基于相似性迁移的网络流量分类方法
2023-02-21郭晨璐
程 超,郭晨璐
(长春工业大学 计算机科学与工程学院,吉林 长春 130000)
0 引 言
传统的网络流量分类方法有:基于端口、载荷及机器学习的分类方法[1-3]。动态端口技术的出现使得利用端口号进行分类不再适用[4];由于法律条令和信息安全等的限制,大部分应用协议的内容并不公开,基于载荷的分类方法也被限制;机器学习算法的前提是训练数据和测试数据必须满足同一特征空间和条件概率分布,但是在现实中,这种前提条件可能并不满足[5]。
迁移学习并不要求训练样本和测试样本分布一致,利用旧的源域知识帮助目标域的学习,实现知识迁移。将基于样本的迁移学习理论TrAdaBoost[6]应用于网络流量分类面临3个问题:一是源域数据与目标域数据相似度低差异较大时,分类效果不好且可能出现负迁移;二是TrAdaBoost是二分类输出模型,需要改变使其适应网络流量多分类任务;三是多次迭代后源域权重的快速收敛问题。基于此,本文提出一种基于相似性迁移的网络流量分类方法,引入TrAdaBoost模型并进行改进,解决上述问题,实现网络流量多分类。
1 相关工作
1.1 定 义
定义一个大量的有标记的源域DS{xi,yi}(i=1,…,n) 和一个样本量很小没有标记(或者标记数目较少)的目标域DT={xj}(j=n+1,…,n+m),xi表示领域上的第i条数据。这两个领域的整体数据分布P(XS) 和P(XT) 不同。即P(XS)≠P(XT)。 我们的学习任务就是要借助DS的知识,来学习DT的知识,从而提高目标样本的分类准确率。
1.2 分类方法步骤
(1)将最初的源域网络流量数据和目标域流量数据预处理,目标域中极少部分用于接下来的训练,剩下的作为测试数据使用;
(2)用TCA[7](transfer component analysis)提取源域和目标域流量数据之间的相似特征,得到最优特征;
