神威·太湖之光上排列熵算法异构并行加速
2023-02-21梁建国
周 倩,梁建国,傅 游
(山东科技大学 计算机科学与工程学院,山东 青岛 266590)
0 引 言
PE[1]可以用相对简单的形式描述难以量化的复杂系统。与常用的突变检测方法如短时傅里叶变换[2]、奇异值分解[3]、小波分析[4]、希尔伯特变换[5]等相比,对突变信息的识别有较好的效果。目前,PE已被广泛应用于包括设备故障诊断[6]、检测信号异常[7]、脑电图检测[8]、识别生物基因序列[9]、测量气候复杂性[10]和纹理图像分析[11]等领域。
随着应用问题的规模不断扩展,时间序列数据的规模呈指数级增长,对PE计算的时效性要求也越来越高。传统的PE算法应用于单机环境,难以满足海量数据处理的需要,多种基于云平台或超算平台的并行PE算法被先后推出。Yang Peng等[12]结合云计算平台和大数据处理技术,设计了时间序列数据的排列熵特征提取算法,验证了并行排列熵算法的正确性。Cao Jian等[13]提出了一种基于云计算平台MaxCompute的并行排列熵算法,但该方法仅适用于云计算环境。张浩等[14]使用MPI+OpenACC将PE算法移植到“神威·太湖之光”的异构众核处理器SW26010上,并取得了一定的效果,但主从核间存在大量通信,且数据规模小,没有考虑负载均衡的问题。因此,如何对PE算法进行优化以最大程度发挥SW26010性能是一个重要的问题。
本文针对神威·太湖之光特有的众核体系结构,提出一种粗粒度和细粒度下的混合排列熵并行计算方法,在核组间通过MPI实现粗粒度的进程级并行,核组内部利用Athread实现细粒度的从核加速,不仅缩短PE算法的计算耗时,还有效解决其数据规模过大的问题。
1 背 景
1.1 PE算法的概述
PE算法是一种检测震动信号突变的方法,可以描述为:给定一个标量时间序列X,有
X=[x(1),x(2),…,x(n)]
(1)
其中,n为数据点总数。PE算法流程为:输入一维序列X,嵌入维数m和时间延迟τ,通过相空间重构,重构矩阵编码,计算PE值来检测突变信号。
1.1.1 相空间重构
先把标量时间序列X嵌入到m维空间中,重构向量Xi的值如式(2)所示
Xi=[x(i),x(i+τ),…,x(i+(m-1)τ)]
(2)
式中:m为嵌入维数,τ为延迟时间。则标量时间序列X的相空间矩阵Mat可由式(3)表示
(3)
其中,K=n-(m-1)τ。
