大规模可变C代码增量式分析方法
2021-08-17石剑君刘法旺计卫星杨玚
石剑君 刘法旺 计卫星 杨玚


摘 要:提出一种基于头文件复用的大规模可变C代码增量式分析方法。以Linux内核代码为例,首先统计和分析了大规模C代码中的头文件包含情况。然后根据头文件包含顺序,构建C代码分析的头文件加载树。最后,按照头文件加载树增量地分析C代码。实验结果表明,与原有的代码分析方法相比,本方法可以极大地提升大规模可变C代码分析的效率。
关键词:大规模C代码;可变代码;代码分析
中图分类号:V211 文献标识码:A DOI:10.3969/j.issn.1003-6970.2021.03.023
本文著录格式:石剑君,刘法旺,计卫星,等.大规模可变C代码增量式分析方法[J].软件,2021,42(03):079-085
Incremental Parsing Method for Large-scale Variable C Source Code
SHI Jianjun1, LIU Fawang2, JI Weixing1, YANG Yang3
(1.School of Computer Science, Beijing Institute of Technology, Beijing 100081;
2.Ministry of Industry and Information Technology Equipment Industry Development Center, Beijing 100846;
3.China Software Testing Center, Beijing 100086)
【Abstract】:An incremental code parsing technique for large-scale variable C source code is proposed. Taking the Linux kernel source code as an example, firstly, we summarize and analyze the included header files in large-scale C source code. Then, header file loading trees are built according to the inclusion order of header files. Finally, the C source code is parsed incrementally based on the header file loading trees. The experimental results show that compared with the traditioanl code parsing methods, our method can greatly improve the efficiency of large-scale variable C source code parsing.
【Key words】:large-scale C source code;variable code;code parsing
目前,大規模C程序已广泛存在于实际生产实践中,例如,Linux 内核、Apache HTTP Server和Mozilla Firefox等程序的代码规模已超过百万行,甚至达到几千万行。相比于普通程序,大规模C程序的开发、管理和维护都变得更加困难。
为了对程序进行优化,自动发现程序中存在的潜在问题,研究人员提出了静态分析和动态分析等程序分析技术[1-2]。静态程序分析是程序分析中一种有效的技术手段,它主要指在不运行程序的情况下,从源代码中提取程序的结构化信息,再进行进一步分析和处理。通过静态程序分析,开发人员可以在开发阶段即可发现代码中存在的潜在问题,从而实现代码优化、缺陷检测和修复,提升程序开发的效率。静态程序分析通常需要借助于编译器前端工具解析源代码,首先通过预处理、词法分析和语法分析等步骤,从源代码或者中间代码中提取出抽象语法树、函数调用图和控制流图等,再利用抽象解释[3]、数据流分析[4]和符号执行[5]等方法对源代码进行分析。
然而,大规模C程序的静态代码解析过程面临诸多挑战:(1)C程序中广泛存在头文件包含、宏定义和条件编译等预处理指令,增加了代码的可变性,代码解析的难度也随之增大;(2)大规模C程序的规模庞大,代码解析的开销较大。例如,Linux内核的源代码规模已超过2700万行,对如此庞大规模的代码进行解析,将面临巨大的时间和空间开销。尽管研究人员提出很多可用于C程序静态源代码解析的工具,然而却难以直接用于大规模C代码分析的过程中。
