云计算环境下海量数据分析系统的设计
2015-02-18苏亚妮霍米会
苏 曦,苏亚妮,霍米会
(1.西安医学院,陕西 西安 710021;2.陕西省人民医院,陕西 西安 710068;3.华为技术股份有限公司,广东 深圳 518000)
云计算环境下海量数据分析系统的设计
苏曦1,苏亚妮2,霍米会3
(1.西安医学院,陕西 西安 710021;2.陕西省人民医院,陕西 西安 710068;3.华为技术股份有限公司,广东 深圳 518000)
摘要:针对传统计算环境中海量数据存储、分析处理效率、实时性、完整性和数据维护费用等难题,利用云计算环境的超大规模、虚拟化、经济和安全可靠等特点,进行海量数据分析。基于分布式计算架构Hadoop,利用并行计算框架Map/Reduce,构建了典型的云计算环境,并采用数据仓库分析平台Hive,实现了高效、实用的海量数据分析系统的设计。以系统总体框架设计为基础,从客户端分析、接收服务器、后端数据分析和数据可视化等模块完成了系统设计,对海量数据分析处理系统设计具有一定参考价值。
关键词:海量数据分析;云计算环境;分布式计算;并行处理;系统设计
信息技术的飞速发展,使产生的信息量呈现爆炸式增长,为此,图灵奖获得者Jim Gray提出了一个新的经验定律:网络环境下每18个月产生的数据量等于有史以来数据量之和[1]。人们要想从这些海量数据中得到有用的信息和知识,传统的数据处理方法面临严峻的挑战,特别是在海量数据存储、分析处理效率、实时性、完整性和数据维护费用等方面[2]。云计算作为信息技术的新贵,将引领信息技术发展加速,将促进信息利用与共享。由大量云计算平台、云应用和云服务构成的云计算环境,为海量数据分析处理提供了超大规模、虚拟化、经济和安全可靠的系统环境[3-5]。
本文正是利用云计算环境下的上述特点,基于分布式计算架构Hadoop,利用并行计算框架Map/Reduce,构建了典型的云计算环境,并采用数据仓库分析平台Hive,实现了高效、实用的海量数据分析系统的设计。
1Hadoop相关技术简介
1.1Hadoop结构及模块
Hadoop的基本体系结构如图1所示。Hadoop是Apache软件基金会所研发的并行运算编程工具和分布式文件系统,它作为一个开源的软件平台,使编写和运行用于处理海量数据的应用程序更加容易[6]。通常来说,Hadoop主要实现2大功能:1)存储,Hadoop采用分布式存储结构,能够实现方便可靠的海量数据存储,即HDFS(Hadoop Distributed File System)组件;2)分析,Hadoop采用并行式计算框架Map/Reduce及其组件,能够实现高效可靠的海量数据分析运算。运用Hadoop框架完成海量数据分析,主要是通过开发编写Map/Reduce系统,进而完成海量数据的分析处理任务。开发过程并不需要了解系统底层的基本架构。其海量数据分析的可靠性是通过更改相应配置文件,利用HDFS完成数个或更多的数据副本备份。若节点出错,则可以通过数据块副本来完成数据处理任务。同时利用Map/Reduce完成数据分析任务调度,将海量数据分割为细粒度的子任务,子任务通过任务调度模型,实现任务的合理分配,即运行更快的节点将分配到更多任务,从而实现快速的海量数据分析。基本执行步骤包括输入数据文件、分割并分配并行计算节点、节点写本地中间文件、合并中间文件和输出最终分析结果。
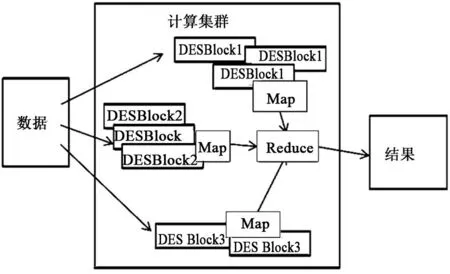
图1 Hadoop的基本体系结构
