一种新的基于多重液相色谱-质谱实验肽信号峰形相似性的校准算法
2018-12-19董晓睿
崔 健,董晓睿,商 凯,陈 强,祁 鑫,崔 浩
(1.中国石油大学 胜利学院 信息技术系,山东 东营 257016;2.中国石油大学 计算机与通信工程学院,山东 青岛 266580)
液相色谱-质谱(LC-MS)是发现并分析生物标志物中复杂肽信号的关键技术,其中对实验谱中的肽信号进行检测和量化至关重要。理论上相同样本多次重复实验得到的谱图是一致的,即同种肽链应在不同谱图的相同位置(相同LC时间与m/z值)产生相同信号。但由于实验误差,多次重复实验谱图会存在较大差异,需对谱数据进行校准,减小误差。
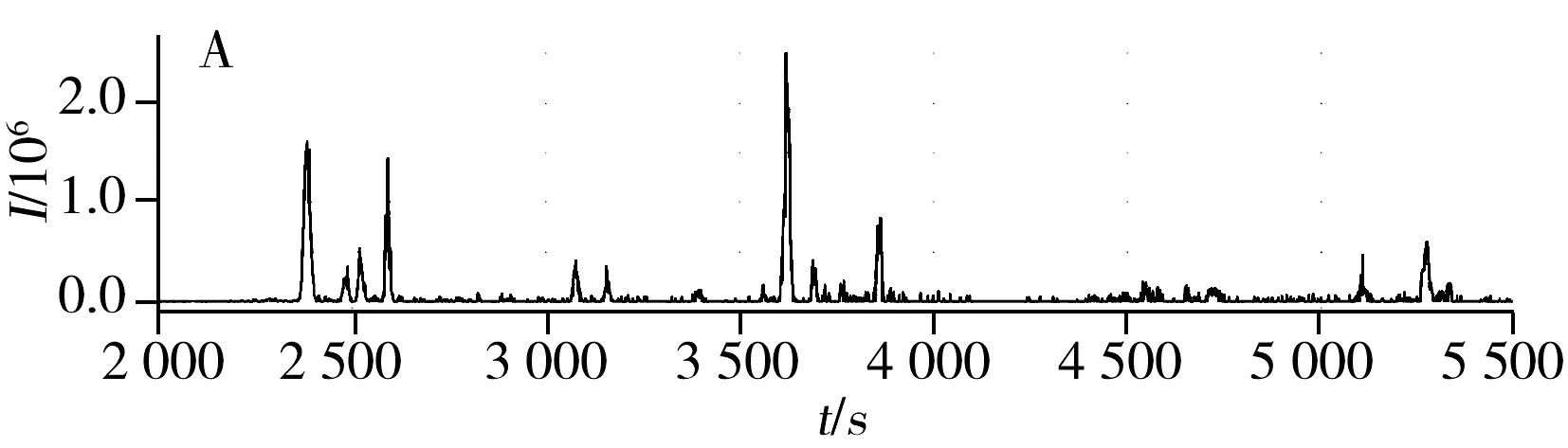
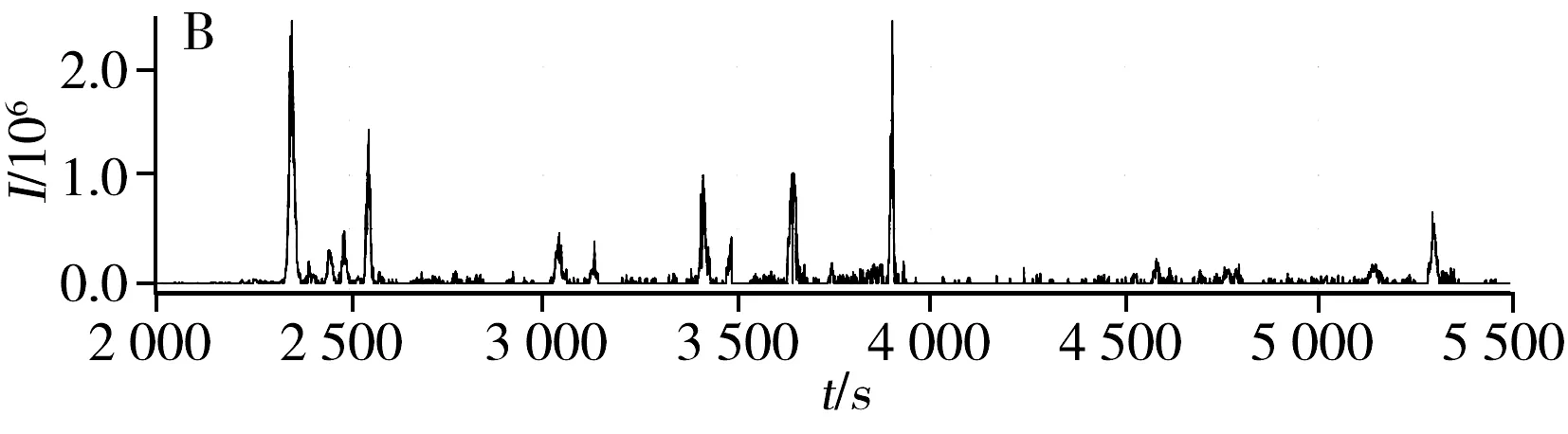
图1 肽链“KVEDMMK”生成的XICsFig.1 XICs generated by “KVEDMMK”A.XICs of peptide “KVEDMMK”in data 1;B.XICs of peptide “KVEDMMK”in data 2
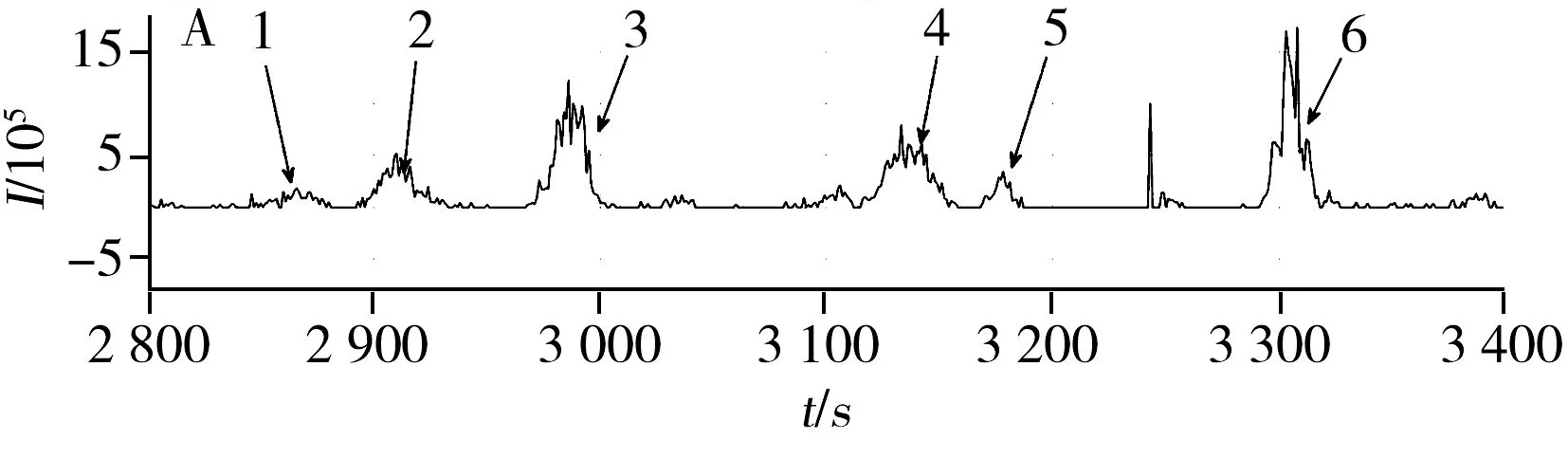

图2 肽链“AGGPTTPLSPTR”的相关峰信号匹配Fig.2 Corresponding peak of “AGGPTTPLSPTR” A.LC peak between 2 800-3 400 of peptide “AGGPTTPLSPTR” in data 1;B.LC peak between 2 800-3 400 of peptide “AGGPTTPLSPTR” in data 2
根据液相色谱-二级质谱(LC-MS/MS)实验标识的LC峰时间位置,通常使用翘曲函数(Warping function)对时间特征进行校准。目前,采用翘曲函数对LC时间轴校准,通常先计算肽链的m/z值,然后固定m/z值对整个时间谱图进行匹配。但由于时间差产生的随机性,该方法并不能完全校准。