基于参数化排序的不确定Top-k查询算法
2020-11-23邹志文
邹志文,张 翅
(江苏大学 计算机科学与通信工程学院,江苏 镇江 212013)
移动物体跟踪[1]、RFID技术、传感器网络和数据融合等应用中产生海量数据,如何从这些海量数据中选择最符合查询条件的信息是数据管理的一个重要课题[2].在数据产生过程中,由于原始数据不准确、需要处理缺失值,满足特殊需求应用,以及使用粗粒度数据集合还有数据的集成等众多原因[3],会产生海量的不确定数据.不确定数据的管理已经成为数据库研究领域的热点之一.
Top-k查询是数据库管理的重要应用之一[4].当数据由确定性数据转换为不确定性数据时会对查询结果产生很大影响,甚至会改变相应的查询语义[5].当前不确定数据库的Top-k查询算法已经有很多种.如U-Topk[6]返回在所有可能世界中具有最大概率的k个元组,U-kRanks[7]返回k个元组的列表,使得第i个排名的元组在所有的可能世界中具有最高的聚合概率.而这两种查询算法,由于缺少相应的剪枝方法从而增加了需要搜索的可能世界实例的数量,所以导致了效率低下.而PT-k查询返回的是所有可能世界中Top-k概率不低于给定概率阈值的元组集合,使得在不展开可能世界的前提下,提高算法的性能.参数化排序中的E-score[8]查询语义返回数据概率和属性分值乘积最大的前k个数据,由于缺少相应的剪枝方法,E-score算法的效率同样不高.
文中提出基于参数化排序的ETK查询算法,在对数据进行剪枝后,引用一个动态规划的Top-k概率计算方法,将计算得出的Top-k概率和数据的属性分值结合,得到一个新的排序参数,将得到的排序参数作为Top-k结果集的查询标准,从而实现数据的概率与属性分值的综合考虑.文中对数据的两个属性都进行约束,更加符合实际应用中的操作需求.由于不确定Top-k查询的计算量较为庞大,文中提出基于ETK查询算法的剪枝规则,从而减少查询工作量,提高算法的查询效率.
1 相关知识
在不确定数据的研究领域中,数据的建模显得尤为重要,可能世界是一种被广泛应用的研究模型[9].不确定数据库D为概率数据库,不确定数据库中部分元组的一个集合构成一个可能世界实例w,每个可能世界实例存在概率在[0,1]中,是在给定范围内的一个概率分布,不确定数据库D中的所有可能世界实例构成完整的可能世界空间Ω.
设D是一个不确定数据集,并且D由n个元组ti组成,ti∈D(i=1,2,…,n).每一个元组ti的形式为ti=(vi,pi),其中vi为数据项ti的得分值,pi为ti在数据库中出现的概率.
对于存在级不确定数据,其对象的所有属性值均是确定的,而对象本身以一定的概率存在于数据库中.显然对于共有n个元组的不确定数据库D,共有2n个可能世界.对于某一可能世界w∈Ω,根据可能世界语义模型,将其存在概率定义为
表1给出了元组ti的属性值和相应发生的概率,其中元组的属性值是确定的.表2给出了可能世界实例及概率计算.

