计算语义合成性综述
2016-05-04王超超熊德意
王超超,熊德意
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
计算语义合成性综述
王超超,熊德意
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
随着自然语言处理技术的飞速发展,单纯在语法层上的研究已经不能解决目前的问题,语义层的研究逐渐成为热点。计算语义合成性作为语义学的关键部分,受到了诸多研究人员的关注。计算语义合成性的研究方法可以分为两大类: 语言学方法和分布式方法。该文详细介绍了它们各自具有代表性的工作,着重阐述了近年来使用广泛的深度学习方法在计算语义合成性研究中的应用,并对这两种方法进行了比较;然后对计算语义合成性在情感分析以及机器翻译中的应用做了细致分析;最后,展望了计算语义合成性未来的研究趋势。
语义合成;自然语言处理;分布式方法;深度学习
1 引言
自然语言在语言学上一般被划分为四个层次: 语音文字层、语法层、语义层和语用层[1],目前对于前两层的研究相对比较成熟,越来越多的研究人员开始聚焦于语义层的研究。计算语义合成性作为语义层研究的重要组成部分,可以利用单词的语义信息合成短语乃至句子的语义信息,从而进一步扩大语义信息的表示范围。因此,近年来计算语义合成性在人工智能、自然语言处理的诸多领域得到了广泛的应用[2]。
计算语义合成性是一个古老的概念,最早可以追溯到柏拉图,他在一次对话中指出: 一句话由名词和动词组成,如果动词能够表示名词当前正在执行的动作,则这句话是正确的[3]。换句话说,柏拉图阐述了语义合成性的一般原则,即每句话都具有一定的结构;每句话中的各个部分都具有不同的功能;这句话的意思由它的各组成部分的意思所决定。
1892年,德国著名哲学家、逻辑学家Frege[4]正式提出了计算语义合成性的概念: 合成表达的语义由它的各组成部分的语义以及连接它们的规则所共同决定。它是形式语义学的一个基本原则,也是允许语言使用者们理解他们从未听过的短语和句子语义的一个基本原则。形式语义学以数学为工具,利用符号和公式精确定义和解释语言的语义,强调语义解释和句法结构的统一。1995年,Partee等人[5]进一步阐述了计算语义合成性的概念: 整体语义是部分语义通过函数运算并按一定的语法规则组合在一起而得到的语义表示。因此,目前计算语义合成性的工作主要集中于发现更好的单词表示以及更好的合成规则这两个方面。了解单词的语义以及各个单词之间的连接规则,人类可以很容易识别句子的语义和创造新的句子,但是对于计算机这仍然是一件非常具有挑战性的工作。
纵观国内外研究人员关于计算语义合成性的研究现状,根据所处阶段的不同以及单词表示方法的不同,我们将计算语义合成性的研究方法分为以下两大类[6-7]。
(1) 语言学方法: 采用语言学方法进行计算语义合成性的研究主要起源于Montague等[8]的工作,包括诸如λ演算等符号逻辑表示的方法[9]。这些语言学方法在语义学研究中发挥了重要的作用,它们将语言学的研究方法与计算语义合成性的原则有机结合,使得我们可以用组合的方法分析语法与语义之间的对应关系。但是采用语言学方法仅能简单表示已知子表达式利用合成规则所得到的合成表达式正确与否,并不能明确表示单词、短语以及句子的语义信息,同时也不能对结果进行定量分析[2]。
