基于Sentinel-2A影像的县域冬小麦种植面积遥感监测
2019-06-01冯美臣杨武德张美俊
王 蓉,冯美臣,杨武德,张美俊
(1.山西农业大学资源环境学院,山西 太谷 030801;2.山西农业大学农学院,山西 太谷 030801)
遥感是获取作物播种信息的关键技术,在农情监测领域具有对地表信息获取的覆盖面广、信息量大、周期短、受地面条件限制少、调查成本相对较低等明显优势[1]。在农作物遥感估产中,农作物种植面积的遥感估算是农作物产量预测的基础和主要内容;准确而及时的农作物类型及其空间分布更新信息是优化种植结构的基本依据,为制定合理、有效的粮食宏观调控措施、保证国家粮食安全提供科学支撑[2]。
农作物遥感识别分类与面积提取的研究主要考虑遥感数据源、特征变量和分类算法[3]3 个方面。到目前为止,适合开展大范围高空间分辨率农作物种植区域识别与提取的遥感数据源主要有GF-1,Sentinel-2 和Landsat-8。田海峰等[4]使用多景GF-1全色多光谱(Pan Multiple Spectral,PMS)影像,对河南省滑县冬小麦种植分布信息进行了提取研究,并取得良好效果。BELGIU 等[5]采用Sentinel-2 多光谱传感器(Multi Spectral Sensor,MSI)数据,对时间加权动态时间规整(Time-Weighted Dynamic Time Warping,TWDTW)算法在农作物分类的应用效果进行研究。ZHANG 等[6]提出利用 Landsat-8 OLI 时间序列和物候参数的融合数据,在多云雨地区提取水稻种植面积。与MODIS 数据相比,GF-1,Sentinel-2 和Landsat-8 等影像数据具有高空间分辨率和高时间分辨率的双重优势,并在一定程度上减少了混合像元对作物分类结果的干扰,提高了农作物分类制图精度与效率。
遥感光谱数据及其衍生的各种指数信息、纹理特征、时间序列阈值和变化信息常被国内外学者用作研究农作物遥感分类的特征变量。其中,光谱及其衍生指数的信息相对容易获得也是最常用的[3]。SONOBE 等[7]在研究Sentinel-2A 多光谱传感器数据计算植被指数的潜力中发现,植被指数在确定特定作物类型方面贡献最大。