基于三维坐标的模糊量化情感分类方法
2016-05-04林明明邱云飞邵良杉
林明明,邱云飞,邵良杉
(1. 辽宁工程技术大学 软件学院,辽宁 葫芦岛 125100;2. 辽宁工程技术大学 系统工程研究所,辽宁 葫芦岛 125100)
基于三维坐标的模糊量化情感分类方法
林明明1,邱云飞1,邵良杉2
(1. 辽宁工程技术大学 软件学院,辽宁 葫芦岛 125100;2. 辽宁工程技术大学 系统工程研究所,辽宁 葫芦岛 125100)
针对微博情感分类问题,构造了基于三维坐标的模糊量化情感分类算法,通过将情感模糊量化,对微博进行多情感分类。首先对情感模糊处理,将情感分为六大类,根据六大类,定义并计算句子的模糊情感;其次将情感量化处理,根据情感类别构造三维坐标模型,将模糊情感值作为句子的坐标,通过坐标将句子映射到三维坐标模型中,使其量化;最后通过模糊量化处理后,根据与坐标轴的夹角判断句子最终的情感分类。通过实验,对三个作者的微博进行模糊量化处理,对其情感分类,实验结果的F值达到85%以上,同时与三种经典算法进行对比实验,准确率有了明显的提高。
微博情感;模糊量化;情感分类;模糊情感;三维坐标
1 引言
随着微博时代的到来,越来越多的人有自己的微博,在微博上发表对某件事的看法,表达自己的情感,然而面对大量的微博内容,快速判断作者的情感非常不便,不能在短时间内准确掌握作者的情感,因此,快速判断微博的情感是一个急需解决的问题。近年来,大多数学者只是将微博情感分为积极的和消极的,然而人们的情感并不止这两类,需要对情感进行更细致的分类,所以本文将情感细化为六大类。由于语言和情感的特点,本文提出了将情感模糊量化处理,首先,由于微博情感并不单一,具有多态性,并不能精确判断句子的情感类别,往往一句话中可能包含多个类别,关键看句子更倾向于哪一类别就判断为哪一类别,这就是句子的模糊性,因此将句子模糊处理;其次,又由于情感模糊的复杂性不便于判断,要想确定句子的所属类别,就需要将情感进行定量分析,所以,将句子的模糊性进行量化处理,通过量化计算,将情感进行最终分类。本文提出了模糊量化情感分类算法,构造了三维坐标模型,定义了模糊情感,通过计算词语相似度,将其转化为模糊情感值,根据模糊情感最终确定句子的坐标值,将句子映射到三维坐标中,使句子量化,根据与坐标轴的夹角对微博句子进行多情感分类。通过与PMI-IR[1]算法、贝叶斯算法[2]、K-means算法[3]进行比较,本文算法的准确率有了明显的提高。
2 相关工作
近年来,国内外相关学者对情感分类进行了研究,有些专家通过语义倾向性对情感进行分类,Turney[1,4-5]提出了Pointwise Mutual Information (PMI) and Information Retrieval(IR)算法的语义倾向性方法Semantic Orientation (SO)进行情感分类,以及对PMI-IR算法中的公式进行逐步改进,并且还对SO-PMI和SO-LAS的方法进行了比较。