面向分布式机器学习训练的计算节点激励策略
2022-08-06孙灏
孙灏
(安徽广播电视大学 滁州分校,安徽 滁州 239000)
网络带宽的限制,将大量的数据传输到远程云端进行处理和存储是不切实际的。由于移动边缘计算技术的快速发展,边缘节点配备了存储和计算功能,因此本地的数据存储和处理成为可能。在边缘网络应用分布式机器学习算法可以在边缘计算节点上实现高效的机器学习模型训练。这种学习技术使边缘计算节点可以协作建立一个共享模型,同时将所有训练数据保留在本地。边缘计算节点会在其本地训练数据上计算对当前全局模型的更新,然后由服务器对其进行汇总。新模型的汇总完成后,所有边缘计算节点都可以访问相同的全局模型以计算其新更新。本研究探讨了如何在网络边缘设计激励机制以进行高效的分布式机器学习的问题,提出了基于深度增强学习的激励策略。
1 问题建模
机器学习模型是基于训练数据学习的。训练数据样本j由两部分组成:向量xj是机器学习模型的输入,另一部分是机器学习模型的输出yj。为了实现机器学习训练,每个模型都有一个关于模型参数ω的损失函数。模型学习过程就是将一组训练数据样本上的损失函数最小化。我们将fj(ω)定义为训练数据样本j的损失函数。
假设网络中有N个边缘节点,每个边缘节点n拥有一个本地的训练数据Dn,其损失函数的定义如下所示:
(1)
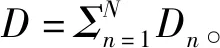
(2)
模型训练的目标是找到能全局损失最小的模型参数,即
ω*=arg minF(ω)
(3)
由于大多数机器学习模型固有的复杂性,一般情况下很难找到式(3)的解析解。因此,可以通过分布式边缘梯度下降算法来求解式(3)[1]。由于同步的方法比异步的方法具有更高的训练精度[2],因此本工作基于同步方法,每个边缘计算节点在每一轮进行τ次迭代。
令cn表示边缘节点n执行一个数据样本的CPU周期数。由于所有训练数据样本{xj,yj}j∈Dn具有相同的大小,因此边缘节点n运行一次局部迭代所需的CPU周期数为cnDn。然后,边缘节点n进行一个局部迭代所消耗的CPU能量为[3]:
(4)
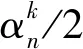
(5)
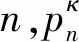
(6)
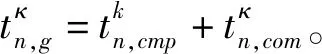
(7)
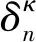
(8)
其中,λ是权重。
在边缘学习系统中,边缘节点和服务器通过进行协商以最大程度地增加自己的利益。 具体而言,第κ轮中节点n和服务器的目标可以公式化为约束优化问题。对于边缘节点n,
(9)
对于服务器,
(10)
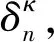
2 最优算法
在本节中,使用单轮优化方法解决激励机制设计问题。
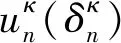
(11)
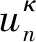
(12)
因此,能得到
(13)
结合式(7)、(8)、(12)和(13),优化问题(10)的目标函数具有如下的形式:
(14)
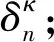
3 基于深度增强学习的激励策略
尽管可以通过单轮次优化的方法来设计激励机制,但是对于服务器而言,要获取边缘计算节点的私有信息还是很困难的。而且,网络环境是动态变化的。对于用户而言,预测真实的网络环境是一个严峻的挑战。因此,单轮次优化方法并不能做出合适的决策。深度增强学习方法能够从过去的经验中基于当前状态和给定的奖励来学习的行动决策。将服务器的定价决策改写为:
(15)
作为学习代理的服务器在深度增强学习设置中与环境交互,其中服务器是定价决策的主要组成部分,环境定义了规则、限制和奖励机制。在第κ轮次中,服务器观察到状态sκ并选择一个动作pκ。完成此操作后,当前状态将传输到下一个状态sκ+1,并且服务器将收到奖励rκ。深度增强学习的目标是找到将状态sκ映射到动作pκ的最佳策略π,该策略可以最大化预期的折现累积奖励。