史飞飞等[8]采用多源数据集进行了农作物分类信息提取研究,发现在NDVI 时间序列数据中融入高光谱数据可以提高分类精度。纹理信息作为区分特征,对高分辨率(米级或亚米级以下)影像数据的分类效果较好[9]。CHUANG等[10]将主成分、灰度共生矩阵纹理信息作为分类器的输入变量,解译出台湾中部地区茶叶种植区域。
另外,选择不同的算法对农作物面积的提取也有着较大的影响。随机森林(Random Forest,RF)方法由于2 个随机性(随机且有放回地抽样训练集、随机地从样本特征维度中选取特征子集)的引入,在分类中不易陷入过拟合,具有分类精度高、泛化能力强、数据挖掘能力优异、抗噪声能力良好等优点,对处理样本数据分布不平衡等方面表现优良,成为当前机器学习领域的研究热点[2]。GAO 等[11]研究探讨了新型高光谱快照马赛克相机在杂草和玉米分类方面的潜力,发现RF 模型表现总体上优于K-最近邻(K-Nearest Neighbor,K-NN)模型。
以上研究都不同程度提高了作物识别精度,但综合数字高程模型、遥感影像数据及其衍生的植被指数信息、纹理特征,利用单时相遥感影像进行雨养区冬小麦与灌溉区冬小麦空间分布信息提取方面的研究少有报道。
笔者在前人研究的基础上,利用冬小麦生长关键期的Sentinel-2A 遥感影像数据,选择红边归一化植被指数、主成分分量与几何纹理特征作为特征变量,研究基于随机森林算法的冬小麦种植面积提取方法,并结合DEM 数据实现雨养区和灌溉区冬小麦的分类,以期为不同灌溉类型冬小麦长势遥感监测以及产量估测提供科学依据。
1 材料和方法
1.1 研究区概况
研究区位于山西省运城市北部的闻喜县,总面积 1 167.1 km2,地理坐标为 110°59′33″~111°37′29″E,35°9′38″~35°34′11″N。闻喜县地处运城盆地与临汾盆地的交界处,地形多样,河谷、塬地、丘陵、山地共存。气候属暖温带大陆性季风气候,昼夜温差大,四季分明。农作物以冬小麦种植为主,属南部冬麦区。
1.2 数据来源
1.2.1 Sentinel-2A 影像数据 Sentinel-2A 的多光谱成像仪含有13 个通道,主要应用于地表覆盖变化监测、资源调查、近海域污染检测、灾害监测等,波段信息如表1所示。结合运城地区冬小麦与其他作物主要生育期,为有效提取冬小麦种植面积[12],选择使用2018年3月27日获取的上层大气反射的L1C 级别的Sentinel-2A 数据。
