刻序列中存储的历史信息,输出门控制的是当前时间序列的输出,其结构如图4所示。
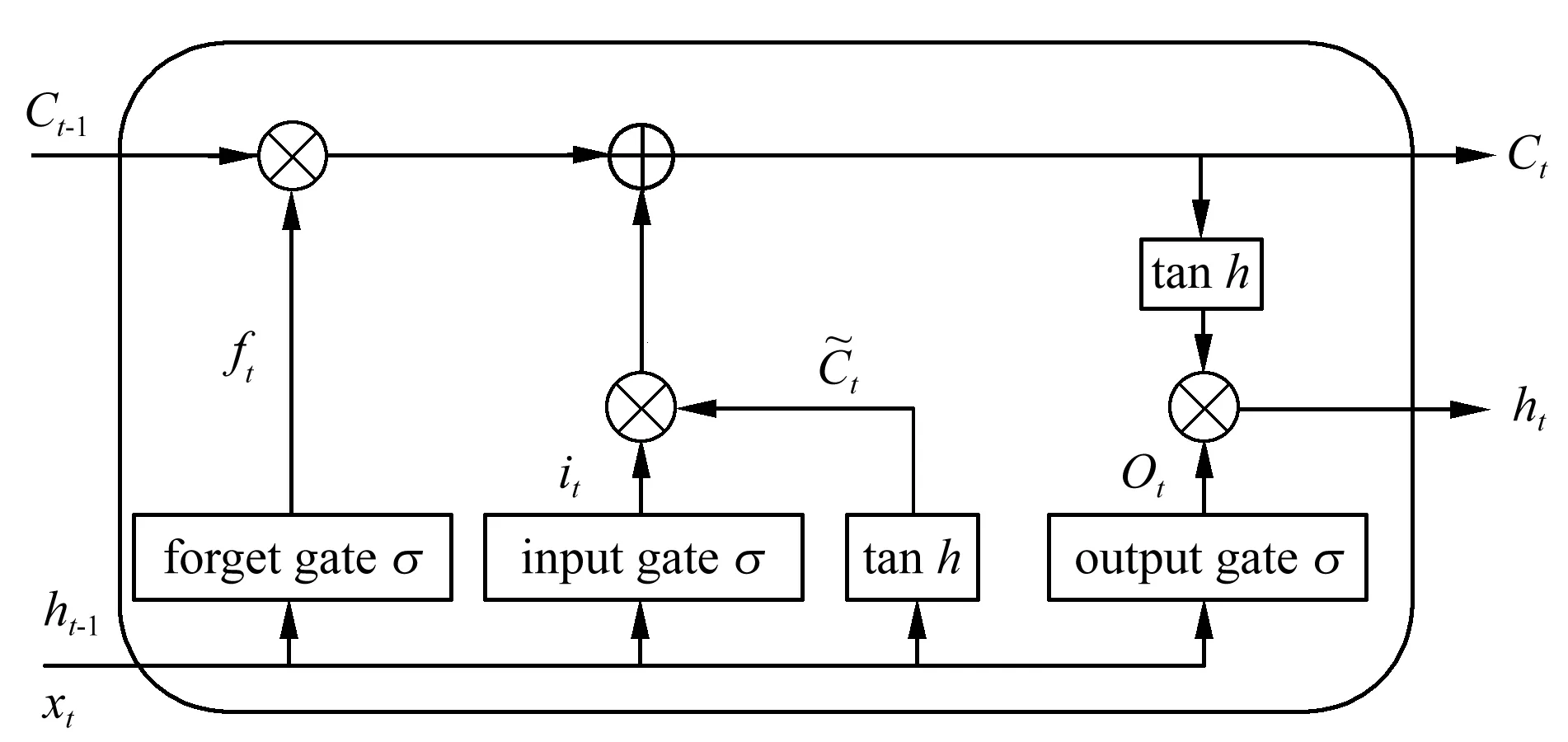
图4 LSTM 模型Fig.4 LSTM model
LSTM模型各个门和状态的计算公式如公式(2)至公式(7)所示:
ft=σ(Wxf·xt+Whf·ht-1+bf)
(2)
it=σ(Wxi·xt+Whi·ht-1+bi)
(3)
Ot=σ(Wxo·xt+Who·ht-1+bo)
(4)
(5)
(6)
ht=Ot*tanh(Ct)
(7)
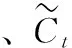
为了使预测结果更加准确,对于当前时刻的输出可能需要若干之前状态的输入和若干未来状态的输入共同决定,因此提出一种双向循环神经网络BiLSTM。该模型整体结构由两个方向相反的LSTM以叠加的方式组成,正向LSTM用来接收从前向后传递的信息状态,反向LSTM用来接收从后向前的信息输入,在同一时刻将两个LSTM的状态输出进行合并,作为BiLSTM当前时刻的输出,从而得到每一时刻的向量特征,弥补LSTM无法访问未来的上下文信息的遗憾;BiLSTM结构如图5所示。

图5 BiLSTM模型Fig.5 BiLSTM model

(8)
(9)
(10)
3.3 TextCNN
提到卷积神经网络(Convolutional Neural Networks,CNN)时,通常会认为CNN属于计算机视觉领域,是用于解决计算机视觉方向问题的模型,而后KIM[6]对CNN的输入层做了一些的变换,提出了用于文本分类的卷积神经网络模型TextCNN。