(2) 分布式方法: 近年来有关计算语义合成性的研究多基于分布式方法[10]。分布式方法在单词表示、识别单词之间的语义相关性以及处理合成性等方面取得了显著进步,有效克服了采用语言学方法进行语义合成性研究时所出现的表达能力弱、不便于计算等问题。
对比发现,分布式方法比语言学方法在计算语言合成性的研究中有更具体的单词表示,且采用了更简单的合成运算方法[4]。使用分布式方法获取到的短语和句子的语义信息,可以更方便地应用于情感分析以及统计机器翻译等诸多自然语言处理的任务中。
本文第二章详细介绍了语言学方法在计算语义合成性研究中的应用,第三章详细介绍了分布式方法在计算语义合成性研究中的应用,第四章比较了计算语义合成性研究中的语言学方法与分布式方法,第五章举例阐述了近年来计算语义合成性在情感分析以及统计机器翻译领域的应用。最后总结了计算语义合成性的研究现状并展望了未来的研究方向。
2 语言学方法
根据Montague等[8]所提出的方法,使用语言学方法进行计算语义合成性研究必须具备以下两个先决条件: 拥有能够提供单词与逻辑表达形式相对应的逻辑词典;能够提供正确的语义合成规则。针对第二点,Bach等[11]提出了一种规则到规则的假设,即在语法和语义之间存在着一种映射关系,可以利用语法层的合成运算来近似表示语义层的合成运算。
λ演算最早由Church等提出用来研究函数定义、函数应用和递归的形式系统[12]。在确定语法规则的基础上,使用λ演算能有效进行语法层的合成运算,因此根据Bach等提出的规则到规则的假设,可以将λ演算应用于语义层的合成运算。以文献[2]所举的实例为例,假如要得到“Every car runs”的合成语义表示,首先从逻辑词典中获取每个单词的语法类型和逻辑表示形式即λ表达式,如式(1)所示。
a.everyDet:λP.λQ.∀x[P(x)→Q(x)]
b.carN:λy.car(y)
(1)
c.runsVerb:λz.runs(z)
其中,逻辑词典为存取所有单词语义信息的逻辑形式的集合,λ表达式为用λ运算符约束每一个变量的数学式。(1a)表示一个限定词的语义逻辑表示形式,λP、λQ起到了占位符的作用,并不表示具体值,这些未知的变量可以用一组实体词替换;(1b)表示一个实体名词的语义逻辑表示形式,y为它的一个特征,通过后续语法基础上的进一步处理可以对它进一步量化,例如y可取为ford,则该表达式表示ford类的car;(1c)表示一个不及物动词的语义逻辑表示形式,z为它的一个特征,假设z也取为ford,而ford确实有runs的属性,则runs(ford)的语义是正确的。在单词逻辑表示的基础上,依据语法规则生成如图1所示带有词性特征的简单语法树。
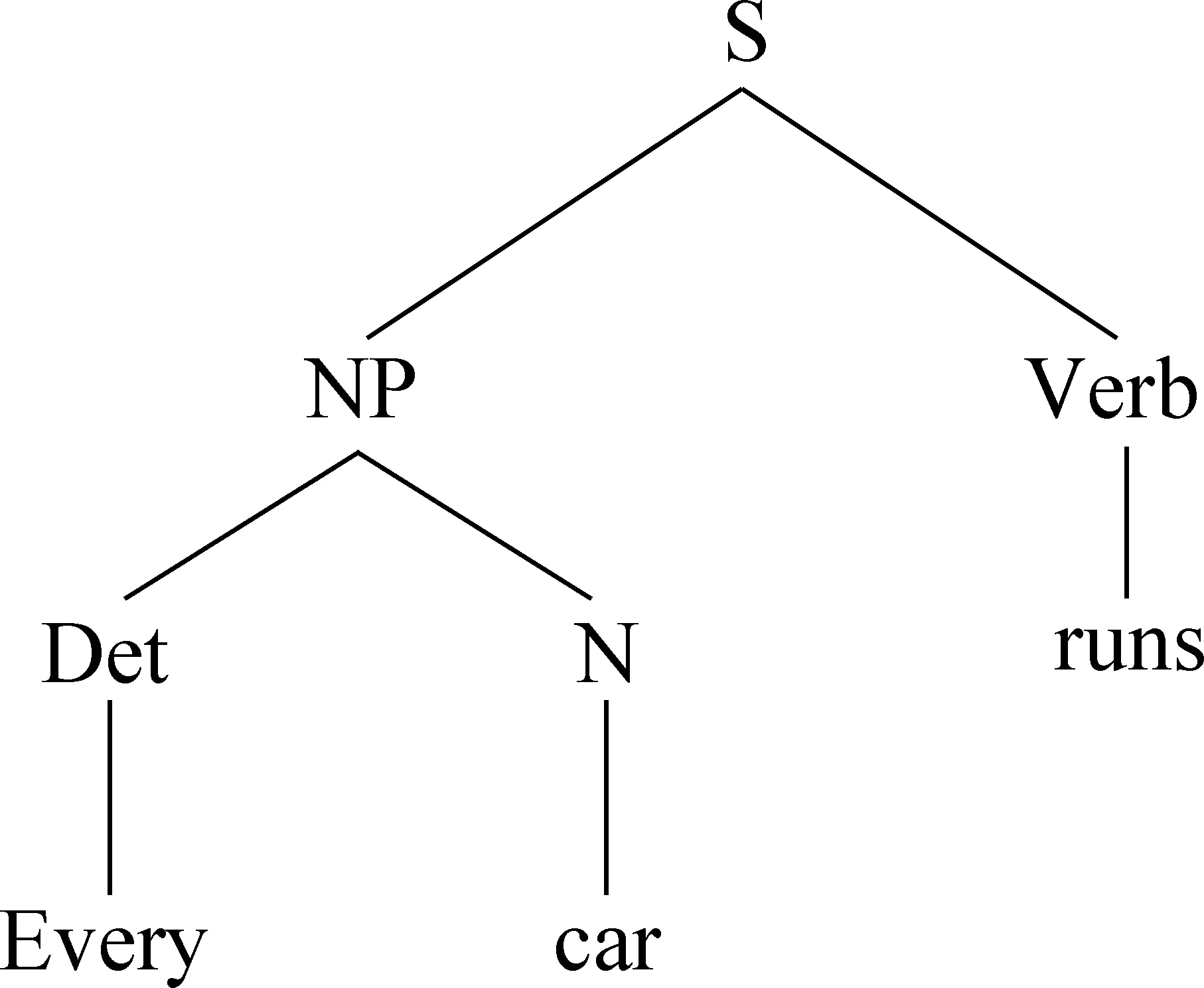
图1 “Every car runs.”的简单语法树
从图1所生成的语法树中可以获取两个简单的合成运算形式,合成运算(1):Det+N→NP,由限定词与名词合成一个名词短语,其具体的计算过程如式(2)所示。通过使用β-归约获取名词短语的语义逻辑表示形式,所谓β-归约名用一个简单的逻辑表达式替换较复杂逻辑表达式中的变量,最终得到它们合成表示的更简单的逻辑表示形式。首先用(1b)替换(1a)中的变量p,再用x替换(1b)中的变量y,通过两次β-归约最终得到名词短语的逻辑表示形式。
λP.λQ.∀x[P(x)→Q(x)](λy.car(y))
