考虑翻箱作业的铁路集装箱中心站起重机调度
2019-04-17郭鹏何迅许素瑕
郭鹏,何迅,许素瑕
(西南交通大学机械工程学院,四川成都,610031)
随着国家“一带一路”倡议的全面展开,铁路货运将面临更为广阔的市场挑战,如何全面提高其市场竞争力已成为当前的难题之一。集装箱铁路运输能够有效缩减转运时间和成本,但我国铁路集装箱运量仅占铁路货运总量的2%~3%,远远低于发达国家(30%~40%)[1]。如此大的差距表明我国集装箱铁路运输存在巨大的潜力和发展空间。为了提高集装箱铁路运输能力,国家“十一五”规划提出建设18个铁路集装箱中心站(以下简称中心站),以实现区域集装箱铁路运输与其他运输方式的无缝衔接。不同集装箱班列、集装箱卡车和堆场之间的装卸及转运作业均由轨道式集装箱起重机完成,对其开展调度优化是站场实现高效转运作业的有效途径。起重机调度问题作为最为关键的站场决策问题之一,现已受到广泛的关注[2]。为了确保同一轨道上各个起重机不可交叉且满足安全距离约束,BOYSEN 等[3−4]提出利用动态规划划分起重机的堆场作业区域。采用集装箱整理系统能够大幅度简化铁路堆场的转运作业,在此基础上研究起重机与集装箱转运卡车的集成调度更加符合实际[5]。GUO 等[6−7]在借鉴集装箱码头岸桥调度问题干涉约束处理技巧的基础上,采用人工蜂群算法对铁路集装箱起重机调度问题进行求解,并从提升外部卡车服务水平的角度构建了更全面的调度优化模型。王力等[8−9]认为集装箱班列卸箱作业和装箱作业过程相同,针对卸箱作业过程建立了中心站起重机调度优化模型,设计了混合粒子群求解算法;针对堆场混堆优化问题,以两阶段优化模型来平衡堆场各箱区进站箱和出站箱的数量并减少堆存所产生的压箱数。上述国内外研究主要侧重于起重机调度优化研究,没有考虑翻箱活动对其作业调度的影响。受堆场空间限制,集装箱必须堆叠放置,使得装卸过程中翻箱作业无法避免。集装箱翻箱作业在码头已得到较为全面的研究[10],模拟退火[11]、束搜索[12]等方法均已用于翻箱操作调度,但与起重机进行集成调度的研究仍较少。目标箱不及时搬运会造成后期搬运时装卸时间的延长,此时1次或多次翻箱作业会被执行,即集装箱装载所需处理时间取决于其开始时间。这一现象与工时阶梯恶化现象相符,即任务开始前的任何延迟都可能导致实际处理时间增加。考虑工时阶梯恶化的调度问题在单机和并行机调度中已有一定研究[13−15],其在钢铁生产、设备维护及医疗救治等过程中具有应用潜力。本文作者采用阶梯恶化函数来描述考虑翻箱作业的集装箱装载作业过程,以此为基础开展铁路集装箱起重机调度优化研究,以期提升站场的转运作业效率。
1 问题描述与建模
1.1 问题描述
考虑翻箱作业的轨道式集装箱起重机调度问题(gantry crane scheduling problem with rehandling operations,GCSPRO),旨在以最短的时间处理在不同集装箱班列、卡车和堆场之间的转运任务或从集装箱班列和转运集卡上装载/卸载任务,用集合Ω={1,…,n}表示。中心站堆场分割成l个操作位置,且从左向右按升序排列。对于任务i(i∈Ω),给定操作位置li来定义起重机对其进行处理的停靠位置;任务i有对应的基本装卸作业时间ai和给定的恶化临界阈值hi;任务i的实际作业时间pi受实际开始搬运时刻si影响,如果si≤hi,那么实际作业时间pi=ai,否则受场地空间限制会有其他箱堆垛到该箱上面,发生1次或多次的翻箱作业(时间为bi),从而实际作业时间pi=ai+bi,若不发生翻箱则其惩罚时间bi为0 s。