如图6所示,TextCNN网络结构比较简单,由若干个卷积层、max pooling、全连接层和Softmax层构成,该模型的核心思想是使用不同尺寸的卷积核获取文本相邻的N-gram特征表示。首先,在卷积层使用多种尺寸的卷积核提取文本的局部特征,并将得到的特征向量输入池化层,通过下采样方式筛选重要特征信息,降低向量维度,减少计算量。然后,将经过1-max pooling处理后的特征向量拼接起来,再经过全连接层和Softmax函数进行多分类。TextCNN对文本近距离浅层特征的抽取能力较强,并且网络架构简单,可以快速提取文本中的局部特征。
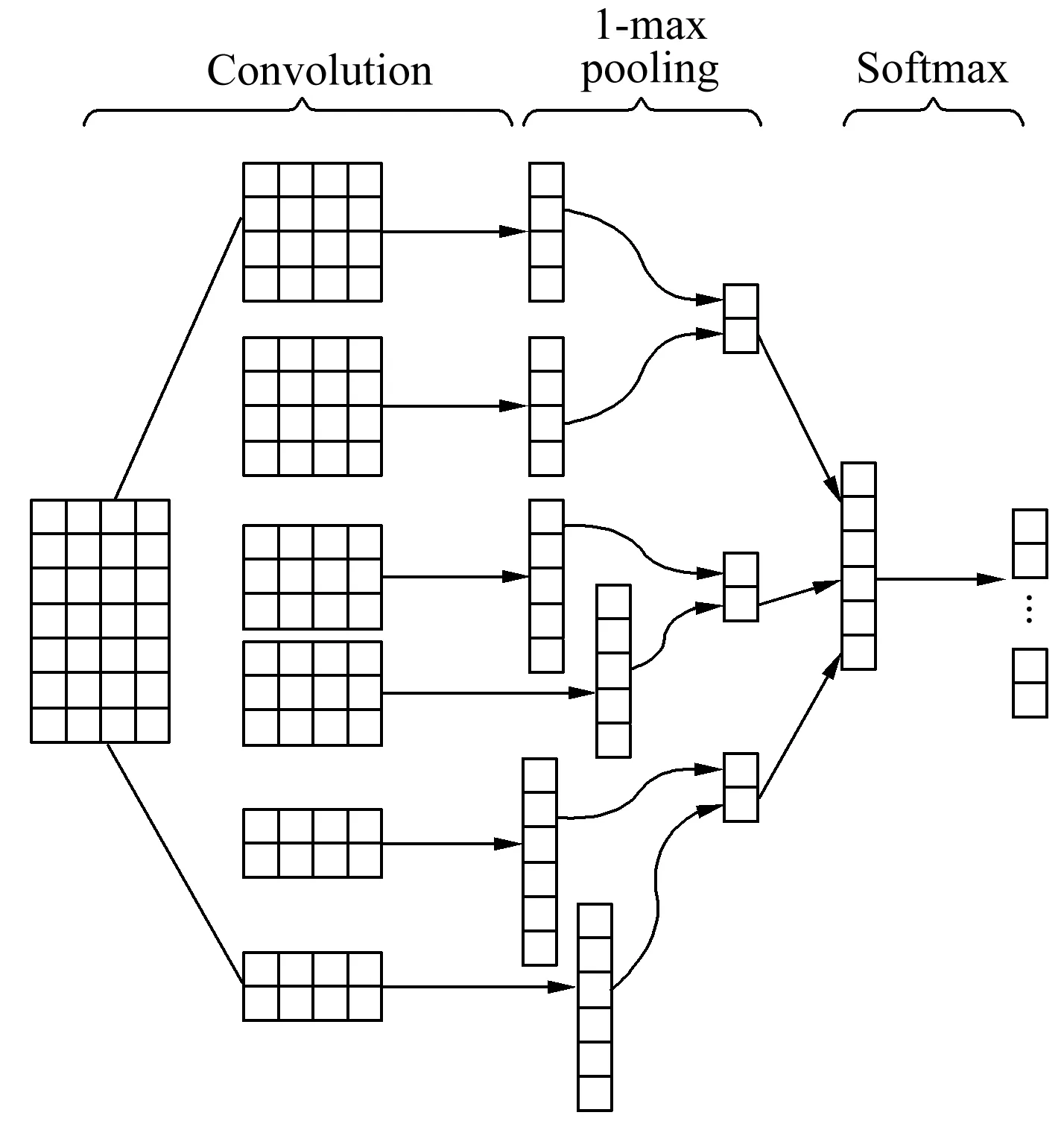
图6 TextCNN模型Fig.6 TextCNN model
3.4 模型总体架构
如图7所示,本文构造了一个基于BERT-BiLSTM-CNN的中文新闻文本分类模型,主要由词向量表示模块和深层文本特征提取分类模块构成。词向量转化模块是一个基于BERT的中文预训练模型,将文本转化为词向量并进行初步特征处理;深层文本特征提取分类模块利用BiLSTM-CNN网络对上下文深层特征和局部关键信息进行提取,最后得到分类结果。

图7 BERT-BiLSTM-CNN模型Fig.7 BERT-BiLSTM-CNN model
BERT-BiLSTM-CNN混合网络结构建立的具体步骤如下。
步骤1:对要进行分类的文本数据集进行预处理,得到输入文本,记为E=(E1,E2,…,Ei,…,En),其中Ei(i=1,2,…,n)表示文本的第i个字。
