基于MongoDB存储和分析辅助决策系统中的海量日志
2019-12-12宋瑜辉
宋瑜辉


摘 要:在辅助决策系统中,传统的关系型数据库已经难以满足对海量日志数据的管理,非关系型数据库的出现,为大规模数据存储挖掘问题提供了卓有成效的解决方案。文章着重分析非关系数据库MongoDB的特点和优势,通过存储和检索算法设计和实际的海量日志数据查询性能仿真,提出将MongoDB数据库应用于辅助决策系统中,有效提高了大规模日志数据存储和分析效率。
关键词:MongoDB;辅助决策;日志
中图分类号:TP311.13 文献标志码:A 文章编号:2095-2945(2019)33-0005-04
Abstract: In the auxiliary decision-making system, the traditional relational database has been difficult to meet the management of massive log data, the emergence of non-relational database, which provides a fruitful solution for the problem of large-scale data storage mining. This paper focuses on the characteristics and advantages of non-relational database MongoDB. Through the design of storage and retrieval algorithm and the simulation of massive log data query performance, this paper proposes to apply MongoDB database to auxiliary decision-making system. It effectively improves the efficiency of large-scale log data storage and analysis. Keywords: MongoDB; aided decision-making; log
引言
國家电网的经营辅助分析决策支持系统是展现财务管理信息,全面实施财务分析,科学支持财务相关决策,辅助生成管理报告的专业化、一体化、集成化管理平台。随着多年信息化建设和企业信息化的不断发展,辅助决策系统中积累了大量的日志信息,包括系统的运行情况日志、业务访问日志、账户管理日志、登录认证日志等等。
这些日志信息真实的记录了每个用户的访问行为,分析这些数据具有重要的意义:首先,通过收集和分析用户行为数据,可以及时掌握用户的需求变化,按照用户需求来优化和升级应用和服务,不断提高服务质量和满足用户不断变化需求的能力,持续改善用户体验,达到增加用户粘性,减少用户流失的目的。其次,通过对收集到的各种日志数据进行挖掘,能发现系统的潜在问题,通过日志分析,可以发现系统中软件、硬件和系统的问题,监控系统中发生的时间,检查错误发生的原因,帮助追踪软件发生的问题;因此,这些日志数据的存储和分析具有重要的意义。
传统解决日志存储和分析的方法主要是将日志数据存放到关系型数据库中,如Oracle数据库或MySQL数据库,关系型数据库对结构化数据的支持较好,能采用SQL标准语法进行数据的检索查询和分析;但是随着企业信息化的发展和业务的广泛应用,其产生的数据量呈指数增长,对于这些海量数据的存储和检索统计的任务也日益增多,如何快速存储、检索、统计这些海量日志数据,从中获取知识并产生商业价值,成为企业急需解决的问题。传统存储到关系型数据库的技术对于海量数据的处理已不能够满足要求,不但开发成本高、效率低、扩展性能差,最大的问题是难以满足业务发展需求,数据量一旦增大,这部分问题将成为瓶颈。然而,随着非关系型数据库的出现,基于分布式思想的MongoDB文档数据库能够很好的解决这个难题,且其具有以下优势:成本低、扩展性能好、数据安全可靠、支持非结构化数据存储和检索等。