→βλQ.∀x[(λy.car(y))(x)→Q(x)]
P:=λy.car(y)
→βλQ.∀x[car(x)→Q(x)]y:=x
(2)
合成运算(2):NP+Verb→S,由名词短语与动词合成一个句子,其具体的计算过程如式(3)所示,同样使用多次β-归约最终得到整句话的语义逻辑表示形式。
λQ.∀x[car(x)→Q(x)](λz.runs(z))
→β∀x[car(x)→(λz.runs(z))(x)]
(3)
Q:=λz.runs(z)
→β∀x[car(x)→runs(x)]z:x
通过上述计算最终生成如图2所示带有语义特征的语法树,从树中可以获取到“Every car runs”采用逻辑表达式表示的语义信息即为∀x[car(x)→runs(x)]。
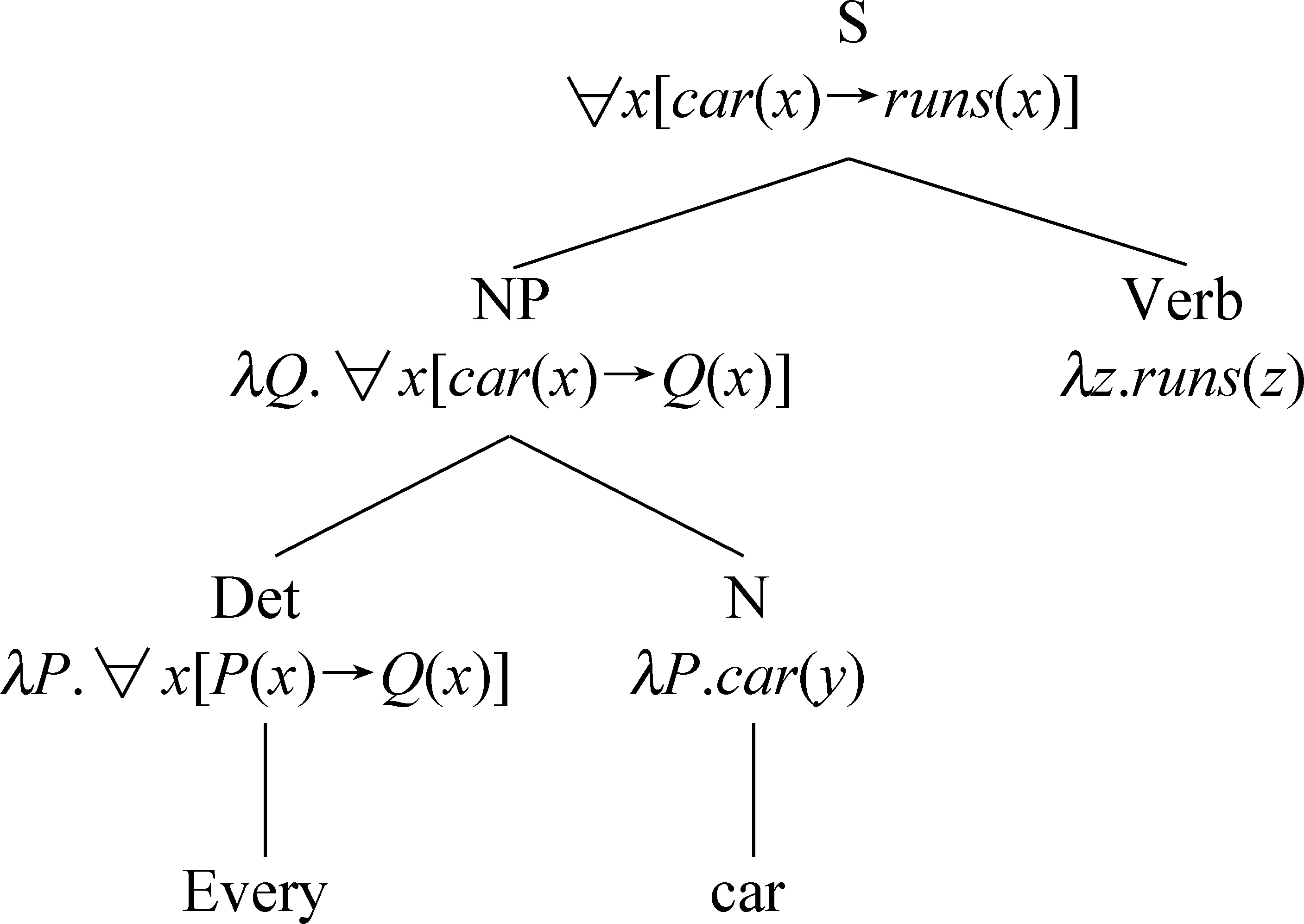
图2 带有语义特征的语法树
3 分布式方法
在计算语义合成性研究中语言学方法的一个最大弊端是: 从词典中获取单词的逻辑表示并不能表示单词的具体含义,因此不能处理单词语义相似度比较[13]、语义角色标注[14]等诸多问题。分布式方法使用向量表示单词,每个单词都具有特定的语义信息。在单词向量表示的基础上,参考文献[2]提出了计算语义合成性分布式方法的分类体系,本节详细介绍了三种目前常用的语义合成方法,即基于向量混合模型的方法、基于向量矩阵模型的方法和基于深度学习的方法。
3.1 基于向量混合模型的语义合成性
Mitchell等[15]基于分布式假设[16]提出利用向量混合模型来获取短语和句子的向量表示,其具体的合成模型如式(4)所示。
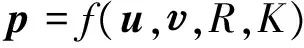
(4)
其中,u和是两个单词的初始向量,R是这两个单词之间的语法关系,K是所需要的背景知识,即构造这两个词的合成表达的意思所需要的附加信息或知识。在同一个语料库中,词与词之间、短语与短语之间以及句子与句子之间通常具有相同的R和K,因此上述合成模型进一步简化为式(5)。
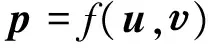
(5)
假如利用乘法和加法作为合成函数,则可以得到向量乘法和带权向量加法这两种具体的计算方法:
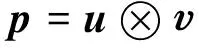
(6)
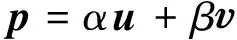
(7)
其中带权向量加法中的α和β是两个可以调整的表示合成短语中每个单词的重要程度的权值。向量混合模型是分布式方法中的最简单的合成运算形式,利用向量混合模型方法得到的输出向量可以看作是相关的输入向量的元素的混合。向量混合模型方法十分简单,在许多自然语言处理的任务,例如文献检索、论文评分以及一致性评估等诸多领域得到了广泛的应用,同时它也是评价其他复杂模型计算语义合成性优劣与否的基础。
此外,Coecke等[17]将张量积引入到了向量混合模型中来。张量积是刻画两个不同维度向量之间乘积的函数,对于两个向量u和,它们的张量积可以通过式(8)计算得到:
(8)
其中,ci,cj分别为向量u和中每一维的值;ni和nj分别为向量u和的偏置向量。同时,在张量积的基础上,Coecke等人又提出了将语法特性作为一个向量融入其中的合成运算方法。假设我们定义u为名词,为动词,则其计算过程如式(9)所示。