本文提出一种基于头文件复用的大规模C代码增量式解析方法,用于解析含有可变代码的大规模C代码。该解析方法主要通过分析大规模代码中头文件的复用情况,构建出用于代码解析的头文件加载树,按照头文件加载顺序解析C代码,无需重复解析大量头文件,从而提升了大规模C代码解析的效率。
1 可变代码解析
为了使程序具有较好的可读性和可维护性,能够在不同的软硬平台上编译运行,C程序中通常包含了大量的宏定义和条件编译等预处理指令。在C程序编译时,编译器首先完成宏替换,并根据条件编译的不同分支,选择相应的代码块进行编译,从而生成不同的目标程序。在C程序中,这些预处理指令控制了代码的可变性(Variability),因此,包含了预处理指令的代码也称为可变代码或可配置代码。
C程序的编译过程包含预处理、词法分析、语法分析、中间代码生成、代码优化和目标代码生成等环节,其中,程序静态分析主要关注中间代码生成之前的过程,即编译器前端的执行过程。预处理阶段主要对源文件中的头文件包含、宏定义和条件编译等预处理部分进行处理。词法分析阶段的任务是对输入符号串形式的源程序进行处理,依次扫描源程序中的每个字符,识别出源程序中有独立意义的语言单词,最后输出token流。语法分析是依据语言的语法规则,对词法分析结果进行语法检查,通常语法分析的结果是一个抽象语法树,是源码的一种中间表示形式。
本文关注的静态代码解析过程与编译器前端分析过程的不同在于:对于给定的具有可变性的C程序源代码,编译器在进行前端分析时只是根据预设的宏定义对部分源代码进行处理,所生成的目标代码中并没有考虑条件宏的所有定义。本文所提出的代码分析方法则关注C代码中可变代码的解析,即在代码解析的过程中,需要解析不同编译条件下的所有代码。如图1所示的Linux kernel v3.19中的一段代码,如果CONFIG_CMA已经被定义,则编译器会选择1040行和1041行#ifdef和#else之间的代码进行编译;否则会选择1043行#else和#endif之间的代码进行编译。然而为了支持代码审查,帮助开发人员走读代码,理解源码结构和内容,以及对代码进行可视化,可变代码分析需要解析1039到1044行之间的所有代码,需要同时考虑CONFIG_CMA定义和未定义两种情况。现有的编译器在遇到条件编译时只选择其中的一个条件分支进行编译,无法支持可变代码的分析,因此需要设计特定的工具支持可变代码的分析。
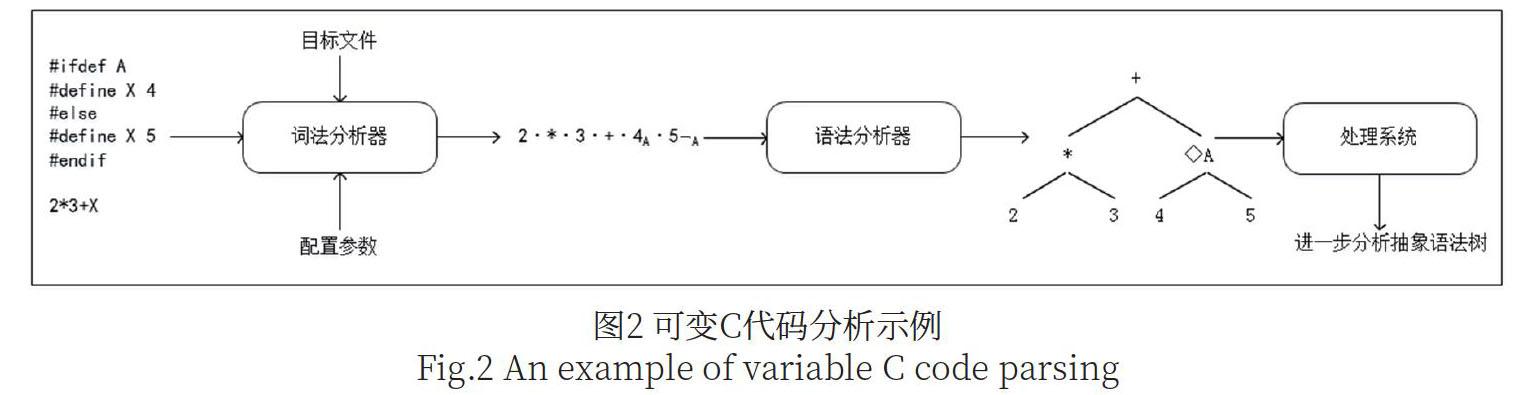
图2展示了一段简单的可变C代码的解析过程。该代码在#ifdef A条件成立时,执行“#define X 4”。否则,则执行“#define X 5”。在该可变代码的解析过程中,主要包含词法分析、语法分析和处理系统三个部分。其中,第一部分是可以分析条件编译指令的词法分析器,其作用是将代码片段转为带有条件的token流。对于上述示例生成的token流中,在#ifdef A之后的所有token都会带有一个条件A的标签,直到相应的#endif结束。对于条件#ifdef A和#ifdef B嵌套的情况,token中的条件标签就会使用 A∧B这样的标识。对于#if ? #elif ? #else ? #endif也会有相应的条件标签标识。对于图2中的输入程序“2*3+X”,经过词法分析得到的token流为“2·*·3·+·4A·5?A”。第二部分是语法分析,其目标是根据词法输出的token流生成可以标识编译条件的抽象语法树,如图2中语法分析所生成的抽象语法树。语法分析器基于带有条件标签的token流进行分析,产生选择结点,用?来标识,其中左子树代表定义 A的解析结果,右子树代表没有定义A的情况。第三部分是可以解析带有条件分支的抽象语法树的分析器,可以对抽象语法树做进一步解析处理。
对使用了大量编译预处理指令的C语言程序进行分析是C程序分析和应用过程中面临的重点问题之一。例如,在C程序代码重构的过程中,需要保证不同条件编译分支的代码都得到正确处理[6]。另外,目前很多集成开发环境如Visual Studio等都提供了即时语法检查的功能,能够在用户输入代码的同时对代码进行全面的分析和检测,如果输入代码包含了条件编译指令,则应尽可能地检测出不同分支的具体问题[7]。以上这些应用场景要求建立一个能够分析可变性代码的代码分析工具。