1.1.2 相空间矩阵编码
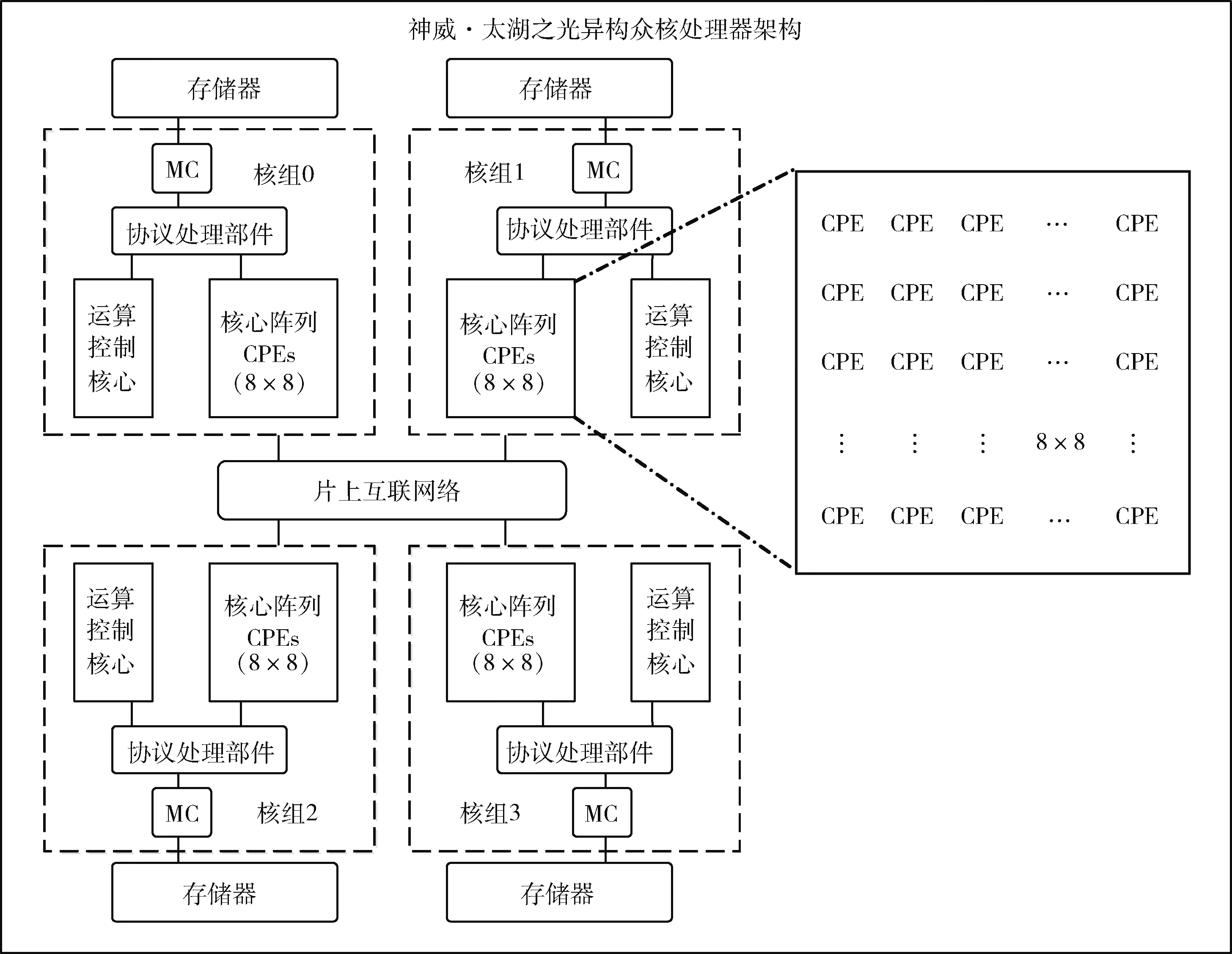
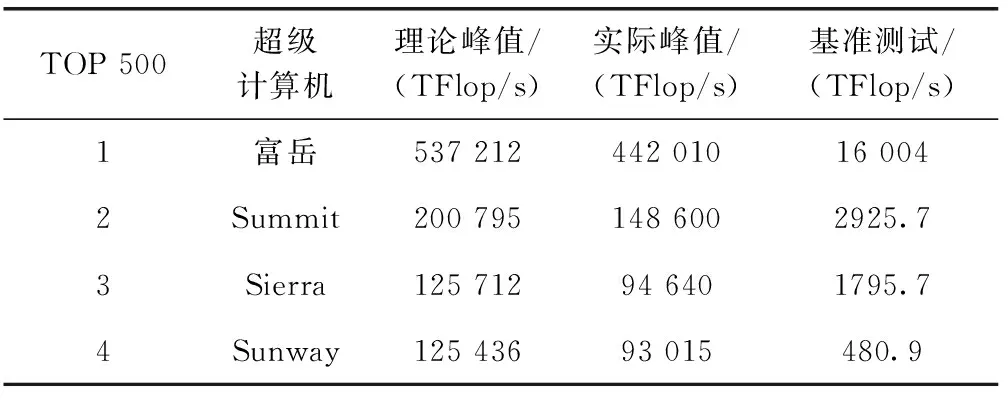
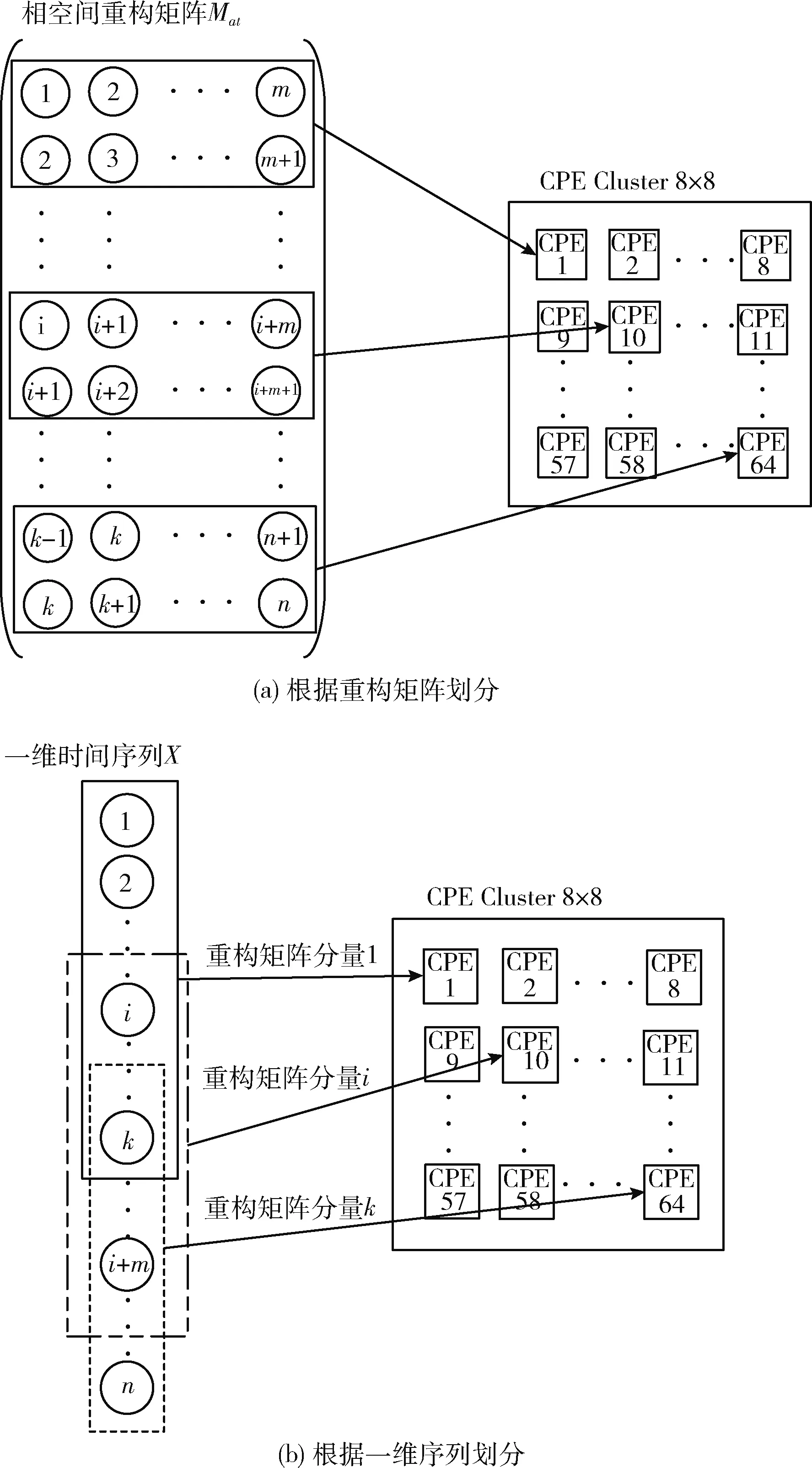
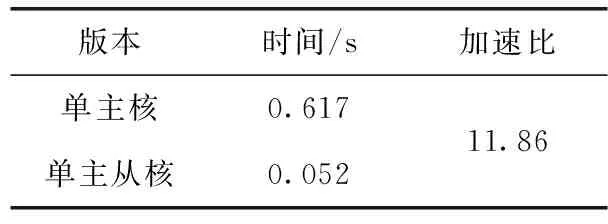
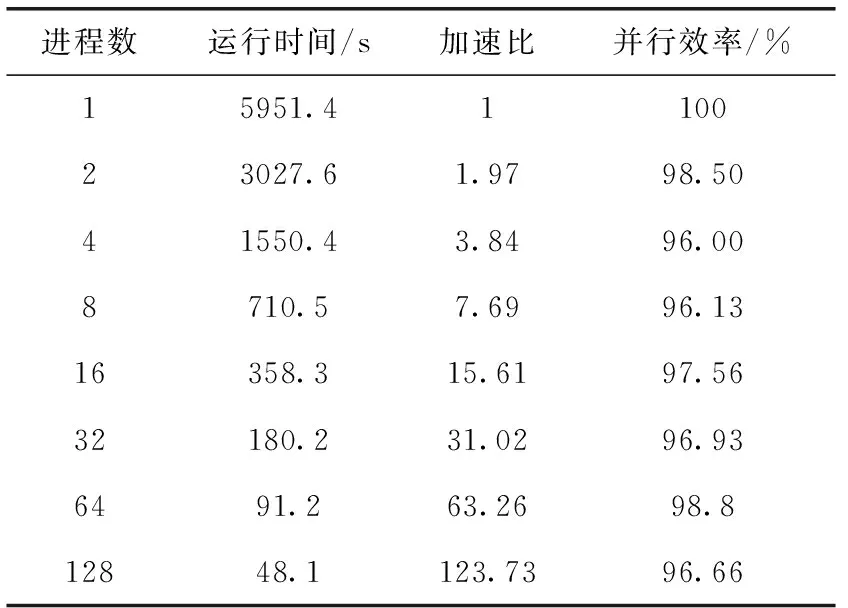
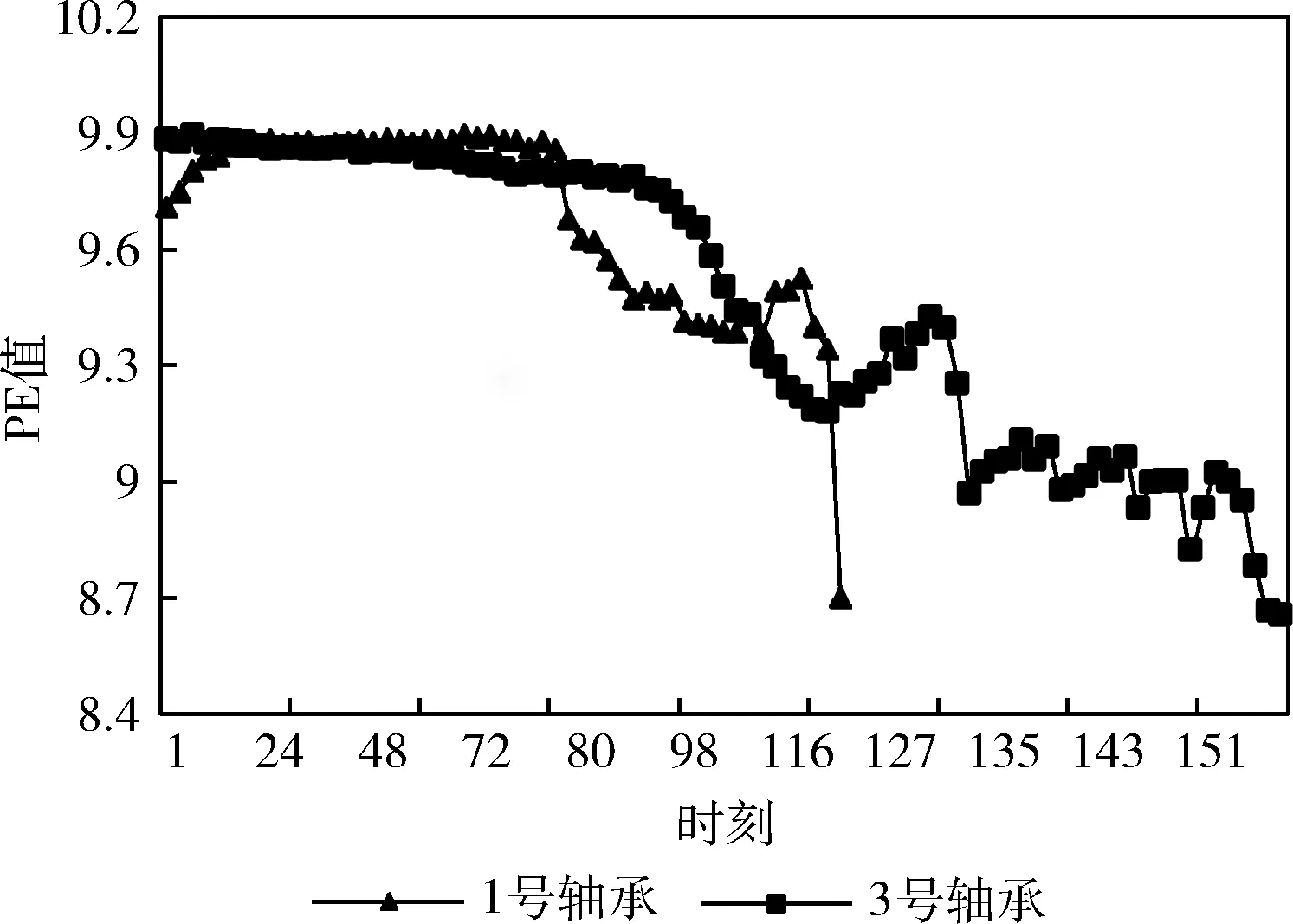
对于给定向量Xi,m个实数Xi升序重新排列: [x(i+(j1-1)τ)≤x(i+(j2-1)τ)≤…≤x(i+(jm-1)τ)]。 当等式出现时,如x(i+(jk1-1)t)=x(i+(j2-1)t), 根据它们对应的j值确定值大小:若jk1 因此,任意向量Xi在相空间矩阵Mat中,都被唯一地映射到一系列符号S(i) 上 S(i)=(j1,j2,…,jm) (4) 其中,i=1,2,…,K,K≤m!。S(i) 是m!个不同符号 (1,2,…,m) 的排列。可以统计时间序列X各种排列出现的次数。 1.1.3 PE计算 假设不同符号的概率分布是P1,P2,…,PK,K≤m!, 然后将时间序列X的PE定义为K个不同符号的香农熵 (5) 当Pj=1/m!, 则Hp(m) 在ln(m!) 时达到最大值。因此,PE值可以判别时间序列信号的随机性。PE值越大,序列信号的随机性越高。排列熵算法的过程如图1所示。 图1 排列熵算法过程 神威·太湖之光由10 240个SW26010异构多核处理器组成,每个处理器中有4个核组(CGs),每个CG由一个管理处理单元(MPE)、一个计算处理单元(CPE)集群、一个DDR3内存控制器(MC)和一个协议处理单元(PPU)组成。每个CPE集群中有64个按8×8网格组织的CPE。SW26010处理器共有260个核,其架构如图2所示。 图2 SW26010处理器架构 根据2020年11月的TOP500[15]数据,“神威·太湖之光”以125 PFlop/s的理论峰值性能位列第4位,与排名前三的超级计算机的性能指标比较如表1。从表1可以看出,“神威·太湖之光”的HPL性能为93 Pflop/s,与Sierra接近;总内存容量与其它超级计算机系统接近;但HPCG仅为480.9 TFlop/s,这是由SW26010的低内存带宽(136.51 GB/s)决定的,也导致每字节浮点数比高达22.42 Flops/byte[16]。