基于MCU的Flash预取加速控制器设计与实现
2018-01-23冯海英范学仕
冯海英,范学仕
(中科芯集成电路股份有限公司,江苏无锡 214072)
1 引言
随着智能可穿戴设备、智能硬件的普及以及物联网的兴起,MCU在消费电子、工业控制、医疗设备以及人工智能等领域得到了广泛应用[1]。为了减少外围分立器件,增加通用型,MCU通常采用内嵌非易失性存储器(Non-Volatile Memory,NVM)保存程序和少量数据,而Flash作为典型的NVM,具有体积小、成本低、高灵活性、多次擦除编程等特点,可以满足高速访问和系统安全性等不同需求,逐渐成为MCU存储器的首选[2],因此MCU市场的蓬勃发展使得嵌入式Flash得到了越来越广泛的研究和应用[3]。十多年来,Flash以高于摩尔定律的增长速度高速发展。目前,Flash已成为集成电路(Integrate Circuit,IC)技术发展的主要驱动器,已和传统的动态随机存取存储器(Dynamic Random Access Memory,DRAM)、静态随机存取存储器(Static Random Access Memory,SRAM)一起构成IC存储的三大支柱产业[4]。
嵌入式Flash特定的接口协议与标准的总线接口协议不同,不能直接集成到芯片中。因此需要设计控制器实现两种接口协议的转换,完成Flash的基本操作[5]。同时,与处理器较高的运行频率相比,嵌入式Flash属于低速存储设备。自20世纪80年代起,处理器性能以每年60%的速率提升,而存储器访问时间的改善速率每年大约为7%[6]。相对于处理器可以通过指令集并行[7]、超标量设计[8]和大量使用寄存器提高自身性能,而Flash性能的提升只能依赖于工艺改良等方法[9]。当前大多数MCU可以工作在100 MHz以上的系统频率上,而Flash的读取速度大多在30~60 ns之间。例如本文使用的Flash最大读取速度为40 ns,理想情况最高速率为25 MHz;UMC推出的UM055EFLLP128KX032CAA的最大速度为40 ns;华虹公司推出的HKEFLYTxxK01系列片上Flash,最大读取速度为63 ns,理想最高频率为 15.9 MHz[10~11]。Flash与处理器之间的巨大速度差异会大大降低处理器取指效率,制约系统整体性能。因此设计带预取加速的Flash控制器至关重要。
本文基于预取和缓存原理,采用位宽扩展技术和改进预取技术相结合的方式,设计了具有预取加速功能的Flash控制器,完成Flash特定接口协议与AHB协议的转换,提高了取指效率,提升系统性能。本文首先详细分析了当前的Flash研究背景及现状,随后对Flash的接口协议进行了阐述,接着重点介绍了预取加速控制器的设计思路与实现方法,最后通过仿真数据和实测数据证明该设计的可行性。
2 AHB和Flash接口协议
2.1 AHB总线协议
作为SoC片上高速总线,AMBA AHB主要负责对带宽有较高要求的IP(Intellectual Property)的互连。AHB可以支持多主机、请求仲裁、突发传输、分离操作、流水操作等复杂操作,以满足中央处理器(Central Processing Unit,CPU)、直接内存存取(Direct Memory Access,DMA)控制器、片内存储器、外部存储器接口等高速设备之间的带宽要求。而系统的大部分低速外设则连接在高级外设总线(Advanced Peripheral Bus,APB)上,系统总线和外设总线之间使用桥接器进行连接[12~14]。本文的嵌入式Flash预取加速控制器属于AHB从机。
2.2 Flash接口协议
本文所选用的嵌入式Flash为ISSI公司推出的64位PFXXXXX,它包括128 kB的主存储区和3 kB的信息区,支持编程、页擦除以及整片擦除,主要由地址缓存单元、地址解码单元、逻辑控制单元、高电压发生单元、输入输出驱动单元和存储阵列单元组成,其整体框架如图1所示。

图1 嵌入式Flash整体架构
其关键信号介绍如下。
(1)CS:Flash 片选信号,高有效;(2)IFREN:信息区选择信号,高有效;(3)AE:地址使能信号,高有效;(4)OE:输出使能信号,高有效;(5)ADDR/DIN/DOUT:地址信号/写入数据/读出数据;(6)PROG/SERA/MASE:编程信号/页擦除信号/整片擦除信号,在AE上升沿有效,Flash开始编程/页擦除/整片擦除操作;(7)NVSTR:定义非易失性存储周期,高有效,Flash 处于正在编程/擦除状态;(8)TBIT:编程/擦除结束指示信号。
与SRAM不同,嵌入式Flash属于异步低速存储设备,本文选用的Flash最快读取速度为40 ns,编程操作时间20 μs,页擦除时间2 ms,整片擦除时间10 ms。
图2为Flash读取访问时序图。OE信号是数据输出的使能信号,在读取Flash的过程中需维持高电平状态,而PORG、SERA、MASE、NVSTR必须为低。AE信号是地址的使能信号,在一次读过程中,AE需要经过低-高-低的变化,tAAD≥40 ns,tAE≥10 ns,因此 Flash的最高读速率为25 MHz。

