基于人体属性分析的考场行为识别
2022-09-29姚捃郭志林赵杰
姚捃, 郭志林, 赵杰
(1.成都理工大学工程技术学院, 乐山 614000; 2.核工业西南物理研究院, 成都 610000)
人体行为识别是人工智能视觉任务的重要技术,在人机交互、智能安防、考场监考、婴幼儿看护中都有着重要应用。
早期的行为识别基于手工提取特征的方法,利用特征描述符包括轨迹特征、梯度直方图特征(histogram of oriented gradient, HOG)、光流直方图特征(histogram of oriented optical flow, HOF)、混合动态纹理特征、光流场特征、人体关节点特征等构建特征空间,进而使用机器学习的方法进行行为的识别。
唐超等[1]提出深度图像特征(RGB depth map,RDG-D)的人体动作识别方法,首先获取基于RGB模态信息的梯度直方图特征、基于深度图像模态信息的时空兴趣点特征和基于关节模态信息的人体关节点位置特征,利用集成决策对三种提取到的特征进行分类,在公开数据集上取得了不错的效果。
刘帆等[2]改进了一种基于全局特征和局部特征的方法来实现人体行为识别,首先使用背景减法获得人体运动区域,然后引入方向可控滤波器改进HOG特征以增强局部边缘信息,同时对加速稳健特征进行聚类获得词袋模型;最后将融合后的行为特征输入支持向量机对行为特征进行分类识别,在UCF Sports等数据集上获得了先进的性能表现。
张恒鑫等[3]借助OpenPose算法得到人体区域中关节点的二维坐标构建骨架模型,提取基于关节向量的多种动作时空特征,采用KNN(K nearest neighbor)模型进行行为识别,在Weizmann数据集上取得了不错的效果。
但是,由于视频场景的复杂性、光线变化、人体遮挡等问题,以上所列举的手工提取特征的方法严重依赖于手工特征提取算子的设置和具体任务的数据集分布,具有一定的局限性,渐渐被深度学习方法所替代,如卷积神经网络、快慢信息网络、TSN双流网络、3D卷积神经网络、TSN双流与长短期记忆网络(long short term memory,LSTM)结合的混合网络等。这些网络利用深度学习强大的特征提取能力,从各个角度提取出行为识别所需要的人体外观和人体运动的高级时空特征(如光流特征、3D时空特征),能更准确地分辨行为类别。