以上数据说明,“神威·太湖之光”具有强大的计算能力,但内存带宽相对较低,这对并行应用的移植和优化带来困难和灵活性。 表1 TOP500排名前四的超级计算机系统简要性能对比 Athread加速线程库是针对SW26010所设计的主从加速编程模型,通过对核组内线程的控制与调度来提升多从核的加速性能。Athread库包含主核上用于管理从核线程的库和从核上支持数据传输和同步的库。通过系统调用将从核初始化,此后从核交由Athread库管理,通过库接口将任务的入口函数和参数写入LDM的指定位置,从核从LDM读取任务入口和参数并开始执行。使用单函数多启动的方式来利用从核,常见的从核调用形式如算法1所示。 算法1:在CPE上Athread框架 输入:CPE需要执行的任务集T;划分给每个CPE所需处理的任务TPEC=part(T,thread_id) 输出:每个CPE的计算结果ResultCPE (1)thread_id←ATHREAD-GET-ID; (2)CPE接收任务GET(TPEC); (3)fori∈TPEC DO(i) endfor (4)向MPE发送计算结果PUT(ResultCPE); (5)MPE调用CPE函数ATHREAD-APAWN; (6)在等待期间穿插任务; (7)MPE等待CPE任务结束ATHREAD-JOIN。 由算法1可见,所有从核启动相同的函数,根据从核号从任务集中挑选出各自需要执行的部分,并通过主从核通信接口来进行相应的数据传输。在等待数据传输时,主核也可以执行其它任务。 本节基于SW26010处理器架构,在分析PE程序特征的基础上,提出了PE移植和优化算法。具体工作分为两个层次:在核组间,按文件数量划分任务,采用对等模式,合理调度MPI进程,实现了多文件负载均衡;在核组内,使用Athread库按块划分相空间重构矩阵,对其分量进行排序并记录排序后的索引,使用双缓冲技术减少数据在主从核之间传输的时间,通过重新组织传输数据减少了主从通信次数。采用本节所设计的MPI+athread并行优化方法,解决了PE程序中两级负载不均衡的问题。 2.1.1 数据规模大 本文所使用的数据集是由西安交通大学现代设计及转子轴承系统教育部重点实验室所发布的数据[17],该数据集是以LDK UER204轴承为处理对象,以1 min为间隔,频率为25.6 kHz,分别对3种工况下15个滚动轴承的全寿命周期进行采样。