基于多维度特征融合的云工作流任务执行时间预测方法
2023-01-16李慧芳黄姜杭徐光浩夏元清
李慧芳 黄姜杭 徐光浩 夏元清
云资源的按使用付费模式以及弹性扩展能力,为大规模科学应用的分布式管理与高效执行提供了快速、灵活、可扩展的部署环境[1-3].科学应用的分布式管理与高效执行的关键在于工作流调度,而调度算法的设计、调度性能的优劣以及调度方案的可实施性,直接取决于任务执行时间的估计精度[4-5].
在实际云数据中心环境下,大量、频繁的用户服务请求与响应,使数据中心的运行数据规模呈指数级增长.其中,工作流执行日志数据包含了大量的任务执行时间历史及其相关影响因素数据,并在数据驱动的任务执行时间预测中发挥着重要作用.任务执行时间的影响因素数据,可根据其特征划分为类别型数据和数值型数据.类别型数据与任务和资源的多样性、异构性相关,其数值离散且取值范围广,如任务名称和机器ID 等;数值型数据则与云环境的动态特性相关,其数值连续,且在一定范围内波动,如资源利用率和网络带宽等.在大数据环境下,类别型数据的高维稀疏特性会扩大模型的搜索空间,数值型数据的低维稠密特性会降低部分特征之间的差异性,从而加大了模型寻优和学习的难度,给任务执行时间预测带来了巨大挑战[6].
本文提出了一种基于多维度特征融合(Multidimensional feature fusion,MDFF)的云工作流任务执行时间预测算法.针对类别型数据和数值型数据的特点,设计不同的特征提取方法,分别提取类别型和数值型特征.同时,通过将提取的特征和原始数据特征进行有选择地融合,并采用轻量梯度提升机算法对融合特征进行挖掘与利用,实现云工作流任务执行时间的精准预测.
本文的主要贡献如下:
1)构建具有注意力机制的堆叠残差循环网络,将类别型数据从高维稀疏空间映射到低维稠密空间,通过减小搜索空间,提升模型对类别型数据的解析能力,同时增强模型对类别型特征的关注度,以有效提取类别型特征,提高预测精度.
2)引入极限梯度提升算法,对数值型数据进行离散化编码,通过将过于稠密的数值型数据稀疏化,突出特征之间的差异性,避免模型训练陷入局部最优的可能,提升模型的非线性信息表达能力,有效提取数值型特征,改善预测精度.
3)设计多维异质特征融合策略,将具有注意力机制的堆叠残差循环网络提取的类别型特征、极限梯度提升(Extreme gradient boosting,XGB)模型提取的数值型特征与原始样本数据进行选择性融合,以充分挖掘与利用任务执行时间的多维度特征,学习更全面的任务执行时间知识,降低预测误差.
1 研究现状
传统的云计算任务执行时间估计方法,大多基于微分测量[7]、相似性分析[8-9]以及数学表达式[10-11]等统计学习算法,忽略了云资源的动态变化以及云环境的复杂特性,难以实现任务执行时间的准确估计.随着机器学习的不断发展,数据驱动的执行时间预测方法被广泛应用于各种云应用场景.近年来,研究人员一直在探索如何将各种机器学习算法(如传统机器学习、深度学习与集成学习算法)应用于云计算任务执行时间预测,以从海量、异构、复杂和多维的工作流任务执行数据中挖掘出更有效的信息.
基于传统机器学习的云工作流任务执行时间预测,大多采用多元线性回归、支持向量回归等早期机器学习算法.Nouri 等[12]和Tahvili 等[13]建立了任务执行时间及其影响因素的多元回归模型,实现任务执行时间的估计.可是,多元线性回归模型更适合捕捉线性关系,难以学习工作流任务执行时间及其影响因素之间的非线性关系.Park 等[14]与郑婷婷等[15]利用支持向量回归,进行任务执行时间预测.但是,支持向量回归采用二次规划计算支持向量,导致很大的内存和时间开销,特别是在大数据样本时,其模型训练时间过长.
深度学习具有超强的特征映射能力,能够从海量数据中学习并挖掘数据之间的非线性关系,为数据驱动的任务执行时间预测提供了新思路[16-17].伍章俊等[18]和Nadeem 等[19]采用径向基函数(Radial basis function,RBF)神经网络,构建了云工作流活动执行时间预测模型.但是,RBF 网络是一种单隐含层的前馈网络,难以有效学习序列数据驱动的任务执行时间变化趋势相关的知识,不适用于云环境下的任务执行时间预测.因此,Rehse 等[20]引入循环神经网络(Recurrent neural network,RNN),通过捕捉任务执行时间的变化趋势来进行任务运行时间预测.Zhu 等[21]提出了基于长短时记忆网络(Long short-term memory,LSTM)的预测方法,解决RNN 因梯度爆炸/消失而引起的预测精度降低问题.Bi 等[22]选择Savitzky-Golay 滤波器,滤除原始数据序列的极值点和噪声干扰,并利用LSTM 进行任务执行时间预测.
神经网络(Neural network,NN)强大的非线性拟合能力和大数据学习能力,使基于深度学习的任务执行时间预测效果得到了明显改善,但是,NN固有的层级连接结构和大量神经元计算,不仅使优化超平面变得十分复杂,也大大增加了模型寻优的难度,从而影响预测精度.此外,这些研究工作大多基于单一机器学习算法,即使特征空间包含非常有效的信息,但是单一模型有限的学习能力,很难找到最优解,直接影响预测精度[23].