2 相关工作
目前常用的静态分析工具如GCC[8]、GNU Cflow[9]和Clang[10]等,这些工具虽然可以分析C程序源文件的集合并输出各函数之间的图表依赖关系,但对源码中的条件编译指令等可变代码的解析存在一定的局限性。例如,Cflow无法直接对目录进行递归分析,只能支持文件级的代码分析,并且不同文件中的重名函数都被视为同一个函数。
Doxygen[11]是一个用于程序文档生成的工具,可以收集程序源码中关于函数和变量的信息。Doxygen支持多种流行的编程语言,如C、Object-C、C#和Java等。Doxygen可以解析源码文件的代码结构,并输出文件中遇到的符号的交叉引用,包括函数、变量和结构体类型的引用关系。利用Doxygen分析源码,可以为每个源文件输出一个包含源码结构的XML文件。結合Graphviz绘图工具,Doxygen可以生成程序源码的函数调用关系图,Doxygen依照配置文件还可以产生HTML、Tex和XML等多种格式的输出文档,其中HTML中用有向图表示了函数之间的调用关系。然而,Doxygen无法支持可变代码的解析。
为了获取源码中条件编译所有可能分支下的代码信息,Christian Kastner等人提出一个新的分析框架TypeChef[12],它主要由三个部分组成:第一部分是可以分析条件编译指令的词法分析器,其作用是将代码片段转为带有条件的token流。第二部分是语法分析,其目标是根据词法输出的token流生成可以标识编译条件的抽象语法树。第三部分是可以解析带有条件分支的抽象语法树的分析器,可以对抽象语法树做进一步解析处理。从以上三个步骤可以发现,TypeChef通过修改词法分析器,使其可以解析未经过预处理的代码,得到带有条件的token流,然后再用语法分析器将token流转为带有条件的抽象语法树,最后再对抽象语法树进行分析,这样可以更加全面地分析源码中的符号信息。以Linux内核代码为例,Linux内核源码根据条件编译可以产生不同的目标代码,其中的代码可变性与源代码中定义的宏有关,在配置文件中设置的宏可以控制具体的目标代码。对于配置文件中的宏,TypeChef用Waterloo大学的Czarnecki开发的提取Linux内核配置变量的工具[13-15]来提取源码中相关的宏定义,并且选择在配置变量定义的情况下获取源码文件[16]。TypeChef解析了Linux kernel v2.6.33.3版本中X86架构下的源代码,根据该工具得到6065个配置宏定义,在配置宏定义的情况下得到7665个源码文件(总共有899万行非空行代码)。
纽约大学Paul Gazzillo等人也提出一种解析原理与TypeChef类似的工具SuperC[17]。SuperC也是经过修改词法分析器、语法分析器,使其可以分析未经过预处理的代码,得到一个可以完整地表示程序结构的抽象语法树。SuperC解析C程序主要包括三个步骤:词法分析、预处理、语法分析。(1)词法(Lexing)分析的输入是C语言源码,输出是带有条件的token 流。(2)预处理过程是分析token,得到一个宏符号表,存储所有的宏以及宏相关的条件。例如,图3所示的代码片段:由于宏const_debug在不同条件下定义不一样,所以const_debug就会被存储多份,并且存储的每个宏都会带有其定义的条件。对于含有歧义的代码,预处理器也是会存储不同的版本。(3)语法分析是解析预处理之后的token。语法分析器是LR分析器的变体,与LR分析器的不同之处在于遇到条件分支可以通过创建子分析器来分析另一个分支路径,在两个分析器状态值一样的情况下再合并。子分析器与主分析器有相同的下推分析栈(分析栈中记录了迄今为止所移进或归约出的全部文法符号,即记录了从分析开始到目前为止的整个分析历史)。
当在相同状态下有相同的输入时就会合并解析器,但该工具在合并过程中必须保证每个子分析器所分析的代码结构是完整的。如图4所示的代码片段:第8行满足了分析器合并条件,但是由于子分析器中分析的是5-7行,该段代码的C语言结构是不完整的,因此,SuperC不会在第8行合并,而是在第9行处理完之后再合并,保证了子分析器中的代码语法的正确性,最后得到一个可以表示源码条件分支的抽象语法树。SuperC与TypeChef一样,也是通过修改词法分析与语法分析使其可以解析没有经过预处理的源码,得到源码中的所有符号信息。但这种经过修改的解析器都有各自的局限性,在使用时需要很复杂的配置,尤其对于Linux内核这样复杂的项目,配置更是困难,因此其可用性较低。
