标签噪声鲁棒学习算法研究综述
2020-07-16宫辰张闯王启舟
宫辰 张闯 王启舟
摘 要:在机器学习领域,监督学习算法在理论层面和工程应用中均取得了丰硕的成果,但此类算法的效果严重依赖训练样本的标签质量,在实际问题中获取具有高质量标签的訓练样本通常费时费力。为节省人力物力,网络爬虫、众包方法等替代方法被用于对训练数据的采集。不幸的是,这些替代方法获取的数据往往存在大量的错误标注,即标签噪声,由此带来了很多潜在的问题。因此,对标签噪声鲁棒学习算法的研究,在推广机器学习工程应用、降低机器学习算法部署成本方面具有重要的意义。本文对标签噪声鲁棒学习算法的最新研究成果进展进行了全面综述,分别从标签噪声的产生、影响、分类等方面进行了详细的总结,对每类标签噪声的处理方法进行了介绍,并对每类处理方法的优缺点进行分析。
关键词: 人工智能;机器学习;弱监督学习;标签噪声;深度学习;鲁棒学习算法
中图分类号: TJ760;TP18文献标识码:A文章编号: 1673-5048(2020)03-0020-07
0 引言
监督学习分类算法在医疗、金融、交通等领域中已经取得了巨大的成功。此类算法通常从大量训练样本中学习出一个分类模型,然后将其用于预测新样本的标签。具体来说,每个训练样本都对应一个事件/对象,并由两部分组成: 一个描述该事件/对象的特征向量(或实例),一个表示该事件/对象真实类别的标签。监督学习分类算法利用大量有标签的训练数据在假设空间下,寻找特定任务下的最优分类器模型,然后将其部署用于预测新测试样本的标签。但是在实际应用场景中,考虑到人力、物力成本或分类任务本身具有的主观性,实际的训练数据通常受到外部噪声影响。
训练数据所受到的外部噪声被定义为数据实例特征和数据标签错误的对应关系[1]或非系统错误的集合[2]。外部噪声通常分为两类,即特征噪声和标签噪声[2-4]。对于分类问题,特征噪声指训练样本的实例特征本身与其真实特征间的偏差。此类噪声通常对目标分类器性能影响较小,甚至人为引入的特征噪声能够提高目标分类器泛化能力或对抗鲁棒性。类似地,标签噪声通常指分类学习算法中用于训练的目标标签与相应实例本身的真实标签的偏差。
与特征噪声相比,许多工作从实验和理论的角度证明了标签噪声对目标分类器性能有着更为严重的负面影响。Frénay等人[5]指出,这种现象可能由两个因素造成: (1)实例标签维度远小于其特征维度;(2)特征对模型训练的重要性或大或小,而标签总是对模型训练有很大的影响。Quinlan[2]的研究也得出了类似的结论: 相对于特征噪声,标签噪声对分类器的影响更大。因此,本文着重讨论标签噪声问题。
标签噪声在实际应用场景中广泛存在。 在军事目标识别场景中,模型的训练往往依赖于准确的目标标注。但是在目标标注过程中,一些外观相似的军事目标经常容易被标注错误,比如坦克和自行榴弹炮等。类似地,在红外或雷达图像场景中,成像质量或者是照射角的变化也经常导致目标标注错误,也就造成了本文所讨论的标签噪声,这些标签噪声将不可避免地对训练模型带来负面影响。因此, 标签噪声鲁棒学习算法的研究对机器学习应用于实际工程领域具有重要意义。
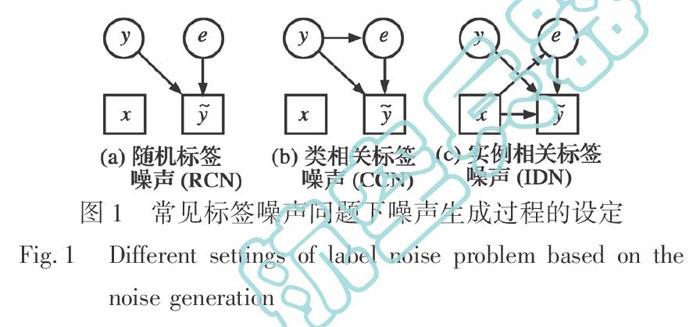
为研究各类标签噪声对目标分类器/分类算法的影响,研究者通常会将噪声标签、真实标签、实例特征三者看作随机变量,进而对三者的依赖关系做出假设。就有向概率图的角度而言[5],大部分工作研究的标签噪声可以分为三类: 随机标签噪声(Random Classification label Noise,RCN)、类相关标签噪声(Class-Conditional label Noise,CCN)以及实例相关标签噪声(Instance-Dependent label Noise,IDN)。三者分别假定标签错误与实例特征和真实标签均无关、标签错误仅与真实标签相关、标签错误与实例特征相关。
三者的概率图表示如图1所示。其中,x表示实例特征,y表示其真实标签(不可观测且完全正确的标注),y~表示其噪声标签(可观测但不完全正确的标注)。此外,与文献[5-6]等类似,本文额外引入隐变量e用于指示该实例是否受标签噪声带来的错误影响。
值得注意的是,已有工作通常限定在一种标签噪声对监督学习算法的影响,而实际场景下标签数据噪声可能是三种情况的混合。此外,其他研究工作尝试研究开放情形下的标签噪声问题,即部分实例样本真实标签不存在于训练样本的标签空间中的情况。本文仅考虑RCN,CCN,IDN三种标签噪声分别对目标分类器的影响以及如何设计特定类型噪声下的鲁棒分类算法。