集成学习可以综合相同/不同模型的学习能力,为云计算任务执行时间预测开辟了新的途径.一些学者将多个单一模型有机结合,通过不同模型的优势互补来增强集成模型的学习能力,并减少预测误差.郑顾平等[24]综合线性、非线性和多项式回归等拟合技术,搭建了基于参数变化的云应用程序执行时间预估模型.类似地,李帅标等[25]将朴素贝叶斯、支持向量回归和LSTM 有机结合,通过Stacking策略进行模型融合,提出了一种业务过程剩余时间预测算法.Nadeem 等[26]通过集成局部学习和进化计算,实现了对e-Science 工作流执行时间的预测.Hilman 等[27]基于LSTM和K 最近邻技术,设计了在线增量学习方法,用于工作流任务运行时间预测.Gao 等[28]采用基于受限玻尔兹曼机(Restricted Boltzmann machine,RBM)堆叠的深度置信网络(Deep belief network,DBN),建立了并发请求云服务响应时间与虚拟机资源之间的映射模型.Pham等[29]提出了基于随机森林(Random forest,RF)的两阶段预测算法,实现对云工作流任务执行时间的估计.实践证明,在大多数情况下,集成方法的预测精度优于单一机器学习算法.因此,本文利用集成学习方法解决大数据驱动的云工作流任务执行时间预测问题.
集成学习在大数据驱动的云计算任务执行时间预测方面取得了一定效果,但它们大多基于仿真数据,且仿真环境难以模拟云环境下资源的动态接入、撤离以及网络的不稳定性.因此,仿真数据给出的离散型或者连续型任务执行时间的影响因素数据,其取值都在一定范围内,使得类别型数据和数值型数据难以区分.也就是说,仿真数据与实际云数据中心环境下的工作流执行日志数据存在很大差异.然而,现有采用仿真数据的集成学习方法往往忽略了这种差异性,在对类别型和数值型数据进行相似处理的基础上,进行云计算任务执行时间预测.现有的集成学习方法存在以下问题:1)对类别型数据的解析能力不足,即类别型数据的高维稀疏特性使搜索空间过大,模型很难找到最优解,从而影响预测精度;2)缺乏足够的非线性表达能力,且模型学习困难、易于陷入局部最优,难以应对数值型数据的低维稠密特性所带来的特征差异性降低问题,影响预测效果;3)直接对提取到的特征进行学习,导致学习效率低甚至学到无效或错误信息,影响预测结果的准确性.
2 相关理论基础
本节介绍本文算法涉及的主要理论基础,即XGB算法[30]和轻量梯度提升机(Light gradient boosting machine,LGBM)算法[31].
2.1 极限梯度提升算法
作为梯度提升机(Gradient boosting machine,GBM)的一种高效实现,XGB 利用梯度提升技术,通过迭代生成残差下降的决策树(即基学习器),将低精度的基学习器组合成一个较高精度的强学习器,并利用正则化和二阶泰勒展开防止过拟合,提高了模型的泛化能力.因此,XGB 模型能获得较好且不同的特征表达,适合处理取值范围固定、数值连续的数值型数据.
数据集D={(Xi,Yi)}含有n个样本和m个特征,其中Xi为第i个样本的输入向量,Yi为Xi对应的输出,Yi∈R,i=1,2,···,n.假设XGB 模型由K棵树集成,其预测函数如下:

式中,l为可导凸函数,表示预测值和真实值Yi的差异. Ω (·) 是正则化惩罚项,用以避免树的结构过于复杂、平滑学习权重并缓解过拟合.
在XGB 模型迭代添加树的过程中,第t次的目标函数可表示为:

2.2 轻量梯度提升机
LGBM 基于单边梯度采样(Gradient-based one-side sampling,GOSS)和互斥特征捆绑技术(Exclusive feature bundling,EFB),能够在不损失预测精度的情况下加速梯度提升过程,提高模型训练效率.因此,相比于XGB 模型,LGBM 模型易于扩展、训练效率高,更适合处理特征维度高、数据量大的数据,满足云工作流任务执行时间预测问题的需求.
作为一种在保证精度的前提下能减少数据量的算法,GOSS 在决策树迭代生成过程中根据梯度绝对值对数据进行排序,选取前a% 个样本,并在剩余的样本数据中随机采样b个样本.在计算信息增益时,通过对采样的小梯度数据乘以系数(1-a)/b,来缓解甚至消除数据分布的影响,使算法更加关注训练不足的实例.在分割点d分割特征j的信息增益的计算如式(7)所示:
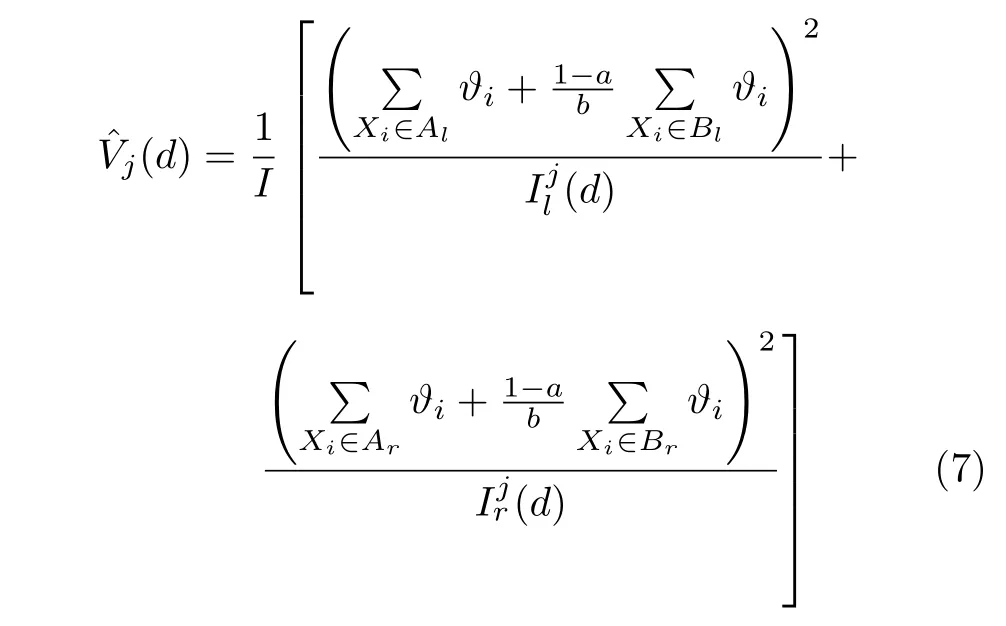
式中,I、(d)和(d) 分别为叶子节点d及其左右两个子节点上的样本个数;Al和Ar分别为d的左、右两个子节点上的大梯度样本集合;Bl和Br分别为d的左、右两个子节点上的小梯度样本集合;ϑi为第i个样本Xi的梯度.