文献[6]在PMI-IR算法中利用两对种子词进行测试,通过搜索引擎的NEAR操作,分别将搜索窗口大小调到10和20进行测试,对手机评论进行了情感分类。文献[7-8]通过PMI-IR算法对中文进行情感分类,前者指出了英文中的分词容易而中文的却不同,还指出中文的种子词不像英文中那么容易选出,后者提出了种子词的选择方法,选出SO值最高和最低的三组词作为种子词对。文献[9]指出了PMI-IR算法的不足并进行克服,只考虑两个形容词“不”和“有点”,通过算法预测形容词的极性。以上都没有针对中文特点进行很大的改动,只是在借助处理英文的特点来处理中文,对中文语言并不是很适用。
除了基于语义倾向性的算法,还有通过词典和相似度等方法进行情感分析,文献[10]构建一个非正式语言词典,或者这些语言不在正式的词典中出现,往往这些词可以判断句子的情感倾向性。文献[11]通过在微博中计算共现概率去学习出候选情感词,改进了词典,通过实验验证抽取的新词汇构建的词典在情感分类中优于两个经典的语料词典。文献[12]基于上下文语义相似度来计算文本语义相似性,由于一些词无法在同义词词典中找到,所以通过Google搜索引擎,搜索两个项的共现概率,从而计算两个项的关系,进而得到相似度。文献[13]提出了情感敏感词典的方法解决交叉领域的情感分类问题。文献[14]提出将动词作为核心元素,确定情感倾向性。文献[15]对电影评论的情感进行二元分类。
以上都是对情感进行二元分类,然而人们的情感并不止积极的和消极的。文献[16-18]将情感细化,文献[16]提出了一种基于PMI-IR算法对博客进行四种情感的分类,喜、怒、哀、惧。但是只考虑了形容词和副词的短语,并不全面。文献[17]用χ2的方法将情感分为五类,生气、高兴、惊讶、憎恨、悲伤。文献[18]将情感分为六大类,愤怒、厌恶、害怕、喜欢、悲伤、惊讶。通过共现概率来计算互信息判断情感。但这些文献对积极类只划分为一个类,并不能很好地表达积极类的情感。
基于以上国内外的研究,本文根据中文语言特点,构造了提取中文语言短语的规则,并且将情感分为六大类,即: 乐、好、忠、怒、哀、惧。将积极类和消极类都分别细化为三类,提出了模糊量化情感分类算法,对微博情感进行分类。
3 情感分类
人们的情感总体分为两大类,积极的和消极的,然而,这两大类情感并不能很好地表达人们的喜怒哀乐,所以本文将情感细化。到目前为止,心理学家和语言学家对情感做了不同的划分[19-22],因为人类的情感非常复杂,不容易界定,所以并没有一个统一的标准对其划分。之前有学者将“惊”作为一类[17-18],本文没有将“惊”作为一类,因为,“惊”可以代表积极的,也可以代表消极的,单从“惊”类的词无法判断句子的情感倾向性,并且“惊”是由其他情感所导致,或许是高兴的,或许是愤怒的,因此,本文没有将“惊”单独划分一类。根据众多学者对情感的分类,以及根据后文三维坐标模型建立的需求,本文将情感分为六大类: 乐、好、忠、怒、哀、惧。其中,乐、好、忠为积极的类,怒、哀、惧为消极的类。这六大类可以代表人们的基本情感类别。分类结果如表1所示。