本文将从标签噪声的产生和标签噪声的影响阐述标签噪声鲁棒学习算法研究的重要意义,并从上述标签噪声的三个分类进一步阐述处理标签噪声的前沿算法,最后对标签噪声学习进行总结并展望其发展趋势。
1 标签噪声的产生
标签噪声广泛存在于交通、金融等多个领域,以及雷达目标检测、红外目标识别等关键应用场景。很多因素可能导致标签噪声[5-6]: (1)标注过程中可获取的信息不够充分,实例特征不足以充分描述目标类别的数据[7-9]。(2)待标注样本任务本身具有主观性,不同标注人员从不同角度出发会给出不同的标签[10-11]。(3)待标记样本自身可辨识度较低,对于一些难以标记的样本,即使专家也无法给出正确标注[1]。(4)标注算法本身质量/精度较低[12-15]。(5)通信/编码问题或数据集处理过程也有可能导致样本标签出现错误[3, 7, 16]。(6)在大规模标注数据中,即使标注算法质量较高,获取的标签也可能存在噪声问题[17]。
2 标签噪声的影响
标签噪声在实际应用中广泛存在。为了降低机器学习算法的部署成本、保障算法的稳定性,研究者不得不研究标签噪声对分类学习算法的影响。首先,标签噪声会严重影响分类学习算法的性能。例如,在RCN或CCN情形下,文献[18-19]从理论角度证明了线性分类器及二次型分类器会受到标签噪声的影响。类似地,Okamoto等人[20]证明了k-NN分类器同样受标签噪声影响。
此外,从实验角度来讲,决策树[2]、支持向量机[21]、AdaBoost等方法[22]效果也会受标签噪声的负面影响。近年来,随着深度学习算法的广泛应用,标签噪声对深度模型的影响也受到了广泛的关注。例如,Zhang等人[23]发现深度模型可以拟合随机标签,即深度模型自身不具有区分正误标签样本的能力。基于其结果,文献[24-25]从实验角度提出了深度模型的记忆/泛化性质。
其次,标签噪声会导致分类器需要更多的训练样本才能达到指定的性能指标[16, 26]。类似地,有标签噪声的训练数据会导致目标分类器模型复杂度大大增加[2, 27]。Dawid 等人[9]则指出标签噪声下观测的类别频率可能会改变。举例来说,在医学研究中,医学研究者通常很关注某种疾病的发病率,但是发病率有很大可能性被标签噪声影响。最后,对于一些其他的任务,例如,特征选择[28]以及特征排序[29]等也受标签噪声的严重影响。
3 标签噪声问题分类
为了能够从理论层面分析标签噪声对各种分类器/分类算法的影响,研究者通常会假设标签噪声的生成过程,并据此设计相应的噪声鲁棒算法。
3.1 随机标签噪声(RCN)
RCN假设噪声标签的生成过程是完全随机的,标签噪声与真实标签或者实例均不相关。例如,在众包场景下,部分没有责任心的标注员会对数据胡乱标注,得到的标签就是完全随机的。该设定较为简单,相应的研究工作也比较彻底。
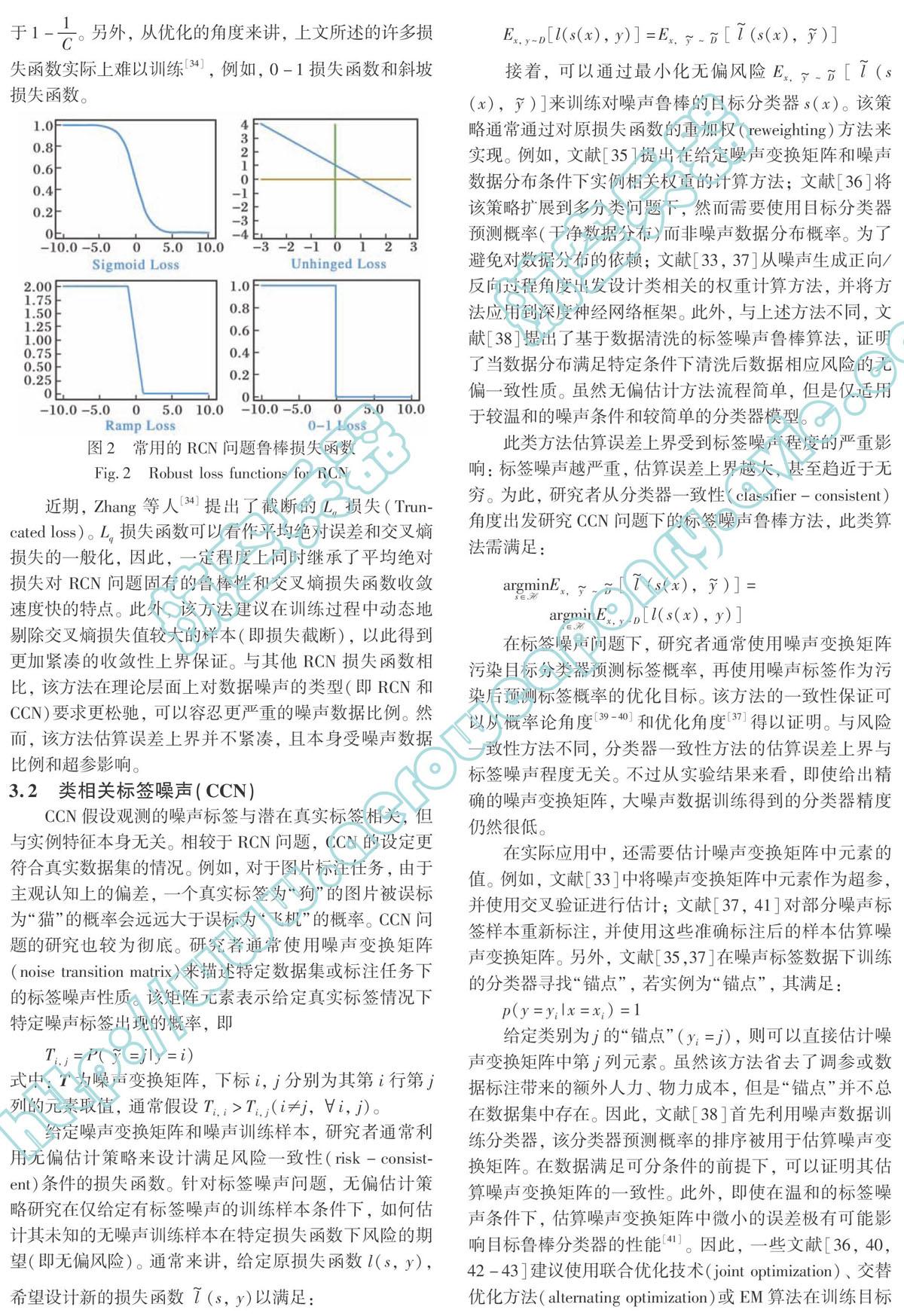
针对RCN,研究者主要关注常用损失函数的固有鲁棒性,或如何设计新的RCN鲁棒损失函数。在理论上,文献[30]证明了0-1损失函数自身对RCN问题鲁棒,而使用交叉熵损失函数(cross entropy loss)[31]和合页损失函数(hinge loss)[32]得到的分类器将明显受到标签噪声的负面影响(见图2)。此外,基于无偏估计的思想,Ghosh等人[31]提出损失函数对RCN问题鲁棒的充分条件: 对称条件(symmetric condition)。
基于此,为得到RCN问题下的鲁棒分类器,一般建议在二分类问题下使用非合页损失函数(unhinged loss)[33]、斜坡损失函数(ramp loss)[30]或S型损失函数(sigmoid loss)[30];在多分类问题下使用平均绝对误差(mean absolute error)[31]作為损失函数。值得注意的是,对于C类分类问题,上文所述损失函数对RCN问题鲁棒的充要条件是训练数据噪声率小于1-1C。另外,从优化的角度来讲,上文所述的许多损失函数实际上难以训练 [34],例如,0-1损失函数和斜坡损失函数。
近期,Zhang等人[34]提出了截断的Lq损失(Truncatedloss)。Lq损失函数可以看作平均绝对误差和交叉熵损失的一般化,因此, 一定程度上同时继承了平均绝对损失对RCN问题固有的鲁棒性和交叉熵损失函数收敛速度快的特点。此外,该方法建议在训练过程中动态地剔除交叉熵损失值较大的样本(即损失截断),以此得到更加紧凑的收敛性上界保证。与其他RCN损失函数相比,该方法在理论层面上对数据噪声的类型(即RCN和CCN)要求更松驰,可以容忍更严重的噪声数据比例。然而,该方法估算误差上界并不紧凑,且本身受噪声数据比例和超参影响。
3.2 类相关标签噪声(CCN)
