面向航空飞行安全的遥感图像小目标检测
2020-07-16李希徐翔李军
李希 徐翔 李军


摘 要:有人机和无人机等各种新型航空飞行器的发展,给航空飞行安全带来了极大挑战,对影响飞行安全的小型目标进行检测是保障安全飞行的首要条件。本文针对现有基于深度学习的目标检测方法在遥感图像小目标检测时存在的不足,以及检测目标尺度过小、图像背景复杂、噪声干扰等问题,探讨了深度学习技术在遥感图像小目标检测方面的研究进展,重点分析了特征金字塔网络、注意力机制、倾斜框检测等相关技术在遥感图像小目标检测上的可行性,提出了一种具有较强泛化能力的目标检测模型。本文以高分二号遥感图像的高压电塔检测为例进行试验,结果表明,本文提出的模型在检测精度和计算开销上可达到更好的效果。
关键词: 深度学习;卷积神经网络;小目标检测;特征金字塔;注意力机制 ;人工智能
中图分类号:TN957.51;TP18 文献标识码:A 文章编号: 1673-5048(2020)03-0054-08
0 引言
随着航空技术的不断发展,如何保障国家空天安全,成为各国军事部门研究的重点和热点问题[1-2]。为了形成良好的航空安全环境,需要对各种潜在的飞行安全威胁进行充分考虑。其中,利用遥感图像对影响航空飞行安全的小型目标进行精确检测,是保障飞行的首要条件,起着至关重要的作用。
遥感图像中的小型目标检测结合了目标定位和识别,目的是在复杂的遥感图像背景中找到若干目标,对每一个目标给出一个精确的目标边框(Bounding Box),并判断该边框中目标所属的类别。对于实际遥感图像中的小目标检测,传统人工设计特征表达算法存在较大的局限性,其检测器依赖于数据自身特征结构,泛用性较弱。而随着深度学习[3]技术的出现,推动了目标检测的快速发展。基于深度学习的目标检测方法能够克服传统方法的缺点,适用于海量数据处理。然而对于图像中小型目标的检测,即通常定义为目标长宽小于原图尺寸的10%或者尺寸小于32×32像素的小目标,传统深度学习的目标检测算法仍然存在较大的改进空间。归纳起来,主要存在以下问题:
(1) 目标尺度过小,网络学习中容易被忽略。比如,部分小目标在经过数次下采样后,在特征图像上的大小只有个位数像素,目标检测器难以对其进行分类和定位。这种现象在低分辨率图像中更加明显。
(2) 遥感图像分辨率过低,图像模糊,携带的信息少,背景噪声影响大(云、雾、噪声等客观存在),导致小目标本身携带的信息过少,特征表达能力弱[4]。
(3) 大部分遥感图像中小目标数量过少。在训练过程中,传统的卷积神经网络更容易学习大目标
的特征,而对小目标的检测效果较差。
本文研究的深度学习模型框架构建的关键点在于实现遥感图像的小目标检测,以解决飞行器飞行安全问题,因此特征提取、特征融合[5-6]中所使用的方法,需要针对小型目标的空间信息和语义信息提取,从而最终实现大尺度遥感图像中的小目标检测。然而在实际的小型目标检测中,由于目标本身过小,深层的特征提取网络中的多次下采样处理,容易导致尺度较小目标被忽略;并且, 由于遥感图像上存在背景噪声问题,大规模复杂背景可能会导致更多的误检,特别是在低分辨率的图像上这种现象更加明显。鉴于现有算法的不足,对小目标检测算法的改良方向进行分析,拟采用以下多种策略来提高小目标检测的性能,包括:
(1) 特征金字塔网络。特征金字塔能够提取待检测目标的多层特征,构建一种多尺度的深度学习模型,实现多尺度特征的融合。然而利用特征金字塔进行特征提取过程中,存在深层网络下采样步长过大导致小目标特征丢失,特征图像的边缘信息较少导致目标边界框回归精度差等问题。因此,可以通过组合残差网络和金字塔网络来构建特征提取网络,从而能够进行浅层特征的提取。而在特征提取阶段利用浅层特征金字塔进行多尺度特征学习,能够避免深层网络带来的计算负担重,从而提升计算速度,并且由于网络参数减少,有利于进行循环式的特征训练。
(2) 注意力机制。空间注意力机制模型是一种从大量信息中有选择地筛选出少量重要信息的基础部件模型。通过学习遥感图像目标与背景特征,运用权重系数进行加权求和的方法实现特征分离,能够对遥感图像中的背景噪声进行抑制。具体来说,注意力机制模块能够获取显著图,将检测目标与背景分离,利用Softmax函数对特征图像进行操作,与原始特征图像进行结合,获取新的融合特征,达到降噪目的。
