基于RFME模型和AdaBoost分类器的电子商务客户关系研究
2021-08-17陈俊龙吴丽丽
陈俊龙 吴丽丽

摘 要:为进一步探究和分析电子商务客户关系,本文提出e价值的指标体系和计算方法,同时基于使用k-means方法对客户进行分类,实现对客户关系的深层发掘。基于改进的RFM模型实现了对客户的辨别与分类功能,对不同客户的e价值能进行有效预测,同时可以为企业在电商相关领域营销策略的差异化实施提供依据。对客户关系进行深层细分。同时基于AdaBoost分类器,提出以C5.0决策树作为基分类器的客户保持与流失预测模型,降低错误预测成本,精准识别高价值客户。
关键词:RFM;AdaBoost;电子商务;客户价值
中图分类号:TP391. 41 文献标识码:A DOI:10.3969/j.issn.1003-6970.2021.03.001
本文著录格式:陈俊龙,吴丽丽.基于RFME模型和AdaBoost分类器的电子商务客户关系研究[J].软件,2021,42(03):001-007
Research on E-commerce Customer Relationship Based on RFME Model and AdaBoost Classifier
CHEN Junlong, WU Lili
(College of Information Science and Technology, Gansu Agricultural University, Lanzhou Gansu 730070)
【Abstract】:In order to further explore and analyze the relationship between e-commerce customers, this article proposes an index system and calculation method for e-value, and at the same time classifies customers based on the use of k-means method to realize in-depth exploration of customer relationships. Based on the improved RFM model, the function of identifying and categorizing customers is realized, and the e-value of different customers can be effectively predicted. At the same time, it can provide a basis for the differentiated implementation of marketing strategies for companies in the e-commerce-related fields. In-depth segmentation of customer relationships. At the same time, based on the AdaBoost classifier, a customer retention and churn prediction model based on the C5.0 decision tree is proposed to reduce the cost of error prediction and accurately identify high-value customers.
【Key words】:RFM;AdaBoost;E-commerce;customer relationship management
0 引言