(9)
3.2 基于向量矩阵模型的语义合成性
基于向量混合模型的计算语义合成性在许多自然语言处理的任务中取得了良好的效果,但是它仍然不能解决语义合成的核心问题,即从语法层中最直接的浅层词的语义获取相应语义层的语义。于是,诸多研究人员在最初的向量混合模型基础上提出了向量矩阵模型的方法,但是主要聚焦于某些特定短语,如动词及其宾语的合成语义信息表示等。本节我们以Baroni等人[18]所提出的名词与形容词的语义合成运算为例,说明基于向量矩阵模型的语义合成性的相关问题。
Baroni等提出用向量表示名词,而修饰该名词的形容词则看作是用矩阵表示的将名词的语义信息映射到名词短语或形容词名词短语语义空间的线性函数。Baroni等在语义合成一般框架的基础上,提出形容词名词语义合成的计算公式如式(10)所示。
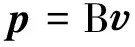
(10)
其中,p是合成的n维的向量,B是修饰名词的形容词矩阵,是存储了名词的语义信息的向量。
在实际的应用中通常使用某种监督学习的方法来获取各个权值矩阵的值,但是并不需要手工标记的数据,只需要在语料库中分别训练出不同的形容词模型,然后再根据具体的输入向量对矩阵值做适当的调整,从而确保输入和输出向量具有相同的维数。
采用上述向量矩阵模型处理计算语义合成性问题,比简单的向量混合模型取得了更优的结果,同时也避免了采用张量积时的繁琐计算。但是目前向量矩阵模型仍然局限于动词与名词、形容词与名词的合成语义表示,并没有应用到所有组成单词的合成运算中。
3.3 基于深度学习的语义合成性
使用深度学习的方法来进行计算语义合成性的研究,是目前的趋势之一。深度学习方法本质是一类机器学习的算法,最早在2006年由Hinton等人[19]提出,它的概念起源于人工神经网络的研究,通过组合低层特征形成更加抽象的高层表示属性的类别或特征,以发现数据的分布式特征表示。使用深度学习的方法能够捕获任意语法类型和长度的短语和句子的语义。深度学习的方法的最大优势在于: 它能真正充分地利用上下文信息来预测出其邻近词,而不像上一节所述的工作那样,只利用目标词与相关词的同现次数来预测目标词的语义信息。
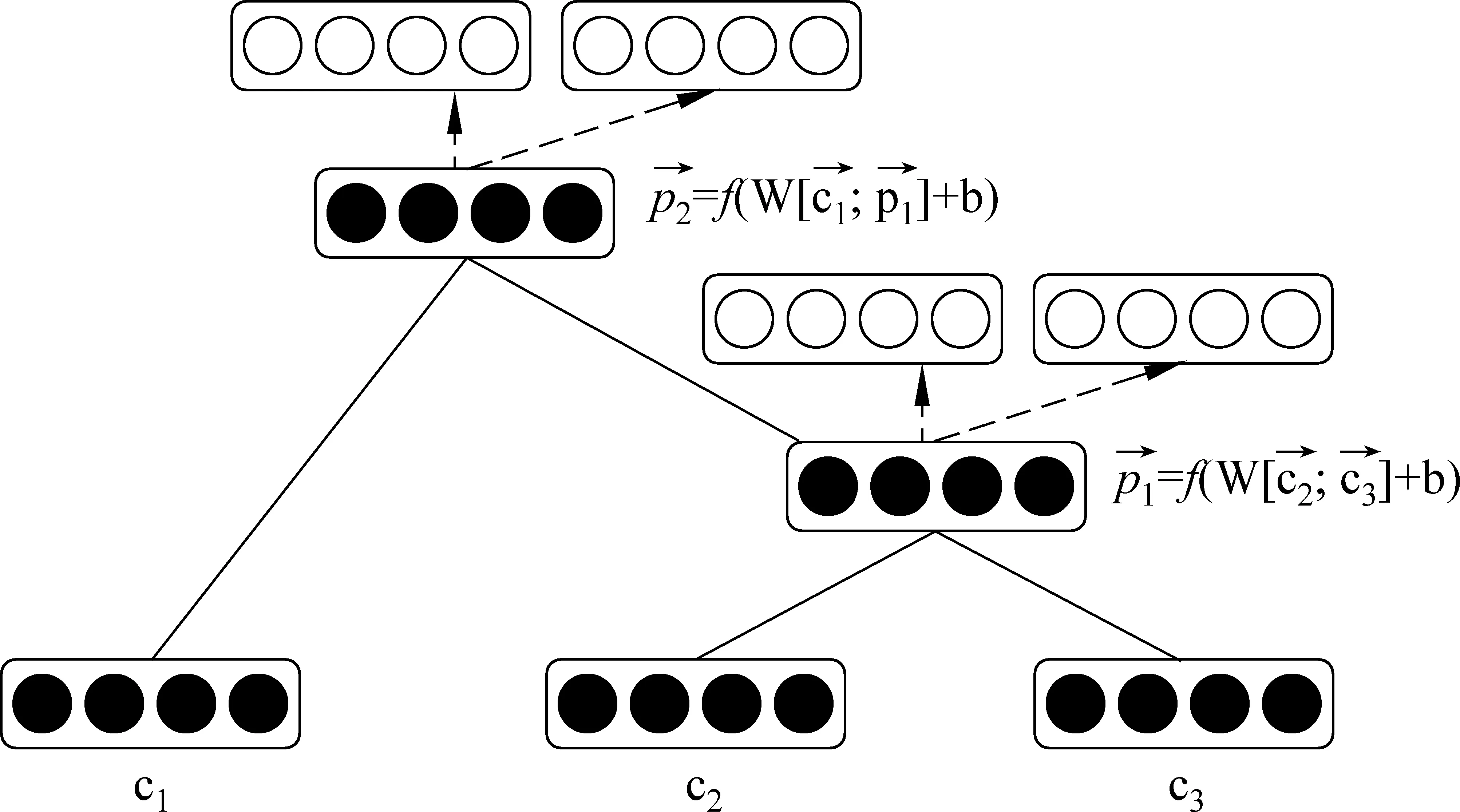
图3 基于深度学习方法的合成语义结构图
Socher等人[20]将深度学习的方法应用到了计算语义合成性的研究中,利用如图3所示的神经网络研究短语和句子的合成语义信息。对于输入的一对单词向量c1和c2,利用式(11)可以计算得到合成向量p:
(11)
其中,[c1;c2]表示两个单词向量的连接。W和b是模型参数,g(x)为如sigmoid或tanh的非线性函数。如图3所示,图中带有实心点的框图表示输入的单词或短语的语义向量,带空心点的框图表示通过父节点重新构造生成的与原叶子节点相对应的节点。叶子节点c2、c3通过式(11)计算得到它们父节点的语义向量p1,依此类推,该父节点语义向量又被用作新的叶子节点向量计算更长距离的短语语义向量。获取到父节点向量p1后,通过式(12)重新构造孩子节点向量。
(12)
对于每一个非叶子节点,计算它们原始孩子节点向量与重新构造的孩子节点向量之间的欧几里德距离作为重构误差,如式(13)所示,通过寻找到误差最小的根节点,从而获取模型的最优参数计算得到合成短语的语义向量。
(13)