(3) 倾斜框检测。目标密集区域如停车场,传统矩形框难以正确拟合目标,目标检测结果可能存在大量矩形框重合,导致结果存在大量漏检。斜框检测算法用倾斜的矩形框代替传统的矩形框,能够更好地拟合遥感图像中小目标的空间位置,即用水平框+旋轉角度来表示一个倾斜框,从而在遥感图像中包含大量密集的小目标情况下具有更强的泛用性。
本文主要研究遥感图像中小目标检测方法及其深度网络模型的构建技术。通过对遥感图像小目标检测框架结构中使用的特征提取、特征选择、注意力机制方法进行分析和研究,构建一种新型的小目标检测网络模型,该网络结构包含特征提取模块、空间注意力模块、RPN模块、分类和定位模块。总体思路是利用特征金字塔对不同尺度的目标特征进行提取,融合特征低层空间信息与高层语义信息,以获取层间互补信息,提高可扩展性。由于大部分遥感图像中不可避免存在各种噪声,模型中还加入了空间位置软注意力机制(Spatial Attention),将浅层特征提取网络和空间注意力机制进行结合,构建一种面向遥感图像的特征提取模型,再利用RPN模块进行ROI区域获取,最终通过分类器和检测器,获取检测目标类别信息以及位置信息。
1 基于深度学习的目标检测发展与局限
目标检测算法的发展分为基于传统手工特征的目标检测和基于深度学习的目标检测。传统目标检测算法(例如,比例不变特征变换[7-8]、定向梯度等)设计特征存在目标表达能力不足、分类错误率高、难以应用于多类目标检测等缺点。深度学习在目标检测领域中有着巨大的应用潜力,一般采用端到端的方法进行目标检测,原始图像输入神经网络能够通过降低维度来减少计算量,并且通过强化深度学习算法能够使预测结果尽可能接近原始边界框,从而确保精确的边界框预测。相比传统算法,深度学习方法具有更强的泛用性,成为了当前目标检测的研究与应用热点。
卷积神经网络从LeNet[9-10]开始,并从AlexNet [11]网络出现开始快速发展,诞生了许多经典的网络。基于深度学习的目标检测算法分为两阶段目标检测算法和单阶段目标检测算法。两阶段目标检测算法又称基于候选区域(Region Proposal)的算法,其首先寻找目标物体的候选区域,然后进行目标物体分类。经典的两阶段算法包括R-CNN[12-13]、SPP-Net[14]、Fast-RCNN[15]、Faster-RCNN等。R-CNN使用基于选择性搜索的方法进行窗口搜索,采用了图像分类网络,但是存在输入的图像需要缩放候选区域的缺陷。He Kaiming等人提出了SPP-Net,在网络的全连接层之前加入空间金字塔池化层,解决不同尺寸图像输入卷积网络的问题,实现了图像中任意大小和长宽比区域的特征提取。Fast-RCNN加入ROI Pooling层进行不同维度特征归一化,并且利用多任务损失函数(Multi-task Loss)进行边框回归,提高训练和检测效率。Faster-RCNN进一步改进和利用RPN(Region Proposal Network)网络来完成候选框的选取,实现了一个完全端到端的卷积神经网络目标检测模型。
单阶段目标检测算法不产生候选区域,直接利用整张图片作为网络的输入,进行分类和定位。典型的单阶段目标检测算法包括YOLO [16]、SSD [17]等。Joseph和Girshick等人在2015年提出YOLO算法,该算法仅通过一次前向传播直接得到目标包围框的位置和目标的类别,极大地提高了检测速度。Liu Wei等人于2015年提出SSD算法,实现了在不同尺度特征图像上利用卷积核预测目标类别和位置,吸收了YOLO算法速度快的特点,提高了精度。
常见的两阶段目标检测和单阶段目标检测方法都有不足之处,前者虽然检测准确率和定位精度更高,但需要首先生成目标候选区域,因此无法达到实时性的检测;后者对于每一层的特征图都要去设置密集的候选框,产生太多的负样本,虽然速度较快,但是由于传统卷积网络在所学特征对方向和尺度变化鲁棒性上表现一般,因此对于小物体和重叠物体检测效果不佳。
2 特征金字塔
2.1 特征金字塔网络
