基于ERNIE的新闻标题文本分类
2023-05-30徐云鹏曹晖
徐云鹏 曹晖
关键词:文本分类;EWLTC; ERNIE;注意力机制
中图法分类号:TP391 文献标识码:A
随着时代的发展,文本数据从传统的实体化向数字化、虚拟化方向发展。新闻文本是我们生活中接触最为广泛的一种文本数据,但由于新闻来源渠道复杂多样,需要对其进行准确的分类。
一方面,准确的新闻类别标签可以帮助用户快速地检索感兴趣的新闻;另一方面,根据用户的使用需求进行标签化、类别化推荐,需要将新闻文本存储至不同类别库中。随着信息的爆炸式增长,人工标注数据完成分类任务极为耗时,且易受到标注人主观意识的影响。对于快速实现文本分类的需求日渐增加,自动文本分类技术应运而生。深度学习方法作为该领域的主流研究方向,突破以往机器学习的瓶颈,给文本分类领域带来重大机遇。
ERNIE (Enhanced
Representation
throughKnowledge Integration)是百度发布的预训练模型。它将Google发布的BERT( Bidirectional EncoderRepresentation from Transformers)中单词级别的MASK拓展成3种级别的Knowledge Masking,从而让模型学习到更多语言知识,在多项任务实践效果上超越了BERT。
Jawahar等在2019年分别通过短语语法(Phrasal Syntax)、探测任务(Probing Task)、主谓一致(Subject-Verb Agreement)、组成结构(Compositional Structure)4个实验发现,以BERT为代表的预训练模型编码了丰富的语言学层次信息:表层信息特征在底层网络,句法信息特征在中间层网络,语义信息特征在高层网络。Encoder层越浅,句子向量越能代表低级别语义信息,Encoder层越深,句子向量越能代表更高级别的语义信息。因此,本文EWLTC模型为了获取不同级别的语义信息,提升模型分类效果,将预训练模型ERNIE Encoder层输出的第1个token向量[CLS]通过注意力机制进行加权求和,并作为后续全连接层的输入,增加了语义信息的融入,使得新闻标题文本结果优于ERNIE以及传统的文本分类模型。
1相关工作
文本分类(Text Classification,TC)作为自然语言处理领域的重要研究领域,主要分为浅层学习和深度学习两个发展阶段。浅层学习在1960~2010年占据文本分类模型的主导地位。浅层学习模型主要是基于统计学习的模型,如朴素贝叶斯(Naive Bayes,NB),K近邻(k-Nearest Neighbor,KNN)和支持向量机(Support Vector Machine,SVM)等。尽管与早期基于规则的分类方法相比,浅层学习模型(Shallow Learning)在准确性和稳定性方面具有显著优势,但浅层模型的堆叠层数仅有1~2层,导致模型的表达能力极为有限,并且样本的特征提取极其依赖先验知识进行手动抽取,反复的实验摸索耗费大量的人力物力,极大地限制了浅层模型的效果。
2006年,Hinton提出深度学习(Deep Learning)的概念,使用多隐藏层的人工神经网络来进行样本的特征抽取与学习,克服了浅层学习依赖人工的缺点,由此成为目前自然语言处理的主流研究方法。卷积神经网络(Convolutional Neural Networks,CNN)与递归神经网络(Recurrent Neural Network,RNN)是用于文本分类任务的2种主流深度学习方法,TCNN与RNN模型相较于浅层学习模型,CNN的并行计算效率高,RNN则更注重文本的序列特征,二者都可以显著提高文本分类性能。随后,研究人员将人类视觉注意力机制的原理引入自然语言处理任务中,其基本原理为在众多的输入信息中聚焦于对当前任务更为关键的信息,而降低对其他信息的关注度,甚至过滤掉无关信息,将其与深度学习模型相结合,有效提升了文本分类的计算效率与准确率。
2018年,BERT的出现在自然语言处理领域具有里程碑式的意义,其在多个自然语言处理(Natural Language Processing,NLP)任務中获得了新的SOTA(state-of-the-art)的结果,其强大的模型特征抽取能力使大量研究工作围绕其展开,自然语言处理研究进入大数据时代,ERNIE模型是BERT的众多改进模型之一。
2模型描述
