关键人脸轮廓区域卡通风格化生成算法
2021-04-10范林龙张笑钦
范林龙,李 毅,张笑钦
关键人脸轮廓区域卡通风格化生成算法
范林龙1,李 毅1,张笑钦2
(1. 温州大学计算机与人工智能学院,浙江 温州 325035; 2. 温州大学大数据与信息技术研究院,浙江 温州 325035)
针对人脸轮廓特征区域的局部化限定,结合关键特征点的提取和脸部邻近颜色区域的融合,并引入注意力机制,提出了一种基于CycleGAN的关键人脸轮廓区域卡通风格化生成算法,以此作为初始样本构建生成对抗网络(GAN)并获取自然融合的局部卡通风格化人脸图像。利用人脸轮廓及关键特征点进行提取,结合颜色特征信息限定关键人脸风格化区域,并通过局部区域二值化生成关键区域人脸预处理的采样图像;为了使生成图像能够自然匹配所提取特征区域,利用均值滤波操作对所提取区域的边缘轮廓进行平滑羽化处理,并相应地扩展风格化生成图像的过渡区域;最后通过构建基于无监督学习的生成对抗网络,使用训练数据集进行人脸图像局部轮廓特征区域的卡通风格化生成。算法对人脸轮廓区域的边缘及邻近区域颜色进行滤波处理,可实现良好的边缘轮廓过渡融合,生成自然的人脸局部轮廓区域的卡通风格化图像。实验结果表明,该算法对于人脸图像的生成具有很高的鲁棒性,能够应用于各种尺度人脸图像的风格化生成。
人脸特征;局部区域;对抗生成网络;风格化
人脸特征已广泛地应用于人脸轮廓提取、分割、识别[1-3]、检索[4-5]和分类等众多研究领域。作为人体自然特征最重要的表征区域,人脸轮廓和关键器官特征点的提取技术,对于人体的生物识别、目标跟踪和行为分析具有非常重要的理论价值。尤其是在基于机器视觉技术的人工智能领域,快速并准确的人脸特征提取经常作为算法的首要条件之一。
近年来,基于特征提取的人脸关键区域风格化生成技术受到了市场的极大关注[6-7]。涌现了一大批基于人脸区域特征提取的应用技术[8-9],如人脸图像的编辑美化、视频人脸风格贴图、“变脸”(Deepfakes)等,在影视娱乐、动漫游戏、广告宣传领域得到了广泛应用。采用传统的图像处理技术,能够实现人脸关键特征的风格改变和迁移,从而达到美化人脸图像的目的。随着计算机视觉领域的发展,采用深度学习技术,能够实现更加智能快速的人脸特征风格化及特征融合。
传统的人脸风格化方法是利用图像处理的技术[10],通过提取人脸面部特征位置,根据所需表情从素材库中调取相应的五官贴图,进行匹配或替换生成卡通图像;在视频图像处理领域[11],利用非真实感渲染,通过学习特定风格的笔触特征[12],模拟表现人脸区域的艺术化特质;在图像滤波研究领域,研究人员利用Kuwahara滤波器[13]平滑权重函数代替矩形区域,考虑各向异性的权重函数形成聚类的方法,能够在平滑图像的同时保留图像有意义的边缘信息,从而提高图像风格化的结果。
近年来,随着深度学习的快速发展,基于对抗生成网络(generative adversarial networks,GAN)的人脸生成领域成为研究热点[14-15]。在人脸图像合成领域,FaceID-GAN将传统的GAN进行扩展,通过加入分类器,确保了生成的人脸具有高质量的身份保留输出,并遵循网络信息的对称性特点,减小训练难度,以实现多视角和表情的人脸图像生成。清华大学的学者提出了一种专用的全局场景卡通风格化的GAN架构的CartoonGAN[16],能够有效地学习使用不成对的数据集进行训练,通过利用稀疏正则化语义损失函数,推进了边缘的对抗损失,保证了清晰的生成图像边缘。最近,一种新的标签协助加强版CycleGAN网络被提出生成卡通风格化人脸图像[17],通过面部特征定义一致性的同时,指导在网络模型中训练局部鉴别器,从用户研究、特定辨识度、结果的总体评价3个方向对网络进行构建研究,使最终的生成图像取得了很好的结果。本文基于CycleGAN的深度学习网络架构,对于局部关键区域卡通风格化的研究,结合人脸轮廓区域分割技术,局部特征的稀疏化提取,能够有效地减少网络的学习时间,具有很大地应用价值。
基于CycleGAN技术的关键人脸轮廓区域卡通风格化生成算法,如图1所示。通过人脸轮廓特征区域的局部化限定,结合关键特征点的提取和脸部邻近颜色区域的融合,并引入无监督学习的注意力机制(attention mechanism),以此作为初始样本构建GAN并获取自然融合的局部卡通风格化人脸图像。