(3)用MMD[8](maximum mean discrepancy)计算源域数据分别与目标域训练数据之间的平均相似度,并以此挑选出相似度较高的流量数据作为分类前的源域训练数据;
(4)将挑选后的源域训练数据和目标域训练数据输入到TrAdaBoost多分类模型中进行训练;
(5)将剩余的目标域测试数据输入到训练模型中,得到预测的目标域网络流量数据的标签。
本文提出的算法设计如图1所示。
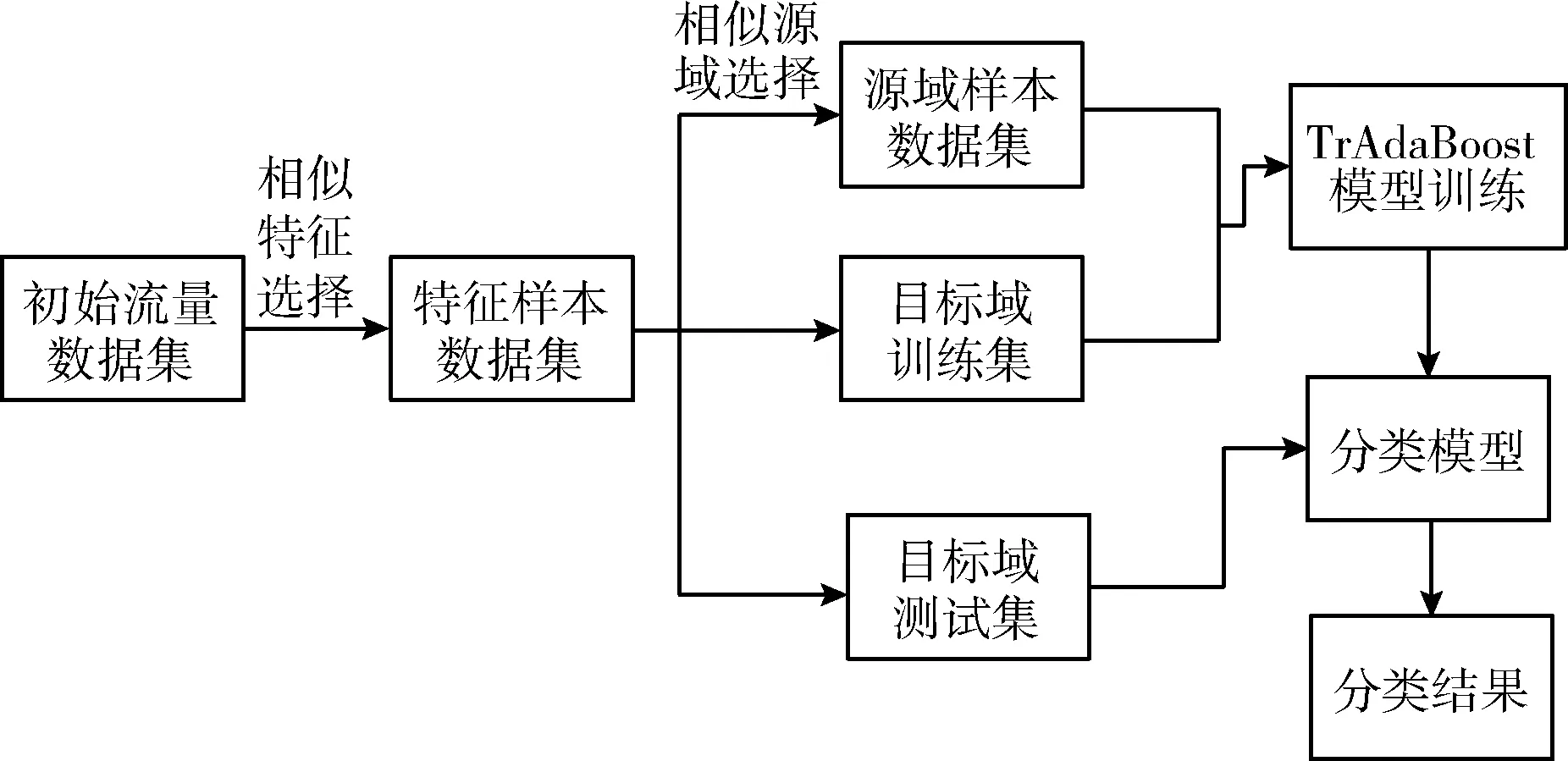
图1 基于相似性迁移的网络流量分类总体设计
1.3 相似度
相似度是指对数据与数据之间或者领域与领域之间进行相似性度量的方法,每个样本或者每条数据是由多个数据特征来进行描述的,数据特征之间的相关性由相关系数度量,样本或者数据之间的相关性由距离方法来表述。相似度可以用不同的距离方法来度量。常见的距离计算方法有K-L散度(Kullback-Leibler divergence)[9]、布雷格曼散度[10]以及最大均值差异。前两种方法需要先估计其概率密度,最大均值差异是用两个领域在希尔伯特空间中的均值差异来近似,计算复杂度低效率高,因此该方法的使用范围最大[11]。本文采用MMD将源域和目标域流量数据映射至核再生希尔伯特空间中,用该空间中两个领域的近似均值的差表示域之间相似值大小,MMD值和相似度呈正比关系。
MMD度量两个领域映射在再生核希尔伯特空间(reproducing kernel Hilbert space,RKHS)上的距离,是一种核计算方法。其表达形式通常如式(1)所示
(1)
其中,x和y是定义在拓扑空间Χ上的随机变量,具有各自的Borel概率度量p和q。
2 算法设计与实现
2.1 相似性特征迁移阶段
(2)

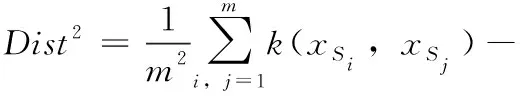
(3)
引入核矩阵K和系数矩阵L
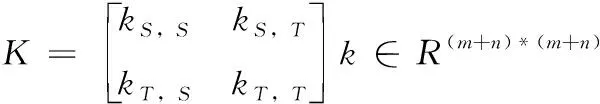
(4)