图2 Flash读取访问时序
图3为Flash编程时序图。PROG信号触发编程操作,AE为地址使能信号,TBIT信号为Flash输出信号,下降沿表示编程操作结束,NVSTR用来控制高电压产生。

图3 Flash编程操作时序
图4 为Flash页擦除时序图,图5为Flash整片擦除时序图。由SERA/MASE触发擦除操作,TBIT下降沿表示擦除操作结束,NVSTR用来控制高低压产生。

图4 Flash页擦除时序

图5 Flash整片擦除时序
3 Flash预取加速控制器设计
3.1 Flash控制器总体架构
嵌入式Flash预取加速控制器整体架构如图6所示,其一端作为从机连接AHB总线,另一端连接64位嵌入式Flash,主要由寄存器模块、保护机制、预取加速、仲裁机制、编程和擦除控制器、读模块、选择字节区加载和测试模式组成。
各主要模块功能如下。
(1)寄存器模块:主要包括实现编程擦除操作的控制寄存器,读出Flash状态的状态寄存器,地址寄存器,解锁相关寄存器,保护寄存器和预取控制寄存器。

图6 Flash预取加速控制器整体架构
(2)保护机制:主要实现对Flash的读保护和写保护,读保护防止程序被窃取,写保护防止程序被篡改。
(3)预取加速模块:通过增加缓存的方式,实现对指令和数据的预取加速,该功能可以寄存器控制开启或关闭。
(4)仲裁机制:本设计中Cortex-M3核通过3组总线访问Flash控制器以实现不同操作,其中I-BUS为核取指令的总线,指令预取在该总线上进行,D-BUS为核取数据的总线,S-BUS为核配置Flash寄存器的总线。其中I-BUS和D-BUS可以通过仲裁机制同时访问Flash控制器,D-BUS拥有更高的优先级。
(5)编程和擦除控制器:实现对Flash的编程/页擦除/整片擦除操作,在访问该模块时需先进行解锁操作。
(6)读模块:从Flash读出数据送到AHB总线上。
(7)选择字节区加载:选择字节区存储了Flash和系统的相关配置信息,复位后首先加载该部分内容,选择字节区的值发生改变后,需重新复位方可生效。
(8)测试模式:用于芯片测试以及出厂相关配置信息的烧录,也可用于量产烧录用户程序,提高效率。
3.2 Flash控制器读操作的实现
在本设计中,采用Cortex-M3,整个系统的最高运行频率72 MHz,而所选Flash的最大读取速度25 MHz,因此需要添加等待周期以实现高频核对低频Flash的访问。具体做法为配置相关寄存器的LATENCY位,决定是否插入等待周期:
(1)LATENCY=0,0< 系统时钟≤24 MHz,无需额外插入等待周期;
(2)LATENCY=1,24 MHz< 系统时钟≤48 MHz,需要额外插入1个时钟等待周期;
(3)LATENCY=2,48 MHz< 系统时钟≤72 MHz,需要额外插入2个时钟等待周期。
Flash预取的开关由相关寄存器的PRFTBE(预取缓冲区使能)控制,该信号为高时开启Flash预取。
当预取开时,在LATENCY=0时,AE信号频率与HCLK时钟频率一致;在LATENCY=1时,将时钟二分频作为AE信号;在LAYTENCY=2时,将时钟三分频作为AE信号,通过判断当前总线状态及跳转状态,选择与AE匹配的地址,产生对Flash读访问。当预取关时,根据当前是否有有效传输产生AE信号和相应的ADDR信号,产生Flash读访问,此时可适当降低读Flash产生的功耗。
3.3 Flash控制器擦除和编程功能的实现
擦除和编程控制器实现Flash的页擦除/整片擦除和半字编程操作。编程/擦除过程如下:
(1)读取Flash状态寄存器,判断当前时刻Flash是否进行其他操作;(2)配置Flash控制寄存器的编程/擦除位;(3)向指定地址写入半字/选择需要擦除的页;(4)等待编程/擦除过程结束;(5)读出相应的内容加以验证。
其具体的状态转换过程如图7所示。收到总线写操作命令时,状态跳转到WR_PRP1状态,判断是否为保护地址,若被写保护,跳回WR_IDLE状态;若可写,跳到WR_PRP2,读对应地址单元,判断是否为全F,若非全F,返回WR_IDLE状态;若可写,跳到WR_TT,发送AE及擦除或编程命令后,经WR_TT2跳到WR_WAIT,若在WR_TT之后有其他擦除或编程要求,在WR_WAIT状态等到Tbit后,将跳回WR_TT,发起下一次擦除或编程,否则跳回WR_IDLE。

