通过经验值提高速度的XML解析算法
2017-03-12周实奇

【摘 要】从XML的属性出发,设计了一套自学习的算法,利用个别报文的解析结果作为经验值,解析新接收到的报文,避免了全量解析XML的CPU消耗,可大幅提高服务响应处理效率。
【关键词】XML解析 自学习 搜索策略树
doi:10.3969/j.issn.1006-1010.2017.02.014 中图分类号:TP301 文献标志码:A 文章编号:1006-1010(2017)02-0068-06
引用格式:周实奇. 通过经验值提高速度的XML解析算法[J]. 移动通信, 2017,41(2): 68-73.
1 引言
随着分布式计算和云计算架构趋势的形成和发展,越来越多的系统需要借助企业服务总线(ESB)进行服务编排、服务路由等处理,将分散的各个业务处理单元的原子服务集成起来,形成业务处理能力,统一对外开放。目前业界流行接口协议,各个处理单元交互主要以Webservices协议为主。
企业服务总线并不涉及业务处理逻辑,但是作为数据交互和服务调度的枢纽,服务的编排和服务路由等相关的处理效率,对整个系统的并发量和吞吐量起决定性的作用。由于处理过程中,需要获取数据包的个别属性字段,例如客户ID、发起方标识等,按目前的通用做法,采用如下方式解析XML数据包。
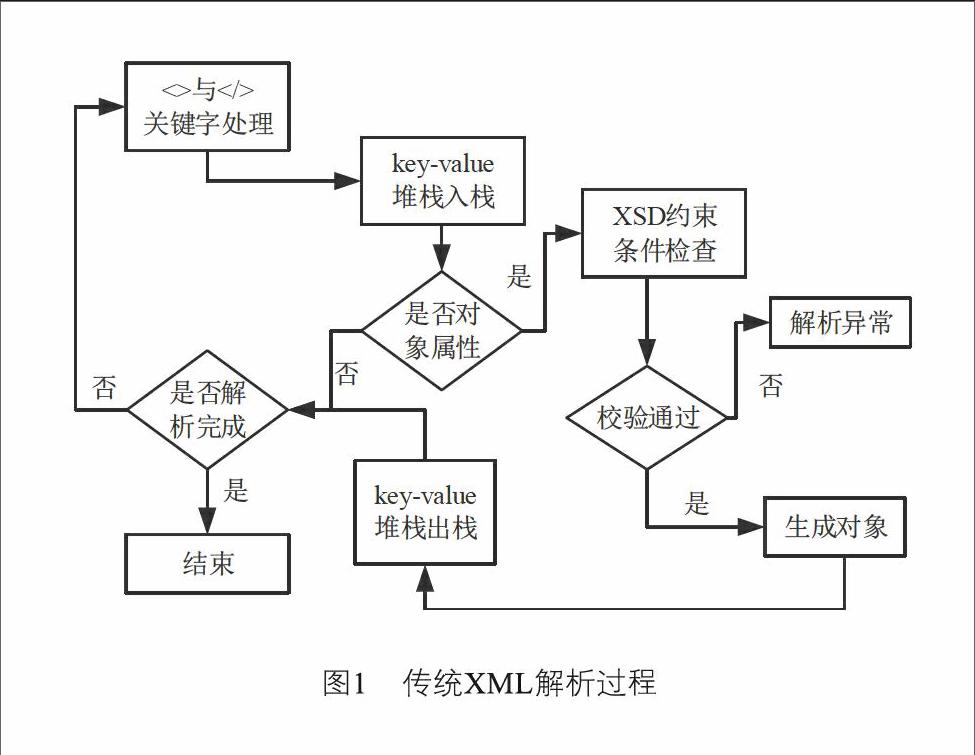
文献[1]、[2]、[3]、[4]的方式,通常将XML数据包整体进行解析,按照XSD定义文件对数据内容进行校验和生成对象的处理方法,通常的处理流程如图1所示:
从以上解析过程中可以得知,在整体XML报文解析的过程中,程序需要遍历整个报文,进行字符串比较操作,同时查找相关的特征关键字。找到关键字以后,需要进行属性的堆栈入栈,并进行属性约束条件检查。同时按照校验结果生成相应的对象。
在ESB企业服务总线等应用場景中,并不进行数据包的业务处理,只是用于路由判断和服务编排等,往往只需要个别的属性值即可,例如只需要请求调用的服务类型和客户ID两个属性值就可以进行服务路由处理。为了获得少数几十个字节,需要遍历处理整个报文,而且处理逻辑复杂,存在提高效率和优化的空间。
在这些应用场景,需要对每一个接入的消息进行服务路由和编排的处理,如果对每个消息报文都要全部遍历,将直接影响系统的整体表现情况,而经过测试,对超过2 k大小的XML协议报文包的解析需要消耗大量CPU计算资源。
文献[5]提供了一种将XML放置到缓存中,加快查询的处理方式。在本文涉及的应用场景中,消息报文已经全部在内存中,需要使用其他方式加快查询。
文献[6]提供了一种将XML建立索引的技术,便于针对个别报文反复多次查询,与本文需要针对多个报文快速查询的方式不同。
目前通过DTD文档生成XML报文,通常采用文献[7]的方法,经过分析可得,相同的属性值的长度如果接近,则ID出现的位置和顺序相对固定,可采用经验策略的方式进行解析。
在应用优化XML解析算法前,需要针对系统中的典型报文进行统计分析,分析相关报文的大小分布情况,以评估优化算法的效果,下面以某系统为例,分析其中报文大小分布情况。
