基于图元识别的OCR文本图像矫正算法分析
2019-04-12彭清畅
姜 毅 彭清畅 徐 娟
(中车青岛四方机车车辆股份有限公司,山东 青岛 266111)
0 前言
OCR文本图像可以在纸质文件信息的互联网传输、存储过程中得到很好地应用,但在人为和机械操作等因素的影响下,OCR文本图像倾斜往往会对后续的文本分析、页面分割、OCR识别造成较为负面的影响,为了尽可能地消除这种负面影响、进一步推进办公自动化,该文围绕OCR文本图像倾斜矫正快速算法展开了具体研究。
1 OCR文本图像倾斜矫正方法选择
为了合理地选择OCR文本图像的倾斜矫正方法,该节分别介绍了霍夫变换和基于投影图矫正2种方法,并最终选择了基于投影图的矫正方法来对OCR文本图像进行倾斜矫正。
1.1 霍夫变换
在OCR文本图像倾斜矫正过程中,霍夫变换图元识别方法能够发挥很大的作用,作为一种典型的特征检测方法,霍夫变换在数位影像处理、电脑视觉、图像分析等领域均得到较为广泛的应用,霍夫变换是用来辨别找出物件中的特征。值得注意的是,为保证霍夫变换能够较好地对OCR文本图像进行倾斜矫正,需要图像旋转与霍夫变换的结合,即根据OCR文本图像的矫正处理要求,合理联用图像旋转技术及霍夫变换处理方法,以保证OCR文本图像的矫正处理效率。
1.2 基于投影图的矫正方法
Ishitani Y在《Impulse noise removal using polynomial approximation》研究中提出了“基于对投影图的形状分析的局域复杂度方法”,该方法的原理为遍历每次倾斜角度下的投影轮廓,并能够在倾斜角度不大时保证矫正精度,但该图元识别方法存在的不足是复杂度较高,但在综合2种OCR文本图像倾斜矫正方法后,该文选择了更具潜力的基于投影图的矫正方法,并对其进行了改进。
2 基于投影图改进的OCR文本图像倾斜矫正快速算法
该节就OCR文本图像预处理、OCR文本图像倾斜矫正快速算法2个部分展开了论述,希望能够为相关业内人士带来一定启发。
2.1 OCR文本图像预处理
为了实现高水平的OCR文本图像倾斜矫正,OCR文本图像预处理环节不容忽视,因此该文首先应用了图像校验去噪技术,并在之后基于邻域信息迭代去噪。在图像校验去噪技术中,Long-Range Correlation得到了充分利用,并同时与自适应模糊开关中值滤波、基于邻域信息迭代去噪实现了高质量配合,较好地满足了OCR文本图像的去噪处理需求,为后续的OCR文本图像倾斜矫正的实现提供了有力支持。
2.2 基于投影图改进的OCR文本图像倾斜矫正快速算法
“基于对投影图的形状分析的局域复杂度方法”在应用中需要沿某一特定方向累加出图像中黑像素点数量的统计图,并对行方向进行投影得到水平投影、对列方向投影得到竖直投影。对于倾斜的OCR文本图像来说,首先进行图像的二值化处理,并开展水平投影黑点像素值统计,由此计算方差,随后即可以特定的步长为间隔、在一定角度范围内分别旋转OCR文本图像,旋转后计算OCR文本图像的水平投影图黑点像素值、方差,基于投影图均方误差最大旋转角,求得最佳倾斜角度。
在具体的OCR文本图像倾斜矫正中,方差评判标准是其中的核心,象每行、平均黑点的方差较小,则代表黑白间隔不严格(倾斜程度越大),如每行、平均黑点的方差越大,则黑白间隔越严格(越不是倾斜)。为减少算法的计算量,实现OCR文本图像倾斜快速矫正,该文采用了将一幅OCR文本图像随机分成5块的处理方式,倾斜角的寻找以黑点数最多的一块为准。而为了快速确定OCR文本图像属于左倾还是右倾,首先需要采用试探法明确矫正方向,即将OCR文本图像左旋一个θ度、右旋一个θ度,并分别进行方差的计算,由此即可明确OCR文本图像的校正方向。
前期算法流程可概括为获得二值化图片→将图片随机分成P1~P5共5块→挑选黑点数量最多的图像块(如式(1)所示)→对图像块P中平均每行黑点个数进行统计(如式(2)所示)→寻找最佳OCR文本图像倾斜角度(Angle)→假设旋转角度为θ→基于图片黑点方差准则函数开展计算(如式(3)所示),式(3)中的 fθ(i,j)、avg(θ)分别为旋转角度θ时图像Pi、Pj点二值化后图像像素值以及旋转角度θ时图像P平均每行黑点数。
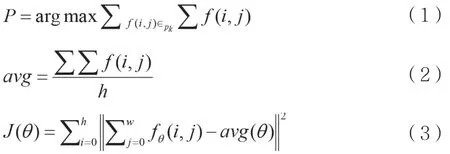
为了进一步提高算法效率,加快OCR文本图像倾斜矫正的速度,必须明确OCR文本图像的矫正方向,即使OCR文本图像左右各旋转t度,对J(t)与J(-t)大小的对比,如J(t)<J(-t),则可以确定OCR文本图像倾斜矫正方向为右旋,否则为左旋。基于OCR文本图像倾斜矫正方向,根据式(4)得出最佳旋转角度Angle开展的计算,实质上属于1次一维最优化搜索,而在OCR文本图像倾斜矫正方法的支持下,该搜索仅从[0,30]或[0,-30]中求解,由此使OCR文本图像倾斜矫正速度大幅提升。

然后需要从连续区间求解转换为离散空间求解,具体的求解流程可以概括为设θ初始值为0→引入OCR文本图像倾斜矫正方向→右旋时θ-=2,否则θ+=2→求得方差最大角度θ1(步长为2°的情况下)→明确[θ1-2,θ1+2]区间→求解方差最大时角度θ*(步长为0.01°的情况下),将OCR文本图像旋转θ*,即可完成OCR文本图像的倾斜矫正。
2.3 基于投影图改进的OCR文本图像倾斜矫正快速算法检验分析
以VisualC++语言分析基于投影图改进的OCR文本图像倾斜矫正快速算法的应用效果。针对OCR文本图像进行二值变换处理后,对处理后的图像进行测试,结果显示不同字号OCR文本图像均可发现倾斜角,且其程序响应时间均短于95 ms,这一结果提示,基于投影图改进的OCR文本图像倾斜矫正快速算法可以基本满足实际的OCR文本图像处理工作的要求。
而从处理后图像的精度参数来看,假定同行中2个等高字符的图像识别标准包围盒的中心垂直偏差水平为1个像素,则在1.02°倾斜角条件下,处理后OCR文本图像精度为0.11°;而当OCR图像的倾斜角为1.19°时,经计算确认其对应的精度参数为0.08°;当OCR文本图像的倾斜角为1.23°时,其对应精度为0.10°。上述结果表明,运用基于投影图改进的OCR文本图像倾斜矫正快速算法进行处理,所得精度均可满足OCR的字符识别要求。
3 结论
综上所述,基于投影图改进的OCR文本图像倾斜矫正快速算法具有较高的可用性,在此基础上,该文涉及的基于投影图矫正方法分析、OCR文本图像的矫正方向明确、转换为离散空间求解等内容,则提供了可行性较高的OCR文本图像倾斜矫正路径,而为了进一步提高矫正的质量与效率,OCR文本图像的去噪、二值化、分辨率提升等内容同样需要得到重视。