经典的目标检测网络,例如Faster-RCNN进行目标检测时,ROI区域和获取往往取决于最后一层特征网络获取的特征图像,然而这种方法仅仅适用于图像中占有较大像素比例的大型目标检测,对于小型目标检测,存在特征提取信息不足、检测精度较低等问题。由于检测目标尺寸过小,在特征提取中经过多层的卷积操作后,小目标的语义信息基本已经消失,在ROI区域映射到特征图像的操作中,经过多层卷积的小目标特征在特征图像上的映射区域只有很小一部分甚至没有。所以,为了解决多尺度的特征提取问题,需要引入特征金字塔网络(FPN)进行语义特征和细节特征学习。
在目标检测过程中,一般低层特征会保留较多的位置信息,高层特征保留较多的语义信息,FPN通过多层CNN堆叠的金字塔形式进行高层和低层特征组合以实现特征融合。FPN的结构设计特点在于其top-down[18-19]结构,以及不同尺度特征的横向连接,将高分辨率的浅层特征及高语义信息的深层特征统一到同一尺度进行特征融合,使得最终获得的融合特征同时具有丰富的空间信息和语义信息。通过单尺度的图像输入,利用FPN能够获取多尺度信息,降低多层CNN网络带来的图像信息损失。
2.2 特征金字塔网络的优化
基于CNN的目标检测一般采用VGG或ResNet作为特征金字塔(FPN)的预训练模型,这些预训练模型在ImageNet[20]上进行了预训练。然而,这些预训练网络存在一些局限,模型最初设计用于图像分类领域,而由于自然图像和遥感图像在图像分辨率、目标占图像比例等方面存在一定的差异性,所以不一定适用于目标检测,可能会导致模型结果不理想。此外,预训练模型网络过深,在模型训练过程中会带来计算冗余等问题。
遥感图像中的小目标在深层特征提取网络中会丢失大部分的特征信息,特征图中较大的采样步幅也会导致小目标被忽略。相对而言,特征金字塔网络采用浅层结构,能够平衡特征位置信息与语义信息,并且浅层网络的参数远远低于前述预训练的网络,网络中下采样运算较少,避免了微小对象像素映射区域过小的问题,提高了鉴别性能。利用这种轻量级架构,检测网络可以从头开始训练并进行多步循环训练。由于其减少了大量冗余参数,在不降低小目标检测精度的情况下,网络能够以较高的速率进行迭代训练更新,进一步提高了检测效率。
3 注意力机制
3.1 注意力机制原理
注意力机制(Attention Mechanism)[21]來源于人类视觉。人类视觉处理图像信息时,通过目视扫描获取全局图像,有选择性地关注获取图像的部分信息,忽略大部分多余信息,即人类视觉更关注于重点区域的细节特征,这种机制被称为注意力机制。注意力机制是一种筛选有价值信息的手段,能够提升信息处理效率和准确率,进行有效的信息资源分配。比如人类在阅读报纸时往往先关注报纸标题,这就是注意力机制的体现。
注意力机制在计算机视觉领域应用广泛,特别是在语义分割、图像分类、目标检测等领域。在深度学习方法中,注意力机制模块主要用于从繁多复杂的视觉信息中筛选出所需的关键信息。在网络的构建中,一般将注意力机制模块插入卷积神经网络的中间部分,对不同的视觉信息进行权重分配,作为一种过滤多余信息,抑制图像噪声的重要手段。
3.2 注意力机制在目标检测领域的应用
注意力机制作为一种增加检测模型广度的手段,在目标检测领域的使用越来越广泛,主要包含以下几个方面:
(1) 空间注意力机制。一般采用Sigmoid函数进行特征图计算,与原始特征图像相加、相乘等。Google DeepMind提出STN[22]网络(Spatial Transformer Network),将空间注意力机制作为一种学习输入图像变化量的预处理模块来使用,一步完成目标仿射变换与定位。Capacity Networks[23]则采用了两个子网络,低性能子网络(coarse model)与高性能子网络 (fine model),前者用于定位ROI区域,后者进行精细化处理,实验证明其两步法的结构具有更高的检测精度。
(2) 通道注意力机制。SENet作为2017届ImageNet分类比赛的冠军,是经典的基于通道注意力机制模型。SENet以图像通道为基准进行权重分配,增强或者抑制不同的图像通道,过滤不重要的通道信息。通道注意力机制在目标检测领域应用广泛,比如嵌入SENet的YOLO改进算法等等。