通过将互斥的特征绑定为单一特征,EFB 从捆绑的特征中构建直方图,达到了在不损失精度的情况进行特征降维的目的.首先,EFB 计算并判断特征之间的互斥程度,若两个特征之间的互斥程度之和小于设定的阈值,则绑定它们的特征,减少参与训练的特征数,提高模型训练效率.其中,两个特征是否互斥及其互斥程度,可按式(8)和式(9)进行判断:
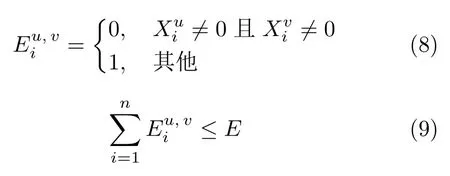
式中,和分别为样本i的第u和第v个特征的数值,E为判断两个特征互斥程度的阈值.
3 基于多维度特征融合的云工作流任务执行时间预测
现有的任务执行时间预测算法缺乏有效的非线性表达能力和高维稀疏数据解析能力,导致任务执行时间预测精度低,难以满足大数据环境下的云工作流任务执行时间预测要求.为此,本文提出了一种基于多维度特征融合的云工作流任务执行时间预测算法.首先,针对类别型数据xCa和数值型数据xNu,设计异质特征提取器,实现对类别型特征和数值型特征的有效提取.其次,有选择地融合原始数据特征和提取到的特征,为预测模型提供更全面、更深层的融合知识.最后,基于融合特征数据构建预测模型,实现对云工作流任务执行时间的精准预测.本文基于多维度特征融合的云工作流任务执行时间预测模型如图1 所示,主要包括特征提取、特征融合和预测3 个部分.
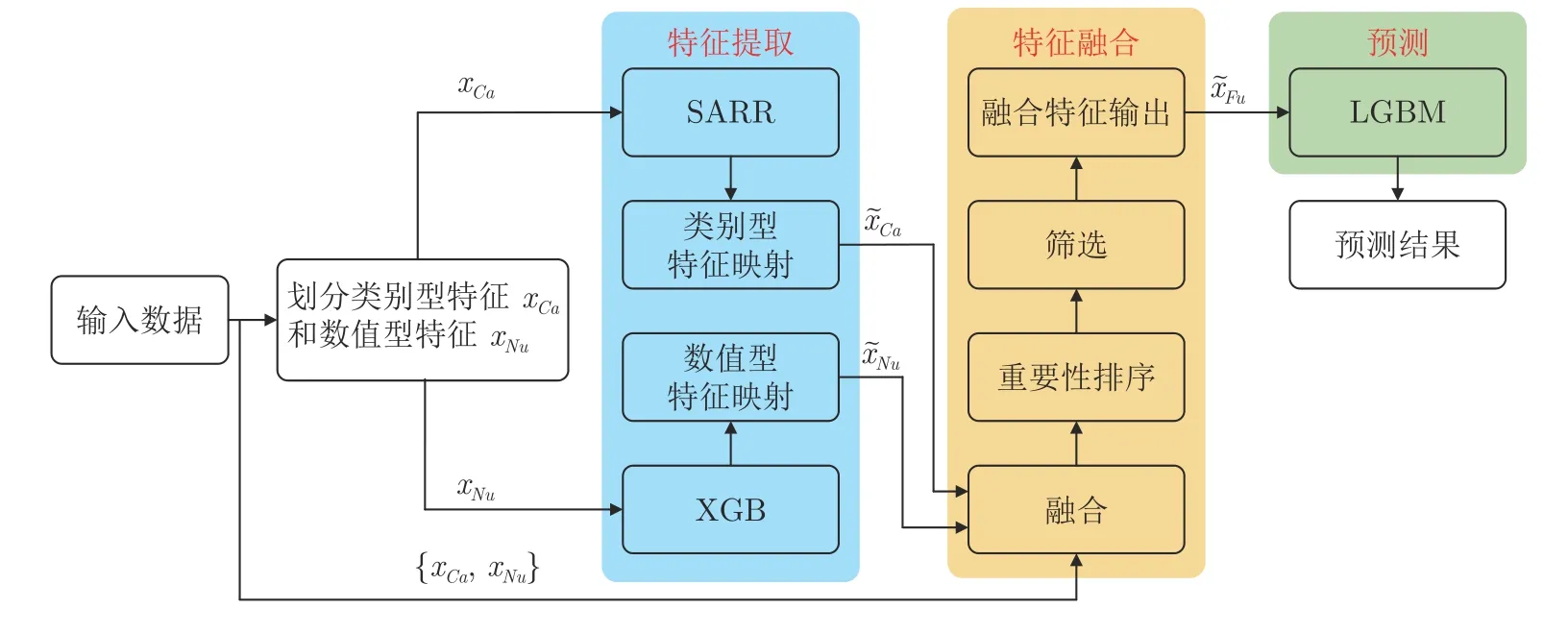
图1 基于多维度特征融合的云工作流任务执行时间预测模型Fig.1 The multi-dimensional feature fusion-based runtime prediction model for cloud workflow tasks
3.1 基于SARR 的类别型特征提取
基于神经网络的预测任务,通常包括特征提取和预测两个步骤.为充分挖掘类别型数据相关的知识,本文MDFF 算法采用具有注意力机制的堆叠残差循环网络(Stacked attention residual recurrent neural network,SARR)提取类别型特征.在RNN 网络的基础上,通过引入注意力机制和添加残差连接,构建堆叠残差循环网络,设计基于SARR的类别型特征提取器.