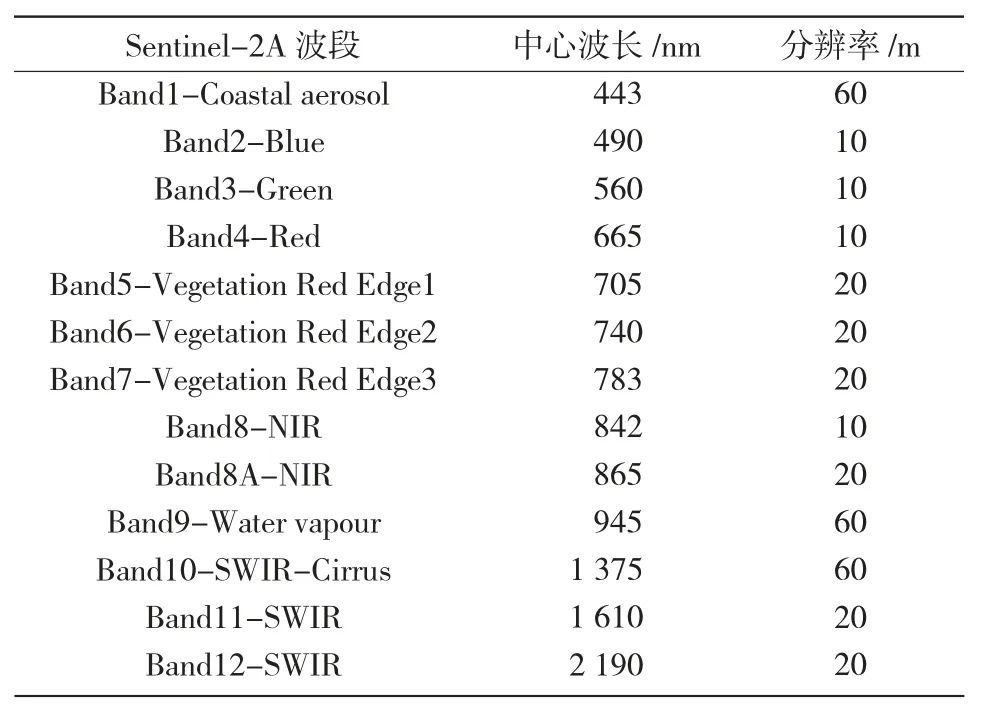
表1 Sentinel-2A 波段信息
1.2.2 地面调查 为获取山西省运城市闻喜县冬小麦的分布情况,2018年3月进行了实地调查。野外调查时采用手持GPS 获取冬小麦的经纬度信息,调查路线覆盖闻喜县绝大部分乡镇(石门乡除外)。在野外调查GPS 数据基础上,结合目视解译方法,确定训练样本数据集和验证样本数据集。
1.3 研究方法
1.3.1 数据预处理 数据下载自欧洲航空局的数据共享网站(http://scihub.copernicus.du/s2/#/home)。原始数据已进行过几何校正处理,由于处理前各波段分辨率不同,因此,使用三次卷积内插法对各波段(不包括 Band1,Band8,Band9,Band10)进行重采样,经处理后的各波段分辨率为20 m。
1.3.2 随机森林分类算法 其通过对数据及特征变量进行随机重采样,构建多个CART 决策树(不剪枝),最终采用多决策树投票的方式确定数据的类别归属。它能够处理具有高维特征的输入样本,又对过度拟合不敏感[13],在生成的过程中就可以对误差建立一个无偏估计。因而,对于遥感影像农作物面积提取具有很好的抗噪性能,在农田制图研究方面取得了有效的分类结果[14-15]。
1.3.3 特征变量的选择
1.3.3.1 主成分分析 主成分分析(Principal component analysis,PCA)又称 K-L 变换,利用波段间的相互关系,在尽可能不丢失信息的条件下,用几个综合性波段代表多波段的原图像,使处理的数据量减少。
1.3.3.2 植被指数 本研究选择窄带绿度植被指数(Narrowband greenness)中的红边归一化植被指数(Red Edge Normalized Difference Vegetation Index,RENDVI)[16]。其计算公式如下。
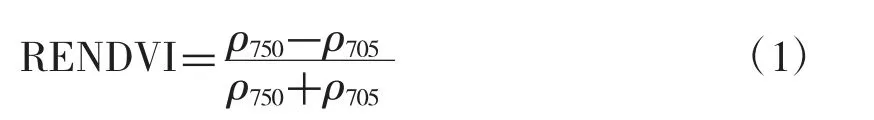