在网络技术日新月异的当下,电子商务平台已经深入各行各业中,生活中处处可见电商领域的产品或服务。在社会发展和进步的同时,电子商务区别于以往传统的消费模式,作为全新的形式冲击全国受众的普遍认知,并使其购买行为产生了或多或少的变化。据资料显示,截止2015年,我国互联网用户已逾6亿,到2019年6月,我国网民规模升至8.54亿,手机网民规模达8.47亿,网络普及率超过61.2%。至2020年3月,我国互联网普及率已达到64.5%,网络购物用户规模达7.10亿,近2015年的两倍[1]。
2019年,我国互联网交易规模达10.63万亿元,与繁荣发展的互联网业态相对应,在全新商务模式下,对消费者管理和客户价值认知评估模式也需要推动发展与转型。与传统行业的销售模式相比,在电子商务环境下,消费者的选择空间极度扩大,信息流动迅速,客户留存率大大降低。有研究显示,电商环境下,客户流失率可高达80%,而获取新客户比保持现有客户的成本高得多,与前者相比,客户留存可节约4~6倍获客成本[2]。对电信运营商来说,用户保持率增加5%,即可为运营商带来85%的利润成长。对传统零售行業来说,在电子商务运营中提高复购率,大幅降低营销成本和服务成本,减少高价值客户流失是维持企业在电商领域长期发展的重要途径[3-4]。基于客户关系理论对电商平台现有客户进行关系识别,对高价值客户进行细致的筛选,“因客施策”,着力打造实施精确营销,将成为客户长期留存和价值提升的基础。
现有客户关系研究当中,已有多种算法和工具被运用于相关数据的统计计算及经营决策当中,从传统统计学、统计学习理论,到人工智能、组合分类器及仿生学算法等,机器学习技术逐渐被运用到企业用户管理决策当中。Renjith提出在使用Logistic回归方法深入解离客户流失影响因数的基础上,利用多个属性变量预测流失客户,并通过机器学习方法对不同的方案根据需求进行检索,并根据客户特征进行个性化组合,从而有针对性的提出细分客户留存策略。张秋菊[5]等则构建了基于FRI(自组织模糊规则归纳算法)的客户流失预测模型,通过利用数据分组处理网络(GMDH)对客户流失状态进行判别,测试样本的正确预测可达到90%以上。
为弥补单个分类器在数据预测中产生的效率与性能偏差,近年来,组合分类器被应用到客户流失预测研究中,利用高效协同工作的方式,充分整合各子分类器不同算法的优势,提高集成学习的效率和性能。Schapire提出的Boosting算法和Breiman提出的Bagging算法即是两种常见的集成学习方法,通过训练多个基础模型解决相同问题,获得数个同质弱学习器并进行正确组合,从而获得更好的性能。
Boosting算法思路主要是利用多棵决策树通过组合而形成的,彼此之间通过投票的方式对结果来进行相应的预测。在应用当中,根据分析对象的特征,产生了多种不同的优化组合方案,如在商业银行的客户流失预测中,引入线性判别LDA,对每个数据的统计属性分别计算。
AdaBoost自适应增强算法(adaptive boosting)则在其基础上改变样本的权重。AdaBoost算法在每一次学习之后将重点关注被分类错误的样本,增加分类正确率高模型的权重,有效解决了早期Boosting算法在实际运用中的困难,作为最优秀的Boosting算法之一被广泛使用在实践当中[6-8]。
本文根据电子商务所具有的一些特点,从相关客户对电商平台具有的价值出发,引入“e-value”概念。这一概念从电子销售渠道和服务商的利益角度出发,确定了影响电商客户e价值的关键指标,并结合客户价值评估模型RFM,和k-means方法将客户分类,建立了RFME模型对客户进行识别和分类。本文将提出e-value的处理规则,从而较为准确地对不同客户的e进行估值,为企业在电子商务领域实施差异化营销策略提供了依据。