CCN假设观测的噪声标签与潜在真实标签相关,但与实例特征本身无关。相较于RCN问题,CCN的设定更符合真实数据集的情况。例如,对于图片标注任务,由于主观认知上的偏差,一个真实标签为“狗”的图片被误标为“猫”的概率会远远大于误标为“飞机”的概率。CCN问题的研究也较为彻底。研究者通常使用噪声变换矩阵(noise transition matrix)来描述特定数据集或标注任务下的标签噪声性质。该矩阵元素表示给定真实标签情况下特定噪声标签出现的概率,即
式中: T为噪声变换矩阵,下标i, j分别为其第i行第j列的元素取值,通常假设Ti, i>Ti, j(i≠j,i, j)。
给定噪声变换矩阵和噪声训练样本,研究者通常利用无偏估计策略来设计满足风险一致性(risk-consistent)条件的损失函数。针对标签噪声问题,无偏估计策略研究在仅给定有标签噪声的训练样本条件下,如何估计其未知的无噪声训练样本在特定损失函数下风险的期望(即无偏风险)。通常来讲,给定原损失函数l(s, y),希望设计新的损失函数l~(s, y)以满足:
接着,可以通过最小化无偏风险
来训练对噪声鲁棒的目标分类器s(x)。该策略通常通过对原损失函数的重加权(reweighting)方法来实现。例如,文献[35]提出在给定噪声变换矩阵和噪声数据分布条件下实例相关权重的计算方法;文献[36]将该策略扩展到多分类问题下,然而需要使用目标分类器预测概率(干净数据分布)而非噪声数据分布概率。为了避免对数据分布的依赖;文献[33, 37]从噪声生成正向/反向过程角度出发设计类相关的权重计算方法,并将方法应用到深度神经网络框架。此外,与上述方法不同,文献[38]提出了基于数据清洗的标签噪声鲁棒算法,证明了当数据分布满足特定条件下清洗后数据相应风险的无偏一致性质。虽然无偏估计方法流程简单,但是仅适用于较温和的噪声条件和较简单的分类器模型。
此类方法估算误差上界受到标签噪声程度的严重影响: 标签噪声越严重,估算误差上界越大,甚至趋近于无穷。为此,研究者从分类器一致性(classifier-consistent)角度出发研究CCN问题下的标签噪声鲁棒方法,此类算法需满足:
在标签噪声问题下,研究者通常使用噪声变换矩阵污染目标分类器预测标签概率,再使用噪声标签作为污染后预测标签概率的优化目标。该方法的一致性保证可以从概率论角度[39-40]和优化角度[37]得以证明。与风险一致性方法不同,分类器一致性方法的估算误差上界与标签噪声程度无关。不过从实验结果来看,即使给出精确的噪声变换矩阵,大噪声数据训练得到的分类器精度仍然很低。
在实际应用中,还需要估计噪声变换矩阵中元素的值。例如,文献[33]中将噪声变换矩阵中元素作为超参,并使用交叉验证进行估计;文献[37, 41]对部分噪声标签样本重新标注,并使用这些准确标注后的样本估算噪声变换矩阵。另外,文献[35,37]在噪声标签数据下训练的分类器寻找“锚点”,若实例为“锚点”,其满足:
p(y=yi|x=xi)=1
给定类别为j的“锚点”(yi=j),则可以直接估计噪声变换矩阵中第j列元素。虽然该方法省去了调参或数据标注带来的额外人力、物力成本,但是“锚点”并不总在数据集中存在。因此,文献[38]首先利用噪声数据训练分类器,该分类器预测概率的排序被用于估算噪声变换矩阵。在数据满足可分条件的前提下,可以证明其估算噪声变换矩阵的一致性。此外,即使在温和的标签噪声条件下,估算噪声变换矩阵中微小的误差极有可能影响目标鲁棒分类器的性能[41]。因此,一些文献[36, 40, 42-43]建议使用联合优化技术(joint optimization)、交替优化方法(alternating optimization)或EM算法在训练目标分类器的同时,估算噪声变换矩阵中元素的值。然而这种思路通常没有严格的理论保障,且依赖参数初始化或特殊的正则化项以避免平凡解的出现。
3.3 实例相关标签噪声(IDN)
IDN假设噪声标签与实例本身相关。这种一般化的标签噪声问题通常难以建模,仅有的理论工作通常会对噪声实例分布做出严格的限制。例如,文献[44]假设任一实例标签错误的概率有统一的上界;文献[45]假设离决策边界(decision boundary)越近的实例越容易错分。
这些假设限制了其实际工程中的应用,因此,一些研究试图在深度学习框架下设计启发式算法来识别/修正潜在的错误标签。这些方法通常不对标签噪声的生成过程做出假设,然而通常会隐式地处理实例相关的标签噪声。
