基于SVM一对一多分类算法的二次细分法研究*
2013-10-22陈中杰
陈中杰,蒋 刚,蔡 勇
(1.西南科技大学计算机科学与技术学院,四川绵阳 621010;2.西南科技大学制造科学与工程学院,四川绵阳 621010)
0 引言
目前,对于支持向量机(SVM)分类算法[1]中的一对一多分类算法,许多学者都进行了多方面的研究。例如:肖荣,李金凤,覃俊[2]以及康维新,彭喜元[3]提出了基于快速粗分类的一对一多分类算法。安欣,王韬,张录达[4]阐述了基于SVM一对一多分类方法的应用前景。赵有星,李琳[5]通过对构成分类边界的超平面的研究,引入了“核空间距离”。
对SVM一对一多分类算法的上述研究,均忽略了样本出现不可分区域的问题,而是粗略地选择其中序号最小的那一类作为测试数据的类别或者是根据决策函数实际值的大小分到与之距离最近的类中[3~6]。本文针对一对一多分类算法出现不可分区域的问题,提出了基于SVM一对一多分类算法的二次细分方法,并通过实验仿真验证该方法的优势。
1 SVM多分类算法
SVM分类算法最初是为二值分类问题设计的,目前,常用的有一对多方法、一对一方法。
1.1 一对多算法
一对多方法(one-versus-rest):训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样N个类别的样本就构造出了N个SVM分类器,分类时将未知样本分类为具有最大分类函数值的那类。流程如下:
假定将第j类样本看作正类(j=1,2,…,k),将其他k-1类样本看作负类,通过两类SVM方法求出一个决策函数

这样的决策函数一共有k个。给定一个测试样本x,将其分别带入k个决策函数并求出函数值,若在k个f(x)中fs(x)最大,则判定样本x属于第s类。
1.2 一对一算法
一对一方法(one-versus-one):其解决方法是在k类问题中进行两两组合,使用每两类的训练样本,构建类对间的最优超平面。给定样本集(x1,y1),…,(xi,yi),xi∈Rn,i=1,…,k,yi∈{1,…,k}类对 ij的决策函数定义如下

该决策函数可通过以下二次规划问题求解

上式针对所有n个样本求解,由于fij(x)=fji(x),因而对于一个k类问题,共有k(k-1)/2个不同的决策函数,将k类问题划分为多个两类分类子问题进行求解,最终可直接求得任意两类之间的分类边界。
在一对一方法中,分类的方法是:“投票机制”,即多数获胜,每个分类器为它的首选类投出一票,最终结果就是拥有票数最多的类别,也就是样本x属于类i,当且仅当
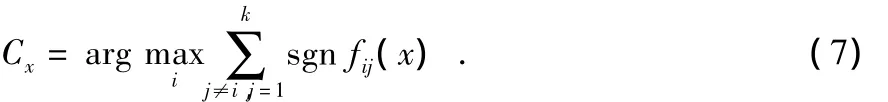
其中,Cx为样本x属于类i时的票数,sgn fij是符号函数,即当fij值为正数时,函数值为1;否则,为0。
当多于一个类别具有相同数目的最多票数时,即出现不可分区域的问题。那么,不可分区域中的样本点就会选择其中序号最小的那一类作为测试数据的类别或者是根据决策函数实际值的大小分到与之距离最近的类中