利用核技巧化简,可将MMD距离化简为tr(KL)-λtr(K),λ≥0, 后者为正则项。TCA实现的目标即为:min[tr(KL)-λtr(K)], 通过映射的核函数将两个样本集的特征嵌入到同一个核空间。在潜在空间(核空间)上投影,核矩阵K分解为
K=(KK-1/2)(K-1/2K)
(5)
引入的矩阵W将核矩阵转换到dim维空间,此时核矩阵可表示为
K=(KK-1/2W)(WK-1/2K)=KWWTK
(6)
其中,W∈R(m+n)*dim,W=K-1/2W。
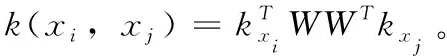
利用核矩阵中的K,源域数据和目标域数据之间的距离可表示为
Dist(XS,XT)=tr((KWWTK)L)=tr(WTKLKW)
(7)
最终得出TCA的优化目标为求解W
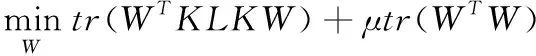
(8)
其中,μ>0是平衡参数,可简写为I,求解式(7)的拉格朗日对偶,对W求导,得到了W的解为 (KLK+μI)-1KHK的前dim个特征向量组成的矩阵,也就是源域XS和目标域XT特征变换后形成的dim维新的数据集。
本文实验分为两组,A组和B组均依据以上过程,基于MATLAB 2016a平台,A组以Moore数据集[13]的entry 01,02,03中的部分数据作为源域训练集,以大约12个月后同一地点的一个数据集entry 12作为目标训练集和目标测试集,B组为8个月后另一地点收集的Day.TCP数据集,以Day1,2,3中的部分数据作为训练集,SiteB中的部分数据作为测试集。对所挑选的数据集作两次TCA转换。首先,移除数据集的标签,做两次TCA转换,第一次以源域训练集和目标域训练集作为输入的矩阵,第二次以目标训练集和目标测试集作为输入。两次均以目标任务作为相似度量,提取目标任务矩阵与其它两个域的相似特征,计算L矩阵和H矩阵,选取的核函数为高斯径向基核函数,dim选择12,计算后的前dim个特征向量组成的矩阵即为新的特征矩阵,也就是降维后的新数据特征。