通过对系统中相关Webservices协议包大小进行抽样分析,可以了解到目前接口协议中,相关消息包的大小。抽样方法为选定业务繁忙时段(15:00-16:00),按照协议包的大小,分为5个级别(0-1 k]、(1 k-5 k]、(5 k-10 k]、(10 k-30 k]、(30 k以上),分别统计数量和平均大小,统计结果如表1所示。
按照消息数据总体大小所占的百分比来进行绘图,相关结果如图2所示。
根据以上分析结果,该系统中大量的消息大小集中在10 k左右,平均10.3 k,少量的数据包大小为30 k以上。
本次优化的主要思路是在确保准确性的前提下,基于经验值进行个别属性的解析,同时具备自我学习和调整策略的能力,能适应各种不同的应用场景,适合在企业服务总线和能力开放平台建设过程中,高效进行服务编排和服务路由判断处理等场景。
2 算法描述
为了提高处理效率,本算法主要基于接收到的报文解析的经验值进行解析。经验值作为解析策略,针对不同服务ID的报文分别定义相关的解析策略。解析策略采用冒泡排序的方法进行管理,实现最优的策略最先被采用。策略可以手工清空或者定期清空,以防止长期运行以后,错误的经验值导致整体解析的处理性能下降。与文献[8]不同,本算法主要关注个别的属性,而不是全量解析。
2.1 整体描述
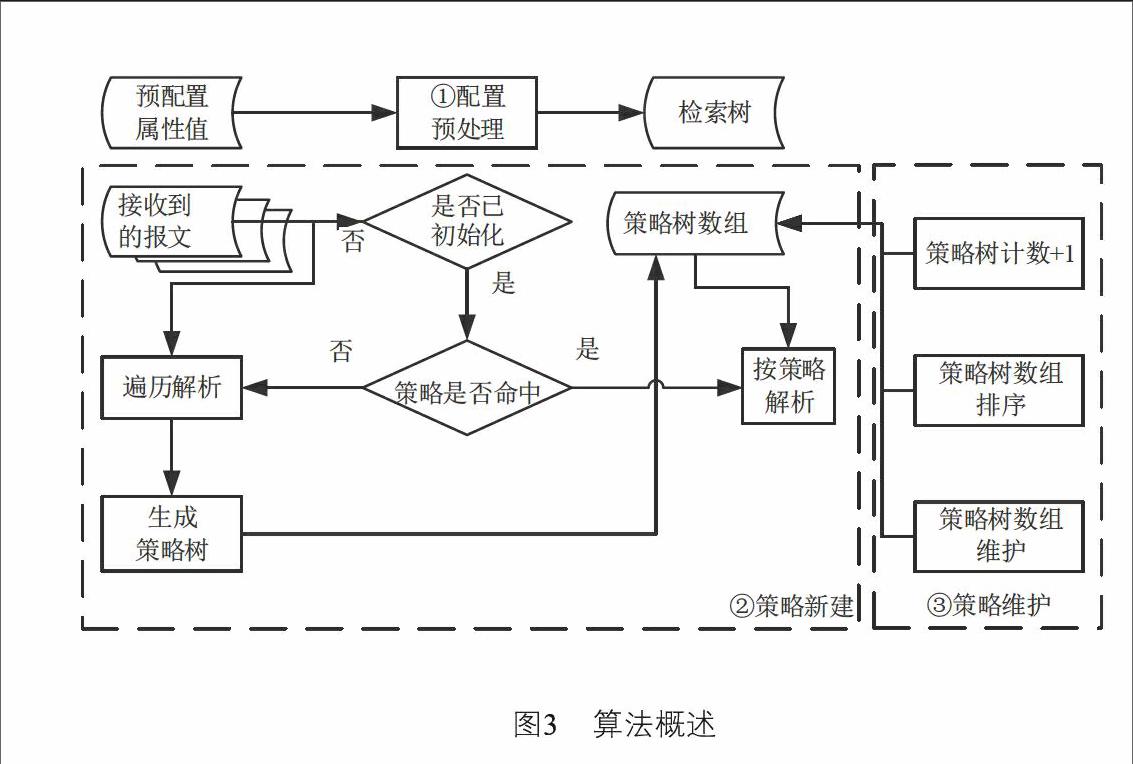
整体上来看,算法分为三大组成部分:
(1)配置关注的属性值,并生成最优搜索路径的检索树。
(2)按照检索树和接收到的报文,进行分析,将相关的经验值保存为策略树,多个不同大小的报文生成的不同策略树保存为策略树数组。
(3)按照接收到报文解析情况中策略的命中情况,调整策略树数组中各个策略树的优先级别;支持手工清除策略树数组和定时清除,以防止旧的经验值无法适应新的情况。
由于算法使用了相对位置,因此无法应用参考文献[9]的并行处理方式,整体结构如图3所示。
2.2 目标属性值的定义与预处理
为了高效处理,对报文只解析关键字段,并不对属性值的约束条件进行判断。首先需要定义关注的属性ID,为提高处理效率,定义了相应的属性ID后,需要对定义的文本进行预处理,形成搜索关键字堆栈树。
目标属性值的定义采用依次罗列XML各个层次对象ID的方式进行定义。
以下为一个例子:
Header, InterBOSS, RoutingInfo, OrigDomain
Header, InterBOSS, RoutingInfo, RouteValue
文献[10]的处理方式,以上文本定义了在服务编排中和服务路由中需要使用到的两个属性,转为伪代码,相应的处理逻辑为:
(1)在报文中检索到
(2)在1的结果之间检索到
(3)在2的结果之间检索到
(4)在3的结果之间检索到
(5)在3的结果之间检索到
根据以上伪代码和定义文本,针对目标属性值定义的预处理流程如图4所示:
为将相同的搜索路径合并,提高处理效率,必须对定义的目标属性值搜索路径进行预处理。预处理的结果为生成搜索索引树,构建搜索树的过程如下:
(1)将多行的目标属性搜索文本进行排序,排序后,相近的搜索路径定义文本出现位置将彼此相近。
(2)读取其中的一行文本定义,拆解其中的属性ID路径,在搜索树中查找是否已经存在对应的节点或者叶子。