图1 人脸关键特征区域和局部卡通风格化
本文首先利用人脸轮廓及关键特征点进行提取,结合颜色特征信息限定关键人脸风格化区域,并通过局部区域二值化生成特征区域人脸预处理的采样图像;为了使生成图像能够自然匹配所提取特征区域,利用均值滤波操作对所提取区域的边缘轮廓进行平滑羽化处理,并相应地扩展风格化生成图像的过渡区域;然后通过构建基于CycleGAN的GAN,调整样本区域进行训练学习;最后,使用训练数据集进行人脸图像局部轮廓特征区域的卡通风格化生成。具体步骤如下:
步骤1. 首先输入一张图片,利用DLIB的HOG特征检测器检测人脸区域,得到包围区域顶点坐标;根据顶点坐标,确定人脸矩形框,同时计算获得一个最小化人脸椭圆特征区域,将此椭圆区域记为Mask 1。
步骤2. 限定矩形区域内人脸关键点,通过68点的关键点检测方法,得到人脸特征关键点区域Mask 2。同时采集计算脸部区域肤色获得感兴趣区(region of interest,ROI) Mask 3。通过计算获得最终人脸学习ROI区域Mask。
步骤3.根据所得ROI区域,结合构建基于U-GAT-IT方法的无监督注意力机制网络来实现图像的转化与融合。通过与Mask进行并集计算,获得局部区域内的卡通生成图像。
步骤4. 最后利用泊松融合的方法将转换后的图像与原始图片进行融合。同时,对于脸部区域不够明显的区域,采用均值滤波,通过调整网络卷积核大小来进行脸部轮廓边缘的平滑操作,能够达到很好地扩宽过度边缘的效果。算法框架流程如图2所示。

图2 人脸关键区域风格化生成算法流程图
1 人脸局部特征区域的风格化方法设计
1.1 基于人脸关键特征的轮廓提取
Mask 1. 在计算机视觉及图像处理中,梯度方向直方图(histogram oriented gradient,HOG)是一种基于形状边缘特征,能对物体进行检测的描述算子,基本思想是利用梯度信息很好地反映图像目标的边缘信息,并通过局部梯度的大小将图像局部的外观和形状特征化。利用DLIB的HOG特征检测器检测人脸区域[1],即

其中,G,G,(,)分别为像素点(,)在水平方向及垂直方向的梯度以及像素的灰度值。
最终得到包围区域顶点坐标,通过这2个点可以计算出中心坐标及半径。根据面部特征尽可能去拟合额头区域。
Mask 2.关键点算法是基于集成回归树(ensemble of regression tress,ERT)算法,即梯度提高学习的回归树方法,如图3所示。该算法通过建立一个级联的残差回归树(gradient boosting decistion tree,GBDT)使人脸的当前形状逐步回归到真实形状。每一个GBDT的每一个叶子节点上均存储着一个残差回归量,当输入落到一个节点时,就将残差加到该输入上,起到回归的目的,最终将所有残差叠加在一起,就完成了人脸对齐的目的,即
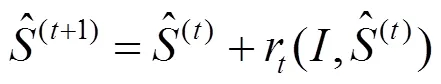
其中,为第t级回归器的形状,是一个由坐标组成的向量,更新策略采用GBDT梯度提升决策树,即每级回归器学习均是当前形状与样本形状的残差。
最终得到68个关键点的坐标,包含眼镜、眉毛、鼻子、嘴巴等主要特征,取最外层27个点得到一个不规则形状Mask 2,如图4所示。
Mask 3. 根据肤色提取特征,采用YCrCb颜色空间Cr分量+Otsu法阈值分割。