有研究者提出了基于翘曲函数的改进算法,如2002年Nielsen等[1]提出的相关优化翘曲函数算法(Correlation optimized warping,COW);2004年Eilers[2]提出的参数时间翘曲函数算法(Parametric time warping,PTW);2006年van Nederkassel等[3]提出的半参数时间翘曲函数算法(Semi-parametric time warping,STW)及Jaitly等[4]提出的液相质谱数据翘曲函数法(lcmswarp)等。Voss等[5]提出了一种将相关特征峰对和整体时间校正相结合的算法,该法关注同时校正多重实验数据,但对数据的处理效果比OpenMS软件[6]略差。此外,当实验样本比较复杂时,在一个m/z值相同的提取离子色谱图(XICs)中会有多个LC峰出现在一个狭窄的LC时间窗口,极可能导致相应特征峰的错误识别。图1显示了肽链“KVEDMMK”在本文所处理的实验数据1和2中产生的XICs,其LC峰信号充满噪声,主峰附近也分布很多噪声峰,即使用OpenMS或Msinspect[7]等软件进行多个数据集处理,也无法避免此类问题。
时间误差的随机性及噪声会导致匹配结果准确性降低。以肽链“AGGPTTPLSPTR”为例(图2),在数据1中检测到多个肽链信号(Peak1~6),与MS/MS检测结果对比,确认Peak3为真正的肽信号峰;数据2中由MS/MS检测到的真实肽信号已标出。以数据2为基准匹配数据1中的真实信号,即在数据1中的6个信号中找到与数据2中真实信号相匹配的信号Peak3。而从时间间隔上显示匹配结果为Peak2,而非Peak3。因此,除时间特征外,还需引入其他特征提高校准匹配的准确性。
目前,仅MS/MS均能识别出的肽链与LC-MS峰重叠的一小部分可以使用Quil[8]、Proteinquant[9]、Msinspect[10]、OpenMS[11-12]和Superhirn[13]等软件进行重复实验数据量化。MaxQuant软件[14-16]可以大大提高量化范围,是因为由MS/MS检测的肽链可以至少量化1次,但在所有数据集中可以同时量化的总肽数量有限,只能是多数据MS/MS肽链信号的交集。这导致多次重复实验数据量化的覆盖率较低。
