基于GPU并行的二维时空中子动力学MOC程序开发及验证
2022-01-27宋佩涛
邹 航,梁 亮,张 乾,*,宋佩涛,赵 强
(1.哈尔滨工程大学 核安全与仿真技术国防重点学科实验室,黑龙江 哈尔滨 150001;2.西安核创能源科技有限公司,陕西 西安 710077;3.中国辐射防护研究院,山西 太原 030006)
为解决中子在不均匀介质中的输运问题,特征线方法(MOC)以其几何普适性的优点,成为近年来反应堆物理设计分析的研究热点。为提高三维非均匀全堆芯输运计算效率,国际上提出2D/1D耦合方法来加速计算[1-3],其中高效率的2D-MOC求解器在全堆输运计算中占有重要地位。由于MOC方法本身具有计算量大、收敛较慢的不足之处,且在中子动力学计算中变得尤为明显,因此国内外提出了一系列加速收敛方法在数值层面上提高MOC的动力学计算效率。其中,粗网有限差分方法(CMFD)能显著降低每个时间步输运计算的迭代次数,但由于动力学问题本身收敛较慢,美国密歇根大学提出多级瞬态方法(TML)并应用在MPACT上[2,4],TML采用预估矫正准静态(PCQS)的思想,将点堆中子动力学、CMFD以及输运计算相耦合,使得在大时间步长条件下能获得较高计算精度,且在CMFD计算中使用1G-CMFD加速MG-CMFD收敛[5]。西安交通大学使用简化源缩放法(SSSM)解决CMFD固定源计算中通量幅值与形状收敛速度不匹配的问题,并在PCQS中点堆中子动力学部分使用在线高阶拉格朗日插值来获得更高精度的反应性计算值[6]。随着图形处理器(GPU)在算力、功耗方面的快速发展,针对GPU自身硬件特性而开发的并行算法已经被大量应用于科学计算领域。MOC方法具有天然并行特性,国内外已开展了基于GPU加速MOC计算的相关研究[7-14]。本文针对全隐式差分方法,同时采用CUDA编程和CMFD加速技术,实现基于GPU并行的二维MOC瞬态计算。
1 中子输运动力学计算理论
1.1 中子输运动力学方程
求解中子输运动力学方程的核心思想是对其进行时间差分[3],并利用先驱核方程积分方法将先驱核方程与中子输运方程进行耦合,推导得到一系列与稳态方程形式相当的瞬态固定源方程(TFSP),并利用稳态中子输运方程求解方法对其进行逐时间步求解。中子输运方程和先驱核方程如式(1)与式(2)所示:
χp,g(r,t)(1-β(r,t))SF(r,t)+Sd,g(r,t))
(1)
k=1,2,…,6
(2)
式中:vg为能群g下的中子速度;φg为位置r处方向为Ω的中子角通量密度;Ck为缓发中子先驱核浓度;Σt,g为宏观总截面;βk为缓发中子份额;λk为衰变常量;Ss,g为散射源项;SF为裂变源项;Sd,g为缓发中子源项;χp,g为瞬发中子裂变谱。各源项定义如式(3)~(6)所示。
(3)
(4)
(5)
(6)

对式(1)的时间项进行全隐式差分,可得式(7):
(7)

(8)

(9)
(10)
(11)
(12)
(13)

1.2 CMFD加速
多群CMFD TFSP方程可由中子扩散动力学方程[2,4-5]推导得出,格式如下:
(14)
(15)
对式(14)使用与推导输运动力学方程相同的时间差分方法,可得式(16):
(16)
(17)
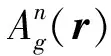
(18)
(19)
(20)
Str=AΦ+BFΦ+C
(21)
将各算子代入式(16)可得CMFD TFSP方程:
(M-S)Φ=χFΦ+AΦ+BFΦ+C
(22)
1.3 MOC动力学计算
由1.1节可知,2D MOC动力学方程可写为如下形式[2,4,6]:
(23)
其中瞬态固定源项定义与式(9)相同:
(24)
在原有源项上加上瞬态固定源项后,式(24)可由稳态MOC求解器逐时间步求解,且现有的并行加速算法不需作较大改动即可套用至动力学计算上。
2 并行算法设计及程序开发
本文基于上述理论,以现有的栅格物理程序ALPHA稳态版本为基础,调用其MOC求解器及CMFD求解器来开发其动力学计算功能。ALPHA中采用GPU加速CMFD及MOC计算,MOC计算中采用特征线-单能群并行策略,CMFD计算采用红-黑排序并行求解策略[6-12],具体计算流程如图1所示。