在此基础上,本文通过以电子商务平台为基础,结合客户消费行为中保持与流失的走向变化,利用CRM理论提出一套预测电商平台客户保持与流失的数理模型。为印证组合模型能对客户流失情况进行更精确的预测,对不同的单一数据挖掘模型和AdaBoost组合模型分别对结果进行预测,并在一定条件下对不同模型的预测结果进行对比,从而来判断不同模型预测的精确度。改进的RFM进一步增强了分类的能力,降低错误预测成本,精准识别高价值客户并采取策略减少客户流失率,为企业电子商务业务降低成本,提高了收益。
1电子商务下的客户关系分析
1.1客户细分
客户细分具有多种角度和维度。依据帕累托原则,企业的核心利润主要由高价值客户创造,这一比例符合广泛存在的二八原则;同时,底部约30%的客户实际上为低价值与无效客户,对这部分客户投入的营销、服务和挽回成本可占到企业利润的50%。因此,有效的对客户价值进行评估和细分,是实现高效客户关系管理(Customer Relationship Management)的基础[10]。客户价值细分有助于帮助企业集中精力,为高价值及有流失可能的客户提供个性化服务与精准营销,是更高效地进行针对性营销活动的重要前提。
本研究中所指客户细分主要指客户价值细分。在电子商务时代,客户消费仍旧是企业获利的直接来源,各电商企业都逐渐由产品中心的经营模式转向用户中心导向,是否能有效进行客户关系维护,挽留流失客户,成为企业是否能保持竞争优势的重要因素。企业依据客户实际价值,对客户进行分类,对高价值客户有针对性地制定相应营销策略,向关键客户进行企业资源倾斜,能够有效提升企业获客和客户挽留的投入产出比,实际上增加利润率,扩大竞争优势,增强企业核心竞争力。这就要求企业首先能够准确对客户价值进行判断和识别。
在网络消费过程中,消费者与企业之间的信息交互呈现即时、双向、周期短的特点,导致客户产生回购的概率大大降低。同时,企业与客户进行沟通时的渠道是否稳定及时并能对问题进行解答,以及企业与客户的供求关系能否长期把持稳定,这些问题需要面临网络信息量大、信息流动速度快、产品同质化程度高、竞争压力大、客户群多样化、差异化程度高等多种挑战。
如何准确在广泛而复杂的客户与潜在客户中,准确识别高价值客户,做好流失预测并及时采取相应策略阻止客户流失,成为电子商务管理和发展人员关注的热点。在众多消费行为相关指标当中,客户消费额度直接与企业产品或服务的质量的销售量相关,并且能够直接作为客户实际价值的量化体现。本研究以客户消费额度为主要显性价值指标,依据历史交易数据进行数据提取,利用RFME模型对客户价值进行量化评估,并完成客户分类。
1.2客户保持与流失
客户流失的企业管理概念是指曾购买或使用过某企业商品或服务的客户,停止在该企业进行消费或合作行为,转而去购买或使用过竞争企业的商品或服务。电子商户客户常常与商家没有契约关系,其消费具有一过性,即在完成一次购买之后,消费者和商家之间的交易行为完成,交易关系终止;直至下一次交易之前,客户与企业之间的关系处在一种非契约关系情境下。
对电子商務运营方来说,识别高价值客户,对其流失概率进行准确预测,在发生客户流失之前进行关系维系和客户挽留,在实际操作层面具有重要意义。而对客户重复购买行为和心理的分析预测,可以帮助企业识别忠诚度更高、复购可能性更大的客户,对其消费行为和购买习惯进行总结和共性分析。围绕客户忠诚度的培养,企业可以根据客户复购决定发生的环节,和消费决策产生的动因等信息,针对性优化其产品、服务与营销手段等,增加留存客户比例,保留高价值客户,降低企业开拓新客户的成本,提升企业对客户的把握能力。
基于电商平台的客户关系推理模型,是结合之前研究结论提出的对电子商务客户关系进行预测的算法模型。它通过追踪统计一段时间内客户在电商渠道发生的浏览、消费等行为信息,对电子商务渠道客户的购买行为进行分析,依照建模细分结果,对不同价值客户进行区别化概率性对待,制定个性化客户保持策略,从而达到平台以更低成本,有效完成客户维持工作。
2基于RFME的客户细分建模
2.1 RFM客户价值