(3) 混合注意力机制。将空间注意力机制与通道注意力机制并联或串联,同时发挥作用。CBAM[24] (Convolutional Block Attention Module)是混合注意力机制的代表性网络,以一种串联的结构将两种注意力机制结合,并且在ImageNet-1K、MS COCO和VOC 2007等數据集上做了大量实验,证明增加CBAM模块后网络性能得到明显提升。
(4) 其他注意力机制。包括与GAN[25]对抗网络、RCNN网络等结合的注意力机制。
由于遥感图像本身存在大量噪声(阴影遮挡、边界模糊、周期性条纹、亮线以及斑点等),在获取候选框区域的过程中可能受到图像噪声影响(背景噪声、噪点等),使得训练模型会造成大量误检,大大降低准确率和召回率。为了削弱非对象信息对模型训练的影响,引入注意力机制能够抑制遥感图像中各种噪声的影响。
4 倾斜框检测
R2CNN[26](Rotational Region CNN)算法作为一种倾斜框(inclined box)检测的经典算法,最初提出用来解决旋转文本的检测。R2CNN算法主要是在Faster-RCNN算法的基础上进行修改,设计了多种不同尺寸的目标检测矩形框,并且利用倾斜的非极大抑制(NMS[27])来优化目标检测结果。R2CNN在检测任意方向的场景文本上取得了良好的效果,其在ICDAR2015和ICDAR2013上取得了相当有竞争力的成果。
由于遥感图像中小型目标具有方向不确定性,特别是停车场等目标密集的地区,如果采用一般矩形框,会产生大量重叠区域,降低检测效果。所以在小型目标的检测上采用R2CNN网络进行倾斜框的预测有利于更好地确定目标的空间位置。相对于排列紧密的小目标,NMS算法可能会造成目标漏检,原因是检测区域的轴对齐框之间的IoU[28]数值一般很高,但倾斜NMS不会漏检目标,倾斜NMS的IoU值较低,因此使用倾斜框检测更加适用于遥感图像上的小目标检测。
具体来说,R2CNN在检测框尺寸上进行了新的设计,采用了三种长宽不一致的尺寸应用于ROI Pooling阶段,另外设计的两种尺寸进行水平目标和竖直目标的检测。R2CNN对提取到的ROI特征进行融合作为后续预测支路的输入,其预测输出包含3个支路,第一个支路对检测框范围内有无目标进行判断。第二个支路是一般的水平框(axis-aligned box)预测,第三个支路是算法的核心,即倾斜框(inclined box)的预测,通过进行倾斜NMS非极大值抑制处理得到最终结果。
5 小目标检测网络
5.1 总体网络结构
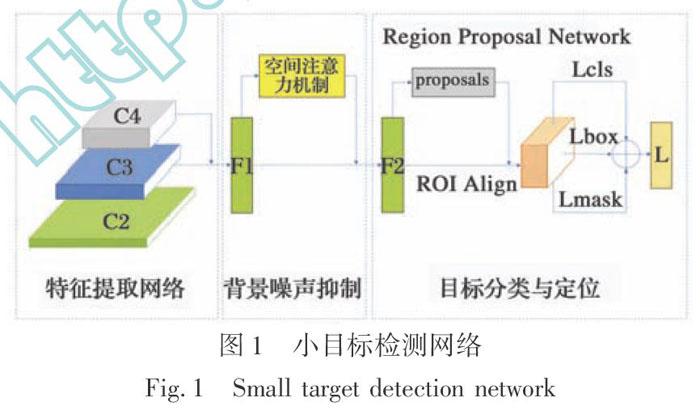
本文提出了一个新型的卷积神经网络,以解决在较低分辨率遥感图像中的小目标检测问题。主要思路是将裁剪过的图像输入空间金字塔进行特征提取,获取融合特征,随后引入空间位置软注意力机制模块,进一步对融合特征进行处理,以抑制遥感图像上的背景噪声,再利用目标检测子网络,获取检测目标的类别和边框位置。本节将介绍新型卷积神经网络的具体网络结构,并且给出空间位置软注意力机制,ROI区域提取,及其Loss函数的详细实现过程。
本文在Fast-RCNN算法的基础上对特征提取部分以及网络检测部分进行了改进,以ResNet-101网络为基础结构,构造了一种新的特征金字塔网络,以提升网络对多尺度特征的表达能力。具体的网络结构如图1所示。首先输入整张图片进入特征金字塔进行特征提取,再利用RPN模块提取检测目标候选框(ROI)信息。之后通过多个卷积层和池化操作来提取特征图对应的候选框区域(Region Proposal),再通过ROI Align模块使生成的候选框映射产生固定大小的特征图像,以统一特征向量维度,方便输入后续的全连接层处理。最终每个特征向量被送到一系列全连接层,进入两个输出层进行类别和位置计算,即一个层利用Softmax函数对目标检测类别(包括背景)进行类别概率估计,另一个层输出每个对象的4个精细边界框位置数值。
5.2 特征提取网络