所有作业任务交由多台同轨且处理速度相同的起重机进行处理,用集合Q={1,2,…,m}表示。所有起重机沿堆场水平方向左右移动,且操作位置自左向右按升序编号。由于共享走行轨道,起重机相互之间不可交叉。起重机k(k∈Q)最早可用时刻为,初始位置为,起重机单位走行时间为t0。起重机k从其初始位置移动到任务j的位置lj所需走行时间。对于任务i和j,从操作位置li移动到操作位置lj起重机所需的走行时间tij=。
在建模过程中应考虑以下约束。
1)优先关系。对于满载的集装箱班列,到达堆场后须将已有的集装箱卸载,随后才能在同一位置进行装载,即同一操作位置上的2个任务不能同时处理且存在优先关系。为了保证此类优先关系,对于位于同一位置的任务对(i,j)用集合Φ来表示即(i,j)∈Φ,且要求任务i须在任务j开工之前完成。一旦待装卸的作业任务给定后,集合Φ可根据任务的属性提前确定。
2)干涉约束。为保证整个作业过程的安全,相邻起重机之间必须保证一定的安全距离,从而使得部分任务不能同时处理。在此用集合Ψ表示不能同时处理的任务对,即对于任务(i,j)∈Ψ,要么在任务j开工前任务i已完成,要么任务i只能开始于任务j完工之后。起重机因安装在同一走行轨道上相互之间也不可交叉作业。以上不可交叉作业和安全距离约束统称为干涉约束。为了避免发生干涉约束,当任务i与j分别指派给编号为u和w的起重机(u,w∈Q)进行处理时,引入最小起重机走行时间跨度来间隔起重机处理任务的完工与开工时刻[16]。若δ为相邻起重机之间的最小安全距离,则起重机u和起重机w操作位置间的最小距离δuw=(δ+1)×|u-w|。由下式计算得出:
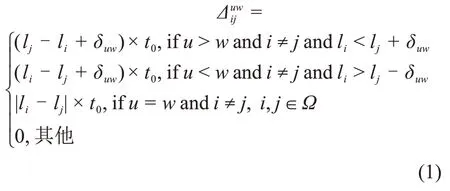
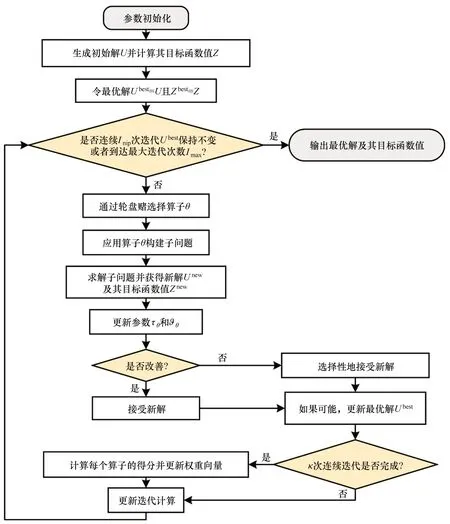
由式(1)可知:当u>w时,若处理任务i的起重机u位于处理任务j的起重机w的安全距离内,则任务i和j不能同时处理,为避免干涉须插入最小走行时间跨度(lj-li+δuw)×t0;相反,当u 3)边界限制。由于安全距离约束,起重机可能会被挤出轨道边界。为确保边界限制,需要指定部分操作位置交由某个特定起重机访问[17−18]。假设最低操作位置为1,最高操作位置为l。若起重机k(k∈Q)处理任务j,为保证起重机安全距离,则有: 根据式(2)和式(3),起重机k(k∈Q)能到达的最低和最高的位置分别被定义为。 针对翻箱作业的铁路集装箱起重机调度优化问题,以最小化最大完工时间Cmax为目标,构建混合整数规划(MIP)模型,模型中各参数定义见表1。 