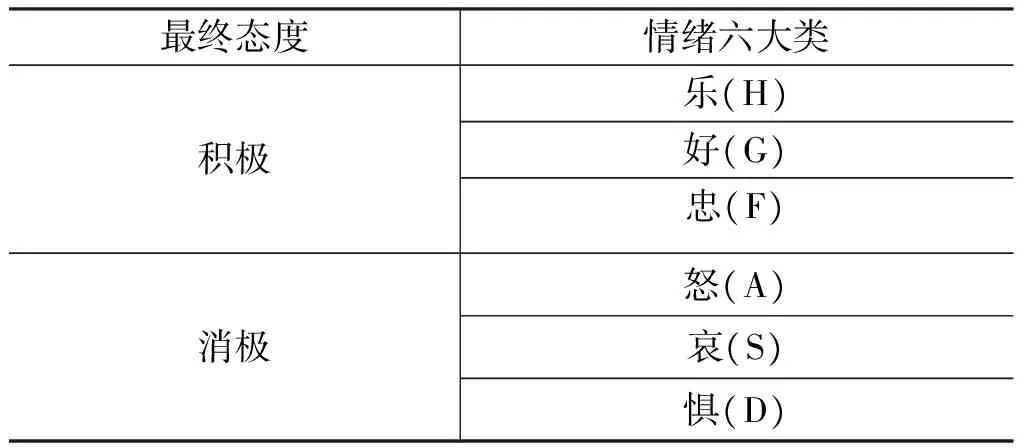
表1 情感分类表
4 模糊情感
4.1 模糊情感定义
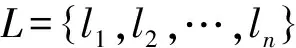
本文并没有直接考虑句子中词语的词义进行情感分析,而是从词性入手,对于句子li,带有感情色彩的都是形容词、副词或动词等短语,而数词、代词等词或短语并不能表达情感,所以要确定句子的模糊情感值,首先要提取句子中表达情感的短语,尽可能地将具有情感倾向性的短语筛选出来,同时尽可能地不筛选出非情感短语,然后确定短语模糊情感值。Turney提出了五种英文短语的规则[1],但并不适合中文,因此文本根据中文语言的特点,通过词性标注,定义提取中文短语的规则如表2。
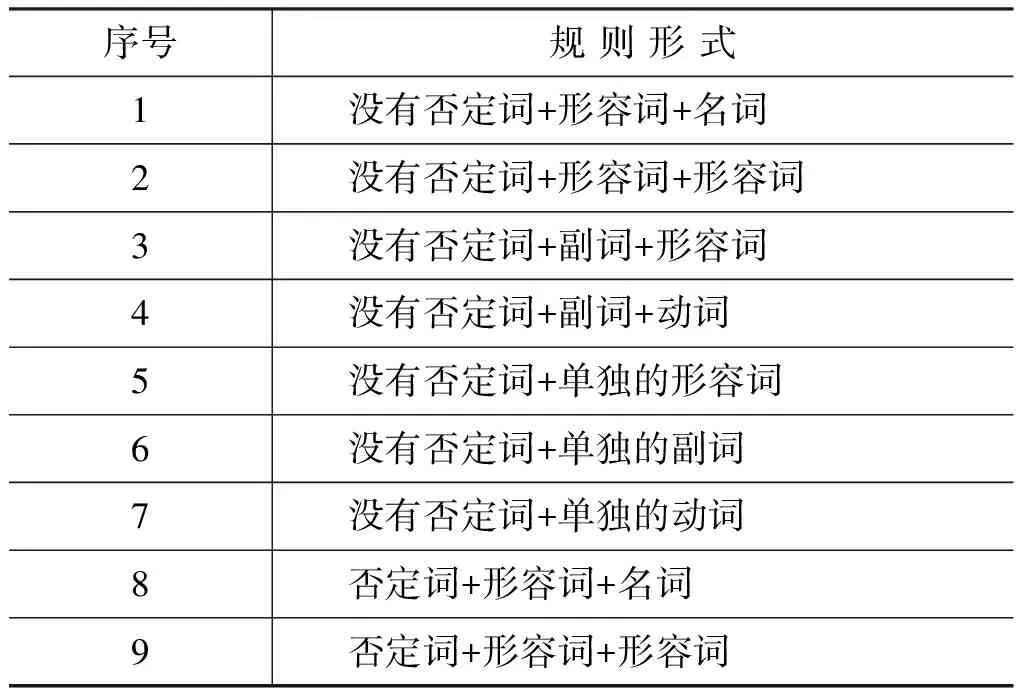
表2 提取中文短语规则

续表
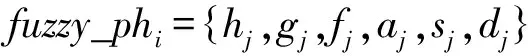
4.2 模糊情感计算
本文根据词语的相似度确定模糊情感,计算每个句子中表达情感的短语与每一大类的种子词的相似度来确定每一大类的模糊值,Turney提出的PMI-IR[5]算法计算词语相似度的方法如式(1)所示。
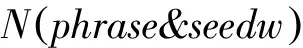
根据模糊情感定义,公式(1)所计算的值显然不适合做模糊情感值,因为根据对数函数的性质,函数图像过(1,0)点,自变量小于1时,函数值为负数,根据公式中的比值意义,结果必然小于1,那么,自变量的值越大,函数值的绝对值越小,也就是说共现次数越大,所占的比重越小,不符合模糊情感的定义。因此,为了使对数值都大于零,本文将函数向左移一个点,使其过(0,0)点,这样在自变量大于零时,函数值单调递增并全部大于零。所以文本定义公式(2)计算词语相似度。
(2)
在搜索引擎中搜索词语时,搜索的结果是包含搜索短语的全部结果,这其中,前面带有否定词的短语也会包含在搜索结果中,如果带有否定词,整个词语及句子的意思就是相反的,这样的结果并不是所需要的,因此搜索时要避免结果中包含否定词。设not为否定词,phrase-not表示搜索词去掉前面的否定词,seedw-not表示种子词去掉前面的否定词,这样搜索的结果更真实。
根据公式(2),首先需要选择种子词,本文将情感分为六大类,所以,需要选择六大类的种子词,由于每一大类单单一个词语并不能明确代表一大类,并且不同的种子词在搜索引擎中出现的次数不同,因此共现次数就会有所影响。为了使每一大类的种子词出现的次数大致相同,本文选择种子词集代替种子词进行计算,只有保证每一大类的种子词集单独出现的总数相同,才能确保短语与每一大类种子词的共现次数有可比性,因为,如果某一大类种子词单独出现的次数很少,那么共现次数就会更少,而如果另一大类种子词单独出现的次数很多,那么共现次数的机会就会很多,所以必须保证每一大类的种子词集单独出现的总数相同,计算的结果才有可比性。