其中,Vx为样本 x属于类i时决策函数的实际输出值[6]。
通过对一对一多分类算法的描述,可以看出:由于该算法的“投票机制”会出现“平局”现象,即出现了不可分区域问题,从而降低了分类的准确率。
原始一对一分类算法,如图1所示。
2 基于SVM一对一多分类算法的二次细分方法
根据第1节对一对一多分类算法的介绍,该算法会出现不可分区域的问题,从而降低了分类的准确率。
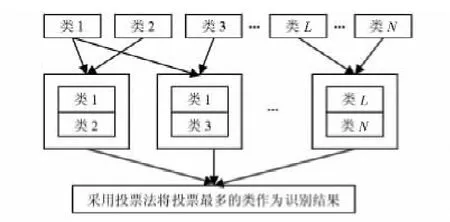
图1 原始一对一分类算法Fig 1 Original one-versus-one classification algorithm
本文在研究了目前学者处理此问题的方法之上,提出了基于SVM一对一多分类算法二次细分方法。该方法的思想如下:
1)首先,也是对N类样本构造N(N-1)/2个SVM子分类器。例如:对于第i类和第j类,构造第i类和第j类的SVM子分类器。
2)对测试样本x在第i类和第j类构造的子分类器上进行分类预测。根据决策函数(2):若样本x属于第i类,则第i类投票数加1;若样本x属于第j类,则第j类投票数加1,累计各类的得分。
3)统计每一个测试样本的得票数,从而得到的各个样本的最高的票数,获取各个样本的最高得票数。根据最后的得票数,若样本有单个最高得票数,则把该样本分为所相应的类别。
4)若对同一样本有多个最高得票数,则把这几个最高得票数相对应的类别的训练数据组成新的训练集,对该测试样本在新组成的训练集上重新进行分类预测,最后得出测试样本的类别。
一对一多分类算法的二次细分方法,如图2所示。
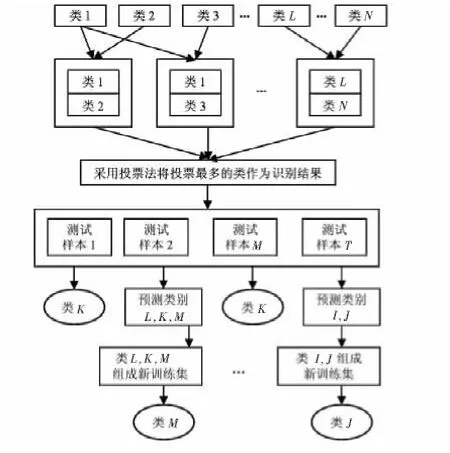
图2 一对一多分类算法的二次细分方法Fig 2 The secondary subdivision method for one-versus-one multi-classification algorithm
3 应用实例与结果分析
本次仿真实验的数据来源于2种不同弹性系数的弹簧组合下的弹性应力变化值。本次实验构建10组不同的弹簧模型,每组采集10个样本,每个样本201个特征。
实验以每组组合的前7个样本作为训练集,共10×7=70的训练样本,后3个样本作为测试样本,共10×3=30个测试样本。本次仿真实验选取RBF作为核函数,实验过程如下:
1)首先对所有样本数据进行小波包去噪,并对去噪后数据进行归一化处理。
2)利用主成分分析法(PCA)对所有数据进行降维和特征提取。
3)采用基于SVM一对一算法对训练样本进行分类建模,并对测试样本进行分类预测,最后获得各个样本的投票统计数据,如表1所示。
4)根据第(3)步的投票统计结果,若同一样本有单个最高得票数,则把该样本分为所相应的类别。若同一测试样本有多个最高得票数,则采用改进后的方法,把最高得票数对应的训练数据组成新的训练集,从而对该测试样本在新组成的训练集上重新进行分类预测,最后得出测试样本的类别。
因样本众多,现只将第一组弹簧模型的第七个样本数据的原始图像(如图3),小波包去噪后图像(如图4),PCA降维和特征提取后图像(如图5)列出。
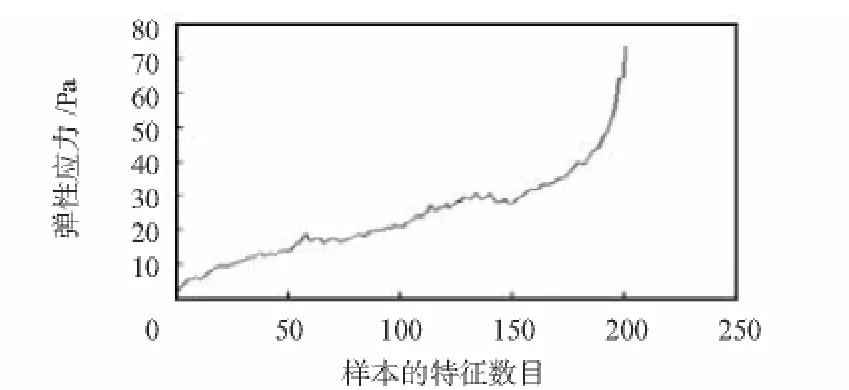
图3 样本原始图像Fig 3 Original image of sample