目标函数: 约束条件: 表1 MIP模型中的参数Table 1 Parameters for MIP model 模型中,目标函数式(4)使最大完工时间最小化;式(5)定义了Cmax属性为同轨道起重机处理各个集装箱装卸作业任务完工时间的最大值,各个任务的完工时间由决策变量xik,yij和zi决定,从而使得最大完工时间Cmax与问题决策变量构建了联系;式(6)计算了每个任务的完工时间;式(7)给出了实际作业时间pi的取值范围;式(8)定义了决策变量zi作用下任务的处理时间;式(9)保证当任务i的开工时刻不晚于任务i的恶化阈值hi时,变量zi=1;式(10)保证每个任务只能被1 台起重机处理;式(11)给出起重机处理首个任务的最小完工时间;式(12)和式(13)确定每个任务关于变量yij的开工时刻;属于集合Φ的任务间优先关系通过式(14)限定;式(15)确保当任务对(i,j)∈Ψ时,任务i和任务j不能同时处理;不等式(16)~(18)为起重机间的干涉约束,式(16)保证每1对来自集合Θ的任务i和任务j被分配给起重机u和w时不能同时被处理;xiu=1表示任务i∈Ω交由起重机u处理,而xjw=1表示任务j∈Ω交由起重机w处理,如果以上分配情况同时出现,则任务i和任务j不能被同时处理,也就意味着变量yij和yji不能同时等于1;式(17)中考虑当yij=1的情况,而yji=1的情况则在式(18)中处理;式(19)和式(20)确保如果操作位置li不在起重机k的可操作范围内,则任务i不能交由该起重机进行处理,即xik=0;最后,式(21)定义了决策变量。 上述问题若不引入翻箱操作则与岸桥起重机调度问题[19]相似,因此,所提出的GCSPRO 是NP-hard的,依靠精确的算法难以在合适的计算时间内获得问题最优解。本文提出将自适应大规模邻域搜索(adaptive large neighborhood search,ALNS)与数学模型相结合构建启发式求解策略。该算法框架与固定及再优化(fix and optimize,F&O)算法[20]类似,在解决复杂组合问题上已得到成功应用[7,21]。在此将该算法称之为自适应邻域规划搜索(adaptive neighborhood programming search,ANPS)算法,其搜索过程中基于邻域操作的破坏算子保留部分变量的取值,基于规划模型的修复算子则重新处理待优化变量。该规划模型的求解交由标准求解器Gurobi完成。 初始解的产生采用SAMMARRA等[22]提出的STASKS 与S-LOAD 规则,即将任务数或者任务负荷均分给所有起重机。结合本文所提出问题,在此S-LOAD考虑2种情况:1)只考虑基本装卸作业时间;2)考虑基本装卸作业时间和惩罚时间之和。一旦完成起重机任务分配即可确定决策变量xik,随后采用起重机单向走行策略确定每台起重机处理任务时的作业顺序。假设起重机和任务均从左到右进行索引且起重机从左向右移动,须对所构建的模型施加约束: 当任务对(i,j)∈Φ,即任务i在任务j开工之前被处理,为了确保起重机的单向走行,须在模型中添加下列约束[23]: 一旦以上步骤完成,变量xik和变量yij的部分值即可给定,未给定值的变量yij即视为待优化变量,由此形成子问题交由求解器Gurobi求解。 