一些文献尝试为每个训练样本赋予一个权重,该权重在训练过程中反映了学习算法对相应样本的重视程度。通常来讲,某一实例权重越大,该实例的标签正确的可能性越大。权重计算的方法可以基于额外的无偏干净数据。例如,文献[46]利用有准确标注的噪声数据训练额外的网络模块,用于预测訓练样本标签正确的概率;文献[47-48]在嵌入空间(embedding space)下计算有标签噪声的训练数据和干净数据间的欧式距离或余弦相似度,并赋予小距离/大相似度的实例更大的权重;文献[49]利用随机梯度下降(SGD)优化算法给出分类器在噪声数据下参数的更新方向,并根据更新后分类器在干净数据下的表现对更新方向进行加权。
权重设计方法也可以不利用额外干净数据。例如,文献[50]使用基于密度的无监督聚类算法来测量每个训练样本的复杂度,然后对简单样本赋予较小的权重,对复杂样本赋予较大的权重;文献[46, 51]假设损失值较小的样本标签更有可能是正确的,据此赋予损失值较小的样本以较大的权重。
值得注意的是,上述加权方法可以看作是数据清洗方法[52-54]的一般化,因此,此类算法或多或少存在数据分布偏差(distribution bias)的问题。其一,某些样本的标签本身正确,然而对于优化器/分类器来讲,难以训练的样本(例如,处于数据分布的决策边界附近)也可能被赋予较小权重甚至被直接删除,显然这会严重影响分类器的泛化能力。其二,即使权重的计算正确,在标签噪声较为严重的情况下,大量的样本在训练过程中几乎不起作用(例如,错误标签样本权重设为零)。
为此,许多方法尝试是否可以直接预测真实标签,其通常利用深度神经网络的泛化/记忆性质。例如,文献[24]指出,深度神经网络在训练过程前期主要尝试学习抽象的/一般化的概念,而在训练过程后期会尝试记住每一个训练样本的输出结果;文献[25]的实验结果表明,在学习率足够大时,深度神经网络对标签噪声有一定的抵抗能力。
据此,针对每个训练样本,文献[55]融合分类器的预测标签和原始噪声标签作为优化目标;文献[56]在缓存训练过程中对于每个训练样本分类器预测标签,并且使用超参从预测标签均值中学习和从原始噪声标签中学习进行权衡;文献[57]将真实标签看成随机变量,在模型训练过程中进行优化,并且作为优化目标。另一些方法尝试利用额外的干净数据对噪声标签进行修正。例如,文献[58]在小规模干净数据下训练额外的分类器模型,该分类器的预测标签和原始噪声标签融合用于大规模噪声数据下对噪声标签的修正;文献[59]假设预先可以得到部分有重新标注的噪声样本,并且利用额外的残差网络模块学习噪声标签到干净标签的映射。与上述方法不同,文献[60]针对具体任务引入业务相关的先验知识对噪声标签进行修正。
此类方法可以避免加权方法中数据分布偏差的问题。然而对于原本正确的标签,上述方法仍然会对其标签进行修正。这会导致原本正确的标签质量有所下降,进而影响最终分类器的性能。为此,一些方法尝试从图论的角度出发,通过探索拉普拉斯矩阵所表示的实例间邻接关系来设计标签噪声的清洗方法[41]或修正策略[61]。
3.4 小结
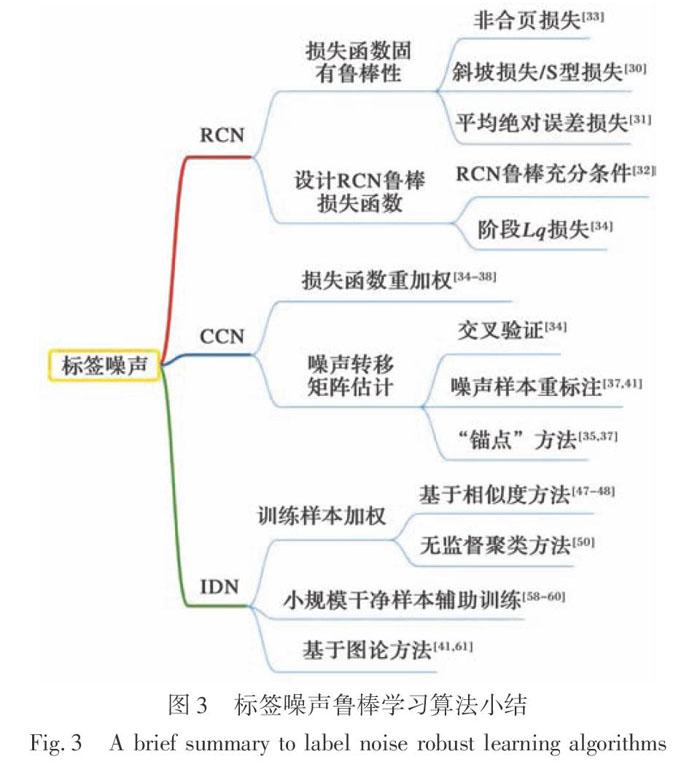
本节从标签噪声的生成过程出发,分别讨论了随机标签噪声(RCN)、类相关标签噪声(CCN)以及实例相关标签噪声(IDN),对每类标签噪声解决方案做了详细阐述并分析了其优缺点。具体来说,对于RCN,关注点在于分析RCN损失函数的固有鲁棒性;对于CCN,关注点在于设计无偏估计策略进而对损失函数重加权,其中一个比较重要的参数是噪声转换矩阵,该参数可以通过交叉验证、数据重标注等一系列方法进行估计;对于IDN,关注点在于对每个训练样本加权,从而反映学习算法对不同样本的重视程度。此外,还有一些方法借助小规模干净数据辅助模型训练,或是采用图论的方法进行数据清洗等。图3详细展示了本节所讨论的标签噪声前沿方法。
4 發展趋势与展望
4.1 发展趋势
关于标签噪声学习的发展趋势,本文对近五年(2015-2019年)发表在人工智能与机器学习相关的顶级会议(NeurIPS,ICML,AAAI,IJCAI,CVPR)上的论文进行调研,统计分析了研究标签噪声的相关论文,统计结果如表1所示。
近5年来,共有182篇关于标签噪声学习的论文发表在上述关于机器学习的顶级国际会议中,统计调查后发现:
(1) 总体而言,标签噪声学习是当前机器学习以及人工智能领域的一个研究热点。关于标签噪声学习的论文在2015-2017年每个学术会议仅有屈指可数的几篇,在2018年有38篇,但在2019年却翻倍增长到了75篇。
(2) 关于标签噪声学习的研究呈现出快速增长趋势,且增长速度越来越快。2015-2017年仅有少量的关于标签噪声学习的研究,但随后每年以相对于上一年成倍的速度增长。2019年关于标签噪声学习的研究已经达到了75篇。可以预测,随后几年关于标签噪声学习的研究会越来越多。