图4 样本小波包去噪图像Fig 4 Wavelet packet denoising image of sample

图5 样本PCA降维特征提取后图像Fig 5 Feature extraction and dimensionality reduction image with PCA of sample
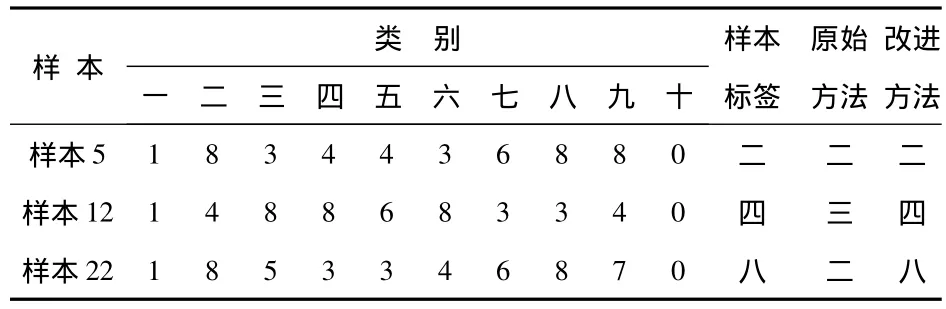
表1 投票后出现不可分区域的样本在原始方法与改进方法后的分类结果Tab 1 Classification results after original and improved methods of sample about inseparable area after voting
由上表可知:第5个样本在第二类、第八类和第九类获得同样的最高得分8分;第12个样本在第三类、第四类和第六类获得同样的最高得分8分;第22样本在第二类、第八类获得同样的最高得分8分。因此,如果按原始方法进行分类,即选择小序号类作为测试数据的类别,则第5个样本被正确分类,而第12个样本被错分为第三类,第22个样本会被错分为第二类。
改进的方法:对于第12个样本,把出现最高得分的第三类、第四类和第六类作为训练集,重新进行训练,再进行分类预测。同理,对于第22个样本,把出现最高得分的第二类、第八类作为训练集,训练后再进行分类预测。
在分类准确率和花费时间上,改进的方法和传统的一对一算法进行比较。结果如表2所示。