步骤2:将所有的Ei输入词向量表示模块,经过语言编码器Transformer的编码后,将文本E进行序列特征化,输出文本wi=(w1i,w2i,…,wni),其中wni示文本中第i句中的第n个词的词向量,将w1—wn词向量拼接(w1,w2,…,wn),得到BERT词向量表示矩阵W。
步骤3:首先,将BERT词向量输入深层文本特征提取分类模块,经过双层BiLSTM后,文本词向量表示的语义语法信息的依赖性进一步得到增强;其次,经过2-gram、3-gram和4-gram等多个卷积核的卷积后,进一步提取文本中的关键特征和文本更深层的结构信息;再次,在池化层中对卷积层获得的每个特征图进行1-max pooling的特征映射处理得到统一的特征值,经过全连接层把池化后的特征连接起来,并进行softmax回归分类,生成最终的分类特征向量;最后输出所属的类别。
4 实验与结果(Experiments and results)
4.1 数据集
为了验证模型性能的优劣,本文在公开的新浪新闻文本分类数据集THUCNews上进行了对比实验,它是根据新浪新闻RSS订阅频道2005—2011年的数据中筛选过滤生成的,包含74万篇新闻文档,均为UTF-8的纯文本格式,本次实验使用的语料库包含14个类别,分别为财经、娱乐、房地产、游戏、股票、体育、教育、政治、科技、社会、彩票、家居、时尚和星座,每个类别包含的数据样本不均等,共20万条带类别标签的新闻数据,其中抽取18万条数据作为训练集,1万条作为测试集,1万条作为验证集。
4.2 实验参数设置
模型参数是模型内部的配置变量,不同的参数设置会影响实验结果,本文实验对比模型包括TextCNN、BiLSTM、BERT、BERT-CNN等神经网络模型,超参数设置如表1所示。
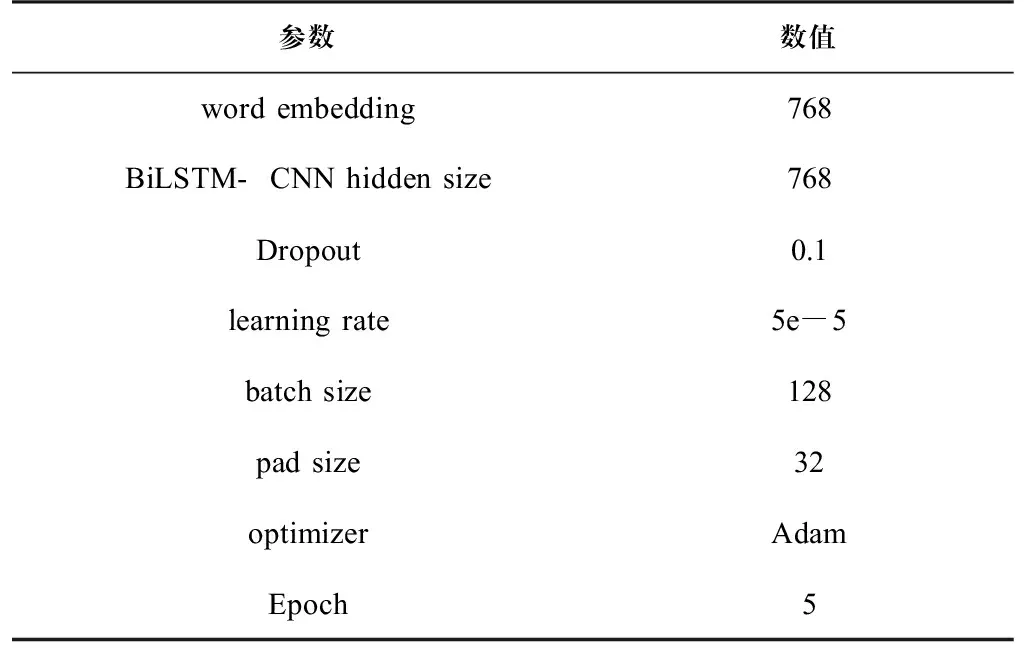