因此,本文提出一种基于MongoDB数据存储和检索海量日志数据的技术,通过存储和检索算法设计和实际的海量日志数据查询性能仿真,展示了本文设计的海量日志数据库查询方法的高效性和准确性。
1 海量日志数据存储需求分析
国家电网的经营辅助分析决策支持系统中的日志主要包括以下内容:用户账户ID、事件类型、事件产生的时间、事件的内容、操作是否成功、请求的来源(如请求的IP地址),其他附属的实践属性信息等;由于在实际生产中客户的需求经常不同,因此不同类型日志常常要求增加一些额外的附属信息以便于日后分析,因此不同类型日志格式并不完全相同;因此传统的结构化日志存储并不适用这种非结构化日志数据的存储。
目前,经营辅助分析决策支持系统中的日志的主要需求如下:(1)不同类型的日志格式不完全相同;(2)能够存储海量上亿级的日志数据;数据能保存1至3年;(3)存储海量日志数据的写入性能要求高效;(4)能够通过多种条件组合检索日志信息;(5)具有日志分类汇总统计功能;
(6)当主机资源达到瓶颈时,能通过动态扩展主机方式增加系统的性能。
2 设计与实现
经营辅助分析决策支持系统中海量日志数据的管理和应用方向集中在两个领域。第一,在线处理数据操作,日志的并发写入操作,海量数据检索查询操作。第二,海量数据分析相关,针对海量日志数据的挖掘、复杂的分析计算; 分布式数据库则是针对海量大数据管理诞生的,强调满足大数据在实时高并发请求压力下的交互业务场景。由于分布式数据库的落地更简单,开发运维上更接近于传统数据管理系统。
2.1 MongoDB介绍
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。为应用提供可扩展的高性能数据存储解决方案。MongoDB是非关系数据库当中功能最丰富,最像关系数据库的。它可以存储比较复杂的数据类型。最大的特点是它支持的查询语言非常强大,还支持对数据建立索引。
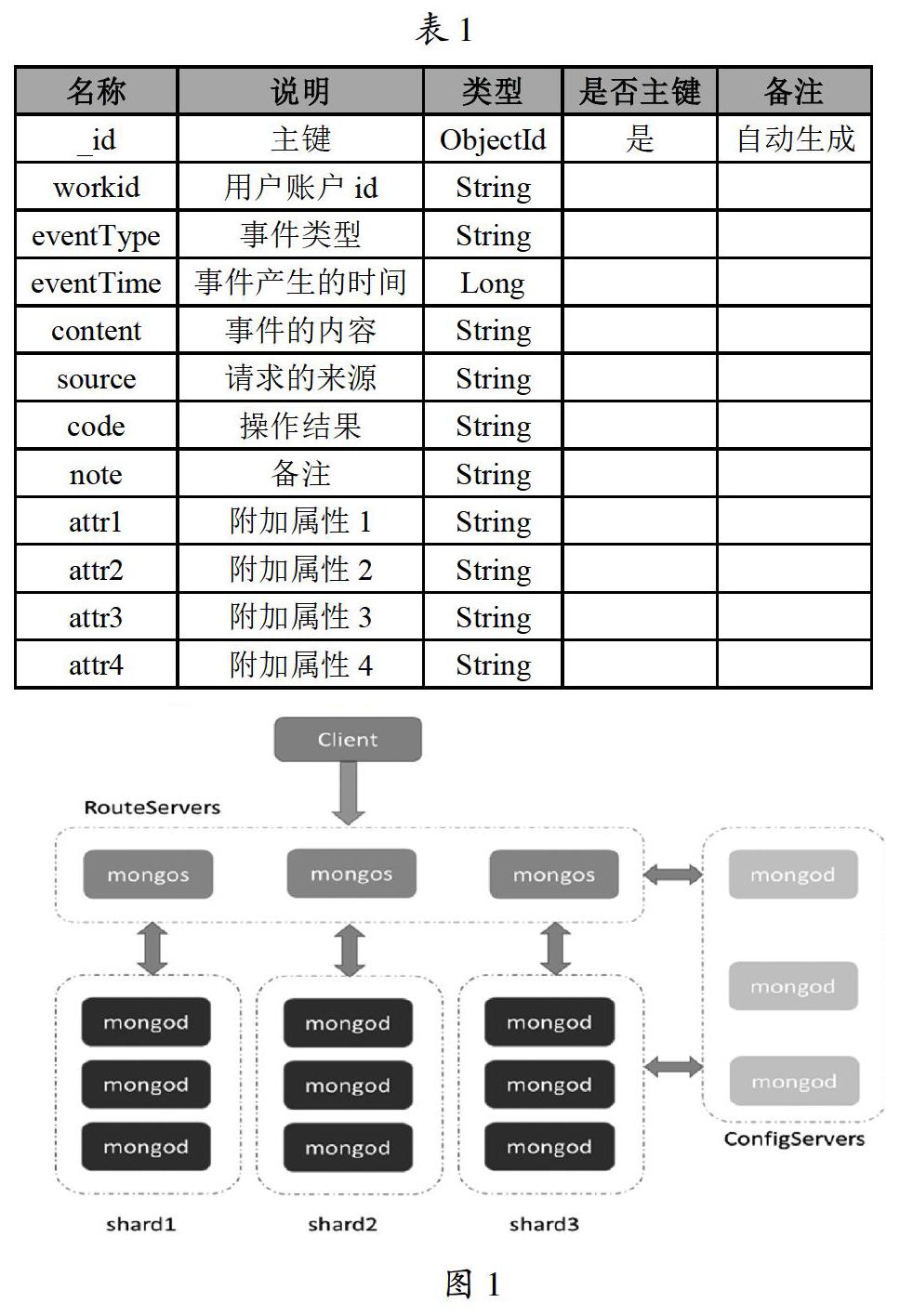
MongoDB集群包括以下几个组件:
(1)分片节点:用来存储数据,为了提供系统可用性和数据一致性,一个生产环境的分片集群,通常每个分片是一个副本集。
(2)查询路由:指客户端应用访问每个分片的路径。
(3)配置服务器:存储集群的元数据,这些数据包含了集群数据集到各分片的映射关系。查询路由就是通过这些元数据到特定的分片上执行指定的数据操作。
MongoDB总体架构如图1所示。
MongoDB功能如下:(1)面向集合的存储:适合存储对象及 JSON 形式的数据。(2)动态查询:MongoDB 支持丰富的查询表达式。查询指令使用 JSON 形式的标记,可轻易查询文档中内嵌的对象及数组。(3)完整的索引支持:包括文档内嵌对象及数组。MongoDB 的查询优化器会分析查询表达式,并生成一个高效的查询计划。(4)查询监视:MongoDB 包含一系列监视工具用于分析数据库操作的性能。(5)复制及自动故障转移:MongoDB 数据库支持服務器之间的数据复制,支持主-从模式及服务器之间的相互复制。复制的主要目标是提供冗余及自动故障转移。(6)高效的传统存储方式:支持二进制数据及大型对象(如照片或图片)。(7)自动分片以支持云级别的伸缩性:自动分片功能支持水平的数据库集群,可动态添加额外的机器。
