中医针灸领域术语自动抽取研究
2016-05-04孙水华黄德根牛萍
孙水华,黄德根,牛萍
(1. 大连理工大学 计算机科学与技术学院,辽宁 大连 116024;2.福建工程学院 信息科学与工程学院,福建 福州 350118)
中医针灸领域术语自动抽取研究
孙水华1,2,黄德根1,牛萍1
(1. 大连理工大学 计算机科学与技术学院,辽宁 大连 116024;2.福建工程学院 信息科学与工程学院,福建 福州 350118)
针对中医针灸领域术语的构成特点,该文建立了一种基于规则的领域术语抽取算法模型,该模型首先对中医针灸领域术语种子集进行有限次的迭代,生成中医针灸领域术语构件集;然后,以术语构件集为领域词典,采用最大向前匹配算法对中文针灸医学文献中的句子进行切分,并抽取候选术语;最后,利用语言规则对候选术语进行过滤处理,筛选出中医针灸领域专业术语。分别以关键字集和中医词典为种子集进行实验,开式测试的F值分别达到76.96%和35.59%。
中医针灸领域术语;术语种子集迭代算法;术语过滤规则
1 引言
医学术语的获取及术语库的构建对生物医学文献中的隐含知识发现有重要的作用,在机器翻译、自动索引、信息检索、信息抽取、构建词汇知识库等领域也有重要的应用价值。作为信息处理领域一项重要的研究任务,术语抽取研究已经取得了长足的进步。目前,术语自动抽取方法主要有三大类: 基于语言规则的方法、基于统计信息的方法、规则与统计相结合的方法。文献[1]利用人工构建规则模板来抽取术语,该方法简单易行,但抽取结果受限于模板的完备性和限定的领域;文献[2-5]利用词频、假设检验、对数似然比、互信息等统计量计算术语的单元性和领域性来抽取术语,该方法不依赖具体领域,适应性好,但低频术语抽取效果较差;文献[6-7]利用条件随机场(CRF)、隐马尔可夫(HMM)等统计模型对术语进行识别和抽取,该方法依赖大规模的标注语料;文献[8-11]将规则与统计两种方法以某种次序组合起来,相互弥补不足,提高了术语抽取的准确率。
与其他领域的术语识别相比,生物医学领域术语的识别研究较少,其研究任务主要集中在对英文医学文献的命名实体识别上,如文献[12-13]针对JNLPBA2004的命名实体识别任务展开了研究。但是,中文生物医学信息急剧增长,仅中文生物医学文献数据库就收录了1978年以来1 600种生物医学期刊中超过300万篇公开发表的医学论文。海量中文生物医学信息的产生,为中文生物医学知识发现任务提供了前所未有的机会。作为在中文医学文献中知识挖掘的一个重要的子任务,中文医学领域术语识别方法的研究已经开始引起科学研究者的关注,如文献[14]提出了基于条件随机场(CRF)的中文生物医学命名实体识别方法。