戎辉等[4]利用卷积神经网络AlexNet对驾驶员行为状态进行识别,首先对驾驶员7种驾驶状态进行了定义,构建了驾驶员状态信息采集系统,然后利用卷积神经网络和迁移学习方法进行行为识别,同时达到了理想的准确率与推理速度。齐琦等[5]提出了一种基于改进多通道3D卷积神经网络结构的人体行为识别方法,同时将图片的空间信息和时间信息作为卷积神经网络的输入进行行为识别,在公开数据集UCF-101上取得了不错的效果。周鹏等[6]提出一种改进的深度卷积神经网络模型(dynamic convolution neural network,DCNN),模型中增加了信号融合单元,并提出一种将时间序列转换成单通道行为图片进行行为识别的方法,在公开数据集UCI上取得了优于传统模型的性能。何嘉宇等[7]构建了特征金字塔层次结构以增强网络检测不同持续时长的行为片段的能力,在公开数据集上获得了先进的识别性能。文献[8-12]利用LSTM长短记忆网络对于时序数据特有的敏感性,对数据之间的联系进行有选择的记忆与遗忘,仅保留对识别结果有益的数据,达到了良好的识别率。Ayed等[13]利用深度卷积神经网络在提取出面部姿势、面部特征和感觉特征基础上进行了行为识别,在CK+(the extended Cohn-Kanade dataset)数据集上取得了不错效果。Fuentes等[14]提出了一种基于深度学习的时空信息分层牛行为识别方法,在有效提取外观特征、时空信息和上下文时间特征基础上进行了牛行为识别,成功检测出15种不同类型的分级活动。Ma等[15]在RexNet基础上加入时序信息,进行了扩展网络的3D算法改进,最终在公开数据集上获得了91.02%的准确率和101.02 f/s的每秒识别帧数。
以上一些基于深度学习提取时空特征的行为识别算法存在着硬件需求过高、时效性不足、复杂场景准确率偏低等问题。在很多应用场景下不能实现实时识别,是这些行为识别算法并未得到有效应用的主要原因。因此有研究者提出利用深度学习模型中多种类输出头的特性,在实际应用中以构建精准的行为类别数据集为基础进行行为识别,以期达到或超越传统机器学习和基于时空特征的深度学习算法的效果。