图4 关键点坐标图
(1) 将RGB图像转换到YCrCb颜色空间,提取Cr分量图像;
(2) 对Cr做自二值化阈值分割处理(Otsu算法)。Otsu算法(最大类间方差法)采用的是聚类的思想,将图像的灰度数按灰度级分成2个部分,并使其灰度值差异最大,每个部分之间的灰度差异最小,通过方差的计算寻找一个合适的灰度级别进行划分。在二值化时采用Otsu算法自动选取阈值并进行二值化。Otsu算法被认为是图像分割中阈值选取的最佳算法,计算简单,不受图像亮度和对比度的影响。因此,使用类间方差最大的分割意味着错分概率最小。
图像总平均灰度为
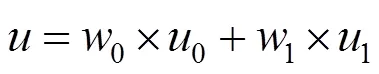
其中,为设定的阈值,初始值为图像的平均灰度;0为分开后前景像素点数占图像的比例;0为分开后前景像素点的平均灰度;1为分开后背景像素点数占图像的比例;1为分开后背景像素点的平均灰度。从个灰度级遍历,当为某值时,前景和背景的方差最大,则该值便是要求的阈值。其中,方差的计算为
该式计算量较大,可简化为
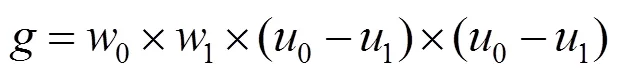
最终将3个Mask合并,得到需要提取的图像,即
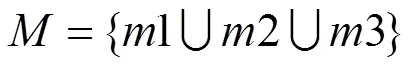
1.2 基于GAN的卡通风格化生成网络
无监督图像到图像是本文采用的全新方法,如图5所示,其结合了注意力模块和自适应归一化模块。本文模型通过基于类激活器(class activation map,CAM)获得的注意力图以区分源域和目标域,引导图像在生成时,聚焦于重要区域而忽略次要区域。这些注意力图将被嵌入到生成器和鉴别器中,以聚焦生成语义上更重要的区域,从而促进模型变换,如图6所示。
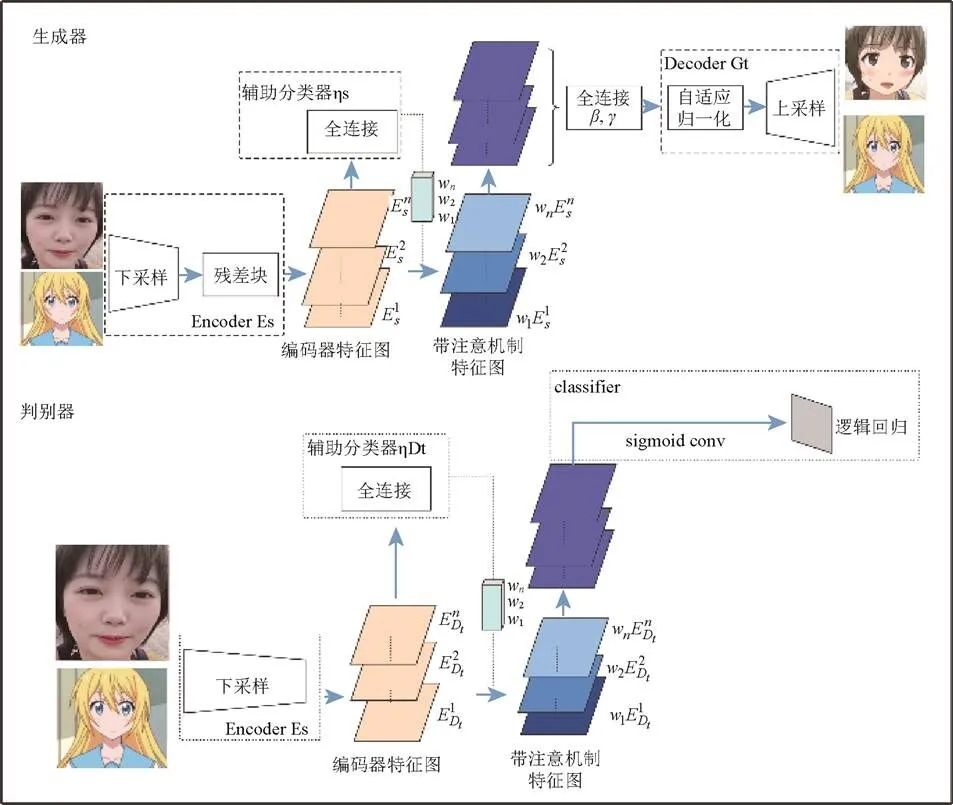
图5 一种无监督图像到图像的对抗生成网络