选取后的最优网络流量特征见表1。
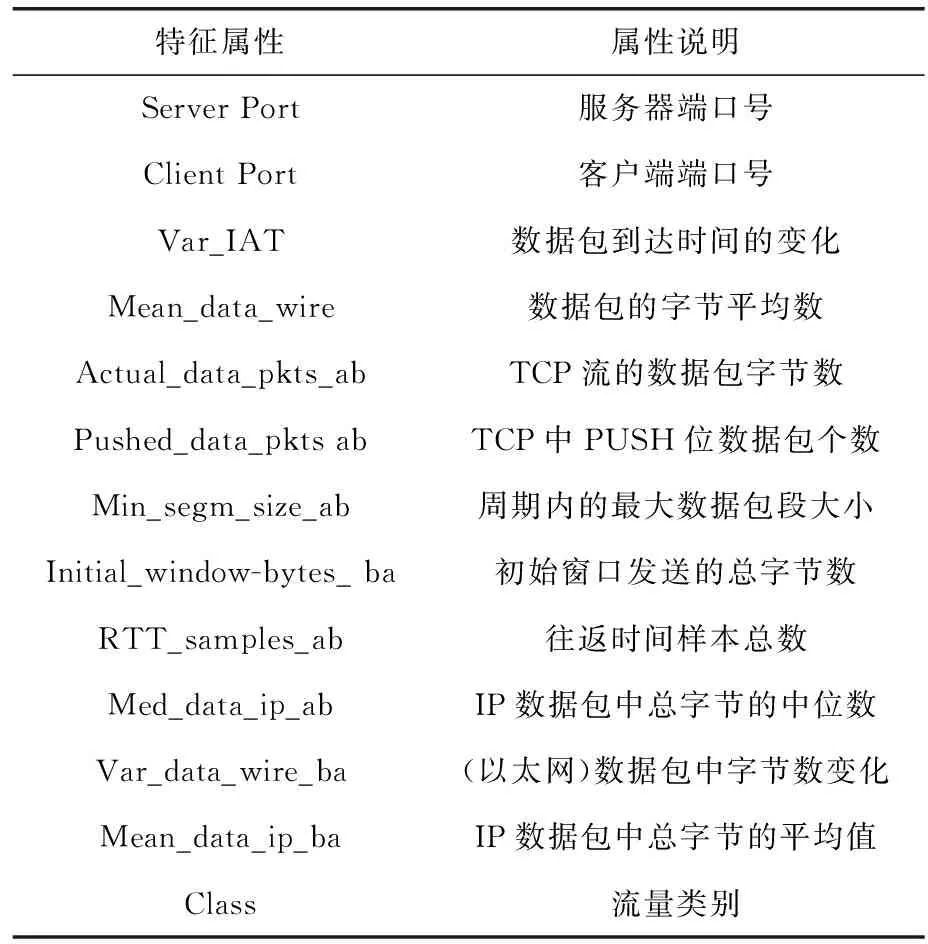
表1 TCA特征选择所得的最优特征子集
2.2 相似性样本迁移阶段
在此次网络流量分类中,源域流量数据集X(x1,…,xm) 和目标域流量数据集Y(y1,…,yn) 分别服从分布p和q,m,n分别是源域和目标域数据集的大小,则两者之间的相似度通过MMD算法表示为
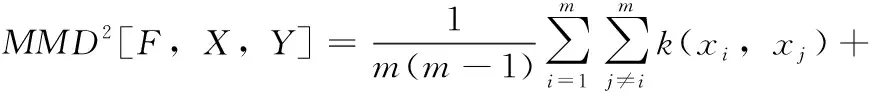
(9)
k是一个核函数,本文中用的是径向基函数(radial basis function,RBF)。将特征选择后的源域数据集样本分别与每一个目标域样本作MMD运算,则第i个源域样本分别与目标域样本的相似值即为
(10)
2.3 改进TrAdaBoost多分类
本节对TrAdaBoost算法做了两个方面的改进:通过权重的调节解决迭代过程中领域之间分布差异较大导致的分类准确率低的问题和由原输出模型产生的多分类目标任务不匹配问题。领域之间分布相差较大同时分配的初始权重不合理是导致分类准确率低的主要原因。因此,对源域数据和目标域数据的权重进行调节使分类器有所选择地分类相似度大的样本,可有效改善这一问题。核心思想是对于每一轮分类正确的源域样本其权重保持不变,分类错误的应降低其权重减轻对目标任务的影响;而对于目标训练样本,分类正确其权重保持不变,分类错误应当加大它的权重,这样下一次迭代时分类器会着重训练这个样本。权重更新表示
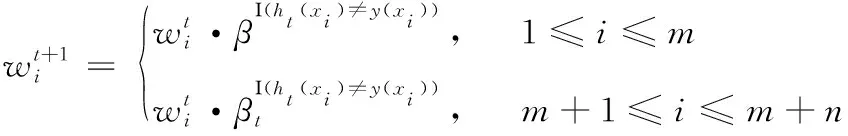
(11)
上述权重更新公式在TrAdaBoost中为二分类输出,y∈{0,1}, 源样本权重更新系数β=1/(1+(2lnm/N)1/2),N为最大迭代次数,目标样本权重更新系数为βt(1-τt)/τt,τt≤0.5是目标样本预测误差,将权重更新机制扩展到多分类中,引进SAMME模型,使用指数型损失函数对其改进