Socher等人[21]后续又对这种简单的合成模型做了进一步的改进,借鉴向量矩阵模型方法提出了如图4所示的MV-RNN模型。首先借助于分词工具并通过适当的语法分析构建一棵二元语法树,然后搜寻树的每一个叶子节点得到其向量和矩阵M。其中,向量存储的是每一个节点自身的内部信息,M存储的是目标节点与它相邻节点之间的连接规则。对于每一个单词,首先将它初始化为一个n维的向量,然后利用Collobert等人[22]提出的无监督学习的方法,对其进行进一步的优化处理,最终得到的向量中存储了单词的语义信息。
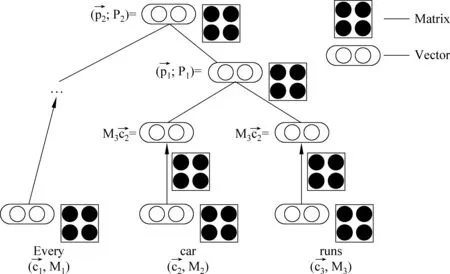
图4 基于MV-RNN模型的语义合成实例
对于每一个单词的矩阵M,首先将它初始化为M=I+ε,其中I是随机初始化的值,ε是高斯噪音,如果向量是n维的,则每一个单词的矩阵M是Rn×n的。因此,对于任意长为m的短语或句子,可以用向量矩阵对: ((c1,M1),(c2,M2)…,(cm,Mm))表示,其中(c1,M1)和(cm,Mm)分别表示短语或句子中单词的向量矩阵表示形式。
与上述提到的许多用于计算语义合成性的方法不同,深度学习的方法预训练的过程通常非常漫长,例如,计算中所需要的参数W和b都是通过使用多次迭代运算而得到的,因此需要大量的训练时间,而且也并不能确保训练得到的参数适用于不同的主题。但是基于深度学习的方法训练得到的单词向量表示带有更丰富的语义信息,采用非线性的合成运算得到的短语和句子的语义信息也更准确。
4 语言学方法与分布式方法比较
前文我们分两个部分分别阐述了语言学方法以及分布式方法在计算语义合成性研究中的应用。对比诸多计算语义合成性的研究方法,从采用λ演算的语言学方法到近年来逐步占据主导地位的基于向量表示的分布式方法,再到现在基于深度学习的方法,在这些方法的不断演变中,计算语义合成性的神秘面纱也逐步被揭开。
语言学的方法在语义学的研究中发挥了重要的作用,它综合利用使得语义合成的过程得到了简化,但是语言学方法不能明确表示单词的语义信息,对单词合成的短语进行逻辑表达时,仅能简单地表示特定子表达式在一定规则下所得到的合成表达式语义的正确与否,并不能定量地分析结果所包含的语义信息。此外,语言学方法对于规则和函数具有较强的限制,并不适用于大规模的数据处理。
基于向量模型的分布式方法的引入,使得我们可以通过简单的数学运算得到短语以及句子的合成语义信息。分布式语义表示,采用向量表示语义,在语义的表示以及可计算性上得到了极大的改善。尤其是随着深度学习技术的发展,能够真正充分利用整个语料的上下文信息,虽然其所得的向量每一维的具体意义目前仍无法解释,但是通过相似度计算等诸多处理方式,能极为方便进行语义层面的研究。但是由于深度学习的方法包含了多层训练模型,并通常需要预处理,因此它的训练速度通常较慢,仍然有许多值得改进的地方[23]。
5 计算语义合成性的应用
迄今为止,计算语义合成性在诸多自然语言处理的任务中得到了广泛的应用,本节着重阐述其在情感分析以及统计机器翻译领域中的应用。
5.1 计算语义合成性在情感分析中的应用
从大规模数据集中分析用户情感是一件非常具有挑战性的工作,但是目前多采用基于“词袋”模型的方法分析用户情感,即不考虑词与词之间、词与短语之间以及词与句子之间的语法语义关系,判断出错的情况不可避免[24]。举例来说,有这样两个句子“白细胞摧毁了病毒的一次攻击”和“病毒的一次攻击摧毁了白细胞”,显然第一句话表达了积极的情感,第二句话表达了消极的情感。但在采用传统基于“词袋”模型的方法,不可避免将这两句话判定为包含同样的情感。此外,目前对于用户情感的描述也存在着一定的局限性,并不能描述用户复杂的情感状态。