式中,ρ705和 ρ750分别对应表2中的 Band5 和Band6 的反射率,RENDVI 值的范围是 -1~1,一般绿色植被区的范围是0.2~0.9。
1.3.3.3 纹理特征 纹理是指图像色调作为等级函数在空间上的变化[17]。由HARALICK 提出的灰度共生矩阵(GLCM)方法是公认的纹理特征提取的有效方法,具有较强的适应能力和鲁棒性[18]。该方法首先计算图像的GLCM,然后由GLCM 导出描述纹理的二阶统计特征[19]。在合适的空间分辨率遥感影像中,农作物区别于其他地物具有更为鲜明的空间纹理特征[20]。因此,加入纹理特征,有利于冬小麦分布区域的准确提取。
1.3.4 基于DEM 的地形分析 数字地面模型(Digiatl Terrain Model,DTM)中地形属性为高程时称为数字高程模型(Digital Elveatoin Model,DEM)。数字高程模型是指描述地球表面形态多种信息空间分布的有序数值阵列。根据文献[21],本研究采用三次卷积方法对研究区DEM 数据进行重新采样,以减少精度损失。
1.3.5 精度评价方法 基于地面样点数据验证是精度验证的主要手段之一,也是说明分类结果准确程度的指标之一。本研究以Kappa 系数、总体精度、制图精度、用户精度等4 项指标表述基于地面样点数据精度验证结果[22]。此外,由于区域冬小麦提取面积在产量估产中具有重要作用,因此,同样需要评价冬小麦面积提取值与实际冬小麦面积值之间的比值。
2 结果与分析
2.1 特征变量的选择
2.1.1 波段数据的统计特征分析 从表2可以看出,B8A 波段标准差(1 247.058 207)为所有波段中最大,其次是B11 波段、B7 波段,标准差分别为1 235.138 932 和1 155.616 279。标准差最大,说明该波段内地物的亮度取值距均值的离散程度最大,即地物间的差异可能表现最明显,信息量最丰富。因此,B8A 波段包含的信息量最丰富,同时也进一步表明原始影像的B8A 波段在植被类型分类中具有显著作用。
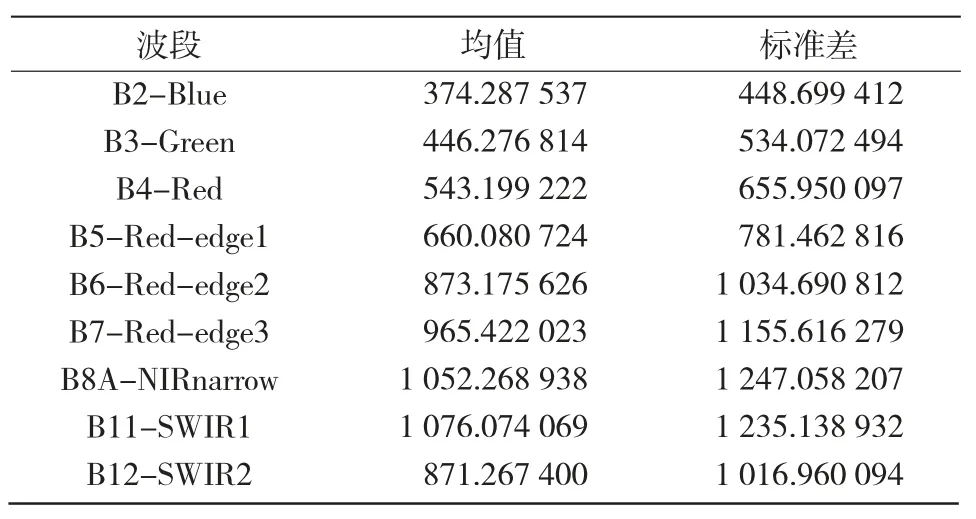
表2 原始影像波段基本信息量