董琪琪等[16]利用SSD(single shot multiBox detector)算法,在建立听讲、睡觉、举手、回答及写字5种学生行为状态数据集基础上进行了行为识别, 达到了95.4%的平均精度。王昊飞等[17]提出了一种基于注意力机制的ResNeXt模型进行行为识别,将注意力机制嵌入ResNeXt网络中,在UCF101和HMDB51数据集上分别进行实验,得到了95.2%和65.6%的准确率。叶黎伟等[18]利用YOLOv5网络结合GCT(gated channel transformation)模式利用采集的课堂视频数据进行了10类课堂行为的识别。窦刚等[19]利用经典的端到端网络YOLOv3,在没有提取时序信息基础上,通过改进的网络进行了考场异常行为识别,解决了推理速度过慢的问题。陈亚晨等[20]基于改进的YOLOv3网络通过去除部分输出检测模块、增加浅层网络的层数以及采用K-means聚类算法选取初始先验框等策略进行了眼行为的识别,达到了91.3%的识别准确率。
以上研究虽然解决了特定场景中行为识别推理速度的问题,然而存在以下问题:①不能同时识别多种行为;②没有利用大型数据集进行迁移学习,在其他问题上扩展性不足。基于此,现提出基于人体属性分析的考场行为识别算法,利用考场特殊场景的优势,在没有光照变化、场景单一、人体上半部没有明显遮挡情况下,采集高清视频图像,进而利用视频处理设备解帧输入深度神经网络,进行快速的人体检测与人体属性分析,再根据属性分析结果进行行为判别。算法采用多标签学习机制可以同时识别出多种行为类别;检测网络优化为单一anchor box,进一步提升了推理速度;使用了大型公开数据集进行预训练,只需稍做更改就可以扩展到其他行为识别任务。提出的算法经过实验验证,具有良好的扩展性、高效性和准确率。
1 方法