将每次采样获取的32 768个震动信号数据存储在一个独立文件中,所有的滚动轴承全寿命周期采样文件数量和达到9216个,总数据量达到3 T以上。 2.1.2 两级负载不均衡 由于文本数量庞大,负载均衡是需要解决的一个难题。分析数据集可知,每个数据文件相互独立且不存在数据依赖。 核组间采用对等模式构建MPI进程,每个进程独立处理一个滚动轴承全寿命周期所有时刻的数据文件,进程与进程完全独立,不存在通信与调度。但在数据集中不同工况下滚动轴承的全寿命周期各不相同,每个滚动轴承的震动信号数据文件数量差距巨大,最少的有42个,最多有2 538个,导致进程间负载极其不均衡,若不进行处理则会浪费大量计算资源。PE算法的热点是针对相空间重构后的每个分量进行升序排序并计算得到的各分量索引,将热点任务分配给从核执行。 在核组内部,每个csv文件中有32 768个振动信号数据,相空间重组矩阵规模为 [32768-(m-1)τ]×m。 由于SW26010处理器的一个核组中包含64个从核,无法将重构矩阵分量均匀地分配给每个从核,导致了从核计算任务不均匀。 因此在PE算法中存在两级负载不均衡的问题。下面首先解决核组间负载不均衡问题。 为读取3种工况15个轴承的数据文件,利用多个进程实现文件的并行读取,且多个进程相互独立地计算同一种工况下轴承的一个csv振动信号数据文件的熵值,使得进程轮询读取9216个数据文件,直至计算处理完。每个进程相互独立,进程间不存在通信与调度,避免了进程间的通信耗时,实现了负载均衡。具体实现如算法2所示。 算法2:多文件负载均衡 输入:9216个csv文件;进程数comm_sz;进程号rank 输出:重构矩阵ch_ti_series_1D[] (1) 遍历15个滚动轴承文件数据 forfile_num←1 to 15 do (2) 判断当前数据文件属于哪个工况环境 switch(file_num) case1-5:work_condi←“35Hz12kN” case6-10:work_condi←“37.5Hz11kN” case11-15:work_condi←“40Hz10kN” default:error (3) 获取每个进程在每种工况下分配到的csv文件数line←indir[l]/comm_sz; (4) 