RFM是一种被广泛用于客户关系管理中的分析模型,通过对客户价值和创利能力的衡量对客户价值进行细分评估,在(R、F、M)三个维度对客户交易行为和其对企业的价值进行量化:
2.1.1 R:Recency
R值指客户的最近一次消费,即客户最近一次消费时间与当前时间的间隔。理论上,R越接近于0,表明该客户属于高价值客户,相对于其他普通客户更易进行消费行为。在电子商务模式当中,搜索和购买操作高度便利,顾客购买选择高度丰富,购买成本大大降低,区域和地域限制被打破。R值小的客户刚完成购买行为时,对品牌印象较好,认知较清晰,最可能购买更新换代之后新上架的产品,对促销力度敏感性更强。关注R值低的客户,有助于企业以较低成本提高回购率和留存率。
2.1.2 F:Frequency
F值指客户的消费频率,即顾客在某一特定时间段(如一个季度内)完成购买的次数。重复购买次数越高的客户,对产品和服务满意度也最高,或者说,对品牌或企业忠诚度最高,其转向竞争对手企业的可能性也更低。增加客戶购买次数意味着从竞争对手处抢夺更多的市场占有率,对F值高的客户进行针对性维护,培养品牌或企业的忠实用户,是建立企业核心品牌资产的中心保障。
2.1.3 M:Monetary
M值指客户的消费金额,即顾客在某一特定时间段的消费金额。M值和F值相同,都是限制在一定时间内的,需要同F值、客单价等其他因素一起进行分析和解读。在产品价值一定的情况下,M值的变化常常与客户对企业认可度相关。
2.2客户的“e-value”
在以往购买力稳步增长的大环境下,客户价值基本体现在购买行为、重复消费行为和增值服务购买力的表现中,以净买入的方式给企业在当下带来的实际收益。而在电子商务环境下,产品曝光、长时间浏览和跳转等都会对企业效益产生贡献。这种用户通过外设键入、网页浏览、线上互动等方式间接形成的“无价”资源就是e-value。
客户的“e-value”主要反映的是客户对该商品或平台具有强烈的兴趣,不期便会对其创造相应的价值。客户在该网站的所有活跃行为,如广告点击、互动评论、留言、发帖、消息打开、信息搜索、内容上传等,都能够创造e价值。在顾客被此类信息所吸引并根据自身需求带有强烈目的性地追求某类消费行为时,便是电子商务平台收获客户满意度,提升影响力和影响面的时候。
对电子商务平台来说,客户e价值主要包括以下三个部分:
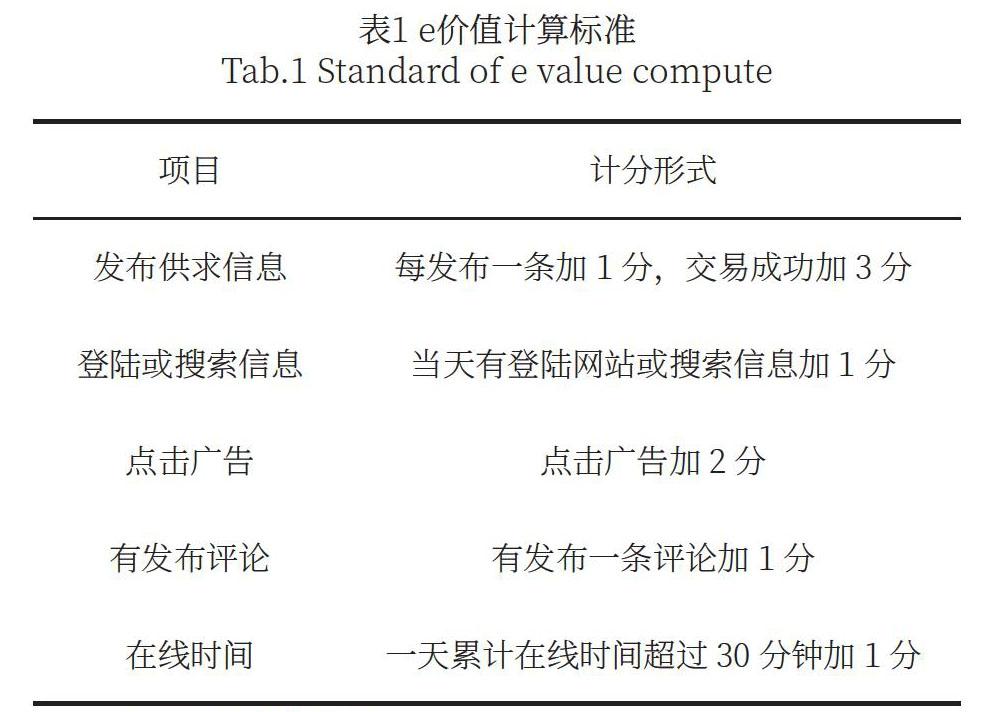
(1)广告价值。广告投放所创造的收益通常是电子商务网站收入的主要来源。网络广告与传统广告一样,通过内容展示,创造消费需求、影响消费观念、促使消费行为产生,是一种以商业目的为出发点的信息传播活动,常常以诱导互动的方式进行信息传递。目前,电子商务网站的广告收入结算常常以点击率为依据,用户的点击动作能够直接为电商网站创造利润收入。
(2)“吸引力”价值。电商网站必须创造对消费者、商家都具有吸引力的价值,才能够保证其必要的流动性,让更多交易方进入平台。更多相关产品或服务信息、更可信的搜索结果、更多评论和互动信息,更多来源广泛、品类多样的消息发布,对交易双方都是充满吸引力的高价值资源,这些“吸引力”价值,在被用户创造的同时也反过来吸引更多用户。
(3)流量价值。目前主流搜索引擎,如百度、谷歌等,在进行算法推荐时,常常将网站访问流量作为主要权重指标,根据网站流量进行聚顶排名。在电子商务网站进行搜索引擎优化(Search Engine Optimization)时,利用搜索引擎规则,使其尽可能在搜索结果的前排出现,对其先于竞争对手被访问,从而占据有利地位,获得品牌收益有重要价值。客户访问量越高,网站自然排名越靠前,网站就更容易获取流量,并持续创造价值。
客户e价值的三个维度都与电子商务网站持续获客和盈利能力直接相关。如表1所示,本研究针对客户e价值[11]建立了价值计算体系。
2.3改进模型的建立
