大规模古籍文本在中国史定量研究中的应用探索
2016-12-29欧阳剑
欧阳剑

摘要 利用新的信息技术与面向数字人文研究的跨学科方法,采用大数据研究理念对古籍文本进行字词的历时词频分布规律可视化分析,以中国史定量研究为例,对部分中国史的经典宏观理论从量化角度进行了初步验证。认为大数据视域下的技术逻辑和人文逻辑相耦合的数字人文研究为人文社会科学经典理论的验证和拓展提供了更多研究空间与研究方法,有利于推进古籍文献深层次的开发与利用。
关键词 大数据 数字人文 定量分析 计量史 古籍
1.引言
随着“大数据”时代的到来,对大规模历史资料进行定量分析已成为历史学研究中一种新的、行之有效的方法,通过统计分析从大规模数据中挖掘新事实、产生新认识,能够发现靠传统文献阅读无法发现的隐藏在历史文献中的史实与现象。20世纪中期以来,历史学定量分析逐渐成为国际学术研究中的一股新风潮,并服务于学界,现在学者们认为许多不具备数字特征的事物或事件,只要所研究的事物或事件存在特征并能加以量化,同样可进行定量研究,计量史学在经济史、政治史、社会史、人口史等领域研究中取得了很多的研究成果,发挥着巨大的作用。人文学科中的定量研究不仅能通过数据挖掘新发现,更能解释和理解这些发现,进而改变我们固有的历史和社会科学理论与认知。
大数据给了人文学科研究的全新思维。人文学科研究往往会预先设定研究问题或理论模型和假设,然后去寻找相关材料,但部分研究因为材料收集有较强的主观性和选择性,往往倾向于重复确认“已知”,而忽略发现“未知”。因此,很难促进对社会事物整体规律形成统一且有效的认知。而大数据研究思维则不是随机样本,而是全体数据;不是精确性,而是混杂性;不是因果关系,而是相关关系。埃雷兹·艾登(Erez Aiden)等在《可视化未来数据透视下的人文大趋势》(UNCHARTED:Big Data as a Lens on Human Culture)中以“谷歌图书”项目为背景,通过500多万本电子书不同词汇使用频度随时间的变化,讲述了大数据在研究历史文化、人类语言、社会名望、群体记忆等方面的重要作用,凸显了大数据对人文社会科学研究的变革意义。大数据时代的各种思潮和视角在不断涌现,大数据作为一种全新的资料,以其大大超越传统调查数据的样本量和时间跨度,为人文社会科学经典理论的验证和拓展提供了更多研究空间。而基于大数据的定量分析则为人文社会科学研究提供了一个全新的视角,传统人文社会科学的实证研究强调在理论的前提下建立假设,大数据时代重在发现知识与现象,在没有理论假设的前提下去预知,从海量的数据中发现知识,寻找隐藏在数据中的模式、趋势和相关性,揭示事物现象与发展规律,大规模的古籍文献扩大了人文学科资料的范围,提供了人文学科新的研究空间和新的研究可能。
2.大数据视域下的传统古籍文献开发及利用分析