ERNIE总体模型结构和BERT -致,使用的是Transformer Encoder,输入与输出的个数保持一致。相较于BERT,ERNIE的改进主要分为两方面。
(1)采用新的Mask方法。BERT初次提出了MLM方法,以15%的概率用mask token([MASK])随机对每一个训练序列中的token进行替换,然后预测出[MASK]位置原有的单词。BERT是基于字的MASK,ERNIE是基于词语的MASK。假设训练句子为“哈尔滨是黑龙江省的省会城市”,BERT会将哈尔滨随机遮盖为哈“mask”滨,无法学习到哈尔滨是一个重要的地点实体。ERNIE则随机遮挡掉地名实体黑龙江,此模型能够在一定程度上学习到“哈尔滨”与“黑龙江省”的关系,即模型能够学习到更多语义知识。相较于BERT,ERNIE成了一个具有更多知识的预训练模型。
(2)增加预训练任务:通过增加对话预料的训练,判断两句话是否属于同一句话取代BERT原有的NSP(Next Sentence Prediction)任务。
ERNIE由12层编码网络组成,每层的隐藏状态hidden_size为768,并且有12个z注意力头(Attention-Head),总计110 M参数。ERNIE在每一层网络都使用第一个输入符号([CIJS])输出进行表征计算,通过自注意力机制汇聚了所有真实符号的信息表征。
ERNIE的每层输出分别为last_hidden_state,pooler_output, hidden_states, attentions,其中,hidden_states是每层输出的模型隐藏状态加上可选的初始嵌入输出。选取其中12层Encoder层的输出,总计12个元组:12*(batch_size,sequence_length,hidden_size)。但12层cls每层的特征信息对于预测的贡献不同,无法简单相加,为此通过引入注意力机制实现对12个向量的加权求和,在模型训练中自动分配权重给对象的cls向量。最终将求和后的向量输入至全连接层进行预测训练。
3实验结果与分析
3.1实验数据集与评价指标
实验中,采用新闻文本分类中常使用的THUCNews,根据新浪新闻RSS订阅频道2005~2011年的历史数据筛选过滤生成。本次实验选取其中的5万条数据集。本文使用目前通用评价指标来评估模型的优劣,即精确率(Precision)和召回率(Recall)。精确率指正确的正样本个数占分类器判定为正样本的樣本个数的比例,召回率是指分类正确的正样本个数占真正的正样本个数的比例。
3.2实验对比
本文使用五折交叉验证(5-fold cross-validation)来测试EWTLC型的效果,该方法的基本思路是:将所有的数据集平均分为5个部分,依次抽取4个部分当作训练集,剩下1个部分当作测试集进行测试,然后将5轮训练与预测后的结果进行平均,将平均值作为模型最后的估计结果。
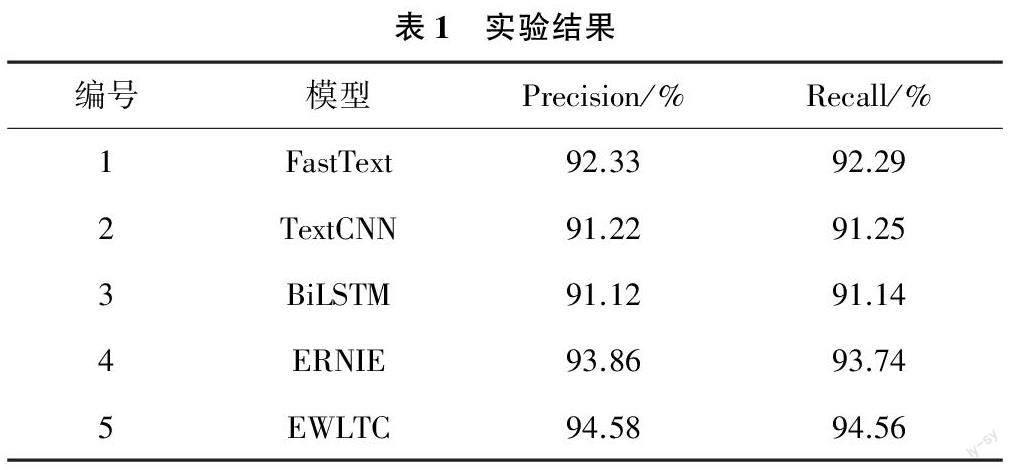
参与对比的网络模型主要包括:(1)FastText模型,采用Facebook AI Research开源的机器学习训练工具FastText对新闻标题进行标签分类;(2)TextCNN模型,采用文本卷积神经网络TextCNN模型对新闻标题进行标签分类;(3)BiLSTM模型,采用双向长短时记忆网络BiLSTM模型对新闻标题进行标签分类:(4)BERT+FP模型,基于BERT预训练模型和全连接层Fully Connected Layers对新闻标题进行标签分类;(5)EWLTC模型,采用EWLTC模型对新闻标题进行标签分类。实验结果如表1所列。
(1)通过对比实验1和实验3结果发现,利用FastText模型相较于BiLSTM模型、TextCNN更为优秀,主要原因是FastText克服word2vec中单词内部形态信息丢失的问题;(2)对比实验4与实验1结果发现,采用预训练模型ERNIE的实验结果是在FastText的基础上大幅度的提升,原因在于预训练模型有助于更好地抽取文本特征,生成文本向量;(3)通过对比实验5结果与实验4结果发现,相较于原本的预训练语言模型只提取最后一层的输出,EWLTC可以学习更多特征、获取更好的分类效果。
4结束语
本文EWLTC模型进一步增强了文本的特征提取与表示能力,实现了更好的文本分类效果。
作者简介:
徐云鹏(1997—),硕士,研究方向:人工智能。
曹晖(1971—),博士,研究方向:人工智能(通信作者)。