本文从中文医学期刊网站(http://www.cqvip.com/)爬取中文医学文献中的摘要、关键字信息,利用摘要信息构建中文针灸医学领域语料库,利用关键字信息构建中医针灸领域术语种子集。通过对术语种子集进行有限次的迭代,产生针灸医学领域术语构件集,以术语构件集为领域词典,采用最大向前匹配算法对语料库中的句子进行切分,抽取候选术语,再利用语言规则模板对候选术语进行后处理,进而抽取出中医针灸领域的专业术语。
2 中医针灸领域术语及其特点
针灸学是以中医学理论为指导,运用针刺和艾灸防病治病的一门临床学科,其主要内容包括经络学、腧穴学、针法灸法学和针灸治疗学等部分。中医针灸领域术语富含浓厚的中国文化烙印,文献[15]将中医针灸领域术语的特点归纳如下:
(1) 专门化。一个中医针灸领域术语与一个或一系列这一学科的语义体系紧密联系在一起,起一种专门指称的作用。
(2) 单义性。一个特定的概念与一个特定的中医针灸领域术语相对应。
(3) 精确性。中医针灸领域术语必须体现它本身的科学性和专业性,它不能是含混不清的模糊词,也不能与它的临近概念相混淆。
(4) 没有感情色彩。中医针灸领域术语不分褒义词和贬义词,也不必借助上下文来了解它的意义。
通过对中文医学期刊网站爬取的中医针灸领域文本的初步统计和分析,我们发现该领域的术语主要涉及经络、腧穴、针灸疗法、中医学病症名及其他含义抽象的针灸学术语。为了便于人工标注语料及术语抽取、知识发现等任务的研究,本文将中医针灸领域术语分为如下五类:
(1) 经络术语: 指运行气血、联系脏腑和体表及全身各部的通道,包括: 十二经脉、奇经八脉、十五络脉等。
(2) 腧穴术语: 指人体经络线上特殊的点区部位,多为神经末梢和血管较少的地方,中医可以通过针灸或者推拿、点按、艾炙刺激相应的经络点来治疗疾病。
(3) 针灸疗法术语: 包括刺法、灸法、拔罐、推拿等治疗方法以及治疗用具术语。
(4) 中医病症名术语: 指具体的疾病名称。
(5) 抽象术语: 指不能归入上述四类且含义抽象的针灸术语。
中医针灸领域术语类别及其实例如表1所示。
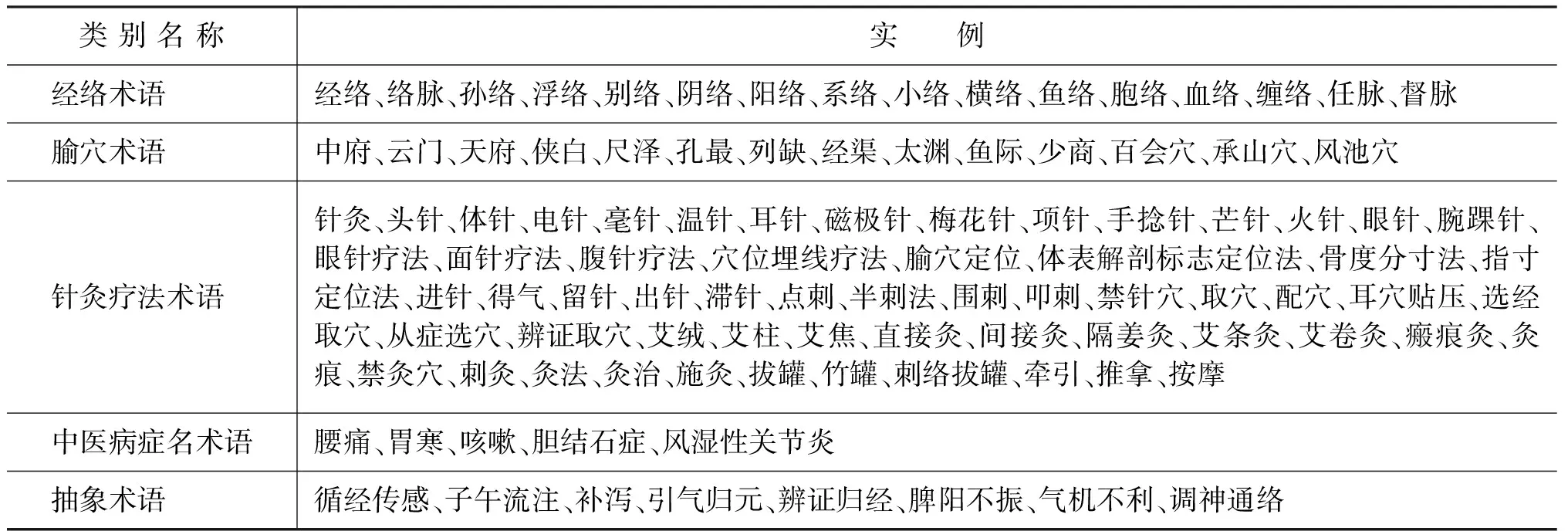
表1 中医针灸领域术语类别及其实例
3 术语抽取模型