(12)
λt=log(1-τt)/τt+log(K-1) 为多分类的权重更新系数,K为类别总数,为了避免源域权重下降过快,给源域添加一个抑制因子θt=K(1-τt), 保持源域与目标域的整体权重比不变,得到多分类权重调整机制
(13)
理论上,源域中的某个样本与目标域中的某个正确分类样本的权重比可能有很大差异。尽管整个目标域样本和整个源域样本的相对权重比保持不变,但在每次迭代时,源域中正样本的权重调整速率比目标域中正确分类的样本快K倍,多次迭代后,某些对分类任务有益的源域样本的权重很小,目标域和源域样本之间的权重差异性逐渐增大,导致分类准确率低。在实际中,为了避免这种权重转移现象,将抑制因子K(1-τt) 设置为2(1-τt) 减缓源域样本权重的收敛速率,避免负迁移。
将二分类转为多分类时,核心思想为:将第一类看作一类,标签记为1,其它所有的类别看作第二类,标签记为0,这样就得到了一个带标签的矩阵,第二次将第二类看作1,其它所有类看作0,依次进行,直到最后一类。本文从数据集中选择种类最多的4类网络流量,通过4个二分类模型,得到每个类别的4种结果,最终根据投票的方式确定所属类别:分类器i对数据x进行预测,若结果是正类,记结果是:x属于i类,类别i获得一票;若是分类结果为负,则除i以外的每个类别都获得一票,统计票数最多的类别,将是x的类别属性。本文中,使用支持向量机(support vector machine,SVM)作为基础分类器,将算法扩展到多分类场景中。迭代次数设置为50次,综上所述,改进后基于相似性样本迁移学习算法的具体步骤如下所示。
基于相似性样本的网络流量多分类算法
输入:有标记的m个样本的相似源域训练数据集Ta和n个样本的目标训练数据集Tb,无标记的目标测试集S,最大迭代次数N,基础算法Learner。
开始循环t=1,…,T

(3)计算分类器在目标域上的错误率