根据企业类型和管理需求的不同,对于各种客户细分理论的研究重点上也会有所不同。本文以电子商务客户为研究对象,综合考虑电子商务环境中客户购买行为和认知模式的多种影响因素和表现形式,将RFM模型对客户交易价值的多维度综合评估的特性与客户e价值的操作性定义相结合,构建了RFME模型,从而对电子商务环境下的客户价值有了更好的评价。
其优势在于:
首先,不仅美妆、小型家电、食品、零售等日常消费品,和餐饮、音像等日常消费场景,在耐用品、大宗、原材料等领域,RFM也有充足的应用案例,证明其在各个领域客户价值。
其次,根据刘元军网络活跃度指标体系建立和引入的e-value(e价值)计算体系,增加了电子商务由于处在网络环境中所带来的特定用户行为模式特征,使得RFME模型体现了网络环境下电商客户价值的新含义。
最后,目前,我国电子商务市场呈现出极少数集成平台占有绝大多数电子商务体量,中小型电子商务网站发展水平不高,规模和效益参差不齐的样态,对大多数中小型偏向特定细分领域、或规模较小的电子商务网站来说,过于复杂的细分模型不但不利于理解,而且操作繁复,耗时耗资较大,模型设计、参数设置、评估监控以及做出决策等环节都需要更长的时间和更多人力物力。随着“奥卡姆剃刀定律”在现代企业管理理论中的发展,组织规模和制度制定当中,舍弃繁琐和非必要流程更符合企业的经济效益,这一原则在客户价值分析和客户关系管理中同样适用。RFME模型舍弃了许多客户价值评估算法的繁复运算,方便实用,更符合我国电子商务企业的实际需求和现实环境。
2.4基于RFME的客户细分建模
(1)数据整理。用户在电子商务网站上的一切点击、浏览和消费行为,都可以被记录和留存。从相关数据当中提取RFME模型对应的字段信息,如特定时间段内顾客的购买、距离统计时间最接近的购买、购买行为的频次与频率等。
(2)数据的处理。将相关字段信息进行数据化整理,以R、F、M、E数值的形式导出,方便k-means聚类分析。
(3)聚类分析。由于本研究对客户价值的评估和细分服务于企业客户关系管理,考虑到管理成本和针对性客户营销活动所需人力物力,客户细分类别过多将大大增加管理难度,中小型电子商务网站难以有效利用客户细分结果做出决策优化,因此,模型针对R、F、M、E四个字段,使用k-means聚类分析。
(4)命名。完成聚类分析后,模型使用多元单因素方差分析法,对数据的显著性差异进行验证,从而判断各客户细分类别在不同字段下是否具有显著区别。接下来,对各细分类别进行多重比较,通过对量化指标的比较分析,得到不同类别客户的特征信息,并进行命名。如某一类客户在其他字段上表现没有显著区别,但在消费频次字段上的值明显高于其他分类,即可以认为这类客户具有同等条件下消费金额较高的特征,命名为高客单价客户。
(5)营销策略的分析。命名步骤当中,各细分类别客户的特征被提取出来。根据细分客户的类别,企业或網站可以对不同特征的用户实施不同的营销策略。如针对高客单价用户,其对小额优惠或低价产品可能敏感度较低,而应通过高质量、具有独特性或高认知度的产品或服务进行客户唤起,进一步增强客户认同。
3客户保持与流失的预测模型
3.1电子商务环境下客户保持与流失的特点分析
在电子商务环境下,由于信息流动速度快,客户选择范围极大拓展,用户对品牌忠诚度更易被动摇,购买决策会被多种因素影响,客户流失也有许多新的特点。
3.1.1用户信任更难建立
电子商务环境下,产品或服务的信息公开透明,企业难以通过信息不对称、或区域隔离,实施产品价格、促销政策等方面的垄断。随着行业竞争的公开化、透明化、全球化,企业不仅需要面对本地的竞品厂商,还要与世界各地的电商平台进行抗衡。在顾客面前放着更多选项的时候,顾客的需求标准也将逐渐提高,造成一种平台不仅要实现顾客的最低购物基本欲望的同时,还需要建立其独特的核心价值观的尴尬境地,在传播中持续传递和构建认同,使客户对企业价值观本身产生认可,从而建立客户对品牌的忠诚。
3.1.2评价指标趋向多元
电子商务环境下,产品和服务能够得到全方位的展示,但同样的,展示风格、广告创意、商品包装、快递速度、网页设计、营销活动等,都会影响到客户对商品和商家的整体评价,评价指标愈加多元化。