(3)如果已经存在对应的节点或者叶子,则不处理,否则新建对应的节点或者叶子。
(4)循环处理一行文本定义的全部属性ID,直到行结束。
(5)循环处理所有文本定义行,直到结束。
按以上处理方式预处理完成后,将生成对应的属性ID检索树,树上的所有叶子节点对应需要输出的目标属性值。由于所有相同的路径已经合并,按此方式检索属性ID不存在冗余操作。
2.3 解析策略新建与初始化
当经验值未建立或者已有的策略搜索失敗,或者策略被手工或者定期清空的时候,需要重新建立相关的策略。文献[11]提供了一种全量路径树的搜索方法,当应用策略失败时,可参考应用进行解析,作为新的经验值。策略新建的过程如图5所示:
首先,按照建立的搜索树建立策略树,策略树的枝叶结构与搜索树相同。按照枝叶结构遍历报文包,同时记下发现关键属性的字符串出现的绝对位置。遍历的过程中,可参考文献[12]的方式进行。
所有的属性ID以及属性Value检索正常以后,需要与现有的策略比对,选择按照报文的比例还是绝对位置新建检索策略树。
如果在原有策略树数组中,命中概率最高的是按比例策略,则新建策略为按比例策略;如果原有策略命中率最高的为按绝对位置策略,则检查是否存在按比例的策略;如果不存在,则新建按比例的策略,否则新建按绝对位置的策略。
如果是第一条策略,则新建按绝对位置的策略。
如果选定新建策略为按比例的策略,则按照检索关键属性ID出现的位置和报文的整体长度,计算出每个属性ID出现位置的比例,保存在策略树中,同时将策略树保存到策略树数组中。
如果选定的新策略为按绝对位置搜索,则报文长度/2=报文长度中值,统计出现在报文长度中值之前的属性ID个数和出现在报文长度中值之后的属性ID个数。按照个数的多少判断是按照报文尾还是报文头的位置计算绝对位置,并将计算结果保存到策略树中,同时将策略树保存到策略树数组内。
2.4 解析报文,同时调整策略树数组的算法
按经验值检索报文的过程中,还需要按照检索的结果不断调整策略树数组,将不同的策略树排列优先级。达到按经验值优化选用策略树的目的。
应用的过程中,采用对策略树数组中的每个策略进行计数,当策略命中一次,则将相关的计数加1,每次策略命中,则与比当前策略更优的策略比较一次,如果计数已经超过了当前更优的策略,则采用冒泡方法,将当前策略向前调整一位,具体算法如图6所示:
先选取出一条策略树,按照策略树的类型和报文长度,计算所有属性ID对应的绝对位置。如果是按比例的策略树,则从报文头开始,按照报文长度*属性ID检索比例的绝对位置计算;如果是按报文头绝对位置检索的策略树,则直接采用属性ID检索位置计算;如果是按报文尾绝对位置检索的策略树,则采用报文长度-属性ID检索位置计算。
计算各个属性ID检索位置以后,则按照计算结果加-10 byte的位置进行字符串比较操作,确定是否在相关的位置出现对应的属性ID。
如果所有属性ID正确检索,则输出对应的key-value值,作为后续处理的依据,同时相关的策略树对应的计数加1,进行策略树数组的冒泡调整。
如果属性ID检索失败,则放弃该条策略,选用下一条策略;如果所有的策略都检索失败,则按照上文的方法,新建对应的策略树。