2.1.2 主成分分析 从表3可以看出,第1 主成分分量(PC1)的信息占9 个波段总信息量的97.3%,第2 主成分占总信息量的2.23%,第3 主成分占总信息量的0.38%,前3 个主成分共占据了99.91%的信息量,其他成分对于影像信息只是噪音,所以,前3 个成分可以代表原始影像的数据信息。在构成第1 主成分的向量中,B8A 最高(为 0.44),占各波段特征向量和的15.3%。这说明第1 主成分中,B8A波段的贡献最大,其次是B11(14.6%) 和B7(14.2%),说明在原始影像的9 个波段中,B8A 波段包含的地物信息量最丰富。
2.1.3 波段间相关性分析 从表4可以看出,B8A与B7 波段间相关系数最高(r=0.999 4),其次是与B6 波段(r=0.997 4) 和 B5 波段(r=0.959 5),与B11 波段的相关系数为0.958 2。说明B8A 波段与这些波段数据彼此重叠较多。
2.1.4 特征变量选择结果 选用B8A 波段作为专门提取纹理特征的波段,经多次试验对比分析,选用3 多3 大小的移动窗口,利用灰度共生矩阵计算该波段的8 种纹理特征:均值、方差、同质性、对比度、差异性、熵(Entropy)、二阶矩、相关性。
综上所述,本研究提取3 类特征波段:红边归一化植被指数(RENDVI)、主成分变换前3 个分量以及原始影像B8A 波段的纹理特征,共计12 个变量。各变量具体信息列于表5。
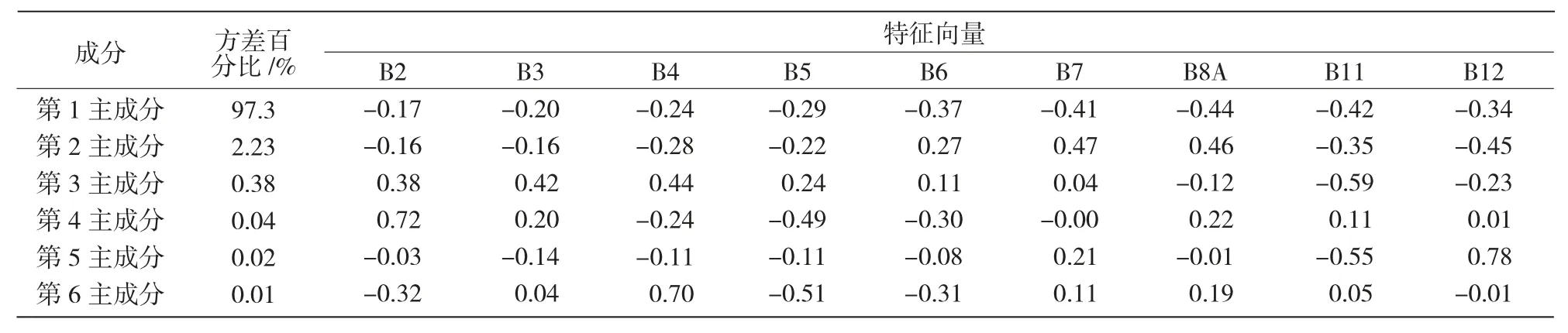
表3 研究区Sentinel-2A 各波段主成分分析结果
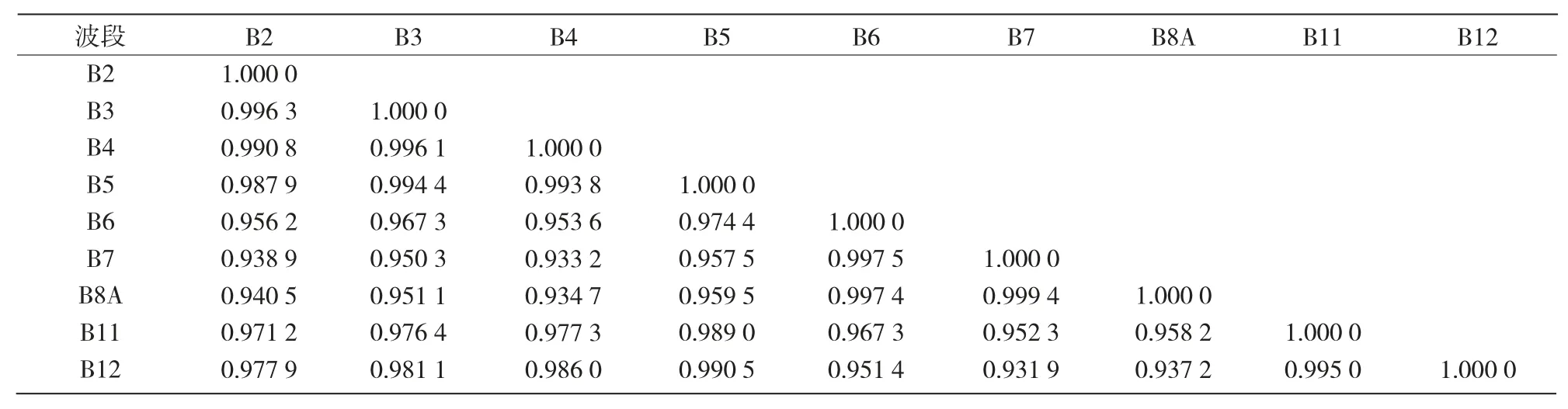
表4 研究区Sentinel-2A 各波段数据相关分析结果

表5 用于分类的特征变量信息
2.2 基于特征波段与随机森林的冬小麦种植面积提取结果
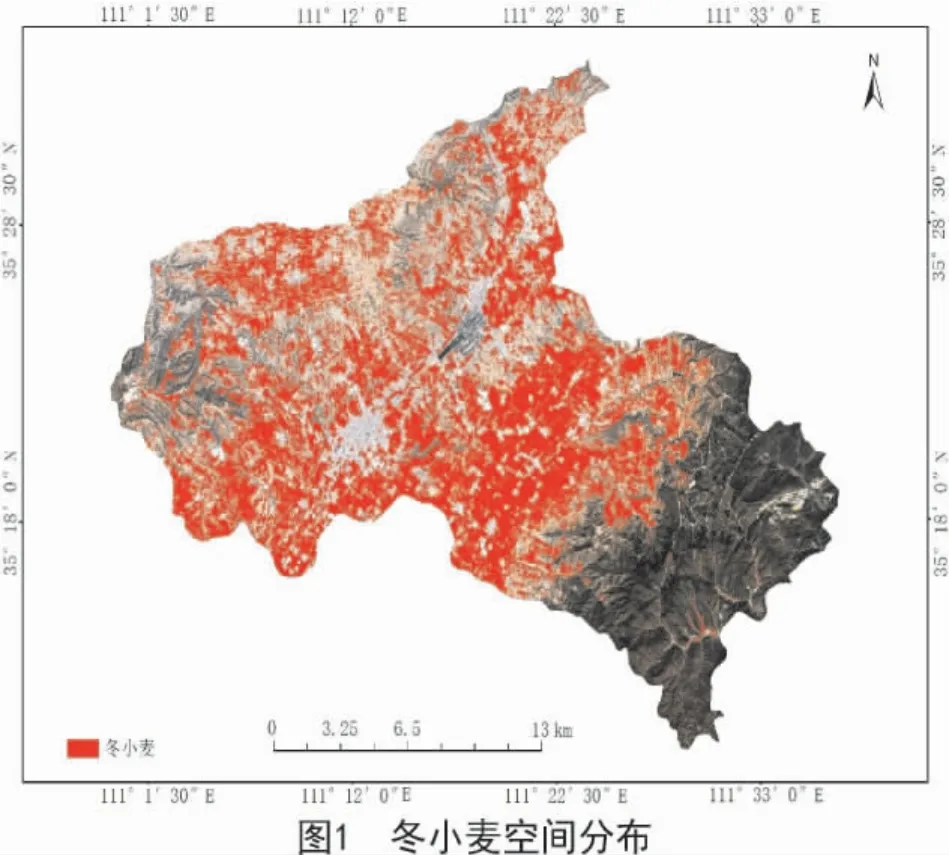
将 2018年3月27日的 Sentinel-2A 影像输入到随机森林分类器[23]中,将前 3 个主成分(PC1,PC2,PC3)、红边归一化植被指数(RENDVI)和 B8A 波段纹理特征组合进行分类提取,获得闻喜县冬小麦种植面积空间分布(图1)。由图1可知,冬小麦主要分布在中部地区,北部有少量种植分布,原因为闻喜县地处运城盆地与临汾盆地的交界夹槽处,三面环山,地势西北、东南高,中间低,冬小麦适宜生长在地形平坦地区,林地等非冬小麦植被主要分布在东南山地;另外,由于丘陵塬地遍布县境,冬小麦在西北部分布较为零散,这与实地调查情况相符。
