融合稀疏点云补全的3D目标检测算法
2021-04-10倪蓉蓉
徐 晨,倪蓉蓉,赵 耀
融合稀疏点云补全的3D目标检测算法
徐 晨1,2,倪蓉蓉1,2,赵 耀1,2
(1. 北京交通大学信息科学研究所,北京 100044; 2.现代信息科学与网络技术北京市重点实验室,北京 100044)
基于雷达点云的3D目标检测方法有效地解决了RGB图像的2D目标检测易受光照、天气等因素影响的问题。但由于雷达的分辨率以及扫描距离等问题,激光雷达采集到的点云往往是稀疏的,这将会影响3D目标检测精度。针对这个问题,提出一种融合稀疏点云补全的目标检测算法,采用编码、解码机制构建点云补全网络,由输入的部分稀疏点云生成完整的密集点云,根据级联解码方式的特性,定义了一个新的复合损失函数。除了原有的折叠解码阶段的损失之外,还增加了全连接解码阶段存在的损失,以保证解码网络的总体误差最小,从而使得点云补全网络生成信息更完整的密集点云detail,并将补全的点云应用到3D目标检测任务中。实验结果表明,该算法能够很好地将KITTI数据集中稀疏的汽车点云补全,并且有效地提升目标检测的精度,特别是针对中等和困难等级的数据效果更佳,提升幅度分别达到6.81%和9.29%。
目标检测;雷达点云;点云补全;复合损失函数;KITTI
近年来,随着硬件设备性能的飞速提升,目标识别、检测、跟踪、语义分割等在日常生活中的应用场景越来越广泛,如自动驾驶、虚拟现实与增强现实、移动机器人、智能家居等。对于自动驾驶和机器人导航等对位置敏感的应用,在传统的2D目标分类、检测算法中,使用相机获取的RGB图像作为输入,无法提供准确的3D位置信息。而3D目标检测中使用的雷达点云数据,与二维图像相比,拥有更加丰富的深度信息,并且还具有抗干扰的优势,恰好可以解决2D图像系统所面临的挑战。因此,3D目标检测成为近几年学术界和工程界的共同兴趣所在。
对于3D目标检测,使用何种数据类型作为输入,以及如何处理数据,成为研究的重点。最原始的3D目标检测,仅仅使用图像作为网络输入,将同一目标不同角度的图像,作为神经网络的输入进行特征提取,其优点为输入单一,充分利用了相对成熟的2D目标检测方法,但不足是2D模型向3D模型转化时造成信息丢失,检测精度极低;为了解决使用图像进行3D目标检测过程中精度低的问题,CHEN等[1]在2017年提出Multi-View方法,可使用RGB图像、点云正视投影、点云俯视投影共同作为输入,虽然检测精度大大提高,但由于对点云进行了手工投影处理,造成了大量信息丢失,并且使用到了俯视投影,对小目标如行人、自行车等物体的检测基本无效;为了解决信息丢失这一问题,ZHOU和TUZEL[2]于2018年提出了端到端的学习方法VoxelNet,直接将激光雷达获取到的原始点云数据作为网络输入,无需进行任何投影等手工处理。