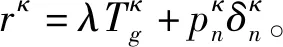
将服务器的策略定义为πθ,其含义为给定状态sκ,在动作空间A下动作aκ的概率分布。基于深度增强学习的学习机制的目标是找到满足以下等式的最佳策略:
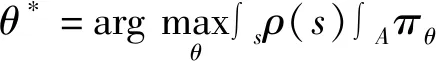
(16)
其中,Q(s,p)是在执行动作a之后测量状态s的未来累积奖励的期望的动作值函数,ρ(s)是初始状态的概率分布。
利用Actor-Critic算法和近端策略优化方法来学习最优的策略。分别用πθ(·丨s)和Vø(s)表示Actor和Critic,其中θ是Actor的未知参数,而ø是Critic的未知参数,然后,可以通过随机梯度上升和随机梯度下降分别学习πθ(·丨s)和Vø(s),即
θ'=θ+l1▽θL1(θ)
(17)
ø'=ø-l2▽øL2(ø)
(18)
其中,θ'是Actor更新后的参数,ø'是Critic更新后的参数,l1和l2是学习率。
由于服务器与边缘计算节点之间的交互是动态的,采用深度神经网络来近似πθ(·丨s)和Vø(s)。Actor网络πθ可以表示为具有两个隐藏层的多层全连接神经网络。给定状态输入sk,Actor网络将输出pκ的高斯分布。Critic网络Vø由一个具有两个隐藏层的多层全连接神经网络和一个带有记忆模块的递归神经网络组成。
在学习之前,服务器初始化其状态s0和学习参数。在边缘学习任务的第κ轮训练中,服务器首先通过将其状态sκ作为Actorπθ的输入来确定其价格pκ。然后,边缘计算节点将根据式(12)确定其CPU周期频率δκ。然后,边缘计算节点从服务器下载全局模型,并通过他们自己的训练数据更新模型。边缘计算节点s完成本地模型训练并上传其本地模型参数后,服务器将通过汇总分布式模型来更新全局训练模型,并计算其奖励rκ。最后,服务器将更新其状态,并将状态、动作和奖励信息存储到重放缓冲区B中。此外,服务器将在每B轮更新其Actor和Critic。具体来说,它首先设置要采样的Actor参数。然后,它将利用存储在重放缓冲区中的历史数据来估计随机梯度,以优化θ和ø并更新其Actor和Critic。经过M次优化后,它将清除重放缓冲区并开始对新的训练数据进行采样。
4 实验评估
对于5个边缘节点的场景,Actor网络和Critic网络的隐藏层分别具有300个和75个节点。我们在Critic网络中采用了最新的存储网络差分神经计算机。每个边缘计算节点的训练数据大小Dn为服从U(0,5,1)的均匀分布,单位为GB;cn服从U(10,30)的均匀分布,单位为周期/位。为了验证本策略的有效性,采用一个包含40个移动节点的移动轨迹数据集。随机选择五个节点作为边缘计算节点。对于每个节点,在完成每一轮的模型训练后,节点将在遇到接入点时立即上载更新后的模型。
首先展示损失函数和奖励函数在训练过程中随时间的变化。图1(a)显示了损失随时间的变化,观察到损失在开始时非常迅速地减小。这是因为在训练开始时,近似值不精确,这会导致较大的损失值;随着训练的进行,损失可以迅速减少到最小,随后损失值变得非常平稳。图1(b)是训练期间的平均奖励,观察到奖励会随着时间单调增长。
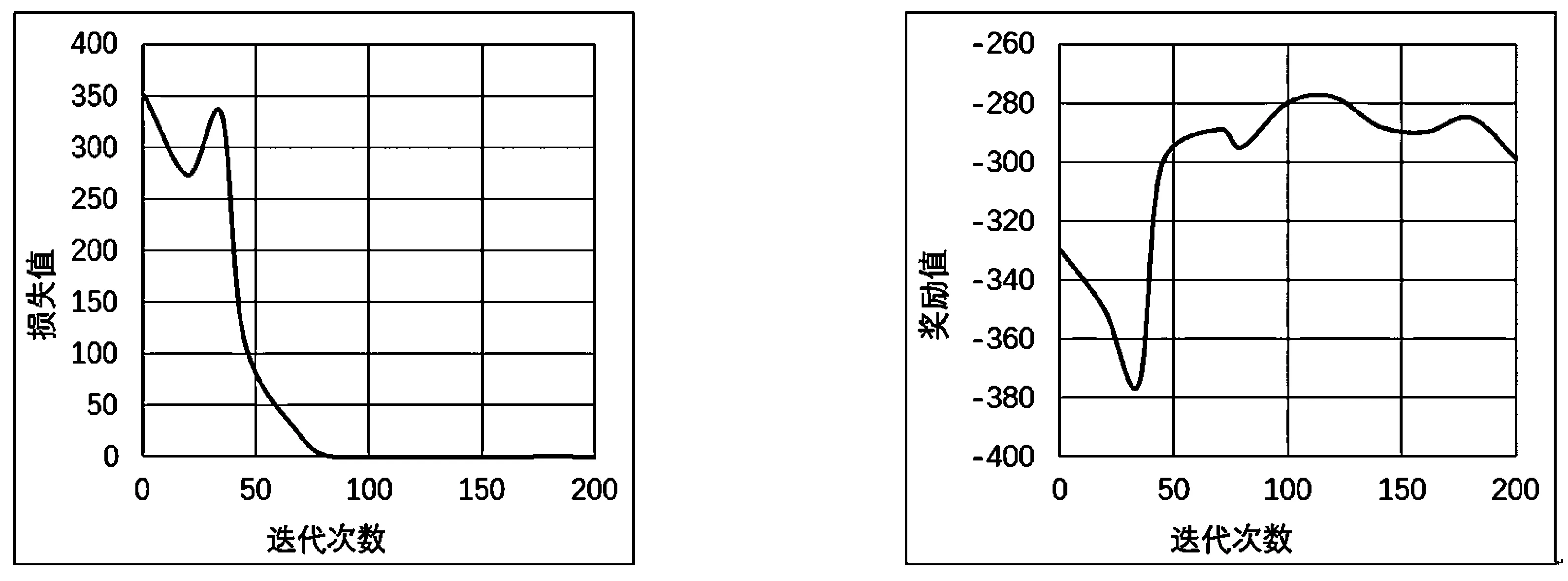
(a) 损失值变化 (b) 奖励值变化
将本方法与两个基准策略进行比较:第一种是贪婪策略,它是一种启发式算法,可以从重放缓冲区中贪婪地选择具有最大奖励的策略;第二个是随机策略,其中服务器在每个回合中随机选择定价策略。对比的结果如表1所示。表1展示了每一轮服务器的平均成本,训练时间和代价。与其他两种方法相比,基于深度增强学习的方法实现了最低的成本。从表1中可以看到,基于深度增强学习的服务器在每一轮中获得的训练时间最少。在具有最低成本的同时,基于深度增强学习的策略所付出的代价更低。

表1 成本、训练时间和代价的对比
5 结论
本研究提出了一种在动态环境中面向分布式机器学习的激励机制,其中每个计算节点需要在动态计算环境中进行本地的学习任务,而且还需要在动态的网络环境中传输本地模型的更新。首先,分析第κ轮的最优解,并提出一种最优算法;其次,提出了一种基于深度增强学习的策略;最后,采用真实的数据集对提出的策略进行验证。在未来的工作中,将本策略部署到真实的应用环境,进一步验证策略的有效性。