SARR 包括Embedding 模块、门控循环单元(Gate recurrent unit,GRU)模块和LSTM 模块三个部分,如图2 所示.图2 中,Embedding 模块包含基于RNN 的Embedding 单元;GRU 模块包括GRU 单元、Attention 单元以及残差连接;LSTM模块包含LSTM 单元、Attention 单元以及残差连接.
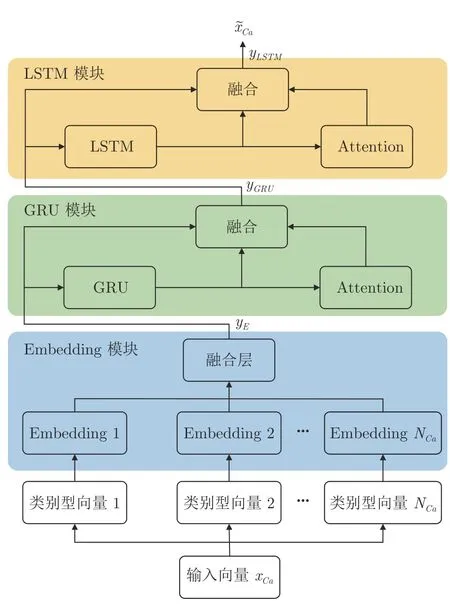
图2 基于SARR 的类别型特征提取器Fig.2 The SARR-based Categorical feature extractor
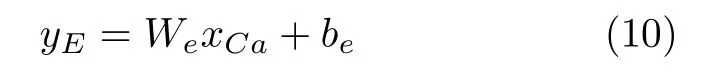

SARR 在不增加网络层数的情况下,解决了梯度消失可能引起的网络退化问题,能够提取与任务执行时间显著相关的特征,并通过为最终的预测器提供更有效的特征,改善预测精度.
3.2 基于XGB 的数值型特征提取
基于梯度提升机的预测方法,通常包括特征提取和预测两个步骤.为充分挖掘数值型数据相关的知识,本文设计了基于XGB 的数值型特征提取器,如图3 所示.其中,从每一个XGB 基学习器的根节点到叶子节点所进行的运算为特征提取过程,从所有基学习器的叶子节点到输出节点的计算属于预测过程.
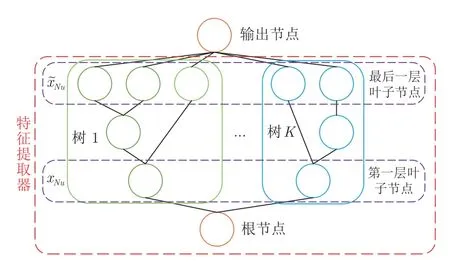
图3 基于XGB 的数值型特征提取器Fig.3 The XGB-based Numerical feature extractor


然后,通过树的结构函数q(·) 寻找每个数值型向量在每棵树的每个分支最深一层中所属叶子的下标,并标记为1,对每个数值型向量进行离散化编码.结构函数q(·) 如式(14)所示:
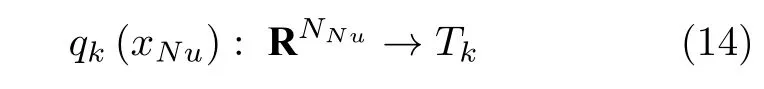
式中,Tk为第k棵树的叶子节点数量.利用XGB对数值型向量进行离散化编码后获得的新向量,即为数值型特征向量
3.3 多维异质特征融合
在提取的类别型特征和数值型特征基础上,本文进一步提出了多维异质特征融合策略,旨在同时收集低维和高维特征信息之间的交互信息,使预测模型学习到更全面且有效的任务执行时间知识,降低预测误差.
本文提出的多维异质特征融合策略,包含特征拼接、特征重要性计算、特征排序和筛选几个步骤.首先,将SARR 与XGB 模型提取到的特征向量与原始输入向量进行拼接,得到一个式(15)所示的新输入向量xfu1,且xfu1∈R1×(NCa+NNu+NSARR+NXGB):
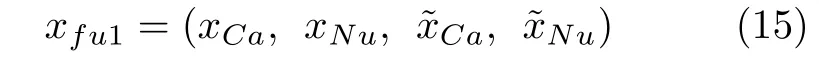
然后,利用xfu1训练LGBM 模型,用于计算不同特征的重要性,并按重要性对特征进行排序:
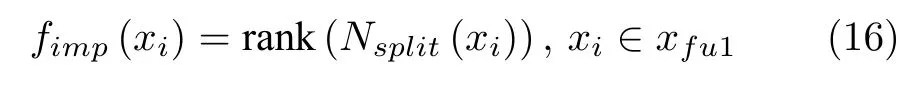
式中,xi为拼接向量xfu1中的第i维特征,fimp(·)为特征重要性计算与排序函数,Nsplit(xi) 为整个特征重要性排序模型生成过程中xi被选取为分裂节点的次数.最后,从排序表中筛选出更具判别力的特征,构成用于任务执行时间预测的多维度融合输入特征向量
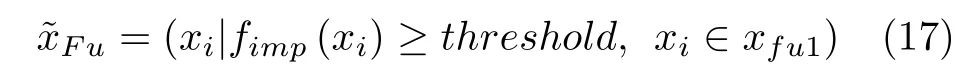
式中,threshold为特征筛选阈值,且xi被选为分裂点的次数越多,说明xi对预测结果的贡献越大.