(4)设置目标域和源域权重更新速率:λt=log(1-τt)/τt+log(K-1),λ=1/(1+(2lnm/N)1/2), 其中,K为类别数量
(5)更新样本权重
循环结束
输出:测试集的标签L
2.4 抑制因子的推导过程
将抑制因子θt=K(1-tt) 添加至源域样本的权重更新机制中,避免源域样本权重收敛过快。令U为第t+1次迭代时正确分类的目标域样本权重之和,V为第t+1次迭代时错误分类的目标域样本权重之和,w1为目标域权重,w2为源域权重,则U、V表示为
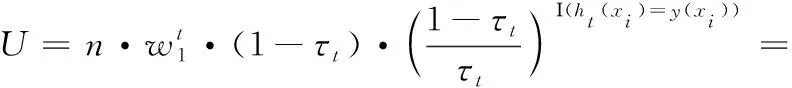
(14)
(15)
t+1次迭代时源域权重更新为
(16)
为了避免源域权重收敛过快,在迭代中引入抑制因子θt,源域样本分类正确则权重保持不变,因此有
(17)
得出抑制因子的值
(18)
3 实验设置和结果分析
3.1 实验设置
实验分为两组,A组数据所用的是剑桥大学Moore等在一天之内不同时间段所收集的流量数据集,包含entry 01-entry 10的10个子集,另有一个子集entry 12是在同一地点的12个月后收集的,数据集中共12类应用,包括:WWW、MAIL、FTP-CONTROL、FTP-PASV、ATTACK、P2P、DATABASE、FTP-DATA、MULTIMEDIA、SERVICES、INTERACTIVE、GAMES[14]。但并不是所有子集都有12种流量类型,因此我们选择了4种常见的流量类型来识别,包括:WWW、MAIL、P2P以及FTP-CONTROL。由于Moore数据集的类别数目很不平衡,我们选用数据子集entry 01,02,03中的部分数据作为训练集,以entry 12作为目标训练集和目标测试集。B组为Moore在8个月后的另一地点收集的Day.TCP数据集,流量类型和A组有较大差别,选择了其中样本类型数目最多的4类来做训练。表2、表3为实验中使用的数据类别和数目。
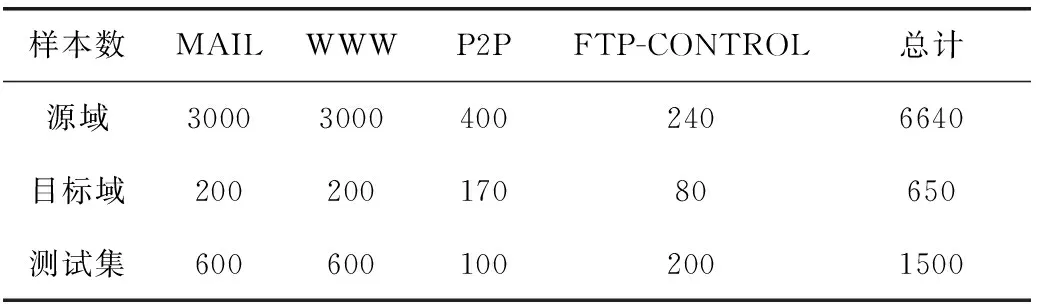