采用类似的步骤处理从右到左的走行顺序,从而获得另一个解。为了确保起重机单向走行,须在模型中添加以下2个约束: 基于S-TASKS和S-LOAD 与单向走行策略,产生4组不同解,从中选择最优组作为算法的初始解。上述基于数学规划的单向走行策略将用于算法的解修复算子。 本文提出5种不同的解破坏移除算子,每个破坏算子都从原有起重机调度序列中删除d个作业任务。所有的破坏算子均是基于当前解进行任务选取,可视为在已有解结构上进行邻域操作。同时每次的任务选取规模较总任务数n来说相对较小,从而保证了解修复算子能够较快地确定待优化变量。一旦任务子集被选定后,相应的变量即视为待优化的,而剩余变量的取值则与原有调度方案中的取值一致。由于起重机干涉约束影响,任务完工时间ci依赖于每台起重机的作业顺序,因此,变量yij,zi和ci(i∈Ω)在以下操作中均视为待优化变量: 1)随机起重机作业移除算子。该算子允许将所选任务重新分配给其他起重机。针对起重机k∈Q,用Ωk表示分配给起重机k的任务集合。该算子随机选择起重机k,从分配给起重机k的任务中选择min{d,|Ωk|}个任务,其中以上选定的任务将会在所有起重机之间重新考虑分配,即与上述选定任务有关的变量xik均视为待优化变量。 2)最大负载移除算子。在此仅考虑瓶颈起重机,分配给起重机k的任务集合Ωk中任务操作顺序按照各任务对应的操作位置进行升序排列。选取前d/2和后d/2个任务,若|Ωk| 3)基于基本装卸作业时间的Shaw 移除算子。参考文献[24],选择相似的任务来产生更优解。初始化选定任务集合D为空集,而后随机从集合Ω中选择1个任务j′。随后计算任务j′和所有剩下的任务的相关性度量值R(j′,j)=|aj′−aj|,再基于参数ε随机选择新的任务j″插入集合D中。基于简单计算,在此将参数ε设定为3。重复上述选择操作直到所选任务集合D的大小为d时停止,该算子流程如图1所示,与选定任务相关的变量xik被视为待优化变量。 4)基于基本装卸作业时间和惩罚时间的Shaw移除算子。该算子与算子3)相似,仅仅相关性度量值R(j′,j)的计算方式不一样。此算子中R(j′,j)的计算将考虑任务i的惩罚时间bi,即R(j′,j)=|aj′+bj′−(aj+bj)|。 5)作业随机移除算子。该算子随机选择任务子集,并允许重新安排所有相关变量,即在所有任务中随机选择min{d,|Ω|}个任务,并且所有相关变量xik都作为待优化变量。 图1 Shaw移除算子操作流程Fig.1 Flow chart of shaw removal 在修复算子方面,使用标准数学求解器来解决基于上述破坏算子和单向走行策略下的数学模型。该数学模型包含MIP和约束(22)~(23)(或者约束(24)~(25))。在该模型中,xik分为待优化部分和已经赋值部分。为了保证求解速度,在此设定该模型的求解时间为Tlocal。 破坏算子的选择基于其在之前迭代过程中的搜索性能,在此用O表示破坏算子集合。整个搜索过程被分成若干个片段,每一段包含κ次迭代,最后一段迭代可能会少于κ次。基于破坏算子的权重,采用标准轮盘赌选择机制来选择算子。 