一种红外与可见光图像信息交换融合网络
2022-08-18曹金亮薛伟民蔡雨含王安红
曹金亮,薛伟民,蔡雨含,王安红
(太原科技大学 电子信息工程学院,太原 030024)
红外与可见光图像融合可以将传感器捕获到的不同模态信息整合成一张图像[1]。根据辐射差异,红外图像可以区分目标与背景,捕获具有热信息的目标并处理成有显著特性的像素组合,但其对背景或低热能辐射目标成像效果差,而可见光成像可以很好的弥补这一不足[2],因此,将红外与可见光信息融合在学术和应用领域都具有重要意义。
传统的图像融合算法可分为图像信息提取和特征融合[3-8],公式表示为:
(1)

近年来,基于深度学习的红外与可见光图像融合技术取得了较更高的性能[9]。为了充分融合图像信息,应在信息提取过程中考虑特征融合以便联合优化。对此,本文提出了图像特征通过神经网络的交叉流动进行密集交换和融合的算法,构建神经网络同步进行信息提取和融合,将固定的融合策略转化为训练得到的高度自适应网络参数权重。
此外,由于融合网络在训练时没有相应的标准数据(ground-truth),许多融合网络并没有将成对的红外与可见光图像作为输入对网络训练,或者采用单输入-单输出的网络结构,使得参数不完全适合红外和可见光图像融合,且融合结果并不能准确还原真实的光照场景。为此,本文提出了一种交叉融合框架(CrossFusion-Net),用于生成包含红外和可见光信息的融合图像。首先,设计了一个具有双输入、交叉连接结构的信息交换自编码网络(IEA-Net),用于特征提取和融合并将红外与可见光图像成对输入进行训练。同时,融合策略由网络结构实现,使得每个源图像的深度卷积特征通过一个双分支编码器交换。其次,提出了一个补偿分支用来获得结构特征和光照特征。第三,设计了一个信息提取模块(Cut-in模块)从源图像中提取多尺度特征。最后,集成模块将所有特征整合在一起,并使用解码器进行重构。实验结果表明,本文的交叉融合网络在客观和主观评价方面都具有很好的性能。且在TNO Image Fusion数据集上能够恢复真实的光照场景。
1 网络架构
1.1 本文提出的信息交换深度图像融合网络
本文提出的信息交换融合网络如图1所示,红外图像、可见光图像同时输入IEA编码器,在IEA编码器中进行特征提取和信息交换产生融合图像;其次,由补偿支路提取的红外和可见光图像作为补偿信息,整合输入IEA解码器进行图像融合。
图1所体现出的信息交换融合网络融合思路由公式表述为:
(2)

图1 信息交换融合网络示意图Fig.1 The diagram of the proposed information-interchanging integration framework
(3)
它们直接将源图像中的结构和光照信息传递给融合图像,使融合后的图像包含更多的结构信息,准确还原真实光照。
1.2 交叉连接结构的信息交换自编码网络(IEA-NET)
如图2所示,本文提出的交叉连接结构的信息交换自编码网络(Information Exchanging Autoencoder Network,IEA-NET)包括编码器和解码器两部分,为双输入和单输出结构。

图2 交叉连接结构的信息交换自编码网络IEA-NETFig.2 The network structure of IEA-NET
IEA-NET编码器的两个分支对称,所以这里只介绍一个分支。首先,一个卷积层扩展输入图像通道数;然后,将扩展后的图像特征传递给三组Cut-in模块进行三个阶段的特征提取和信息交换。
IEA-NET中使用交换支路,如图2所示。该结构将不同分支的特征交换到对称分支相应位置。每组Cut-in模块提取信息后,交换两分支信息。每个分支会得到来自对称支路的信息补偿,并由残差模块整合这些特征。最后,所有的特征通过四层卷积重建为融合图像。本文使用网络结构融合特征,因此该网络具有更强的泛化能力和融合性能。
1.3 Cut-in 模块
Cut-in模块结构如图所3所示。该模块有两个路径:主路径含三个卷积层,每个卷积层连接一个ReLU层;第二条路径含一个卷积层和一个ReLU层。最后,两条路径通过Concat层连接。为了保持输入和输出通道数目相同,每个路径中的通道数将会在输入时减半。Cut-in块有三个优势:1)该模块进行密集连接;2)这种体系结构改善了通过网络的梯度流,使网络更容易训练;3)该结构在提取特征时保留多尺度信息。
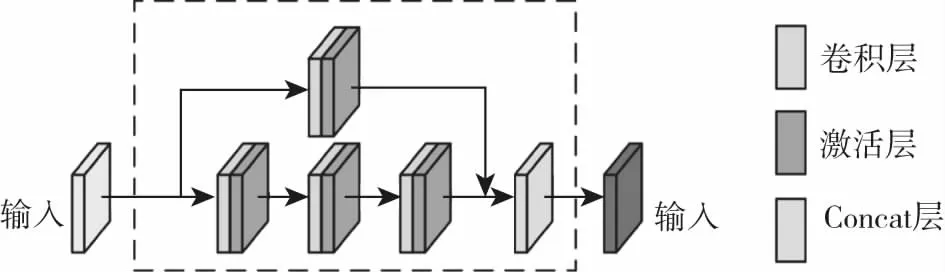
图3 Cut-in模块结构示意图Fig.3 The network structure of cut-in block
1.4 补偿支路(Compensation Branch)
如图4所示,补偿分支获取和传递结构和光照信息并直接连接IEA-NET残差模块。