另外,由于客户对不同领域、不同品质的商品需求逐渐变化,加之各个平台的竞争和冲击,当下客户的忠诚度已然不能使用以往的关联特征进行描述,对产品或服务满意的同时,客户仍旧愿意选择转而尝试新的产品与服务,这一比例甚至高达65%~85%。贝思公司的一项调查显示,90%的背离客户会对他们以前获得的服务表示满意,也就是说,仅从客户满意与否来看,商家难以对客户是否可能流失进行预测。随着现代计算机技术的发展,通过模型和算法的优化,我们能够将更多样化的有效指标纳入客户流失的分析预测当中。
3.1.3客户认知具有实时性、交互性
在电子商务渠道中,客户可以通过网页的浏览顺序,相关页的跳转打开,视频、图片的播放展示,甚至网络直播等获得实时的、交互性的数据信息。客户与企业之间的沟通渠道也从传统的线下面对面沟通,到客服中心等的热线电话,发展到如今语音、文字、视频等多形式,时间、空间、地域等多维度的实时在线交流。
相应的,企业与客户沟通的方式和渠道也愈加多元,通过用户行为分析、客户价值分析、问卷调查、客户访谈等方式,企业能够迅速获取最新、最直接、最真实的客户信息,实时进行数据资料的更新。利用实时交互性数据进行的客户价值和流失可能性分析评估具有更强的效度和信度,更有利于企业制定有效战略。
3.2 AdaBoost算法
首先给定一个弱学习算法和训练集((x1,y1),(x2,y2),…, (xn,yn)),xi∈X,X表示其中的某个域或者实例空间;yi∈Y={1,-1},将分类问题作为一个带类别标志的集合进行分析,将回归问题作为一个数值进行计算。AdaBoost在每次迭代t=1,2,…,T时反复调用给定的弱学习算法。AdaBoost算法的主要思想,就是通过在指定训练集中进行训练,最终达到可以对一套固定的权重分布来进行维护的目的。在第t次迭代时,第i个训练样本(xi,yi)分布的权重记为Dt(i)。初始化时,对各个训练样本指定的初始权重均为1,保证在初始化时各个样本的权重都是相同的。然后通过调用多学习算法来对训练集进行T次迭代,并将每次迭代后的结果同训练结果重新输入训练集中,达到对训练集上的权重分布产生更新的目的。在此训练过程中,对其中所有失败训练例所赋予的权重偏大,从而使得学习算法在后续学习过程中,都可以针对之前训练中的这些失败的训练例进行学习,集中注意力在这些分类“困难”的样本上。
在迭代过程中,每一步弱学习算法的任务就是根据训练样本的分布及权重Dt产生一个弱假设ht:X→{1,-1}。弱假设ht的好坏由误判率εt来衡量:
(1)
该误判率的大小与弱学习算法训练所依靠的权重分布Dt相关。实际上,弱学习算法就是一个可以把权重分布Dt用在训练样本上的算法,通过权重分布对学习的训练的重点进行相应的识别。
在进行T次训练后,得到一个预测函数序列h1,h2,…, ht,AdaBoost算法就会给每隔弱假设h也赋予一个权重αt。αt可以对该弱假设的重要性进行衡量,对效果好的所赋予的权重大,对效果坏的赋予的权重小。αt的选取原则就是使损失函数能够最小。在进行T次迭代后,分类问题中最终的预测函数H(x),便以之前得到的权重分布为依据,使用投票的凡是来产生该函数。
代码如下:
训练集:S=((x1,y1),(x2,y2),…,(xn,yn)),xi∈X,yi∈ Y={1,-1}
初始化:Di=1/n,i=1,2,…,M
循環t=1,2,…,T
由Dt基于弱学习算法进行训练,得弱假设ht;
ht的误判率:;
选择;
更新权值
其中,为归一化算子(使得Dt+1为一个分布)
循环结束,输出最终假设:
(2)
(3)
3.3基于Logistic的回归分析算法
Logistic回归实际上是一种分类方法,用于二分类问题。
先找到一个合适的假设函数,该函数即为分类函数,用它来预测输入数据的判断结果,这个过程需要对数据有一定的了解和分析,并且知道预测函数的基本特征。