3 增量式可变代码解析
尽管研究人员提出了TypeChef和SuperC等方法可以用于大规模C代码的解析,这两个工具重新设计了编译器前端的词法分析器和语法分析器,构建了带条件的语法分析树,将源代码的编译条件带到了语言的中间代码表示中,从而为程序的进一步分析处理奠定了良好的基础。但是由于Linux代码的规模过于庞大,这些工具的使用配置复杂,用户很难准确配置,并输出期望的结果。
图5显示了Linux kernel v3.19中的一段可变代码,该代码片段中包含了条件编译指令#ifdef CONFIG_ACPI和#ifdef CONFIG_X86,其二者之间存在嵌套关系。在解析该代码片段的过程中,很多可变代码解析工具如SuperC等遇到第一个条件编译指令#ifdef CONFIG_ACPI时,需要克隆一个新的编译实例以实现不同条件编译分支的编译和解析。当遇到嵌套的第二个条件编译指令#ifdef CONFIG_X86,需要再次克隆一个新的编译器实例,从而使得代码解析的时间开销大大增加。而Linux内核这样的大规模复杂C代码包含大量的条件编译指令,因此,利用SuperC进行内核代码解析的开销非常大。
3.1 Linux kernelv3.19头文件复用情况
Linux内核是典型的大规模C语言程序,以3.19版本为例,其中包括54180个文件,18406489行代码,并且包括了923640个宏定义和41398个条件编译指令,而多个宏定义嵌套和条件编译嵌套会导致更加复杂的代码结构。虽然TypeChef和SuperC给出了可变代码分析与提取的可行方案,但是对如此大规模代码的分析仍然需要较长的时间。从另一个角度考虑,大规模代码也为可变代码解析加速提供了其他的可能。对Linux内核代码进行仔细分析发现,尽管内核代码中大量的条件编译指令,但这些条件编译指令大多存在于头文件中,且在C代码编译的过程中,很多头文件被多次包含,头文件的重复解析大大降低了代码解析的效率。本文统计了Linux kernel v3.19代码中头文件的包含次数,表1展示了被包含次数最多的10个头文件。其中,头文件module.h被包含的次数最多,达到6911次。除此之外,init.h、kernel.h和slab.h被包含的次数也超过了5000余次。
3.2 基于头文件复用的增量式解析方法
uperC等代码解析工具在分析每个C文件代码时需要合并所有的头文件代码再进行分析。因此,尽管一個头文件可能被多个C文件包含,但在解析不同C文件的过程中,该头文件都会再次被解析,导致代码解析的开销大大增加。本文提出一种基于头文件复用的增量代码解析方法,首先分析内核C代码中头文件的复用情况,然后,在解析每个C文件的过程中,如果头文件被复用,则直接获取头文件的解析结果,而不再重复解析该头文件。由于在每个C文件中,头文件是按顺序被加载的,头文件之间可能存在依赖关系,因此,本方法首先以Linux内核中头文件的加载顺序构建加载树,再按照头文件加载树依次增量解析C文件代码。
如图6所示的头文件加载树,树中的每个非叶子结点(矩形)代表头文件,叶子结点(椭圆形)代表要解析的C文件,头文件之间的边代表加载顺序,头文件与C文件之间的边代表从根结点出发到达此C文件的头文件都被包含于该C文件中。因此,按照图中的加载顺序进行解析,所有的头文件和C文件只需要被解析一次。例如,C文件arch/sparc/lib/atomic32.c、drivers/acpi/ac.c、drivers/acpi/sbs.c和drivers/acpi/processor_perflib.c 在编译的过程中都需加载头文件module.h,而drivers/acpi/ac.c、drivers/acpi/sbs.c、drivers/acpi/processor_perflib.c 在编译时都需加载头文件module.h、init.h、kernel.h、slab.h 和types.h,因此,在解析这些C文件时,原有的解析方法将对module.h解析4次,对init.h、kernel.h、slab.h和types.h分别解析3次,而按照本文的方法,上述头文件都只需被解析1次。
基于上述思路,本文提出的增量式可变代码解析的具体工作流程如算法1所示,首先扫描所有的C文件,获取包含的文件列表。为了保证语义的正确性,本文只获取每一个C文件开始部分连续包含的文件,遇到代码部分则立即停止。然后对于每个C文件的include列表,从树的根节点开始查找对应深度的头文件,如果已经在某条路径上发现,则直接复用,否则创建一个新的节点和分支路径。头文件加载树的每个节点对应一个头文件,并且可能包含到达该节点的所有C文件。