计算每个进程所需处理的文件编号 file_num=(my_rank+1)+k*comm_sz; (5) 每个进程获取对应csv文件数data_input(); (6) 相空间重构 ch_ti_series_1D[]=re_organization() (7)endfor 在上述基于MPI的并行PE算法基础上,引入神威Athread编程模型,在核组内部从核间进行数据并行,重构矩阵的相关计算由从核来实现,以充分发挥神威异构众核的能力。主核主要负责读取数据、初始化以及进程划分任务、传送数据、汇总索引概率来计算熵值;从核从主核获取所需处理的重构矩阵分量数据后,每个CPE对重构矩阵分量进行升序排序,将所得序列索引传送回主核。针对2.1.2节中所述的核组内负载不均衡的问题,先将重构矩阵按块划分,保证将任务量均匀的分配给每个从核,若不能均分,则由第一个从核处理余下的重构矩阵分量碎片。 算法3:矩阵重构分量排序 输入:待排序数组S;嵌入维数m和重构分量标示d 输出:整数索引_rank[] (1) 从核获取重构矩阵分量 athread_get(PE_MODE, &ch_ti_series_1D[k*m],&a_slave[0],m*8, &get_reply,0,0,0) (2) 判断数据是否正确传输完毕 while(get_reply!=1); (3) 按升序排序重构矩阵分量 (4) 利用下标数组M得到重构分量索引 (5) 将索引rank[]传送回主核 athread_put(PE_MODE,&res, &_rank[k],8,&put_reply,0,0) 2.3节提出的基于Athread加速线程库的PE并行算法,由于数据规模大,通过分析程序热点可知,主核将重构矩阵所需数据传输到从核是最耗时的部分,本小节从减少主从通信次数和采用双缓冲方法两个方面对CPE数据传输部分进行优化。 2.4.1 减少主从通信次数 PE算法核心主要涉及重构矩阵Mat的计算,且矩阵Mat各行之间不存在数据依赖关系,可以直接在原数据结构上进行并行化。图3(a)是上述2.3节中采用基于块划分方法的数据分割图,在主核中将一维线性序列进行相空间重构,在主从核间传输重构矩阵分量,从核获取所需处理的重构矩阵分量后,再进行排序。由于重构矩阵规模大,主从核传输数据产生了很大的耗时。为了减少主从通信次数,提出了将构建重构矩阵分量的任务分散到从核的优化方案,如图3(b)所示。