目前,我国古籍文献的数字化已经比较成熟,文字层面的数字化也具一定规模,为古籍的深度开发与利用奠定了基础。古籍文献的统计分析是数字人文研究对古籍深度利用的基本需求,定量分析则是数字人文研究的一种主要研究方式。与传统的定性分析不同,定量分析是依据统计数据,建立数学模型,并用数学模型计算出分析对象的各项指标及其数值的一种方法。因此,定量分析的应用使人文学科研究更趋于科学化。人文学科的研究者对定量分析的需求日趋强烈,研究者不再满足检索结果的简单罗列,更需要从计量学的角度对符合一定条件的古籍文献从作者、文献来源、体裁及年代等多角度进行统计分析。近年来学者在古代诗、词、古代文学及中国史等研究中采用定量研究的趋势更为明显,例如,武汉大学著名词学研究者王兆鹏教授把文献计量的方法成功地引入词学研究中,李伯重教授在史学研究中大量地采用量化方法,李中清教授通过定量方法提出了150年来中国精英出身家庭四个阶段论述,胡俊峰、俞士汶利用统计分析的方法定义了唐宋诗中词汇语义的统计表达,20世纪90年代中期,北京大学开发的古诗研究系统就设置了统计分析的功能,定量方法的使用使得人文学科的研究成果增加了定量的特征,增强了人文科学研究的科学属性。
此外,多元、多角度的对比分析及古籍内容挖掘也是人文学科中数字人文研究所急需的。科学研究可以从多个角度进行对比分析,发现新的问题与现象,寻找隐藏在数据中的模式、趋势和相关性。对于作为史料来源的古籍文献来说,通过文献记载的史实对比,可以考察文献原始出处及后续的演变。哲学上,空间和时间的依存关系表达着事物的演化秩序,时间及空间上的比较分析法是常用的分析方法,它从时间角度和空间角度对事物的发展及变化进行立体式的描述,将是古籍文献深度利用方面的重要方式。而古籍内容挖掘更是人文学科领域深度分析的主要方式。利用文本挖掘技术可以对历史事件的发展等做出宏观的描述,更能准确地还原历史真相,对古籍文献中错综复杂人物关系建立关联,历史人物的社会评价做出客观的判断,对语言、社会及地理等现象进行有效的解释,同时古籍内容挖掘也是古籍数字化知识构建的基础。
随着古籍数字化的进一步发展,更多的学者开始认识到古籍数字化带给我们的不仅仅是海量的古籍文献存储,“数字化”为技术与人文的合流构筑了新平台,更为一个技术逻辑和人文逻辑相耦合的“数字人文”的出现提供了可能。传统的古籍开发与应用模式已难以适应人文学科中数字人文研究的需要,急需研究辅助工具与研究方式的创新与开发。引入大规模定量计算分析方法,构建可持续完善和丰富的数据集和分析工具,充分利用新的信息技术、中文信息处理技术及跨学科方法来对古籍进行深层次的分析与挖掘,对数字化古籍文献所蕴涵的多重信息进行多角度的揭示和重组,这种深度的开发使古籍文献不再是平面的、孤立的资料,而使其构成一个立体的文化学术知识库。
3.大数据视域下的古籍文本可视化分析与挖掘
词汇的时空传播与演化探索,研究意义重大。金观涛与刘青峰的《观念史研究:中国现代重要政治术语的形成》,以十年之功,建立起一个庞大的“中国近现代思想史专业数据库”(1830-1930年),通过核心关键词在历史文献中的统计数据,找到一份中国重要政治术语形成时期的观念史地图,从而跳出传统史学研究被诟病的框架——研究观念起源往往囿于思辨而无法实证。计量史学遭遇的是方法论难题,建设大规模数据集,则可能是逾越“大历史观”、整体史研究与繁芜历史资料间鸿沟的有效办法。如何将这类历史资料进行合理有效的编码和数据集成化,并通过实证分析更好地帮助我们了解社会发展的历史经验和对当下的启示,成为学界需要加强探索和讨论的关键技术课题。
