基于水平井资料的砂砾岩储层岩石相建模方法
2022-09-29董越李永强曹茜唐力
董越, 李永强, 曹茜, 唐力
(1.中国石化石油勘探开发研究院, 北京 102200; 2.中国石油长庆油田分公司勘探开发研究院, 西安 710018; 3.中国石油华北油田公司, 任丘 062552)
传统的以直井井网开发的砂岩油藏已具有比较成熟的储层表征与建模的方法。该方法以录井、测井、地震等作为基本资料,通过较为完善的井网,首先开展精细的地层对比,建立地层格架[1];随后在格架内部识别不同类型沉积相(岩石相),明确砂体发育规律[2];最后通过变差函数的控制,以井控点的已知数据推测未井控部位的数据[3],在全区进行沉积相(岩石相)建模,形成三维地质模型,再以相控的手段建立孔渗模型[4]。
上述储层表征方法在中国已有多个成功案例,指导了大量储层开发的工作[5]。然而,在盐家油田盐227块以水平井开发的砂砾岩油藏研究中,该方法具有较大的不适用性。首先,水平井资料主要以优质储层为钻探目标,因此存在一定取样偏差,在直接应用于储层表征之前,应进行一定的预处理,但目前相关研究、方法较少;其次,砂砾岩储层在沉积过程中属于事件沉积,砾、砂、泥在沉积过程中快速堆积,本身相变较快[6-7],通过测井资料直接识别沉积相(岩石相)较为困难[8]。第三,水平井在数据逻辑结构、数据空间分布上也都与直井存在较大差异,水平井数据如何进行变差函数分析、如何用于建模一直是难以解决的问题,这进一步增加了盐227块砂砾岩油藏表征的难度。
为解决上述问题,现以岩心、测录井、地震等为基本资料,提出了一套全新的水平井开发的砂砾岩储层表征方法。该方法首先以“向量角抽稀”的方法对水平井测井资料进行预处理,消除了水平井数据的取样偏差;其次通过卷积神经网络的手段对测井数据进行深度学习,以数据自识别的方法建立了高精度的单井岩石相识别结果,作为地质建模的基础数据;最后,应用变差椭圆法对岩石相数据进行空间变差函数分析,并以随机模拟的手段建立地质模型,完成对储层的表征。经过验证,储层表征结果与实际生产数据吻合度较高。该方法对于研究区及类似区块油藏表征具有一定指导意义。
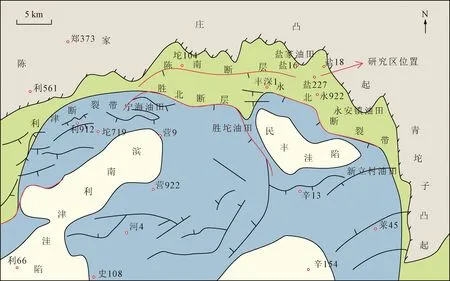
图1 盐227块构造位置图Fig.1 Structural location of Y227 block
1 盐227块地质概况
盐227块砂砾岩油藏位于盐家油田中部,其构造位置处于东营凹陷北部陡坡带东端、陈家庄凸起南部、盐18古冲沟的西侧翼(图1)。
1.1 构造特征
在垂向上,盐家地区主要受陈南断层的控制。主断面以铲式构造为主,上部倾角约为50°,下部较缓,倾角约为30°。
在平面上,盐家地区呈现“沟梁相间”的特征。盐227块该区沙四段砂砾岩体构造相对简单,呈鼻状形态,地层西南低北东高,地层倾角8°~20°;埋深 3 210~3 860 m(图2),最大厚度达到 650 m,地层北薄南厚,呈楔形。
1.2 沉积特征
在沙河街组沉积时期地形高差较大,陈家庄凸起成为该区主要的物源,地形高差大、沉积速度快,在盐227块沉积厚层砂砾岩体。盐227块主力含油层段为沙河街组沙四段,构造上呈单斜状分布(图2),纵向上可以划分为4个砂组,储层主要分布于3、4砂组[9]。
该地层属于一套近岸水下扇沉积,整体岩性较粗,以厚层致密砂砾岩为主,泥质隔夹层发育较弱。自下而上碎屑粒度由粗变细,整体呈现正旋回的特点。岩性主要为中粗砂岩、含砾砂岩、砾状砂岩、细砾岩、中砾岩等,砂地比达到92.6%,细粒沉积物中普遍含有砂砾,分选磨圆较差。成分成熟度和结构成熟度均较低,常见重矿物发育,体现其近源快速堆积的特征。取心井岩心观察发现泥岩以深灰色及黑色为主,常见砂质滑动、包卷层理等构造,反映其沉积水体较深、地形坡度较大以及浊流沉积的特征。
1.3 开发情况
该油藏以9口丛式水平井和3口直井进行开发[10],目前已进入高含水期,亟需开展精细油藏三维地质表征以对剩余油挖潜提供指导。
2 水平井测井资料预处理
2.1 水平井数据样本偏差
在空间中,地质体水平发育规模和垂向发育规模存在较大差异,这导致了水平井与直井在数据结构上表现出较大不同。一般情况下,可近似看作均质的地质体在水平向的展布规模远远大于垂向展布规模。以苏里格气田石盒子组储层为例,其水下辫状河道微相中的辫流带水平向延伸长度可达200~1 000 m,而垂向上的厚度一般只有10~20 m(图3)。因此,相较于直井,水平井井段内会更多地钻遇较为优质的储集体。此外,水平井在钻井过程中会进行轨迹控制,其目的也是为了钻遇更多优质储集体。因此,相较于直井,水平井数据将存在相当大的样本偏差。
在建模过程中,水平向网格的规模也远远大于垂向网格的规模。在油藏开发阶段,通常水平向网格的规模可达20~50 m,而垂向网格一般在1~3 m。因此,尽管可以通过测井曲线精确识别岩石相,但在建模过程的第一步——数据采样(即将穿过模型单一网格的大量数据归一为单一数据,作为该网格内的原始数据,也称为“粗化”;一般对于岩石相、沉积相等离散数据,归一的方法为“most of”,即最多值)过程中,由于水平井更多地钻遇了优质储层,因此储集性能较差的岩石相会在粗化过程中被严重遮蔽(图3)。