文献[25]针对上述问题,以深度学习方法中的递归自动编码器模型(RAE)为基础将合成语义应用到用户情感分析中,有效解决了缺乏语法结构以及用户情感复杂描述的局限性。针对语料情况,将用户情感分为五个大类,例如,“understand,sorry, hugs, wow,just wow”,每一大类中与之相对应有若干个标签,例如,“excited,cried”等,形成一个标签库。对于一个待分析的句子,首先获取单词语义向量,此时的单词语义向量可以通过多种方式(如逐点互信息或Word2vec*https://code.google.com/p/word2vec/等)获取到,再依据如图3所示的深度学习模型结构,每次选取误差率最小的组合,两两组合依次向上迭代,直至到达根结点。其中,误差率通过式(14)计算得到。
(14)
其中,Erec为重构误差可通过式(13)计算得到。式(13)中的A(x)表示从语句x能够构造树的全部可能集合,T(y)是返回树中所有非叶子结点的索引s的函数,c1和c2为树中的两个叶子结点,表示待合成的两个单词的语义向量表示形式。
此时,我们获取了目标句子或短语带有语法结构的语义向量表示形式,在此基础上为所得到的树中的每个父结点增加一个平滑层d(p;θ):
d(p;θ)=softmax(Wlabelp)
(15)
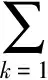
(16)
对目标函数采用梯度下降求解,便可求出模型参数θ。此时,训练一个简单的逻辑回归分类器利用该模型参数θ便可以分析待处理句子的情感。实验结果表明,将计算语义合成性应用于情感分析中能有效解决基于“词袋”模型导致误判的问题,此外还大大简化了人工处理的成本。
5.2 计算语义合成性在统计机器翻译中的应用
经过50多年的发展,统计机器翻译的方法经历了从词语层面、浅层语法层面、深层语法层面到半语义层面的进步[26],近年研究人员逐渐把研究的方向转向语义层的研究。在语义层的研究中,计算语义合成性的研究也越来越广泛。这一节,我们以文献[27]将计算语义合成性加入到短语翻译模型中的工作为例介绍计算语义合成性在统计机器翻译领域的应用。
其主要的思想是: 首先在源语言端和目标语言端分别抽取出短语,然后将源语言和目标语言中的短语,通过多层神经网络模型映射到一个低维的浅层语义空间。于是,对于源语言和目标语言的短语,都可以用一个与语言环境无关的特征向量来表示它的语义信息,最后通过计算各特征向量之间的相似度获得源短语对到目标短语对的翻译得分。由于该翻译得分是这些特征向量之间的平滑函数,所以语义上的微小改变仅会略微改变翻译得分的值,确保了翻译得分能够保持适当的值,然后将它作为一个特征加入到训练模型中。
将语义合成性应用到统计机器翻译中,关键在于把源语言和目标语言短语映射到同一个语义空间,然后计算出翻译得分[28]。假设从源语言或者目标语言中抽取的短语用向量表示为p,则它映射到语义空间中的特征向量y可采用式(17)计算得到。
(17)