由于空间中点云数据相当大,目标检测搜索的范围广,且每一个点都是三维数据,因此在神经网络卷积层中涉及到了三维卷积,计算量极其庞大,不满足用于自动驾驶场景中实时性检测的要求;2019年SHI等[3]提出了PointRCNN的3D目标检测方法,其同样仅使用雷达点云作为网络输入,通过将点云分割为前景和背景对象来生成少量、高质量的3D提案,来自分割学习的点的代表不仅善于生成提案,还对后面的Box优化也有所帮助;QI等[4]提出了VoteNet框架,是一个基于深度点集网络和霍夫投票的端到端3D目标检测网络,不再依赖2D检测器。这2种仅仅依赖雷达点云的目标算法,对于点云稀疏的情况并不理想。为同时解决精度、信息丢失、计算量、点云稀疏的问题,本文提出了F-PointNet[5]算法,即先利用发展相对成熟的2D目标检测形成候选框,再根据相机和候选框的位置形成视锥,在视锥范围内使用原始点云数据进行3D目标检测,这既减小了空间点云的搜索范围,也大大降低了计算量。
在实际应用场景中(如无人驾驶),由于激光雷达分辨率、扫描距离、遮挡问题等因素的限制,现实世界中的三维数据往往是不完整的[6]。如图1所示,1号车辆为扫描到的较为完整的车辆信息;2号车辆由于相机与目标之间的位置关系存在一定的偏离,信息不完整;3号车辆由于距离相机位置较远,也有一定的信息丢失,由于数据信息的丢失对于3D目标检测是极其不利的。
因此,为了在进行3D目标检测时得到更为准确的检测结果,本文采用深度学习的方法对缺失的点云进行补全。
1 相关技术
F-PointNet算法是实现端到端学习的3D目标检测网络框架,如图2所示。主要步骤如下:
(1) 2D目标检测。以RGB图像作为输入,采用RPN网络,生成二维候选框;
(2) 视锥生成。根据相机位置以及2D候选框,利用计算机图形学中的方法生成视锥;
(3) 3D实例分割。为了去除视锥内的非感兴趣点云,利用PointNet算法[7]将视锥内的检测目标分割开;
(4) 3D框估计。对于分割出的目标点云,利用改进的PointNet算法输出3D框参数,完成3D目标检测任务。
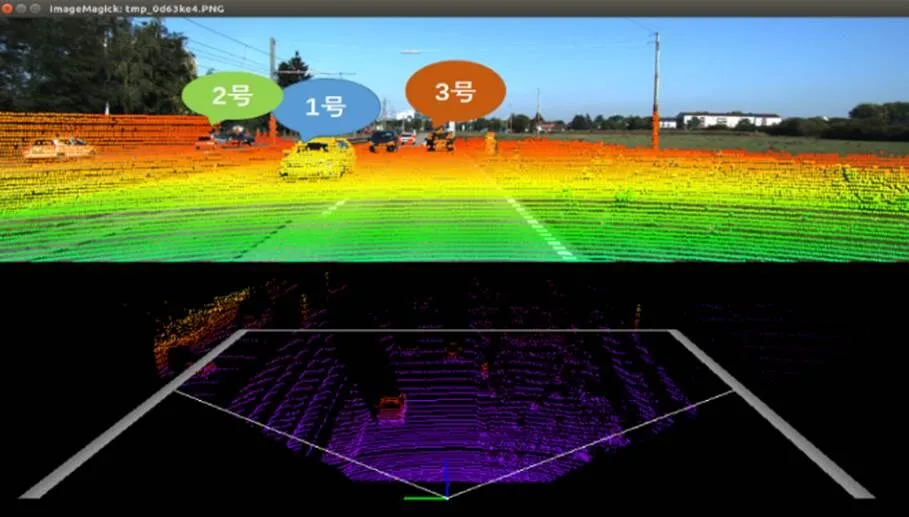
图1 激光雷达实际扫描示意图
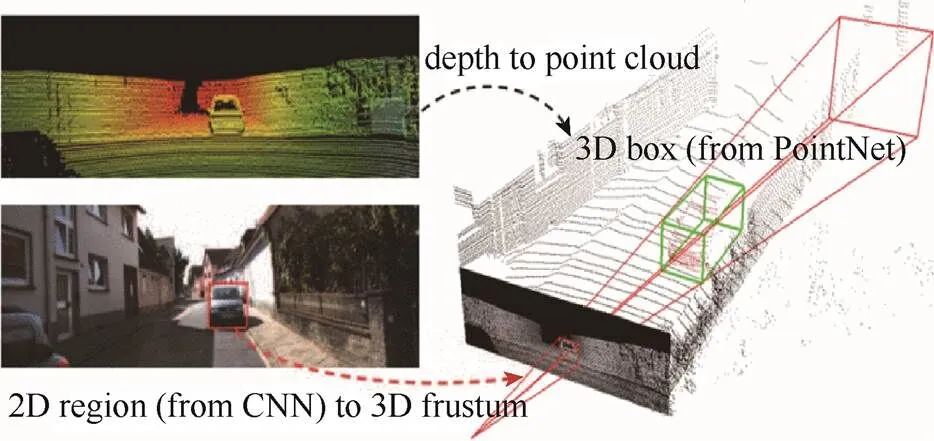
图2 F-PointNet整体框架[5]
2 融合稀疏点云补全的3D目标检测算法
2.1 算法框架
目前基于雷达点云的3D目标检测算法已成为学术界研究的热点,但实际采集到的点云并不是完整的[8],遮挡问题、扫描距离、雷达分辨率都会造成采集到的点云丢失部分信息,这样的数据残缺会直接导致目标检测算法的性能下降[9]。因此,本文提出了融合点云补全网络(point-cloud completion network,PCN)的3D目标检测算法,以达到优化目标检测算法的目的。图3为PCN的目标检测算法流程,包含5个部分,其中点云补全的效果直接影响了目标检测的精度,因此需先对PCN进行改进,再应用至目标检测任务中。