图6 注意力机制图
数据集具有不同形状和纹理变化量,其变化结果的质量除与注意力机制有关,还受归一化函数选择的影响。参考批处理实例标准化(btch-instance normalization),采用了自适应层实例标准化(adaptive layer-instance normalization),适当地选择实例标准化(instance normalization)和层标准化(layer normalization)之间的适当比率,在训练期间从数据集中学习其参数。可选归一化功能帮助注意力引导模型灵活控制纹理和形状。主要内容归纳:
(1) 采用无监督图像到图像新的转换方法,其集新的注意模块和新的归一化函数AdaLIN为一体。
(2) 注意模块通过基于辅助分类器获得的关注图来区分源域和目标域,从而帮助模型知道在何处进行密集转换。
(3) AdaLIN功能帮助注意力引导模型灵活地控制更改形状和纹理的数量。
1.2.1 生成器
图像依次经过一个下采样模块和一个残差块后,得到了编码后的特征图。其分为2路,一路是通过一个辅助分类器,得到有每个特征图的权重信息,并与另外一路编码后的特征图相乘,得到有注意力的特征图。注意力特征图仍分为2路:①经过一个1×1卷积和激活函数层,得到1,···,特征图。特征图则通过全连接层置于解码器中;②作为解码器的输入,经过一个自适应的残差块和自适应归一化层上采样模块后得到生成结果。
首先计算的是实例的标准化和层标准化
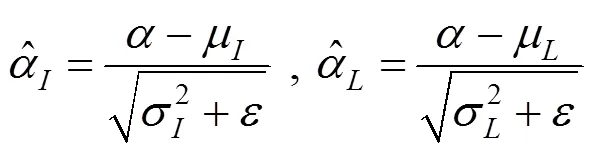
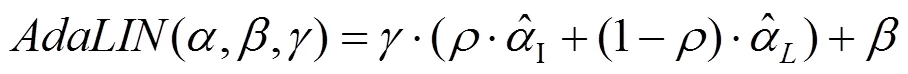
为了防止超出[0,1]范围,对其进行了区间裁剪

1.2.2 判别器
判别器的设计结合了全局判别器(global discriminator)以及局部判别器(local discriminator)的原理,将全局和局部判别结果进行连接。判别器中加入了分类激活映射(class activation mapping,CAM)模块[18],虽然CAM未在判别器下做域的分类,但由于注意力图能够注意到目标域中真实图像和伪图像之间的差异并对其进行微调,所以注意力模块的加入有助于判别图像真伪。
1.2.3 CAM与辅助分类器
CAM对图片中的关键部分进行定位[18]。通过图像下采样和残差块得到的编码器特征图,经过平均池化(global average pooling)和最大池化(global max pooling)后得到依托通道数的特征向量。创建可学习参数权重,经过全连接层压缩。对于编码器特征图的每一个通道,可赋予一个权重,该权重决定了这一通道对应特征的重要性,从而实现了特征映射(feature map)的注意力机制。
当生成器可以很好地区分源域和目标域输入时,注意力模块可以帮助模型知道在何处进行密集转换。将平均池化和最大池化得到的注意力图做连接,经过一层卷积层还原为输入通道数,最终送入 AdaLIN中进行自适应归一化处理。
1.2.4 损失函数
本文模型的完整目标包括4个损失函数。可使用最小二乘GAN目标进行稳定训练,而不是使用Least Squares GAN。对抗性损失使用Adversarial loss匹配翻译图像与目标图像分布的差异

循环损失为了缓解模式崩溃问题,cycle-gan架构下的环一致性loss,A翻译到B,然后B翻译到A’,A和A’需要相同,loss采用的是1loss。

身份丢失为了确保输入图像和输出图像的颜色分布相似,本文将身份一致性约束应用于生成器,即

生成器和鉴别器的CAM loss不同表现为:
生成器CAM loss,采用的是BCE_loss

鉴别器CAM loss,采用的是MSE

用CAM的原因是利用辅助分类器η和ηD的信息,给定一个图像∈{X,X},G→和D了解当前状态下2个域之间的最大区别是什么。
最后,联合训练编码器、解码器、鉴别器和辅助分类器,以优化最终目标

