Hadoop云平台下基于LATE改进的推测执行算法
2016-05-10高弘博张丰满翟嘉伊
卢 慧,高弘博,张丰满,王 梅, 翟嘉伊,肖 震
(1.成都纺织高等专科学校软件测试中心,四川 成都 611731;2.中国建设银行武汉数据中心,湖北 武汉 430070)
Hadoop云平台下基于LATE改进的推测执行算法
卢慧1,高弘博1,张丰满1,王梅1, 翟嘉伊1,肖震2
(1.成都纺织高等专科学校软件测试中心,四川 成都 611731;2.中国建设银行武汉数据中心,湖北 武汉 430070)
摘要:为解决Hadoop云平台下推测执行算法的不足,基于LATE算法提出一种新的任务进度计算方法,并且采用更细粒度的方式选择执行备份任务的节点。实验结果表明,该算法能够更精准的选定掉队者任务并选择合适的执行节点,缩短作业的执行时间,提高云平台的效率。
关键词:Hadoop云平台LATE算法掉队者任务
随着Internet和Web技术的高速发展,大数据时代已经来临,如何从大数据中获取有价值的信息,成为科研机构和业界的研究热点[1-3]。Hadoop是一个分布式云计算平台, 其核心思想源自于Google公司的MapReduce编程模型和GFS文件系统模型。由于Hadoop的代码开源,目前各大IT公司均采用其作为云计算运行框架,并结合应用需求进行改进,针对海量数据的处理取得了良好的效果。但是在实际的使用中,Hadoop云计算还存在着一些不足[4-5]。
为了进一步提高Hadoop集群的运行效率,减小作业的完成时间,Hadoop系统提供了一种推测执行机制。但是在实际使用中,集群中机器存在一定的异构性,针对异构的集群环境,Hadoop的调度算法还有待改进。通常在同构环境下该机制的确起到了一定效果,但是在实际的生产环境中,由于集群异构等问题,会出现straggler问题[6]。该机制不但没有起到提高作业效率的作用,反而由于过多的执行备份任务占用了过多的资源,影响了整体作业的执行效率。
近年来,相关学者针对Hadoop云平台下推测执行机制提出一些新的调度算法,其中文献[7]提出了一种基于LATE的推测执行算法,该算法采用任务带宽的方式计算任务的剩余时间,并且加入了节省集群资源的策略。但是该算法使用任务的平均速度计算任务的剩余完成时间,会造成掉队者任务的误判断,并且没有考虑执行备份任务的节点的质量。随着Hadoop使用场景的扩展,相关学者随之提出了各种改进的资源调度算法。改进算法的设计目标因需求而异,主要包括降低作业执行时间、提升系统吞吐率、满足作业时间限制、提升数据本地性以及适应异构环境等[8-11]。改进算法的目标不同,且针对的资源调度层次不同,有的是针对作业层改进,有的是针对任务层改进,所以没有一个固定的指标。
针对上述问题,本文提出一种基于LATE改进的推测执行算法,实现更精准的定位掉队者任务并选择更合适的节点执行备份任务。
1Hadoop推测执行算法
1.1推测执行过程
推测执行算法的思路是以空间换时间,同时启动多个相同任务然后选取先执行完毕的任务的结果,这样可以提高任务计算速度。推测执行算法的核心在于选择需要推测执行的任务以及选择在执行推测备份任务的节点[12]。
在Hadoop默认的推测执行算法中,为了判定掉队者任务即执行进度低于平均水平的任务,TaskTracker会实时记录其运行的任务的进度,并周期性的发送给JobTracker。
为了避免落队者任务影响整体作业的运行效率,Hadoop提出了Speculative task机制。该机制的思想如下:在任务运行后,开始对任务的运行进度进行实时预测,如果有任务的进步明显落后与所有任务的平均水平,则判定这类任务为掉队者任务,从而对此任务重新申请资源,针对此任务执行一个备份任务。