图2 盐227块构造井位图Fig.2 Structure and production wells of Y227 block

图3 水平井数据样本偏差及数据粗化过程中的遮蔽效应(引自文献[11],略有修改)Fig.3 Sample bias of horizontal wells and shield effect in data upscaling (cited from literature[11] and slightly modified)
上述分析表明:水平井数据在本质上就存在较大的样本偏差,而三维建模的数据粗化方法又会进一步放大该样本偏差。如果未对水平井数据进行预处理而直接用于地质建模,则会导致建模结果过于乐观,即代表高储集性的岩石相的比例远大于真实情况。
2.2 向量角抽稀方法
上述分析表明,在利用水平井测井曲线进行岩石相识别、储层地质建模之前,很有必要先对测井数据进行预处理,以消除样本偏差的影响。目前针对水平井数据纠偏的研究较少,因此借鉴了遥感、测绘学中点云数据的三角网抽稀法[12],创新性地提出了向量角抽稀法,以对水平井测井数据进行预处理。

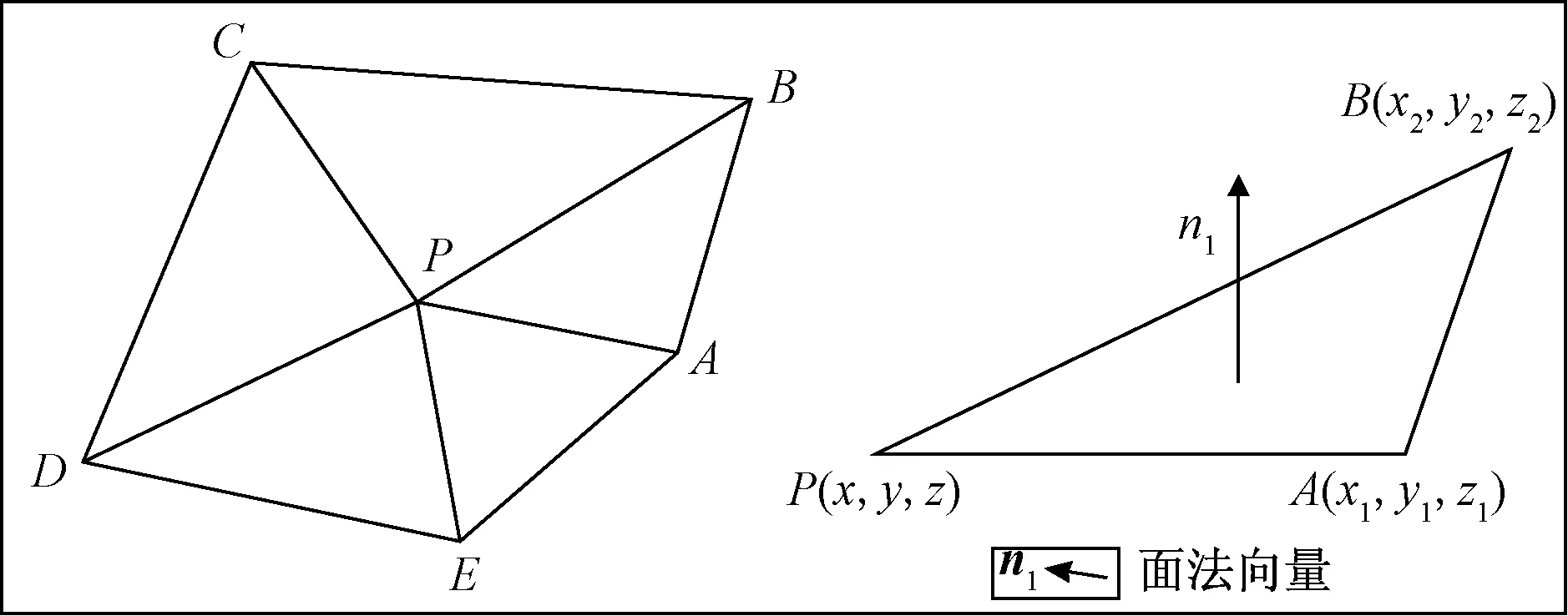
图4 三角网抽稀方法Fig.4 Triangle network thinning methods