构造一个代价函数cost,即损失函数。用以表示预测的输出结果和训练数据的实际类别之间的偏差。若考虑所有数据,可以将cost求和或平均,记为J(θ)函数,表示所有预测结果和训练数据的实际类别之间的偏差。
最小化代价函数,获得最优的模型参数解,即J(θ)函数的最小值。因为函数的值越小预测结果就越准确,方法一般使用梯度下降法。例如:
(4)
(5)
拟合概率的Logit函数——Logit(πi),作为事件比值的对数,也就是事件发生地概率(成功)和事件没发生的概率(失败)的比值的自然对数:
(6)
引入阈值πi,大于πi则y^ =1,小于πi则y^ =0。拟合结果不一定很准确,因此需要有一个拟合误差,误差值尽可能小,与线性回归不同,响应变量的观测值不能被分解成拟合值和误差项的和。
用于连接πi和解释变量线性组合的Logit函数的选择,被概率逐渐趋向与0或1的实施所激励,同时概率值不能超过这个界限才能保证πi是一个有效地概率。因此,由于线性函数在预测结果的响应变量值上的结果没有限制,并不会满足二值响应变量所处的[0,1]区间,所以不能使用线性回归模型进行二值响应变量的预测。
在算法的执行过程中,从回归效果上来分析的话,Logistic回归和线性回归具有相同的特性,即若将回归过程中与输出变量无关的属性以及其余一些相似度高的属性进行删除之后,Logistic回归会更具优势。由此可以看出,无论是Logistic还是线性回归,若想使其的回归结果具有较好的性能,那么对特征能否进行适宜的处理便会起到关键的作用。同时Logistic回归与其他及算法相比,更容易从实际应用的实现相应的功能,并且在运行过程中所具有的效率也是很高的。
3.4基于AdaBoost的客户保持与流失预测模型
客户保持与流失的问题是一个二元的分类问题,就是通过对历史后台数据进行分析,针对客户对不同产品或企业的维持与流失情况进行规律总结,从而可以预测未来一段时间内客户对该产品或企业维持与流失的情况。客户管理人员,可以根据可靠的预测结果,对可能流失的重要的客户进行及时的挽救措施。
综上所述,AdaBoost相当于对若干个弱分类算法进行线性组合,从而得到最精确的预测结果。但是在整个预测过程中,AdaBoost仅仅是一个组合分类器算法,只能对每一个单个分类模型的训练结果进行组合融合,并未使用弱分类器作为基分类器来完善整个过程中的分类功能,因此对弱分类算法的选择也要进行综合考虑。C5.0决策树与神经网络相比,虽然二者的非线性拟合能力不相上下,但是C5.0决策树比神经网络具有更快的训练速度,并且泛化能力也要强于神经网络,因此本文选择C5.0决策树作为指定弱分类算法在AdaBoost中起到基分类器的作用。
4实验结果与结论
对于AdaBoost模型的整体训练过程而言,整个过程中的预测准确率是逐渐提升的,整个训练过程会针对在迭代过程中产生的错误进行以及并纠正,并将结果再次输入到训练集中,从而保证下次迭代过程中的预测准确率。随着训练伦次的增加模型的预测能力会不断地接近极限,当训练轮次够高的时候,每多训练一次模型的预测正确率提高就很小了。轮次的确定一般在模型的验证阶段进行。
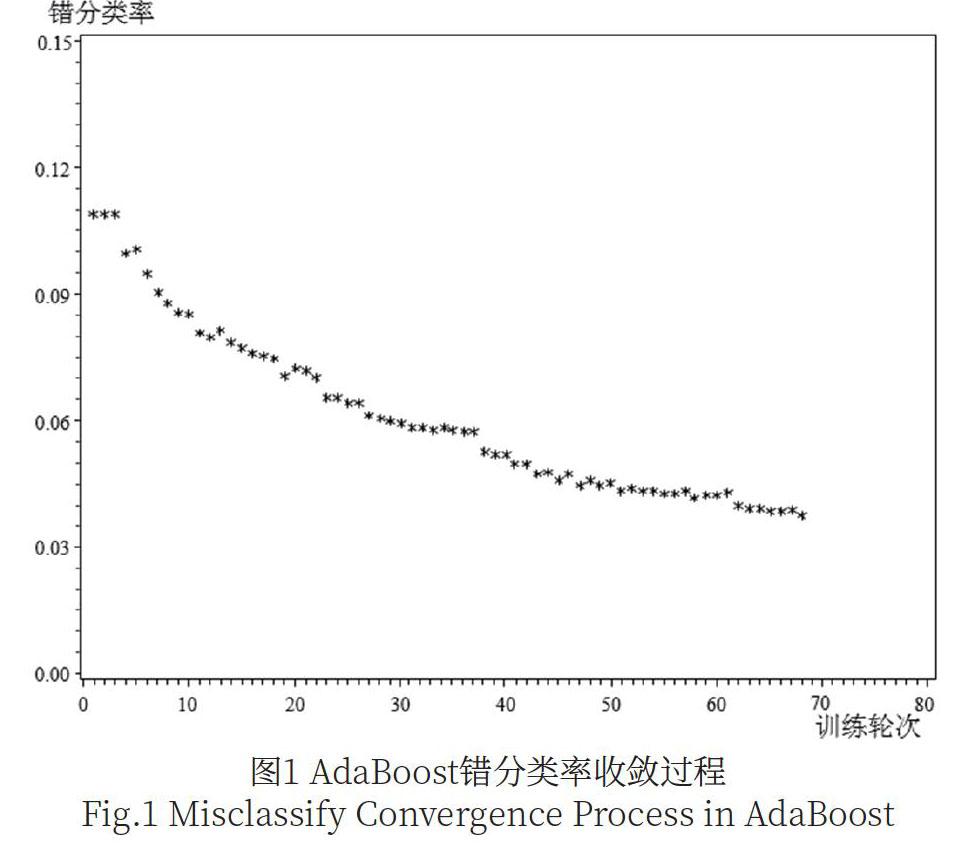
为表现本文的改进方法优越性,选取了几种常见模型与其进行比较,通过对同一个分类数据集建立AdaBoost模型,然后比较准确率的方式来说明AdaBoost算法的优势。使用SASEM,实验数据集进行建模。错分类率收敛过程如图1所示。
本文选取了4中常见模型进行比较,如表2所示:
综上所述,AdaBoost算法具有明显的优势,它的自动纠错能力相较于其他算法更适合用来进行分析。尽管精度仅仅比其他算法高约6个百分点,但在实际的生产生活中这些提升对模型带来的优化效果是巨大的。由此可见,本文提出的基于RFME和AdaBoost分类器的客户价值模型可为电商平台精确化计算出客户价值并根据计算结果预测客户流失。