图7 编程/擦除状态转换图
3.4 Flash控制器预取加速的实现
预取加速模块是Flash控制器的关键单元,负责提高Flash的读取性能。本文基于预取和缓存原理,采用位宽扩展技术和改进预取技术相结合的方式,设计了一种具有预取加速功能的Flash控制器。
首先采用位宽扩展技术,通过扩展Flash位宽,实现一次Flash访问取出多条指令,本文采用64位Flash,对于Cortex-M3的32位指令而言可以提高一倍的取指效率。单纯使用位宽扩展技术,处理器仍然必须等到Flash读取结束才能获取第一条指令,依旧存在单次访问延迟的问题。本文利用处理器处理已取出指令的间隙,发起硬件预取操作。
以顺序取指为例,如图8所示,使用两组预取BUFF来记录访问Flash的地址和取出的数据。其具体操作流程如下:
(1)当处理器读取N时,将数据和地址分别存入BUFF0的数据和地址寄存器,向总线返回数据D(N);(2)读取 N+4地址时,D(N+4)已在 BUFF0 中,直接读出;(3)读取N+4地址的同时预取N+8地址的值,并在读取N+8地址时,将数据和地址存入BUFF1的数据和地址寄存器;(4)以此类推读出其余地址。
从图8中可以看出,增加一组64位的BUFF0并不断更新其读地址和数据,即可实现预取技术。考虑到本文的32位CPU为Cortex-M3,受到流水线结构、数据和控制相关的影响,指令会出现跳转、间断,此时预取BUFF中的值将是无效的,需重新访问Flash,通过增加一组64位BUFF1,配合BUFF0共同完成硬件预取加速,如图9所示。之所以不多增加几组BUFF,是因为由于跳转指令的存在,过多的预取操作反而会导致系统性能的降低,同时会增加成本。