图5 向量角抽稀方法Fig.5 Vector angle thinning methods
在水平井数据质量控制过程中,可以借鉴三角网抽稀法对数据进行抽稀。相比于测绘高程数据,水平井测井曲线的维度由三维降至二维,因此对于某一点P,其周围有且只有2个测井数据点(假设为A和B),如图5所示。AP和BP两条线段的法向量记为n1和n2,若n1和n2夹角小于某个设定的角阈值,则认为P点与周围两个点的差异不大,可删除P点。在确定阈值的过程中,需要考虑测井曲线本身的数值起伏。对于密度测井等曲线,其起伏本身较小,因此可以确定相对较大的阈值;而对于电阻率测井等,则需要确定较小的阈值。此外,抽稀可进行多次,结合地质认识挑选最后的结果。
2.3 水平井测井资料处理结果
盐227块钻井资料较全,常规测井曲线均可收集到。考虑到测井曲线主要用于储层岩石相的识别,因此挑选对于岩石相较为敏感的曲线进行资料处理。分析认为,盐227块砂砾岩储层不同岩石相之间的主要差异为岩石密度、孔隙度,而孔隙度大小又进一步影响了岩石骨架与孔隙流体的比例。因此挑选了中子孔隙度(CNL)、密度曲线(DEN)和声波时差曲线(AC)等进行抽稀预处理,以用于后续岩石相识别。
通过MATLAB软件进行编程,并完成了9口水平井相关测井曲线的处理。经过反复实验,结合前期地质认识,认为取迭代次数n=2时抽稀效果最符合真实情况。
3 储层岩石相识别
3.1 盐227块储层岩心岩石相类型
岩石相是某一沉积微相中可近似看作均一体的岩性组合,同一岩石相的岩性、电性、物性具有相似性。狭义的岩石相应定义为岩性及沉积构造相似的岩石组合。在实际研究中,一般通过相似岩性来定义岩石相。
对于盐227块砂砾岩油藏的岩心岩石相类型、物性、含油性等特征的讨论参见文献[14],按照岩石粒度大小,可在岩心上识别出泥岩相、含砾砂岩相、砾岩相三类,岩石粒度依次增大。其中含砾砂岩相的物性和含油性较好,砾岩相较差,而泥岩则为非储层,物性最差。
通过岩心数据,可以精确识别储层岩石相类型和发育厚度。然而,取心井和取心段均分布较少,无法覆盖全区。在盐227块,取心井只有Y227和Y227-1两口井,取心段长度也只有106 m。如何将岩心识别的储层岩石相推广到非取心井或者取心井的非取心段是储层表征的关键问题。
3.2 岩石相识别常规方法
通过岩心刻度测井,采取测井曲线交会图和人工干预相结合的方法,可以在常规储层有效识别岩石相[15-16]。这是因为常规储层在沉积过程中搬运过程远,沉积速度相对慢,沉积分异较好,岩性相对较纯。因此不同岩石相的电性特征差异较大,通过两条测井曲线就可以有效地在交会图上将不同岩石相区分开来。部分三角洲前缘沉积甚至可以通过自然电位(SP)或者伽马(GR)一条曲线就能识别泥岩相和砂岩相。