针对两个重复LC-MS实验数据,本文采用普通的区间检测方法,选取多次重复实验数据中均被MS/MS检出的肽链信号作为训练数据集。以MS/MS检测到的肽链的m/z值及LC时间值为真实值(Ground truth),训练数据集中所有肽链在两个数据中均具有真实值。从训练数据集中随机选取部分肽链,基于其真实值建立统计学习模型,训练数据集中剩余部分作为测试序列进行模型测试,以模型给出的最高分值作为匹配结果,再比对真实值,计算百分比作为检测模型的准确性(Accuracy)。最后,仅在1个数据中被MS/MS检测到的肽链通过模型匹配其在另外数据中的相关区间(无MS/MS检测结果),提升校准后肽信号的覆盖率。
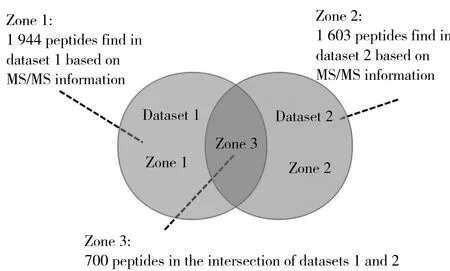
图3 数据1和数据2的MS/MS检测肽链信息文氏图Fig.3 Venn diagram of MS/MS peptides information of data 1 and data 2
1 实验部分
1.1 数据来源
本文处理的数据由RCMI Proteomics and Protein Biomarkers Cores at UTSA实验室提供,为经过LTQ Orbitrap Velos仪器处理的TAGE肿瘤数据(肿瘤样本的多次重复实验数据),选取2组数据(数据1与数据2)进行分析。每个数据分为Level1和Level2。数据中每个数据点包括3个坐标时间值、质荷比值、强度值。数据1中Level1的有用数据(强度值不为0)为11487个,Level2的有用数据(强度值不为0)为58636个。数据2中Level1的有用数据(强度值不为0)为11446个,Level2的有用数据(强度值不为0)为59573个。数据1中被MS/MS检测到的肽链为1944个,数据2中被MS/MS检测到的肽链为1603个,交集为700个,并集为2847个(图3)。
