基于非对称增强注意力与特征交叉融合的行人重识别方法
2022-02-02李媛媛郝兴军张立国
金 梅,李媛媛,郝兴军,杨 曼,张立国
(燕山大学 电气工程学院, 河北 秦皇岛 066004)
1 引 言
行人重识别主要解决跨摄像头、跨场景下行人的识别与检索问题,在智能安防、公共安全、刑侦等领域有着广泛的应用前景,是计算机视觉领域研究的热点[1]。传统行人重识别方法[2,3]采用先手工设计图像特征,再进行相似度度量,适应性差、计算效率低,很难应用在场景复杂的大数据集上。随着卷积神经网络[4,5](convolutional neural network, CNN)和计算机硬件的快速发展,基于深度学习的算法[6,7]逐渐代替了传统方法,行人重识别的性能得到了显著提升。
早期的行人重识别研究是以提取图像的全局特征为主[8,9],由于实际场景较为复杂,不同摄像机拍摄到的同一行人图像[10]在光线、姿态、遮挡、视角等方面存在差异,不利于行人重识别。局部特征[11]可以在特定范围内捕获稳定的行人特征,取得更好的检索效果,但会出现局部范围内行人对不齐[12],导致需要引入姿态估计模型[13]从而增加计算量等一些新的问题。为了进一步提升行人重识别性能,相关学者们开始探索其他方法研究。
引入注意力机制可以在增加少量参数的情况下显著提升计算精度,在行人重识别任务中受到广泛应用。Chen T L等[14]将注意力机制与多样性正则化无缝地嵌入网络中学习多样性特征,但忽视了局部特征,只利用全局特征预测行人重识别。Li W等[15]提出的HA-CNN结合软、硬注意力,以多个分支学习行人的全局、局部特征并融合,优化未对齐的行人图像,但网络结构复杂。Xu J等[16]为解决行人遮挡的问题提出的AACN结构,主要分为PPA(pose-guided part attention)和AFC(attention-aware feature composition)两个子结构,前者学习人体重要的区域特征并计算各区域可视化分数,后者将上述区域特征与全局特征融合。Tay C T等[17]提出的AANet结构,在一个框架中结合注意力机制提取到行人的全局、局部以及属性特征,并分别预测这3类特征。但这两种方法提取到的特征缺乏边缘、纹理等信息。
虽然以注意力机制为基础的网络模型在一定程度上改善了行人重识别的性能,但提取到的特征信息不充足。
为获得较为全面的行人信息,Zhao H Y等[13]提出SpindleNet定位人体的关节点并进行区域划分来提取局部特征,然后与全局特征融合,此方法只利用了高层信息,并且需要额外训练骨骼关键点检测网络。Wang C等[18]提出的Multi-scale &Multi-patch不依赖其他辅助模型,使用尺度标准化块统一处理多层特征实现融合,融合时没有考虑特征之间的差异性,不能消除网络深度不同带来的隔阂。Wang Y等[19]采用自注意力模块使网络选择性地关注特征的重要区域,并对中、高层特征进行加权融合,但未考虑低层特征的细节信息。
基于上述行人重识别方法提取到的特征种类单一、网络复杂、需要依赖其他辅助模型等问题,本文提出了一种非对称增强注意力与特征交叉融合网络模型(asymmetric enhanced attention and feature cross fusion network, AEFC-Net),可获得全面有效的行人信息进行行人重识别。该方法引入注意力机制设计了非对称增强注意力模块(asymmetric enhanced attention module,AEM),从多个角度出发提取显著特征,同时考虑到网络各层特征的差异,利用特征交叉融合模块(feature cross fusion module, FCM)实现多特征融合,以弥补仅利用单一种类特征进行行人重识别预测的不足,并平均切分最后输出,获得行人的局部特征。本文提出的方法将在Market1501、DukeMTMC-reID与CUHK03这3个公开数据集上进行有效性验证。
2 非对称增强注意力与特征交叉融合网络模型
2.1 网络结构
本文提出的AEFC-Net结构如图1所示。