在特征提取网络模块中,进行了特征金字塔的构建,将ResNet-101作为特征提取的基础训练网络。由于是基于小目标的目标检测,深层的网络结构会导致目标语义信息消失,为了减少网络参数,以{C2,C3,C4}为基础层级结构,采用C3、C4层进行特征融合,在C4层主要获取语义信息,在C3层获取更多位置信息,然后进行C3、C4层特征融合。输入遥感图片首先经过C2层卷积,然后通过C3、C4获取特征图像,C3层首先进行上采样,然后通过一个插入模块处理,扩展特征图像的接收域并增强语义信息。插入模块主要由1×1的卷积核与3×3卷积核组成,1×1的卷积核的主要作用是减少特征图像通道数,完成通道降维,并不改变特征图像尺寸。3×3卷积核对所有融合特征进行卷积,减少上采样产生的混叠效应,并且3×3卷积核相比大尺寸卷积核具有更多的非线性函数,使得判决函数更加可靠。最后将的C3、C4特征图像调整为统一尺寸,逐个像素进行特征图像相加,获取加入注意力机制的融合特征。
具体实验中将高分二号遥感图像进行裁剪,输入图像为800×800×3的RGB图像,利用ResNet-101网络提取出C2、C3、C4不同尺寸的特征图像,然后将C3与C4的上采样图像进行特征融合,得到最终特征图像F1。特征提取网络中C2,C3,C4层具体结构如图2所示。
5.3 背景噪声抑制
空间软注意力机制模块作为特征提取网络输出特征图像的后续输入网络,经过平均池化层和最大池化层,在通道维度上进行卷积运算生成显著性图,显著性图包含检测区域为前景和背景的分数,能够区分图像前景与背景信息。通过在显著性图上进行Softmax函数计算,生成空间注意力特征图,进一步抑制遥感图像中的背景阴影或者其他噪声并相对增强对象信息。由于显著性图具有连续性,因此并没有完全去除非对象信息,这种方式有利于保留一定程度的上下文信息并提高鲁棒性。
空间变换网络(Spatial Transformer Network)模块可作为新的层直接加入到原有的网络结构中。模型的输入为
U∈RH×W×C(1)
式中: H和W分别代表上一层特征图像张量的高度和宽度;C代表图像张量的通道数量,包括多个卷积核产生的图像通道信息。之后将特征图像输入两条通道,一条通道是特征图像信息进入下一层RPN网络,另一条通道是特征图像直接进入空间注意力机制模块。其中上层网络通过Inception和C4层后进行参数学习,学到的參数能够作为特征生成器的参数,通过Softmax算法,生成一个新的特征图像。然后,与原始输入特征图像进行相加,最终获取新的特征融合图像。
V∈RHt×Wt×C(2)
空间注意力机制模块中的核函数(kernel)表示如下:
K(x,z)=φ(x)×φ(z)(3)
通过空间位置软注意力机制模块获取新的融合特征图像,能够有效抑制目标检测中的背景噪声。
5.4 损失函数
对每个ROI候选区域而言,损失函数由三部分
组成: 分类损失、回归损失、分割损失。多任务损失函数定义如下:
L=Lcls+Lbox+Lmask(4)
对于分类损失函数Lcls,采用对数似然损失(Log-likelihood Loss)方法进行计算,也被称为交叉熵损失(Cross-Entropy Loss),输出目标属于每一个类别的概率值,公式如下:
Lcls(Y,P(Y|X))=-logP(Y|X)=
-1N
∑Ni=1∑Mj=1yijlog(pij)
(5)
式中: X,Y为输入和输出变量;N,M代表样本数量、目标检测类别数量;yij为一个取值为0或1的数,对输入样本是否为类别j进行判断,代表GT标签是否为此类别;pij为输入样本属于类别j的概率。yij定义如下:
yij=0negative label
1positive label
(6)
对于回归损失函数Lbox,为了减少计算量,使函数更具鲁棒性,采用L1损失函数进行计算,L1损失函数也被称为最小绝对值偏差(LAD),损失函数Lbox计算公式为
Lbox(w,w*)=smoothL1(w-w*)(7)
smoothL1(x)=0.5x2if |x|<1
|x|-0.5otherwise(8)
式中: w={tx,ty,tw,th},以向量形式表示检测框4个顶点的参数化坐标;w*代表与w对应的ground-truth的4个顶点坐标向量。