图3 算法流程图
2.2 基于复合损失的PCN网络
2.2.1 PCN网络
PCN是一个编码、解码机制的网络,如图4所示。编码部分将信息不完整的点云作为输入,假设共个点,通过2个PointNet网络,输出一个维特征向量。级联解码[8]部分接受这个特征向量,以全局特征向量作为输入,解码端首先通过全连接层,得到点较为稀疏的补全点云,再经过一个折叠机制的解码层,以稀疏点云中的每个点为中心,在其周围生成-1个点,可形成共计=×个密集点,完成稀疏点云补全工作。即解码网络先后生成一个粗略的输出点云coarse和一个细密的输出点云detail。

图4 点云补全网络
2.2.2 复合损失函数
损失函数测量输出点云和Ground Truth点云之间的差异。由于2个点云都是无序的,因此损失需要对点的排列保持不变[10]。原PCN网络采用倒角距离(chamfer distance,CD)进行衡量,即
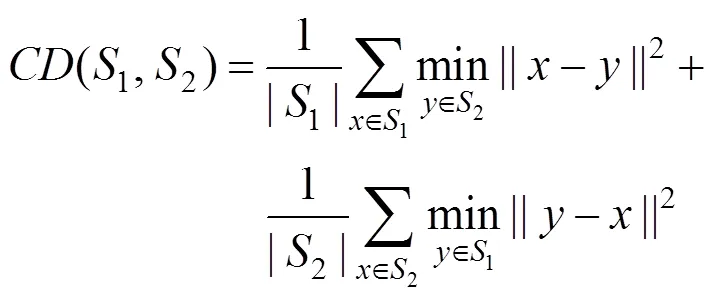
由损失函数计算输出点云1和Ground Truth点云2之间的平均最近点距离。和分别为点云1和点云1内的点,是一个三维坐标。在这个损失函数中第一项尽量使PCN网络输出点靠近Ground Truth点云,第二项确保Ground Truth点云被PCN网络输出点云覆盖。
因此,为了减小网络整体误差,提升点云补全的效果,需重新定义了一个复合损失函数,即
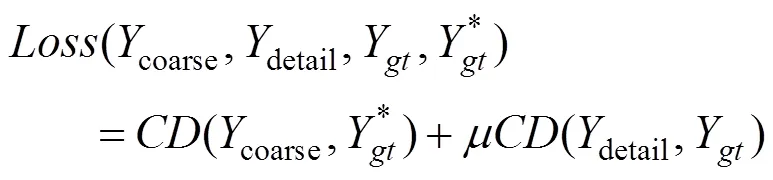
改进损失函数后,点云补全网络的输出与Ground Truth点云之间的CD将会变小,即输出与Ground Truth更接近。但是3D目标检测使用到的KITTI数据集为真实环境中采集到的数据,而真实世界中并不存在完整的Ground Truth点云,因此,本文提出2个指标来验证改进算法的有效性:
(1) 保真度误差(fidelity error)[11]。从输入中的每个点到其最接近的输出点的平均距离。即输入输出之间的CD用来衡量在输出点中,输入点云的保存程度;
(2) 最小匹配距离(minimal matching distance,MMD)[11]。输出点云与训练数据集中最接近的汽车模型的CD,该指标衡量KITTI数据集经过补全后,是否保持了汽车模型的特征信息。
保真度误差及MMD越小,表示点云补全的效果越好,越有利于3D目标检测任务的进行[12]。表1为该算法在KITTI数据集上的客观验证效果,保真度误差和MMD均值都有所减小,说明改进的损失函数使得输出点云包含了更多输入点云的形状信息,以及更接近汽车模型的信息。

表1 KITTI数据集评估结果
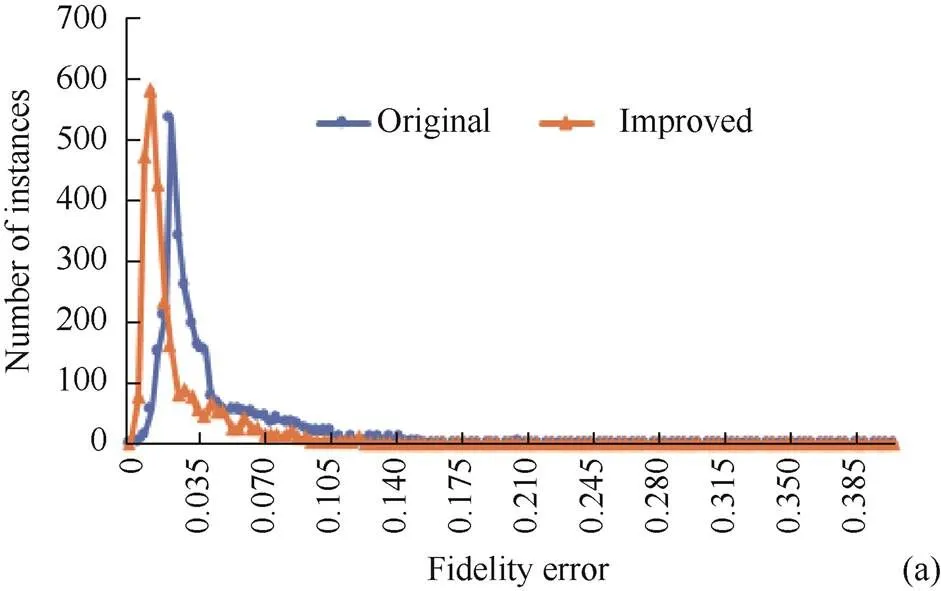