推测执行算法分别针对Map任务和Reduce任务提出了进度估算方式。针对Map任务,任务的进度即为当前处理的数据量与输入文件数据量的比值。而针对Redcue任务,则将Redcue任务的三个阶段的等值划分,即Copy、sort、reduce三个阶段各占进度的1/3。算法根据公式(1)计算一个任务的进度,其中 是一个范围为0到1的正数,代表任务的进度值。M为Map任务已经处理的数据量,N为Map任务输入文件的数据量。K为Reduce任务已完成的阶段数。

(1)
通过上述方式即可估算出一个任务的进度,如当一个Redcue任务正处于sort阶段并且已经拷贝了大概一半的数据时,该任务的进度按照公式计算为(1/3)×(1+1/2)=1/2。推测执行算法通过公式(2)计算所有运行任务进度的平均值,根据公式(3)判定任务是否为掉队者任务。如果任务的进度值满足公式(3),其中Threshols默认设为0.2,则认为该任务落后于所有任务的平均进度,判定该任务为掉队者任务。如果判定为掉队者任务,那么当有TaskTracker请求任务时,则会针对掉队者任务执行其备份任务。
(2)
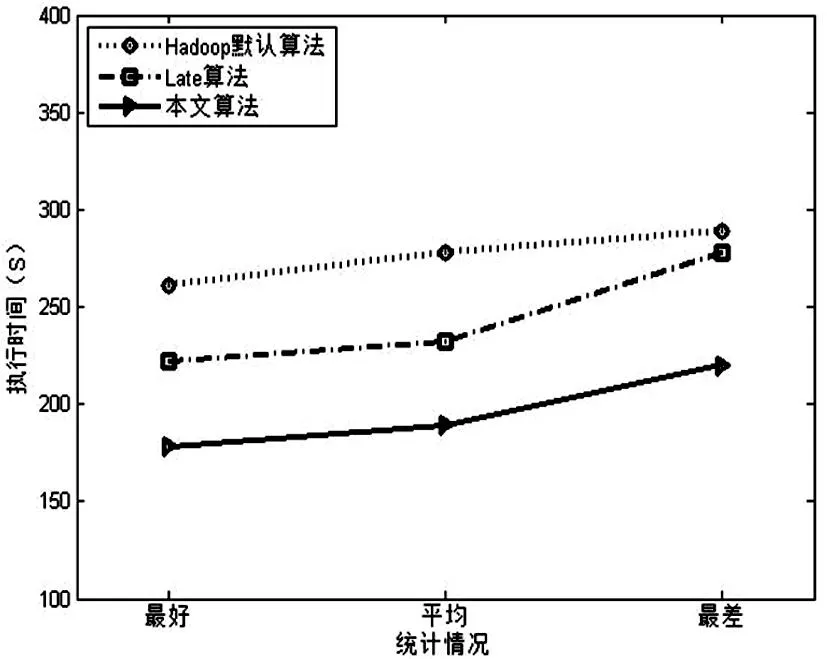
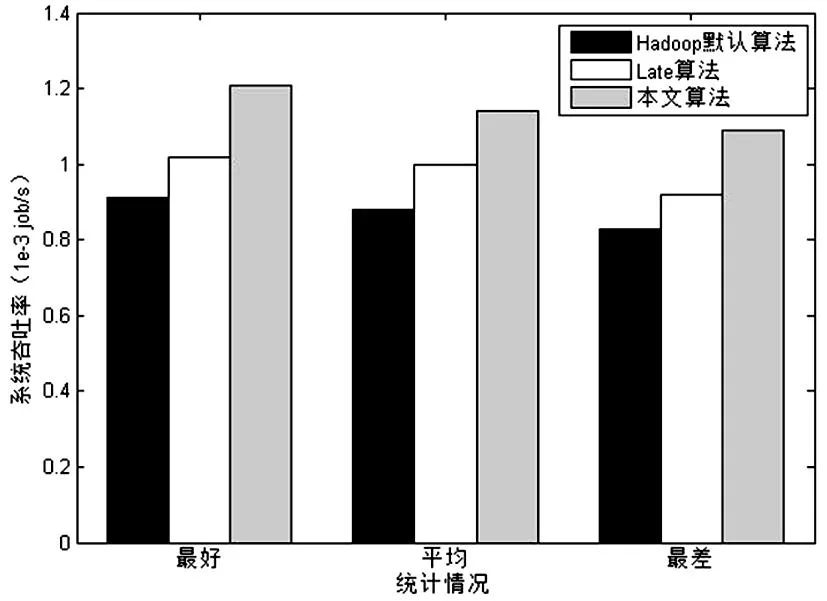
ProgressScorei (3) 1.2Late调度算法 LATE算法是在Hadoop默认推测执行算法的基础上,针对异构集群提出的一种改进算法,其思想是减少默认推测执行算法中执行备份任务的数目,从而降低推测执行带来的不必要的资源消耗。 根据任务的执行进度推测出任务的完成时间,LATE算法中优先执行那些能够在最快时间内完成的备份任务。在LATE算法中设置了如下三个参数,来实现控制备份任务执行数目。 1)SpeculateCap:备份任务总数的阀值。若同一时间内系统中运行的备份任务的总数大于该阀值,则不能进行备份任务的执行; 2)SlowNodeThreshold:慢节点判断的阀值。若节点的处理速率小于该阀值,则判定节点为慢节点。 3)SlowTaskThresHold:掉队者任务判断的阀值。若任务的执行速率小于该阀值,则判定任务为掉队者任务。 LATE算法中根据公式(4)计算任务的运行速率 ,其中 按照Hadoop默认推测执行算法计算,T是任务已经运行的时间。然后根据公式(5)计算任务的剩余时间。 (4) (5) LATE算法的工作流程如下: 1)如果有一个节点请求新的任务,判断全局备份任务数是否大于SpeculateCap值,若大于该值则返回结束推测执行算法,否则进行下一步。 3)对正在执行的任务(不包括已经在备份执行的任务)计算其预计完成时间并排序,选择预计完成时间最小且任务执行速率低于SlowTaskThresHold的任务,执行其备份任务。 2算法描述 2.1估算任务进度 本文算法受到文献[7]的启发,利用TaskTracker记录的任务运行历史信息,计算各作业的任务阶段耗时比例。并且加入自校正的思想,即当有新的任务运行完后,会及时的针对该任务所属的作业进行阶段耗时比例的更新。SMAR算法相对于LATE算法能够更合理的估算出任务各阶段的耗时比例,但是由于其没有考虑不同类型作业的特性、处理数据的大小,会造成估算结果的不准确。本文利用任务运行历史信息的进行了更小粒度的计算,针对每个作业进行阶段耗时比例预估计算。 每个TaskTracker需要在任务成功运行后记录其执行阶段的相关信息,根据任务的类型分为两种:Map任务的执行阶段相关信息MapTaskInfo(JobId,TaskId,MP1,MP2),Reduce任务的执行阶段相关信息ReduceTaskInfo(JobId,TaskId,RP1,RP2,RP3)。