图1 GPU加速的MOC耦合CMFD求解瞬态固定源问题流程图Fig.1 TFSP solution procedure for MOC with CMFD acceleration based on GPU
整体计算流程如下:1) 在CPU端进行初始稳态和动力学的初始化计算,包括几何预处理和截面初始化等计算所需信息;2) 将几何、截面信息从系统内存一次性拷贝到显存;3) 执行CMFD计算,为MOC迭代提供初值;4) 通过本征值和通量偏差判断整体迭代是否收敛。
CMFD计算主要包括:1) 粗网多群参数归并及线性系统的构造,由于各粗网参数和CMFD方程组中各方程相互独立,可将粗网参数归并与方程构造分配给各GPU线程并行执行;2) CMFD源项更新也可在GPU端并行执行,每个线程负责单个粗网单个能群的源项计算;3) CMFD线性系统求解,本文所采用的线性方程组解法为逐次超松弛迭代(SOR),为保证在GPU并行求解,本文采用红-黑排序,将相互独立的方程求解分配给不同的GPU线程并行执行,因此求解过程中有1/2的方程可并行求解,随后提供更新后的结果,用于另一半方程的并行求解;4) CMFD收敛后,利用CMFD结果更新MOC细网通量,为下一次MOC计算提供初值。采用GPU线程并行后,1个线程执行1个粗网内所有细网在单个能群下的通量更新。
MOC将采用CMFD更新后的通量进行计算。本文采用Jacobi格式的输运扫描算法进行输运求解,其中源项计算采用GPU多线程并行求解,输运扫描计算采用的特征线-能群并行的策略。
3 数值验证
本文采用TWIGL基准题与2D MINI-CORE基准题测试程序精度及效率。计算平台采用多核工作站,工作站所用CPU为Intel Core i7-8700K,所用GPU为NVIDIA Geforce 2080Ti。
3.1 TWIGL基准题
TWIGL基准题[15]是一个两群三区问题,其几何结构及堆芯网格划分如图2所示。TWIGL堆芯内部由3种不同材料区域构成,通过改变区域1材料的热吸收截面来驱动堆芯功率发生瞬态变化。ALPHA的计算参数如下:栅元尺寸2.0 cm×2.0 cm,每个栅元使用5×5矩形网格划分,特征线间距0.02 cm,角度离散采用32个辐角和最佳三极角,初始稳态和动力学计算通量收敛准则均为1.0×10-7,时间步长分别选用2、5和10 ms,CPU和GPU计算均使用双精度。

图2 TWIGL基准题几何结构及堆芯网格划分Fig.2 TWIGL benchmark geometry and core division strategy
堆芯功率时变计算结果如图3、4所示,参考解由VARIANT和DeCART给出[15],可看出ALPHA计算结果与参考解符合良好,堆芯功率最大相对误差为0.43%。各区域平均棒功率计算结果比较列于表1。区域3功率相对误差较区域1、2大,最大误差出现在0.2 s,恰好是功率开始瞬变的时刻。带有CMFD加速的不同硬件条件下计算效率与精度比较列于表2。由于TWIGL问题规模较小,GPU算例中对于每个时间步的计算时间并不能达到所用GPU的峰值算力,且调用GPU过程中所消耗计算资源占比较多,所以GPU算例计算时间并未随着步长增大而呈比例地减小,但相比CPU算例而言,加速效果依然明显。对于2 ms步长算例,加速比达到6.6。GPU并行条件下的CMFD加速效率对比列于表3。CMFD加速性能十分可观,加速比基本在40左右。对比表3中3种不同的时间步长计算结果可发现,CMFD时间占比随时间步长的减小而减小,从而CMFD加速比也随之减小。对比表2与表3结果可发现,GPU并行条件下的加速比随着MOC计算时间占比增大而增大。

图3 TWIGL功率变化及相对误差Fig.3 Core power behavior of TWIGL and relative error

图4 不同时刻TWIGL精细功率分布 Fig.4 Detailed power distribution of TWIGL at different time

表1 TWIGL各区域平均棒功率计算结果比较Table 1 Region wise pin power comparison of TWIGL

表2 TWIGL基准题不同硬件条件下计算效率及精度比较Table 2 Computational efficiency and accuracy comparison for TWIGL in different hardware conditions

表3 TWIGL基准题CMFD加速效率比较Table 3 Effectiveness of CMFD for TWIGL
3.2 MINI-CORE 2D基准题
MINI-CORE 2D基准题[15]几何结构以及边界条件如图5所示,该堆芯由5个铀富集度为4.2%的UOX组件和4个钚富集度为4.0%的MOX组件组成。控制棒仅位于中心的UOX组件内,通过匀速提棒使得堆芯产生瞬态功率变化。ALPHA的计算参数如下:每个组件为17×17栅元排布,每个栅元使用5×5矩形网格划分,选用特征线间距为0.02 cm,角度离散选用32辐角和最佳三极角,初始稳态和动力学计算通量收敛准则均为1.0×10-6,CPU和GPU计算均使用双精度。