Hadoop模块设计如图2所示,Hadoop的功能模块包括作业跟踪器(Job Tracker)、任务跟踪器(Task Tracker)和应用程序(Application)。作业跟踪器负责作业管理和操作,任务跟踪器负责任务的管理和操作、应用程序接口。
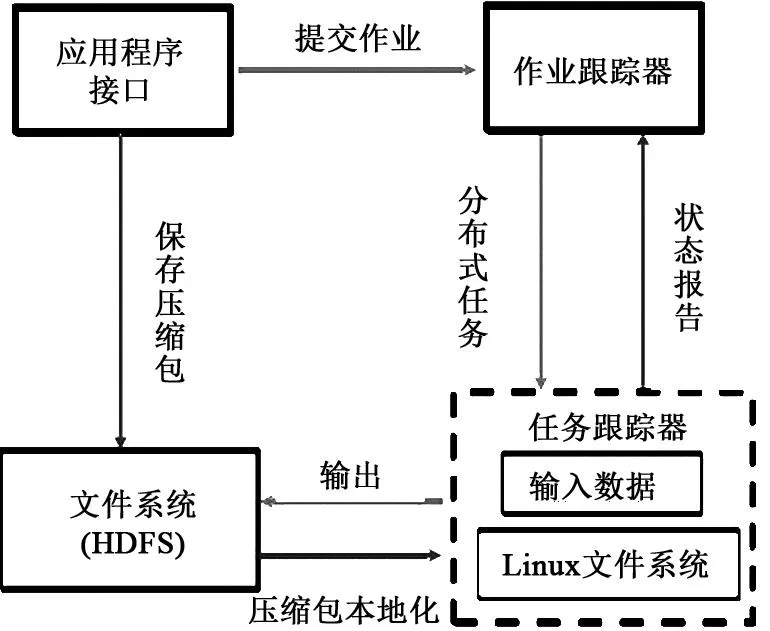
图2 Hadoop模块设计
1.2Map/Reduce及其框架
Map/Reduce编程模型是一个可以在云计算环境中进行并行数据分析的框架,利用由普通计算机组成的、通过高速网络连接的无共享集群,执行大规模数据分析任务。该模型非常简单。对于同一程序,Hadoop支持多种语言编写的Map/Reduce代码,其中Java是其默认的语言。与传统的DBMS相比,Map/Reduce实现了更好的容错性和异构环境的操作性[7]。
Map/Reduce程序最为重要的特性在于其本质上是并行处理,只要能够为海量数据分析提供足够的计算机,其能够完成的数据分析量是没有限制的,因此,其优势也在于海量数据的分析处理上。Map/Reduce是为数据密集的并行计算设计的一种模型,数据被存储在分布式文件系统(Distributed File System,DFS)中,以键-值对(key,value)来表示数据,计算时分为2个过程(Map和Reduce),分别表示为:
Map: map(k1,v1)→list(k2,v2)
Reduce: reduce(k2,list(v2))→list(k3,v3)
Map/Reduce数据流如图3所示,在主节点进行数据分割,然后调用分节点进行Map任务,Map任务的输出数据按照key的哈希值进行排列(shuffle)后,含有同一个哈希键值的数据对被传递到分节点的同一个Reduce任务,Reduce任务完成后的输出写入到DFS中。
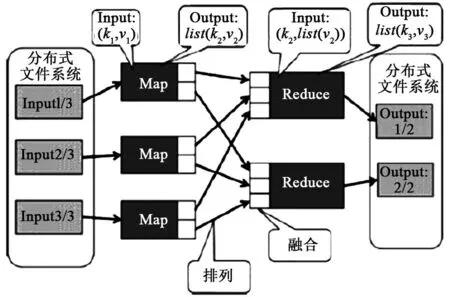
图3 Map/Reduce数据流
Map/Reduce并行计算框架,分布式程序的编写大大简化,这样能够使得用户从编程的细节中解放出来,从而有更多的精力去处理任务的描述和实现。HDFS被证明在搜索引擎类型的应用中是高效的。随着数据爆炸式增长,Map/Reduce程序不局限于搜索引擎。Map/Reduce模型将作业划分到各个节点执行,实现Job级别的并发,但对每个单独的任务,计算和I/O都是无并发的,当遇到一些任务对计算和I/O能力要求较高时,易产生系统瓶颈以及集群不稳定。
1.3Hive平台
基于Hadoop,立足于并行计算框架Map/Reduce,Hive平台能够提供Hive SQL分析语言,能够完成HFDS系统中的数据分析,可有效简化分布式海量数据分析的复杂性,构建出高效实用的数据分析平台,系统架构[8]如图4所示。

图4 Hive系统架构
Hive平台数据分析流程是将结构化数据存储进数据仓库,通过Hive SQL语句完成数据的分析。相比于Pig、HBase等分布式数据处理平台,Hive平台的优点如下:1)简洁易懂,能够使复杂紧耦合的Map/Reduce数据分析变成简单松耦合的SQL语句查询,使分布式数据分析更简洁易懂;2)接口通用,能够通过X/Open的SQL调用级接口服务开发框架,在分布式环境中,开发人员能够采用常用的方式访问数据。
2系统总体架构设计