算法1:头文件加载树构建buildTree
输入:根节点root、某个C文件ci的include列表hl、递归深度depth
输出:更新后的头文件加载树
Begin:
If depth == length(hl) Then
root.cFileList.append(ci)
return
End
hf ← hl[depth]
If hf not in root.children Then
Create a new node n
n.hFile ← hf
root.children ← root->children.append(n)
Else
n ← find node from roots children list using hf
End If
buildTree(n, hl, depth+1)
End
與SuperC不同,本文提出的解析方法从头文件加载树的根节点开始,首先对每个节点对应的头文件内容进行解析,然后对解析器进行复制,在同一个状态下分别对该节点对应的C文件进行解析。如果该节点有多个子节点,则也需要对解析器进行复制,以对后续的节点分别进行遍历和解析。
具体过程如算法2所示。
算法2:文件解析算法parse
输入:根节点root,可变代码解析器P
输出:更新后的头文件加载树
Begin:
Parse root.hFile
For c in root.cFiles
P ← Deep copy p
Parse c using P
End For
If root has one child Then
Parse(n, P)
Else
For each n in roots children list
P ← Deep copy p
Parse(n, P)
End For
End If
End
该算法首先对当前节点对应的头文件进行分析,然后检查当前节点是否有C文件,如果有的话就对分析器进行拷贝,对每个C文件进行分析并输出分析结果。处理完当前节点后,检查当前节点是否有多个节点,如果有多个节点,则同样需要对分析器进行拷贝,以隔离的状态递归处理不同的分支。当前节点如果只有一个子节点,则可以直接基于当前的分析器状态继续分析。
事实上,Linux内核中头文件的复用情况更加复杂,而头文件中的宏定义和条件编译等预处理指令是代码解析中最耗时的部分,因此,采用本文的方法可以大大缩短C代码解析的时间。
4 实验评估及结果
4.1 实验环境
本文以Linux kernel v3.19源代码为实验数据。实验环境为Windows 10操作系统,CPU为Intel i7-7700,内存为16GB。本方法利用已有的可变代码解析工具SuperC实现对Linux kernel v3.19代码的解析,SuperC的版本为2.4.0。
4.2 性能评估
为了评估本章提出的基于头文件复用的增量代码解析方法的有效性,分别用本方法和SuperC工具解析Linux kernel v3.19的源代码,并将其代码解析的时间进行了对比。
实验结果表明,用原方法解析内核代码的时间为91小时,而采用本方法时解析时间仅为56小时。表2列出了解析不同Linux内核目录时,本方法与SuperC解析的时间对比。整体上来讲,与原方法相比,本方法解析Linux内核代码所需的时间大大缩短了,平均加速比达到1.59。
图7展示了C文件中包含的头文件序列长度与这些头文件序列被复用的次数的关系。从图7中可以看出,在Linux kernel v3.19代码中,头文件被包含的最长序列长度为29,且只有2个C文件中包含了如此多的头文件数目。被复用次数最多的头文件序列长度为2,复用次数多达439次。
5 结论
本文设计了一种用于大规模可变C代码增量式解析的方法。本方法基于头文件复用设计了可用于C代码增量解析的文件加载树。以Linux kernel v3.19为例,与传统的可变C代码解析方法相比,本文提出的代码解析方法可以更加高效快速地解析大规模可变C代码。
参考文献
[1] 陆申明,左志强,王林章.静态程序分析并行化研究进展[J].软件学报,2020,31(5):7-18.
[2] 陈厅.动态程序分析技术在软件安全领域的研究[D].成都:电子科技大学,2013.