2.2.1 特征波段对分类精度的影响 由表6可知,未加入特征波段,采用原始影像波段作为随机森林分类器的输入数据,分类结果的总体精度为94.72%,Kappa 系数为0.92;采用3 项特征波段后,分类结果的总体精度增加了3.39 百分点,Kappa 系数增加了0.05,这与分类结果(图1)表现一致,说明综合主成分分析、红边归一化植被指数以及纹理特征后能提高遥感影像分类总体精度,同时冬小麦的分类用户精度由87.91%提升到92.22%,说明引入特征波段有助于提高冬小麦种植面积提取的可信度。
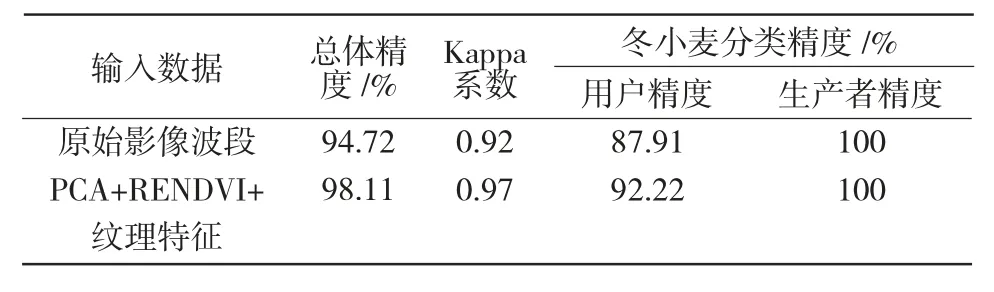
表6 随机森林算法条件下原始影像波段与特征波段分类精度对比
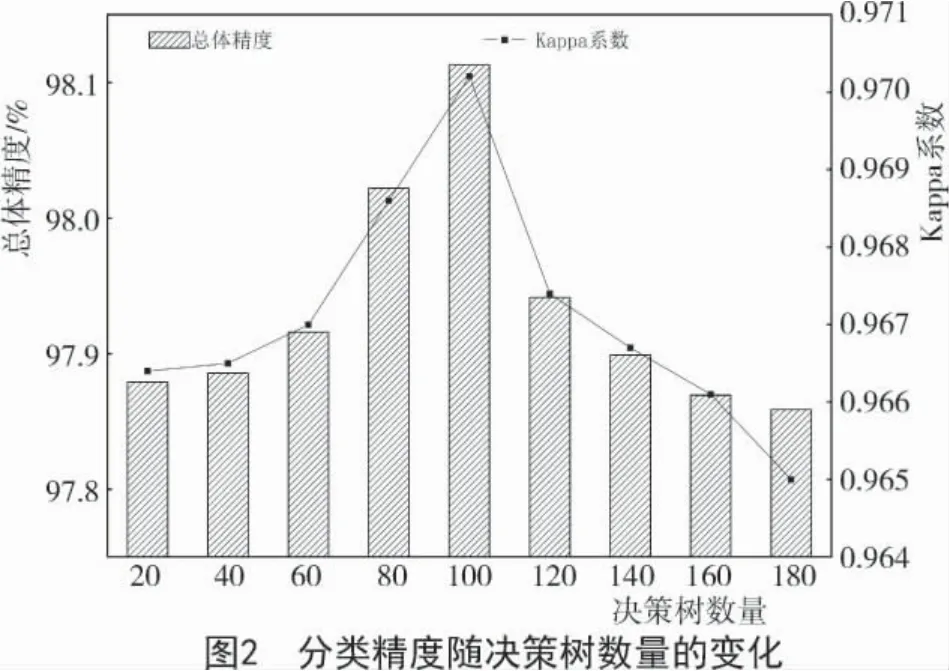
2.2.2 决策树和特征变量的数量对精度的影响考虑到在随机森林分类过程中,决策树和特征变量的数量可能影响最终分类的精度,需研究决策树和特征变量的数量对分类精度的影响。特征变量的数量对分类精度的影响甚微可忽略不计,即分类精度对特征变量数量的设置并不敏感[24]。因此,本研究仅分析决策树的数量对分类精度的影响。由图2可知,当保持特征变量数量不变时,将决策树的数量分别设定为20,40,60,80,100,120,140,160,180进行试验,得到的分类精度随决策树数量变化而改变。由图2可知,在20~100 的范围内,当决策树数量增加,分类精度随之增加,并且在决策树数量为100 时分类精度达到最大值;当决策树数量超过100 时,分类精度随决策树数量的增加而出现降低趋势,且随着决策树数量增加,模型训练时间也在增加。
2.3 不同分类方法分类结果对比
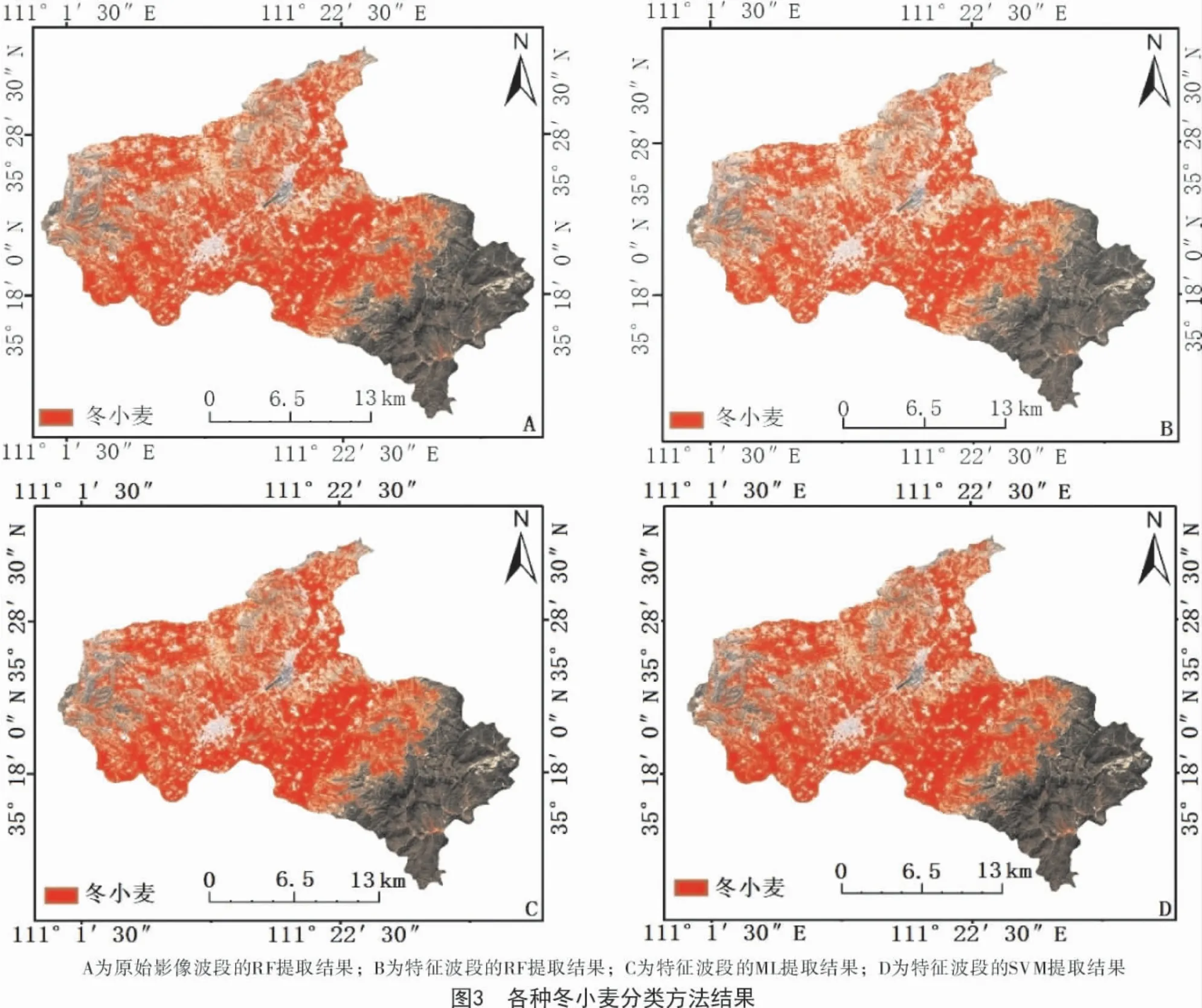
为进一步验证本研究所采用的随机森林分类方法的有效性,利用实地调查点信息将随机森林算法分类结果与支持向量机算法、最大似然算法进行对比分析(图3)。