其中JobID和TaskID分别是任务所属作业的全局ID号、作业中该任务的ID号。MP1、MP2分别代表Map任务的map阶段和combine阶段的耗时比例,RP1、RP2、RP3分别代表Reduce任务的copy、sort和reduce阶段的耗时比例。每当TaskTracker向JobTracker周期发送心跳信息时,会将TaskTracker上新完成的任务的执行阶段信息一并发送。JobTracker在接受到心跳信息后,会在历史记录模块中添加这些新完成任务的信息,然后更新各任务的阶段耗时比例值,用于任务进度的判断。 每当TaskTracker中有任务运行结束后,会将该任务的运行情况记录为MapTaskInfo或RedcueTaskInfo记录在本地磁盘上,然后发送给TaskTracker。例如MapTask1运行完毕,会将(001,001,0.65,0.35)记录下来并发送给TaskTracker。TaskTracker则会周期性的向JobTrakcer发送心跳信息,JobTracker受到心跳信息后会解析出任务的MapTaskInfo和ReduceTaskInfo。解析出后根据作业ID对各个作业的Map任务、Reduce任务的阶段耗时比进行更新。由于在未有任务完成之前,MP1、MP2、RP1、RP2、RP3采用默认值1、0、0.6、0.3、0.1。当每次JobTrakcer收到心跳信息且MapTaskInfo和ReduceTaskInfo中有内容时则进行阶段耗时比例的更新操作。更新操作的具体方式是对同一作业的Map任务和Redcue任务的同一阶段的耗时进行平均值处理。例如MapTask1运行结束后,由于开始没有其他任务运行结束,则JobTrakcer会对MapTask1对应的001作业的Map任务的阶段耗时比值进行更新,更新为MP1=(1+0.65)/2=0.83,MP2=(0+0.35)/2=0.17。 通过对历史信息的分析与自学习更新操作,可以更加精确的确定各个作业的不同阶段比例耗时。 那么在此基础上,我们可以更精准的计算任务的进度。将Map任务和Reduce任务的进度分开计算,公式如下: MapProcessScorej= (6) (7) (8) 通过公式(6)、(7)可以分别计算出Map中任务和Reduce任务的进度。公式中的任务各阶段耗时比例值由JobTracker通过对任务的历史信息自学习计算得到,N是任务要处理数据中键值对的数目,M是已经处理了的数据的数目。最后,通过根据作业类型由公式(8)可以确定任务的进度。 2.2定位掉队者任务 在Hadoop推测执行算法中,若一个任务的进度值低于所有运行任务进度的平均值,且差值大于一个固定的阈值,则此任务判定为掉队者任务。在LATE算法中通过任务运行的速率对任务的运行时间进行预估,选择剩余时间最大的任务进行备份执行。但是其没有考虑实际运行中任务的不同批次问题。例如一个map任务task1已经运行了90%,预估的剩余时间为100s,同时运行着map任务task2,其实在task1任务运行了一段时间后才获得资源开始调度,运行进度只有30%,预估剩余时间为200s。那么按照LATE算法则会选择task2进行备份执行。这种不考虑任务运行批次的调度方式是不符合实际情况的,不能真正的定位到需要备份执行的strggler任务。本文通过结合任务速率和任务剩余预估时间两个因素,从而完成掉队者任务的判定。 CA153是人乳腺癌患者的组织碎片及细胞质中提取的糖类抗原物质,属于乳腺癌相关抗原, 对乳腺癌患者随诊有一定意义,主要用于治疗后监测乳腺癌患者的疾病复发和转移。有研究表明[9],较高水平的CA153可作为乳腺癌可靠的预后标记,与晚期和复发直接相关。