按照马创新、曲维光、陈小荷主张的古籍数字化开发的两个层次来看,显然,以存档和检索为目的的古籍文献表层数字化已取得丰硕成果,而古籍文本可视化分析与挖掘属于深层次的开发,深层次的古籍文献开发主要是古籍知识单元标注及知识网络构建、古籍文献之间的关联、文本内容分析及挖掘等,就目前的数字化古籍文献的开发及利用现状来说,面向数字人文研究的数字化古籍文献的深度利用所面临的主要问题有以下两点:
(1)缺乏有效的对于数字化古籍文献的整合。
目前的古籍文献数字化存在各自为政的状况,由于版权及产权的原因,导致数字化的古籍文献分散于不同公司、不同研究机构中,而且重复建设严重,不仅功能单一,数据也往往只涵盖某一个类别或某一个专题,分散的数据不能实现多元化及整体化的研究对比与分析。而有比较才有鉴别,有比较才有发现,有综合才能发现知识、规律的全貌。大数据时代已经来临,超大规模古籍数据、更多更丰富的古籍文献汇集在一起,可以提供更多、更全面、更准确的资料,满足文、史、哲等各学科研究的需要,对交叉学科来说更是不可或缺。面向数字人文研究的数字化古籍文献整合的目是共享或者合并来自于两个或者更多应用的数据集,创建一个具有更多功能的数字人文研究应用的过程,数字化古籍文献的整合将有利于知识揭示、现象发现,将极大节省研究者的时间,提升研究和创新水平,通过异构数字古籍文献的融合、聚类和重组使资源从数据层的揭示与展现转向信息层、知识层的深度服务,通过将零星的史料片段按一定规则重新组合、排列,对蕴含在古籍中的知识进行多元重组,使不同知识单元之间建立关联,形成一个多维的知识网络,可以帮助研究者发现原有脉络中难以获得的发现与解读。因此,数字化古籍文献整合势在必行,打破古籍数据库建设“小、散、乱”,以及各自为政的模式,已形成学术共识。
(2)缺乏新的数字人文研究范式及方法。
基于古籍文献的语言、文学及历史等人文学科的研究在学术上的突破往往依赖于新材料的发现。虽然数字化古籍文献的使用引发了研究思维的转变,改变了学术前沿的概念,但囿于研究工具及研究手段限制,人文学科研究在创新方面遇到新的瓶颈,在传统研究范式的制约下,使得一些研究项目无法开展,研究视野受到束缚,传统的数字化古籍文献的开发及利用模式难以催生突破式的发现。马克思说过:生产工具促进生产力的发展。同样,先进的研究工具有利于学术研究的发展。新的数字人文研究工具与方法的出现将突破传统的研究范式,古籍文献数字化的广泛普及促进了古籍的利用,大大节约了研究者查找资料的时间,消除了古籍文献独占的客观制约,史料的综合化消除了语言、文学、历史、哲学等学科的材料隔阂,在如今强调各学科协同创新的大背景下,更为人文学科的交叉研究提供了条件。
3.1数据来源
数据和方法是数字人文的两大支柱。数字人文领域的研究使数据驱动(Data-Driven)研究成为热点,数据已成为数字人文研究的基础和核心。大规模古籍文本具有覆盖时空跨度大、材料面广的特点,很大程度上可避免选择资料时的疏漏与偏废,弥补史学家惯用的“选精”与“集粹”研究方法带来的缺陷。古籍文本的收集、整理是大规模数字化古籍文献研究的基础,而对古籍文本语料库的构建主要采取对已有数字化古籍文献整合的方式。大规模古籍数据并不是单一数据很大,其最核心的问题是多源跨域数据的融合,即通过融合不同类别、不同专题的数字化古籍数据的知识来共同解决单一数据解决不了的难题。大规模古籍数据有三个非常重要的层次:数据的获取、数据的描述和数据的分析,在语料库的建设过程中,语料库应该满足三个基本要求:样本的代表性;规模的有限性;机器可读性。因此古籍文本语料库构建应遵循以下原则:
(1)目的性。数字化古籍文献整合的主要目的是为人文学科的研究服务,因此,古籍文本语料库构建需要以研究的适用范围为导向,有针对性地选取多数据进行融合,特别需要收集有一定权威、认可度的高质量数据,实现多数据源的浓缩,帮助降低学者研究时的对比、统计和分析数据的劳动强度。
(2)一致性。古籍数据整合的一致性首先表现在格式的一致性。多来源的数据易导致格式的不统一,因此,存储和处理时必须对数据进行统一的编码格式转换。为了提高电子文本的规范化和标准化程度,1987年美国计算机语言协会(ACL)、美国文学与语言计算协会(ALLC)和美国计算与人文协会(ACH)赞助并组织的文本编码倡议(TEI)为电子形式的文本材料定义了一系列的通用标准,并被世界各国广泛采用。其次,数据内容的准确性也应保持一致性,这样才能提高分析结果的可靠性。再次,数据的分割、统计、分析方法的一致性,在同一标准下进行分析及统计,这样的结果才有可比性。因此,一致性的古籍文献分割、保存、整合、透视和展示方式,可以最大程度地保证研究结果的可靠性、可检验性及再现性,也有利于后期的更新与维护。
(3)多样性。数字化古籍文本语料库是一个庞大的文本文献的集合,主要用于观察、分析和研究文、史、哲等多个学科的需要,不仅仅满足于传统的语言学词汇、语法、语义语用、语体等研究的需要,更需要能满足文、史、哲等多学科和跨学科研究的需要,因此加工深度及标注信息既要反映各种语言学属性,语料也应具有多样性,更应注重多学科的交叉和融合。
(4)共享性。人文研究学者需要的不仅仅是统计分析的结果,他们对原始研究数据也有强烈的需求。传统的研究者常从档案、出版物或者文物等人类文化记录中提取数据,有时可能会花费几个月甚至几年的时间。而语料库将极大节省研究者的时间,帮助他们利用现有数据提出新的研究问题或作为有效的例证。因此,语料库文本数据的共享也是非常必要的。
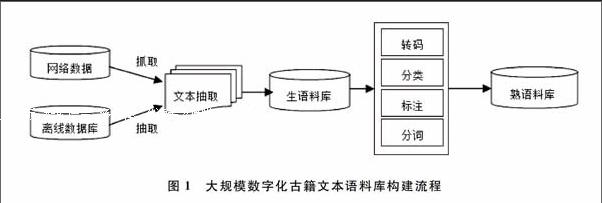
目前,已数字化的古籍文本主要以两种形式存在,一种是网络上的各种专业性论坛或网站,另一种则存储于专业数据库中。从数据收集角度来说,主要来源途径有网络数据采集与专业数据库文本获取两种。然后对获取来的文本进行编码、分类、标注等处理。大规模数字化古籍文本语料库构建过程如图1所示。利用计算机自动、半自动收集的方式,加快了数字化古籍文本建库的速度,为建设大规模古籍文本语料库提供了保障。经过近半年的抓取及抽取,收集、整理了41563种(大约48亿字)数字化古籍本文,涵盖从上古到民国的经、史、子、集等40个类目的文献,覆盖面广且有时间上的延续性,形成了一个比较综合、学科门类全面的数字化古籍文本语料库。
3.2数据处理
构建面向人文学科的分析系统并非单纯将古籍文献数字化,而是需要凭借人文学者对古籍文献的深刻理解,创造性地进行编码、归类和整合。大规模、长时期的数字化古籍文献普遍存在着体量庞大、标注不明确和不同年代同类信息含义有差异等诸多问题。采用灵活、有效的编码方法成为研究历史数据成败的关键。对数字化古籍文献进行系统、合理的分类与编码是开展数据库构建和进行最终定量分析的基础和前提。在进入生语料库之前,数字化古籍文本语料需要经过以下三个数据整理的步骤:
(1)版本挑选。在大规模机器自动采集的过程中,网络采集源的数据质量难以通过机器来判定,因此,通过人工方式对数据整理是不可或缺的,也是为了保证高质量古籍文本语料库的需要。通过人工检查的方式对数据进行整理,去除那些低质量、残缺的数据,挑选出那些高质量的数字化古籍版本,高质量的文本语料更能提高分析、统计的准确性,提高分析结果的可信度。
(2)文本抽取。由于采集的古籍文献的数据来源不同,因此文本的载体格式也呈多样化,采集的数据格式包含PDF、WORD、HTML等多种形式,为了研究的需要,在数据整理及标注前需对采集的数据进行文本数据的抽取及编码转化。文本数据的抽取通过程序自动抽取,抽取过程中把UTF-8、Uni-code、GBK等不同编码转换成统一的Unicode编码。
(3)文本转码。与文本载体格式类似,采集、抽取的文本字体存在大陆简体、古籍繁体及台湾繁体字等三种。不同字体造成了对于以文本为基础的统计及内容分析的困难和复杂性。因此,古籍文本语料采用大陆简体,字体转换采用厦门大学、教育部语言文字应用研究所、北京师范大学联合开发的《汉字简繁文本智能转换系统》进行简繁异体字转换,形成统一的简体字。《汉字简繁文本智能转换系统》采用语料库语言学的研究方法,通过数线性模型(Log-Linear Models)进行简繁字体转换,准确率达到97%以上。
生文本语料的标注也是语料库构建的一个重要环节。古籍文献的准确标注能够使计算机快速准确地找到目标文献,并能有效地建立文献之间的关联。生语料的标注既要适应计算机自动处理的需要,也要考虑到人文学科研究的需要。生文本语料的标注分成两部分,一是对古籍文献的外部特征的元数据标注;二是对古籍文献的内容进行标注。古籍文献的外部特征主要是指文献名称、作者(包含编、撰、注、疏等)、作品年代、著者信息(出生时间、死亡时间、出生地等)、版本信息、作品分类等。古籍文献的外部特征可为数据分析、统计提供必要的信息,例如分析、统计过程中的时间点就是按照作品的作者卒年时间为依据的,在卒年时间不明确或无法考证时即按作品所在的年代为依据(作者的卒年及古籍文本的版本考证是一个难题,存在诸多争议,这涉及史书语料时代性这一老大难的问题,通过相关专业人士的核查将为分析的准确性提供保障)。
在标注古籍文献作者及地理信息时,参考了哈佛大学费正清中国研究中心、台湾中央研究院历史语言研究所和北京大学中国古代史研究中心共同开发的《中国历代人物传记资料库》(CBDB)与复旦大学的《中国历史地理信息系统》(CHGIS),根据研究的具体需要,从前者抽取了作品作者的生卒年代、地理信息等,从后者整合了部分地理信息。通过抽取、整合多个外部数据源,充分利用了外部的已有资源,不但减少了标注的时间,而且丰富了数据内涵,同时准确性及可靠性也得到了保证。