每次搜索开始时,将每个破坏算子的权重设置为0.5,以保证其选择概率一致(wθ=0.5,θ∈O)。权重在此后的κ次迭代中保持不变,然后采用下式对其进行更新: 式中:Sθ为破坏算子θ的累计得分;Smin和Smax分别为Sθ(θ∈O)的最小值和最大值;参数η∈[0,1],可反映权重wθ(θ∈O)如何快速对搜索性能作出反应。 为了衡量破坏算子θ(θ∈O)的性能,在每次迭代过程中均记录Sθ。在每一段迭代初始,所有算子得分均重置为0。当使用算子θ时,用τθ表示在某段迭代过程中目标值的累积改进,而ϑθ表示在该段迭代过程中累积的计算用时。在每段迭代过程开始时,ϑθ和τθ初始化为0,则Sθ可表示为 式中:Sθ考虑了在某一段迭代过程中使用算子θ对候选解的质量改进速度。 修复算子存在时间限制,新解的质量并不总是比现有解质量更好。为了避免陷入局部最优解,在此使用模拟退火来更新现有的解。该方法的初始温度为T0,并在每次迭代中通过冷却参数μ进行更新。若新发现的解Unew优于当前解U,则当前解被最新解代替。另外,每次迭代产生随机数,如果该值小于e-(Znew-Z)/T(其中T为当前温度),那么,当前解被Unew取代更新。当满足下列任一终止条件则算法停止搜索:1)达到最大迭代次数Imax;2)连续Inip次迭代中最佳解并无改善。 图2 ANPS算法框架Fig.2 Flow chart of the proposed ANPS algorithm ANPS 算法框架如图2所示,从参数初始化开始,然后根据第2.1节中提到的启发式策略生成初始解U,并计算其目标值Z。算法的最优解为其迭代过程中已发现的最佳计算结果。令最优解Ubest=U及其目标函数Zbest=Z。算法开始迭代直到满足停止准则为止。对于每次迭代,基于轮盘赌选择机制选择破坏算子θ,然后利用算子θ生成子问题。若产生的子问题可行,则通过标准求解器求解得到新的Unew和Znew,并观察是否存在更新最优解和替代当前解的可能。若新解的目标函数值优于当前解则将其更新为当前解,否则,引入随机数继续判断。若新解的目标函数值优于已发现的最优解,则更新最优解。同时,参数τθ和ϑθ通过τθ:=τθ+Z-Znew和ϑθ:=ϑθ+tθ更新,其中tθ表示在迭代过程中破坏算子θ的计算用时。一旦权重更新条件满足,则更新权重wθ,并重置参数τθ和ϑθ。 本文所提出的GCSPRO 问题与现有的起重机调度问题有所不同,因此须构建算例进行分析。在此将单向走行策略、MIP和初始解与所提出的ANPS 算法进行比较。升序单向搜索由目标函数(4)、约束(5)~(21)以及约束(22)~(23)进行定义(称为UDS_A);降序单向搜索由目标函数(4)、约束(5)~(21)及约束(24)~(25)定义(称为UDS_D)。初始解为S-TASKS和S-LOAD 求得的最优解。采用默认设置下Gurobi7.5.1 来求解优化模型,使用C#在Visual Studio 2017 环境中实现算法。运算采用英特尔i7-7700 CPU(3.6 GHz)、12 GB RAM和安装有Windows 10操作系统的台式电脑。 