然而,砂砾岩储层的沉积模式与常规储层差异较大。近岸水下扇沉积速度快,砾、砂、泥来不及完成沉积分异,相互混杂地快速堆积在构造斜坡底部,形成扇体沉积。因此,砂砾岩储层岩性的特征是砾中有砂,砂中有泥,泥中有砾,不同粒度的组分混杂地堆积在一起。这就导致难以通过测井曲线以交会图的方式简单地将不同岩石相区分开来,从而无法在无取心的井或井段上识别岩石相。
3.3 SegNet卷积神经网络
SegNet模型在最初的卷积模型Lenet的基础上做了进一步深化,能够深度学习数据内在本质结构。该模型最初被应用于自动驾驶和智能机器人深度图像语义分割,目前也广泛应用于遥感、地震、测井等图像的识别和分割[17-19]。
SegNet网络主要通过编码器—解码器的结构来对输入数据进行处理,形成输出数据。编码器实际上是一系列非线性处理模块,每个模块都包含数个卷积层、归一化层、激励函数层和池化层。其中,卷积层主要负责图像本质特征提取,而池化层主要负责降维。通过这样一系列模块,输入的图像数据由高维向量向低维向量转换,实现了对高维数据中最为本质的低维平移不变性特征的提取。由于数据发生了降维,因此在编码器中,数据每通过一个非线性模块,数据量都会减半。随后,数据被输入解码器。解码器也由一系列非线性模块构成,是编码的反过程。通过解码,低维数据被重新提升至高维,数据量逐步翻倍至初始水平,并在此过程中实现重构[20](图6)。
利用测井曲线进行岩石相识别的过程本质上也是图像识别的过程。该过程包括SegNet模型训练和岩石相识别两步。第一步,通过岩心上识别的岩石相数据作为label(即标志数据),测井曲线作为输入数据,对卷积神经网络进行训练,确定合适的非线性模块数量和卷积层数量;第二步,将测井曲线再次输入到训练好的SegNet网络中,实现对于测井曲线的分类分割,其结果即识别出的岩石相(图7)。对于识别结果影响较大的参数为SegNet网络结构的非线性模块数量和卷积层数量。
3.4 岩石相识别结果
通过反复实验,确定了SegNet网络结构中的核心要素:非线性模块数量和卷积层数量。研究认为,当编码器末端非线性模块中的数据量大小为岩石相类别(输入数据中Label内的类别数量,本次研究中类别数为3)的1~2倍时效果最好。以含砾砂岩相为例,其平均厚度约为8 m,按照测井采样密度(8数据点/m),其数据量为64×1,则第一个非线性模块输出数据量为32×1,第二个为16×1,以此类推,第4个为4×1,满足要求。因此,最终SegNet模型的非线性模块数量设计为8个(解码和编码各4个)。
卷积层的数量在各非线性模块中并不相同。实验认为,可将后面模块中卷积层的数量设置为前一模块的两倍。例如,第一个模块中卷积层数量为16个,则第二个设置为32个,第三个设置为64个,以此类推。
在设置好Segnet卷积模型后,以预处理后的声波(AC)中子(CNL)、密度(DEN)等曲线作为输入数据,完成了盐227块沙四段3、4砂组储层单井岩石相的识别(图8)。通过与岩心识别岩石相对比,准确度较高,平均达90%。