(3) 上述在人工智能顶级会议各大机器学习的论文中,既包含了理论又包含了应用,每年关于标签噪声学习的研究论文在理论和应用上分布都比较均匀,体现了标签噪声学习的理论研究价值和实际应用价值,进而从侧面体现了标签噪声学习的重要性。
4.2 展望
监督学习算法在工程领域和理论层面都取得了丰硕的成果。然而,此类算法需要强监督信息的支持,例如,有高质量标签的训练样本。但是在实际工程应用中,高质量标签难以获取或成本较高。
根据标签噪声的生成方式,本文依次介绍了处理随机标签噪声、类相关标签噪声、实例相关标签噪声三种问题的前沿方法。虽然这些方法取得了一定的进展,但是仍存在许多问题。
(1) 本文介绍方法通常仅在标签噪声程度较为温和的条件下生效。当标签错误数据规模接近或大于正确数据规模时,多数算法无法从训练样本中学习正确的数据分布模式。此外,在理论层面下许多一致性方法在极端噪声情形下泛化能力极差,甚至估算误差上界可能趋近于无穷,然而在实际应用中,极端标签噪声经常出现。因此,如何处理极端情形下的标签噪声问题值得深入研究。
(2) 本文介绍的三种标签噪声形式并不能包含真实数据下的所有可能情况。一方面,噪声的来源可能不唯一,真实噪声标签数据中的噪声形式可能是随机标签噪声、类相关标签噪声和实例相关标签的混合。另一方面,特别是基于网络爬虫等技术的标签生成方法存在开集问题。即部分训练样本的真实标签不在给定标签空间内。
(3) 本文介绍的标签噪声处理方法通常隐式地假设分类器模型有一定识别噪声数据的能力,然而当分类器所在假设空间足够大时,最优分类器可能直接学习噪声标签。例如,分类器/风险一致性方法和重加权方法。一个十分有潜力的替代方法是对数据分布作出假设,然而此类型的已有方法太过简单且不具有一般性。如何对数据分布做出一般化假设,并据此设计标签噪声鲁棒算法是值得深入思考的问题。
(4) 更多标签噪声问题的应用场景还有待探索。标签噪声问题在实际应用场景中广泛存在,本文讨论了许多处理标签噪声的前沿算法,它们在医疗、交通、金融等领域中已经取得了不错的表现。接下来,探索和发挥标签噪声鲁棒算法在军事、材料、航空航天等关键领域的作用是标签噪声学习的一个重要研究方向。
参考文献:
[1] Hickey R J. Noise Modelling and Evaluating Learning from Examples[J]. Artificial Intelligence, 1996, 82(1-2): 157-179.
[2] Quinlan J R. Induction of Decision Trees[J]. Machine Learning, 1986, 1(1): 81-106.
[3] Zhu X Q, Wu X D. Class Noise vs. Attribute Noise: A Quantitative Study[J]. Artificial Intelligence Review, 2004, 22(3): 177-210.
[4] Wu X D. Knowledge Acquisition from Databases[M]. United States: Greenwood Publishing Group Inc., 1995.
[5] Frénay B, Verleysen M. Classification in the Presence of Label Noise: A Survey[J]. IEEE Transactions on Neural Networks and Learning Systems, 2014, 25(5): 845-869.
[6] Frénay B, Kabán A. A Comprehensive Introduction to Label Noise[C]∥ European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning,Bruge, Belgium,2014.
[7] Brodley C E, Friedl M A. Identifying Mislabeled Training Data[J]. Journal of Artificial Intelligence Research, 1999, 11: 131-167.
[8] Brazdil P, Clark P. Learning from Imperfect Data[M]. Machine Learning, Meta-Reasoning and Logics, Boston: Springer, 1990: 207-232.