图1 AEFC-Net结构图Fig.1 AEFC-Net structural diagram
该特征学习分为上、下两个支路:(1)上支路(黑箭头部分)以预训练好的ResNet50模型为骨干网络快速获取特征,移除原网络后面的全局平均池化GAP层以及全连接FC层,并且将卷积块Conv5_x的步长设置为1,不进行下采样操作,使最后两个卷积块输出的特征大小相同;(2)下支路(蓝箭头部分)主要由非对称增强注意力模块AEM及特征交叉融合模块FCM构成。
AEM采用了多重池化聚合的跨邻域通道交互策略对Conv3_x 、Conv4_x与Conv5_x层的通道进行调整,使网络重点关注3个特征中的行人区域,学习显著性通道,增强预测目标的判别性。FCM则对AEM强化学习后的特征进行优化处理,逐步消除低、高层特征之间的像素位置及信息差异,使得调整后的特征有效地融合在一起。
为了使网络学习到更加丰富的行人特征,本文对上、下支路(红箭头部分)的输出特征进行相加,然后将特征水平分割成K块,并且使用GAP对每个块进行处理得到K个局部特征向量,使每个块均获得局部范围内的稳定特征。上述特征向量分别送入由FC层与Softmax层构成的K个分类器,预测输入图像的行人信息。
2.2 非对称增强注意力模块
注意力机制是调整信息重要性的有效手段,可用于提取辨别性的图像特征,大部分注意力机制采用池化对输入特征的空间维度进行压缩,但是不同池化关注的信息不同并且会损害信息的完整性。
针对这一问题,本文提出一种非对称增强注意力模块AEM,其分为最大池化跨邻域通道交互分支MPA与平均池化跨邻域通道交互分支APA两个特征处理支路,采用全局最大池化GMP和全局平均池化GAP分别压缩特征,并且使用跨邻域通道交互策略获取每个通道与局部范围内相邻通道间的关系,捕获显著特征,然后将两分支的输出与原特征相加融合,获得多种显著信息与背景信息并存的特征。非对称增强注意力模块如图2所示,其中L、H、W分别为模块的长、高、宽。

图2 非对称增强注意力模块图Fig.2 Asymmetrical enhanced attention module diagram
AEM利用1×1卷积对输入进行通道交互与信息整合得到特征F,然后分为两个支路学习行人的显著特征。其中MPA分支利用GMP进行空间压缩,聚合特征空间中的显著性信息,得到一个1×1×C大小的特征向量。
利用变形操作将向量维度进行变换得到C×1×1,利用k×1卷积建立每个通道与局部范围内跨通道间的关系,其中卷积核k的大小根据通道数自适应获取,本实验中设置为C/4-1。通过Sigmoid层得到每个通道的权重值,与原特征逐通道相乘,输出加权后的特征,可以表示为
F1=δ{R[M(F)|k=C/4-1]}⊗F
(1)
式中:F1为MPA分支输出特征向量;δ为Sigmoid函数操作;R为一维卷积计算;M为全局最大池化操作;k为一维卷积核大小;C为输入特征通道数;F为分支输入特征向量。
APA分支的通道权重的计算方法及过程与MPA分支一样,区别在于此分支采用GAP聚合特征空间的整体性信息,池化后的特征向量经跨邻域通道交互策略得到各通道与局部范围内相邻通道间的关系,通过Sigmoid层得到C个权重值,与原特征通道相乘后输出另一个加权后的特征,可以表示为
F2=δ{R[A(F)|k=C/4-1]}⊗F
(2)
式中:F2为APA分支输出特征向量;A为全局平均池化操作。
多重池化聚合的跨邻域通道交互策略在增强特征中有辨别力的通道的同时弱化了原背景信息,为了保持信息的完整,将输入特征与上述两个分支的输出特征相连,进行相加处理,可以表示为
Fc=F1+F2+F
(3)
式中Fc为AEM输出特征向量。
2.3 特征交叉融合模块
在卷积神经网络中,低层特征的感受野小,边缘、纹理等信息丰富,而随着层数的增加深高层特征包含抽象的语义信息,二者具有互补性。目前一些行人重识别的研究偏重于对高层特征的利用,忽视低层特征,导致细节信息的缺失,不能很好地满足行人重识别任务需求。针对上述问题,本文设计了FCM优化低层特征、提取高层特征, 消除二者间的差异,实现多尺度特征融合。特征交叉融合模块如图3所示。