本文所设计的海量数据分析系统的总体架构如图5所示。系统总体架构与传统数据分析系统相差不大,分为3部分:客户应用程序(客户端组件)、后端处理服务器和报表系统。该海量数据分析系统的基本工作流程是客户端组件收集用户使用软件信息后,根据事件数据格式,上传至接收服务器(Collector),实现汇总数据肢解后,发送至EMR,经过Mapper与Reducer之后,基于Hive平台,对数据进行合并计算,并将汇总结果导入Mysql,输出可视化报表,以供分析人员和决策人员使用。
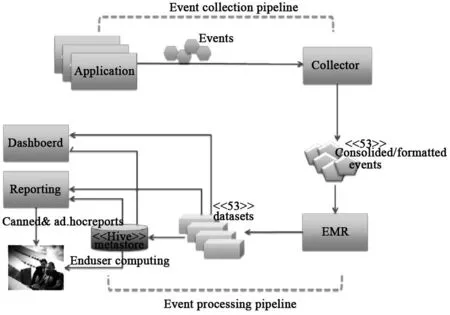
图5 系统总体架构
3系统模块分析
3.1客户端分析设计
用户在安装软件过程中,客户端同软件一起被部署到了用户计算机中,其以软件的组件形式存在。客户端的主要功能是收集客户的操作记录,并上传至后端处理服务器。客户端组件的设计需要考虑如下问题:1)事件类型的定义;2)事件数据的存储形式;3)事件发送策略。本文所设计的客户端信息流程图如图6所示。
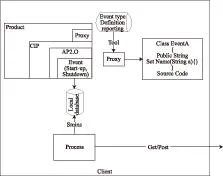
图6 客户端信息流程图
客户端组件在Proxy中定义收集用户使用软件所产生信息的数据格式,在定义数据格式过程中完成2项工作:1)完成不关心数据的剔除,以减少后端服务处理器的数据量,进而提高数据分析的效率;2)完成数据格式规范化,并将规定格式的数据存储至本地数据库,每5 min与后端处理服务器进行一次通信,上传或下载数据信息。
3.2接收服务器设计
接收服务器主要是完成与客户端组件的通信,并接收客户端发送过来的统一格式的事件,基于Tomcat的Serverlet会将事件信息写入log4j的log文件中并上传至S3。其基本工作流程如图7所示。
为确保海量数据分析结果的实时性,在设计接收服务器时应根据时间需求设定log文件上传至S3的频率。本系统设计频率为1分钟/次。这样,后端数据分析(EMR)能够在预定时间分析这些数据。系统数据分析顺序图如图8所示。

图7 接收服务器设计的基本工作流程
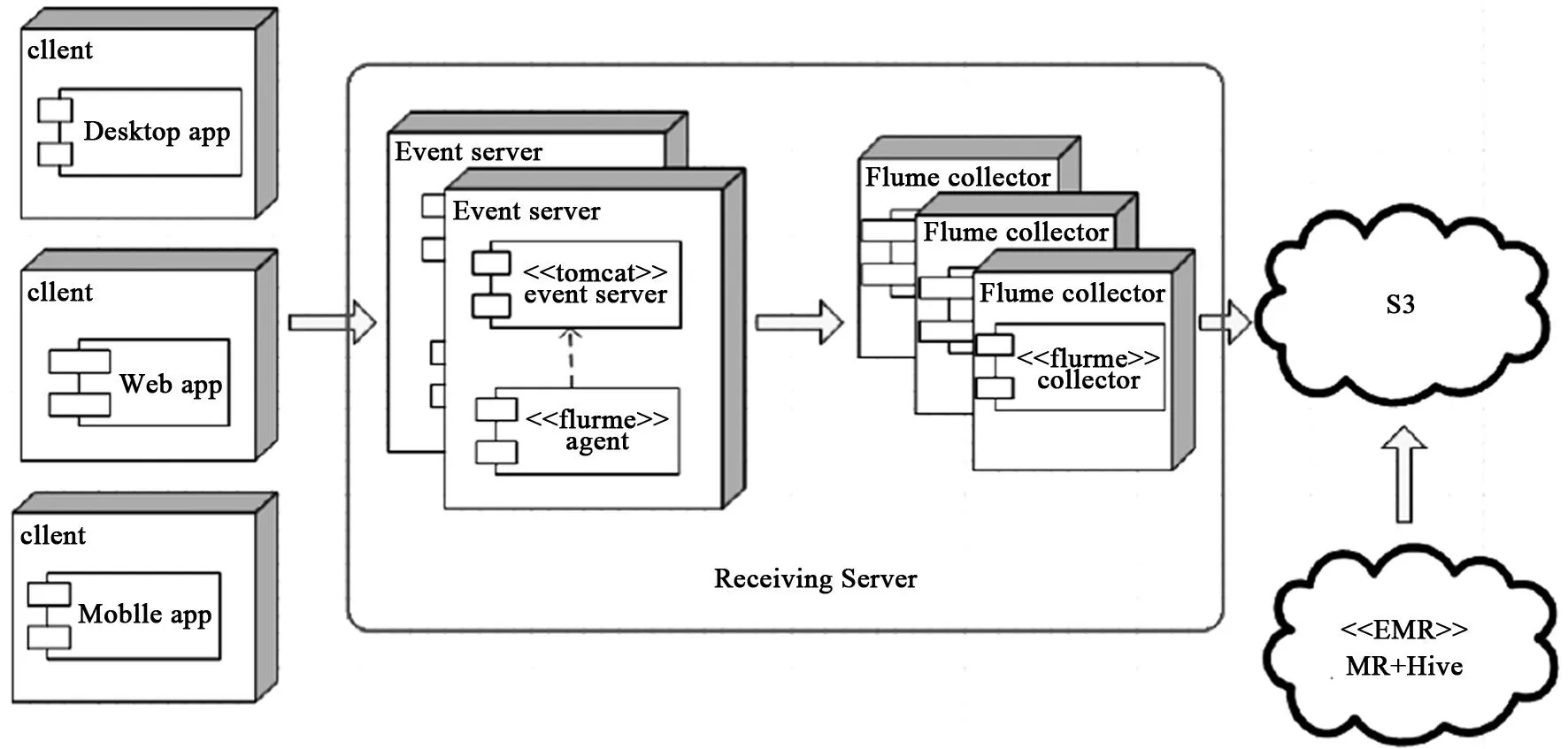
图8 系统数据分析顺序图
3.3后端数据分析设计
3.3.1数据预处理
后端数据分析之前,需要对事件数据预处理。事件数据预处理的设计主要是用来接收Event Collect的输出数据文件,并对数据类型、版本或其他属性进行区分。
预处理的基本前提条件包括:1)Event Collect输出的数据文件与S3指定目录的数据文件不冲突;2)Event Collect输出的数据文件格式必须为文本,并且每一行作为一个事件的记录,在每一个事件记录中的每一个信息的格式都是键值对(Name value pair,name=value),信息之间都是用“&”符号来隔开的;3)事件定义的Json文件与S3指定目标下的文件不冲突。
数据预处理以EMR job的形式分如下4步进行:1)输入数据文件的准备;2)Hadoop job提交;3)mapper和reducer任务执行;4)处理结果的记录、输出并上传至S3中。
3.3.2数据分析设计
完成数据预处理,并且Event Collect将所有数据输出转移后,Hadoop job初始化,数据文件所在文件夹作为该Hadoop job的输入路径。输入数据准备完毕后,EMR job运行Hadoop job开始处理输入数据文件,实现逻辑流程通常采用定制化的Mapper和Reducer来实现。程序包括Mapper、Reducer和Combiner程序,下述对程序具体实现功能进行介绍。
