大数据时代高校精准资助路径探索
2021-08-17景璐璐陈天宇顾炜江潘卿
景璐璐 陈天宇 顾炜江 潘卿

摘 要:大数据时代,教育数据治理面临更为复杂的困境,精准资助是国家教育扶贫的核心任务之一,鉴于目前高校难以有效进行贫困生精准识别,文章提出一种基于大数据技术的高校精准资助模型。通过梳理学生在校的全量数据,设计提取学生基本信息、消费数据等共计23类数据对学生的经济情况进行建模评估,通过数据采集、数据处理、数据集中展现,精准识别贫困生与非贫困生。该模型优化引用机器学习算法对模型进行训练,结合学工大数据对结果进行评价,能及时发现“隐性贫困”,得到一个有效的贫困生识别方法。
关键词:教育数据治理;精准资助模型;机器学习算法
中图分类号:G717 文献标识码:A DOI:10.3969/j.issn.1003-6970.2021.03.025
本文著录格式:景璐璐,陈天宇,顾炜江,等.大数据时代高校精准资助路径探索[J].软件,2021,42(03):090-093
Exploration of Precise Subsidy Paths for Colleges and Universities in the Era of Big Data
JING Lulu1, CHEN Tianyu2, GU Weijiang1, PAN Qing1
(1.Office of Cyberspace Affairs, Nanjing Forestry University, Nanjing Jiangsu 210037;
2.China Mobile (Suzhou) Software Technology Co., Ltd., Suzhou Jiangsu 215000)
【Abstract】:In the era of big data, education data governance is faced with more complex difficulties, and precise subsidy is the core task of education poverty alleviation. In view of the difficulty of accurate identification of poor students in colleges and universities, this paper proposes a precise subsidy model of colleges and universities based on big data technology. By combing the total data of students in school, we design and extract a total of 23 types of data, such as students' basic information and consumption data, to model and evaluate the economic situation of students, and accurately identify poor students and non-poor students through data collection, data processing and data centralized display. The model uses machine learning algorithm to train the model optimally, and evaluates the results with the big data of Nanjing Forestry University. It can find out the "hidden poverty" in time and get an effective method to identify the poor students.
【Key words】:education data governance;precision funding model;machine learning algorithm