由于每个词单独出现的次数不同,为了使每一大类种子词集单独出现的总数相同,所以每一大类的种子词集的个数不同,例如,“怒”类中的词单独出现的次数相比“乐”类少很多,因此“怒”类的种子词集个数比较多,本文通过Google搜索引擎搜索,每一大类种子词集单独出现的总数为3 500 000左右。种子词集如表3所示。
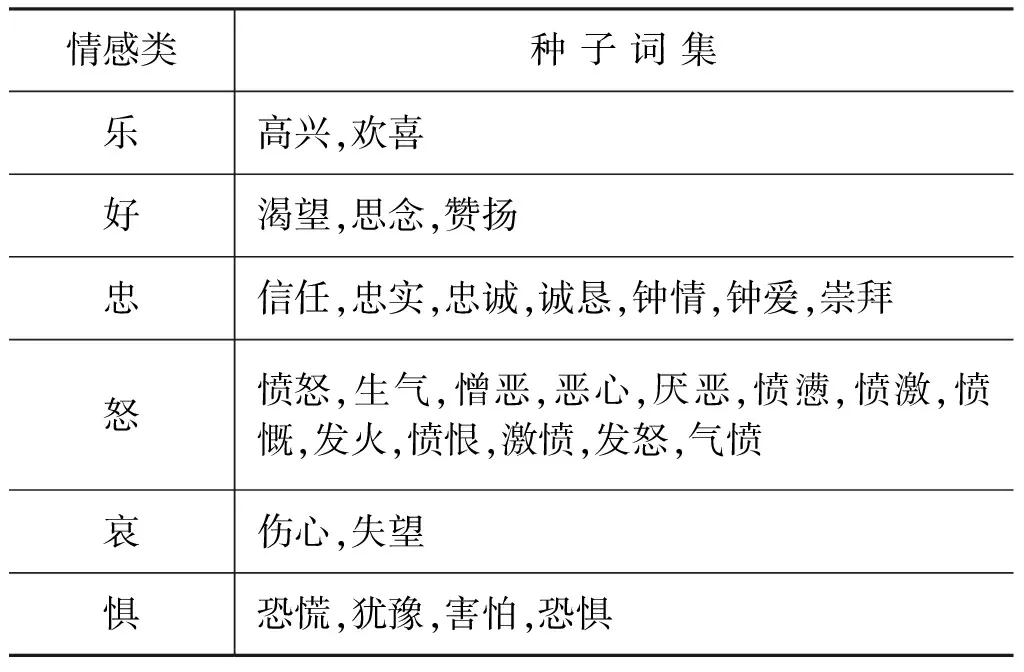
表3 种子词集表
设“乐”类种子词集为集合LE={高兴,欢喜},“好”类种子词集为集合HAO={渴望,思念,赞扬},“忠”类种子词集为集合ZHONG={信任,忠实,忠诚,诚恳,钟情,钟爱,崇拜},“怒”类种子词集为集合NU={愤怒,生气,憎恶,恶心,厌恶,愤懑,愤激,愤慨,发火,愤恨,激愤,发怒,气愤},“哀”类种子词集为集合AI={伤心,失望},“惧”类种子词集为集合JU={恐慌,犹豫,害怕,恐惧}。
由于将种子词集代替种子词计算,并且各个类的种子词集单独出现的总数大致相同,所以可以将公式(2)简化为公式(3),设CLASS为六大类其中的一个类,s_class为相应类别的种子词。
(3)
确定句子li的模糊情感fuzzy_li,首先要确定li中phrasej的模糊情感fuzzy_phj。根据公式(3)和种子词集得到公式(4)计算phrasej的模糊情感值,其中,s_le,s_hao,s_zhong,s_nu,s_ai,s_ju分别为乐、好、忠、怒、哀、惧的种子词。
(4)
根据phrasej的模糊情感定义及phrasej和li的关系,li的模糊情感可以写为
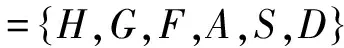
其中,n为句子中提取出情感短语的个数,再根据公式(5)计算li的模糊情感。
(5)
通过计算可以确定句子li的模糊情感fuzzy_li={H,G,F,A,S,D}的各个值。为了更准确地得到句子属于每一大类的程度,本文将句子映射到坐标中。
5 三维坐标模型
由于人们的情感非常复杂,不容易准确分类,所以要将情感进行清晰的度量,即量化处理,通过三维坐标模型,准确将句子定位到坐标中,使句子情感量化,进行情感分类。根据表1对情感的分类,将“乐、好、忠”分别作为X,Y,Z的正半轴,将“怒、哀、惧”分别作为X,Y,Z的负半轴,正半轴和负半轴的类并不需要是一对反义类,因为本文将正半轴和负半轴分开计算,二者互不冲突。三维坐标模型如图1所示。
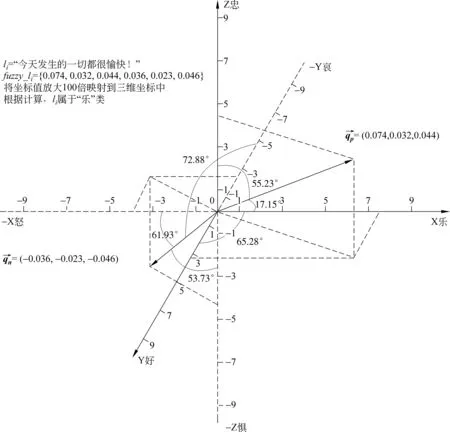
图1 三维坐标模型图