本文建立的中医针灸领域术语抽取模型主要包括术语构件集生成、候选术语抽取和术语过滤。中医针灸领域术语抽取的步骤如下: 1)从爬取的医学论文中抽取关键字信息构建中医针灸领域术语种子集;2)从爬取的医学论文中抽取中文摘要信息构建中医针灸领域语料库;3)调用术语构件生成器将中医针灸领域术语种子集经过有限次迭代生成中医针灸领域术语构件集;4)以中医针灸领域术语构件集为领域词典,调用候选术语抽取器抽取中医针灸领域语料库中的针灸领域术语,生成中医针灸领域候选术语集;5)调用术语过滤器,利用规则集对候选术语进行过滤,生成中医针灸领域术语集。中医针灸领域术语抽取的流程如图1所示。

图1 中医针灸领域术语抽取的流程
3.1 术语构件集生成算法
中医针灸领域术语构件是指那些更大概率地出现在中医针灸领域术语中的字、单词或复合词,术语构件可以是词根、前缀、后缀或某些包含于中医针灸领域术语中的字符串。首先,从爬取的中医针灸领域文献中提取关键字信息,经过去重、去噪处理及人工审核后,形成中医针灸领域术语种子集。接着,在中医针灸领域术语种子集中采用迭代算法自动学习术语构件,生成中医针灸领域术语构件集。术语种子集迭代采用文献[11]中的算法,其基本思想是: 用构件集中的构件切分种子集中的每个术语,将最佳切分中产生的新构件添加到构件集中,迭代学习新构件直至算法收敛。最佳切分选择方法如下: 对于种子集S中的术语s,用Tc中的构件进行切分,得到多个不同的切分结果,如式(1)所示,切分Ri(s)的权重计算如式(2)所示。从式(2)的含义可以看出,含有新构件ri越少和越短的切分权重越大,极端情况就是不切分权重最大。因此,选择权重最大但不等于1的切分为最佳切分,将其产生的新构件ri1,ri2,…,rim+1添加到构件集Tc中。参数α、β的值根据实验效果进行调节,本文通过实验结果比较,α和β均取值0.5。术语切分及新构件生成的实例如表2所示。
(1)
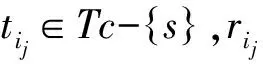
(2)
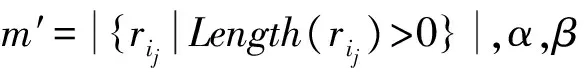

表2 术语切分及新构件生成实例
为了获取高领域度的新构件,剔除如表2中的“后/r”、“电/r”、“垂直/r”等低领域度的单字或字串,通过对迭代学习中产生的新构件集及术语错误集进行人工分析,总结规律,得到如下的术语构件过滤规则,并对每轮迭代学习中产生的新构件都采用术语构件过滤规则进行过滤。
规则一 丢弃最佳切分Ri(s)首部、中部产生的单字长构件rij,将尾部产生的单字长且频率>1的构件rij添加到Tc中。
规则二 将最佳切分Ri(s)中长度>1且频率>1的新构件rij添加到Tc中。
rij的频率是指在同一轮迭代中构件rij在不同术语的最佳切分中出现的次数。术语构件集生成算法描述如图2所示。