1.2 数据处理
1.2.1数据预处理如图4所示,根据实验1和实验2的MS/MS信息表,生成MS/MS肽信号合集,并计算相应肽信号的质荷比(m/z值)。然后在数据1和数据2的Level 1数据中,分别计算肽链m/z值(前后各取20×10-6宽度)下的LC谱图,获取全时间段的XICs;在全时段XICs上进行区间检测,在数据1与数据2中分别获得的区间段均为候选信号区间。
1.2.2训练数据集生成具备可测试的真实值是选取训练数据集的前提。本研究以MS/MS检测到的肽信号的m/z值与时间值为真实可靠的值。首先,选取图3中的交集部分作为生成训练数据集的基础(共700个肽链),将预处理区间检测后包含MS/MS时间点的肽链选作训练数据集合(共599个肽链)。再在训练数据集中随机选取一半作为训练序列,产生时间差统计学习模型以及峰形相似性模型;剩余部分作为测试序列,测试模型匹配结果的准确性(以MS/MS检测值作为真实数据比对)。
1.2.3统计学习模型生成基于以下两个假设建立模型:①同一肽链在重复实验中产生信号区间的位置(包括m/z与时间)理论上一致,不同种肽链产生的信号位置有差别;②同一肽链重复实验产生的信号形状理论上一致,不同种肽链产生的信号形状有差别。在训练数据集中选取训练肽信号k个,以图2为例:肽链“AGGPTTPLSPTR”在数据1中的真实信号峰(Peak 3)与数据2中的真实信号峰为相关信号峰对,数据1中其他信号峰(除去Peak 3)与数据2中真实信号峰为非相关信号峰对,分别计算相关信号峰对的时间差与峰形相似性,以及非相关信号峰对的时间差与峰形相似性。时间差即为区间最高值的时间差值,峰形相似性为计算两个信号的线性回归决定系数r2的值。r2反映了两个数列的相似程度,如数列x、y的r2值反映了数列y的变化可用数列x的变化来解释的百分比,计算公式如下:
r2=SSreg/SStot=1-SSres/SStot
其中,SStot为总平方和,SSreg为回归平方和,SSres为残差平方和。r2结果在0~1之间,SStot在数据确定后始终为固定值。估计的准确性越低,则SSres越大,r2越接近0;反之,则r2越接近1,即峰形越相似r2值越接近1。