图4 补偿支路结构示意图Fig.4 The network structure of compensation branch
补偿支路结构如图4所示,首先用两个卷积层提取信息,然后通过最大池化层提取每个图像块中最大像素获取结构特征。一方面,该支路提取图像边界信息,增强结构信息;另一方面,提取图像更大范围相似区域的背景信息,获取更准确的光照信息。接着Cut-in模块进一步提取特征,并对特征进行反卷积。最大池化和反卷积可能会改变特征图大小,为了确保最终图像大小与原始图像相同,本文使用‘填充/裁剪’层恢复图像大小。最后,通过残差模块进行信息整合,从而得到原始图像的结构信息和光照信息。本文算法总共使用了六个这样的分支,其中三个对称的分支使用不同窗口大小的最大池层(2/4/6)获得三种不同尺度的特征,相应地,反卷积层采用不同的步长(2/4/6).
1.5 损失函数与网络训练
双输入结构有两幅源图像但只有一幅融合图像,本文采用的数据集是由配对的红外和可见光图像组成。因此,我们设计双路结构损失函数:Lssim和Lms-ssim,计算公式为:
Lssim=1-SSIM(0,I)
(4)
和
Lms-ssim=1-MSSSIM(0,I)
(5)
其中SSIM(O,I)为结构相似性损失,MSSSIM(O,I)是多尺度结构相似性损失。可见光图像支路和红外图像支路损失LVIS和LIR计算公式为:
LVIS=γ×Lssim(Ovis,I)+β×Lms-ssim(Ovis,I)
(6)
LIR=γ×Lssim(Oir,I)+β×Lms-ssim(Oir,I)
(7)
其中Oir是红外源图像,Ovis是可见光源图像,I是融合图像。γ设为0.8,β设为0.2.
本文采用RGB-NIR Scenes数据集[10]的954幅配对的红外和可见图像训练网络,通过对这些图像进行随机裁剪(500×500的块)、随机镜像、Resize和旋转,共获得8 000幅训练图像。训练集与验证集的比例为7∶1,同时所有图像转换为灰度图像,以图像对送入网络进行训练。本文算法使用Adam优化器优化网络,学习率设定为0.001.在训练中,若验证集损失函数指标在5个epoch不发生变化,学习率减半,直到小于0.000 01会停止训练,如果验证损失10个epoch不变,训练也会停止。本文算法使用GTX2080Ti GPU训练,使用的深度学习平台为Keras.
2 实验结果和分析
2.1 对比实验设置
本文方法与基于CNN[11]的方法、DeepFuse[6]、DenseFuse[8]和FusionGAN[7]进行比较。所有参与比较方法的参数都严格按照其原文设置配置。所有比较方法都是文章中给出的预训练模型,若无预训练模型,本文将严格按照原论文中训练参数训练网络。
此外,本文还使用8个公认的融合指标评估结果。包括平均梯度AVG,反映小细节对比度和图像中纹理变化特点和融合图像的锐度。Qabf为从源图像传输到融合图像的信息量,Labf为自源图像的信息丢失量,SSIMa[12]为结构相似性,MS-SSIMa[13]为多尺度结构相似性,MEF代表融合后图像的曝光质量, Nabf计算融合图像的伪影并表示为数值[14]。PSNRa为峰值信噪比,是基于误差敏感的图像质量评价指标。
2.2 对比实验结果
本文对五种图像融合方法主观视觉评价和客观质量评价进行了分析。本文选择CNN[11],FusionGAN[7],DeepFuse[6]和DenseFuse[8]四个有代表性的结果进行实验比较,融合结果如图5所示。
从整体视觉感知角度看,CNN[11]和FusionGAN[7]方法所产生的图像具有明显的模糊和伪影,不能清楚反映图像细节(如图5(a)和(b)所示)。DeepFuse[6]、DenseFuse[8]和本文结果没有明显视觉差异(如图5(c)、(d)和(e)所示),这三种方法都能准确地恢复原始图像细节并提供清晰的视觉感知,但本文结果拥有更清晰的边缘信息(如图5中第三行的图像中的吉普车和图5中第四行图像中的人)。
(1)对场景光照环境恢复能力的主观评测:
在恢复光照场景方面,CNN[11]方法在夜景上表现不佳(如图5第一行图像),其他四种方法表现良好。FusionGAN[7]、DeepFuse[6]和DenseFuse[8]错误地将白天场景还原为夜景(如图5第二行图像),CNN[11]和本文方法准确地恢复了光照场景。在这五种方法中,只有本文方法能在保持良好视觉感知的同时,准确地恢复白天和夜晚场景。
(2)客观指标评测:
如图5所示, DeepFuse[6]、DenseFuse[8]和本文算法结果很难在人类感知上找出区别。为了验证算法的有效性,本文对TNO数据集中的20组图像进行测试并取平均值,实验结果展示在表1中。最佳值用粗体表示。本文方法获得7个度量(Labf、Qabf、Nabf、SSIMa、PSNRa、MEF、MS-SSIMa)最佳值,以及一个度量(AVG)第二佳值。SSIMa和MS-SSIMa值表明,本文的方法可以更好地保存结构信息。此外,最高的MEF值表示本文的方法具有良好的光照信息,而PSNRa和AVG值表示本文的方法具有良好的图像质量。Qabf值表示本文的方法获得的图像与源图像更相关,并且由于Labf值最小表示本文的图像信息丢失最小。因此,本文的方法对于红外和可见光图像融合最有效。