MongoDB特点如下:(1)面向集合(Collenction-Orented)。(2)数据被分组存储在数据集中,被称为一个集合(Collenction)。每个集合在数据库中都有一个唯一的标识名,并且可以包含无限数目的文档。集合的概念类似关系型数据库(RDBMS)里的表(table),不同的是它不需要定义任何模式(schema)。(3)模式自由(schema-free)。(4)意味着对于存储在 MongoDB 数据库中的文件,不需提前定义它的任何结构定义。(5)文档型。(6)存储的数据是键-值对的集合,键是字符串,值可以是数据类型集合里的任意类型,包括数组和文档。这个数据格式称作“BSON”即“Binary Serialized dOcument Notation.”
2.2 日志表设计
2.2.1 表模型设计
表名t_log,由于不同类型的日志格式不同,以下是公共部分的定义:
2.2.2 表分片设计
由于海量日志需要存储较长时间,因此需要支持数据分片功能,未来当集群主机性能到达瓶颈时可以轻松的增加主机节点方式扩展,因此需要对日志表进行数据分片。
一般来说,完美的分片键将会有下列的特征:(1)所有的插入、更新以及删除将会均匀分发到集群中的所有分片中。(2)所有的查询将会在集群中的所有分片中平均地分发。(3)所有的操作将会只面向相关的分片:更新或者删除操作将不会发送到一个没有存储被修改数据的分片上。(4)一个查询将不会被送到没有存储被查询数据的分片上。
好的分片键的五个准则如下:(1)分片键基数。(2)写分布。(3)读分布。(4)定向读。(5)读本地性。分片键的选择原则如下:(1)不要选时间日期,选尽可能使数据分散的字段。(2)分析下最常见的查询,防止使用单一自增的字段,避免新增数据始终路由到一个分片,造成写热点。(3)如果有范围查询的,最好包含一个对应的业务字段,避免查询的时候数据太分散。
综上所述,分片的语句定义如下:对数据库启用分片:sh.enableSharding(“fzjcdb”);日志表分片键建立主键:db.t_log.createIndex({workid: 1, _id:1})日志表建立分片sh.shardCollection(“fzjcdb.t_log”, {workid: 1, _id:1} )
2.3 日志表分析
由于业务要求对日志表有统计分析的需求,因此需要MongoDB中的日志表也能支持按小时,按天,按月的统计分析。
针对统计分析,MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。类似关系型数据库中的分组求和函数。
常见的MongoDB的聚合操作和MySQL的查询对比如表2。
3 系统测试结果分析
测试实验分10线程,100线程,200线程并发测试,分别监控各主机CPU,IO,网络变化。
4 结束语
本文主要提出了一种基于MongoDB存储和分析辅助决策系统中的海量日志的高效计算和分析方法。通过对海量日志数据进行数据分片设计,使得海量日志的存储具有高扩展性,高性能等优点的同时也具有一定的统计分析查询支持的功能,通过压力测试验证,这种存储海量日志的方式较好,满足高性能写入和查询的需求。
参考文献:
[1]李纪伟,段中帅,王顺晔.非结构化数据库MongoDB的数据存储[J].电脑知识与技术,2018,14(27):7-9.
[2]张路路.基于MongoDB的大数据存储方法研究与应用[D].成都理工大学,2015.
[3]冯国瑞,王亮.基于大数据和云计算的电网财务系统决策研究[J].通信电源技术,2017,34(01):113-115.
[4]王昌照.基于大数据的“三统一”配电网规划辅助决策系统[J].供用电,2017,34(01):32-37+23.
[5]毋毅,赵康.基于大数据平台的电网全业务数据分析域研究[J].电脑知识与技术,2016,12(34):15-17.