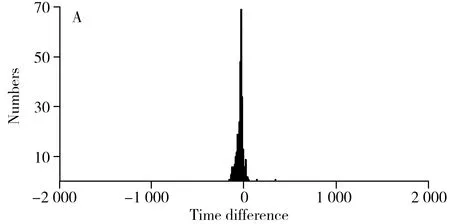
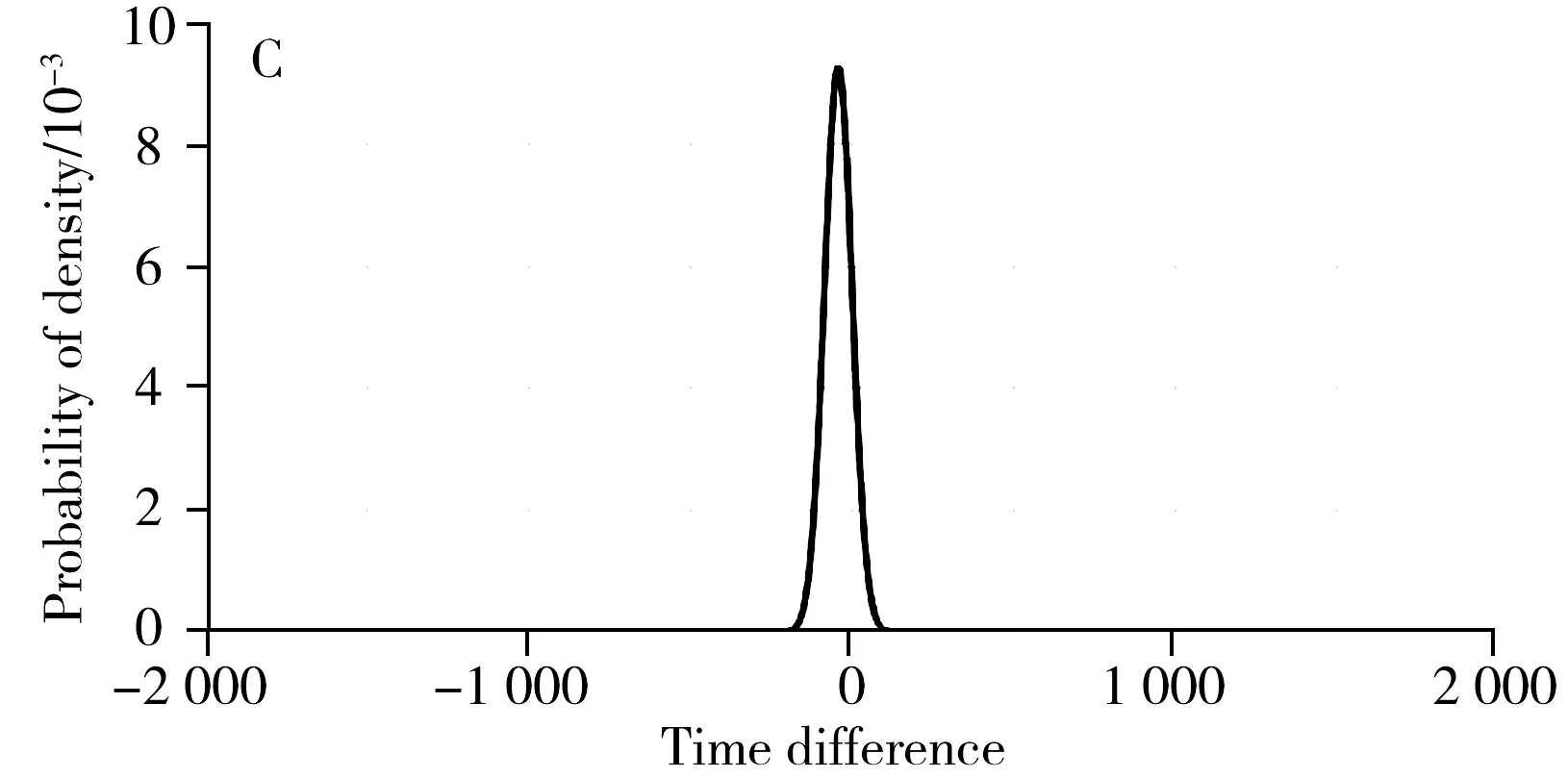
时间差特征统计特性如图5所示。时间差直方图基本符合正态分布,相关信号峰对的时间差相对非相关信号峰对的时间差更集中(图5A、B)。针对时间差样本,采用最大似然估计生成两个正态分布模型的参数。用相关峰对的时间差样本t估计正态分布模型f(Δt|t)的参数μ和σ:
得到相关信号峰对的时间差模型f(Δt|μ,σ2):
同理使用非相关峰对时间差样本得到非相关信号峰对的时间差模型。图5C、D为相关和非相关信号峰对的正态分布时间差模型。
峰形相似性特征统计特性见图 6,相关信号峰对的相似性集中在0.7以上(图6A),而非相关信号峰对的相似性比较分散(图6B)。采用gamma分布进行拟合:
gamma分布具有两个参数k和θ,采用matlab中gamfit( )函数进行gamma分布参数的极大似然估计得数值解,得到相关信号峰对的相似性模型和非相关信号峰对的相似性模型,峰形相似性模型的区分度较明显(图6C)。
1.2.4LC峰匹配校准基于图3的交集数据建立时间差与峰形相似性的统计模型,并测试模型有效性后,将统计模型用于图3中去交集部分肽链的校准匹配,即根据仅在1个数据中由MS/MS检测到的肽链信号,匹配其在另一数据中的相关信号。最终由MS/MS检测到的每一个肽链均能在数据1和2中匹配到相关信号峰对。
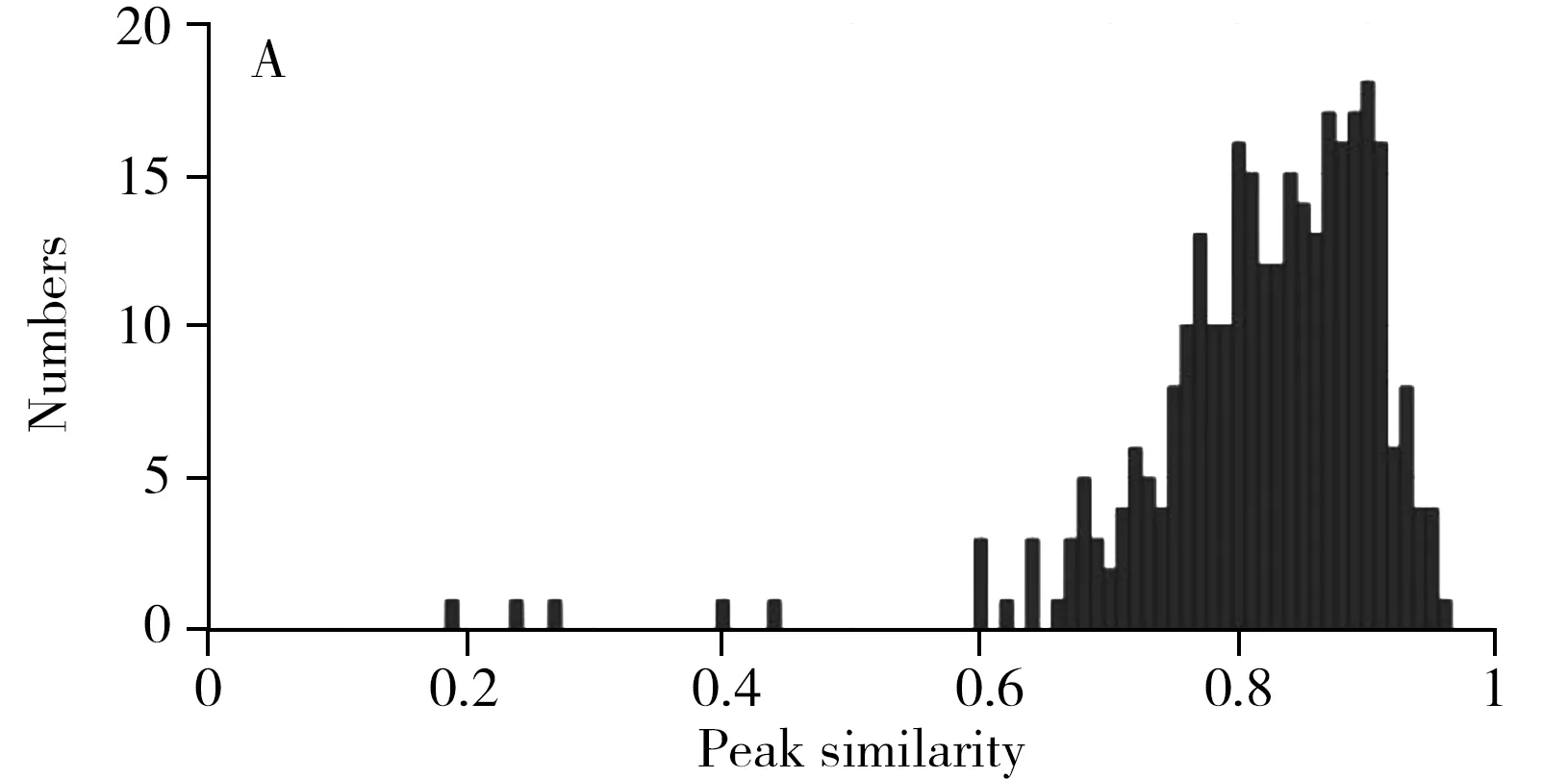
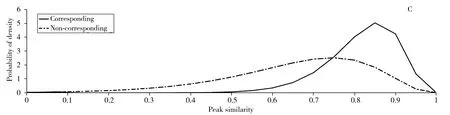
图6 相关峰与非相关峰峰形相似性模型Fig.6 Peak shape similarity of corresponding and non-corresponding peak modelsA.histogram of corresponding peak similarity(相关峰对峰形相似性直方图);B.histogram of non-corresponding peak similarity(非相关峰对峰形相似性直方图);C.model of peak similarity(峰形相似性模型)