表2 分析结果一览表Tab 2 List of analyzed results
通过表2可以看出:改进的方法与原始的方法相比,改进的算法在多花费了极短的时间(0.018 3 s)的前提下,显著提高了分类的正确率。同时通过表1和表2的结果可以看出改进的方法对样本12和样本22进行了正确的分类,证明了该方法的可行性。
但是,该方法还存在一定的问题,即,若第二次细分之后还是出现同一样本有多个最高得票数的情况,是否还需要进行第三次细分,本文通过再进行另外9次仿真实验进行验证。10次实验仿真结果如表3所示。
通过表3可以看出:只有实验三和实验六在第三次细分之后在很小程度提高了分类准确率;实验一、实验二、实验五、实验七、实验九在第三次细分之后的准确率与二次细分方法保持一致,没有提高,反而多消耗了一定的时间;实验四、实验八、实验十只通过二次细分方法就达到了100%的准确率,不需要进行第三次细分。
通过以上分析可以看出:只有很小一部分的数据(20%)提高了分类的准确率,大多数的数据(80%)没有提高分类的准确率,反而大大增加了分类所需要的时间。因此,针对小样本数据问题,只进行二次细分方法就能达到理想的分类准确率,没有必要进行继续细分。
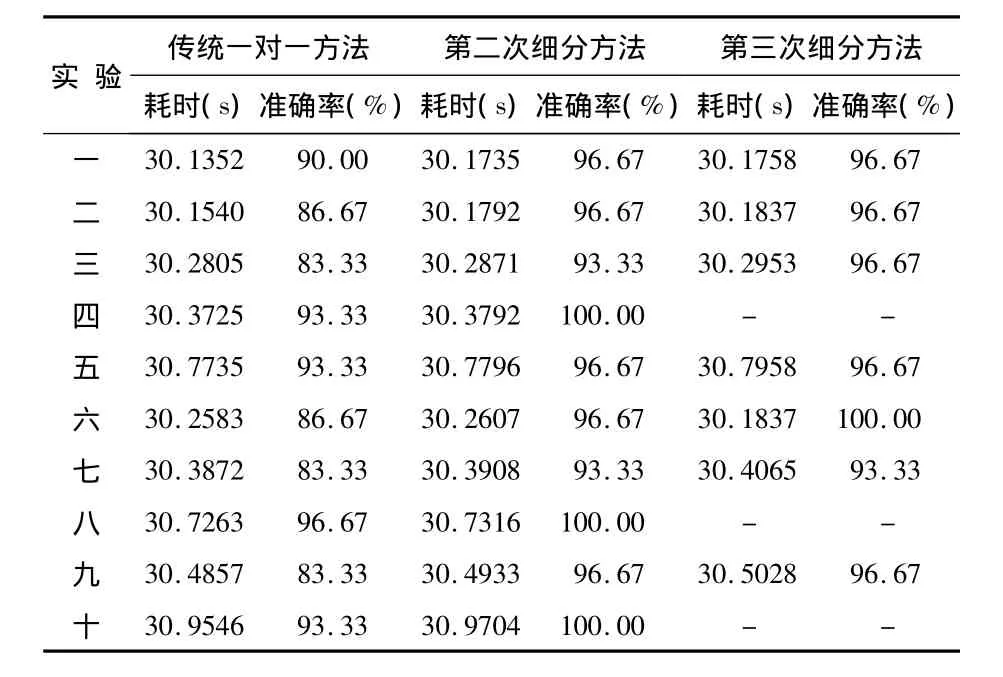
表3 10次实验结果一览表Tab 3 List of ten times experimental results
4 结束语
本文针对一对一多分类算法中出现不可分区域的问题,提出了基于SVM的一对一多分类算法的二次细分方法。仿真证明:改进的方法在处理小样本数据有突出的优势,可以明显提高分类的正确率。
[1] Vapnik V.The nature of statistical leaning theory[M].New York:Springer Press,1995.
[2] 肖 荣,李金凤,覃 俊.一种改进的一对一多类支持向量机[J].软件导刊,2010,9(10):109 -111.
[3] 康维新,彭喜元.基于二层SVM多分类器的桩基缺陷诊断[J].电子学报,2009,36(12A):66 -70.
[4] 安 欣,王 韬,张录达.一种基于SVM分类的多类识别方法及应用[J].北京农学院学报,2006,21(2):20 -22.
[5] 赵有星,李 琳.基于支持向量机的多类分类算法研究[J].计算机与信息技术,2007,29(1):129 -130.
[6] 王 天,叶秀芬,刘晓阳,等.基于SVM算法的碟形水下机器人姿态预测方法研究[J].传感器与微系统,2012,31(4):56 -59.
[7] Hsu C W,Lin C J.A comparison of methods for multi-class support vector machines[J].IEEE Tran on Neural Networks,2002,13(2):415-425.
[8] Agarwal K.Process knowledge-based multi-class support vector classification(PK-MSVM)approach for surface defects in hot rolling[J].Expert Systems with Applications,2011,38(6):7251-7262.
[9] Debnath R,Takahid N,Takahashi H.A decision based on oneagainst-one method for multi-class support sector machines[J].Pattern Anal Applic,2004,1(5):164 -175.