人体检测和人体属性分析从本质上讲都涉及分类与定位算法,因此采用了效率与性能并重的YOLOv3来实现。YOLOv4和YOLOv5虽然是在YOLOv3基础上进一步改进,但都是在细枝末节上进行的优化,反而丢失了YOLOv3在工业界的普遍适用性。所以总体思路是将人体检测与属性分析作为YOLOv3网络的并行化任务,并对输出向量加以修正。
1.1 数据准备
在数据准备阶段,需要采集本地视频数据集,筛选出视频数据中典型的正常行为与违规行为,然后对视频帧进行标注。其中纸条、手机、书本等应归为人体携带属性;而扭头、斜视、说话、埋头等作为人体行为属性。由于人体检测与属性分析由统一的网络完成,所以需要对数据进行整体标注,考场主要行为数据判定如表1所示。
标注应符合多标签学习模式,采用与行人属性分析的WIDER数据集相同的json格式,需要标注出人体目标的bbox及所携带属性。bbox由4个坐标给定,属性由属性向量给定。
结合表1给出属性对照及单个目标标注(纸条)示例如下:
{′attribute_id_map′:
{′0′: ′note′,
′1′: ′phone′,
′2′: ′book′,
′3′: ′turn′,
′4′: ′strabismus′,
′5′: ′speak′,
′6′: ′bury′,
′7′: ′probe′}
{′attribute′: [1, -1, -1, -1, -1, -1, -1, -1],
′bbox′: [565.398773006135,
370.6503067484663,
76.95705521472392,
238.7239263803681]}
}
最后经过数据预处理,进行了数据集的标签可视化,如图1所示。
1.2 模型训练
训练阶段,神经网络模型主要采用了以特征金字塔和Darknet53相结合作为backbone的YOLOv3算法,并基于考场监考的任务特点在YOLOv3网络结构基础上进行了如下改善。
(1)设定1个anchor box,只有检测到人体目标时人体附属的属性信息才有判定的价值,同时考虑到坐姿下人体目标大小基本一致,因此YOLOv3只需要1个anchor box来检测人体目标类别,极大地提升了检测效率。