隨着高等教育规模迅速扩大,高校大学生数量逐年攀高,相应贫困生人数也呈现了逐年上升态势。《2019年中国学生资助发展报告》[1]显示,政府、高校及社会共资助全国普通高校贫困生人数达4817.59万人次,资助金额1316.89亿元,比上年增加166.59亿元,增幅达14.48%。贫困学生的增多大大增加了贫困生资助部门的工作难度和工作量。贫困生认定是一个相当复杂的过程,必须要综合考虑各方面因素,目前贫困生的认定方法大多是定性的,要做到公平公正必需要对贫困生认定做定量的解释,建立精准资助机制[2]。精准资助是国家教育扶贫的核心任务之一,只有抓好学生精准资助,才能推动教育精准扶贫[3]。
1大数据精准资助技术和实践基础
实现基于大数据技术的精准资助,一方面需要在大数据技术的支撑下,通过学生的消费行为数据,动态掌握学生的整体情况;另一方面需要在精准资助理念的支撑下,不断优化资助形式、方法与策略。
1.1 大数据技术
精准资助的大数据技术的主要包括以下内容:(1)学生消费行为数据采集。在校园各类生活过程中产生的数据,比如食宿打卡、超市消费等,利用各类信息系统记录行为发生的时间、行为的类型及相应的环境信息,实时、动态的对学生整体消费数据进行跟踪、记录、集成、规约,为数据挖掘和分析做好准备工作。(2)消费数据分析。利用数据收集、数据挖掘、数据分析、数据可视化等手段,对每个学生的消费过程和结果进行分析,对贫困数据初步掌握,可以进一步分析学生的消费倾向和习惯,实现个性化资助。(3)个性化资助。教育部在2017年发布了《关于进一步加强和规范高校家庭经济困难学生认定工作的通知》,通知指出要精准分配资金名额,明确重点受助学生,其中就包括采用“隐形资助”的个性化资助方式,避免大张旗鼓地把困难学生与非困难学生割裂区分开,这就要求基于消费的过程和结果,建立更加人性化的精准资助模型[4]。
1.2 精准资助现状与实践
传统模式下,贫困生认定主要根据学生的家庭基本信息、家庭人均收入、家庭成员是否患有重大疾病等影响家庭经济情况的几项指标对所有申请贫困资助的学生进行量化评估,按照评估结果及学生日常消费水平进行排序,简单概要的划分学生的经济困难程度。从流程上看,贫困生认定过程涉及诸多主观因数,学生日常消费水平没有数据支撑,导致认定结果准确性较低,无法得到师生的认可。贫困生在申请资助时,首先要提交资助申请,还要开具各类材料证明,不仅流程繁琐,效率低下,还可能产生数据造假。
随着大数据技术在教育领域的应用广泛应用,在高等教育管理和教学各方面发挥了重要的作用,高校学生资助工作也试图充分利用校园大数据,在原有工作模式基础上探索新的发展方向,力争实现学生资助工作的科学化、精准化、智能化,提升工作效率和质量。文献[5]通过学生多样化数据从方方面面记录学生的家庭及个人情况,利用用户画像技术精准识别贫困生,做到个性化资助[4]。文献[6]通过设定不同的贫困等级,运用大数据相关技术判断学生是否是贫困生,在Hadoop平台上运用GBDT算法将学生在学校所产生的行为数据进行处理,分析属于哪一级贫困生,将学生进行分级资助并对贫困生进行精准识别[5]。欧阳铁磊[7]以学生在校一卡通数据为基础,进行数据挖掘研究,为贫困生资助工作中提供了一些参考信息。张玺[8]等人利用大数据优化贫困生认定系统,采用支持向量机(Support Vector Machine,SVM)算法对学生校园一卡通的消费数据进行分析,将学生按照贫困与非贫困进行分类。柴政等[9]借助于深度神经网络DNN,把原有的数据集分成两类,分别进行训练和验证,用训练后的模型来预测学生的贫困等级。从以上研究来看,使用精准资助算法模型比传统贫困生识别效率和精确度都有一定提高。
2大数据精准资助方法和框架
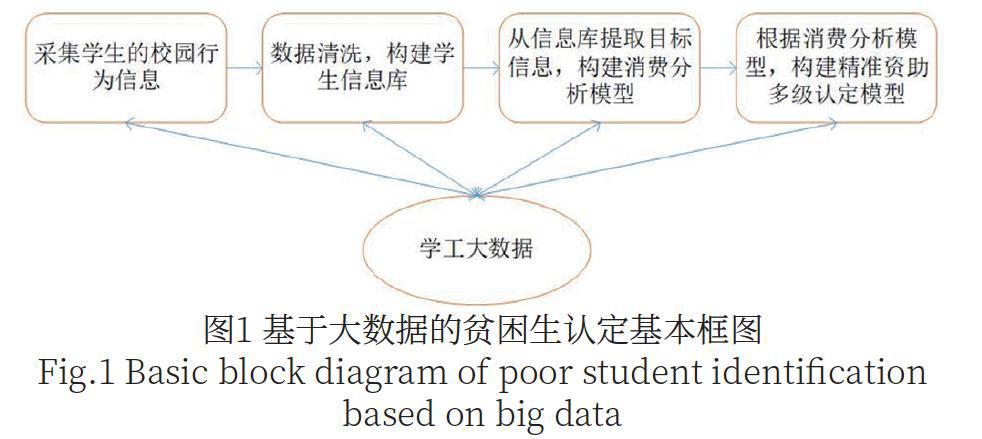
目前,利用大数据技术识别贫困生可以最大限度地实现资助公平,最大限度地实现国家资助资金精准发放。通过数据采集,分析学生日常的消费情况,再辅助以严谨的评判标准,例如以学生每月在食堂用餐60次以上、每天就餐低于平均值10块钱等筛选标准,大概勾画出学生们的经济情况及困难程度。这与传统的提交材料证明等方式相比,具有高针对性和高精准度,彻底打破了传统资助资源“按比例”“一刀切”的分配模式。基于此,本研究提出一种基于大数据的贫困生多级认定方法,流程如图1所示。
