复杂背景环境下基于SSD_MobileNet深度学习模型的火焰图像识别研究
2020-05-26赵亚琴孙一超
卢 鹏,赵亚琴,陈 越,孙一超,徐 媛
(南京林业大学机械电子工程学院,南京,210031)
0 引言
火焰的快速检测对火灾的预警和及时处理具有重要意义,火灾监控视频系统是预防火灾的重要手段,而火焰是火灾发生的重要视觉标志,因此,基于图像特征的火焰识别方法已成为防火领域的热点。基于图像特征的火焰识别方法主要分为火焰静态特征和动态特征两类。火焰静态特征主要有边缘、颜色空间信息等,乔建强[1]提出了基于边缘特征的火焰检测方法,对图像提取边缘特征信息,从而进行火焰识别;陈天炎等[2]提出基于YCbCr颜色空间阈值分割的方法,利用火焰在颜色空间中的特征提取火焰区域。火焰动态特征包括混合高斯背景模型、帧差等,如李庆辉等[3]利用一种自适应混合高斯模型检测视频序列中的运动目标,然后采用聚类算法分割疑似火焰区域与非火区域;Stadler等[4]使用加权帧间差分法提取火焰候选区域,通过高闪烁频率区分火焰和非火焰,将阈值滤波和高通滤波器应用于强度变化从而提高识别率。由于火焰的外焰具有运动的特征,而焰心的运动特征并不是很明显,因此,采用常见的基于颜色、边缘、纹理等静态图像的特征,难以区分火焰和火焰颜色、纹理相似的红花或光照等干扰对象,基于动态特征的检测方法又会使得焰心区域被错误地判断为背景。
深度卷积神经网络可以学习归纳图像特征,具有更强的辨别能力和泛化能力,一些研究者探索了将深度卷积神经网络应用于火灾图像识别。如,Wu等[5]用Krizhevsky等[6]网络模型设计了火焰与烟雾分类器,该分类器以56×56的图像块为输入,最后用softmax对图像块进行分类;Frizzi等[7]设计了一个包括4层卷积层、2层最大池化层和2层全连接层的卷积神经网络,最终输出层是个三分类器,能分类出火焰、烟雾或无火灾。然而,目前的研究大多数集中于利用深度学习网络来对整幅火焰图像进行分类,这种粗粒度的分类方法在图像中火焰区域较小时,目标特征容易“淹没”在复杂的背景特征中,导致最后的分类产生漏检,而且这类方法无法标记出图像中的火焰区域,无法应用于后续火焰蔓延特征、火势大小、火焰面积的计算等研究中。此外,由于火灾视频监控终端通常是嵌入式系统,对算法识别的效率要求更高。更精细的深度目标检测网络往往伴随着巨大的参数量和复杂的计算,不适用于精简的嵌入式系统,如Ren等[8]提出的Faster R-CNN用于目标检测,其基于候选区域的网络结构难以快速运行。此后,Redmon等[9]提出了YOLO,只用一次评价直接从输入的整幅图像预测边框和类别概率,相对于Faster R-CNN精度降低但具有较高的检测速度便于实时检测,Liu等[10]又提出了SSD (Single Shot MultiBox Detector)与YOLO同属于单次检测器,同时吸收了Faster R-CNN的一些长处,在不损失精度的情况下保持了快速的特性,但依旧难以搭载在如无人机这种对林火实时检测的嵌入式系统中。
本文将经典SSD深度学习网络的VGG16[11]替换为MobileNet[12],应用深度可分离卷积,降低网络参数,构建一种基于SSD_MobileNet的复杂环境火灾火焰区域检测模型,实现复杂环境中火焰图像中火焰区域的较精确标记。针对光照和红花等类似火焰的干扰,扩充背景数据集样本并迁移参数再次训练模型,进一步提高模型的泛化能力。
1 火灾火焰区域检测SSD_MobileNet模型
1.1 火焰区域检测的MobileNet网络结构
(1)MobileNet网络结构
火焰区域检测MobileNet的网络结构如图1所示,MobileNet各层特征图尺寸如表1所示。输入图像尺寸为300×300×3,第一层卷积层conv0为标准卷积,后面十三层为深度可分离卷积。
(2)MobileNet网络结构的计算复杂度分析
设卷积核K尺寸为DK×DK×M×N,M为输入的通道数,N为输出的通道数,若输入特征图F尺寸为DF×DF×M,卷积核移动步长为1,并计入延拓,使特征图刚好能被完全卷积,则标准卷积计算公式为[12]:

图1 MobileNet网络结构

表1 MobileNet各层特征图尺寸
(1)
标准卷积的对应计算量为:
DK×DK×M×N×DF×DF
(2)
深度卷积计算公式为:
(3)
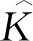
深度卷积的对应计算量为:
DK×DK×M×DF×DF
(4)
深度卷积对输入的每个通道使用一种卷积核,没有对其进行组合产生新的特征。而逐点卷积层利用1×1卷积来对深度卷积的输出计算一个线性组合从而产生新的特征。逐点卷积的计算量为:
M×N×DF×DF
(5)
火焰区域检测MobileNet的网络结构通过将卷积分为两步得到的计算缩减为[12]:
(6)
MobileNet使用3×3的深度可分离卷积相较于标准卷积少了8到9倍的计算量,然而只有极小的准确率下降。
1.2 火焰区域检测的SSD MobileNet网络结构
将图2(a)中的VGG16结构用MobileNet结构代替,火焰区域检测的SSD MobileNet的网络模型如图2(b)所示。图2(b)虚线框中为MobileNet的前14层网络(即图1中conv0到conv13的部分),后面直接添加8层卷积层,并仿照SSD300选取6层用作预测。由于火焰区域检测的MobileNet网络结构中尺寸为38×38的特征图过于靠前,不适合用作预测,因此,本文的火焰区域检测SSD_MobileNet模型选用19×19的conv11作为最大尺寸预测层,并额外补充了2×2的特征图(conv16_2)。
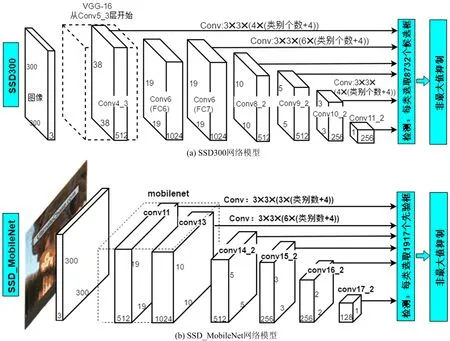
图2 SSD300和SSD_MobileNet网络模型对比
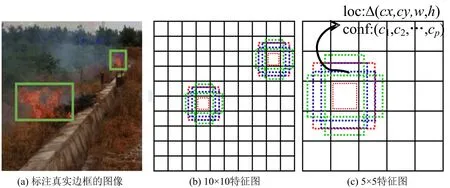
图3 SSD_MobileNet模型的先验框
1.3 火焰区域检测先验框的确定
SSD_MobileNet模型借鉴了Faster R-CNN锚点框机制,将各特征图分割为若干相同大小的网格,如图3所示,对每个网格再设定一系列固定大小的先验框,然后分别预测先验框的偏移以及类别得分,最终通过非极大值抑制方法得到检测结果。
预测层尺寸的选取直接影响各层先验框的数量。如表2所示,火焰区域检测的SSD_MobileNet结构的先验框总数相对SSD300结构有明显的减少,从而能够进一步增加火焰区域检测SSD_MobileNet模型的检测速度。

表2 SSD_MobileNet和SSD300先验框数量
1.4 网络训练
SSD训练时需要构建样本图像的标准框与先验框的匹配策略,原始的匹配策略为:首先,计算图像中每个标准框与其先验框的IOU值(Intersection Over Union),选择IOU值最大的先验框匹配该标准框,以确保每个标准框至少匹配一个先验框;然后,选择IOU大于某个阈值(本文设为0.5)的剩余先验框与该标准框匹配;对于某个先验框,如果有多个标准框与之匹配,则该先验框只与IOU最大的那个标准框进行匹配。最后采用困难负样本挖掘(hard negative mining)[13]方法,选取误差较大的先验框作为训练的负样本,并确保正负样本比例接近1∶3。
SSD的这种训练过程对于疑似火焰区域都需要人工标记标准框,然而,这种策略必然耗费大量的时间和人力。干扰对象实际中是不确定的,为每一种干扰对象提供训练数据集也是不现实的,而且,某些干扰对象如小花花丛、密集的枫叶等图像中前景零散出现在背景中,这也增加了标准框标记的难度。为了提高训练效率和解决某些干扰对象标准框难以标记的问题,本文将训练数据集分为火焰和干扰两部分,使用无人工标记的干扰数据集训练,只对火焰图像打标。具体训练过程如下。
每次训练迭代时,分别从火焰和干扰两种数据集中抽取图像样本,一次迭代至少两张图像,其中包含一张火焰图像,保证每次迭代都能产生正样本。如果存在来自干扰数据集的样本参与迭代训练,本次迭代采用的匹配策略为先用SSD的训练方法确定正样本,然后将所有图像中负样本先验框按置信度降序排列,选取一定数量的置信度较高的先验框作为最后参与训练的负样本。若迭代中的样本均来自火焰数据集,则直接用SSD的训练方法匹配正负样本。
这种训练策略中干扰数据集只提供背景类,不需要专门对干扰对象进行分类标记,避免了干扰对象的多分类问题,最终只需对目标作火焰和干扰二分类,此外,Faster R-CNN和YOLO均可借鉴这种策略训练。尽管在迭代中对所有负样本先验框排序操作增加一定程度存储空间的占用,但并不影响火焰预测时的速度和空间利用率。
确定好训练样本后,接下来就是在迭代训练中降低损失函数。本文的SSD_MobileNet的位置损失函数为[10]:
(7)
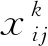
(8)
平滑损失smoothL1(x)定义为[10]:
(9)
置信损失函数为[10]:
(10)