为求得普遍性规律,图5给出了KITTI数据集上2 483组输入点云的保真度误差和MMD的分布。可观察到,改进损失函数之后对于大部分样本,保真度误差及MMD均减小,说明改进的算法对于没有Ground Truth的点云也有较好的补全效果,能够达到提升目标检测精度的目的。
2.3 融合PCN的目标检测算法
通过对PCN的改进,不难发现KITTI数据集中汽车点云补全的保真度误差和MMD均减小,说明改进算法对于自动驾驶场景中的汽车点云有较好的补全效果。因此,接下来通过融合PCN至目标检测算法中,对缺失部分信息的稀疏点云进行补全处理,可解决由于点云稀疏而给3D目标检测带来的精度低问题。
基于PCN改进的F-PointNet网络,将F-PointNet网络中3D实例分割后的稀疏点云补全之后,得到密集点云,再对3D框的参数进行回归。对分割后的点云进行补全操作的原因主要有:①实际扫描的点云是稀疏的,若直接在不完整的点云上计算3D框的质心,将与Ground Truth有较大的差异;②对分割后的目标点云进行补全处理,而不是操作在采集到的原始点云上,如果将空间内所有的点云补全,由于背景、遮挡物等非感兴趣目标点云的存在,会造成大量的嘈杂点云,这对目标检测反而会带来不利的影响。
改进的目标检测算法如图6所示。以RGB图像和雷达点云共同作为网络的输入,先进行2D目标检测并生成视锥,假设视锥内的点云数量为,那么网络中视锥内的点云便由×3的矩阵来表示,为得到的目标类别;接着,由3D实例分割网络判断视锥内的每个点的类别是否属于感兴趣区域,分割出属于感兴趣区域点云的个稀疏点;而后经过PCN点云补全网络,生成个密集点;最后经过3D框估计网络,输出立体框参数,完成目标检测。
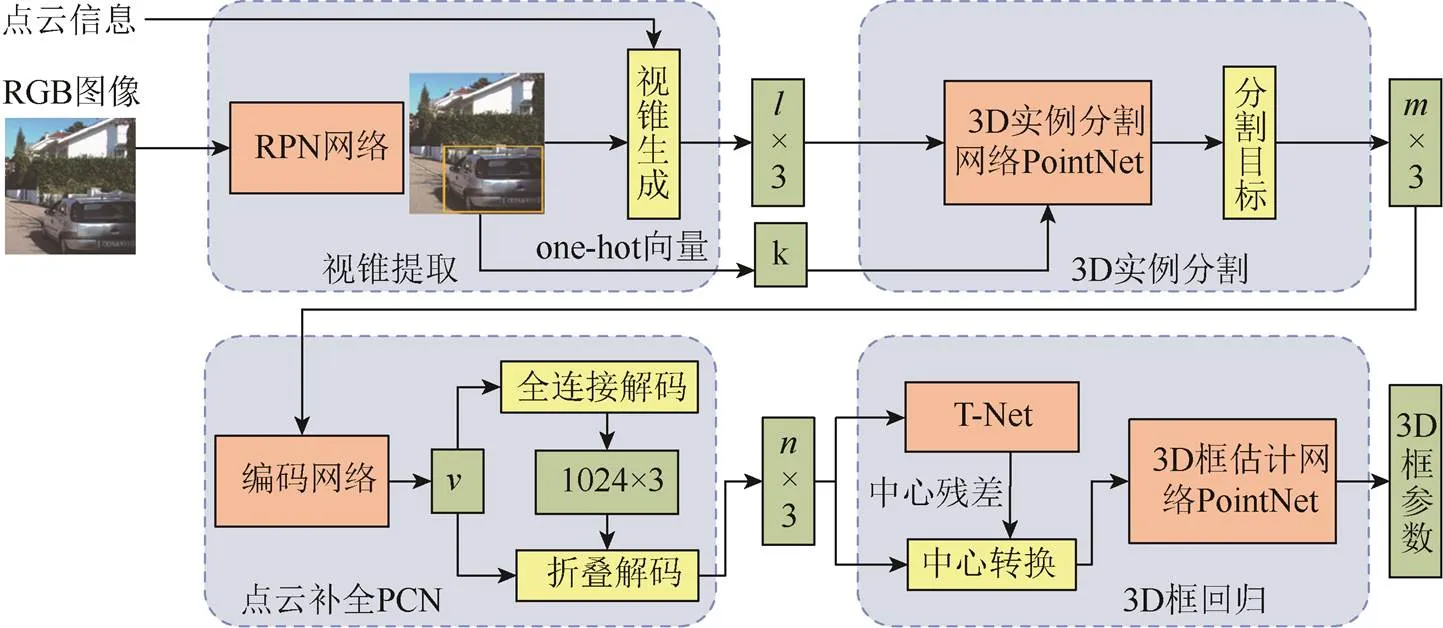
图6 改进的3D目标检测网络
3 实验结果及分析
3.1 实验数据集
在目标检测过程中,使用的数据是自动驾驶场景中3D目标检测一贯使用的三维KITTI数据集,包含训练集3 712组数据,验证集3 769组数据,每组数据包含RGB图像、雷达点云数据和将两者对应起来的投影参数。根据遮挡、截断情况及点云稀疏程度等,将数据分为简单、中等、困难3个等级。训练和目标检测虽然用的是不同的数据集,但是点云补全网络的PN层是改进的PointNet网络,其最大的优势是具有一定的自适应能力,T-Net结构是一种特殊类型的空间转换网络(spatial transformer network,STN)[13],可将不同尺度的输入,转换成最有利于模型的结果。这是当下很多点云处理网络使用PointNet网络的重要原因。
3.2 PCN改进前后的倒角距离

图7 点云补全算法对比结果
除了以上的对比结果,表2还给出各种补全算法的最终输出与Ground Truth之间的CD,发现本文方法最佳,CD为0.054 967,较改进之前降低了0.014 453,证明了本文方法的有效性,请注意,表2中的CD为各种方法在Shapenet数据集上257组验证集的平均结果,而非某一组数据的CD。