(1)数据采集—采集学生的校园消费行为信息:采集学生的校园行为信息,包括学生的消费信息、基本信息及恩格尔系数、属地GDP等。(2)数据清洗—构建学生信息库:对学生的校园消费行为信息进行清洗和关联处理。(3)数据建模—从学生信息库中提取目标行为信息,并根据目标行为信息计算行为评价指标,根据行为评价指标构建初始消费分析模型。根据消费分析模型及待认定行为信息,进一步构建贫困生多级认定模型。
以我校资助工作为例,基于学工大数据的精准资助方法核心在于学生消费数据分析模型的构建。学生一卡通数据支出状況能够在一定程度上反映出学生的贫困程度,困难家庭的学生通常具有消费地点稳定、消费结构简单、消费连续性强等特点。对学工、教务和一卡通系统等线上和线下的数据进行全方位采集,采集到的原始数据无法直接对其进行特征分析和建模,需要对原始数据进行预处理、消除错误、缺失、冗余等无效数据,提高数据价值。经过预处理后的数据相对比较完整,且结构统一,对这部分数据进行整合分析,提取学生消费行为特征,结合学生家庭信息、建档立卡信息、贷款信息等构建学生消费行为与家庭经济情况的关系。通过机器学习算法对数据进行聚类分析,将学生的消费水平划分等级,根据等级层次为每位学生添加合理的贫困标签。在此基础上,通过数据可视化技术,直观的对学生消费数据分析结果进行展示,帮助学校全面掌握贫困生数据库。
3 基于大数据的精准资助方法实践认证
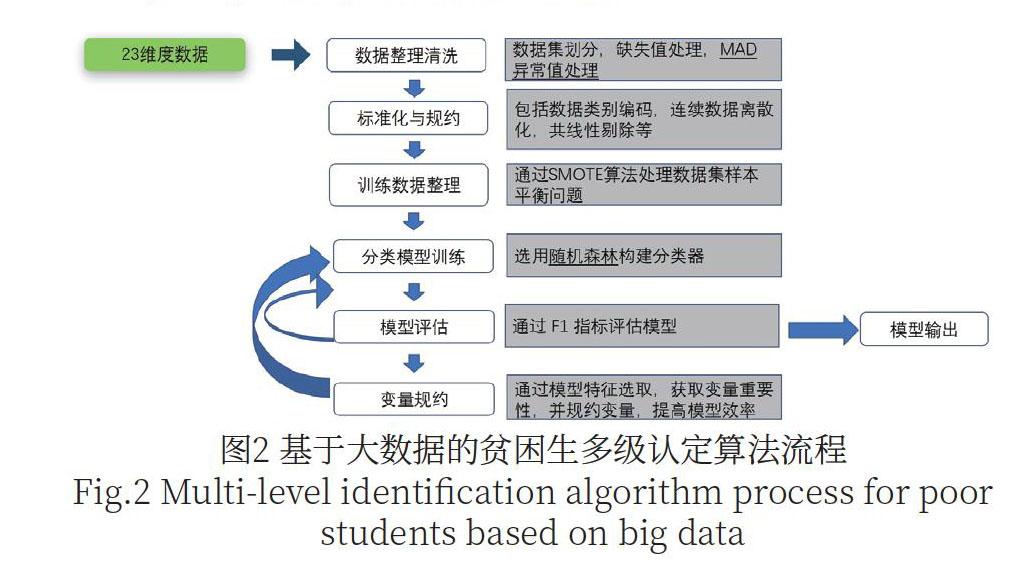
基于大数据技术的贫困生多级认定模型,包括4个模块:采集模块、信息库构建模块、初始消费分析模型构建模块、贫困生多级认定模型构建模块。模型采用基于逻辑判断的自步集成学习模型,集成学习不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器的方式来完成学习任务,采用多种机器学习算法,为精准资助提供决策支持。该模型功能点包括三部分:(1)精准识别贫困生,即符合贫困生统计特征且接受资助的学生;(2)发现需要关怀的学生,即符合贫困生统计特征但又未接受资助的学生;(3)发现异常贫困生,即接受资助,但行为特征与贫困生有明显差异的学生。
模型的算法流程如图2所示。
3.1校园大数据的采集和处理
数据来源于我校2019-2020年贫困生认定数据,通过学生基本信息、消费数据等对学生的经济情况进行评估,从而识别贫困生与非贫困生。贫困生识别涉及23个字段,以学生学号作为标识字段,假设家庭困难学生在成长时养成相对稳定的消费习惯,在消费指标中发现特征并形成分类器,并进行对一般性学生的经济困难水平进行评估。评估时,考虑不同人群的消费结构,以性别,民族,户口类别,省份等作为基本指标以消费流水为基础的消费相关数据为消费指标。随后,根据一般学生的消费水平参数以及关怀学生的消费水平,评估资助金额。23个字段如表1所示。
数据清洗时,由于本次分析选用消费数据,基于严格的消费数据流水进行整合,部分消费数据为空,均可理解为没有发现相关消费记录,所以针对缺失值的处理,统一用0代替。针对消费异常值,即部分学生有较为特殊的消费特点,部分维度分布下出现极端情况,在一些模型(尤其基于距离的模型)有较为严重的影响,故需要发现并规约,异常值发现算法基于中位数,采用MAD 算法计算各项指标(连续型指标的正常范围,并对超范围的数据统一转换为极值),MAD(中位数绝对偏差)是一个健壮的统计量,是单变量数据集中样本差异性的稳健度量,对于数据集中异常值的处理比标准差更具有弹性,可以大大减少异常值对于整个数据集的影响。 以下为各类数据的 MAD 范围,如图3所示。
数据清洗后的训练数据整理主要解决目标数据不平衡问题,类不平衡(Class-imbalance)是指在训练分类器时所使用数据集的类别分布不均。例如一个二分类问题,1000个训练样本,比较理想的情况是正类、负类两种样本的数量相差不多(本文正、负类样本特指贫困生和非贫困生)。如果正类样本有999个、负类样本仅有1个,就意味着存在类不平衡。从训练模型的角度来说,如果某类的样本数量很少,那么这个类别所提供的“信息”就太少。常见的方法,通过过采样,欠采样等方式,从样本抽取中消除不平衡性。精准资助多级认定方法采用SMOTE进行过采样。SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中。
3.2 精准资助贫困生认定方法