总体目标损失函数为位置损失和置信损失的加权和,因此,总体目标损失函数为[10]:
(11)
其中,N是先验框正样本的数量,α为权重系数。
2 火焰检测实验结果与分析
2.1 实验流程
首先采用纯火焰数据集训练一批基于深度学习的检测模型,针对测试中如花丛和光照等误检率较高的对象建立干扰数据集。然后迁移第一批模型训练的卷积层参数,用来对新模型参数初始化,在添加了干扰的数据集上,用新的训练策略再次训练模型。最后,用统一的测试集对两批模型分别测试验证,记录数据。
2.2 数据集描述
实验视频数据来源于拍摄[14]和公共网站(http://imagelab.ing.unimore.it/visor)。如图4所示,火焰视频的训练样本取自13个不同的场景,随机选择其中8个火焰场景用于训练集,剩余5个火焰场景用于测试集。场景中的背景有枯草,火焰伴有强烈的烟雾,在有风的情况下,形态更是波动剧烈。每个火灾火焰视频文件能分解上千张图像不等,根据火焰变化的幅度,每10到40帧取一张图像,总共采集到1 500张火焰图像,对每张图像标注后,进行了第一批的训练。干扰数据集有花丛、枫叶、红黄颜色衣服的行人以及各种形式的光照,总共800张。测试数据集包括400张火焰图像作正例和200张无火焰图像作负例。

图4 训练集示例
2.3 评估指标
实验评价模型检测效果的评测指标为[15]:
(12)
(13)
(14)
其中precision为精确率,recall为召回率,F1score为precision和recall的调和平均值,nTP为火焰的正检总数,当预测框和标准框的IOU值大于0.5的检测记录为正检;nFP为火焰的误检总数;nFN为火焰的漏检总数。火焰检测主要是用来防止灾害,在保证误检总数nFP合理的前提下,要求火焰正检总数nTP越高,漏检总数nFN越低,模型效果越好。在同一测试集上测试,调节置信度阈值,在火焰识别的精确率大于0.85的区域内先找到最高召回率,在此基础上再确定最高的精确率所对应的阈值。
2.4 实验结果分析与比较
由于已有文献基于深度学习的火焰检测方法只是对测试图片进行火焰和非火焰的分类,没有对火焰区域标记,而本文是重点研究几种深度学习的火焰图片中火焰图像的标记准确性,因此,本文实验主要比较几种常见的深度学习和本文的SSD_MobileNet模型的火焰区域标记性能。
本文实验所用的硬件配置为CPU:Intel i7-8700,GPU:Nvidia GTX1060,显存6GB,内存16G,使用tensorflow框架,以4幅图像为一个批次,初始学习率设为0.001。
置信度阈值调节后,模型的精确率略高于85%,部分火焰正例样本和反例样本的检测结果如图5所示,本文的SSD_MobileNet模型将颜色和纹理与火焰相似的一些干扰误检为火焰,如图5最后的红花、光照2幅图像。只采用火焰正例样本的模型识别结果如表3所示。Faster R-CNN是所有模型中参数最多的,数据集容量较小,难以体现出满意的检测效果。YOLOv3-tiny[16]的误检率和正检率较其它模型低,更偏向于高精确率而非召回率。经典的SSD300与本文的SSD_MobileNet模型火焰识别性能相当。

表3 纯火焰数据集训练的模型识别效果

图5 SSD_MobileNet测试结果示例 Fig. 5 Example of SSD_MobileNet test results
加入干扰样本用改进的匹配策略训练后,测试发现模型的误检率有显著下降,图5中颜色和纹理与火焰相似的花和光照能够被正确的识别。重新调节阈值,结果如表4所示。F1 score值相对第一次实验的上升表明加入花和光照的数据集后,模型的检测效果有了确切的提升。由于阈值的下调,精确率上升较小,召回率均提升了1.5~2.5个百分点。

表4 加入干扰集训练的模型识别效果
表5记录了各模型的检测速度。Faster R-CNN要生成候选区域再进行识别,且参数较多,速度上存在明显的缺陷;YOLOv3-tiny检测速度最快;轻量化的SSD_MobileNet的检测速度大约是SSD300的两倍。
通过上述分析可知,Faster R-CNN在小容量数据集上难以训练到满意的效果,YOLOv3-tiny虽然检测速度最快,但其过低的召回率不适合用于火焰检测。SSD的两个模型的检测效果显著高于Faster R-CNN和YOLOv3-tiny。本文的SSD_MobileNet火焰检测模型不仅识别精度与SSD300几乎相当,而且在速度上具有明显的优势,更能满足火焰实时检测的要求。

表5 各模型速度对比
3 结语
本文用MobileNet替换经典SSD的VGG16网络,构建的SSD_MobileNet火焰区域检测模型,在针对红花和光照等类似火焰颜色干扰的环境下漏检和误检问题,添加干扰图像扩大数据集,并迁移纯火焰数据集上训练模型的参数初始化新模型训练。本文的SSD_MobileNet火焰区域检测模型应用深度可分离卷积,显著降低了网络参数,在极小的准确度损失情况下,有着显著的速度提升,方便移植到移动端,更适合应用到实时火焰检测领域中。