通过不断调整策略树的优先级以及新增加策略树的方式,策略树数组具备自学习自适应新报文格式的能力。新增加的报文样式,当第一次出现的时候,所有策略树都会检索失败,同时会自动新增一条对应的检索策略树。如果该报文出现的频率足够频繁,一段时间以后,新增的策略树将提到最高的优先级。
为了防止系统长期运行以后,相关旧的策略树计数巨大,导致对新的报文格式一直优先采用旧的策略树进行检索,可以采用手工清空策略树数组或者定期(例如每日或每周)自动清空策略树数组的方式。策略树数组清空以后,会按照目前最新报文的情况自动重建。即用最新的报文情况作为经验值,而放弃原有的长期经验值。
2.5 应用约束条件
算法直接应用原有报文的解析结果,并不对报文进行全文解析处理,所以存在如下的应用限制:
(1)只对XML属性ID进行是否存在的检测,不进行是否唯一以及其他例如数据类型等的检测。
(2)并不适用于数组作为检索对象的情况,因为无法预知算法会匹配上数组中的哪一个对象。
3 对比测试情况
采用四核3.3 GHz的PC服务器,配置8GbDDR3内存,进行测试,测试的数据为生产系统中的业务繁忙时段(15:00-16:00),按时间顺序和流水号顺序,截取各种业务报文1万个,预先读到内存中,采用单机环境,对比使用DOM传统方式输出关键属性字段和使用基于经验值自学习自适应的算法输出关键字段,比较解析包的平均耗时。
相关的报文示例如下:
<?xml version='1.0'encoding='utf-8'?> Envelope xmlns:env="http://www.w3.org/2003/05/soap-envelope"xmlns:xenc="http://www.w3.org/2001/04/xmlenc#" xmlns:wsse="http://docs.oasis-open.org/wss/2004/01/oasis-200401-wss-wssecurity-secext-1.0.xsd"> 0235 ……略…… 配置的3个关键属性ID如下: Header, InterBOSS, RoutingInfo, OrigDomain Header, InterBOSS, RoutingInfo, RouteValue Header, InterBOSS, SNReserve,MsgReceiver 应用两个方法,分别输出对应的属性值,用于比较本算法计算结果的输出值是否正常,即检查本算法的准确性。 由于通用算法与本算法相比,主要消耗系统CPU的计算资源,为了方便比较考虑,本测试均采用单进程和单线程的处理方式,对报文进行串行解析,计算全部解析完成的时间。 3.1 按数据包大小解析对比情况 将采样的数据包按大小分为0 k-1 k、1 k-5 k、5 k-10 k、 10 k-30 k一共4类,將每一类进行比较,测试结果如表2所示。 3.2 按报文时间顺序全量处理对比情况 将采样的数据包,按照流水号的顺序,不区分数据包大小,全量进行解析,测试结果对比如表3所示。 3.3 测试总结 从图7的比较结果来看,使用传统的DOM方式解析XML数据包,随着数据包大小的变化,解析匹配关键字的运算消耗的CPU时间也随即增长,耗时从0.62 ms上升为4.32 ms。