Lmask函数为平均二值交叉熵损失函数,二值的交叉熵函数定义如下:
对于每个检测样本而言,yi表示检测目标的期望输出值,y^l表示检测目标的实际输出值。mask模块的ROI区域输出维度为K×m2,其中m2代表ROI Align输出的特征图像尺寸,即检测网络中每一个类别都有一个尺寸为m2的二值化mask层,以区分前景与背景。而ROI Align相对于ROI Pooling具有更高的像素对齐精度,相对于ROI Pooling引入了双线性插值算法,使ROI特征更好地映射到原始图像。
在计算过程中,mask层通道数目与目标检测类别相同,每个通道对应一个类别,对每一个类别都采用Sigmoid函数进行计算,判断所属类别概率,输出每一个ROI区域对应的最终类别。在利用Lmask函数进行计算时,仅仅使用所属类别分支的相对熵误差进行Loss计算,以避免跨类别竞争,最终取ROI区域全部像素交叉熵结果的平均值为Lmask函数输出结果。
6 实验
6.1 数据集
实验中,利用高分二号图像进行裁剪制作目标检测数据集。遥感影像中的高压电塔作为一种大尺寸影像中的稀疏小目标,是研究小目标检测的理想对象,因此,以高分二号影像中的高压电塔作为检测对象,裁剪出186张包含高压电塔的800×800图像,共包含343个高压电塔目标,目前的像素尺寸范围为13.44×13.76到93.36×101.64。实验中利用留出法划分数据,其中70%为训练数据集,30%为测试数据集,再进行高压电塔检测模型训练和测试实验。
在数据集中,每个目标的四边形边框表示为(x1,y1),(x2,y2),(x3,y3),(x4,y4),其中(xi,yi)为注释四边形的顶点坐标,按顺时针排序。由于VOC2007数据集以xml格式注释,将裁剪后的图片txt文件转换为xml文件,利用VOC数据格式进行目标检测实验。
6.2 评估指标
目标检测有三个评估指标。第一个是精确率(precision),用于测量每一类识别出来的图片中True positives所占的比率。第二个是召回率(recall),用于测量每一类正确识别出来的目标个数与测试集中所有目标个数的比值。第三是平均精度(AP),简单来说就是对PR曲线上的求均值。
精确率(precision)计算公式如下:
precision=tptp+fp=tpn(10)
式中: n代表True positives + False positives,也就是系统一共识别出来多少图片。
[10] Chen Y T, Chen T S, Chen J. A LeNet Based Convolution Neural Network for Image Steganalysis on Multiclass Classification[J]. DEStech Transactions on Computer Science and Engineering, 2018, 332: 218-222.
[11] Aswathy P, Siddhartha, Mishra D. Deep GoogLeNet Features for Visual Object Tracking[C]∥ IEEE 13th International Conference on Industrial and Information Systems, 2018: 60-66.
[12] Masita K L, Hasan A N, Paul S. Pedestrian Detection Using R-CNN Object Detector[C]∥ IEEE Latin American Conference on Computational Intelligence, Gudalajara, Mexico, 2018: 1-6.
[13] Taniguchi K, Kuraguchi K, Konishi Y. Task Difficulty Makes ‘NoResponse Different From ‘Yes Response in Detection of Fragmented Object Contours[J]. Perception, 2018, 47(9): 943-965.