[9] Dawid A P, Skene A M. Maximum Likelihood Estimation of Observer Error-Rates Using the EM Algorithm[J]. Journal of the Royal Statistical Society: Series C (Applied Statistics), 1979, 28(1): 20-28.
[10] Smyth P, Fayyad U, Burl M, et al. Inferring Ground Truth from Subjective Labelling of Venus Images [C]∥ Proceedings of the 7th International Conference on Neural Information Processing Systems, 1994: 1085-1092.
[11] Malossini A, Blanzieri E, Ng R T. Detecting Potential Labeling Errors in Microarrays by Data Perturbation[J]. Bioinformatics, 2006, 22(17): 2114-2121.
[12] Kovashka A, Russakovsky O,Fei-Fei L, et al. Crowdsourcing in Computer Vision[J]. Foundations and Trends in Computer Graphics and Vision, 2016, 10(3): 177-243.
[13] Li W, Wang L M, Li W, et al. WebVision Database: Visual Learning and Understanding from Web Data[EB/OL]. (2017-08-09) [2020-01-15]. https:∥arxiv.xilesou.top/pdf/ 1708.02862.pdf.
[14] Kittur A, Chi E H, Suh B. Crowdsourcing User Studies with Mechanical Turk[C]∥ Proceedings of the SIGCHI Conference on Human Factors in Computing Systems,2008: 453-456.
[15] Xiao T, Xia T, Yang Y, et al. Learning from Massive Noisy Labeled Data for Image Classification[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2015: 2691-2699.
[16] Angluin D, Laird P. Learning from Noisy Examples[J]. Machine Learning, 1988, 2(4): 343-370.
[17] Northcutt C G, Jiang L, Chuang I L. Confident Learning: Estimating Uncertainty in Dataset Labels[EB/OL].(2019- 10-31)[2020-01-15]. https:∥arxiv.sou.top/pdf/1911.00068.pdf.
[18] Heskes T. The Use of Being Stubborn and Introspective[M].Studies in Cognitive Systems,Boston: Springer, 1994:1184-1200.
[19] Lachenbruch P A. Note on Initial Misclassification Effects on the Quadratic Discriminant Function[J]. Technometrics, 1979, 21(1): 129-132.
[20] Okamoto S, Nobuhiro Y. An Average-Case Analysis of the K-Nearest Neighbor Classifier for Noisy Domains[C]∥Proceedings of 15th International Joint Conferences on Artificial Intelligence,1997: 238-245.