图6 SegNet卷积网络模型Fig.6 SegNet convolutional neural networks model

图7 基于卷积网络的岩石相识别模型Fig.7 Lithofacies identification model based on SegNet convolutional neural networks

图8 基于卷积网络的岩石相识别结果Fig.8 Lithofacies identification results based on SegNet convolutional neural networks
4 水平井变差函数分析
4.1 水平井数据的特殊性
直井数据用于三维地质随机建模的技术已经比较成熟。将地层网格化后,可直接将直井岩石相数据采样至网格内,在变差函数的控制下,通过序贯高斯模拟的方法,以已知网格推测未知网格,最终完成随机模拟。这是因为:在开发阶段直井数量较多、井距较小、井位排布相对规则,可以保证在各个方向都能有足够多的数据来支持变差函数的分析,得到有效的主次变程。然而水平井数据在空间分布上与直井存在较大差异。与直井数据在平面上呈规则的“点云”状分布不同,水平井数据的分布呈“串”状,在沿水平井轨迹的方向数据密集,而在垂直井轨迹的方向上几乎没有数据。因此以常规方法进行水平向变差函数分析时,将会因为没有足够数据的支撑而导致变差函数不收敛、主次变程无法求取的问题,从而导致随机模拟无法进行。因此,如何应用水平井数据进行变差函数分析,成为制约油藏地质建模的关键问题。
4.2 变差椭圆分析方法
考虑到水平井数据的特殊性,提出了一套针对水平井的变差函数分析方法。与直井直接求取变差函数不同,水平井数据可先求单井变差函数,然后通过拟合变程椭圆来间接求取主次变程。
(1)单井一维变程求取。考虑到水平井数据在沿井轨迹方向上比较密集,因此在对岩石相做变差函数分析的过程中,首先分析其单井一维变程。沿着井轨迹的方向,按照一定的滞后距取得该参数的相应点对,通过计算得到变差函数,并由此获得岩石相在该井轨迹方向上的一维的变程。例如,在盐227块内进行孔隙度的变差函数分析过程中,就可以获得沿着盐227-1HF、盐227-2HF、…、盐227-9HF等9条代表不同方向的变程(图9)。

图9 盐227块含砾砂岩相变程椭圆Fig.9 Variogram ellipse of pebbly sand facies
(2)变程椭圆的拟合。根据地质统计学原理,同一参数在不同方向上的变程应可以组成一个变程椭圆:该椭圆的长轴方向和大小代表了此参数主变程的方向和大小,而短轴方向的代表了此参数次变程的方向和大小。因此,在得到某参数沿数个方向的变程后,可以用这几个变程拟合出一个变成椭圆,通过量取这个椭圆长短轴的大小和方向,即可求取该参数主次变程的大小和方向(图9)。
由于沿着水平井方向取点对能够设置较小的滞后距,因此能够获取大量的点对用于变差函数的计算。以上方法能够获得更高的精度,并有效解决了常规方法应用于本区存在的块金值高、点对数量少、变差函数不收敛、变程无法确定等问题。

图10 盐227块岩石相模型Fig.10 Lithofacies model of Y227 block
4.3 水平向变差函数分析结果
应用盐227块9口水平井单井岩石相识别数据,通过水平向变差椭圆分析方法,分别求取了泥岩相、含砾砂岩相、砾岩相的水平向主次变程的方向和大小(表1)。分析认为,求取过程中单井变差函数分析结果收敛,单井变程可信,水平主次变程能够反映各岩石相的空间展布规律。