表2 A组实验数据集

表3 B组实验数据集
3.2 结果分析
本节中,将提出的改进算法与迁移学习算法以及传统机器学习算法进行对比来评估算法的有效性。不同算法性能的对比结果见表4。
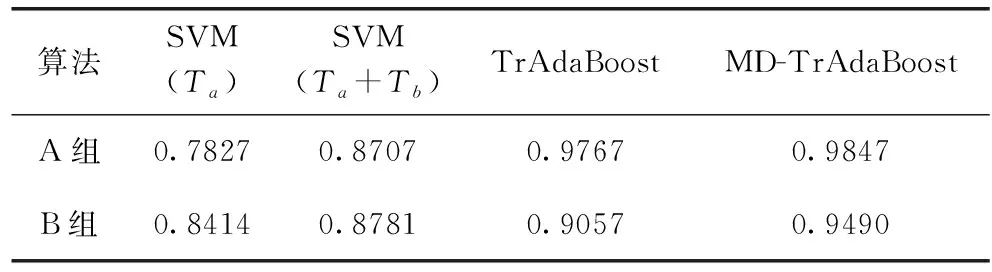
表4 不同算法的分类准确率对比
SVM(Ta):传统的机器学习算法,仅使用源域数据作为训练集进行训练;
SVM(Ta+Tb):传统的机器学习算法,使用合并的源域和目标域作为训练集进行训练分类;
TrAdaBoost(Ta+Tb):初始的迁移学习算法,未进行MMD算法筛选最优相似源域集合,对数据集直接训练进行分类;
MD-TrAdaBoost:改进后的基于相似性迁移的算法,使用合并的源域和目标域作为训练集进行训练分类。
一般来说,网络流量分类算法性能主要通过分类准确性(Accuracy)、准确率(Precision)、召回率(Recall)以及F1测度(F1-score)4个指标来评价,此次多分类结果的混淆矩阵见表5、表6,4种流量类别各自的评价指标如图2、图3所示。
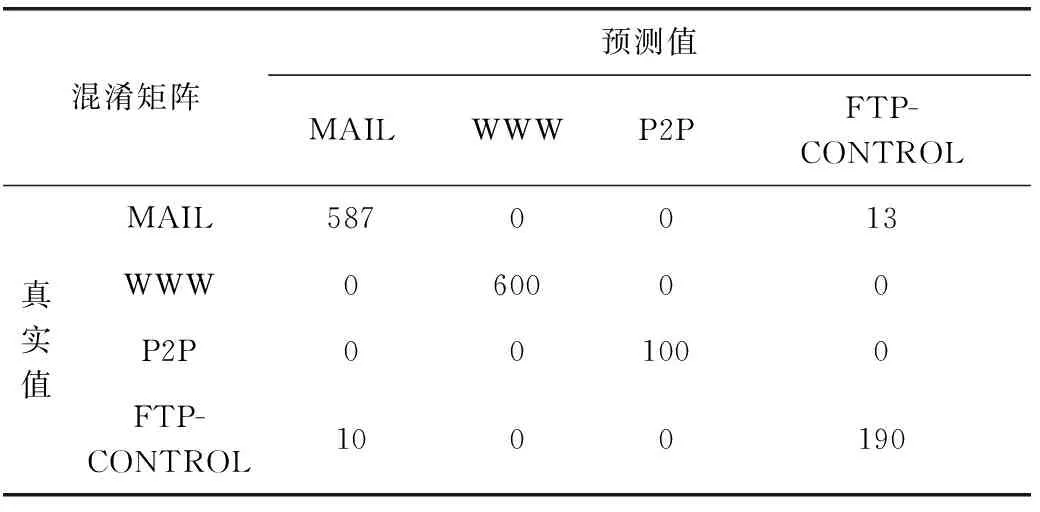
表5 A组多分类混淆矩阵
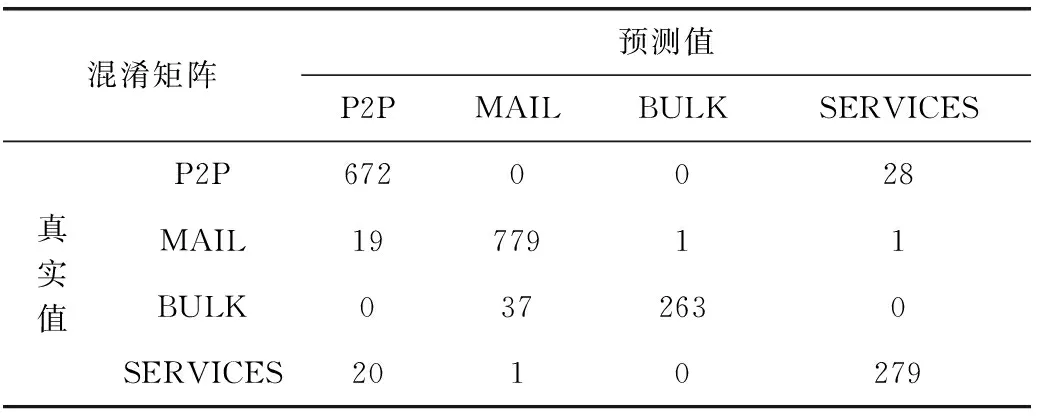
表6 B组多分类混淆矩阵
从表4中可以看出,迁移学习算法性能明显高于传统机器学习算法,本文提出的基于相似性迁移的网络流量分类算法性能明显高于其它,进一步观察表5和表6的混淆矩阵可知,A组中WWW和P2P被全部分对,F1分数和召回率都是100%,说明这两类的特征独特,明显和其它类别有区分,B组并没有完全被分类正确的类别,这4种类别均有被误分类给其它类别。在4种方法中,BULK在分类时误分类给MAIL的数目最多,原因在于BULK的特征和MAIL最为相似,MAIL的数量明显多于BULK,在整体分类时系统会优先考虑数目占比最大的类别。