3.4 云工作流任务执行时间预测
在获得多维异质融合特征的基础上,本文采用LGBM 模型对多维异质特征进行充分挖掘与利用,以精准地预测任务执行时间,为大数据环境下的云工作流调度提供决策支持.
本文基于多维度特征融合的云工作流任务执行时间预测方法,包括3 个部分:1)针对类别型数据和数值型数据,设计不同的特征提取方法,分别提取类别型和数值型特征;2)将提取到的特征数据与原始数据进行选择性融合,为预测模型提供更全面的特征输入;3)构建基于融合特征的预测模型,获得云工作流任务执行时间预测结果.整体流程如下:
步骤1.输入云工作流任务执行时间数据集D={(Xi,Yi)},其中,Xi为第i个样本的任务执行时间影响因素向量;Yi为第i个样本的任务执行时间.
步骤2.将一个输入数据向量Xi划分为类别型数据向量xCa和数值型数据向量xNu,即Xi={xCa,xNu}.
步骤3.利用类别型数据向量xCa,训练SARR模型,不断调整参数,直至获得误差最小的SARR 模型.
步骤4.对训练好的SARR 模型,去掉其输出层以及输出层的所有连接参数,得到类别型特征提取器,并对xCa进行特征提取,获得类别型特征向量.
步骤5.利用数值型数据向量xNu,训练XGB模型,并对xNu进行特征提取,获得初始数值型特征向量
步骤6.利用类别型特征向量和初始数值型特征向量训练LGBM 评判模型.
步骤7.调整XGB 模型参数,重复步骤5~6,直至LGBM 评判模型的误差稳定在一定范围内,且波动不超过5%;挑选出使LGBM 评判模型误差最小的XGB 模型参数,并基于该组参数训练XGB模型.
步骤8.对训练好的XGB 模型,去掉其输出层以及输出层的所有连接参数,获得数值型特征提取器,并对xNu进行特征提取,获得最终数值型特征向量
步骤9.构建多维异质特征融合器,将类别型数据向量xCa、数值型数据向量xNu、类别型特征向量和数值型特征向量进行融合,获得融合后的特征向量
步骤10.基于融合特征向量利用网格寻优算法训练LGBM 预测模型,直至获得误差最小的LGBM 模型,并将其作为预测器.
步骤11.取出类别型特征提取器、数值型特征提取器、多维异质特征融合器和预测器,构建基于多维度特征融合的云工作流任务执行时间预测模型.
步骤12.输出云工作流任务执行时间预测模型.
4 实验结果与分析
为了验证所提出的基于多维度特征融合的云工作流任务执行时间预测模型的有效性,本文选择2018 年阿里巴巴集群数据集行进行仿真实验,通过在不同指标下与6 种基线预测方法进行对比说明本文方法的优越性.
4.1 实验配置
4.1.1 数据集
本文实验数据来源于阿里巴巴2018 年集群运行日志数据集Cluster-trace-v2018[32].Cluster-tracev2018 记录了阿里巴巴某个生产集群中约4 000 台服务器8 天的运行详细日志,具体可查阅https://github.com/alibaba/clusterdata/blob/master/Clu ster-trace-v2018.
在进行云工作流任务执行时间预测前,本文对Cluster-trace-v2018 数据集进行了预处理.首先,分析Cluster-trace-v2018 数据集,寻找任务执行时间相关的关键属性,并根据这些关键属性匹配不同数据表中的数据,获得包含任务执行时间和相关影响因素的数据集.其次,对该数据集存在的异常值和缺失值进行处理,获得包含22 155 组云工作流任务的执行时间及其对应的所有影响因素数据,即最终可用于检验算法的云工作流任务执行时间数据集.最后,在获取的数据集上随机抽取17 724 组数据构成训练集,将剩余的4 431 组数据作为测试集.
4.1.2 对比算法
为了验证MDFF 的有效性和优越性,本文选取了六种对比算法,包括深度兴趣网络(Deep interest network,DIN)[33]、深度交叉网络(Deep &cross network,DCN)[34]、深度因子分解机(Deep factorization machine,DeepFM)[35]、宽度与深度模型(Wide &Deep,W&D)[36]、两阶段预测方法(Two stage approach,TSA)[37]和梯度提升树与线性回归的结合方法(Gradient boosting decision tree+linear regression,GBDT+LR)[38].其中,DIN和DCN 侧重于类别型数据的处理,其数值型特征提取能力弱;TSA 以及GBDT+LR 偏向于数值型数据的处理,类别型特征的提取能力弱;Deep-FM和W&D 能同时提取类别型特征和数值型特征.所有方法采用的参数组合均为使预测效果最好的参数组合,其具体模型结构或参数设置如下:
在DIN 中,嵌入单元1和2 的维度分别为82和80,Dense 单元的神经元个数为16,隐含神经元个数为32,激活函数为Relu,输出层神经元个数为1,激活函数为Relu;最大迭代次数为500,批量大小为100,优化器为Adam.
DCN 的嵌入维度为8,网络的随机失活(Dropout)比例均为0.5,隐含层的神经元个数为64-64,领域维度设为原始特征维度,交叉宽度设为领域维度与嵌入维度的乘积;最大迭代次数为450,批量大小为100,批量标准化因子为1,批量标准化衰减因子为0.95,学习率为0.01,L2正则化系数为0.01,优化器为Adam.