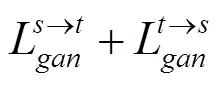
通过训练,可以得到转换成卡通风格化的图片,然后利用泊松融合法将转换后的图片与原始脸部图片进行融合,并对边缘部分进行滤波操作,保证图片平滑过度,最终完成局部人脸轮廓提取区域风格化的操作。
2 实验结果与分析
2.1 数据集与损失函数
本文采用一个由真实图片和动画作品组成的数据集,所有图像均已调整为256×256进行训练,自定义数据集采用女性照片作为训练数据和测试数据,数据来源均是从Anime Planet爬取。首先检索动漫角色人物,然后提取面部图像。训练数据集的大小为3 400,测试数据集的大小为100,图像均为256×256,如图7所示。

图7 Selfie2anime数据集
损失函数包括:①判别器损失曲线(图8):Discriminator_loss表示判别器鉴别伪造数据和真实数据的能力,损失值越小,鉴别能力越强;②生成器损失曲线(图9):Generator_loss表示伪造图片技术的能力,损失值越低,说明伪造能力越强。

图8 判别器损失曲线
综上,从图8和图9可以看出,无论是Discriminator_loss还是Generator_loss都有着明显的变化,虽然损失函数在训练中发生振荡,是因为生成器和判别器彼此会消除对方的学习。不过损失函数图像最终很明显均呈下降趋势,随着迭代次数的增加,Discriminator_loss以及Generator_loss都明显降低,鉴别能力和伪造能力均明显增强。直到鉴别器无法分出数据是真实的还是生成器生成的数据时,这时对抗的过程达到一个动态的平衡。

图9 生成器损失曲线
2.2 实验结果分析
为了测试本文方法的可行性和有效性,采用该算法,对不同的输入图像进行处理,得到局部人脸轮廓提取的区域风格化效果图像。以下实验均在Windows10操作系统中完成,Intel(R) Core(TM) i9-9900K CPU 3.6 GHz GeForce RTX 2080 Ti,16 G内存,Pycharm python编程实现,实验结果如图10所示。

图10 实验最终生成效果图
同时,还将本文算法模型与其他图像迁移模型进行了对比,如图11所示,实验结果很好地展现了本文算法的优良性。图11(b)由于CAM模块的聚焦,很明显眼睛周围的转换要比其他模型好,图像之间不同形状和纹理变化量,其变化结果的质量除了与注意力机制有关,也明显受到归一化函数选择的影响。通过这2个模块,其转换后的目标图像不论从细节、形状都得到了极大的提升。
实验结果表明注意力模块(图12)和AdaLIN (图13)可以在含有定制网络架构和超参数的各种数据集中产生更加喜人的效果。辅助分类器获得的注意力机制图可以指导生成器更加关注源域和目标域之间的不同区域。此外,还发现,在引导模型灵活地控制形状更改和纹理数量上,AdaLIN也发挥着重要作用。
通过本文方法生成的区域卡通风格化效果图片色彩鲜明。转换后的人物头像生动形象,具有卡通动漫人物所特有的特征,对局部卡通艺术风格结果图像进行了较好的模拟。

图11 不同GAN图像迁移模型((a)源图像;(b)本文结果;(c)基于CycleGAN的结果;(d)基于UNIT的结果;(e)基于MUNIT的结果;(f)基于DRIT的结果;(g)基于AGGAN的结果;(h)基于CartoonGAN的结果)

图12 CAM模块分析((a)源图像;(b)生成器的注意力图;(c~d)鉴别器的局部注意力图和全局注意力图;(e)带有CAM模块的结果;(f)不带CAM模块的结果)
(1) 采用CAM模块分析。对于CAM模块,通过消融实验来确定生成器和辨别器使用的注意力模块的优点。如图12(b)特征图帮助生成器聚焦于与目标域更具辨别力的源图像区域。如图12(c)和(d)所示,分别通过可视化鉴别器的局部注意力图和全局注意力图判别鉴别器集中注意力的区域,以确定目标图像是真实的还是伪造的。生成器可以用注意力图调整鉴别器所关注的区域。请注意,本文结合了2个感受野大小不同的鉴别器的全局和局部注意力图。可以帮助生成器捕获全局结构(比如面部区域和眼睛周围)作为局部区域。有了这些信息,一些区域的解析会更加谨慎。如图12(e)所示的关注模块的结果验证了在图像翻译任务中利用关注特征图的有利效果。另一方面,可以看到在没有使用注意力模块的情况下根本无法完成良好的迁移,如图12(f)所示。

