基于知识图谱的大学生职位推荐方法
2022-08-04徐红艳王碧莹王嵘冰
徐红艳,王碧莹,冯 勇,王嵘冰
(辽宁大学 信息学院,辽宁 沈阳 110036)
0 引言
在国内经济稳定、高速发展及国际重视中国市场的背景下,各行业都在扩大生产经营规模,藉此产生了更多的职位需求.在信息技术的推动下,这些职位需求数据在网络空间迅猛增长和快速传播,进而引发信息过载问题[1].在海量的职位信息中找到适合的职位对求职者来说是一件复杂而又耗时的事情,尤其对缺乏工作和社会经验的应届大学生,职位选择显得愈发困难.
当前的职位推荐系统大多是热门职位推荐或是基于关键词匹配的推荐,然而热门职位推荐缺乏针对性,基于关键词匹配的推荐不能满足用户的个性化职位需求[2].知识图谱作为一种新兴知识处理技术,它可以从知识层面表述知识实体及知识间的关联,将其应用于职位推荐领域可以更好地处理职位供需间的匹配,带来更为准确的职位推荐.面对互联网中海量的招聘数据,基于知识图谱的职位推荐不仅能满足求职者对所需职位的高覆盖率,也能体现出职位推荐的个性化特征.因此,本文提出了一种基于知识图谱的大学生职位推荐方法,通过借助知识图谱工具显示招聘资源间的结构关系以及职位的分布情况,根据知识图谱中展现的关系,将与求职大学生有着直接或间接关系的职位推荐给他们,这样有助于提高大学生的就业率.本文通过引入知识图谱相关技术,开发出来的职位推荐系统能为高校毕业生提供一个简洁高效的职位推荐平台,使学生可以更精准地获取到适合自己的职位信息,这样可以加快毕业生的求职速度,有效地缓解学生的就业压力,也能为企业节约时间和招聘成本.
1 相关工作
1.1 知识建模
知识建模是知识图谱构建技术的基础.有2种搭建知识图谱的方法:自顶向下(top-down)和自底向上(bottom-up).自顶向下是预先定义好本体和数据模式,然后把实体加进知识库系统中,这种搭建方法必须采用当前的部分结构化知识库系统作为基础知识库系统,FreeBase知识库就是采用这种方法构建而成的.自底向上是从一些对外界开放的数据信息中获取实体,选择可靠性比较高的放到知识库系统中,然后对顶层的本体模式进行搭建,很大一部分知识图谱就是依靠自底向上的方法搭建出来的,这里面最具代表性的是Google和微软构建的知识库,这也符合互联网数据内容知识产生的特点.
1.2 知识抽取
知识抽取中最重要的是如何从异构数据库中自动抽取信息内容以获得替代的知识单元.相对于垂直领域的知识图谱,其数据通常采用2种方式获得:1)业务本身的生成数据信息,这类数据大体上是指企业内部的数据库表,并将其以结构化形式存储起来;2)以网页形式存在的非结构化数据,这类数据一般是从Internet上抓取的公开数据.第1种类型的数据通常经过简单的预处理就可以用作AI系统后续的输入数据,而后1种类型的数据就要依靠自然语言的处理技术来获得结构化的数据信息.这一点恰好是知识抽取部分的一个难题,它涉及的核心技术包括实体抽取、关系抽取以及属性抽取[3].
1.2.1 实体抽取
实体抽取指的是从文本数据中自动检索出命名实体[4],它的目的是在知识图谱中构建节点.实体抽取的质量很大程度上影响着后面知识获取的质量和获取速度,所以说实体抽取是知识抽取环节中最基础也是最重要的模块.
1.2.2 关系抽取
文本语料在前面的实体抽取后获得的是一系列分散开来的命名实体,为了更好地从中获得语义信息,在把这些实体和概念关联在一起之前,必须从与之对应的语料中获取出实体间的关联信息,这样才能得到知识系统的网状结构.关系抽取技术,归根结底就是从文本语料中抽取实体之间关联关系的一项技术[5].
1.2.3 属性抽取
属性抽取的最终目的是要从不一样的信息源中收集指定实体的属性相关信息,以达到详细描述实体属性这一目的[6],如针对某款笔记本电脑,可以从互联网中获取多源异构的数据,从中得到其品牌、配置等信息.
如果把实体的属性值看作是一种特殊的实体,那么属性抽取实际上也是一种关系抽取.百科类网站提供的半结构化数据是通用领域属性抽取研究的主要数据来源,但具体到特定的应用领域,涉及大量的非结构化数据,属性抽取仍然是一个巨大的挑战[7].
1.3 知识表示
知识表示旨在通过计算机来展现知识的可行性和有效性,它想要达到数据结构与控制结构的统一,因此,不仅要注意知识存储上容易出现的状况,也要想到知识使用方面的问题.知识表示可以看作是叙述一组事物的约定,从而将知识表示为能够被机器识别处理的数据结构[8].