表2 不同点云补全算法效果对比
3.3 3D目标检测实验结果
图8为城市和高速公路2个场景中的点云补全前后,基于雷达点云的3D目标检测的对比实验结果,图8(a)和(c)为真实场景中使用F-PointNet进行检测的结果;图8(b)和(d)为将3D实例分割的点云补全操作之后进行的3D目标检测结果,其中红框为Ground Truth,绿框为本文算法预测出来的立体框,可以观察到,经过补全操作后,本文检测结果更接近Ground Truth,对于远处的目标,原算法并未检测出来,图中远处仅有一个红色的立体框,而经过补全之后,远处目标也被检测到,并且结果与Ground Truth极其相近。
以上为实验的主观结果,但要是衡量点云补全算法在目标检测任务中的有效性,还需要从客观的目标检测结果的平均精度(average precision,AP)来分析。表3给出了在Nvidia GeForce 1060TiGPU,Ubuntu16.04,Python2.7,Tensorflow1.12实验配置下,本文算法各个环节运行的平均时间。表4是不同算法对KITTI数据集中的车辆目标进行检测的结果,结果中的简单、中等、困难表示不同遮挡情况以及稀疏程度的点云。目标检测的IOU阈值设定为0.7。
从对比实验结果发现,在未增加过多运行时间的前提下,可将F-PointNet算法3D分割后的稀疏点云进行补全操作,得到密集点云,再完成3D框的估计,观察到实验结果有了很大程度的提升。特别是针对中等和困难2个等级的数据,分别提升了6.81%和9.29%,效果显著。这是因为对稀疏点云加密后,更接近简单等级的数据,从而检测效果有了明显地提升。


表3 本文算法运行平均时间(ms)

表4 不同目标检测算法实验AP对比结果(%)
4 结 论
与RGB图像相比,虽然雷达点云不易受到光照、天气等外界因素的影响,但就雷达点云本身而言,会因为激光雷达的分辨率、距离等因素,造成点云的稀疏问题,特别是远处的目标,采集到的点云数据更加稀疏。因此,本文提出一种融合稀疏点云补全的目标检测算法,有效地提升了目标检测精度。在解码网络,根据网络采用全连接解码与折叠解码级联的解码方式的特性,定义了一个新的复合损失函数。复合损失函数中除了原有的折叠解码阶段的损失之外,还增加了全连接解码阶段存在的损失,以保证解码网络的总体误差最小,从而使得点云补全网络生成信息更完整的密集点云。最后,通过实验证明,本文的改进对稀疏点云补全效果更好,并且应用到3D目标检测任务中,检测精度大大提升,特别是KITTI数据集中中等和困难级别的点云,3D目标检测提升效果更好。
[1] CHEN X Z, MA H M, WAN J, et al. Multi-view 3D object detection network for autonomous driving[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 6526-6534.
[2] ZHOU Y, TUZEL O. VoxelNet: end-to-end learning for point cloud based 3D object detection[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 4490-4499.
[3] SHI S S, WANG X G, LI H S. PointRCNN: 3D object proposal generation and detection from point cloud[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2019: 770-779.
[4] QI C R, LITANY O, HE K M, et al. Deep hough voting for 3D object detection in point clouds[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV). New York: IEEE Press, 2019: 9276-9285.
[5] QI C R, LIU W, WU C X, et al. Frustum PointNets for 3D object detection from RGB-D data[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 918-927.
[6] THRUN S, WEGBREIT B. Shape from symmetry[C]//The10th IEEE International Conference on Computer Vision (ICCV). New York: IEEE Press, 2005: 1824-1831.
[7] CHARLES R Q, SU H, MO K C, et al. PointNet: deep learning on point sets for 3D classification and segmentation[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 77-85.
[8] CHEN L C, ZHU Y K, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[M]//Computer Vision – ECCV 2018. Cham: Springer International Publishing, 2018: 833-851.