精准资助贫困生认定算法采用随机森林进行分类模型训练:随机森林顾名思义,使用随机的方式建立一个森林,森林由多个决策树组成,随机森林的每一棵决策树之间不相关。形成森林之后,每输入一个新的样本,就由森林中的每一棵决策树分别进行投票似判断,观察这个样本应该属于哪一类,哪一类被选择最多,就可预测该样本为被选择最多的类。随机森林属于集成学习,把分类树组合成随机森林,即在变量和数据的使用上进行随机化,生成很多分类树,并汇总分类树的结果。本模型构建1000个决策树组成森林,并对未知数据进行投票。混淆矩阵也称为误差矩阵,是精度评价的一种标准格式。
精确率(Precision)为TP/(TP+FP);模型判断出的所有正例(TP+FP)中,其中真正例(TP)占的比例。正例即正类样本,负例即负类样本,下同。
准确率(Accuracy)为(TP+TN)/(TP+TN+FN+FP);模型判断正确的数据占总数据的比例。
召回率(Recall)为TP/(TP+FN);模型正确判断出的正例(TP)占數据集中所有正例的比例。
其中,TP:真正例,FP:假正例,FN:假负例,TN:真负例(文中,正例指贫困生,负例指非贫困生)。
F1值是精确率和召回率的调和均值,F1=2PR/(P+R),是精确率和召回率的综合评价指标。P:Precision;R:Recall。
应用于测试数据集,结果如下表2。
如表2所示,多次测试后,模型准确率为0.8,还可以进一步提高模型的准确率。通过特征选取,逐步获取各个变量的重要性,并规约变量,提高模型效率。经过测试后,变量重要性排序:户口类别最为重要,而性别最不重要,后续把性别变量去掉,再观察准确率。
根据模型,确定学生的贫困度,根据一般学生的消费水平参数以及关怀学生的消费水平,评估资助金额。贫困度,以投票树为指标,例如在本研究中,1000棵决策树,有500棵认为是贫困,则学生A贫困度为50%。另外,根据一般学生的消费水平以及被关怀学生的消费水平,评估资助金额。例如学校非贫困生月均消费金额假设为300元,某学生月均消费金额250元,如已经接受补助,且补助金额不足300的,则增加补助金额到300元。
4 结语
大数据驱动的精准资助模型是指以大数据技术为手段,在精准分析学生在校消费现状的基础上,对资助模型进行精准设计、对贫困生进行精准定位、对资助形式进行精准定制、对资助模型精准评价进而做出精准决策,使精准资助过程和结果可量化、可优化。同时,利用大数据对学生进行“隐形资助”,不仅可以解决一些贫困学生生活上的压力,又可以维护他们的尊严。这与高校中传统的资助方式相比,最大的特点就是利用现有的大数据技术进行分析,在资助公平和学生尊严之间找到了平衡,既充满人性,又精准高效,让学生们更有尊严且更公平地享受国家的这份关怀。
参考文献
[1] 全国学生资助管理中心.2019年中国学生资助发展报告[N].人民日报,2020-05-21(006).
[2] Wei Huang,Fan Li,Xiaowei Liao,et al.More Money,Better performancy?The effects of student loans and need-based grants in China's higher education[J].China Economic Review,2017,9(5):208-227.
[3] 徐新洲.林业高校精准扶贫“三全”模式研究:以南京林业大学为例[J].中国高校科技,2020(12):18-21.
[4] 黄立,戴航.基于大数据的高职院校贫困生精准资助[J].教育与职业,2019(15):53-60.
[5] 李成飞.大数据背景下高校贫困生资助工作精准化研究[D].南京:南京邮电大学,2017.
[6] 杨胜志.基于大数据的大学生精准资助贫困等级研究[D].长春:东北师范大学,2018.
[7] 欧阳铁磊,叶玲肖.基于大数据分析的高校贫困生精准资助策略研究[J].计算机应用与软件,2020,37(8):45-47+129.
[8] 张玺,呙森林,孙宗良.基于校园一卡通消费数据对高校贫困生分类的应用研究[J].数字技术与应用,2016(8):100.
[9] 柴政,屈莉莉,彭贵宾.高校贫困生精准资助的神经网络模型[J].数学的实践与认识,2018,48(16):85-91.