根据PE算法的特点可知,重构矩阵具有一定的规律性,矩阵第i行仅需要一维震动信号序列的第i~i+m号元素。 图3 PE算法athread数据划分 由图3(b)可见,主核不再将重构矩阵分量发送给从核,而是发送构建重构矩阵分量所需的一维震动信号序列,每个从核接收各自所需的序列后再重构成矩阵分量,进行后面的计算工作。这一方法将主核的任务分散至从核,发送的数据量大幅减少,提高了程序性能。 2.4.2 双缓冲机制 在CPE并行区域中,虽然DMA固有特性可以大大降低内存访问的开销,但在PE程序的大规模数据情况下,主从核的内存访问限制了并行效率。为了进一步提高并行效率,采用双缓冲机制,充分发挥DMA固有的异步性能。在主从核传输数据的过程中,有多轮DMA操作,CPE需要使用双内存空间来缓冲MPE和CPE的重构矩阵分量数据,在CPE传输所需数据的过程中进行计算操作,从核间的通信开销小于计算开销,从而实现了计算与访存的重叠,众核加速会达到理想的并行加速效果。 算法4:双缓冲机制 输入:重构矩阵分量ch_ti_series_1D[];轮次d; 输出:写回标志write_back (1)fork←0 to d-1 do (2) 设置当前轮次标记index←mod(k,2)+1 (3) 读入首批数据 put_reply(mod(k+1,2)+1)←1 (4) athread_get(PE_MODE,ch_ti_series_1D [k*m/2],a_slave[0,index],m*8,get_reply,0,0,0) (5) 修改当前轮次标记 index←mod((j-jmin),2)+1 (6) 设置下一轮次标记 next←mod((j-jmin)+1,2)+1 (7) 重构矩阵分量排序 (8) 读入下一轮次所需数据 athread_get(PE_MODE,ch_ti_series_1D[k*m/2+1],a_slave[0,next],m*8,get_reply,0,0,0) (9)endfor (10) 等待最后一轮数据写回 do while(write_back=put_reply(index)) 本节在“神威·太湖之光”上对第2节提出的优化方法进行实验测试。首先给出嵌入维数m和时间延迟τ这两个参数的选取规则。为了评估本文所提出方法的有效性,在单个节点上进行测试,并与串行版本进行比较,得到其运行时间和加速比,再将并行PE算法扩展至多个节点,并进行可扩展性分析,最后通过所得15个滚动轴承全寿命周期的熵值,进行分析。 