2 结果与讨论
2.1 结果分析
2.1.1模型测试结果对模型进行10次测试,每次均从训练数据集中随机选取300个肽链信号作为训练,剩余299个肽链信号作为测试,将模型得到的匹配结果与MS/MS检测值(真实值)进行比对得到准确度。对时间模型和峰形模型分别进行单独测试,然后按照峰形和时间模型不同的权重配比进行综合测试,得到最优配比后再测试1次。
单独使用时间模型进行10次独立测试,准确率的平均测试值为96.3%,标准差为0.76。单独使用峰形模型进行10次独立测试,准确率的平均测试值为66.3%,标准差为1.79。
按照不同权重配比,综合使用时间模型与峰形相似性模型,结果如表1所示。总体上时间模型比重越高,准确性越高,这与单独分析时间模型结果优于峰形相似性模型的结果相符。但峰形相似性模型对整体准确性有所提升,配比为8∶2时的准确性达98.3%。

表1 模型在不同权重下测试结果Table 1 Testing result of different weights
采用8∶2的权重配比,综合使用时间与峰形模型进行10次测试,准确率的平均值为97.8%,标准差为0.77。准确率平均值提高了1.5%,对于并集2 847个肽链,提高大约为42个肽链的校准。通过Wilcoxon rank sum test对两种方法的结果进行显著性检验:其中方法1单纯使用时间方法校准,方法2采用时间峰形综合方法校准。Wilcoxon rank sum test将观测值和零假设的中心位置之差绝对值的秩分别按照不同的符号相加作为其检验统计量,检验成对的观测数据之差是否来自均值为0的总体(产生数据的总体是否具有相同的均值)。本文随机分配训练集和测试集,共10次,方法1和方法2的结果均在具备相同训练集和测试集的情况下得到。计算观测数据之差,共10个样本,假设两种方法的结果无显著差异,即H0:两种方法的检测结果无显著差异;H1:两种方法的检测结果有差异;在取显著水平为0.05的条件下,通过Wilcoxon rank sum test得到P-value为0.001,h值为1,即在5%的显著水平下拒绝H0,表明方法2相比方法1的结果有明显改进。