3.2 术语抽取算法
从爬取的中医针灸文献中提取摘要信息,构建中医针灸领域语料库。对语料做去噪处理并以标点符号进行粗切分,采用文献[11]的方法进行术语抽取处理。中医针灸领域术语抽取模块的基本处理过程是: 从未标注无结构的领域语料库中逐句读取字串,采用最大向前匹配算法,以术语构件集Tc作为领域词典切分字串,切分结果如式(3)所示,抽取xk和xk+1之间的串tk1tk2…tkik(1≤k≤n)作为中医针灸领域候选术语,用规则模板过滤候选术语,生成中医针灸领域术语,直至语料处理完毕。
e=x1t11t12…t1i1x2t21t22…t2i2…xntn1tn2…tninxn+1
(3)
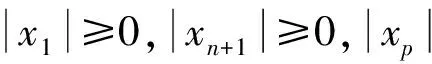
3.3 术语过滤规则
为了提高术语抽取的精确率,通过分析术语错误集,总结出如下候选术语过滤规则。在过滤时,本文用到两个特征词表,分别是术语首词列表(以下简称PrefixWord)和术语尾词列表(以下简称SuffixWord),它们均通过对中医针灸领域术语种子集学习获得。为了便于叙述,以下假设过滤处理的候选术语为:
1) 限定首词,若tk1不在PrefixWord中,则去掉tk1,将剩余部分作为候选术语继续该操作,直到首词在PrefixWord中,或字符串为空时结束。例如,候选术语“进/t针灸/t”经本条规则处理后的术语是“针灸”。
2) 限定尾词,若tkn不在SuffixWord中,则去掉tkn,将剩余部分作为候选术语继续该操作,直到尾词在SuffixWord中,或字符串为空时结束。例如,候选术语“咳嗽/t变/t”经本条规则处理后的术语是“咳嗽”。

图2 术语构件集生成算法
3) 若tk(n-1)tkn都在SuffixWord中,则删除tkn,剩余部分为术语。例如,候选术语“慢性/t支气管炎/t病/t”、“麦粒灸/t灸/t”经本条规则处理后的术语是“慢性支气管炎”、“麦粒灸”。
4) 若tk1tk2…tki…tk(n-1)tkn中,所有构件t都不在种子集中,则舍弃tk1tk2…tki…tk(n-1)tkn。例如,舍弃候选术语“刀/t周围/t”。
5) 若tk1tk2…tki…tk(n-1)tkn为单字组成的字串,则舍弃tk1tk2…tki…tk(n-1)tkn。例如,舍弃候选术语“刺/t刀/t灸/t”。
6) 若tk1tk2…tki…tk(n-1)tkn为含有数字或字母的字串,则舍弃tk1tk2…tki…tk(n-1)tkn。例如,舍弃候选术语“脑缺血/t 3/t h/t”。