图5 MINI-CORE 2D基准题几何结构Fig.5 MINI-CORE 2D benchmark geometry
堆芯功率时变计算结果如图6、7所示,参考解由DeCART与VARIANT给出[15],ALPHA计算结果与参考解符合良好,2 ms步长算例中堆芯功率最大相对误差为3.3%,出现位置在0.01 s。不同时刻下组件功率计算结果列于表4,各时刻下组件功率相对误差均在0.05%以内。带有CMFD加速的不同硬件条件下计算效率与精度比较列于表5,可看出GPU计算加速效果良好,对于2 ms算例加速比为3.8倍。GPU条件下的CMFD加速效率对比列于表6,CMFD加速效果明显,10 ms算例加速比可达到51.6。MINI-CORE基准题中GPU加速比与CMFD时间占比的关系与TWIGL结果一致,即GPU加速比随CMFD时间占比增大而减小。

图6 MINI-CORE 2D功率变化及相对误差Fig.6 Core power behavior of MINI-CORE 2D and relative error

图7 不同时刻MINI-CORE 2D精细功率分布 Fig.7 Detailed power distribution of MINI-CORE 2D at different time

表4 MINI-CORE 2D各区域平均棒功率计算结果比较Table 4 Region wise pin power comparison of MINI-CORE 2D
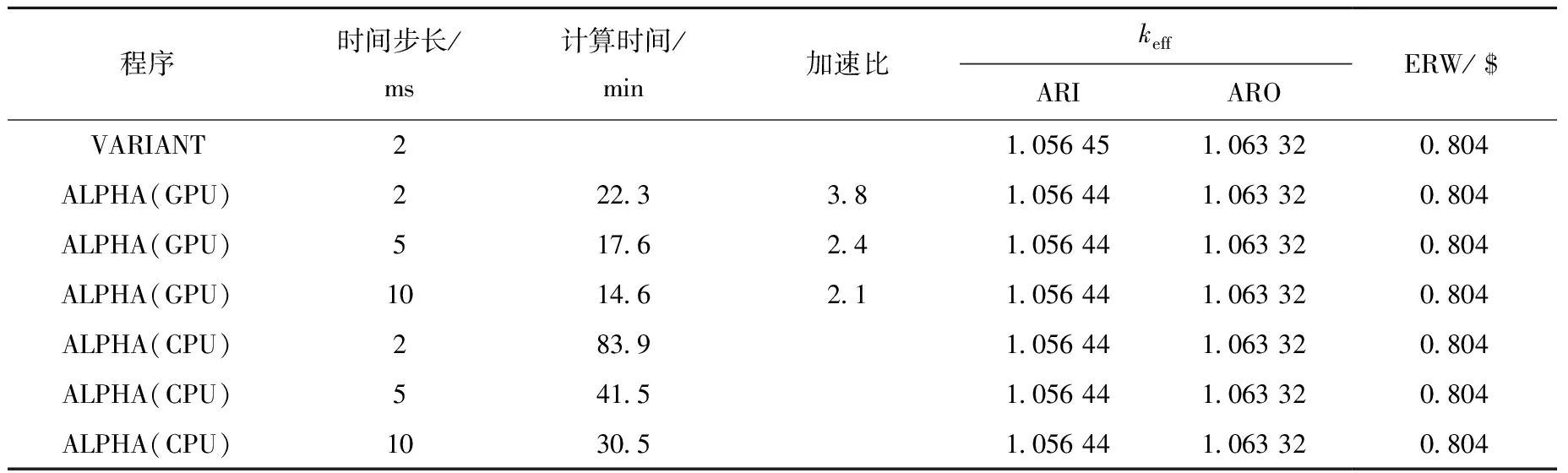
表5 MINI-CORE 2D基准题keff及计算效率比较Table 5 Steady-state keff and calculation efficiency of MINI-CORE 2D

表6 MINI-CORE基准题CMFD加速效率比较Table 6 Effectiveness of CMFD for MINI-CORE
4 结论
本文介绍了采用GPU加速的TFSP并行算法,实现了GPU并行加速动力学MOC及CMFD计算。TWIGL基准题和MINI-CORE 2D基准题数值结果表明:程序满足瞬态输运求解的精度要求;同时,采用单GPU进行小规模堆芯瞬态输运计算时,与单CPU相比加速倍数约在2~6倍,且加速比随CMFD计算时间占比的增大而减小。本文仅初步实现了CMFD TFSP加速计算,所涉及的并行算法可推广至预估-校正准静态方法以及TML方法,提升全堆瞬态计算的效率。