根据模糊情感的计算,li的每一类的模糊值都不是零,并且都是正数。根据式(5),共现次数越大,PMI值越大,就越接近这个类,因此将PMI值作为句子的三维坐标值。本文将积极类和消极类分开计算,设句子的积极向量为qp,消极向量为qn。根据三维坐标的特点,设句子正半轴的坐标为:xp,yp,zp,负半轴的坐标为:xn,yn,zn。对于正半轴,将“乐、好、忠”的模糊值赋值给正半轴的坐标,即:xp=H,yp=G,zp=F,对于负半轴,将“怒、哀、惧”的模糊值相反数赋值给负半轴的坐标,即:xn=-A,yn=-S,zn=-D。将正半轴的三个坐标值作为积极向量qp,负半轴的三个坐标值作为消极向量qn,因此确定句子的积极向量为qp=(xp,yp,zp),消极向量为qn=(xn,yn,zn)。
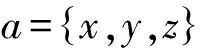
(6)
(7)
如果通过公式(6)和(7)分别求句子积极向量和消极向量与坐标轴的夹角,这样算出的积极夹角和消极夹角无法进行比较,只能将积极的夹角和消极的夹角分别比较,这样无法确定句子的最终情感倾向,如果要将积极和消极夹角同时比较,公式中的分母必须一样,因此将余弦值公式(6)和公式(7)改为公式(8)和公式(9)。
(8)
(9)
将分母进行统一,这样才可以将积极和消极进行比较,通过公式(8)和公式(9)可以求出向量qp和qn与X,Y,Z轴的单位向量求余弦值。再通过余弦值,根据公式(10)和公式(11)求出与各个坐标轴的夹角。
(10)
(11)

如图1所示,句子li为“今天发生的一切都很愉快!”,经过计算,得到fuzzy_li={0.074,0.032,0.044,0.036,0.023,0.046},因此,li的qp=(0.074,0.032,0.044),qn=(-0.036,-0.023,-0.046),为了便于在图中便于表示,将li的坐标值放大100倍,这并不影响计算结果,qp与X,Y,Z轴的夹角分别为: 17.15°,65.28°,55.23°,qn与X,Y,Z轴的夹角分别为: 118.07°,107.12°,126.27°,即qn与X,Y,Z轴的补角分别为: 61.93°,72.88°,53.73°,因此,minjiao=17.15°,maxjiao的补角为53.73°,所以该句子判断为积极类的“乐”类。通过三维坐标模型,将句子映射到其中,直接将句子定位到坐标中,如果不映射到坐标中,无法比较句子属于某一类别的程度,所以通过夹角,不仅得到句子的类别,而且还能得到属于某一类别的程度,即越接近坐标轴越属于某一类,最终可以综合看到整个坐标中句子分布情况,实现了对句子情感进行量化处理,通过情感量化,对情感分类。
6 模糊量化情感分类算法
首先,对句子进行分词,然后去掉停用词等噪声,再根据表2提取短语。本文根据中科院的ICTCLAS对微博句子集L={l1,l2,…,ln}分词,并进行词性标注,根据表2提取短语的规则提取出每句中表达情感的短语phrasej。