图3 特征交叉融合模块图Fig.3 Feature cross-fusing module diagram
2.3.1 低层特征处理
首先,为实现多尺度融合,需要设置步长为2的3×3卷积对输入特征Xin进行降采样,减小尺寸,得到特征Xs;其次为了提取不同感受野的特征并且减少计算量,设置了3个分支:b1、b2及b3。每个分支分别采用不同数目不同扩张率的3×3conv,从上至下卷积数目、扩张率的设置如表1所示。

表1 FCM各分支卷积参数设置Tab.1 Convolution parameter setting for FCM branches
为了加强同级别信息的交流与传递,采用跳跃连接以及相加的计算方交叉式融合特征,可以表示为
X1=φ(Xs/d1)⊕φ(Xs/d2)
(4)
X2=φ(Xs/d2)⊕φ(Xs/d2)
(5)
X3=φ(X1/d5)⊕φ(X2/d5)
(6)
式中:X1、X2、X3表示各分支中处在同级别的不同扩张率的卷积融合得到的特征;φ表示3×3卷积计算;d为卷积核的扩张率大小。
3个分支的输出特征感受野各不相同但有着同等重要的作用,并且考虑到计算的问题,采用通道拼接的方式进行融合。因为拼接后会导致后续计算量增加,所以利用1×1conv进行降维处理,输出优化后的低层特征,可以表示为
X′=γ[φ(Xs/d1),φ(X1/d5),φ(X3/d7)]
(7)
Xout=P(X′)
(8)
式中:X′为3个分支特征通道拼接后的输出特征;Xout为输出的低层特征;γ表示通道拼接;P为1×1卷积计算。
2.3.2 高层特征处理
由于高层特征的语义信息丰富,与低层特征的处理相比,仅设置了两个分支:b4与b5,同样采用不同数目不同扩张率的3×3 conv,如表1所示。分支连接处采用与低层特征相同的处理方式,先拼接后降维,提取到高层特征,可以表示为
Yout=P{γ[φ(Yin/d2),φ(Yin/d5)]}
(9)
式中Yin、Yout分别为输入、输出的高层特征。
对上述提取到的特征相加处理,得到同时拥有多种信息的特征,有效地解决行人判别时,信息不充足的问题,可以表示为
Z=Xout+Yout
(10)
式中Z表示FCM输出特征。
3 实验结果分析
3.1 数据集
本文在Market1501、DukeMTMC-reID、CUHK03这3个主流公开的数据集上进行了充分的实验,各数据集属性信息如表2所示。其中,CUHK03数据集行人边界框分为DPM检测和手工标记两类,本文使用DPM检测的行人边界框并且使用第2种测试协议[20]。

表2 数据集详细信息Tab.2 Data set details
3.2 实验设置
本文实验是基于NVIDIA RTX 2080 Ti GPU上使用Pytorch1.2.0框架实现,计算机的操作系统为64位的Ubuntu16.04.6 LTS,Python版本为3.7.3。网络的训练周期数为60,训练时批次大小设置为32,初始学习率为0.1,经过40个周期后学习率调整为0.01。选择SGD作为优化器,动量设置为0.9,采用L2正则化,权重衰减因子设置为5×10-4。K个分类器交叉熵损失Loss0,Loss1,…LossK-1之和作为最终损失,训练时取K= 6。测试时将K个特征向量拼接得到完整的行人特征。
3.3 消融实验
3.3.1 AEM消融实验
为了验证AEM结构的有效性,本文在Market1501数据集上做了几组实验进行对比,结果如表3所示,“√”表示添加了该模块中的相应结构,“—”表示没有添加该模块中的相应结构。从没有AEM时开始实验,依次加入MPA、APA与Shortcut分支,由于MPA分支与APA分支计算方式及过程基本一致,所以只讨论了添加MPA分支时的情况。从表3中可以观察到,精度由低变高,AEM结构完整时达到最高,首位命中率Rank-1与平均精度均值mAP分别为93.5%、80.8%,证明了AEM的加入增强了模型对行人的重识别能力。