2.1.2数据并集的校准匹配根据图3,数据1与数据2并集共4 247个肽链,区域1中有1 944个(数据1中待校准匹配的个数),区域2中有1 603个(数据2中待校准匹配的个数),并集共3 547个肽链。通过算法匹配,最后得到匹配区间的肽链共3 226对,校准匹配的覆盖率达91.0%。
2.2 讨 论
以上研究存在以下问题:
①区间检测准确性需提高。本文的区间检测是以基础峰值位置检测到高强度峰区域内背景噪声标准偏差的3倍作为阈值,高于阈值的信号被纳入区间,长度超过连续6个点的信号被认为是候选LC峰区间。但数据1和数据2的MS/MS交集共700个肽链,仅检测到599个包含MS/MS时间点区间的肽链,检测覆盖率为85%。
②数学模型区分度需提高。通过验证,时间差模型区分度好,但在噪声较多的XICs中,仍受大量干扰信号影响。峰形相似性模型的引入虽有所改善,但区分度比时间差模型差。本文仅用线性回归决定系数(r2)描述两个信号相似性的值,模型的准确性有待提高。
③双模型的混合应用。本文对两个模型的综合使用采取简单的设置权值后相加的方法,今后将探索建立一个数学模型对两个特征进行统一。
3 结 论
本文通过采用统计学习的方法,利用多次重复的液相色谱-质谱实验的谱图中肽信号的时间差与峰形相似性两个特征,选取训练数据集建立统计模型,并对模型有效性进行验证,完成了对谱图的校准,并实现了多个肽信号对的匹配,准确性达98%以上,覆盖率达91.0%,为基于多次重复LC-MS实验数据的肽链量化提供了有意义的数据支撑。
致 谢:Michelle Zhang及RCMI Proteomics and Protein Biomarkers Cores at UTSA实验室为本研究提供了生物实验数据,并为论文写作与修改提供巨大帮助。