表 1 超参数设置Tab.1 Hyperparameter setting
4.3 实验环境
本次实验环境配置如表2所示,预训练模型使用Hugging Face发布的BERT中文预训练模型。为了避免训练结果产生过拟合现象,本次实验使用提前终止技术(如果每次迭代之后的损失值变化很小,在迭代一定的次数后就不再进行参数的优化)。
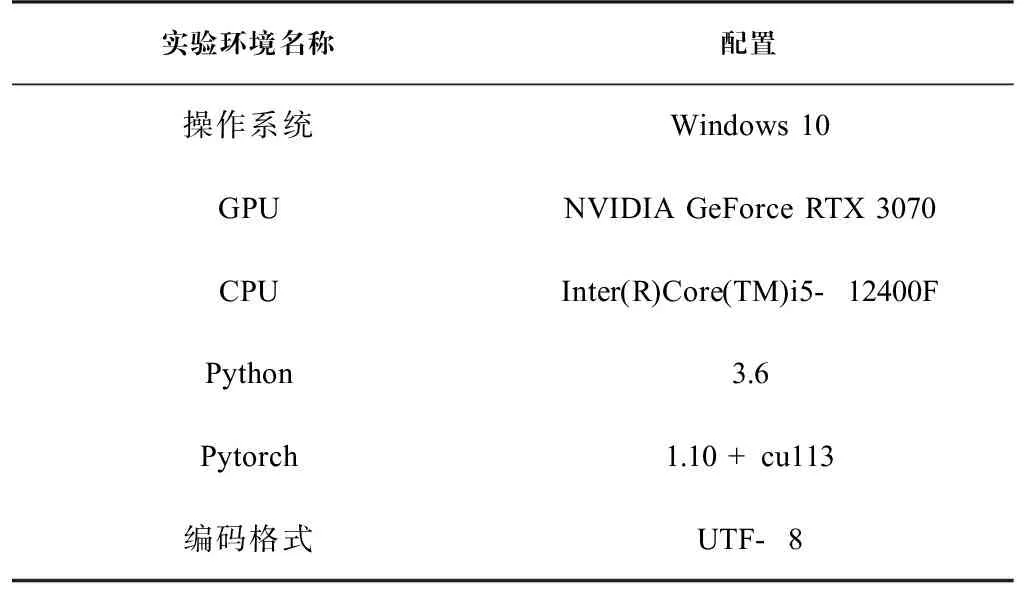
表 2 实验环境Tab.2 Experimental environment
4.4 分类性能评估指标
评价指标是评价数据表现的标准是数据分析中非常重要的部分。对于此类标签文本分类,常用的评价指标是宏精确率(Macro-Precision)、宏召回率(Macro-Recall)和宏F1(Macro-F1),这3个评价指标通过计算得出的结果可以直观地观察模型在文本分类任务中的性能表现,因此本实验采用以上3个评价指标进行分析。其中,宏精确率表示每个类别精确率的算术平均值,如公式(11)所示;宏召回率表示每个类别召回率的算术平均值,如公式(12)所示;宏F1表示每个类别F1值的算术平均值,如公式(13)所示。
(11)
(12)
(13)
4.5 实验结果与分析
各个模型的实验结果如表3所示,对比TextCNN和BERT-CNN模型可以看出,分类的宏精确率和宏F1分数提高了0.73%和0.72%。对比TextRNN和BERT-BiLSTM模型可以看出,分类的宏精确率和宏F1分数提高了0.49%和0.45%。由此可以得出,在融合BERT预训练模型后,能够更好地提取文本中的特征信息,所以引入BERT预训练模型可以提升新闻文本分类的效果。