[21] Nettleton D F, Orriols-Puig A, Fornells A. A Study of the Effect of Different Types of Noise on the Precision of Supervised Learning Techniques[J]. Artificial Intelligence Review, 2010, 33(4): 275-306.
[22] Dietterich T G. An Experimental Comparison of Three Methods for Constructing Ensembles of Decision Trees: Bagging, Boosting, and Randomization[J]. Machine Learning, 2000, 40(2): 139-157.
[23] Zhang C Y, Bengio S, Hardt M, et al. Understanding Deep Learning Requires Rethinking Generalization[C]∥ International Conference on Learning Representation (ICLR), Toulon, France, 2017.
[24] Arpit D, Jastrzebski S, Ballas N, et al. A Closer Look at Memorization in Deep Networks[C]∥Proceedings of the 34th International Conference on Machine Learning, 2017: 233-242.
[25] Krueger D, Ballas N, Jastrzebski S, et al. Deep Nets Dont Learn via Memorization[C]∥International Conference on Learning Representation(ICLR), Toulon, France, 2017.
[26] Aslam J A, Decatur S E. On the Sample Complexity of Noise-Tolerant Learning[J]. Information Processing Letters, 1996, 57(4): 189-195.
[27] Brodley C E, Friedl M A. Identifying Mislabeled Training Data[J]. Journal of Artificial Intelligence Research, 1999, 11: 131-167.
[28] Frénay B, Doquire G, Verleysen M. Feature Selection with Imprecise Labels: Estimating Mutual Information in the Presence of Label Noise[J]. Computational Statistics & Data Analysis, 2014, 71: 832-848.
[29] Shanab A A, Khoshgoftaar T M, Wald R. Robustness of Thre-shold-Based Feature Rankers with Data Sampling on Noisy and Imbalanced Data[C]∥Proceedings of Twenty-Fifth International Florida Artificial Intelligence Research Society Conference, 2012.
[30] Ghosh A, Manwani N, Sastry P S. Making Risk Minimization To-lerant to Label Noise[J]. Neurocomputing, 2015, 160: 93-107.
[31] Ghosh A, Kumar H, Sastry P S. Robust Loss Functions under Label Noise for Deep Neural Networks[C]∥ Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence,2017.
[32] Manwani N, Sastry P S. Noise Tolerance under Risk Minimization[J]. IEEE Transactions on Cybernetics, 2013, 43(3): 1146-1151.
[33] Natarajan N, Dhillon I S, Ravikumar P K, et al. Learning with Noisy Labels[C]∥ Proceedings of the International Conference on Neural Information Processing Systems(NIPS), 2013: 1196-1204.
[34] Zhang Z L, Sabuncu M. Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels[C]∥ Proceedings of theInternational Conference on Neural Information Processing Systems(NIPS),2018: 8778-8788.
[35] Liu T L, Tao D C. Classification with Noisy Labels by Importance Reweighting[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 38(3): 447-461.
[36] Xia X B, Liu T L, Wang N N, et al. Are Anchor Points Really Indispensable in Label-Noise Learning? [C]∥ Conference on Neural Information Processing Systems (NIPS), Vancouver, Canada, 2019.
[37] Patrini G, Rozza A, Krishna Menon A, et al. Making Deep Neural Networks Robust to Label Noise: A Loss Correction Approach[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017: 1944-1952.
[38] Northcutt C G, Wu T L, Chuang I L. Learning with Confident Examples: Rank Pruning for Robust Classification with Noisy Labels[EB/OL]. (2017-08-09)[2020-01-15]. https:∥arxiv.xilesou.top/pdf/1705.01936.pdf.
[39] Yu X Y, Liu T L, Gong M M, et al. Learning with Biased Complementary Labels[C]∥Proceedings of the European Conference on Computer Vision (ECCV), 2018: 68-83.
[40] Goldberger J, Ben-Reuven E. Training Deep Neural- Networks Using a Noise Adaptation Layer[C]∥International Conference on Learning Representation (ICLR), Toulon, France, 2017.
[41] Wei Y, Gong C, Chen S, et al. Harnessing Side Information for Classification under Label Noise[J]. IEEE Transactions on Neural Networks and Learning Systems, 2019.
[42] Jindal I, Nokleby M, Chen X. Learning Deep Networks from Noisy Labels with Dropout Regularization[C]∥ IEEE International Conference on Data Mining (ICDM), Barcelona, Spain,2016: 967-972.
[43] Khetan A, Lipton Z C, Anandkumar A. Learning from Noisy Singly-Labeled Data[EB/OL]. (2017-12-13)[2020- 01-15]. https:∥arxiv.xilesou.top/pdf/1712.04577.pdf.
[44] Cheng J C, Liu T L, Ramamohanarao K, et al. Learning with Bounded Instance-and Label-Dependent Label Noise [EB/OL]. (2017-09-12) [2020-01-15]. https:∥arxiv.xilesou. top/ pdf/ 1709.03768.pdf.
[45] Menon A K, Van Rooyen B, Natarajan N. Learning from Binary Labels with Instance-Dependent Corruption [EB/OL]. (2016-05-04) [2020-01-15]. https:∥arxiv.org/pdf/1605.00751.pdf.