(2)修改任务输出,将YOLOv3输出的80个类别的分类置信度向量改为本任务所需的人体属性分析向量,每个人体目标框后携带8个属性的置信度(纸条,手机,书本,扭头,斜视,说话,埋头,探头),改善后的输出与YOLOv3输出对比如图2所示。
(3)加入注意力机制,基于考场人员坐姿特点,加入注意力机制模块(convolutional block attention module,CBAM),对于给定的中间特征图,CBAM按顺序推导出沿通道和空间两个独立维度的注意力图,然后将注意图相乘到输入特征图进行自适应特征细化。通道注意力聚焦在“什么”是有意义的输入图像,为了有效计算通道注意力,需要对输入特征图的空间维度进行压缩,对于空间信息的聚合,常用的方法是平均池化。空间注意力聚焦在“哪里”是最具信息量的部分,这是对通道注意力的补充。为了计算空间注意力,沿着通道轴应用平均池化和最大池化操作,然后将它们连接起来生成一个有效的特征描述符,如图3所示。
CBAM可以无缝集成到任何CNN架构中,开销可以忽略不计,并且可以与基础CNN一起进行端到端训练。对于考场特殊环境下的考试人员,与违规行为有关的属性(如书本、扭头)往往集中在上半身区域,因此加入CBAM模块,尤其是CBAM中的空间注意力图将有效地提升目标检测与属性分析的准确率,在残差网络中加入CBAM模块后如图4所示。
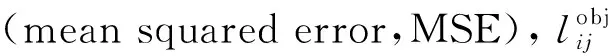
L=Lt+Lc+La
(1)

(2)

(3)
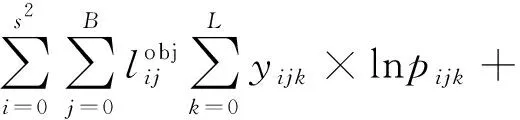
(1-yijk)ln(1-pijk)
(4)
(5)进行预训练,本地采集视频数据非常耗时,为了提高人体属性分析最后的准确率,需要利用主流数据集的预训练模型来初始化网络参数。结合考场任务的需求,最终选择了WIDER数据集,WIDER数据集一共包含13 789张图像,共57 524个行人边界框,并且为每个行人标注了14种属性,每种属性包含存在、不存在两种情况。WIDER数据集与其他数据集对比如表2所示。

表2 行人属性识别数据集Table 2 Pedestrian attributes recognition data set