分别对比BERT-BiLSTM-CNN模型与BERT-CNN、BERT-BiLSTM的宏F1分数,分别提高了0.56%和0.78%,而比TextCNN和TextRNN的宏F1分数高了1.28%和1.23%。与其他一般的深度学习模型如表3中的Transformer、BERT等模型相比,本文模型的分类效果都是最优的。这是因为BiLSTM模型可以提取上下文的全部信息,但是无法提取文本的局部信息;而TextCNN模型可以提取文本中的关键信息,但是无法捕获长距离的语义信息。本文构建的BERT-BiLSTM-CNN同时弥补了以上两种模型的缺点,并且实验结果也证明了基于BERT-BiLSTM-CNN模型的新闻文本分类比一般的深度学习分类模型效果好。

表 3 THUCNews数据集实验结果Tab.3 Model experimental results of THUCNews dataset
5 结论(Conclusion)
文本分类是NLP领域一个非常经典的任务,本文将多种深度学习模型融合并应用在新闻文本分类任务上。首先利用预训练模型BERT对文本数据进行高纬度映射,得到嵌入向量,其次通过双层BiLSTM对输入文本的特征信息进行提取,可以获取全局上下文信息,再次经过TextCNN对其中更深层的关键信息提取,最后经过softmax进行文本所属类别的预测。与传统模型相比,BERT-BiLSTM-CNN算法分类的精确率有所提升,得益于本文对词向量转换过程保留了更多的语义语法信息。在未来的研究中,可以通过文本数据增强和外部知识进一步增强文本特征表示、引入更为优秀的词向量预训练模型、引入对比学习和提示学习等方法,进一步提升新闻文本分类的准确度。