表3 AEM消融实验Tab.3 AEM ablation experiment (%)

表4 FCM消融实验Tab.4 FCM ablation experiment (%)
3.3.2 FCM消融实验
为了验证FCM结构的有效性,本文在Market1501数据集上做了一系列比对实验,结果如表4所示。首先,在没有FCM结构下,Rank-1和mAP分别为91.8%、78.1%;其次,先后添加了b1分支和b1、b4分支做了两组实验,精度均有提升且后者大于前者;最后,在b1、b4分支存在的基础上再依次加入剩余的b2、b3、b5分支,直至FCM结构完整。从实验结果可以看出,每添加一个分支都在一定程度上提升了模型效果,表明了FCM结构可以显著提高网络性能。
3.3.3 AEM、FCM数目消融实验
为了研究AEM与FCM数目对模型表现的影响,本文在Market1501数据集上做了各模块不同数目组合的实验,结果如表5所示。在不引入注意力机制与融合策略的情况下,Rank-1为91.3%,mAP为77.5%;在此基础上增加一个FCM时,模型效果明显提升;当在FCM存在的基础上再加入AEM时,效果进一步提升; 当AEM、FCM数目完整时,实验结果达到最好。

表5 模块数目消融实验
3.4 对比实验
将本文所提出的网络模型在Market1501、DukeMTMC-reID、CUHK03这3个公开数据集上与近几年的先进算法进行对比,结果如表6所示,“-”表示该算法没有在此数据集上实验。本文所有实验均未采用重排序Re-ranking算法优化结果。
从表6可以观察到,本文提出的方法在3个公开数据集上均取得了一些方面的提升。首先,Market1501数据集上的Rank-1和mAP分别达到了93.5%和80.8%,超越了其他对比算法。