由排列熵的定义可知,嵌入维数m和时间延迟τ的取值会影响PE值的大小。相空间重构矩阵分量具有m!种序列,若m取值过大,导致索引序列是不重复的,每种序列仅出现一次,以至于PE值固定为同一个值,不能表达震动信号的突变,也就不具有实际意义。Band等[1]在提出排列熵的概念时就建议m取3~7,τ取1。综合其它相关文献[18]的研究可知,在突变信号检测中,τ对熵值的影响较小,而m取6时得到的PE值能够较好地反映滚动轴承振动信号的突变。因此,在实验中取嵌入维数m=6,时间延迟τ=1。 单核组性能评估表2显示了PE串行算法和单核组并行算法的性能比较,并行算法的计算性能远高于串行算法。相比于主核,使用64个从核进行并行计算在理论上能够产生64倍的加速。但实际上,加速比远远小于理论值,仅取得了11.86倍的加速,其原因是: 表2 单主核版本与单主从核版本的运行时间对比 (1)排列熵算法仅将重构矩阵排序进行从核加速,没有考虑数据读取与熵值计算,在处理大规模数据时,读取数据的时间开销也很大; (2)在主进程划分任务时,任务的切分需要时间; (3)从核所需要的计算数据由主核获取,需要时间进行通信,在带宽一定的前提下,传输数据将损耗大量时间; (4)由于CPE存储空间有限,无法同时获取大量数据,部分数据碎片需要直接访问MPE主存来获取,增加了访存时间,无法达到理论加速比。 采用与单核组实现相同的方式,用MPI实现了基于多个SW26010处理器核组的并行程序。首先将多个数据文件均匀地划分到每个SW26010处理器核组上,然后充分利用64个从核,采用加速线程库Athread在处理器核组内并行处理,其核组内处理过程与图3(b)的描述一致。 在基于粗粒度与细粒度的并行排列熵算法中,成倍增加进程数,得到其对应的测试数据,测试结果以单核组串行程序的性能指标为基准,性能对比结果见表3。 由表3数据分析可得,在128进程时,最大加速比达到了123.73倍。且本文设计的PE算法并行效率稳定,其原因是此算法并不存在MPI进程间的通信与调度,各个进程相互独立。因此,随着进程数的增加,不会产生过多的额外开销,并行效率不会降低。 表3 PE算法众核优化测试结果 在分析并行PE算法的强可扩展性时,将MPI进程数成倍扩大至128个,SW26010节点数扩展至32个,其实验结果如图4所示。 