表1 元组属性值和概率值

表2 可能世界实例及概率计算
如表2所示,共有23=8个可能世界实例w,不失一般性,其中w为空的情况一般不考虑.
数据的不确定性(概率问题)使得准确描述实际应用中的情况十分困难且不太现实,一般而言只能描述与可用信息一致的一组可能世界的集合.相比数据原有的概率属性,可能世界模型的存在使得解决不确定数据的相关问题时,从不确定的数据库转化为确定的可能世界实例.
2 不确定Top-k查询算法(ETK)
在Top-k查询中,用户往往只关注排名靠前的一部分数据,对排名靠后的数据并不关心,因此并不需要对所有的数据都进行排序计算.本节给出Top-k概率的计算方法以及一些剪枝规则用来对数据集进行删减,从而不必计算所有数据的Top-k概率以及排序参数,同时给定参数化不确定Top-k查询算法.
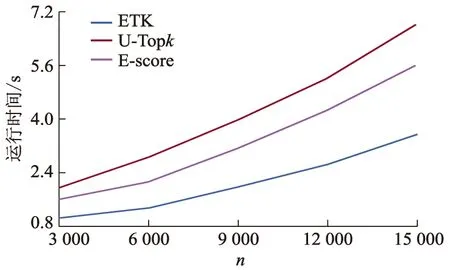
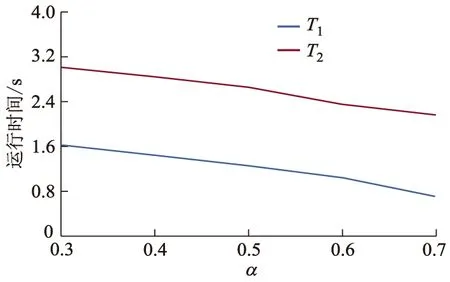
定义1在一个给定的不确定数据集D中,对于任意的两个元组ti,tj,如果元组ti的排序属性分值小于等于元组tj的排序属性分值,那么称为ti支配tj,用来ti 不确定数据集相对确定数据集,还存在一个概率的问题,因此仅仅是返回排序分值优先的数据对象,并不能满足不确定数据的查询要求,所以还需要对数据的概率进行排序. 定义2在一个给定的不确定数据集D={t1,t2,…,ti,…,tn}中,对于任意的两个元组ti,tj,如果ti 定理1在一个给定的不确定数据集D={t1,t2,…,ti,…,tn}中,对于给定的数据元组ti,tj,tk,如果ti 证明因为ti 给定一个不确定数据集D,该数据集中的任一元组ti=(vi,pi),其中vi为该元组的排序属性值,pi为该元组的存在概率,数据集D已经按照属性值vi降序排序(文中认为排序属性值越大越好).不确定数据集的所有可能世界集合Ω={w1,w2,…,wn},同时,使用Pr(wi)来表示可能世界实例wi的概率.在可能世界模型下的元组t的Top-k概率为所有可能世界实例中,可能世界空间Ω中所有包含元组t的可能世界实例的概率之和,表达式为 (1) 例如,表2中t2的Top-k概率为Pt(t)=Pr(w3)+Pr(w5)+Pr(w7)+Pr(w8)=0.224+0.056+0.096+0.024=0.400. 数据的Top-k概率经由可能世界实例的累加运算而得,相对于数据的存在概率,它是由确定的世界实例得来,因而在处理不确定数据时,更具有可靠性. 然而在实际运算中,根据可能世界模型对可能世界空间Ω中包含元组t的所有可能世界实例进行累加运算会非常麻烦,因此,在这里引用了一个用于求解不确定数据的近似Top-k概率动态规划算法.在ZHANG X.等[10]的文献中,对此递归算法有具体的研究与说明,因算法较为复杂,在此不再赘述. 给定一个不确定数据集D,其中数据t已经根据属性分值的升序进行排序,那么数据t的Top-k概率可以用以下公式来计算:当1≤i≤k时,Pt(ti)=P(ti);当i>k时, (2) 在k值为0时,默认数据Top-k概率为0.根据值的大小对i进行分类处理,在当前数据下标i比k小的情况下,数据t的Top-k概率即为数据的本身存在概率,当数据下标i大于k时,即可用递归公式进行数据的Top-k概率计算. 由于不确定数据的数据量十分庞大,随着数据量的增加,查询工作的计算量是呈指数增长的,所以在进行Top-k查询处理的时候,计算量过大,因此提出一些剪枝规则来减少计算量. 定义3对于一个给定的不确定数据集D,一个属性分值的约束范围R=[fmin,fmax],文中的Top-k查询要求返回结果集中的数据要满足数据的属性分值都在R的约束范围内. 剪枝方法1给定一个不确定数据集D,一个分值函数F,和一个属性分值约束范围[fmin,fmax].对于在数据集D中的任意不确定数据t,如果t的属性分值不在分值约束范围R内,那么数据t可以从D中直接剪枝. 定义4用户根据需求来给定一个概率阈值α,要求最后的Top-k结果集中的元组满足:{t|t∈D,Pt(t)>α},其中Pt(t)即为2.1中所求得的数据元组的Top-k概率. 定理2给定一个不确定数据集D,对于任意的不确定元组t∈D,如果元组t的Top-k概率Pt(t)≤P(t),那么不确定数据集D中的任意一个元组t的Top-k概率都不会超过该元组的存在概率. 证明基于可能世界实例的语义模型,对于任意的不确定数据t∈D,t的Top-k概率是包含了t的所有可能世界实例的概率总和[11],即为 对于任意的可能世界实例w∈Ω,如果t∈w并且w中最多只有k-1个元组比t有更高的得分值,那么t的Top-k概率符合所求,在此假设所有的不确定数据之间都是互相独立,没有相互影响规则的,所以有 由可能世界语义模型可知,对于所有的w∈Ω,都有 所以,有 故可得 Pt(t) ≤P(t). 证毕. 剪枝方法2给定一个不确定数据集D,一个用户根据需求定义的概率阈值α.对于数据集D中的任意不确定数据元组t,如果元组t的存在概率P(t)∈α,那么数据t可以从D中直接剪枝. 证明因为P(t)∈α,由定理2可得Pt(t)≤P(t)≤α,根据概率阈值的Top-k查询可知,结果集中的元组t的Top-k概率必须大于α,所以元组t不属于最终的结果集. 