此外,在乳腺癌患者中,CA153的持续升高与HER2阳性相关。CA153也可用于转移性乳腺癌的辅助诊断, 乳腺癌术后CA153阳性率可达80%,肝、骨处转移可引起血清CA153显著升高。CA153对早期乳腺癌的敏感性及特异性较差,可潜在地用于检测高危人群乳腺癌的发生。 在计算任务的运行速率时,本文只考虑正在运行阶段的运行速率。因为已完成的阶段已经没有预估价值,而未进入的阶段则由于过于复杂且有随机性是无法预估的。所以本文只考虑正在运行阶段的速率。 ProgressSpeed=ProgressScore/T (9) 计算完任务的运行速率之后,需要完成任务剩余时间的预估。剩余时间最长(且运行速率小于平均速率)的节点将会获得最高的优先级被执行备份任务。 一个任务的剩余运行时间是所有未完成阶段的剩余运行时间之和,本文将任务的剩余运行时间划分为正在运行阶段的剩余时间和未运行阶段的剩余时间两部分。如果一个任务正运行在阶段cp(current phase),则cp阶段剩余时间由其剩余处理数据量和该阶段运行速率决定。然而,cp阶段之后的各阶段fp(follow phase)的剩余时间很难预估,因为任务还未进入这些阶段。因此,我们使用阶段平均进程速率预估fp阶段的剩余时间。阶段平均运行速率是指进入该阶段的所有进程速率的平均值。如果某阶段没有任何任务已经进入,我们不计算其阶段的时间,这对所有任务都是公平的。由于每个任务处理的数据量不一样,计算fp阶段的剩余时间需要考虑本任务的数据量和已进入该阶段任务的数据量的比例。可以通过公式求导出任务的剩余运行时间: (10) 掉队者任务的选择流程如下: 1)按公式算任务的运行速率,如果运行速率低于所有任务的平均速率,则进行下一步; 2)计算任务的剩余运行时间,将任务按剩余时间由大到小排序; 3)将剩余时间最大的任务判定为掉队者任务。 2.3选择执行备份任务节点 在判定完掉队者任务后,需要对掉队者任务进行备份执行,即在另外一个节点上重新执行该任务。但是由于在异构的环境下,重新执行掉队者任务的节点的性能可能比当前节点的性能更差,则会导致备份任务依旧会是一个掉队者任务。这样不仅不会提升作业的执行时间,反而会消耗系统的可用资源。所以在选择执行备份任务节点的时候应该过滤掉这种节点,下文称之为慢节点。 在实际运行环境中,由于Map任务和Reduce任务运行的特点和阶段都不相同,所以节点执行Map任务和Reduce任务的速率也是不同的。LATE算法中仅仅在判定节点的快慢时没有对任务的类型进行区分,这样对导致备份任务的执行效率。本文针对此问题将慢节点区分为:Map任务慢节点和Redcue任务慢节。 假设一个TaskTracker上运行的Map任务数为 MapNum,运行的Reduce任务数为 ReduceNum。根据公式(11)、(12)可以分别计算出该TaskTracker上Map任务和Reduce任务的平均运行速率。 (11) (12) 假设系统中运行的TaskTracker的总数为TTNum,可以根据公式(13)、(14)分别计算出整个集群中Map任务和Reduce任务的平均运行速率。 (13) (14) 3实验及结果分析 3.1实验环境 本实验集群的硬件采用10台商用测试服务器,其分别部署在三个机架上,采用1gbps以太网连接。 其中,每台服务器上部署了OpenStack云计算管理系统,并且采用KVM软件负责划分虚拟机资源。每个虚拟机配置 2个虚拟核,4gb内存,40GB磁盘空间。由于其具备异构的特点,所以通过在每台服务器上划分不同数目的虚拟机来模拟异构的运行环境,具体如表1所示。 