基于成都青白江铁路集装箱中心站实际运营情况以及由KIM 等[25]提供的基准数据生成方法来产生算例。实际装卸作业时间为3~10 min,为此测试算例中任务j的基本处理时间aj在U(3,10)均匀分布中产生。集装箱任务的作业位置沿班列分布,每个位置都有1个卸载或装载任务,同一位置的班列或卡车关联任务数不超过2个。任务j∈Ω的操作位置lj通过均匀分布从集合{1,2,…,n}中获得,其处理优先顺序如下:卡车卸载任务、卡车装载任务、班列卸载任务、班列装载任务。集装箱翻箱作业只发生在装载过程中,现有堆场设置下集装箱可堆叠3层,第4层为起重机吊具移动预留空间。如果只有1个集装箱位于目标集装箱顶部,集装箱的翻箱处理时间是2个时间单位,那么,因翻箱作业导致的惩罚时间bj可通过均匀分布从{2,4,6}中取得;参考文献[13]中的方法,恶化阈值hj从3个均匀分布的取值区间中获取,即H1:=[1,A/2),H2:=[A/2,A]和H3:=[1,A],其中。对于轨道式集装箱起重机,假设其初始位置沿班列等距分布,最早到位时刻设置为0;在相邻操作位置之间,起重机走行时间为t0个时间单位,安全距离设置为1个作业位置。 算例包含小规模和大规模算例集。对于小规模算例,任务数量n在集合{10,15,20,25}中选取,起重机数量m在{2,3}中选择;对于大规模算例,任务数量n从{40,60,80,100}中选择,起重机数m从{3,4}中选择;每个参数n和m组合生成5个算例,共计240个算例。 参数设置是通过解的质量和计算时间之间的权衡来实现的,利用小规模算例进行测算确定参数取值。在此考虑不同参数值对解的质量和计算耗时的影响,以平均偏差和平均运行时间为基准。本文所提出的ANPS 算法主要包括d,κ,η,T0,μ,Inip,Imax和Tlocal这8个基本参数。基于测算结果,Inip和Imax分别被设置为20和200;初始温度T0和冷却参数μ分别设置为100和0.95;由Gurobi求解子问题的时间限制Tlocal=50 s,而参数d则为满足10≤d≤min(20,0.4n)的随机数,d最小值为10;经过正交试验后确定κ=8,η=0.7 为最佳组合。 对于每个算例,用RPD=100%×(Z-Zbest)/Zbest表示所得目标函数值与不同方法求得的最优解之间的相对偏差(%),同时算法所得最优解个数与平均计算用时也列入结果中,在此最优解指的是所有方法给出的最佳结果。Gurobi求解MIP的计算时间限定为1 800 s,若实际计算时间未超过设定的1 800 s,则给出的解为问题的最优解。UDS_A和UDS_D 中较优解列于UDS 栏中。值得注意的是,“UDS”中列出的运行时间是UDS_A和UDS_D 之和。表2所示为小规模算例的计算结果。由表2可知:Gurobi求解MIP可得到作业任务数为10和15的算例最优解,所有算例与最优解的平均相对偏差为2.01%左右,平均计算用时为773.09 s。在120个算例中,有88个算例在使用MIP 求解时因1 800 s 时间限制而停止。采用单向走行时,UDS_D的性能略微优于UDS_A的性能,UDS 结果堪比MIP的结果,但并不总能产生最优解,UDS 中解的平均相对偏差为1.13%,而UDS的平均计算用时还不到MIP的平均计算用时的2%。