7) 若tk1tk2…tki…tk(n-1)tkn含有数量词,则舍弃tk1tk2…tki…tk(n-1)tkn。例如,舍弃候选术语“针刺/t合谷/t十二/t针/t”。
8) 若tk1tk2…tki…tk(n-1)tkn为数字+中文形式,则舍弃tk1tk2…tki…tk(n-1)tkn。例如,舍弃候选术语“3/t 穴/t”。
9) 限制中医针灸领域术语的长度为1~12字。
4 实验及结果分析
4.1 测试语料及评测指标
从网站(http://www.cqvip.com/)上爬取《针灸临床杂志》期刊2009至2013年发表的医学文献的摘要和关键字信息。关键字信息经过去重、去噪处理及人工审核后,作为中医针灸领域术语种子集。抽取的摘要信息共4.2M,随机选择其中的210篇摘要,按照本文对中医针灸领域术语所做出的五类界定,进行人工标注术语,并将经人工标注好术语的摘要集作为系统的闭式测试语料。爬取该网站的《上海针灸杂志》期刊文献摘要2.8M,随机选取其中的210篇摘要,经人工标注术语后作为系统的开式测试语料。从网站(http://www.tcm100.com/ShuJuKu/ZhongYiCiDian/ZhongYiCiDian.aspx)爬取中医名词20 109个,剔除其中的书名、人名,将余下的19 916个中医名词作为对比实验用的中医术语种子集。
系统采用准确率(P)、召回率(R)和F-值三个通用的测评指标进行评价,测评指标的具体定义如下式(4)所示。
(4)
(5)
(6)
4.2 实验结果分析
基于以上设计思想,我们使用Java语言实现了一个中医针灸领域术语抽取实验系统,并在该实验系统上进行了中医针灸领域术语抽取的闭式测试和开式测试,测试结果如表3所示。
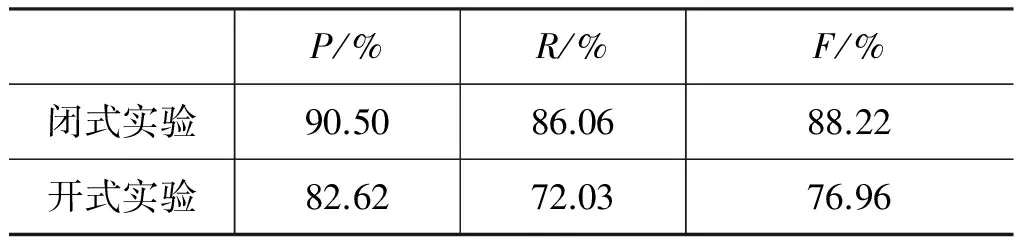
表3 开式实验与闭式实验评测指标对比表
由于术语种子集和闭式测试语料库同源,二者的拟合度较高,所以闭式测试的评测指标好于开式测试。通过分析错误识别的术语后发现,误识的原因主要有以下两点: ①没有对测试语料进行分词,使得术语识别时前词和后词的部分字串区分不开,术语边界标识不准确,从而引发术语识别错误,影响术语抽取的准确率; ②中医针灸领域文献中存在用词不够规范的现象,并且新的针灸领域术语不断出现,使得种子集以及种子集迭代后的构件集对领域术语的覆盖度有限,造成部分领域术语以及新出现的领域术语识别困难,影响术语抽取的召回率。术语识别错误实例及其原因分析如表4所示。

表4 错误识别的术语实例及其原因分析表