Mapper程序的主要功能包括:1)验证数据格式,检验下面的字段是否存在,或者格式是否正确;2)调用用来做事件格式验证的外部工具,事件数据做全数据验证,检验那些必须的字段是否有有效的赋值,并且检验其数据类型是否与事件的定义文件一致;3)提取数据文件中的字段和值以用来做数据分割和数据分发,构建key string以供Reducer使用。该key string包含如下2个部分:Event Type和Version。
Reducer程序主要基于Mapper的输出键值对,将这些数据按事件类型分类排序,并上传至S3的指定文件夹中。Reducer程序输出的数据文件可按下述格式进行命名。
L0-
其中,
Combiner程序主要是用来执行日常合并计算,并具有如下功能:1)丰富数据的属性,主要利用连接事件数据、支持数据获得;2)派生出新的数据字段,利用连接不同类型的事件数据获得;3)产生完整的session记录,利用Startup Event和Shutdown Event,获得Startup timestamp和Shutdown timestamp。实现的基本步骤包括:1)初始化支持数据的表;2)Startup、Shutdown的初始化以及恢复的划分;3)初始化Session表;4)执行合并计算逻辑,并且将结果载入到Session表中指定的分区中。针对应用需求,完成报表设计并进行合并计算,主要包含:1)初始化支持数据的表;2)初始化必须的事件或者合并计算的表;3)初始化目标表;4)执行合并计算逻辑,并且将结果载入到Session表中指定的分区中。
Combiner程序主要是根据Map/Reduce输出结果的大小来决定的,若Mapper输出结果很大,不利于网络传输,将进行合并。
3.4数据可视化设计
海量数据分析系统最终呈现给决策人员的信息,主要通过数据可视化来实现,从而使分析结果变得直观可见。主要分为数据存入Mysql和系统报表动态生成。
数据存入Mysql主要是通过Hadoop所提供的接口,完成数据库链接,遍历各项Hive表,读出Hive表中的数据,并存入Mysql中。根据海量数据分析系统前端程序的设计,生成不同样式、不同时间节点、可供直观阅读和分析的数据分析报表,供分析人员和决策人员使用。
4结语
在信息社会,人们的生活正在发生潜移默化的转变,所产生的数据量呈指数式增长,要想从海量数据中分析得到有用的信息,云计算环境所提供的分布式处理、并行计算等成为必然选择。本文通过分析Hadoop、Map/Reduce以及Hive平台,完成了云计算环境下海量数据分析系统的设计,对海量数据分析系统设计具有一定的参考价值。
参考文献
[1] 陈康,郑纬民.云计算:系统实例与研究现状[J].软件学报,2009(5):1337-1348.
[2] 王敬昌.基于Hadoop分布式计算架构的海量数据分析[J].数字技术与应用,2010(7):6-7.
[3] 程苗,陈华平.基于Hadoop的Web日志挖掘[J].计算机工程,2011(11):37-39.
[4] 刘永楠,王宏志,高宏.Map/Reduce 框架下基于字符串波形的实体识别方法[J].计算机科学与探索,2011,5(8):730-739.
[5] 魏永山,张峰,陈欣,等.一种云计算环境下的XML查询数据服务的优化方法[J].计算机工程与科学,2013,35(6):30-36.
[6] Tom White. Hadoop权威指南[M]. 北京:清华大学出版社,2010.
[7] 郑启龙,房明,汪胜,等.基于Map/Reduce模型的并行科学计算[J].微电子学与计算机,2011,26(8):13-17.