相比于表中性能优越的APDR[26]算法,本文方法充分利用特征间的互补优势,通过对其有效融合获取丰富的特征信息,取得了更好的表现;其次,本文方法在DukeMTMC-reID数据集上的表现同样优于对比算法,相比于PAN[21]等经典算法有大幅度提升,与新颖的DUNet[24]算法相比Rank-1、mAP显著提升了3.0%、4.9%;最后,在CUHK03数据集上,本文方法相较于先进的Ensemble[28]算法,Rank-1相差0.8%,但mAP提高了1.2%。
3.5 实验结果可视化
为了直观地展示本模型的行人重识别效果,本文选择在具有代表性的Market1501数据集上给定待查询图像进行行人重识别,如图4 所示。
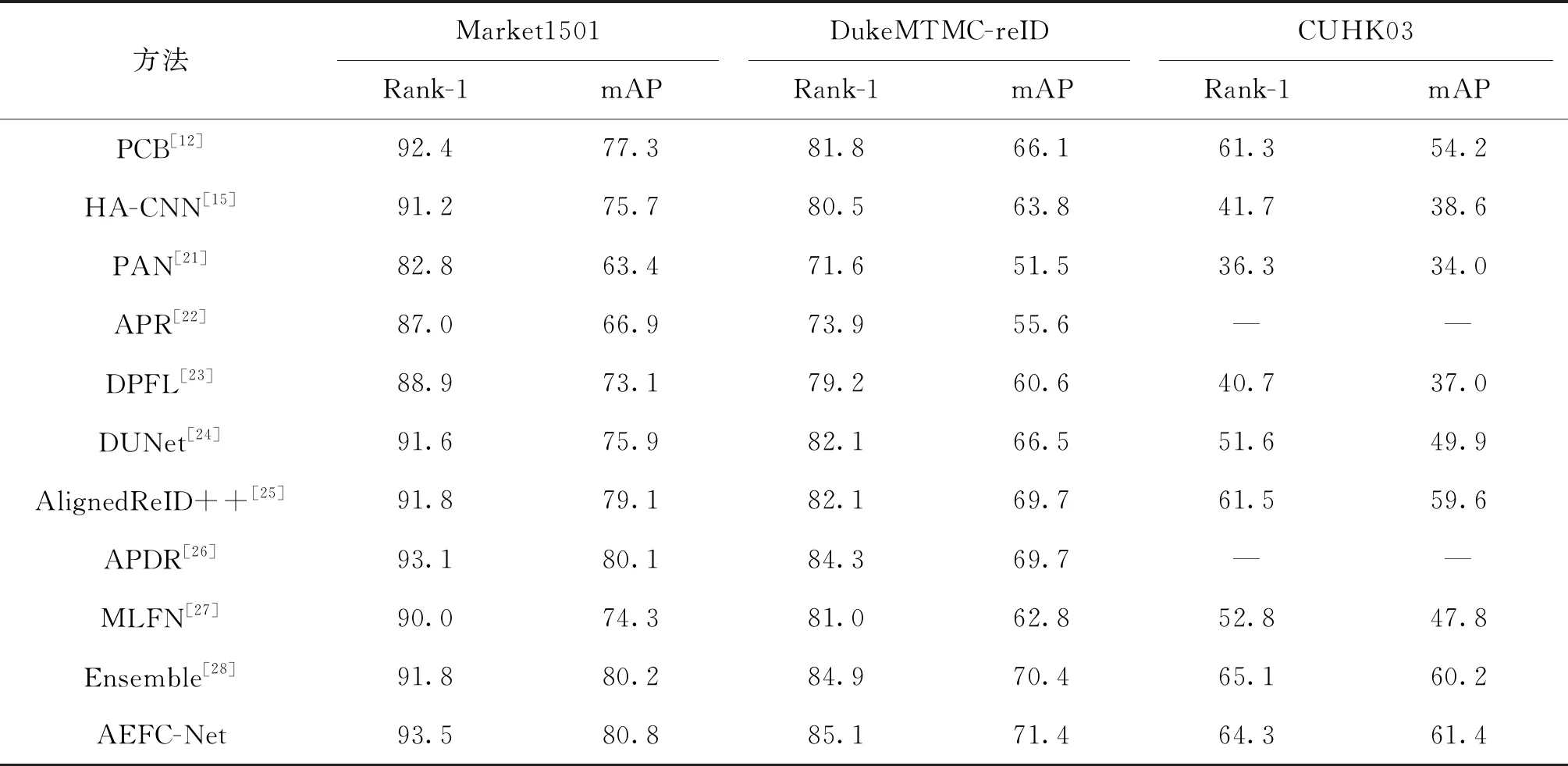
表6 在Market1501、DukeMTMC-reID、CUHK03数据集上与主流方法对比Tab.6 Comparison with mainstream methods on Market1501、DukeMTMC-reID and CUHK03 (%)

图4 Market1501数据集上给定行人前10位查询结果图Fig.4 The top ten query results of a given pedestrian on the Market1501
随机选取了3张行人图像进行查询,左侧的第1列为查询图像,右侧的10列为该行人前10位的检索图像,绿色框为正确识别,红色框为错误识别。
根据可视化结果可以看出,对同一行人检索的准确率较高,表明了本文方法的有效性。
4 结 论
针对目前多数行人重识别方法提取到的特征信息不充分、不具辨识性这一问题,本文提出一种基于非对称增强注意力与特征交叉融合的行人重识别方法,从以下3个方面提升重识别性能:(1)考虑网络不同层特征的差异性,对低、高层特征分别处理使其有效融合,达到信息互补的目的。(2)非对称结构的注意力模块在保护信息完整性的同时,加强辨别性特征,抑制无关干扰。(3)获取局部范围内稳定、可辨识的行人特征,使网络可以更好的应对行人遮挡问题。本文所提出的模型在多个公开数据集上进行了验证,都取得了较好的效果,从而证明了该方法的有效性。