为了检验算法的效果,将本文设计的算法、文献[11]中提及的迭代引导算法(The Iterative Bootstrapping Algorithm,IBA)以及两组规则在不同的种子集,相同的标注集上进行了对比实验,实验结果如表5所示。
从表5看出,本文方法比IBA算法有较大的优势,这与中医针灸领域术语的结构特点有关。中医针灸领域术语的组成结构中存在常用词字串,若不对切出的术语构件进行规则过滤,术语构件中就会混杂常用词字串。这种情况下,利用向前匹配法进行领域术语获取时,会导致术语边界确定不准确,从而使中医针灸领域术语抽取的精确率大大降低。用中医词典种子集替换关键字种子集重做四组实验发现,术语抽取的P、R值下降较大,说明种子集的规模对术语抽取结果评价及评价的客观性都有影响。因此,实际应用中要保证种子集的规模和质量。
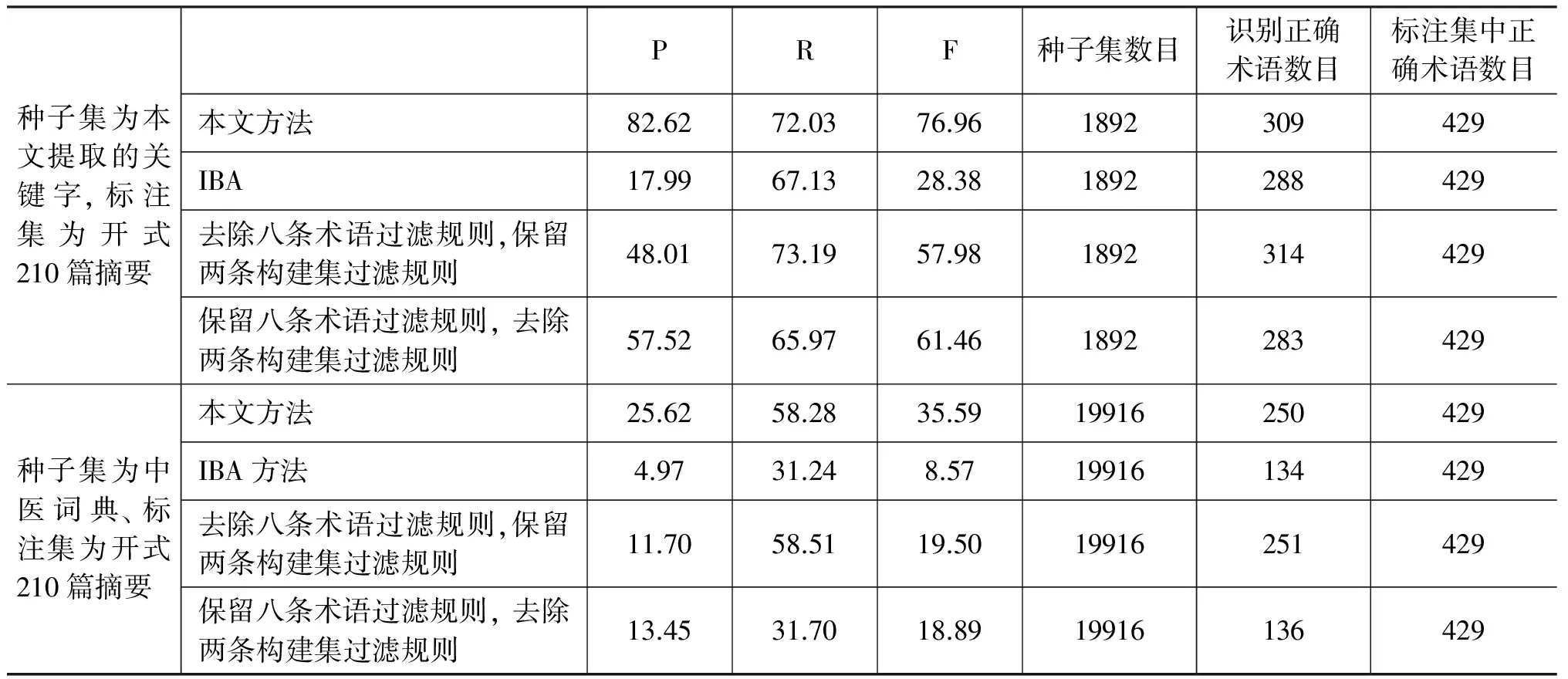
表5 规则效果及种子集效果实验
5 结语
针对中医针灸领域术语的构成特点,将该领域术语分为五类。通过分析现有术语抽取技术在中医针灸领域术语抽取中存在的问题,建立了中医针灸领域术语抽取的算法模型,实现了中医针灸领域术语抽取的原型系统。通过对《上海针灸杂志》上随机抽取的210篇摘要进行的开式测试结果来看,该方法较好地解决了现有术语抽取技术存在的中医针灸领域术语构件中混杂常用词字串的问题,提高了中医针灸领域术语抽取的精确率。后续的研究中,将在现有术语抽取算法模型的基础上,进一步研究中医针灸领域术语边界识别问题以及新词识别的问题。
[1] Bourigault D. Surface grammatical analysis for the extraction of terminological noun phrases[C]//Proceedings of the 14th conference on Computational linguistics-Volume 3. Association for Computational Linguistics,1992: 977-981.
[2] Li D,Wang Q,Li Y,et al. A Domain-Specific Chinese Term Extraction Method Based on Prefix and Suffix[C]//Proceedings of the Computer Science & Service System (CSSS),2012 International Conference on IEEE,2012: 1356-1359.