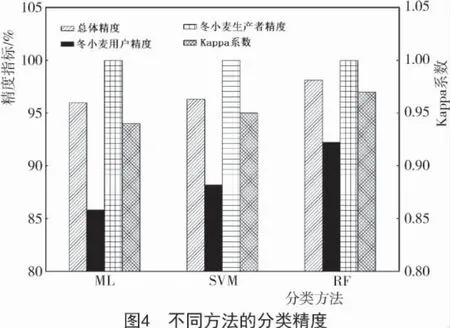
从图3可以看出,随机森林算法(RF)、最大似然算法(ML)和支持向量机算法(SVM)分类结果在空间分布上大致趋于一致,但随机森林算法分出的冬小麦地块较为完整,且能分出绝大部分冬小麦种植区域,其分类总体精度和Kappa 系数均最高,分别为98.11%和0.97(图4),其次是支持向量机算法(总体精度和Kappa 系数分别为96.3%和0.95),最大似然算法最差。这是由于最大似然算法分类器基于统计算法,计算给定像元属于某一训练样本的似然度,根据似然度将像元归并到似然度最大的一类当中,而在3月下旬闻喜县冬小麦与蔬菜的光谱特征容易混淆,增大了利用似然度划分地物像元的难度。支持向量机分类是一种建立在统计学习理论基础上的机器学习方法,可以自动寻找那些对分类有较大区分能力的支持向量,由此构造出分类器,可以将类与类之间的间隔最大化,因而较最大似然法有更高的分类准确率,但是蔬菜与冬小麦的混淆光谱仍对其有一定的影响。而随机森林算法通过对数据及特征变量进行随机重采样,采用多决策树投票的方式确定数据的类别归属,在生成过程中就可以对误差进行一个无偏估计,因此,其可信度最高,为92.22%。黄健熙等[25]使用MODIS 数据对黑龙江省主要农作物的种植面积提取进行研究,发现SVM算法分类精度优于RF,ML 算法的分类精度,这可能是由于MODIS 数据空间分辨率低,混合像元效应明显,导致每棵决策树的分类能力降低,而森林的分类效果(错误率)与每棵树的分类能力有关;本研究中Sentinel-2A 数据空间分辨率明显优于MODIS 数据,故RF 算法分类效果最佳。
2.4 雨养区与灌溉区冬小麦分类结果
由于不同灌溉条件下冬小麦有着不同的生育进程,因此,在冬小麦长势监测和估产的研究中应该进行雨养区冬小麦与灌溉区冬小麦分类,以提高监测精度。在晋南地区冬小麦种植区域中,灌溉区冬小麦一般分布在海拔600 m 以下,坡度小于15°的平川区域,此区域有利于土壤水分涵养;反之,则为雨养区冬小麦分布区[26]。