2 基于知识图谱的大学生职位推荐方法描述
本文提出了一种基于知识图谱的职位推荐方法,推荐方法的框架如图1所示.通过将知识图谱的概念引入到职位推荐中,以此来弥补当前职位推荐方法中存在的推荐精度不高、缺乏个性化等问题.所提方法的思想:首先将知识图谱映射到低维稠密向量空间里,以获取职位信息中的职位相似度;接下来依据职位信息生成用户的行为矩阵,进而计算出职位之间的相似度;然后通过融合这2种类型的职位相似度,得到融合后的职位相似度矩阵,并以该矩阵作为基础,得到用户对职位库中所有职位的估算分值;最后依据这个分数得出推荐给用户的职位排序列表.下面分别对方法中的核心环节加以详细描述.
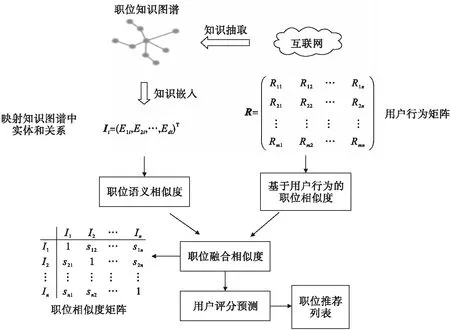
图1 基于知识图谱的大学生职位推荐方法框架
2.1 向量化表示
关于知识建模等构建知识图谱的相关技术和方法已经在第1节中详细介绍,下面介绍知识图谱的向量化表示.
这里使用TransE算法将知识图谱中的实体与关系嵌入到低维向量空间中[9],TransE算法的主要思想是将三元组(h,r,t)中的关系看作从实体head到实体tail的翻译.其中,h是头实体的向量表示,r是关系的向量表示,t是尾实体的向量表示.通过不断调整三者的向量表示,使得h+r尽可能与t相等,即h+r=t,那么就说明知识图谱中的三元组成立.如果成立,TransE算法就必须达到公式(1)和公式(2)的要求:
对正样本三元组:h+r≈t
(1)
对负样本三元组:h+r≠t
(2)
在上面两式中,h+r与t的关系表示与向量相似度的近似等价程度.这里向量相似度通过计算欧氏距离实现,得分函数的公式如式(3)所示:
f(h,r,t)=‖h+r-t‖L1/L2
(3)
得分函数值越小,越有利于正样本三元组;得分函数值越大,对负样本三元组越有利[10].接着,TransE算法通过损失函数测试表示学习的效果,损失函数的计算如公式(4)所示:
(4)
其中,S是正样本的集合,S′h,r,t是三元组(h,r,t)的负样本.知识图谱中三元组的负样本是通过随机替换头实体h或尾实体t后经过大量训练得到的.以x表示公式(4)中方括号内的式子,则[x]+指的是max(0,x);γ表示函数间隔的大小,且γ>0.TransE算法通过不断地训练和优化算法,损失函数的值可以达到最小.算法通过不断地迭代来更新参数,直到收敛或者达到最大迭代次数,这时知识图谱中的实体就会被映射到向量空间中的相应位置[11].
2.2 相似度计算
本小节主要对系统中职位的相似度进行计算,分为2个部分:基于简历的职位相似度计算和基于用户行为的职位相似度计算.
本文所提方法的相似度计算有2个来源:1)通过提取用户简历中的信息计算其与职位的相似度;2)由用户在系统上对职位作出查看或收藏等用户行为而得到的职位相似度.最后融合这2种来源的相似度,以此获得最终的职位信息相似度.
2.2.1 基于简历的职位相似度
前文介绍了知识图谱中富含大量的语义信息,可以从语义的层面描述职位之间的相似度[12].2.1节里又详细地阐明了知识图谱中实体向量化表示的具体步骤,因此获得了实体在高维空间里的向量表示.接下来根据职位的嵌入向量,介绍职位语义相似度的详细计算.
首先,把知识图谱上职位信息的实体和关系都映射到d维空间里去,职位Ii嵌入一个d维的向量如公式(5)所示:
Ii=(E1i,E2i,…,Epi)T
(5)
这里的Epi指的是职位Ii在第p维上嵌入向量的数值.
然后使用欧几里得距离计算后获得的评分函数,对知识图谱中的实体和关系做嵌入操作[13].还需使用它测算向量的语义相似度,以此来精准表达用户的简历与职位信息之间的相似性.在这一步之前,需要先用公式(6)来计算职位之间的距离:
(6)
通过公式(6)的计算最终欧几里得距离大于等于零,再经过公式(7)的计算,可以把它控制在区间(0,1]:
(7)
这个式子的计算结果越大,就表明用户的简历信息与职位信息之间的语义相似度数值越大.如果该数值是等于1的,简历信息与职位信息之间的语义相似度就是最大的,可以认定两者相似程度很高;反之,如果该值是趋近于0的,就认定两者之间毫无关联.