[3] GANGE G,NABAS J A,SCHACHTE P,et al.Abstract interpretation over non-lattice abstract domains[C]//International Static Analysis Symposium. Springer, Berlin, Heidelberg,2013: 6-24.
[4] REPS T,HORWITZ S,SAGIV M.Precise interprocedural dataflow analysis via graph reachability[C]//Proceedings of the 22nd ACM SIGPLAN-SIGACT symposium on Principles of programming languages.1995:49-61.
[5] TRABISH D,MATTAVELLI A,RINETZKY N,et al. Chopped symbolic execution[C]//Proceedings of the 40th International Conference on Software Engineering. 2018:350-360.
[6] 周天琳,史亮,徐寶文,等.Refactoring C++Programs Physically重构C++程序物理设计[J].软件学报,2009,20(003): 597-607.
[7] Visual studio.https://visualstudio.microsoft.com/.
[8] Gcc,the gnu compiler collection.http://gcc.gnu.org/.
[9] Gnu cflow.http://www.gnu.org/software/cflow/.
[10] Clang:a C language family frontend for LLVM. http://clang.llvm.org/.
[11] Doxygen.http://www.doxygen.org/.
[12] KASTNER C,GIARRUSSO P G,RENDELende T,et al.Variability-aware parsing in the presence of lexical macros and conditional compilation[J].Acm Sigplan Notices,2011,46(10):805-824.
[13] SAKAGUCHI S,TAKAHASHI T,HATA H,et al.Variability modeling in the real:a perspective from the operating systems domain[C]//Proceedings of the IEEE/ACM international conference on Automated software engineering, 2010:73–82.
[14] SHE S,LOTUFO R,BERGER T,et al.Reverse engineering feature models[C]//Proceedings of the 33rd International Conference on Software Engineering,2011:461-470.
[15] SHE S,LOTUFO R,BERGER T,et al.The Variability Model of The Linux Kernel[C]//International Workshop on Variability Modelling of Software-intensive Systems, 2010:45-51.
[16] BERGER T,SHE S,LOTUFO R,et al.Feature-to-code mapping in two large product lines[C]//International Conference on Software Product Lines:Going Beyond, 2010:498-499.
[17] GAZZILLO P,GRIMM R.SuperC:parsing all of C by taming the preprocessor[C]//ACM Sigplan Conference on Programming Language Design and Implementation, 2012:323-334.