而采用经验值的自学习由于使用经验值的算法,不校验报文对象属性的约束条件,同时只解析需要的个别字段,解析过程中直接按照经验值定位,与数据包大小关系并不密切,当数据包从1 k左右大小变为10 k左右大小时,处理耗时从0.21 ms上升为0.32 ms。从耗时的比例来看,效率提升从2.9倍到13.5倍左右,数据包越大,效率提升越明显。 从测试结果来看,适用于数据包大小在1 k以上,处理过程中涉及的属性在5个以内的企业服务总线相关产品应用场景中。 4 结束语 从测试的结果来分析,通过自学习的方式,可以将不同系统间的协议报文解析形成经验策略,并依据策略,避免了全文解析XML的CPU计算资源消耗。与使用DOM的传统方式相比,效率有近10倍的提升。与使用DOM的传统方式相比,解析结果只包含关注的少数属性。 随着体系架构的深入演进,ESB企业服务总线等相类似的处理单元将获得越来越多的重视。在协议路由,服务流程编排等场景下,应用该算法将极大提高系统的整体处理效率,节约处理资源。由于在该场景下,报文的长度和属性值在一段时期内具备高度的相似性,而报文变化后,该算法在不需要人工干预的情况下,也能通过一段时间的运行,形成新的高优先级的解析策略,具备非常广阔的应用场景。在处理过程中只关注少量的属性,而报文各个相关属性值的长度变化较少的场景下,都可以进行应用。 参考文献: [1] 金蓓弘,曹冬磊,任鑫,等. 高性能的XML解析器OnceXMLParser[J]. 软件学报, 2008,19(10): 2728-2738. [2] 孔令波,唐世渭,杨冬青,等. XML数据的查询技术[J]. 软件学报, 2007,18(6): 1400-1418. [3] 陈义,王裕国,杨电怀. XML查询模式发掘[J]. 软件学报, 2004,15(zk): 114-123. [4] 徐如志,钱乐秋,程建平,等. 基于XML的软件构件查询匹配算法研究[J]. 软件学报, 2003,14(7): 1195-1202. [5] 张亮,李然,汪卫,等. XML数据物化模式的生成与优化技术[J]. 软件学报, 2007,18(2): 323-331. [6] 孔令波,唐世渭,杨冬青,等. XML数据索引技术[J]. 软件学报, 2005,16(12): 2063-2079. [7] 王庆,周俊梅,吴红伟,等. XML文档及其函数依赖到关系的映射[J]. 软件学报, 2003,14(7): 1275-1281. [8] 张博,耿志华,周傲英. 一种支持高效XML路径查询的自适应结构索引[J]. 软件学报, 2009,20(7): 1812-1824. [9] 方跃坚,余枝强,翟磊,等. 一种混合并行XML解析方法[J]. 软件学报, 2013,24(6): 1196-1206. [10] 吕建华,王国仁,于戈. XML数据的路径表达式查询优化技术[J]. 软件学报, 2003,14(9): 1615-1620. [11] 高军,杨冬青,唐世渭,等. 基于树自动机的XPath在XML数据流上的高效执行[J]. 软件学报, 2005,16(2): 223-232. [12] 王静,孟小峰,王宇,等. 以目标节点为导向的XML路径查询处理[J]. 软件学报, 2005,16(5): 827-837.★