(4)文本切分。词频分析是文本挖掘中的一种重要研究方式,也是文本可视化的一种重要模式。当面对海量文本时,人们需要对每个文本或者整个文本集合的主要内容进行快速浏览,因此需要构建基于词频的文本可视化。常用的思路是将文本看作一个词汇的集合,利用词频信息来呈现文本特征。例如谷歌(Google)实验室推出书籍词频统计器(Books Ngram Viewer)就是以历代词频分析研究为基础而进行的可视化分析。对古籍文献的内容进行标注是数字化古籍文献知识提取和知识重组的关键。对古籍文献的切分必须遵循古代汉语词汇的发展特点,在大规模地对不同朝代的古籍文本进行分词时,采用分朝代、分词汇表的方式切分才符合古代汉语词汇的发展规律。即切分不同朝代的古籍文本语料时采用相应朝代的词汇表,可以最大程度上提升古籍分词的准确率。笔者采用分段叠加的方式,从已有的古代汉语词汇词典及专书中提取词汇,从已有语料中采用统计学的方法自动提取词汇作为补充,以二元(Bigram)模型为主对古籍分词。
3.3大规模古籍文本可视化分析与挖掘
大规模古籍文本可视化分析与挖掘以古籍文本为基础,基于大数据研究理念,采用格拉布斯(Grubbs)法进行数据降噪,最大程度消除问题数据,在分词后的古籍语料库基础上,以词频统计为研究核心对古籍文本进行分析与挖掘,采用单位时间窗口滑动技术对单位时间内的词频进行分析,运用内存实时计算思想很好地解决了读取数据的瓶颈问题。实时统计分析则采用并行计算方式解决了实时查询效率问题,统计分析结果以时间轴为主线的微观散点图和宏观曲线图对进行宏观层次与微观层次展示,并以古籍文献作者为主线,利用地理信息系统(GIS)技术,将我国庞大的、静态的、分散的数字化古籍进行大规模的集成和地图展示,以古籍文献的检索为线索在地图上呈现相关作者的地理分布,实现了实时、在线、立体、可视化、定量分析字词的历史词频分布规律,为研究者构建一个以语言学、历史文献学、历史地理学等人文学科为主的古籍实时统计分析平台。
4.大规模古籍文本可视化分析与挖掘在中国史定量研究中的应用
大规模古籍文献的收集整理和量化数据集是相当有难度的,而更大的挑战来自对历史数据定量分析结果的理解和诠释。大规模古籍文献经过可视化定量分析后,常常有一些“不期而遇”的发现。以大规模数据为基础的量化研究还能较好纠正研究的主观性,实现研究从常见的理论或问题驱动转向数据或经验驱动。运用数学方法对历史资料进行定量分析,使史学研究更趋于精确,大规模的古籍文本其本身就具有重要的历史研究价值。在此基础之上,通过该系统能对一些历史事件与现象作定量分析,使结论的可靠性具有更好的说服力。
武则天一度成为争论最多、留下疑惑最多的一个历史人物,对武则天的历史评价向来毁誉不一。迄今学术界对武则天功过的评价仍然众说纷纭,不仅史学界没有定论,在大学课堂里亦评价各异。在传统研究中,研究者易将“某一或某些例证所反映的现象普遍化”,从而可能丧失真实性,导致研究结果具有一定的不可靠性。通过大规模古籍文献来分析历史文献中对武则天称谓的变化,从中能发现一些有趣的历史现象。由于笔者非历史学专业出身,对问题描述与解析可能会存在一些偏差,需要专业人士来对获得的现象进行更为合理的解读。
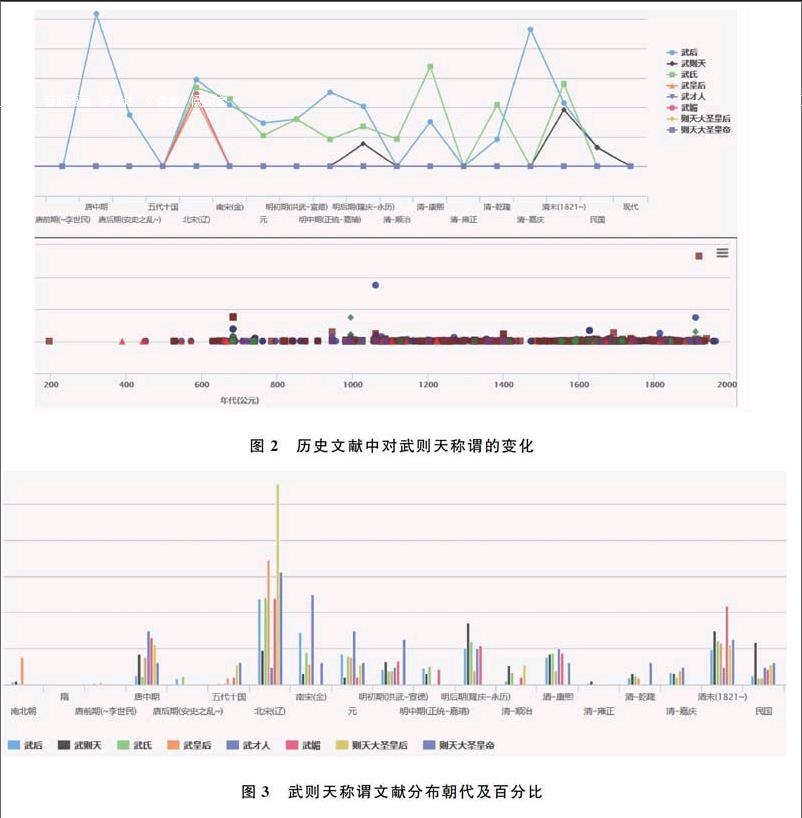
系统统计分析显示,在历史文献中对武则天称谓的总体分布和年代分布如图2、图3所示。从其称谓来看有武后、武才人、武则天、武氏、武皇后、武媚、则天大圣皇后、则天大圣皇帝等,武则天死后,唐人对其的评价曾发生过一些变化,正如王双怀教授所说“唐中宗给武则天举行隆重的葬礼”,睿宗即位后,“对武则天的评价明显降低”,“唐玄宗基本上还是肯定了武则天。”,“盛唐以后的统治者对武则天是相当尊重的”。从词频可以看出,到唐末期很少出现直呼其名的或称其“武氏”,从唐中期到唐末时期基本以“武后”相称,虽然不承认其皇帝身份,但称谓也无有意贬低之意。