表1 各岩石相主次变程数据表
5 岩石相地质建模
储层地质建模的基本思路,是在地层网格化的基础上,将井数据、地震数据等各种已知数据赋予至网格中,进而通过各种算法,依据网格的空间关系,内插或外推地层所有网格内某种属性的值。这些算法均出自地质统计学原理,一方面使得网格内贮存的数值符合某种数学关系,另一方面也在此过程中体现了地质的思想[21]。
在经过水平井测井资料预处理、储层岩石相识别、水平向变差函数分析后,以单井岩石相数据作为硬数据,以变差函数作为控制要素,应用序贯高斯模拟的方法建立了盐227块岩石相地质模型(图10)。随后以孔隙度测井为硬数据,采用岩石相模型作为控制,应用序贯高斯模拟方法建立了孔隙度模型(图11)。
在此基础上,结合生产数据,对建模结果进行了验证。首先以孔隙度大于5%作为优质储层的发育标准,对岩石相模型进行了模型雕刻,只保留孔隙度大于5%的部分(图12)。随后,统计不同水平井钻遇连通优质储集体的规模,并与单井产量做交会(图13)。
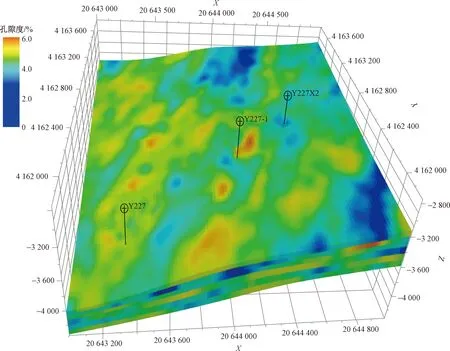
图11 盐227块孔隙度模型Fig.11 Porosity model of Y227 block

图12 盐227块储层雕刻结果Fig.12 Reservoir carving results of Y227 block
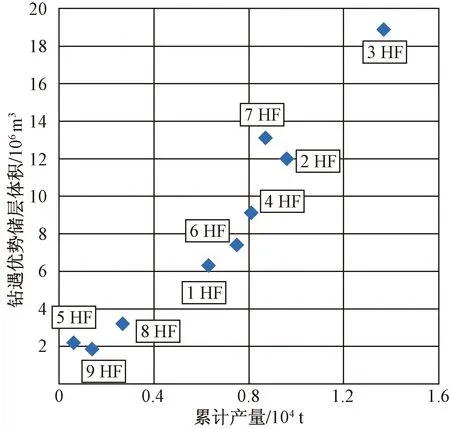
图13 水平井单井产量与钻遇连通优质储层体积交会图Fig.13 Cross plot of total yield and the volume of connecting send bodies drilled by horizontal well
从图13可见,单井产量与连通体规模基本上呈正相关,即水平井单井钻遇连通体规模越大,产量越高。由此可见,建模结果与生产数据能够很好吻合,建模结果较为准确。
6 结论
充分利用岩心、测井等资料,针对水平井开发的砂砾岩油藏,提出了一套岩石相地质建模方法。经过研究,得出以下结论。
(1) 水平井因更多地钻遇优质储层,因此其资料存在较大取样偏差,在用于进行岩石相识别之前,需进行预处理。通过向量角抽稀的方法可以剔除部分干扰点。当抽稀迭代次数为n=2时,处理效果最好。
(2) 采用卷积神经网络的方法可以有效解决在岩石相识别过程中,砂砾岩储层相变快、测井曲线特征不突出等问题。设置8个非线性模块的SegNet模型能够准确识别3类储层岩石相,识别精度平均达90%。
(3) 通过先计算水平井单井一维变程,随后拟合变程椭圆的方法,可以解决水平井在特定方向上数据量少、水平向变差函数不收敛的问题,有效求取主次变程。
(4) 通过上述方法,建立了盐227块岩石相模型和孔隙度模型。经过验证,模型与生产数据吻合较好,模型准确度较高。