表1 集群虚拟机配置表 3.2不同负载性能验证 本节通过在异构Hadoop集群中运行三种不同类型的作业,对Hadoop默认推测算法、LATE算法、本文提出的ISSL算法进行了实验,并对比分析了实验结果,验证了本文算法在异构环境下能够减小作业的执行时间、有效提升系统吞吐WordCount、Sort、Grep是Hadoop中最典型的三类作业,可以代表Hadoop中最常用的各类作业。本节分别针对这三类类型不同的作业,对Hadoop默认推测执行算法、LATE算法和本文算法进行实验。每一类实验都运行6次,为了减小随机因素的影响,本文对每次实验用例结果的最好、最差、平均情况都进行了统计。由于每次实验中作业类型相同且输入数据量相等,本文和文献[12]采用同样的方式度量系统的吞吐率,即系统每秒处理作业的数量。 3.2.1WordCount测试 WordCount作业用于计算输入文件中各单词的出现的次数,是Hadoop中最常处理的作业。本实验测试用例的输入文件大小为8GB,每隔30s提交一个WordCount作业,一共提交6次。 图1是三种算法执行Wordcount作业的实验结果,其中(a)是三种算法的作业执行时间的结果对比图,(b)是三种算法执行时系统吞吐量的结果对比图。通过实验结果可以发现,本文提出的ISSL算法的在平均情况下,作业执行时间比Late算法、Hadoop默认算法降低了10%,而且相对于Late算法、Hadoop默认执行算法分别提升了5%、6%的系统吞吐率。 在WordCount作业中,本文算法针对作业的执行时间及系统吞吐量两个方面并没有获得很明显的提升。因为作业处理的是纯文本文件,间接数据和最终输出的数据会比较小,所以WordCount作业大部分时间用于在map阶段,即CPU密集型作业。一旦Map任务运行结束,Reduce任务只需要很短的时间。因此,wordcount作业的性能由Map任务的执行效率决定。由于wordcount作业中map任务的平均执行时间只有70s,在快的节点上执行和在慢的节点上执行差异不大,所以导致提升度比较小。 (a)作业执行时 (b)系统吞吐量 3.2.2Sort测试 Sort作业主要是对点击率排序等,其和wordcount作业有着很大的不同,其Map任务会产生的大量中间数据会通过网络传递到Reduce任务节点,同时Reduce任务产生的结果数据也比较大,并需要写到磁盘上。因此,Sort作业属于I/O密集型作业。测试用例采用的得数据集是点击率文件,大小为30GB。每一个sort作业有100个reduce任务,本文每个150s提交一个作业,一共提交3次。 下页图2是三种算法执行Sort作业的实验结果,其中(a)是三种算法的作业执行时间的结果对比图,其中(b)是三种算法执行时系统吞吐量的结果对比图。本文提出额ISSL算法的作业平均执行时间低于LATE算法19%,低于Hadoop默认算法37%。并且本文提出的ISSL算法相对于LATE算法、Hadoop默认算法分别提高了15%、32%的系统吞吐量。 在作业执行时间和系统吞吐量两个方面,本文算法ISSL在处理sort作业时相较于Wordcount作业都获得了很大的提升,主要是由于sort作业中reduce任务的工作量大于map任务,mao任务只占据了整个作业执行时间的一小部分。在map和reduce阶段,本文算法有更多的机会执行高效的推测任务,导致更高的吞吐量。 (a)作业执行时间 (b)系统吞吐量 3.2.3Grep测试用例 Grep作业主要是在输入文件中通过正则匹配找到包含指定串的表达式,当表达式出现的比较频繁时,Grep作业类似于Sort作业,是一个I/O密集型作业;当表达式出现很稀疏时,Grep作业者类似wordcount作业,是一个CPU密集型作业。本用例的测试输入文件大小为23g,每个150s提交一个作业,一共提交3次。 