[9] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[10] ARMENI I, SAX S, ZAMIR A R, et al.Joint 2D-3D-Semantic data for indoor scene understanding[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). New York: IEEE Press, 2017: 7126-7134.
[11] MASCI J, BOSCAINI D, BRONSTEIN M M, et al. Geodesic convolutional neural networks on Riemannian manifolds[C]//2015 IEEE International Conference on Computer Vision Workshop (ICCVW). New York: IEEE Press, 2015: 832-840.
[12] RUSU R B, BLODOW N, MARTON Z C, et al. Aligning point cloud views using persistent feature histograms[C]//2008 IEEE/RSJ International Conference on Intelligent Robots and Systems. New York: IEEE Press, 2008: 3384-3391.
[13] QI C R, YI L, SU H, et al. PointNet++: deep hierarchical feature learning on point sets in a metric space[C]//2017 Neural Information Processing Systems. New York: IEEE Press, 2017: 5099-5108.
[14] QI C R, SU H, NIEßNER M, et al. Volumetric and multi-view CNNs for object classification on 3D data[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 5648-5656.
[15] ACHLIOPTAS P, DIAMANTI O, MITLIAGKAS I, et al. Learning representations and generative models for 3D point clouds[C]//2018 International Conference on Machine Learning. New York: IEEE Press, 2018: 40-49.
[16] YANG Y Q, FENG C, SHEN Y R, et al. FoldingNet: point cloud auto-encoder via deep grid deformation[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 206-215.
3D object detection algorithm combined with sparse point cloud completion
XU Chen1,2, NI Rong-rong1,2, ZHAO Yao1,2
(1. Institute of Information Science, Beijing Jiaotong University, Beijing 100044, China; 2. Beijing Key Laboratory of Modern Information Science and Network Technology, Beijing 100044, China)
The 3D object detection method based on radar point cloud effectively solves the problem that the 2D object detection based on RGB images is easily affected by such factors as light and weather. However, due to such issues as radar resolution and scanning distance, the point clouds collected by lidar are often sparse, which will undermine the accuracy of 3D object detection. To address this problem, an object detection algorithm fused with sparse point cloud completion was proposed. A point cloud completion network was constructed using encoding and decoding mechanisms. A complete dense point cloud was generated from the input partial sparse point cloud. According to the characteristics of the cascade decoder method, a new composite loss function was defined. In addition to the loss in the original folding-based decoder stage, the compound loss function also added the loss in the fully connected decoder stage to ensure that the total error of the decoder network was minimized. Thus, the point cloud completion network could generate dense points with more complete informationdetail, and apply the completed point cloud to the 3D object detection task. Experimental results show that the proposed algorithm can well complete the sparse car point cloud in the KITTI data set, and effectively improve the accuracy of object detection, especially for the data of moderate and high difficulty, with the improvement of 6.81% and 9.29%, respectively.
object detection; radar point clouds; point cloud completion; compound loss function; KITTI
TP 391
10.11996/JG.j.2095-302X.2021010037
A
2095-302X(2021)01-0037-07
2020-05-27;
27 May,2020;
2020-08-28
28 August,2020
国家重点研发计划项目(2018YFB1201601);国家自然科学基金项目(61672090);中央高校基本科研业务费专项资金(2018JBZ001)
:National Key Research and Development Program (2018YFB1201601); National Natural Science Foundation of China (61672090); Special Fund for Fundamental Research Funds for Central Universities (2018JBZ001)
徐 晨(1995–),男,河北张家口人,硕士研究生。主要研究方向为自动驾驶、目标检测。E-mail:18125180@bjtu.edu.cn
XU Chen (1995–), male, master student. His main research interests cover autonomous driving and object detection. E-mail:18125180@bjtu.edu.cn
倪蓉蓉(1976–),女,安徽淮南人,教授,博士,博士生导师。主要研究方向为数字图像处理与模式识别、数字水印与取证。E-mail:rrni_mepro@163.com
NI Rong-rong (1976–), female, professor, Ph.D. Her main research interests cover graphic image processing, pattern recognition,digital watermarking and forensics, etc. E-mail:rrni_mepro@163.com