图13 AdLIN模块分析((a)源图像;(b)本文结果;(c)仅在解码器使用IN的结果;(d)仅在解码器使用LN的结果;(e)仅在解码器使用AdaLIN的结果;(f)仅在解码器使用GN的结果)
(2) AdaLIN结构分析。本文将AdaLIN应用到了生成器的解码器上,残差块在解码器中的作用是嵌入特征,上采样卷积块在解码器中的作用是从嵌入特征生成目标域图像。如果门参数的学习值接近1,则意味着对应层更多地依赖于IN。同样地,如果学习的值接近于0,则意味着对应层更多依赖于LN。如图13(c)所示,仅在解码器中使用IN时,源域的特征(例如,耳环和颧骨周围的阴影)由于在残差块中使用的(基于Channel-wise的规范化特征统计)按信道的规范化特征统计而被很好地保留。然而,由于上采样卷积块中的IN无法捕获全局样式,因此对目标域样式的转换量有些不足。另一方面,如图13(d)所示,如果在解码器中仅使用LN,则借助于在上采样卷积中使用的(基于layer-wise的规范化特征统计)分层归一化特征统计,可以充分地转换目标域样式。但是,在残差块中使用LN,对源域图像的特征保留较少。对2种极端情况的分析表明,在特征表示层中更多地依赖于IN而不是LN来保持源域的语义特征是有益的,而对于从特征嵌入中实际生成图像的上采样层则相反。因此,在无监督的图像到图像转换任务中,根据源域和目标域的分布来调整解码器中IN和LN的比例的AdaLIN更为可取。图13(e)和(f)是采用AdaIN和GN的结果。显然与这些方法相比,采用AdaLIN方法显示出更好的效果。
3 结束语
本文提出了一种新的基于GAN技术的关键人脸轮廓区域卡通风格化生成算法。首先利用人脸轮廓及关键特征点的提取,结合颜色特征信息限定关键人脸风格化区域,并通过采用二值化技术生成关键区域人脸预处理的采样图像;为了使生成图像能够自然匹配所提取区域,利用均值滤波操作对所提取区域的边缘轮廓进行平滑羽化操作,并相应地扩展风格化生成图像的过渡区域;然后通过构建基于无监督图像到图像转换方法,调整样本区域进行训练学习;最后,使用训练数据集进行人脸图像局部轮廓特征区域的卡通风格化生成。本文算法由于对人脸轮廓区域的边缘及背景颜色进行滤波处理,而且在初始化阶段对采样区域进行了尺寸的自适应修正,在量化生成的过程中,能够实现良好的边缘轮廓过渡融合,生成了自然的人脸局部轮廓区域的卡通风格化图像。本文算法对于人脸图像的生成具有很高的鲁棒性,能够应用于各种尺度人脸图像的风格化生成,适用范围非常广泛。
[1] ZHANG X Q, WANG D, ZHOU Z Y, et al. Robust low-rank tensor recovery with rectification and alignment[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2019, PP(99): 1-1.
[2] ZHANG X Q, JIANG R H, WANG T, et al. Attention-based interpolation network for video deblurring[EB/OL]. [2020-10-20]. https://doi.org/10.1016/j.neucom.2020.04.147.
[3] ZHOU E J, FAN H Q, CAO Z M, et al. Extensive facial landmark localization with coarse-to-fine convolutional network cascade[C]//2013 IEEE International Conference on Computer Vision Workshops. New York: IEEE Press, 2013: 386-391.
[4] WU Y, HASSNER T, KIM K, et al. Facial landmark detection with tweaked convolutional neural networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(12): 3067-3074.
[5] KOWALSKI M, NARUNIEC J, TRZCINSKI T. Deep alignment network: a convolutional neural network for robust face alignment[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). New York: IEEE Press, 2017: 2034-2043.
[6] WANG N N, GAO X B, TAO D C, et al. Facial feature point detection: a comprehensive survey[J]. Neurocomputing, 2018, 275: 50-65.
[7] ZHANG Y, DONG W M, DEUSSEN O, et al. Data-driven face cartoon stylization[C]//SIGGRAPH Asia 2014 Technical Briefs on - SIGGRAPH ASIA’14. New York: ACM Press, 2014: 201-300.
[8] SUN Y, WANG X G, TANG X O. Deep convolutional network cascade for facial point detection[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2013: 3476-3483.
[9] ZHANG Z P, LUO P, LOY C C, et al. Facial landmark detection by deep multi-task learning[M]//Computer Vision – ECCV 2014. Cham: Springer International Publishing, 2014: 94-108.
[10] XU Z J, CHEN H, ZHU S C, et al. A hierarchical compositional model for face representation and sketching[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(6): 955-969.
[11] WINNEMÖLLER H, OLSEN S C, GOOCH B. Real-time video abstraction[J].ACM Transactions on Graphics, 2006, 25(3): 1221-1226.
[12] KYPRIANIDIS J E, COLLOMOSSE J, WANG T H, et al. State of the “art”: a taxonomy of artistic stylization techniques for images and video[J]. IEEE Transactions on Visualization and Computer Graphics, 2013, 19(5): 866-885.