[3] 何婷婷,张勇. 基于质子串分解的中文术语自动抽取[J]. 计算机工程,2006,32(23): 188-190.
[4] 梁颖红,张文静,周德富. 基于混合策略的高精度长术语自动抽取[J]. 中文信息学报,2009,23 (6): 26-30.
[5] 游宏梁,张巍,沈钧毅,等. 一种基于加权投票的术语自动识别方法[J]. 中文信息学报,2011,25 (3): 9-16.
[6] 李丽双,党延忠,张婧,等. 基于条件随机场的汽车领域术语抽取[J]. 大连理工大学学报,2013,53(2): 267-272.
[7] 岑咏华,韩哲,季培培. 基于隐马尔科夫模型的中文术语识别研究[J]. 现代图书情报技术,2008,12: 54-58.
[8] 刘豹,张桂平,蔡东风. 基于统计和规则相结合的科技术语自动抽取研究[J]. 计算机工程与应用,2009,44(23): 147-150.
[9] Ji L,Sum M,Lu Q,et al. Chinese terminology extraction using window-based contextual information[M].Computational Linguistics and Intelligent Text Processing. Springer Berlin Heidelberg,2007: 62-74.
[10] 周浪,张亮,冯冲,等. 基于词频分布变化统计的术语抽取方法[J]. 计算机科学,2009,36(5): 177-180.
[11] Zhang C,Niu Z,Jiang P,et al. Domain-specific term extraction from free texts[C]//Proceedings of the Fuzzy Systems and Knowledge Discovery (FSKD),2012 9th International Conference on. IEEE,2012: 1290-1293.
[12] Kim S,Yoon J. Experimental Study on a Two Phase Method for Biomedical Named Entity Recognition[J].IEICE Transactions on Information and Systems,2007,E90-D(7): 1103-1110.
[13] Chan S K,Lam W,Yu X F. A cascaded approach to biomedical named entity recognition using a unified model[C]//Proceedings of the 7th IEEE International Conference on Data Mining,Omaha,Nebraska,USA,2007: 93-102.
[14] Gu B,Popowich F,Dahl V. Recognizing biomedical named entities in Chinese research abstracts[M].Advances in Artificial Intelligence. Springer Berlin Heidelberg,2008: 114-125.
[15] 蒋锦文,于鹏. 浅谈中医学术语的特点和研究方法[J]. 天津中医学院学报,2000,3: 023.
Automatic Term Extraction in TCM Acupuncture Domain
SUN Shuihua1,2,HUANG Degen1,NIU Ping1
(1.School of Computer Science and Technology,Dalian University of Technology,Dalian,Liaoning 116024,China;2.College of Information Science and Engineering,Fujian University of Technology,Fuzhou,Fujian 350118,China)
A term extraction algorithm model based on language rules in TCM acupuncture domain is established. Firstly,the seed set of TCM acupuncture domain term is iterated finitely to generate the component set. Secondly, by regarding the component set as the domain dictionary,the model applies maximum forward matching algorithm to segment the sentences and extracts term candidates. Finally,the term candidates are filtrated by rules. The F-measures for open test are 76.96% and 35.59%,with keywords and traditional Chinese medicine dictionary as the seed set,respectively.
TCM acupuncture domain term; term seed set iteration algorithm; term filter rule

孙水华(1962—),博士研究生,副教授,主要研究领域为自然语言处理与机器翻译。E⁃mail:sunsh@mail.dlut.edu.cn黄德根(1965—),博士,教授,博士生导师,主要研究领域为自然语言处理与机器翻译。E⁃mail:huangdg@dlut.edu.cn牛萍(1988—),硕士研究生,主要研究领域为自然语言处理与机器翻译。E⁃mail:425204127@qq.com
2014-02-04 定稿日期: 2015-04-29
福建省自然科学基金(2014J01218);国家自然科学基金(61173100)
1003-0077(2016)03-0118-07
TP391
A