DeepFM 的嵌入维度为80,其因子分解机和网络的随机失活(Dropout)比例分别为1和0.5,网络部分的神经元个数为32-32,激活函数为Relu;最大迭代次数为500,批量大小为100,批量标准化因子为1,批量标准化衰减因子为0.995,学习率为0.01,L2正则化系数为0.01,优化器为Adam.
在W&D 中,Wide 部分采用线性回归方法,并选用默认参数.Deep 部分采用含两个隐含层的神经网络,其结构为325-100-50-1,网络部分神经元个数为32-32,激活函数为Relu.最大迭代次数为500,批量大小为100,优化器为Adam.
在TSA 中,第1 阶段预测采用随机森林,基学习器数量为200,最大树深度为7;第2 阶段采用线性回归,且选用默认参数.
在GBDT+LR 中,GBDT 部分的基学习器数量为150,LR 部分采用线性回归,且选取默认参数.
在MDFF 中,类别型特征提取模型SARR 的嵌入单元1和2 的维度分别为82和80,Dense 单元神经元个数为16,GRU 单元和LSTM 单元的神经元个数均为32,最大迭代次数为400,批量大小为100,随机失活(Dropout)比例为0.15,激活函数为Relu,优化器为Adam.数值型特征提取模型XGB 的基学习器数量为30,学习率为0.15,最大树深度为8,列采样比例为0.4.任务执行时间预测模型LGBM 的学习率为0.15,基学习器数量为1 000,最大树深度为9,最多叶子结点个数为31,列采样比例为0.4.
4.1.3 评价指标
为了检验本文MDFF 算法的预测精度,本文选取了平均绝对误差(Mean absolute error,MAE)、均方根误差(Root mean square error,RMSE)、均方根对数误差(Root mean square log error,RMSLE)和决定系数(R square,R2)四种评价指标[39-40],并在这些评价指标的基础上,设计了预测精度差值δ和预测精度改善比例η两个指标,分别用于反映MDFF 算法的预测精度提升的数值大小以及提升程度.
1) MAE 表示目标真实值和预测值之差的平均绝对值,用于度量两个变量之间的差异.MAE具有较强的可解释性和鲁棒性,且MAE的值越小,说明预测模型的性能越好.MAE的具体计算如式(18)所示:
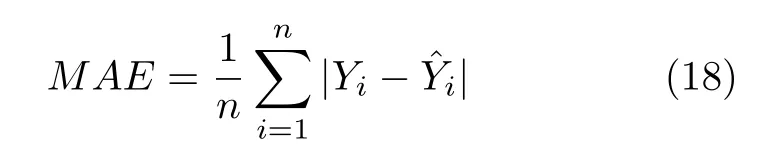
式中,n为样本数量,分别为第i个样本的真实值和预测值.
2) RMSE 表示目标真实值和预测值的样本标准差,用于度量模型的预测误差大小.RMSE 与数值范围紧密相关,相对于MAE 来说,RMSE 对数值预测的错误更加敏感,但鲁棒性较弱.RMSE 的值越小,说明预测模型的性能越好.计算公式如下:

3) RMSLE.鉴于RMSE 容易被数值较大的样本所主导,RMSLE 在RMSE 的基础上增加了取对数操作,以便在保持RMSE 敏感性的基础上,对模型进行公平地评价.RMSLE 的值越小,说明预测模型的性能越好.计算公式如下:
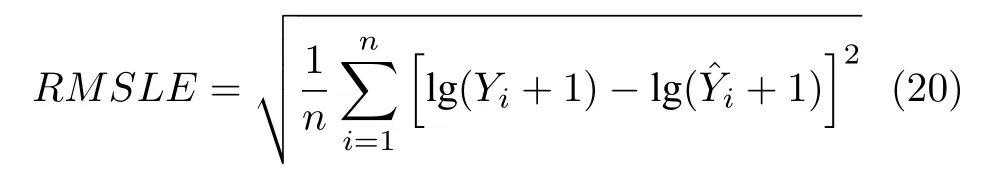
4) R2 通过数据的变化来表征一个预测算法的拟合程度.R2 的值越大,说明预测模型的性能越好.计算公式如下:

5)预测精度差值δ用于表示本文MDFF 算法预测精度提升的数值大小.计算公式如下:

6)预测精度提升比例η表示MDFF 算法的预测精度改善程度.计算公式如下:
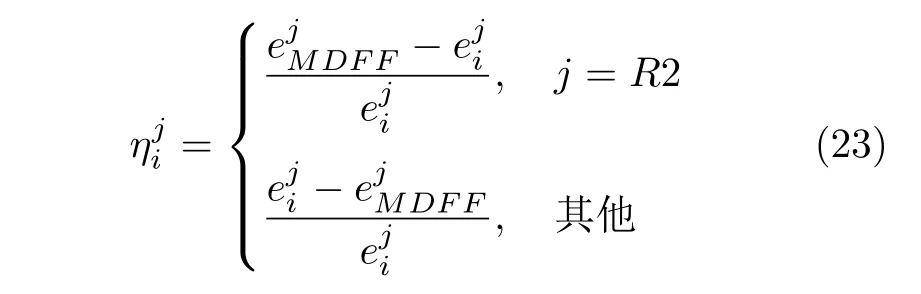
4.2 实验结果分析
为了避免随机性,本文采用10 次实验结果的平均值进行性能比较.针对不同的评价指标,分别计算所有方法的MAE、RMSE、RMSLE和R2 值,如图4~7 所示.由图4~图6 可知,本文MDFF 算法的MAE、RMSE、RMSLE 值达到了最小,说明其预测结果的平均绝对误差和均方根误差更小,且对大数值样本的偏向性最小.由图7 可知,MDFF 的R2 值最大,说明该算法的拟合程度最好.