参考文献
[1] RENJITH S.An integrated framework to recommend personalized retention actions to control B2C E-commerce customer churn[J].International Journal of Engineering Trends and Technology,2015,27(3):152-157.
[2] JU C H,LU Q B,GUO F P.E-commerce customer churn prediction model combined with individual activity[J].Systems Engineering-Theory & Practice,2013,33(1):141-150.
[3] ZHU Bangzhu.E-business customer churn prediction based on integration of SMC,rough sets and least square support vector machine[J].Systems Engineering-Theory & Practice,2010,30(11):1960-1967.
[4] YU X B,GUO S S,GUO J,et al.An extended support vector machine forecasting framework for customer churn in e-commerce[J].Expert Systems with Applications,2011,38 (3):1425-1430.
[5] 朱幫助,张秋菊,邹昊飞,等.基于OSA算法和GMDH网络集成的电子商务客户流失预测[J].中国管理科学,2011,19(5):64-70.
[6] SCHAPIRE R E.The strength of weak learnability[C]// Foundations of Computer Science,1989.30th Annual Symposium on.IEEE,1989:197-227.
[7] BREIMAN L.Bagging predictors[J].Machine Learning, 1996,24(2):123-140.
[8] YING Weiyun,LIN Nan,XIE Yiayia,et al.Research on the LDA boosting in customer churn prediction[J].Journal of Applied Statistics & Management,2010,29(3): 400-408.
[9] LIU M,QIAO X Q,XU W L.Three categories customer churn prediction based on the adjusted real adaBoost[J]. Communication in Statistics-Simulation and Computation, 2011,40(10):1548-1562.
[10] ZHANG Wei,YANG Shanlin,LIU Tingting.Customer churn prediction in mobile communication enterprises based on CART and Boosting algorithm[J].Chinese Journal of Management Science,2014,22(10):90-96.
[11] 刘远君.基于统计方法的交易平台型电子商务网站CRM应用研究[D].杭州:浙江工商大学.