由图2和图3可知改进后的TrAdaBoost算法类别的各项指标在两组数据中也均为最高,SVM本身为二分类,将其应用到多分类时性能效果不是很好,本文将其应用到迁移学习框架中,利用权重更新机制提高分类准确率,同时从样本和特征两个角度基于相似性的原则对数据进行了改进,提高了可迁移性,对源域数据添加抑制因子能有效减缓源域权重的转移现象,减少了旧源域数据的浪费。
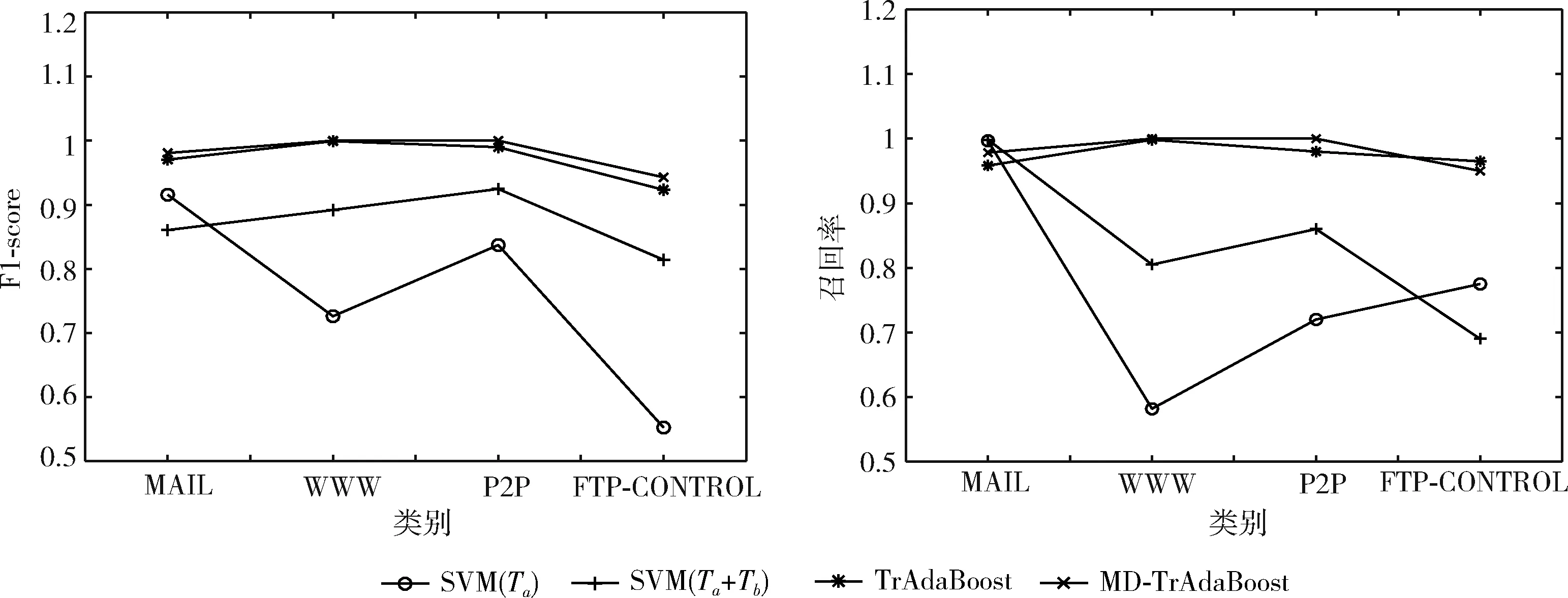
图2 A组网络流量类别的F1测度和召回率对比

图3 B组网络流量类别的F1测度和召回率对比
抑制因子的添加使得算法更好得利用源域知识,减小无关源域样本对整体的影响,分类效果比原始的TrAdaBoost算法好很多,以A组数据为例,经过相似性筛选后的源域样本和目标域样本数目分别为4600和650,源域误差τa设置为0时,根据权重调节机制,当误差为0时,分类正确的源域样本权重保持不变,图4描绘了传统的TrAdaBoost算法权重和本文改进的算法MD-TrAdaBoost权重的比值随迭代次数的增加在不同的目标域分类误差10%到40%下变化的曲线。通过图4的仿真结果,可以看出:①在本文改进的算法中,即使源域样本正确分类,整体源域权重也会收敛;②改进的算法符合源域权重更新机制,分类正确时其权重不变,分类错误时其权重降低;③如果不添加抑制因子,错误率τa越小,则源域权重收敛越快。
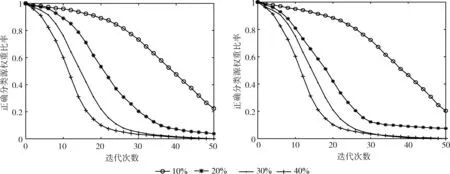
图4 不同误差率下的权重比值结果
4 结束语
本文提出了一种基于相似性迁移的网络流量分类方法,该方法把相似性作为特征和样本筛选的度量标准,减小了领域之间的分布差异,通过将TrAdaBoost算法的权重更新机制进行改进,解决了源域样本权重速率下降过快的问题。实验结果表明,通过该方法对测试数据的标签进行预测,相比其它网络流量分类方法性能更高,提高了可迁移性,避免负迁移。未来考虑引入多个源域,和在线学习算法相结合设计一种更符合网络环境的流量分类方法。