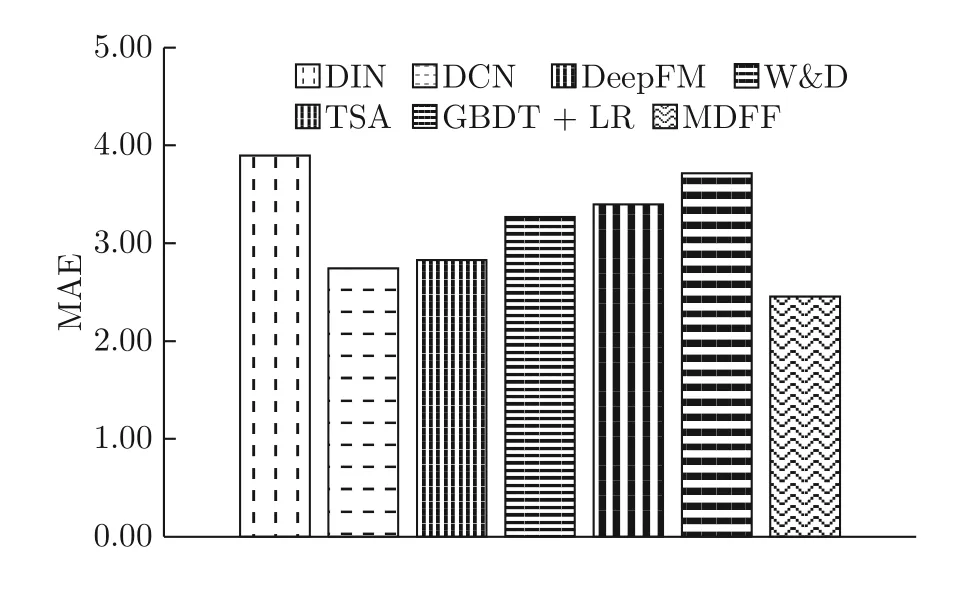
图4 不同方法的MAEFig.4 MAE comparisons among different methods

图5 不同方法的RMSEFig.5 RMSE comparisons among different methods

图6 不同方法的RMSLEFig.6 RMSLE comparisons among different methods
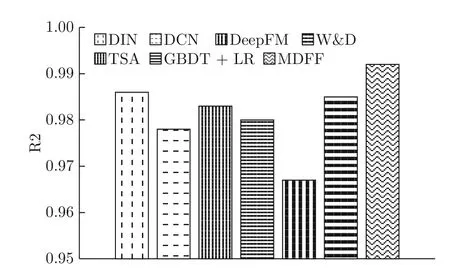
图7 不同方法的R2Fig.7 R2 comparisons among different methods
由图4~7 结果,可以得出以下结论:
1)由于DIN、DCN、TSA和GBDT+LR 要么侧重提取类别型特征,要么侧重提取数值型特征,而忽略另外一类特征,使模型很难获得全面的特征知识.因此,其模型对特征的非线性表达能力和解析能力不足.在本文提出的MDFF 算法中,针对类别型数据和数值型数据的特点,分别设计不同的特征提取器,有效地从原始数据中提取类别型特征和数值型特征,挖掘更全面的任务执行时间知识,提高了工作流任务执行时间的预测精度.在上述四类评价指标下,MDFF 算法的预测性能均优于四类对比算法,即DIN、DCN、TSA和GBDT+LR.
值得注意的是,注意力机制的引入,使得DIN的RMSE和R2 仅次于MDFF,预测误差波动相对较小且获得了较好的拟合效果.这也说明了本文采用具有注意力机制的SARR 模型,在提取类别型特征方面的有效性.由于梯度提升算法对数值型数据进行了离散化编码,所以GBDT+LR 的RMSE和R2 值仅次于DIN,且预测误差较小,达到了较好的拟合效果,这说明本文设计的基于XGB 的特征提取算法,能够有效地提取数值型特征.
2)虽然DeepFM和W&D 算法能同时提取类别型特征和数值型特征,但是与本文MDFF 算法相比,其预测结果相对较差.主要原因如下:a)本文提出的MDFF 算法,通过具有堆叠循环网络结构、注意力机制和残差连接的SARR 模型,将类别型数据从高维稀疏的特征空间映射到低维稠密的特征空间,提高了模型对类别型特征的关注度.因此,与DeepFM和W&D 采用DNN 进行类别型特征提取相比,MDFF 算法能够更有效地提取类别型特征;b) DeepFM和W&D 分别采用因子分解机和线性回归模型提取数值型特征,而本文MDFF 算法利用XGB 对数值型数据进行离散化编码,通过对过于稠密的输入向量空间进行稀疏化处理,提高了特征之间的差异性,从而能更有效地提取数值型特征.此外,通过异质多维度特征融合策略,本文MDFF 算法能够有效避免因直接使用类别型特征和数值型特征而引入冗余信息或者噪声的可能性.总的来说,SARR和XGB 的使用,使得MDFF具有更强的提取类别型和数值型特征的能力,结合多维异质特征融合策略,MDFF 不仅能够提取有效的深层特征,还能学习更全面的任务执行时间知识,使预测性能得到了明显改善.
为了进一步说明本文提出的MDFF 算法与对比算法在不同指标上的精度提升程度,表1和表2给出了MDFF 与其他对比算法在四种性能指标下的差值和性能提升比例.
由表1和表2 可以看出,不同算法在不同性能指标下具有不同的性能表现,且MDFF 与对比算法的性能差值以及MDFF 算法的性能提升比例也不相同,但相对来说,本文提出的MDFF 算法在不同性能指标下的表现更优.这也说明了MDFF 具有更强的类别型和数值型特征提取能力,同时对特征进行重要性排序并有选择性地融合,大大提高了预测性能.