[13] PAPARI G, PETKOV N, CAMPISI P. Artistic edge and corner enhancing smoothing[J]. IEEE Transactions on Image Processing, 2007, 16(10): 2449-2462.
[14] ZHANG K P, ZHANG Z P, LI Z F, et al. Joint face detection and alignment using multitask cascaded convolutional networks[J]. IEEE Signal Processing Letters, 2016, 23(10): 1499-1503.
[15] SHEN Y J, LUO P, LUO P, et al. FaceID-GAN: learning a symmetry three-player GAN for identity-preserving face synthesis[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 821-830.
[16] CHEN Y, LAI Y K, LIU Y J. CartoonGAN: generative adversarial networks for photo cartoonization[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 9465-9474.
[17] WU R Z, GU X D, TAO X, et al. Landmark assisted CycleGAN for cartoon face generation[EB/OL]. [2019-10-04]. https://arxiv.org/abs/1907.01424.
[18] ZHOU B L, KHOSLA A, LAPEDRIZA A, et al. Learning deep features for discriminative localization[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 2921-2929.
Generative adversarial network-based local facial stylization generation algorithm
FAN Lin-long1, LI Yi1, ZHANG Xiao-qin2
(1. College of Computer Science and Artificial Intelligence, Wenzhou University, Wenzhou Zhejiang 325035, China; 2. Institute of Big Data and Information Technology of Wenzhou University, Wenzhou Zhejiang 325035, China)
In view of the localized facial contour features, combining with the extraction of key feature points and the fusion of adjacent color regions of the face, we presented a CycleGAN-based local facial stylization generation algorithm, and constructed the deep learning network with the attention mechanism to generate the local facial cartoon stylization. The sample facial images were marked by using the local area binarization method to constrain the key features and points. In order to naturally match the generated image with the extracted features, the mean filtering operation was utilized to smooth and feather the edge contour of the extracted region. Finally, the generative adversarial networks (GAN) network was constructed, and the training data set was employed to generate cartoon stylization images in the local contour feature area of facial images. The experiment results show that the presented algorithm exhibits high robustness for generating facial stylization, and that it can be applied to the generation of stylized facial images of various scales.
facial features; local area;generative adversarial networks; stylization
TP 391
10.11996/JG.j.2095-302X.2021010044
A
2095-302X(2021)01-0044-08
2020-04-13;
13 April,2020;
2020-08-02
2 August,2020
国家重点研发计划项目(2018YFB1004904);温州市科技计划项目(G20180036,R20200025)
:The National Key Research and Development Program of China (2018YFB1004904);Basic Science and Technology Project ofWenzhou (G20180036, R20200025)
范林龙(1997–),男,四川成都人,本科生。主要研究方向为计算机视觉。E-mail:4624986@qq.com
FAN Lin-long (1997-), male, undergraduate. His main research interest covers computer vision. E-mail:4624986@qq.com
李 毅(1984–),男,宁夏银川人,讲师,博士。主要研究方向为计算机图形学、计算机视觉等。E-mail:liyi@wzu.edu.cn
LI Yi (1984–), male, lecturer, Ph.D. His main research interests cover computer graphics, computer vision, etc. E-mail:liyi@wzu.edu.cn