五代后,称其为“武氏”的文献开始大量出现,与“武后”称谓不差上下,从大量文献来看,该时段褒贬都有,对武则天任用酷吏、改朝换代的事和武周政治进行了严厉的抨击,“但总的看来,是否定武则天的”。北宋时期,欧阳修、宋祁等人用最恶毒的语言攻击武则天,但是,欧阳修等人只是反对武则天干预朝政、任用酷吏、杀戮宗室大臣以及改朝换代,并不否认她的政绩。及至南宋,人们对武则天的评价越来越低,但也不是都持全盘否定的态度。到了清初,因对异族统治不满,又无能为力,遂借古讽今,但也有文献对武则天的评价是较高的。称其“武皇后”、“武媚”基本上集中在五代十国到南宋,而称其为“则天大圣皇帝”(图4)的基本以史书记载为主,文献分布也比较分散。所有以上记录武后、武才人、武则天、武氏、武皇后、武媚、则天大圣皇后、则天大圣皇帝等称谓的文献作者空间上的聚合分布如图5所示,除了江苏、浙江一带比较多以外,其他地区分布得比较均匀。
对另一个经典的历史思想观念进行验证的是“重学轻术”。中国传统观念一直受“重学轻术”这一思想的影响,学、术在我国古代分别具有不同的含义,按《汉语大词典》、《康熙字典》等的解释,都有不少义项,“学”基本是指钻研知识、获得知识、掌握知识等为主,而“术”则多指技艺、方法。可见,学术在中国古代的知识体系中学是学,术是术,且在传统的儒家思想中学是“儒道之经”,术是“奇技淫巧”。从图6可见,“学”的频率在中国古代文献中要远高于同期“术”的频率,不知是否跟中国古代儒家历来重“学”轻“术”有关,或一定程度上反映了儒家思想对仕人思想的影响。
文学地理学的研究对象是文学要素的地理分布、组合与变迁,文学要素及其整体形态的地域特性与地域差异,文学与地理环境之间的相互关系。文学要素包括文学家、文学作品和文学读者,地理环境则包括自然地理环境和人文地理环境。文学地理学的任务,就是考察不同的自然地理环境和人文地理环境对文学家的气质、心理、知识结构、文化底蕴、价值观念、审美倾向、艺术感知、文学选择等构成的影响。文学与地理环境的关系是一个互动关系。对中国历代文学家的地理分布格局分析是文学地理研究的重要内容。而古籍文献则又是分析的主体。系统提供了古籍作者空间信息可视化分析功能,为文学地理的空间环境分析提供了新的研究工具。
在传统研究中,从地理空间的视角研究文学作品,定量化解析文本中的空间信息是一项繁杂的工作。系统能通过文学作品中词组出现频率来分析其空间分布及方言词分布,提供时间和空间二个维度的分析视角。例如,先秦至西汉年间(公元前2070-公元23年)古籍文献的作者(由于系统目前没有严格按谭正璧主编的《中国文学家大辞典》对属于古代文学家的人物进行标识,故统计分析的是所有古籍文献的作者数据。以下同)主要地理分布如图7。这一时期的作者分布主要在黄河以北地区,在山东与山西境内;东汉至西晋年间(公元23-公元316年)古籍文献的作者主要地理分布如图8,这一时期的作者分布主要中心开始往长江一带转移,以成都、武汉、南京为主;东晋至南北朝年间(公元316-公元581年)古籍文献的作者主要地理分布如图9,这一时期的作者分布主要以南京为主;隋至五代十国年间(公元581-公元979年)古籍文献的作者主要地理分布如图10,这一时期的作者主要分布中心重新北迁,主要分布在黄河中下游地区,以河南、山东为主;宋至清末年间(公元979-公元1911年)古籍文献的作者主要地理分布如图11,这一时期的作者分布区域明显扩大,而且主要分布在沿海及中、东部地区。