图8 预取加速时序图
整个预取加速功能的实现可总结如下。
(1)选取Flash地址。若等待传输的地址(在读Flash期间锁存的地址)不在BUFF中,Flash地址选取等待地址(锁存地址);若当前总线传输地址不在BUFF中,Flash地址选取当前地址;若当前总线传输地址/等待传输地址在BUFF中 (无等待传输),Flash地址选取当前地址+8的地址。
(2)判断是否预取。若当前地址和当前地址+8均在BUFF中,暂停预取,否则开启预取。
(3)是否更新BUFF。正在读取当前传输对应的Flash单元时,当前传输地址对应为跳转地址且跳转失败,读取单元不等于新地址,也不等于新地址+8,不更新BUFF;预取当前地址+8对应Flash单元时,在读Flash周期的中间周期(LATENCY=2)时,发生成功跳转且预取地址不等于当前地址,也不等于当前地址+8,不更新BUFF;预取当前地址+8对应Flash单元,在Flash数据锁定信号有效时,发生跳转且当前地址不等于读Flash期间READY信号为低的锁定地址,也不等于当前地址,更不等于当前地址+8,不更新BUFF。
(4)成功跳转判断。在更新标志发生时或之前,跳转状态由1或2跳转为8,或者有其他跳转发生,此时可不更新BUFF。
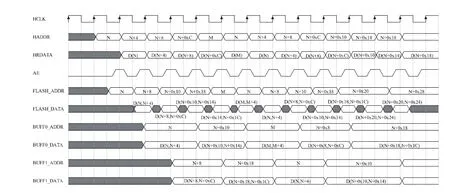
图9 带跳转的预取加速时序图
3.5 Flash控制器保护机制
Flash中的用户代码程序(主存储区)可以防止非法读出,通过设置读保护实现这一保护措施。在设置读保护后,除用外代码本身外的任何操作均无法读出Flash中的用户代码程序,在解除读保护时将产生一次整片擦除。
同样也可以对Flash加以页保护,防止程序在跑飞的情况下被意外改写,可通过设置写保护实现,任何试图在一个写保护的页面进行编程或者擦除时均会在Flash控制器的状态寄存器中反馈保护错误标准。
本文采用Cortex-M3的内核,并且支持3种启动方式:Flash启动,SRAM启动和系统Memory启动。Flash的内存空间可分为 main flash、option byte和system memory,本文设计的读保护访问权限如表1所示,“√”表示允许访问,“×”表示禁止访问。
3.6 其他部分设计
考虑到芯片测试以及出厂相关配置信息的烧录,以使其量产时更高效地烧录用户程序,本文设计了Flash测试模式,此测试模式可以直接与标准SPI进行通信,方便操作,提高烧写效率,降低成本。同时增加了低功耗设计,系统进入低功耗模式后Flash也进入相应的低功耗模式。
4 结果及分析
为验证本文设计的Flash预取加速控制器的功能,同时对性能和功耗进行评估。本文搭建的SoC实验平台,集成了ARM公司Cortex-M3的32位低功耗处理器、AHB总线、Flash预取加速控制器、ISSI的64位某型Flash和SRAM。控制器实现对Flash的读、编程和擦除3类操作,具体仿真波形如图10~14所示。
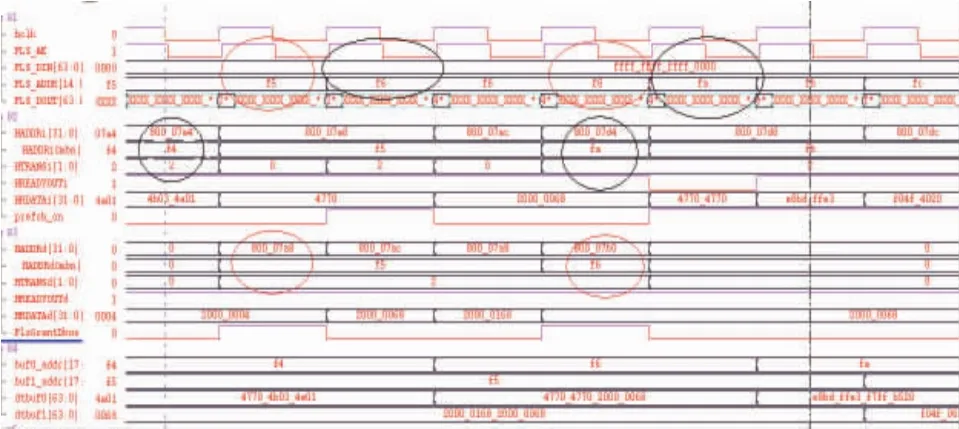
图10 LATENCY为0时预取及仲裁时序
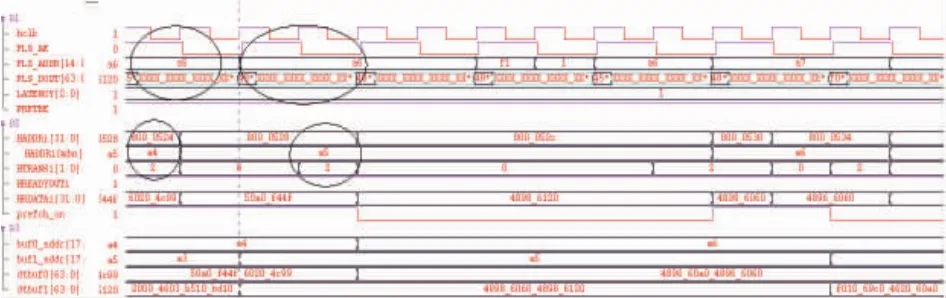
图11 LATENCY为1时预取时序

图12 LATENCY为2时预取时序

图13 页擦除时序
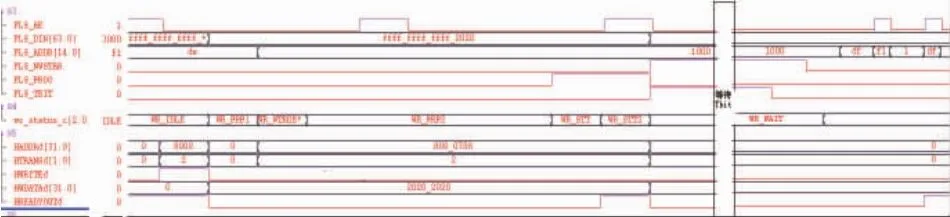
图14 编程时序
图10为LATENCY为0时预取及仲裁时序。在I-Bus和D-Bus同时读取0x080007a8地址时,D-Bus具有更好的优先级,优先读出数据0x20000068,随后I-Bus读出该值。I-Bus及D-Bus读取和仲裁正确。
图11和图12分别为LATENCY为1和2时的预取时序,其读取结果正确,预取时序符合图8所述本文设计的预取加速原理。
图13和图14分别为Flash擦除和编程时序仿真图,其结果与Flash本身擦除及编程时序一致,即图3和图4所示。
在对预取加速控制器的预取效率评估中,采用上述实验平台,分别在预取开启和关闭的情况下读取相同的地址空间内容(地址包含连续、跳转等),以耗费时间作为标准进行评估。具体实验数据见表2。