图4 PE算法强可扩展性 由图4可见,PE算法的执行时间随着节点数的增加而减少,单核组执行时间为5951.4 s,当MPI进程数达到128时,执行时间为48.1 s,此时加速比最高达到了123.73倍。但是相比于单核组并行版本,PE并行程序的可扩展性并未达到理想的加速状态,仅为理想状态的96.7%。其主要原因在于,虽然进程间并未存在通信与调度,但创建并行域、进程任务切分、核组内数据传输依然花费了时间开销。因此,在实际应用时,需要综合考虑数据规模、嵌入维数和时间延迟的选取规则、平台节点资源情况、合理设置核组数,避免资源的浪费或竞争。 图5是使用本文所设计的PE算法得到的1号和2号滚动轴承的全寿命周期PE值的折线统计图。这两个轴承的失效位置均为外圈,在正常的工作状态下,排列熵值稳定在9.8附近,在经过损坏临界点处,PE值急剧下降,最后降为8.7附近。 图5 滚动轴承全寿命周期PE值折线 滚动轴承在正常状态下的震动信号为随机信号,信号无规则,PE值较为平稳;故障时信号中存在周期性的冲击信号,具有一定的规律性,因此PE值呈现下降趋势。可以看出,本文所设计的PE算法能够很好的反映出滚动轴承的振动信号变化,适用于检测各种领域振动信号的突变,具有很强的通用性。 本文在“神威.太湖之光”平台上提出了一种基于MPI+Athread的PE算法并行加速方法,实现了粗粒度的进程级并行和细粒度的线程级并行,解决了文件数量过多所产生的负载不均衡、数据量庞大所引起的效率低等问题,采用了双缓冲技术减少了主从通信时间,使用DMA通信和重组传输数据降低了主从通信次数,将核心计算任务合理划分到从核,提高了算法的时效性。此外,对本文所提方法进行测试,验证不仅可以在单个节点上实现11.86倍的加速,而且在多个节点上具有良好的可扩展性和并行效率。下一步,将在“神威·太湖之光”异构平台上,针对在大规模应用的并行化过程中普遍存在的问题,提出一种通用的并行模型。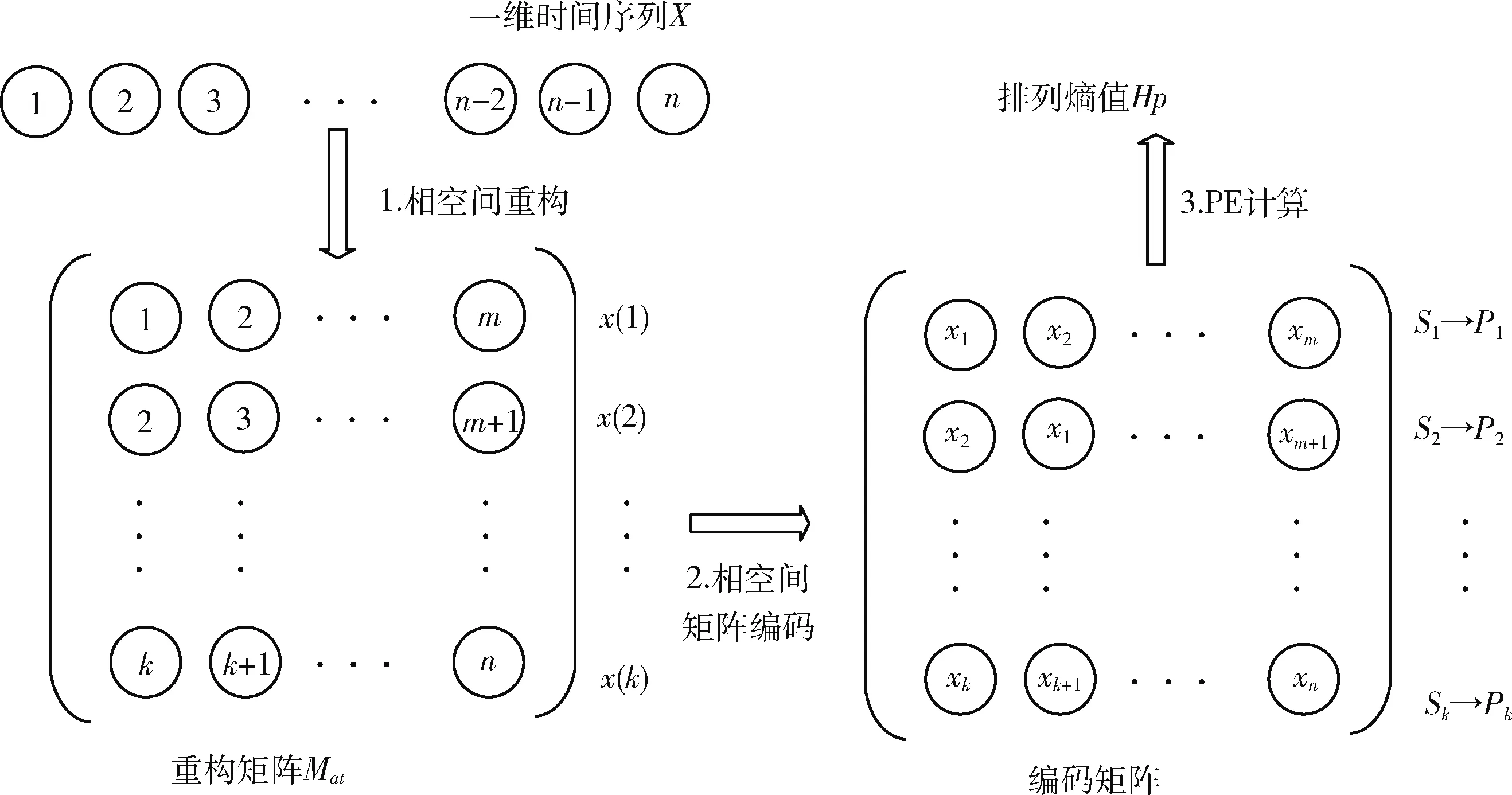
1.2 SW26010多核处理器
1.3 神威Athread加速线程库
2 PE算法并行设计与优化
2.1 PE算法特征分析
2.2 基于MPI多文件负载均衡优化算法
2.3 基于MPI+Athread的并行PE算法
2.4 基于MPI+Athread的并行PE算法优化方法
3 实验及结果分析
3.1 关键参数确定
3.2 多核组性能评估

3.3 PE算法分析
4 结束语