因此,在解决起重机调度问题上UDS具有较强的优势。本文提出的ANPS算法除了在120个算例中有2个无法找到比UDS 更好的解以外,其他结果与UDS的求解质量一样好。此外,初始解与最优解的平均相对偏差为6.25%,而ANPS 解与最优解的平均相对偏差仅仅为1.16%。这意味着通过ANPS算法,解的平均相对偏差了5.09%。 表2 小规模算例的计算结果Table 2 Computational results for small scale example 表3所示为大规模算例计算结果。当任务数n≥20 时MIP的求解时间明显变长,耗尽时间限定的1 800 s。随着算例的增加,使用Gurobi 求解的UDS 平均运行时间显著增加。UDS_A和UDS_D都耗尽了给定的限制时间,并且仅仅6个算例找到了最优解。UDS 求解大规模算例平均相对偏差为19.56%,由此表明算例规模增加,问题的复杂程度也急剧增加。初始解的平均相对偏差为3.83%,这比UDS 策略解的质量要高得多。此外,初始解的平均计算用时仅为8.09 s;对于ANPS 算法,相对偏差从0%到0.71%不等,120个算例的平均相对偏差仅为0.08%。从表3 可以发现ANPS 算法为120个算例中的115个提供了最优解,平均运行时间为275.15 s。值得注意的是,当作业任务数n大于60个时,ANPS算法总能给出最优解,由此证明ANPS算法在求解大规模算例时是有效的。初始解给出最优解数量为24,这意味着91个算例的最优解是由ANPS算法搜索得出的。 表3 大规模算例的计算结果Table 3 Computational results for large scale example 1)采用阶梯恶化函数对集装箱装卸转运作业时间进行描述。在考虑作业优先约束、轨道式集装箱起重机干涉约束与边界约束的基础上,构建了混合整数规划模型。 2)将数学规划与自适应大规模邻域搜索进行集成,提出了自适应邻域规划搜索求解算法。该算法采用5种破坏算子构建子问题,并利用标准求解器Gurobi 实现求解。基于铁路集装箱中心站实际运行情况构建的算例测试结果表明:所提出的ANPS 算法在大规模算例中取得了良好的计算效果,较之混合整数规划与单向搜索策略均有明显的优势,适用于求解此类问题,从而为大规模铁路集装箱转运过程中的资源调度问题提供决策支持。
1.2 数学模型




2 求解方法
2.1 初始解生成
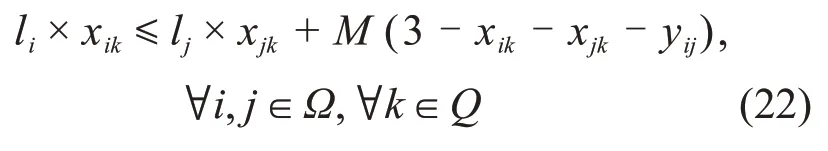
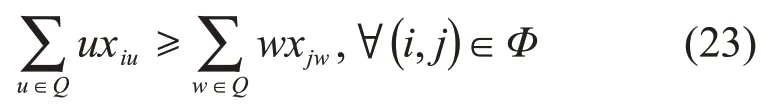

2.2 破坏算子
2.3 修复算子

2.4 破坏算子自适应选择策略
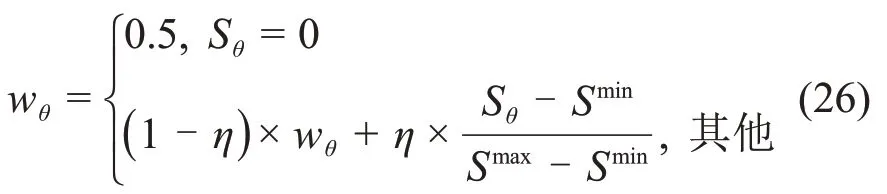

2.5 更新与停止准则
2.6 算法框架
3 算例分析
3.1 算例生成
3.2 算法参数选取
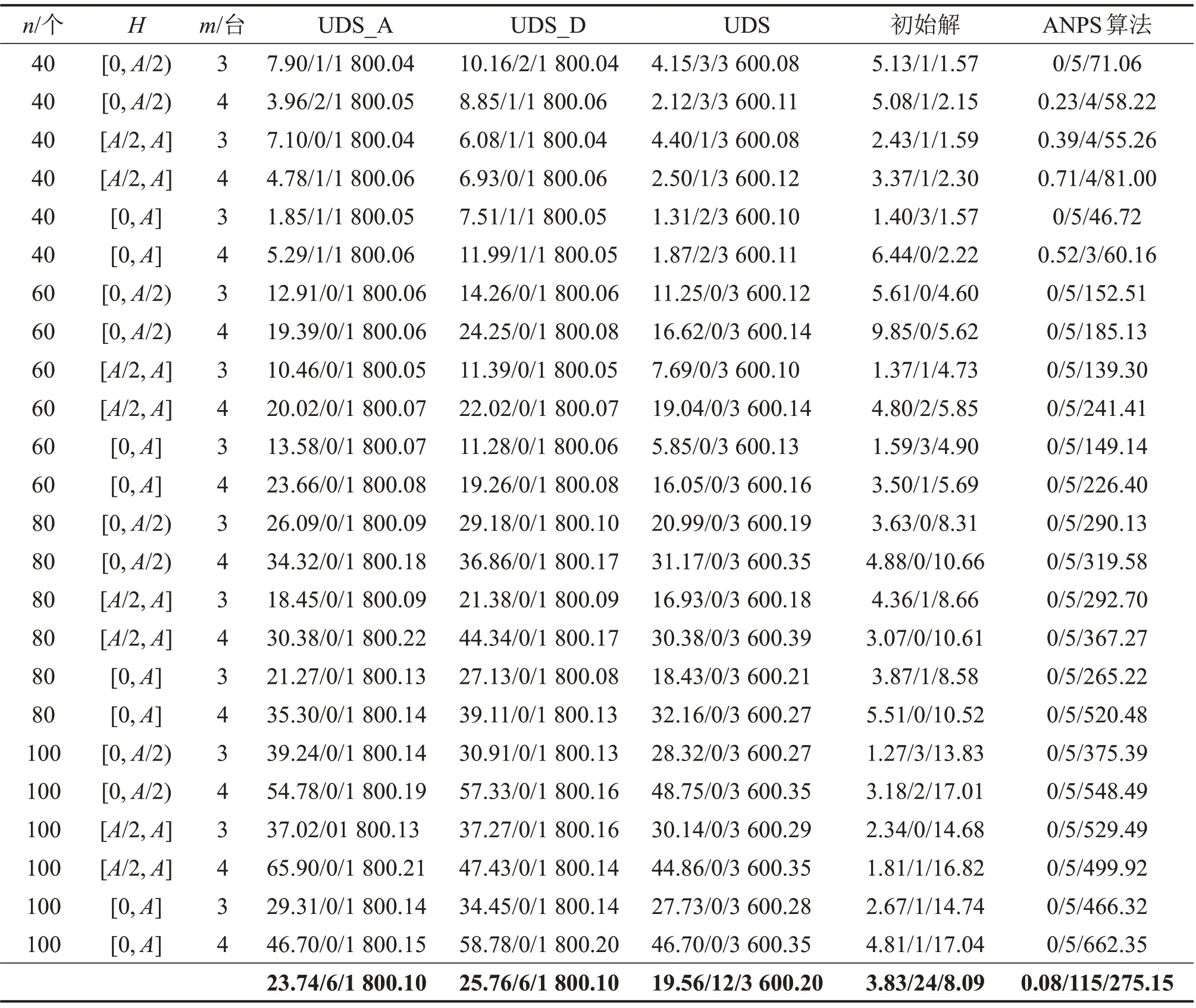
3.3 结果分析

4 结论