图3是三种算法执行Grep作业的实验结果,其中(a)是三种算法的作业执行时间的结果对比图,(b)是三种算法执行时系统吞吐量的结果对比图。通过实验结果可以发现,在平均情况下,相对于LATE算法、Hadoop默认执行算法,本文提出的ISSL分别降低了39%、48%的作业执行时间,提升了38%、42%的系统吞吐量。 在Grep作业中,map任务工作量大于Sort作业中map任务的工作量,平均执行时间是sort任务的1.3倍。因此,推测执行针对map任务可以取得更好的效果。 (a)作业执行时间 (b)系统吞吐量 通过上述三种不同类型的实验,可以发现本文算法相对于Hadoop默认推测执行算法、LATE算法,均能有效的降低作业的执行时间,提升系统的吞吐率。这些性能的提升主要是由于本文算法通过新的进度估算方式提升了掉队者任务的判定准确性,这样会避免系统执行不必要的备份任务,浪费系统的资源。同时,本文算法相对于LATE算法在选择执行备份任务的节点时进行了更细粒度的区分,使不同类型的任务在最适合的快节点上执行,从而提升了备份任务的执行效率,减小整个作业的执行时间。并且,在多次试验中最差、平均、最坏的情况下,本文算法的性能都优于Hadoop默认算法、LATE算法,证明本算法是非常稳定的。 4结束语 伴随大数据时代的到来,Hadoop云平台的使用场景不断扩展,通过对Hadoop资源调度框架的研究本文构建了资源预估模型,在此基础上对作业调度算法的推测执行算法进行了改进。由于Hadoop的不断发展,下一步将针对实时调度及数据放置策略等进行研究。 参考文献 [1]K Kambatla, A Pathak, and H. Proc. of the First Workshop on Hot Topics in Cloud Computing: Pucha.Towards optimizing hadoop provisioning in the cloud[C]. Washington DC, 2009. [2]林闯,苏文博,孟坤,等. 云计算安全:架构、机制与模型评价[J]. 计算机学报,2013(9):1765-1784. [3]孟小峰,慈祥. 大数据管理:概念、技术与挑战[J]. 计算机研究与发展,2013(1):146-169. [4]H. Chang, M. Kodialam, R. Kompella, T. Lakshman, et al. INFOCOM 2011 Proceedings IEEE :Scheduling in mapreduce-like systems for fast completion time[C]. Inforcm,2011. [5]栾亚建,黄翀民,龚高晟,等. Hadoop平台的性能优化研究[J]. 计算机工程,2010(14):262-266. [6]Daewoo Lee,Jin-Soo Kim,Seungryoul Maeng. Large-scale incremental processing with MapReduce[J]. Future Generation Computer Systems,2013,10:130-139. [7]Huo Tang, Junqing Zhou, Kenli Li, et al. A MapReduce task scheduling algorithm for deadline constraints[J]. Cluster Computing,2013,164:109-112. [8]Wei Dai,Mostafa Bassiouni. An improved task assignment scheme for Hadoop running in the clouds[J]. Journal