模型预训练使用标准的YOLOv3网络,将输出网络属性向量修改为WIDER数据集所需的14个2值属性向量,并在每一个残差块后添加一个CBAM模块,以准确高效的提取人体上半身属性信息。
预训练完成后初始化YOLOv3网络,输出修改为任务所需的1个anchor box并携带8个2值属性向量,在本地数据集上进行再次训练,获得最终模型。
1.3 模型部署
模型运行阶段,利用部署在考场的高清摄像头采集视频数据流,并接入到视频处理设备。视频处理设备主要进行视频解帧与帧图像预处理,以符合神经网络数据输入。
将模型导入考场边缘设备中,视频处理设备的输出视频帧作为输入数据,边缘设备同时输出所有考场人员目标检测框和属性分析值,并根据属性分析值的结果作出实时的考场行为判断,整体部署如图5所示。
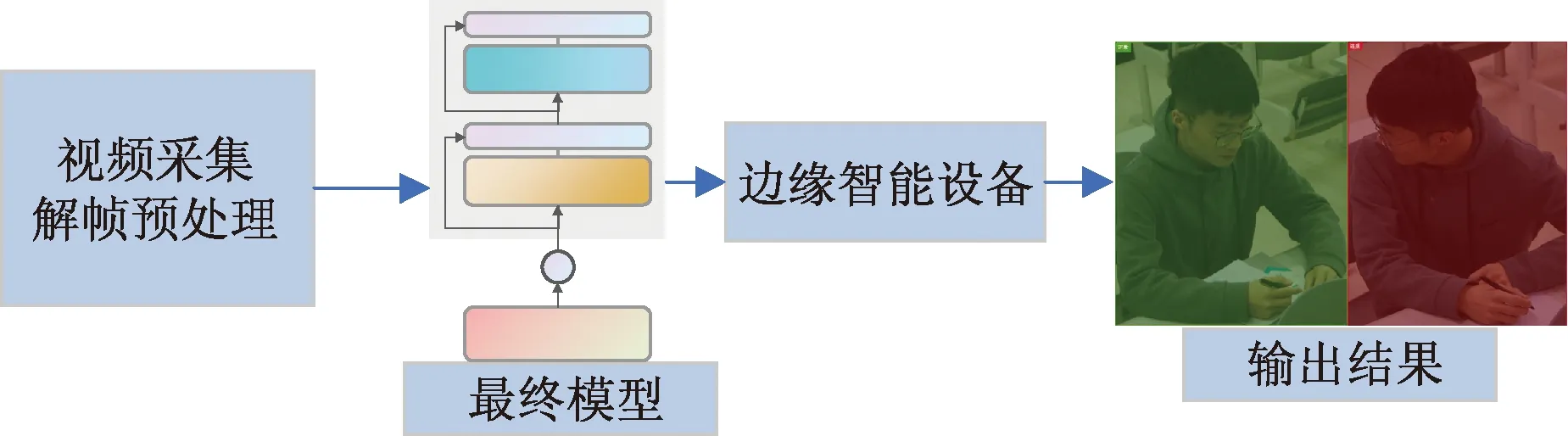
图5 整体部署Fig.5 Overall deployment
2 实验
利用摄像头和视频处理设备将视频采集解帧后输入边缘智能设备,分三组分别检验正常考场行为、各种违规行为、正常与违规行为。实验运行部分结果如图6所示,可以发现,只有当所有人体属性值均未检出才会判定为正常行为;如果检测出1条或多条属性,将判定为违规行为。

图6 模型实验结果Fig.6 Experimental results of ours
为了验证模型改善方案对最后本实验改进的YOLOv3模型结果的影响大小,并确定最终采取的措施,在WIDER数据集上进行了anchor、损失函数、预训练三种改进方案的消融实验,评价指标采用mAP(mean average precision),分别以mAP50和mAP75以度量在WIDER数据集14个属性上平均性能,实验结果分析如表3所示。
实验结果发现,三种措施对于mAP50和mAP75指标都有一定提升,且设置anchor提升效果最为明显。
原因为:①唯一确定的anchor能够使得网络对数据集上的预测框拥有一个正确的先验认识,使得边界框的预测更加容易,参数学习更加轻松,从而提升检测效果与效率;②损失函数的改进能够让模型学习到更好的坐标回归参数,使得模型预测的坐标位置更加准确,进而最终提升属性检测准确率。