从以上古籍文献作者的地理分布图可以看出,古籍文献作者的地理分布是有规律可循的,从周秦到清代中心的分布大体呈现以下规律:
(1)以都城区域为中心分布。都城既是全国的政治和军事中心,也是全国的文化和人才中心,聚集了丰富的教育与经济资源,文化和文学人才兴盛,这种现象在我国古代早期表现更为明显。先秦时期的都城以黄河以北区域为主,此时的作者基本分布在黄河以北区域,东汉至西晋年间都城开始往南迁移,如蜀国建都成都,吴国建都建业(今南京),此时的作者基本分布在长江中下游区域,东晋至南北朝年间的都城也是建业,此时的作者分布以南京为中心,隋至五代十国年间的都城以西安、开封、洛阳为主,此时则以黄河中下游区域分布为主。由此可见,宋朝之前都城区域的变化对作者地理分布影响为主因。
(2)以经济中心分布。黄河中下游流域与长江一带古时是中国的经济重心,最为富庶,这些地区的文人占了全国的绝大多数,经济的繁荣,也带动了教育的发展,这些为文学人才的成长提供了重要的条件。从宋朝开始,长江中下游地区成为经济中心,此时,经济中心对作者地理分布影响成为主因。
(3)文明程度的影响。文化传统悠久、文化根基深厚的地区一旦形成,就有一定的稳定性,不会因政治、经济等外在条件的改变而立刻改变。比如长江下游的江苏、浙江一带,无论朝代的更替都一直保持着文化和文学人才的兴盛。
(4)交通的影响。早期的作者地理分布影响因素主要是都城及经济,从宋朝开始,随着交通的便利,作者地理分布呈现出分散的态势,交通的发达促进了各地经济、文化交流,经济与文化的广泛交流是一个地区文化建设的一种重大的推动力,此时,作者地理分布集中在中国沿海及中、东部地区,而西部地区由于交通因素限制了经济与文化的交流。
以上分析的结果与曾大兴在《文学地理学研究》中的研究成果高度相符。空间信息可视化分析为古籍深层次开发与应用的发展做出了一种探索和尝试,实现了从古籍作品一般信息的统计学分析扩展到古籍信息空间信息挖掘,为文学地理学研究提供了新的视角,也为其他历史、文化地理学等相关学科的研究提供了可参考的案例。
5.结语
大数据视域下的技术逻辑和人文逻辑相耦合的数字人文研究为社会科学经典理论的验证和拓展提供了更多研究空间与研究方法。在人文学科领域,数字化大数据成百上千倍地扩大了资料的范围,无疑有助于人们较为系统、全面地了解已有研究成果。但同时资料总量的快速增涨也给学者带来了巨大挑战,研究所涉及的资料大大超出一般的阅读、分析和理解所能处理的范畴,是以往“不可研究”或“难以研究”的。数字人文分析方法的出现,为人文学科研究提供了新的研究空间和新的研究可能。笔者利用新的信息技术与面向数字人文的跨学科研究方法及研究范式,采用大数据研究理念,对古籍文本进行了历时词频分布规律的可视化分析,并以中国史定量研究为例,对部分中国史的经典宏观理论从量化角度进行了初步验证。大规模的古籍文本定量分析是对古籍文献深层次开发与利用的一种有益尝试。