其中,W1是从输入层到隐藏层的映射矩阵,W2是从隐藏层到输出层的映射矩阵。在语义空间的特征向量基础上,通过计算源语言短语向量ps与目标语言短语向量pt的相似度来表示源语言短语和目标语言短语的翻译得分。它的计算过程如式(18)所示。
score(s,t)≡simθ(ps,pt)=ysTyt
(18)
其中,s和t为源语言和目标语言短语,ps和pt分别为源语言语义空间和目标语言语义空间下源语言短语和目标语言短语语义向量。ys和yt分别为源语言短语和目标语言短语在语义空间中得到的特征向量,得到翻译得分后,将其作为一个参数加入到传统的基于线性对数模型的短语机器翻译过程中。英法机器翻译上的实验结果表明,这种新的模型的BLEU值比传统的短语翻译模型提高了0.7~1.0。
目前计算语义合成性在机器翻译中的应用多采用这种在单语空间计算语义向量再投影的方法,在投影的时候不可避免地会产生语义丢失的现象。Hermann等[29]提出一种多语言模型,将分布式假设扩展到了多语空间,在多语空间计算短语乃至句子的合成语义信息,有效避免了投影时可能出现的语义丢失现象。将通过这种模型获得的语义向量应用于机器翻译中,相信定能有效提升翻译的质量。
6 总结与展望
本文对计算语义合成性的研究方法进行了全面的综述和分析,参考了国内外诸多研究人员有关计算语义合成性研究的文章、方法。首先概要介绍了传统语言学方法在计算语义合成性研究中的应用,然后对于近年来兴起的基于单词向量表示的分布式方法选取了具有代表性的基于向量混合模型、基于向量矩阵模型以及基于深度学习的方法做了详细的介绍。同时也介绍了计算语义合成性在情感分析和统计机器翻译领域中的应用。
从本文对语言学方法和分布式方法的分析比较中可以看出: 计算语义合成性质量的好坏直接影响了其应用的质量的好坏,而单词的表示以及单词之间的合成规则直接影响了计算语义合成性质量的好坏。因此,计算语义合成性研究的重点仍然是寻求更好的单词向量表示以及更便利、有效的合成规则。
计算语义合成性研究是一件非常具有潜力和挑战性的工作,它可以极大地影响与改善自然语言处理的过程。但是即使采取目前最新的分布式方法,计算语义合成性研究仍然没有取得最优的结果。采用单词向量表示的分布式方法的前提是分布式假设是正确的,然后才可以利用上下文信息表示目标单词的语义信息,但是正如文献[2]所提出的质疑,Harris等人提出的分布式假设是否正确仍然是一个需要商榷的命题。此外,对于介词、限定词以及关系代词这些功能词的语义很难有一个稳定正确的表示方法。在单词向量表示的基础上,无论是线性的或者非线性的合成运算方法,都没有综合利用语法和语义规则。而这些问题都需要研究人员进一步挖掘与探究。
[1] 冯志伟. 自然语言处理的历史与现状[J]. 中国外语,2008,01:14-22.
[2] Kartsaklis D. Compositional Operators in Distributed Semantics. Springer Science Reviews[OL]. DOI: 10.1007/s40362-014-0017-z. 2014. www.cs.ox.ac.uk/files/6248/kartsaklis-springer.pdf
[3] Cornford FM,ed. Plato’s theory of knowledge: The theaetetus and the sophist[M]. Courier Dover Publications,2003.