[14] Akbas E, Eckstein M P. Object Detection Through Search with a Foveated Visual System[J]. PLoS Computational Biology, 2017, 13(10): e1005743.
[15] Shao F M, Wang X Q, Meng F J, et al. Improved Faster R-CNN Traffic Sign Detection Based on a Second Region of Interest and Highly Possible Regions Proposal Network[J]. Sensors, 2019, 19(10): 2288.
[16] Zhang D P, Shao Y H, Mei Y Y, et al. Using YOLO-Based Pedestrian Detection for Monitoring UAV[C]∥Tenth International Conference on Graphics and Image Processing, 2019: 110693Y.
[17] Li H T, Lin K Z, Bai J X, et al. Small Object Detection Algorithm Based on Feature Pyramid-Enhanced Fusion SSD[J]. Complexity, 2019: 7297960.
[18] Forder L, Taylor O, Mankin H, et al. Colour Terms Affect Detection of Colour and Colour-Associated Objects Suppressed from Visual Awareness[J]. PloS one, 2016, 11(3): e0152212.
[19] Hua X, Wang X Q, Wang D, et al. Military Object Real-Time Detection Technology Combined with Visual Salience and Psycho-logy[J]. Electronics, 2018, 7(10): 216.
[20] Holman A C, Girbǎ A E. The Match in Orientation Between Verbal Context and Object Accelerates Change Detection[J]. Psihologija, 2019, 52(1): 93-105.
[21] Zhang Y, Chen Y M, Huang C, et al. Object Detection Network Based on Feature Fusion and Attention Mechanism[J]. Future Internet, 2019, 11(1): 9.
[22] Lin C H, Yumer E, Wang O, et al. ST-GAN: Spatial Transformer Generative Adversarial Networks for Image Compositing[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018: 9455-9464.
[23] Guleryuz O G, Kozat U C. Joint Compression, Detection, and Routing in Capacity Contrained Wireless Sensor Networks[C]∥IEEE/SP 13th Workshop on Statistical Signal Processing, Bordeaux, France, 2005: 1026-1031.