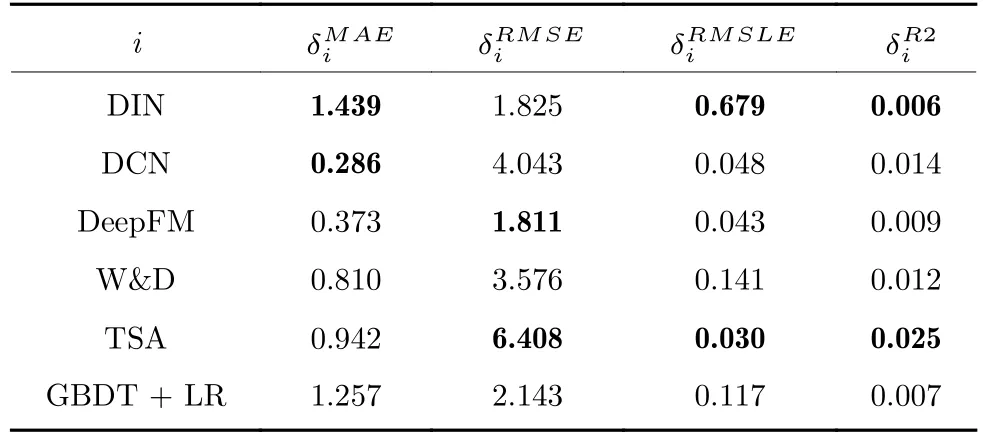
表1 预测精度的差值Table 1 The difference of prediction performance
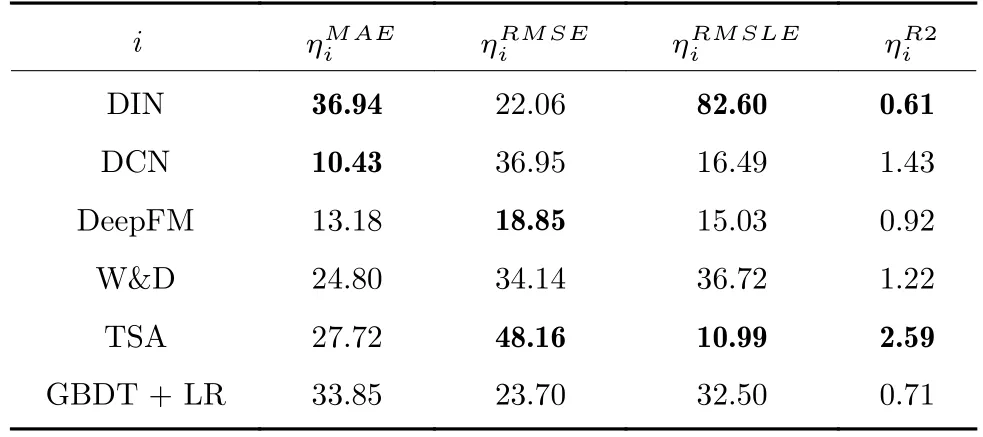
表2 预测精度提升的比例(%)Table 2 The proportion of performance improvement (%)
在上述性能指标的对比中,本文提出的MDFF 算法都能取得良好的性能表现,即MDFF 算法具有较强的异质特征提取与融合能力,获得了更高的预测精度.与各类对比算法相比,MDFF 算法主要有以下3 个方面的优势:1) MDFF 算法采用SARR提取类别型特征,将类别型数据从高维稀疏的特征空间映射到低维稠密的特征空间,避免了搜索空间过大的问题,提高了模型对类别型特征的关注度.因此,相对于普通DNN 网络,MDFF 算法能更有效地、更具针对性地提取类别型特征;2) MDFF 采用XGB 提取数值型特征,即借助于XGB 对数值型数据进行离散化编码,并对过于稠密的输入向量空间进行稀疏化处理,提高了特征之间的差异性,实现了数值型特征的有效提取;3) MDFF 采取多维异质特征融合策略,对SARR和XGB 提取到的特征进行有选择性地融合,以充分挖掘与利用多维度特征,为任务执行时间的预测提供更全面有效的知识,改善了预测性能.由此可见,通过类别型特征和数值型特征的有效提取与融合,MDFF 算法的预测精度得到了明显提升.
综上所述,本文提出的基于多维度特征融合的预测算法预测平均误差、预测误差波动和预测偏向性更小,不仅对类别型特征和数值型特征有较强的解析和表达能力,而且能够对异质特征进行充分地挖掘与利用,实现了对云工作流任务执行时间的精准预测,可以满足大数据环境下的云工作流任务执行时间估计需求.
5 结束语
云计算中的工作流调度和资源配置依赖于任务执行时间的准确估计.本文针对工作流任务执行时间预测问题,提出了一种基于多维度特征融合的预测方法.首先,构建具有注意力机制的堆叠残差循环网络,对类别型数据进行特征提取,增强了模型对类别型数据的解析能力.其次,引入XGB 对数值型数据进行离散化编码,提取数值型特征,提高了模型的非线性表达能力.然后,融合提取到的特征和原始样本特征,获得多维异质特征,给预测模型提供了更全面的任务执行时间知识.最后,利用LGBM 对多维异质特征进行充分挖掘,构建预测模型,实现对云工作流任务执行时间的精准预测,并采用阿里巴巴的集群数据集进行了实验验证.实验结果表明,该方法优于现有的基线预测算法,在MAE、RMSE、RMSLE 以及R2 四种评价指标下,均达到了更好的性能.因此,本文所提出的基于多维度特征融合的预测方法,能够满足大数据环境下云工作流任务执行时间预测的需求.然而,本文仅在集群数据集上进行了预测模型的搭建,如何将预测模型部署到实际云数据中心,实现工作流任务执行时间的在线预测,仍需进一步探索研究.