2.2.2 基于用户行为的职位相似度
根据用户行为得到的所有信息可以看出用户自身对于职位信息的关注[14].基于物品的协同过滤推荐的主要思路也是如此.基于物品的协同过滤推荐可实现领域范围之内的推荐,是依据访问系统的全部用户对物品做出的用户行为进而得到物品之间的相似度,接着把认定是相似的物品按照用户行为的历史数据进行推荐.本文将用户对职位信息的用户行为划分成许多个类别,这里以最为寻常的评分信息作参照对职位信息进行向量化表示.
假设本文实现的系统里有访问系统的m个用户U=(U1,U2,…,Um)和被单位发布出来的n个职位I=(I1,I2,…,In),那么用户对职位的评分信息可以表示为如公式(8)所示的m×n矩阵Rm×n:
(8)
接下来,要把职位Ii表示成如公式(9)所示的一个m维的向量,它的数值意味着在每一个维度上都有相应的求职者对职位的一个打分.
Ii=(R1i,R2i,…,Rmi)T
(9)
这里利用余弦相似度公式得到基于用户行为的职位信息相似度[15],具体的计算如公式(10)所示:
(10)
公式(10)计算出来的数值越大,就代表职位Ii与职位Ij之间被用户行为的影响程度越深.一旦计算结果等于1,就可以说这2个职位从某种程度上来讲是一样的;如果计算结果等于0,就意味着这2个职位之间完全无关.另外,如果这个用户u没有给职位i打出评分数据,那么Rui的数值就是零.
2.2.3 相似度融合
根据获取到的简历信息对于职位相关信息的嵌入向量,可以获得基于简历信息的职位相似度simknowledge_graph.同时,依据用户行为而生成的职位相关的评分矩阵,可以获得基于用户行为的职位相似度simusers_behavior.这里用加权的方法对这2种相似度进行融合计算,可以获取所需的最终相似度数值,详细的计算方式如公式(11)所示:
sim(Ii,Ij)=α·simknowledge_graph(Ii,Ij)+(1-α)simusers_behavior(Ii,Ij)
(11)
这里α代表2种相似度算法的融合度,它的区间在[0,1],表示最终职位相似度中根据简历信息计算的职位相似度的占比大小.α的数值等于1说明最终相似度的结果全部是根据简历中用户信息获取的职位相似度数值;α的数值等于0说明最终相似度结果全部是根据用户行为计算出来的相似度值.职位相似度融合之后的区间也是[0,1].
对全部用户信息与职位信息之间的相似度进行融合以后,基于职位信息的相似度通过矩阵的方式展现如下:

这里,sij表示职位Ii和职位Ij之间的相似度,sij=sji.另外,如果i等于j,sij的值为1,即这里全部的职位信息和它们自己的相似度数值都是1.
2.3 推荐列表生成
这里帮助求职者进行偏好职位推荐的基本思想:首先根据2.2节计算获取到的简历信息与职位之间生成的相似度矩阵以及求职者对于职位的用户行为生成的矩阵,然后通过预测来获得每个求职者给未评价过的职位内容的打分数值;最后系统根据求职者对每个职位内容的预测评分生成一个按照评分由高到低排序的职位列表.
生成职位相似度矩阵之后,这里通过pui指代预估出来的用户u对职位i的分值,借助公式(12)就可以计算出pui的数值.
(12)
其中sij表示职位Ii和职位Ij之间的相似度,Ruj指代现存评分矩阵里用户u给职位j打出的分值,N(u)是用户u已经给出评分的职位信息的全部集合,S(i,k)指代和职位i相关性最高的k个职位的全部集合.
经过公式(12)计算得出的预测评分数值越高,代表该职位与用户过往评分数值很大的职位相似程度越高,其在系统中职位推荐列表里的位置排列更靠上些.
在本文实现的职位推荐系统中,系统给每位求职者都推荐一个含有N个职位在内的详情列表.系统给求职者作出推荐的依据如下:如果求职者对职位的预测评分数值很高,那么就有理由认定该用户对这个职位偏好强烈,这个职位信息在列表中的位置就靠前,也更易被访问系统的求职者注意到;反之,这个职位的信息可能出现在列表中相对靠后的位置,甚至可能因为数值过低没有出现在列表中.按照这个思路,系统最终会生成一个包括N个职位信息在内的、依据数值由高至低排列的职位推荐列表.