[8] Thusoo A, Sarma J S, Jain N, et al. Hive-A petabyte scale data warehouse using Hadoop[C]//Proceedings of the 2010 IEEE 20th International Conference on Data Engineering (ICDE), USA:IEEE, 2010:996-1005.
责任编辑郑练

Design of Massive Data Analysis System based on Cloud Computing Environment
SU Xi1, SU Yani2, HUO Mihui3
(1.Xi’an Medical University, Xi’an 710021, China; 2.Shaanxi People’s Hospital, Xi’an 710068, China;
3.Huawei Technology Co., Ltd., China)
Abstract:For the problem that the data analysis system is hardly to be applied in massive data for storage, analysis and processing efficiency, real-time, integrity and data maintenance costs, etc, the application of the cloud computing environment in the massive data analysis is ultra large scale, virtualization, economy and security is proposed. Based on the distributed computing architecture of Hadoop, using the parallel framework of Map/Reduce, the typical cloud computing environment is constructed. When adopt the analysis of the data warehouse platform Hive, the effectively and practical massive data analysis system is designed. With the design of the overall framework of the system as the foundation, analyze from the client, the receiving server, back-end data analysis, data visualization, and so on, the massive data analysis processing system design has a certain reference value.
Key words:massive data analysis, cloud computing environment, distributed computing, parallel processing, system design
收稿日期:2015-02-09
作者简介:苏曦(1987-),男,硕士,助教,主要从事统计与数据处理等方面的研究。
中图分类号:TP 311.5
文献标志码:A