定义5在一个给定的不确定数据集D={t1,t2,…,ti,…,tn}中,对于任意的两个元组ti,tj,假设S(ti),S(tj)分别为元组ti,tj的Top-k概率与属性分值的乘积,如果S(ti)≥S(tj),那么称为ti排序支配tj,用ti 在不确定数据集D中,数据已经按照属性分值大小进行排序,然后将Top-k概率引入到查询语义中,将参数化排序函数值S(t)定义为元组t的Top-k概率与属性值的乘积,计算式为 文中将计算得出的S(t)定义为排序的参数,在Top-k查询中用S(t)作为排序的标准,在数据的属性分值和Top-k概率都满足约束条件的情况下,选取S(t)排序在前k的数据. 在不确定数据集D中,对于剪枝过后的数据集,计算得出每个数据的排序参数S(t),并且根据S(t)对数据进行排序,选取排在前k位的数据,并且要求数据的属性分值在给定的分值范围R内,且Top-k概率不小于概率阈值α. 首先初始化结果集为空用来存储最后的Top-k查询结果;然后对于不确定数据集D进行分值和概率阈值的约束;再按照分值的降序排序,计算得出剩余数据集中数据的Top-k概率;最后对数据集进行最后的删减,计算得出剩余数据集的排序参数,将排序在前k的数据送入S中并且返回结果集. ETK查询的输入如下:一个不确定数据集D,概率阈值α,一个正整数k,属性分值F,约束范围R=[fmin,fmax].其输出包含了所有ETK查询结果的集合S.ETK查询算法的伪代码如下: initialize the Top-kanswer setS=∅; for each tupletinDdo if (P(t)<αorF(t)∉R) then Remove(t);(移除数据t,剪枝方法1和2) Sort(t);(对剩余数据进行排序) for the remaining tuples inDdo Compute(t);(计算数据Top-k概率,见式2) Remove tupletfrom the databaseD; compute theS(t)=F(t)·Pt(t) of each tuple remaining; selectktuples which have the maximumS(t) score and Top-kprobability no less than α,and put them into the answer setS; returnS. 针对以上提出的ETK算法进行了一部分试验来验证算法的执行效率以及准确性.试验在一个单机环境下进行,CPU为Intel(R)Core(TM)i7-6700HQ ,4核,主频2.6 GHz,内存8 GB,操作系统为64位win10.算法采用Visual Studio 2013实现. 采用国际冰情监视工作站(international ice patrol,IIP)所收集的关于冰山漂移情况的数据库来验证算法的有效性.数据集中的每个记录当作一个元组,每个观测记录都由于观测点的不同而具有不同的可信度,把几个观测点的可信度分别用概率值0.3,0.4,0.5,0.6,0.7表示,这些概率即为元组的存在概率. 试验中的数据集T1,T2分别为从2007,2009年冰山漂移数据中选取的数据,各包含6 000,13 000条数据.图1是在数据集T1上进行的比较,图2是在数据量n为3 000,6 000,9 000,12 000,15 000情况下的比较. 图1 在数据集T1上的比较 图2 数据集不同情况下的查询时间 在图1和图2中,取概率阈值α=0.5,这两组试验对文中提出的ETK查询算法与传统U-Topk查询算法以及参数化排序中的E-score查询算法进行时间上的比较,在经过文中提出的基于Top-k概率的剪枝方法后,ETK算法的查询时间明显少于U-Topk和E-score算法,在k值增大的时候,减少的查询时间较为明显,而在数据量较大的时候,ETK的性能提升则较为明显,查询时间也明显减少. 图3给出了ETK查询算法在k值不同情况下查询时间的变化. 图3 不同k下的查询时间 由图3可见,在k逐渐增大的过程中,结果集中的数据量逐渐变多,所以Top-k概率以及S(t)的计算量增加了许多,即导致了算法的查询运行时间随着k值的增加而变大,可以看到数据集的增加会使得运行时间变化较为明显. 图4给出了文中ETK查询算法在概率阈值α取不同值下进行查询的时间变化. 图4 不同α下的查询时间 由图4可见,概率阈值α的选取对算法的运行时间有着很大的影响,文中不探讨概率阈值的选取问题.根据阈值与数据的关系可知,α取值越大,被剪枝掉的数据就越多,因此需要进行的计算就越少,所以随着α逐渐增加,运行所需要时间也越来越少. 1) ETK算法引用可能世界模型计算得出的Top-k概率,从数据原有的概率转化为数据的Top-k概率,实现了从不确定概率到确定可能世界实例的转变,在算法的可行性上有所提高. 2) 算法中提出了基于Top-k概率以及概率阈值的相关剪枝技术,在对数据进行查询处理之前,实现了对数据集的缩减,大大的减少了计算量. 3) 试验部分通过与以往算法的对比,以及对不同参数情况下的对比,进一步证明算法在时间性能上的提升,验证了算法的有效性.2.1 Top-k概率及其计算
2.2 剪枝方法

2.3 ETK查询算法


3 试验与结果分析


4 结 论