表1 读保护/非读保护时对Flash空间的访问权限表
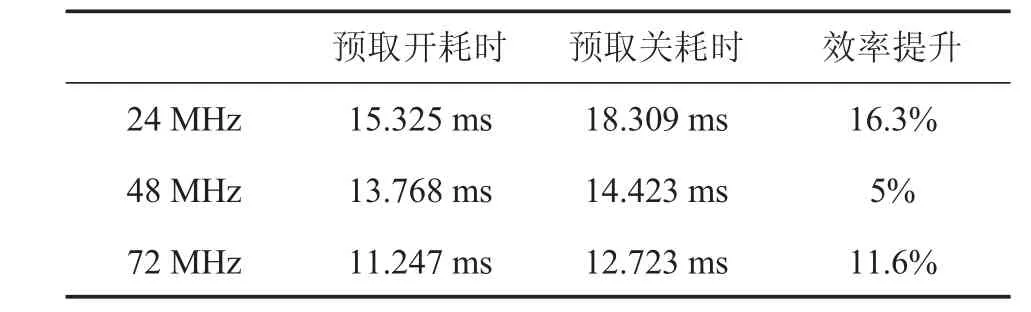
表2 预取开关耗时实验结果表
实验结果表明,时钟频率在24 MHz、48 MHz和72 MHz时(即LATENCY分别为0/1/2),预取开启比预取关闭耗时更少,效率分别提高了16.3%、5%和11.6%。其中在48 MHz时,由于时钟频率刚好为Flash读取速度的两倍,两个时钟周期完成一次读操作,故预取开关耗时相差不大,仅在跳转发生时,预取开具有更高的效率。
搭载本文设计的Flash预取加速控制器的MCU芯片,已完成样品流片和测试,其结果与预期设计一致。
5 结论
本文基于预取和缓存原理,采用位宽扩展技术和改进预取技术相结合的方式,设计了具有预取加速功能的Flash控制器,完成Flash特定接口协议与AHB协议的转换。搭建了SoC仿真实验平台,验证了设计的正确性。实验结果表明,本设计最多提高了16.3%的Flash取指效率,提升了系统性能。同时设计了明确的保护机制以保护用户程序;实现了Flash测试模式与通用串口的通信,提高测试和烧录效率,降低成本。实际样片结果表明本设计的正确性和合理性。
[1]郭炜,魏继增,郭筝,谢憬.SoC设计方法与实现[M].北京:电子工业出版社,2011.
[2]Brewer J,Gill M.Nonvolatile memory technologies with emphasison flash:acomprehensive guide to understanding and usingflashmemorydevice[M].Hoboken:Wiley,2011:19-62.
[3]潘立阳,朱钧.Flash存储器技术与发展[J].微电子学,2002,1:47-52.
[4]刘卫.NAND Flash控制器的设计与验证[D].长沙:国防科学技术大学,2008:23.
[5]Ma D,Huang K,et al.An automatic SoC design methodology for integration and verification[J].Advanced Material Research,2011,383-390:2222-2230.
[6]Cappelletti P,Golla C.Flash memories[M].Kluwer Academic Publishers,1999.
[7]Wong C L.Methods for increasing instruction-level parallelism in microprocessors and digital system[M].US,US6988183,2006.
[8]Aagaard M D,Cook B,et al.A framework for superscalar microprocessor correctness statements[J].International Journal on Software Tools for Technology Transfer,2003,4(3):298-312.
[9]郑文静,李明强,舒继武.Flash存储技术[J].计算机研究与发展,2010,47(4):716-726.
[10]蒋进松.高效的片上Flash加速控制器软硬件设计[D].杭州:浙江大学,2016.
[11]王钰博.嵌入式Flash加速控制器的设计与实现[D].杭州:浙江大学,2014.
[12]AMBA Specification(Rev 2.0)[P].ARM,ARM IHI 0011A.
[13]周立功.ARM嵌入式系统基础教程[M].北京:北京航空航天大学出版社,2008.
[14]Jungwook P,Cheong K,et al.An energy efficient cache memory architecture forembedded systems[C].Proceedings of the 2004 ACM Symposium on Applied Computing.NewYork,USA:ACM,2004:884-890.