然后,确定模糊情感。借助Google搜索引擎中的高级搜索模式,根据公式(4),计算每个phrasej的模糊情感fuzzy_phi={hj,gj,fj,aj,sj,dj},通过li中每个phrasej的模糊情感值,根据公式(5)计算每个li的模糊情感fuzzy_li={H,G,F,A,S,D}。
第三,确定qp和qn。根据得到的模糊情感值确定积极向量qp和消极向量qn。
第四,确定minjiao和maxjiao。根据公式(8)和公式(9),计算li的qp和qn分别与X,Y,Z轴的单位向量的余弦值,再根据公式(10)和公式(11)计算li与每个轴的夹角,得到正半轴的最小角minjiao,和负半轴的最大角maxjiao。
第五,比较并确定类别。如果minjiao较小,该句子为积极类中相应最小角的类,反之,为消极类中相应最大角的类。
具体算法步骤如算法1所示。

算法1 模糊量化情感分类算法
7 实验
7.1 模糊量化情感分类算法实验
本文通过新浪API获取了三个作者的新浪微博,第一个作者的微博为2353条,第二个作者的微博为995条,第三个作者的微博为1564条。两名实验员同时对三名作者的微博进行情感标记,取出标记相同的微博作为实验数据,取第一个作者的2085条微博,第二个作者的789条微博,第三个作者的1247条微博进行实验。如果对大规模文本进行实验,需要用联机处理,因为本文的数据量相对较小,单机就可以进行实验。
通过模糊量化情感分类算法,对三个作者的微博分别进行情感分类。分类结果如表4所示。
根据表4,三个作者的微博正确分类结果与人工标记对比图如图2所示。
从图2可以看出,作者1和作者2积极情感的微博要多于消极情感的微博,作者3消极情感的微博要多于积极情感的微博。从这三个图中可以看出,“乐”和“好”的准确率要比其他类别低,因为这两个类别很相似,一句积极的话中往往“乐”和“好”的模糊值会很相近,因此,会把“乐”的句子误判为“好”类,也会把“好”的句子误判为“乐”类。
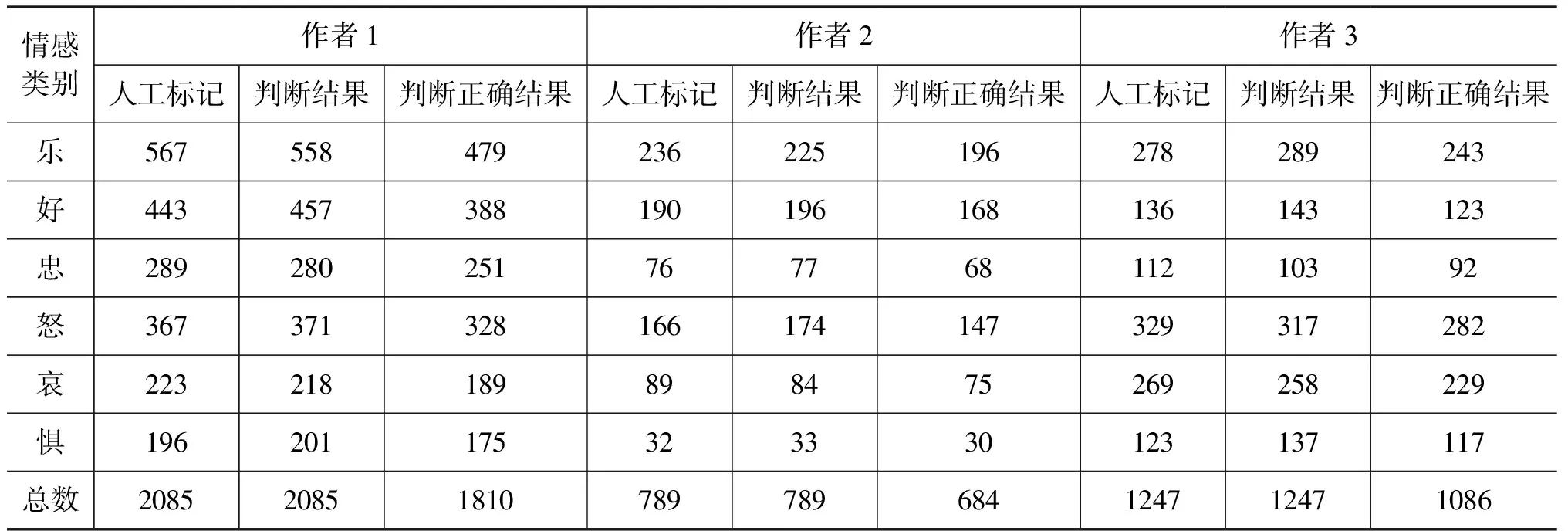
表4 实验结果表
图2 正确分类与人工标记对比图
7.2 对比实验
为了说明本文的先进性和有效性,本文将模糊量化情感分类算法与几个经典的分类或聚类算法进行比较,本文分别和PMI-IR算法、K-均值聚类算法,朴素贝叶斯方法进行比较,三种方法的结果如表5所示。
(1) PMI-IR方法: Turney提出的PMI-IR算法,根据本文提出的选取中文短语的规则,以及本文选取的种子词集,根据PMI-IR算法对三个作者的微博进行情感倾向性判断。
(2) K-均值聚类: 根据本文构造的方法提取每句话的情感倾向性短语,同时将本文选取的种子词作为初始聚类中心点,根据K-均值聚类方法对3个作者的微博进行情感倾向性判断。
(3) 朴素贝叶斯方法: 根据本文构造的方法提取每句话的情感倾向性短语,本文将三个作者的微博语料库,对每一类别平均分成五组,进行五倍交叉实验,依次选取每一类中的一组作为测试集,其他的作为训练集,进行朴素贝叶斯分类。