3 实验分析
3.1 数据集与实验环境介绍
本系统通过网络爬取技术抓取互联网招聘数据[16],数据包括23 213条节点数据,11种关系类型在内的关系数据126 559条.下面将其按照7∶3的比例分为训练集和测试集,并针对这2个数据集进行实验.
本文实验环境如下:
1)操作系统:Windows 7
2)CPU:频率 2.60 GHz
3)编程工具:PyCharm Community Edition 2019.2.3和Python
4)显卡信息:Intel(R)HD Graphics 4000
3.2 指标和参数选取
本文实现的职位推荐系统是向用户推荐偏好的职位信息,因此针对系统生成的职位推荐列表,选取2个数据集采用交叉验证的方法进行实验分析,从准确率(Precision)和召回率(Recall)2个指标评价职位推荐系统的推荐结果.
为了更加清楚地解释准确率和召回率,本文定义一些符号如下:
TP(True Positive)代表推荐系统已经推荐,且实际的用户行为也确实发生了的样本;
FP(False Positive)代表推荐系统已经推荐,但实际的用户行为并没有发生的样本;
FN(False Negative)代表推荐系统没有推荐,但实际的用户行为发生了的样本.
准确率的定义如公式(13)所示:
(13)
准确率计算公式的含义是,在所有被职位推荐系统预测推荐的样本中实际推荐的概率.
召回率的定义如公式(14)所示:
(14)
召回率计算公式的含义是,在职位推荐系统实际推荐的样本中被预测推荐的职位概率.
这里融合度的变化范围是[0,1],设定融合度的变化数值为0.1,共做11组实验,即观察融合度数值以0.1为步长的情况下准确率和召回率的变化情况.融合度数值等于0,代表职位推荐方法全部采用基于简历信息与职位信息的相似度算法;融合度数值等于1,代表推荐方法使用的都是基于用户行为的相似度算法.随后,用数据集对这些算法做实验分析,以此得到指标状况最佳时的融合度数值.下面对不同融合度数值下的各个算法进行实验分析.
图2为2种相似度算法在不同融合度数值下准确率指标变化情况,图3为相同条件下召回率的变化情况,当融合度数值为0时,表示基于简历信息与职位信息的相似度算法的指标情况.由图2和图3可以发现,当融合度值在0.6的时候,融合相似度算法在2个指标上都达到了最高点,表明在这个融合度下,该融合算法在准确率、召回率上的表现都是最佳的.

图2 不同融合度下的准确率

图3 不同融合度下的召回率
3.3 实验结果
本文选取使准确率和召回率都到达最理想效果的融合度0.6,验证当融合度值确定时本方法在不同近邻数K下的准确率和召回率,使用主流应用的基于内容的推荐方法、协同过滤推荐方法以及混和推荐方法作为本文提出的推荐方法的对比方法.通过对比实验比较这4种方法在近邻数的不同选值下准确率和召回率的情况.近邻数K的值分别选取50,70,90,110和130,实验10次取得平均值作为实验的最终结果.
从图4和图5中可以看出,本文提出的推荐方法在准确率和召回率上表现良好,说明在引入知识图谱概念的基础上,对2种相似度进行融合,推荐的效果比基于内容的推荐方法和协同过滤推荐方法相比要更好,当近邻数为100时,本文提出的方法在准确率上提升了约5%,在召回率上提升了约3%,弥补了当前推荐方法的不足,同时也说明了本文提出的职位推荐方法的优越性.
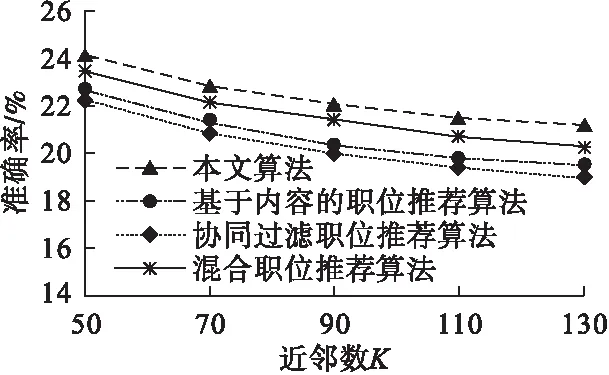
图4 不同近邻数K下的准确率

图5 不同近邻数K下的召回率
4 结束语
针对大学生面对海量招聘信息时的职位选择困惑,本文提出了基于知识图谱的职位推荐方法,通过使用图形数据库Neo4j构建一个求职招聘领域知识图谱,将知识图谱中的实体映射到低维稠密向量空间里,对其中的实体和关系进行向量化表示,计算用户的简历信息与职位信息之间的相似度,同时根据用户行为计算其与职位间的相似度,通过融合相似度计算得到用户对职位的预测评分,进而生成职位推荐列表,以提高推荐系统的精准度.经对比实验验证,本文所提职位推荐方法能够更好地满足当前大学生的就业需求.