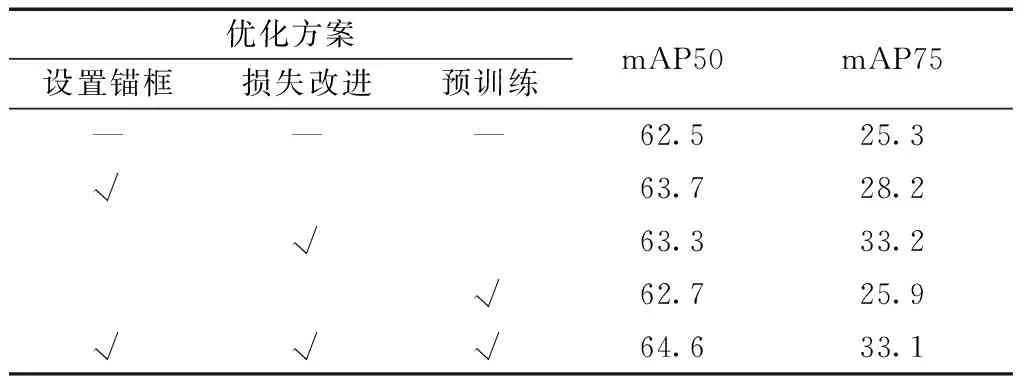
表3 消融实验mAPTable 3 Ablation study mAP
为了分析模型在实际监控中对比传统方案的效率与准确性提升程度,利用WIDER数据集、本地采集数据集、WINDER+本地数据集三种数据组合分别测试传统行人属性识别算法PANDA、MLCNN和本实验改进的YOLOv3模型(简称Model)表现。
三种方案都需要进行预训练和迁移学习,才能在实际的考场视频上进行属性分析和行为判别,模型训练过程对比如图7所示。
可以发现Model相比MLCNN和PANDA,模型具有优良的训练曲线,曲线在中前段就很快收敛到低值,中后段也更加平稳,反映出模型泛化推理阶段具有更好的鲁棒性。
三种方案学习过程的准确率对比如图8所示。
从准确率上对比可以发现Model相比PANDA和MLCNN,学习曲线在后半段趋于平滑稳定,也具有更高的性能指标,更符合实际考场应用需求。
将三种方案部署于考场,并对考场行为视频长时运行进行汇总和分析,评价指标采用行人属性识别常用的mA(mean accuracy),mA计算公式为
(5)
分析结果如表4所示。由表4可知,模型准确率与推理速度相对于传统属性分析算法具备一定优势,原因为:①YOLOv3集成了SSD多尺度预测、全卷积(fully convolutional networks,FCN)、特征金字塔(feature pyramid networks,FPN)、DenseNet特征复用等多种特性,具有工业部署的优势;②改进的网络中加入了CBAM注意力模块,在预训练阶段能很好地提取到人体上半身局部属性信息;③由于本地数据集采集自室内环境,场景单一,没有明显遮挡,简化了anchor box与属性向量等因素,使得WIDER+Local的迁移学习方案获得了三种算法上的最佳效果。
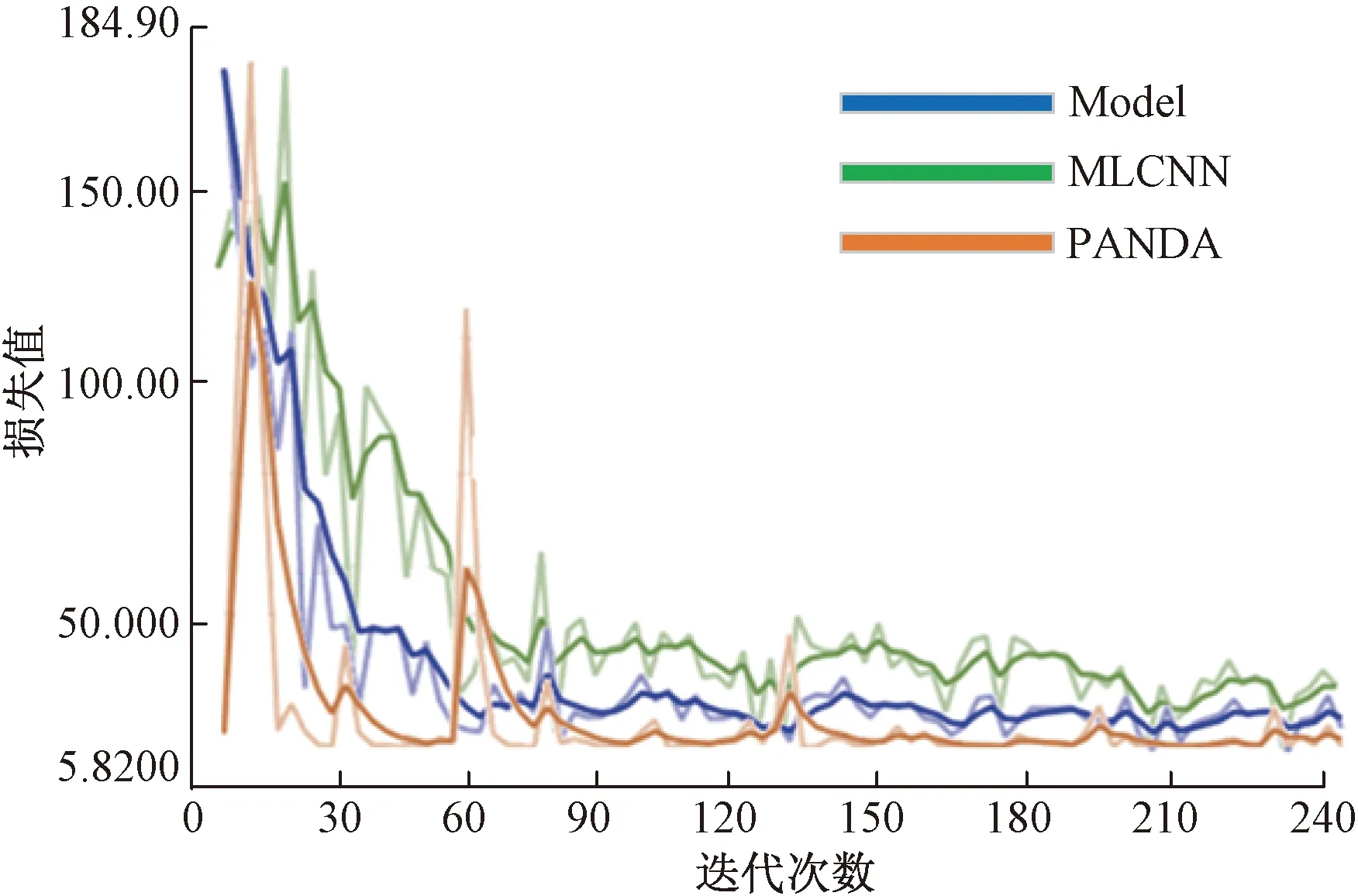
图7 模型训练过程对比Fig.7 Comparison of training process