图5 TNO数据的视觉效果对比图Fig.5 Visual results on the TNO dataset

表1 与四种优秀方法的客观指标比较
2.3 电力图像应用
在训练数据集中加入制作的电力图像数据,重新训练网络使其更适合电力数据图像融合。几对具有代表性的实验结果如图6所示。
(1)图像边缘信息感知效果的提升:
本文的图像融合算法可以有效提高图像边缘信息感知效果,如图6第一行图像所示,框中的变压器配电柜在红外图像和可见光图像中都不清晰,经过本文算法的融合,图像可以更清晰的表现配电柜的纹理细节和边缘信息。又如图6第二行图像所示,可见光图像由于光照不足,基本处于不可见状态,而红外图像的边缘模糊,经过融合,框中的绝缘子具有更明显的边缘信息。

图6 电力融合图像的视觉效果Fig.6 Visual results on power image dataset
(2)图像细节信息感知效果的提升:
本文的图像融合算法可以有效提高图像的细节信息感知效果。如图6第三行图像所示,红外图像变压器图像条纹模糊,而可见光图像由于光照原因,无法很好表现细节信息。经过图像融合,如第三行框中融合图像所示,变压器条纹清晰,拥有良好细节信息和更好的视觉效果。再如图6第四行框所示,融合图像相较于可见光和红外图像具有更好的视觉效果和细节信息。
(3)红外图像和可见光图像的信息综合:
如图6第5行所示,虽然红外图像对焦失败,但经过图像融合,本文算法依然保留红外图像的热量信息并与可见光图像信息融合得到一副视觉效果良好的图像。如图6第六行框中电线杆所示,融合的图像具有可见光图像和红外图像独有的特征,并整合在一张图像中。
2.4 与其他图像融合算法比较
图7给出了本文算法与其他深度学习红外可见光融合图像的对比,可以看到:CNN[11]算法融合后的图像视觉效果不佳,融合图像有大量伪影。FusioGAN[7]方法对图像细节恢复较差,图像纹理不够清晰。Densefuse[8]整体对比度低。只有本文提出的算法,有良好的细节,同时还有较强的对比度,目标边缘轮廓更加清晰。

图7 电力融合图像的对比视觉效果Fig.7 Visual comparison results on power image dataset
表2给出与其它算法的客观指标对比,CNN[11]虽然在数值上有优势,但是其视觉效果很差。本文算法虽然没有取得数值的第一,但综合主观视觉效果和客观数据结果,本文算法在拥有良好视觉效果的同时,还有较高的客观指标,因此,可以认为是一种有效的电力图像融合模型。

表2 与三种优秀方法的客观指标比较
3 结论
提出了一种具有很强泛化能力的红外和可见光图像融合方法。本文算法使用了一个交叉连接结构的信息交换自编码网络(IEA-NET)和六个多尺度补偿支路进行图像融合。根据主观和客观评测的验证,本文所提出的方法可提供有效的红外与可见图像融合。通过对实际电力图像的融合,本文所提算法能够有效提升边缘信息质量和图像细节质量,能够将红外和可见光图像信息整合为一张图像,并取得了较好的性能。