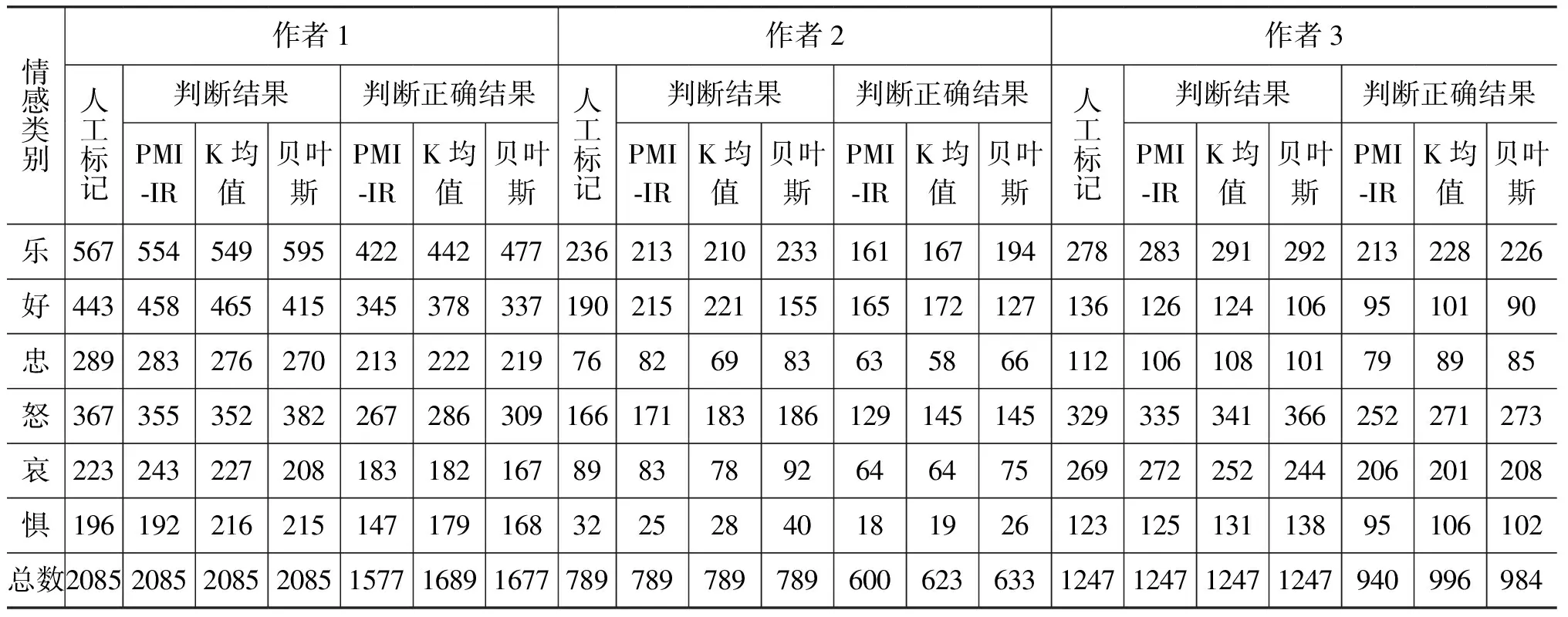
表5 对比实验结果
7.3 实验评价
为了验证本文的全面性和准确性,评价标准采用准确率(Precision)、召回率(Recall)以及F值(F-measure)用来评价整体性能。根据算法特点,本文对准确率、召回率和F值进行定义。
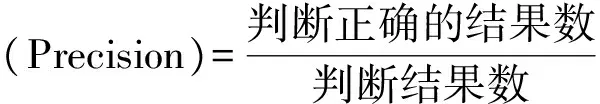

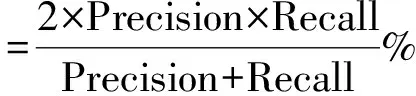
根据定义,本文的算法和三种经典的方法准确率比较如表6所示。
根据定义,本文分别用四种方法计算三个作者的准确率,召回率和F值的平均值如图3,图4和图5所示。
从图3和图4可以看出,本文的准确率和召回率都高于其他三种方法,结合准确率和召回率,本文通过F值综合评价试验,从图5可以看出,本文的F值都达到了85%以上,而PMI-IR方法用本文提取中文情感短语的方法平均F值达到了75%左右,K-均值和贝叶斯方法基本都达到了80%以上,所以,可以看出本文的方法可以有效地判断出微博的情感。
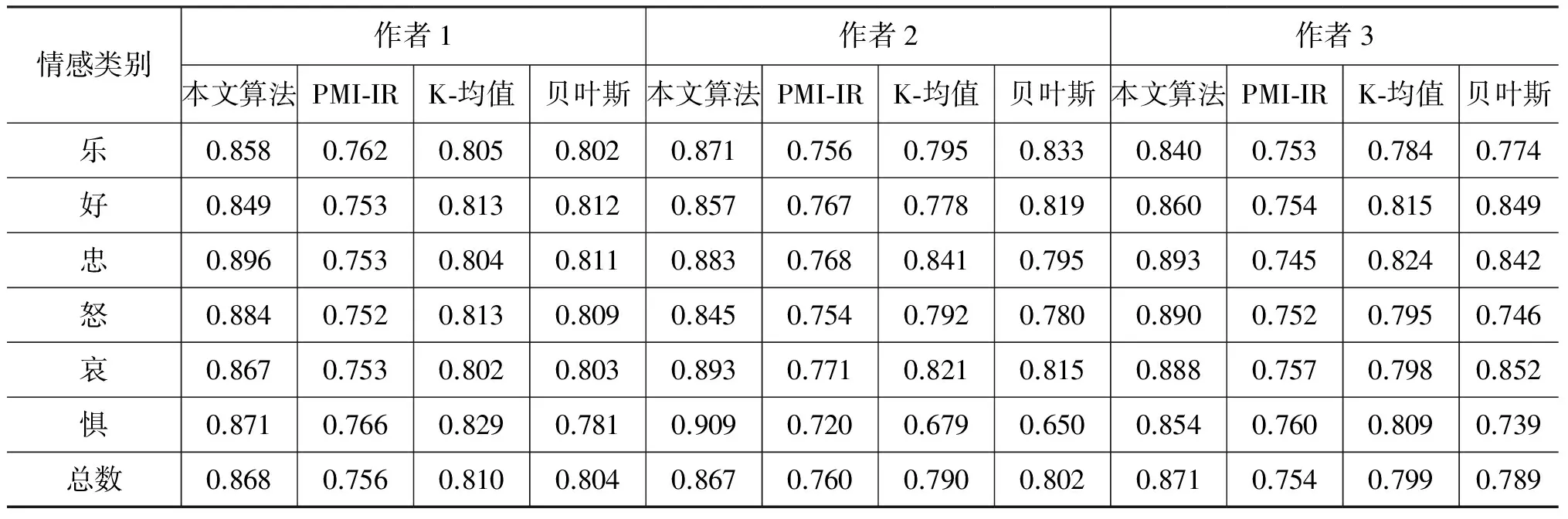
表6 准确率比较表
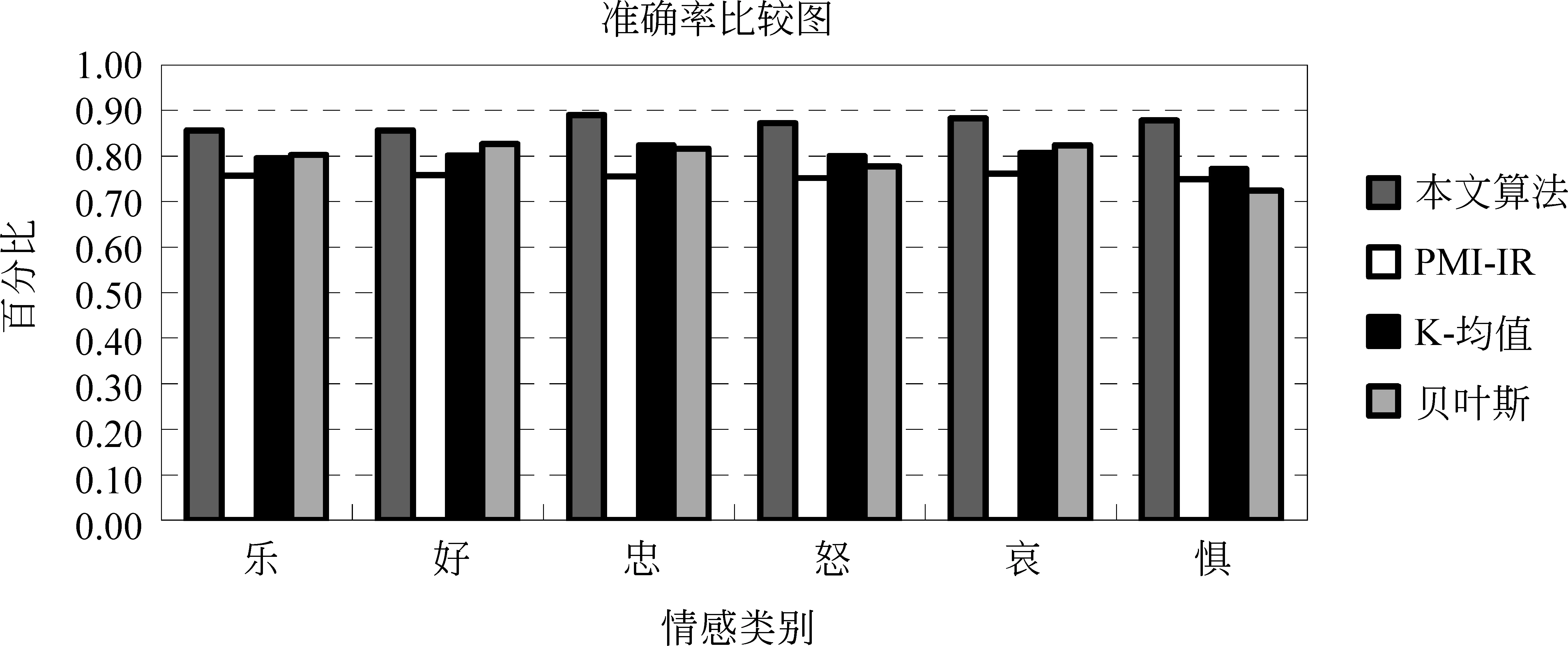
图3 准确率结果图
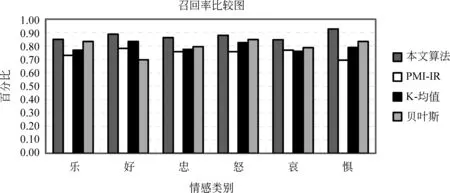
图4 召回率结果图
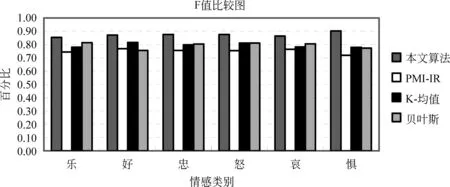
图5 F值结果图
8 结论
由于微博数量剧增,根据微博内容自动判断作者的情感是一个急需解决的问题,并且人们的情感非常丰富,所以不能只将情感分为积极的和消极的,因此本文将情感类别细化,分为六大类,即: 乐、好、忠、怒、哀、惧,提出了基于三维坐标模型的模糊量化情感分类算法,对微博进行多情感分类。由于中文语言的复杂性,并不能精确判断句子的情感类别,需要将句子模糊处理,而要想确定句子的所属类别,只有将句子的模糊性进行量化处理,才可以将句子进行计算判断。本文根据六大类情感,提出了模糊量化情感分类算法,构造了三维坐标模型,通过句子的模糊情感值将句子映射到三维坐标中,使其进行定量计算,最终判断句子的情感类别,实现了句子的模糊量化处理。通过实验,F值达到了85%以上,与其他三种方法进行对比实验,准确率有了明显的提高,因此,该算法可以有效地将情感分为六大类。
[1] Turney P D. Thumbs up or thumbs down?: semantic orientation applied to unsupervised classification of reviews[C]//Proceedings of the 40th annual meeting on association for computational linguistics,2002: 417-424.