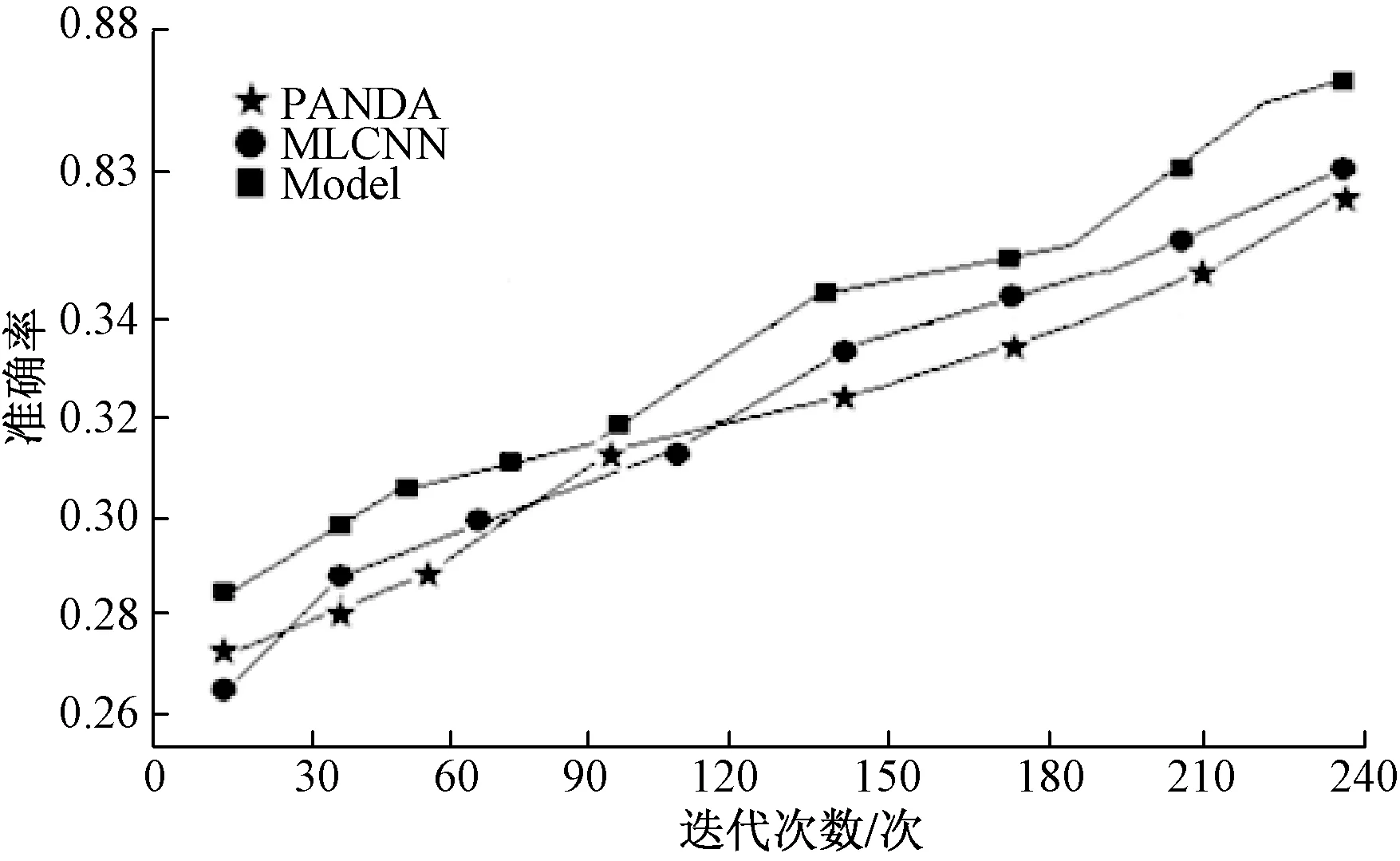
图8 三种模型学习过程对比Fig.8 Comparison of learning process of three models
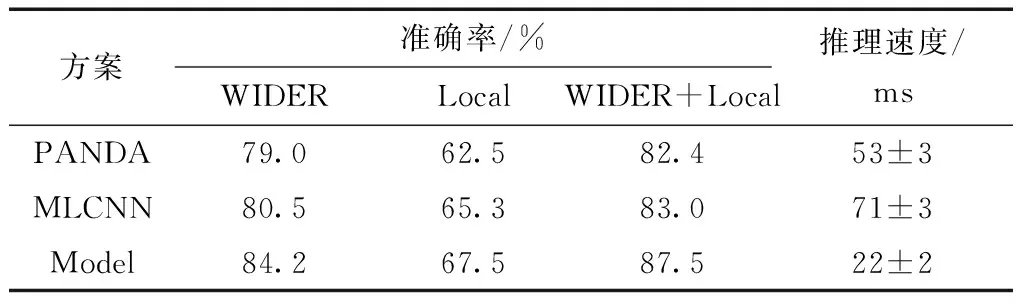
表4 准确率mA和推理速度分析Table 4 Analysis of accuracy mA and reasoning speed
对各属性预测准确率的进一步分析可以发现,由于加入了通道注意力和空间注意力机制,在WIDER数据集上可以提取到非常良好的人体上半身局部属性特征。而书本、纸条、手机等属性因为预训练数据集没有相关样本而本地采集样本又较少,因此最终扭头、斜视、说话、埋头、探头等与人体局部特征相关属性上表现明显好于其他非人体局部特征相关属性;同时纸条属性又属于小目标,相较于书本和手机的检测精度更低,所有属性最终检测准确率如图9所示。
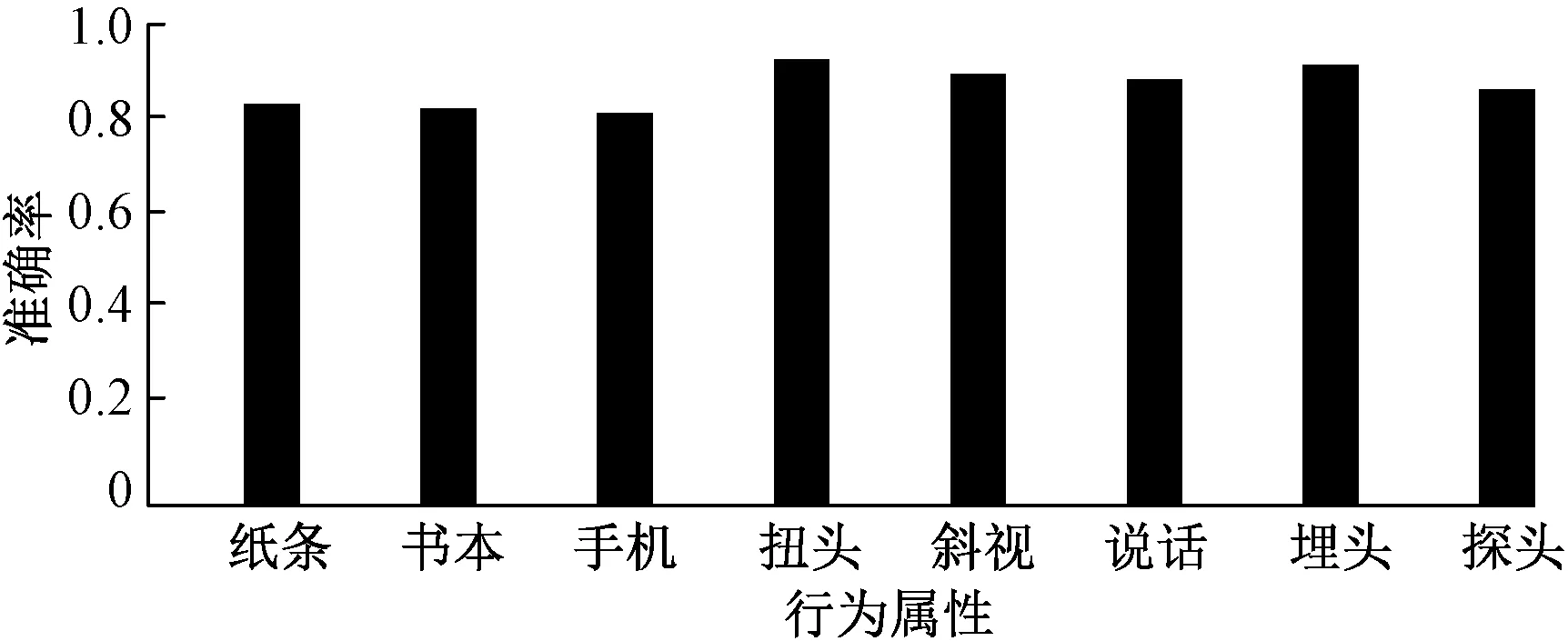
图9 各属性检测准确率对比Fig.9 Comparison of accuracy of attributes
3 结论
虽然行人属性识别领域由于问题场景的复杂性、拍摄角度不同、相同属性类内差异巨大、光线变化、类内和类间遮挡等问题而仍然存在很大的挑战。但是在实际的考场监控场景中,由于摄像头角度固定、室内无明显光学变化、检测的目标单一、类内无遮挡等天然的优势,使得利用YOLOv3改进后的模型能较好地同时执行人体检测和人体属性分析任务。
基于人体属性分析的考场行为识别也具有不可避免的缺陷:①由于问题的特殊性,需要对本地采集数据进行精心的标注;②由于本地数据集采集数量有限,无法胜任实际应用,需要借助大型人体属性数据集的预训练参数;③人体属性分析属于静态帧的行为识别方法,没有加入时序信息,在一些情况下会造成错误的判定,如弯腰捡东西、举手提问等。
鉴于此,应根据需要加入人工复核机制,或增加检测属性,或增加视频采集时长,而这些措施无疑都增加了算法的复杂性与操作的难度。
