基于多损失值融合神经网络的语音增强研究
2021-04-22朱世宇李根孙令翠谢箭柏森孟宓
朱世宇 李根 孙令翠 谢箭 柏森 孟宓
(1.重庆工程学院,重庆 400056;2.重庆电讯职业学院,重庆 402274)
0 引言
多个研究中指出,增强后语音均方差损失值得分较小的语音(与相对应干净语音相比)不能保证其具有高语音质量和高可懂度[1-2],均方差损失函数,其缺乏与人类听觉感知系统或人类听觉间的关联。对语音增强神经网络损失函数的改进,能提高语音增强神经网络性能,从而解决其受损失函数制约性能的问题。
本研究中提出的多损失值损失函数,由经过训练的语音生成对抗神经网络中的判别网络,融合均方差损失函数构成。在判别网络损失函数基础上,使用均方差损失函数,保证了增强语音与干净语音间的相关性。
此外本研究中提出的基于多损失值融合神经网络,使用音频波纹数据作为输入,在较多语音增强神经网络模型中,使用语音频域信息作为输入[3-4],语音音频数据与语音频域数据转换过程,并非完全可逆,转换过程中语音音频部分细节信息(例如相位信息)丢失[5]。直接使用音频波纹数据作为输入,保留了音频数据的细节信息。为保证语音音频细节信息在卷积网络层间的流动,在卷积网络特定层间添加跳连结构,使相位、校正等语音音频细节信息,不经过卷积网络进行特征抽取压缩,直接在各卷积网络层间流动。也进一步避免了语音音频细节信息丢失的问题。
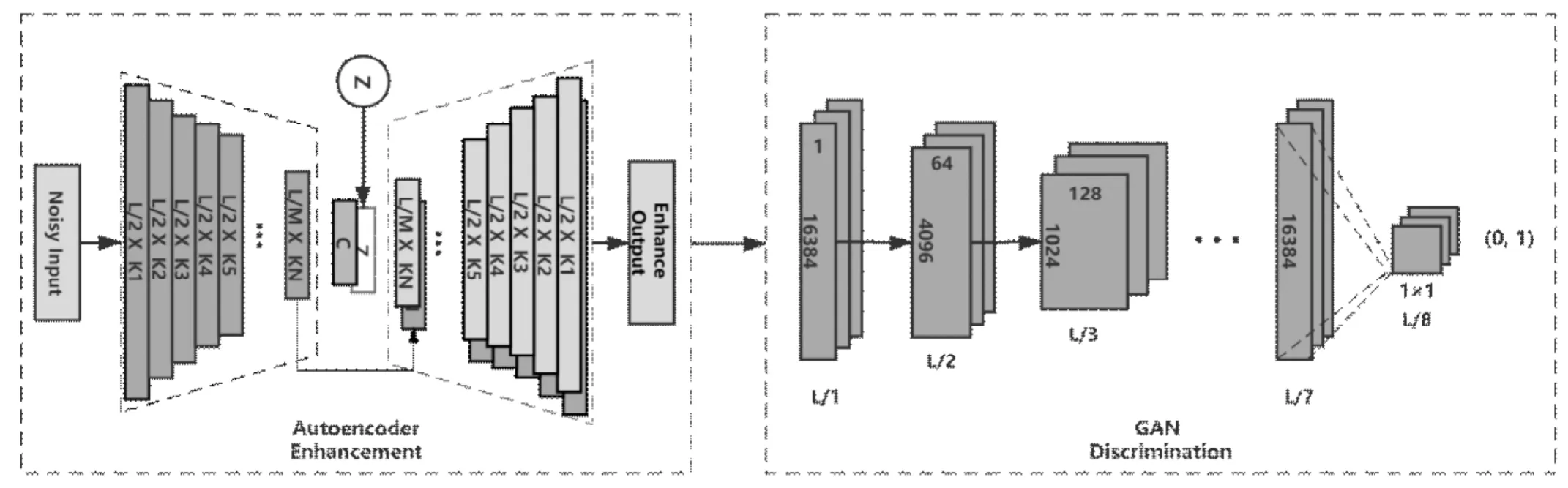
图1 多损失函数结构Fig.1 Multi-loss function structure
1 多损失函数
使用对抗网络判别器作为损失函数,判别器网络被链接在基于自编码器的语音增强网络后。其网络结构如图1所示。
如图中所示,语音增强结果将继续被输入判别器网络结构。判别器网络结构并不参加网络模型训练,判别器网络权重由对抗神经网络训练获得,判别器将对语音增强结果进行计算给出二分类结果值。
假设带噪语音输入为ˆ,带噪语音经过自编码器的语音增强网络获得增强后的语音,增强结果继续经过对抗网络判别器计算获得结果为0与1的真假二分类结果。最终的损失值计算为:
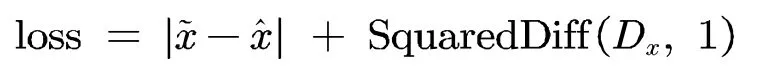
其中的SquaredDiff为差平方函数,式中将求得Dx与1的差平方结果。为平衡两部分计算结果差值的数量级,将引入超参 ,所以最终的损失式为:

其中均方差损失值与判别网络损失值,数值相差为两个数量级。将各损失值统一到同以数量级,可避免其梯度变化倾向于单个损失函数[5]。因此引入经验参数λ,根据数量级差异在实验中设置λ=100。
2 实验方案
为完成多信噪比下,语音增强神经网络,语音增强性能的评估。以及多种噪声环境下其语音增强性能评估,本研究实验分两部分完成。
第一部分实验,此部分采用不同信噪比下的语音进行实验,具体的,选择了四个信噪比(SNR),即0dB、5dB、10dB、15dB的测试语音音频,进行语音增强实验。为获得良好性能的判别网络,首先对语音生成对抗神经网络进行训练。其中共投入473段人声语音数据,其原始语音长度为38秒,经过分割为时长为1秒的训练数据,总共约为20000段训练音频。语音生成网络使用20000段左右语音进行了训练,即一个训练周期(Epoch)。而后为训练基于多损失值融合神经网络的语音增强模型,进行150个训练周期的网络训练。
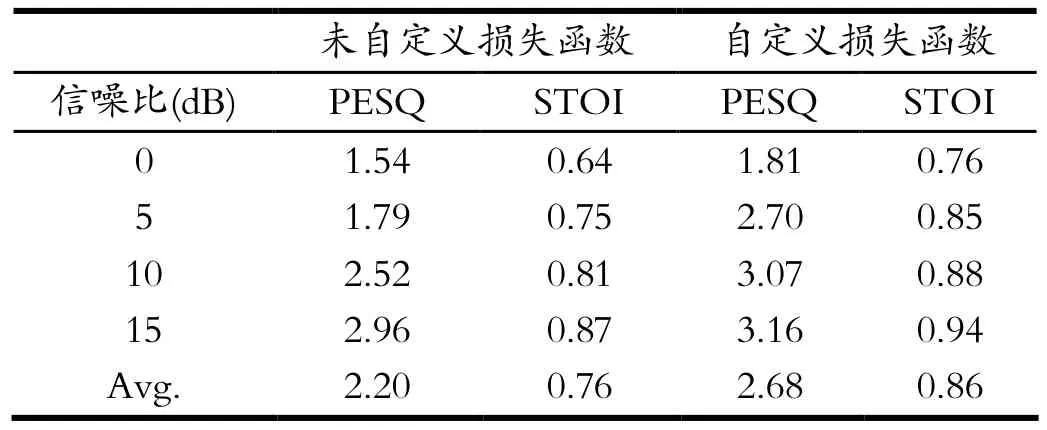
表1 PESQ与STOI对比结果Tab.1 Comparison results of PESQ and STOI
第二部分实验,为了证明具有多损失函数的自编码语音增强网络的在多种噪声下的普适性。设计了一组对照实验。与实验第一部分相同使用了一个训练周期的语音生成对抗网络模型中的判别网络。将未自定义损失函数的语音增强网络,与加入自定义损失函数后的语音增强网络,经过同样的40个训练周期,以及150个训练周期的训练,两模型使用同样的参数配置,且均为首次训练。随后随机选择16组不同噪声语音音频进行测试。两模型也均采用相同数据,进行训练与测试。通过PESQ与STOI评分进行评价,每组对照实验进行4次。未自定义损失网络模型采用均方误差作为损失函数。

图2 (b)噪声语音Fig.2(b) Noise speech

图2 (c)增强语音Fig.2(c) Enhanced speech
3 实验结果
通过在不同信噪比下对不具有自定义损失函数的基于自编码器的语音增强模型,与具有自定义损失函数的基于自编码器的语音增强模型,进行对比其结果如表1所示。从结果中可以看出具有自定义损失函数的模型下,PESQ评分均值相较于未自定义损失函数的模型,高出约0.4个点,STOI评分高出0.1个点。且在不同信噪比下具有自定义损失函数的模型分数均高于不具有自定义损失函数模型。因而具有自定义损失函数的基于自编码器的网络模型,相较于MSE损失函数即传统损失函数的自编码器网络模型,在性能效果上具有提升。
语谱图时声音频率随时间变化的直观表示,如图2所示,图2为信噪比为10dB的增强语音信号语谱图,图2(a)为纯净语音的语谱图,图2(b)为带噪声语谱图,图2(c)为增强后语音的语谱图。通过语谱图可观察到,被噪声掩盖的语音信息,在增强后有明显恢复。如图中的A-a区域至C-a区域,原本被噪声遮盖的B-a区,在经过语音增强后C-a区对其进行了恢复。