[4] Frege G. ‘Über Sinn und Bedeutung’,in P Geach and M Black,eds.Translations from the Philosophical Writings of Gottlob[M]. Oxford: Blackwell,1892: 56-78.
[5] Partee B. Lexical semantics and compositionality[J]. An invitation to cognitive science: Language. 1995. 1: 311-360.
[6] Clark S,Pulman S. Combining Symbolic and Distributional Models of Meaning[C]//Proceedings of the AAAI Spring Symposium on Quantum Interaction,2007: 52-55.
[7] Blacoe W,Lapata M. A comparison of vector-based representations for semantic composition[C]//Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Association for Computational Linguistics,2012: 546-556.
[8] Montague R. English as a formal language[J]. Linguaggi nella societae nella tecnica. 1970: 189-224.
[9] Moggi E. Computational lambda-calculus and monads[M]. University of Edinburgh,Department of Computer Science,Laboratory for Foundations of Computer Science,1988.
[10] Guevara E. Computing semantic compositionality in distributional semantics[C]//Proceedings of the 9th International Conference on Computational Semantics.Association for Computational Linguistics,2011: 135-144.
[11] Bach E. An extension of classical transformational grammar[C]//Proceedings of the 1976 Conference at Michigan State University,1976: 183-224.
[12] Church A. The calculi of lambda-conversion[M]. Princeton University Press,1985.
[13] 石静,吴云芳,邱立坤等. 基于大规模语料库的汉语词义相似度计算方法[J]. 中文信息学报,2013,27(1)1-6,80.
[14] 王鑫,孙薇薇,穗志方.基于浅层句法分析的中文语义角色标注研究[J]. 中文信息学报,2011,(25)01: 116-122.
[15] Mitchell J,Lapata M. Vector-based Models of Semantic Composition[C]//Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics,2008: 236-244.
[16] Harris Z S. Mathematical structures of language[J]. Wiley. New York. 1968.
[17] Coecke B,Sadrzadeh M,Clark S.Mathematical Foundations for Distributed Compositional Model of Meaning[J]. Lambek Festschrift. Linguistic Analysis. 2010,36: 345-384.
[18] Baroni M,Zamparelli R. Nouns are vectors,adjectives are matrices: Representing adjective-noun constructions in semantic space[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics,2010: 1183-1193.
[19] Hinton G E,Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J]. Science,2006,313(5786): 504-507.
[20] Socher R,Lin C C,Manning C,et al. Parsing natural scenes and natural language with recursive neural networks[C]//Proceedings of the 28th International Conference on Machine Learning (ICML-11),2011,129-136.
[21] Socher R,Huval B,Manning C D,et al. Semantic compositionality through recursive matrix-vector spaces[C]//Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning. Association for Computational Linguistics,2012,1201-1211.
[22] Collobert R,Weston J,Bottou L,et al. Natural language processing (almost) from scratch[J]. The Journal of Machine Learning Research,2011,12: 2493-2537.
[23] Mitchell J,Lapata M. Composition in distributional models of semantics[J]. Cognitive science,2010,34(8): 1388-1429.
[24] Pang B,Lee L,Vaithyanathan S. Thumbs up?: sentiment classification using machine learning techniques[C]//Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing-Volume 10. Association for Computational Linguistics,2002: 79-86.
[25] Socher R,Pennington J,Huang E H,et al. Semi-supervised recursive autoencoders for predicting sentiment distributions[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics,2011: 151-161.
[26] 刘群. 统计机器翻译综述[J]. 中文信息学报,2003,17(4): 1-12.
[27] Gao J,He X,Yih W,et al. Learning Continuous Phrase Representations for Translation Modeling[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: Long Papers-Volume 1. Association for Computational Linguistics. Baltimore,Maryland. 2014: 699-709.
[28] He X,Deng L. Maximum expected bleu training of phrase and lexicon translation model[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics,2012: 292-301.
[29] Hermann K M,Blunsom P. Multilingual Models for Compositional Distributed Semantics[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics,2014: 58-68.
A Survey of Computational Semantic Compositionality
WANG Chaochao,XIONG Deyi
(School of Computer Science and Technology,Soochow University,Suzhou,Jiangsu 215006,China)
Despite of the rapid development of natural language processing,studies at the syntax level can’t fully satisfy what we need. Semantics is becoming a hot research topic in the NLP community. As the key part of semantics,computational semantic compositionality receives more attention. In this paper,we classify the approaches towards computational semantic compositionality into two categories: linguistic methods and distributional methods. We present some typical studies for each category,including the recent deep learning approaches. After an introduction to these two approaches,we make a comparison between linguistic methods and distributional methods. Then we introduce several applications of computational semantic compositionality on sentiment analysis and machine translation. Finally,we provide some suggestions on future directions of computational semantic compositionality.
semantic compositionality; natural language processing; distributional method; deep learning

王超超(1989—),硕士研究生,主要研究领域为机器翻译。E⁃mail:chaochaowang@foxmail.com熊德意(1979—),教授,主要研究领域为自然语言处理,机器翻译。E⁃mail:dyxiong@suda.edu.com
2014-6-9 定稿日期: 2015-12-8
江苏省自然科学基金青年基金(BK20140355)
1003-0077(2016)03-0001-08
TP391
A