of Cloud Computing,2013,21:231-240. [9]Ezerra A,Hernndez P,Espinosa A,et a1.Proc of the 20th European MPI Use Group Meeting :Job scheduling for optimizing data locality in Hadoop clusters[C]. ACM Press,2013. [10]Zhuo Tang, Junqing Zhou, Kenli Li,et al. A MapReduce task scheduling algorithm for deadline constraints[J]. Cluster Computing,2013:164-173. [11]Z Guo, G Fox, M Zhou. IEEE International Conference :Improving Resource Utilization in MapReduce[C]. Washington DC ,2012. [12]N Maheshwari, R Nanduri, V Varma. Future Generation Computer Systems :Dynamic energy efficient data placement and cluster reconfiguration algorithm for MapReduce framework[C]. IEEE Computer Society,2012. Improved Speculated Scheduling Algorithm Based on LATE of Hadoop Cloud Platform LUHui1,GAOHong-bo1,ZHANGFeng-man1,WANGMei1,ZHAIJia-yi1,XIAOZhen2 (1.SoftwareTestingCenter,ChengduTextileCollege,Chengdu611731;2.WuhanDataCenter,ChinaConstructionBank,Wuhan430070) Abstract:In order to improve the limitation of speculated scheduling algorithm of Hadoop cloud platform, a new task process algorithm based on LATE was proposed and notes of backup task were selected by adopting more fine-grained way. The experiment results showed that such algorithm could more accurately select the stragglers and choose proper executing mote, shorten executing time and improve the efficiency of cloud platform. Key words:Hadoopcloud platformLATE algorithmstraggler 中图分类号:TP393 文献标识码:A 文章编号:1008-5580(2016)02-0200-07 基金项目:基于云计算的蜀锦蜀绣综合服务平台(2012FZ0081) 收稿日期:2015-12-20 第一作者:卢慧(1970-),女,硕士,高级讲师,研究方向:云计算、大数据分析、物联网。