[46] Jiang L, Zhou Z Y, Leung T, et al. MentorNet: Learning Data-Driven Curriculum for Very Deep Neural Networks on Corrupted Labels[C]∥International Conference on Machine Learning(ICML), Stockholm, Sweden, 2018.
[47] Lee K H, He X D, Zhang L, et al. CleanNet: Transfer Learning for Scalable Image Classifier Training with Label Noise[C]∥ Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2018: 5447-5456.
[48] Wang Y S, Liu W Y, Ma X J, et al. Iterative Learning with Open-Set Noisy Labels[C]∥ Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2018: 8688- 8696.
[49] Ren M Y, Zeng W Y, Yang B, et al. Learning to Reweight Examples for Robust Deep Learning [EB/OL]. (2018-06-08) [2020-01-15]. https:∥arxiv.xilesou.top/pdf/1803.09050.pdf.
[50] Guo S, Huang W L, Zhang H Z, et al. Curriculumnet: Weakly Supervised Learning from Large-Scale Web Images[C]∥Proceedings of the European Conference on Computer Vision (ECCV), 2018: 135-150.
[51] Han B, Yao Q M, Yu X R, et al. Co-Teaching: Robust Training of Deep Neural Networks with Extremely Noisy Labels[C]∥ Conference on Neural Information Processing Systems(NIPS), Montreal ,Canada,2018: 8527-8537.
[52] Angelova A, Abu-Mostafam Y, Perona P. Pruning Training Sets for Learning of Object Categories[C]∥ Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2005: 494-501.
[53] Sun J W, Zhao F Y, Wang C J, et al. Identifying and Correcting Mislabeled Training Instances[C]∥Future Generation Communication and Networking (FGCN), Jeju-Island, Korea, 2007: 244-250.
[54] Zhu X Q, Wu X D, Chen Q J. Eliminating Class Noise in Large Datasets[C]∥Proceedings of the International Conference on Machine Learning (ICML), 2003: 920-927.
[55] Reed S, Lee H, Anguelov D, et al. Training Deep Neural Networks on Noisy Labels with Bootstrapping [EB/OL]. (2014-12-20) [2020-01-15]. https:∥arxiv.xilesou.top/pdf/ 1412.6596.pdf.
[56] Tanaka D, Ikami D, Yamasaki T, et al. Joint Optimization Framework for Learning with Noisy Labels[C]∥ Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2018: 5552-5560.
[57] Yi K, Wu J X. Probabilistic End-to-End Noise Correction for Learning with Noisy Labels[C]∥ Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2019.
[58] Li Y C, Yang J C, Song Y L, et al. Learning from Noisy Labels with Distillation[C]∥Proceedings of the IEEE International Conference on Computer Vision(ICCV), 2017: 1910-1918.
[59] Veit A, Alldrin N, Chechik G, et al. Learning from Noisy Large-Scale Datasets with Minimal Supervision[C]∥ Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2017: 839-847.
[60] Gao B B, Xing C, Xie C W, et al. Deep Label Distribution Learning with Label Ambiguity[J]. IEEE Transactions on Image Processing, 2017, 26(6): 2825-2838.
[61] Gong C, Zhang H M, Yang J, et al. Learning with Inadequate and Incorrect Supervision[C]∥IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 2017: 889-894.
A Survey of Label Noise Robust Learning Algorithms
Gong Chen 1,2*,Zhang Chuang 1,2,Wang Qizhou 1,2
(1. Key Lab of Intelligent Perception and Systems for High-Dimensional Information of Ministry of Education, School of
Computer Science and Engineering,Nanjing University of Science and Technology,Nanjing 210094,China;
2. Jiangsu Key Lab of Image and Video Understanding for Social Security, School of Computer Science and
Engineering, Nanjing University of Science and Technology,Nanjing 210094,China)
Abstract:
In the field of machine learning, supervised learning algorithm has achineved fruitful results both in theory and engineering application.
However, such fully supervised learning algorithms are severely dependent on the label quality of the training sample, and reliably labeled data are often expensive and time consuming to obtain in real-world applications. Some surrogate approaches such as web crawler and crowd-sourcing methods, are widely used to collect training data. Unfortunately, there are usually lots of misannotations (i.e. label noise) in the data obtained by these surrogate methods, which result in many potential negative consequences. Therefore, the research on label noise robust learning algorithm is of great significance in promoting the application of machine learning engineering and reducing the deployment cost of machine learning algorithm. In this paper, the latest research progress of label noise robust learning algorithm is comprehensively reviewed. The generation, influence and classification of label noise are summarized in detail. The processing methods of each kind of label noise are introduced, and the advantages and disadvantages of each kind of processing methods are analyzed.
Key words: artificial intelligence;machine learning;weakly supervised learning;label noise;deep learning;robust learning algorithm
收稿日期: 2020-01-15
基金項目:国家自然科学基金项目(61973162);江苏省自然科学基金项目(BK20171430)
作者简介: 宫辰(1988- ),男,教授,吴文俊人工智能优秀青年奖获得者, 研究方向是弱监督机器学习。
E-mail: chen.gong@njust.edu.cn
引用格式: 宫辰,张闯,王启舟.标签噪声鲁棒学习算法研究综述[ J].
航空兵器,2020, 27( 3): 20-26.
Gong Chen, Zhang Chuang, Wang Qizhou. A Survey of Label Noise Robust Learning Algorithms[ J]. Aero Weaponry,2020, 27( 3): 20-26.( in Chinese)