[2] Domingos P,Pazzani M. On the optimality of the simple Bayesian classifier under zero-one loss[J]. Machine learning,1997,29(2-3): 103-130.
[3] Huang J Z,Ng M K,Rong H,et al. Automated variable weighting in k-means type clustering[J]. Pattern Analysis and Machine Intelligence,IEEE Transactions on,2005,27(5): 657-668.
[4] Turney P D. Mining the web for synonyms: PMI-IR versus LSA on TOEFL[C]//Proceedings of the 12th European Conference on Machine Learning. Springer-Verlag,2001: 491-502.
[5] Turney P D,Littman M L. Measuring praise and criticism: Inference of semantic orientation from association[J]. ACM Transactions on Information Systems (TOIS),2003,21(4): 315-346.
[6] ZI-qiong Z,Yi-jun L I,Qiang Y E,et al. Sentiment classification for Chinese product reviews using an unsupervised internet-based method[C]//Proceedings of the IEEE,2008: 3-9.
[7] Ye Q,Shi W,Li Y. Sentiment classification for movie reviews in Chinese by improved semantic oriented approach[C]//Proceedings of the 39th AnnualHawaii International Conference on. IEEE,2006,3: 53b-53b.
[8] Shi L,Jun-zuo Y,Qiang Y. An experimental research on sentiment classification of Chinese reviews by semantic orientation method[C]//Proceedings of the IEEE,2008: 3999-4004.
[9] Xu G,Huang C,Wang H. Automatically Predicting the Polarity of Chinese Adjectives: Not,a Bit and a Search Engine[M]//Chinese Lexical Semantics. Springer Berlin Heidelberg,2013: 453-465.
[10] Cui A,Zhang H,Liu Y,et al. Lexicon-Based Sentiment Analysis on Topical Chinese Microblog Messages[M]//Semantic Web and Web Science. SpringerNew York,2013: 333-344.
[11] Feng S,Wang L,Xu W,et al. Unsupervised Learning Chinese Sentiment Lexicon from Massive Microblog Data[M]//Advanced Data Mining and Applications. SpringerBerlin Heidelberg,2012: 27-38.
[12] Martinez-Gil J,Aldana-Montes J F. Semantic similarity measurement using historical google search patterns[J]. Information Systems Frontiers,2013: 1-12.
[13] Bollegala D,Weir D,Carroll J. Cross-Domain Sentiment Classification using a Sentiment Sensitive Thesaurus[J]. IEEE Transactions on Knowledge and Data Engineering,2012.
[14] Karamibekr M,Ghorbani A A. Verb Oriented Sentiment Classification[C]//Proceedings of the IEEE,2012,1: 327-331.
[15] Shi L,Jun-zuo Y,Qiang Y. An experimental research on sentiment classification of Chinese reviews by semantic orientation method[C]//Proceedings of the IEEE,2008: 3999-4004.
[16] Duan X,He T,Song L. Research on sentiment classification of Blog based on PMI-IR[C]//Proceedings of the IEEE,2010: 1-6.
[17] Ning Y,Zhu T,Wang Y. Affective-word based Chinese text sentiment classification[C]//Pervasive Computing and Applications (ICPCA),2010 5th International Conference on. IEEE,2010: 111-115.
[18] Kozareva Z,Navarro B,Vázquez S,et al. UA-ZBSA: a headline emotion classification through web information[C]//Proceedings of the 4th International Workshop on Semantic Evaluations,2007: 334-337.
[19] 林传鼎.社会主义心理学中的情绪问题[J].社会心理科学,2006,21(83): 37-62.
[20] 许小颖,陶建华.汉语情感系统中情感划分的研究[C]∥第一届中国情感计算及智能交互学术会议论文集.北京: 中国中文信息学会,2003: 199-205.
[21] Ekman P. Facial expression and emotion[J]. American Psychologist,1993,48(4): 384-392.
[22] Zhang Y,Li Z,Ren F,et al. Semi-automatic emotion recognition from textual input based on the constructed emotion thesaurus[C]//Proceedings of 2005 IEEE International Conference on.2005: 571-576.
Three-dimensional Coordinate Based Fuzzy Quantification for Sentiment Classification
LIN Mingming1,QIU Yunfei1,SHAO Liangshan2
(1. School of Software,Liaoning Technical University,Huludao,Liaoning 125100,China;2. System Engineering Institute,Liaoning Technical University,Huludao,Liaoning 125100,China)
A fuzzy quantification based on the three-dimensional coordinate is presented for microblog sentiment classification. Firstly,we define and divide the microblog sentiment into six classes,and calculate the fuzzy sentiment. Secondly,we construct the three-dimensional coordinate based on the sentiment classes,and mapped the sentences into the three-dimensional. Finally,we decide the sentiment classification of the sentence according to the angle between the sentence and axis. Through the experiment on classifying three authors’ microblogs,the F-measure reaches more than 85%,outperforming three classical algorithms.
sentiment of microblog; fuzzy quantifying; sentiment classification; fuzzy sentiment; three-dimensional coordinate

林明明(1989—),硕士研究生,主要研究领域为数据挖掘、情感分析。E⁃mail:glcylin@163.com.邱云飞(1976—),博士,教授,主要研究领域为数据挖掘、情感分析。E⁃mail:qyflntu@163.com.邵良杉(1961—),博士,教授,主要研究领域为数据挖掘、情感分析。E⁃mail:lntushao@163.com.
2014-01-17 定稿日期: 2014-06-09
国家自然科学基金(70971059);辽宁省创新团队项目(2009T045);辽宁省高等学校杰出青年学者成长计划(LJQ2012027)。
1003-0077(2016)03-0152-11
TP391
A