从图5和表7可以看出,灌溉区冬小麦主要分布在礼元镇、东镇镇、侯村乡、桐城镇、郭家庄镇、裴社乡、河底镇以及神柏乡东南部等各乡镇沿涑水河流域的平川区域,面积为12 773.33 hm2,占总面积的34.92%;而雨养区冬小麦主要分布在闻喜县西北部和东南部各乡镇丘陵垣台区域,在西北部分布较为零散,在后宫乡西部分布较为集中,面积为23 806.66 hm2,占闻喜县冬小麦总面积的65.08%。同山西省统计年鉴数据(38 800 hm2)进行对比分析,闻喜县冬小麦总提取面积的精度可以达到94.28%,雨养区为93.48%,灌溉区为95.8%。本研究得出的雨养区和灌溉区冬小麦提取精度明显优于文献[26]的研究结果(86.16%和86.15%),说明Sentinel-2A数据可以明显降低混合像元效应,更适合区域冬小麦种植面积提取研究。
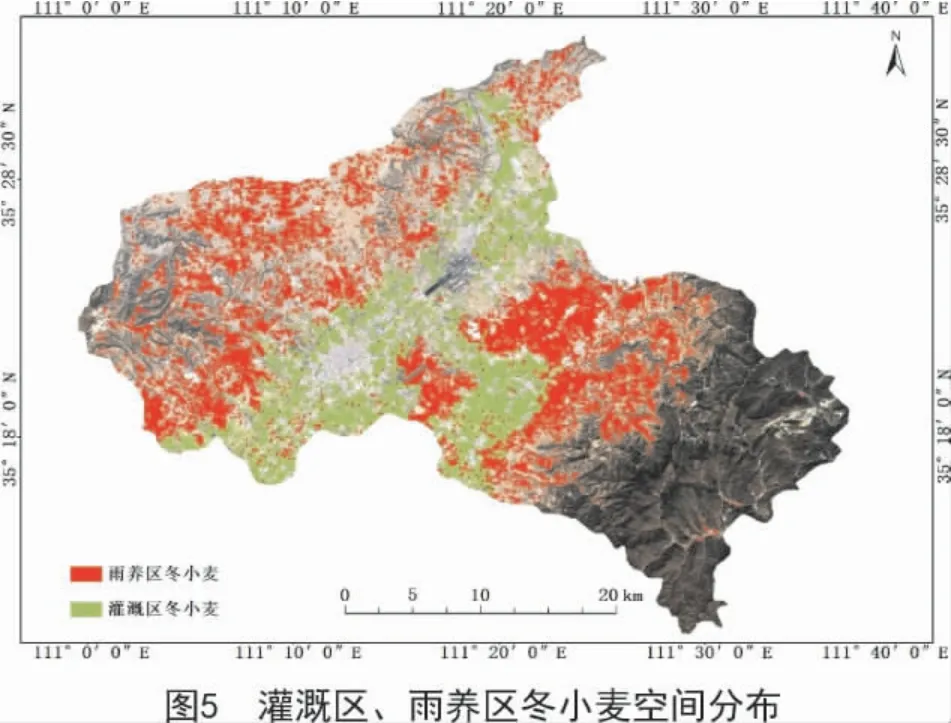
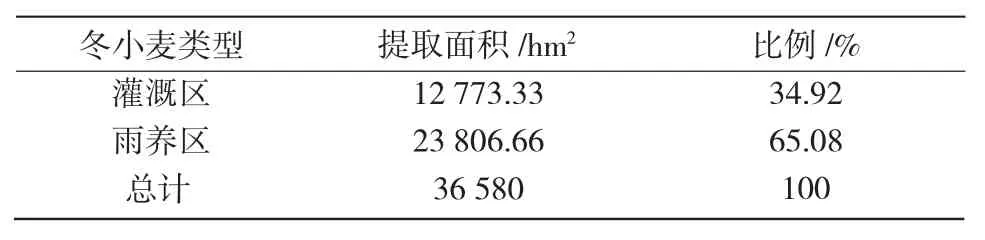
表7 闻喜县雨养区、灌溉区冬小麦分类统计结果
3 结论
本研究以2018年冬小麦拔节期内的Sentinel-2A 数据为数据源,以山西省运城市闻喜县为研究区,通过利用遥感影像主成分变换、波段特征提取技术,将主成分信息、波段空间纹理特征、红边归一化植被指数以及大量调查样本点输入到随机森林分类器中进行决策树构建,并基于数字高程模型提取的坡度、高程信息,提取了2018年闻喜县冬小麦的灌溉区与雨养区的空间分布信息。结果表明,Sentinel-2A 遥感数据适合作为县域尺度冬小麦监测的数据源。Sentinel-2A 数据重访周期为10 d,在农作物物候时期内更容易获得质量较好地遥感影像,并且该数据影像空间分辨率较高,获取成本低,能够满足大面积冬小麦监测的要求。采用随机森林分类器对闻喜县地物进行识别与分类,其分类总体精度达到98.11%,Kappa 系数达到0.97,优于同等条件下采用支持向量机法与最大似然算法。主成分分析、纹理特征和RENDVI 的引入可以提高单时相遥感影像对县域冬小麦分类识别能力。2018年闻喜县冬小麦遥感监测面积为36 580 hm2,提取精度达到94.28%。其中,雨养区冬小麦遥感监测面积为23 806.66 hm2,提取精度达到93.48%,占当年总面积的65.08%;灌溉区冬小麦遥感监测面积为12 773.33 hm2,提取精度为95.8%,占当年总面积的34.92%。
