汽油调合优化神经网络模型的研究
2013-07-19钟英竹
钟 英 竹
(中国石化石油化工科学研究院,北京100083)
汽油调合是汽油生产过程中的一个重要环节,调合时部分性能参数呈非线性变化(如辛烷值、诱导期等),导致调合过程较难实现自动控制。国外通过对汽油调合机理的深入研究,开发出汽油在线调合技术。目前已经工业化应用的产品主要有Honeywell公司的优化调合软件包BPC、HIS公司的产品调合调度软件 H/BOSS、AspenTech公司的ORION等产品。这些技术都具有汽油组分利用率高、调合方案合理、经济效益显著等特点。上述汽油在线调合技术的核心都采用了机理类模型,通过非线性回归、偏最小二乘回归、模糊控制等方法来解决非线性预测问题[1]。
近年来,国内引入了多套汽油在线调合设施,实际使用中都存在“水土不服”的现象,存在的问题主要是对关键的非线性调合参数(辛烷值、抗爆指数等)的预测存在较大误差。导致产生这些问题的原因是多方面的,一个重要原因是中国汽油组成中催化裂化组分的比例较高(超过70%),造成汽油的调合机理与国外有所不同,从而使得根据国外数据开发的机理模型不能适应国内油品的调合需求。同时由于各炼油企业生产工艺不同,调合组分也不尽相同,所以从国外引入的汽油调合系统需要二次开发,以建立适合国内具体企业调合过程的机理数学模型[2-5]。
汽油调合优化技术的关键是汽油调合模型能够精确计算非线性参数,并能够通过优化得到最佳的汽油调合方案。由于国内汽油调合组分种类较多,且不同调合组分产量的波动性较大,因此还要求开发的汽油调合模型具有较强的自适应特性。考虑到目前对汽油调合的机理尚不很清楚,而神经网络模型通过模拟生物神经网络进行信息处理,不需要建立机理模型,适应性强;在理论上可以任意精度拟合任意复杂的非线性函数,适合复杂的非线性过程;同时具有自学习、自组织和自适应性。另外,经过多年的发展,神经网络模型技术已经在图像识别、决策支持等人工智能领域得到成功应用[6-8]。因此,本课题尝试借助神经网络技术,在不需要研究调合机理的前提下,结合某炼油企业汽油生产和调合的特点,有针对性地开发一种通用性强、可自我学习、且具有较高预测精度的汽油调合整体优化模型。
1 汽油调合神经网络模型的建立
建立神经网络模型的关键是根据实际需要,确定合理的输入参数和输出参数的个数;并根据研究对象的特点,确定合理的神经网络的拓扑结构;最后,根据研究对像的内在规律,确定模型的学习方法以及隐含层神经元节点数量等参数。因此,本课题首先对某炼油企业汽油生产和调合装置的特点进行了分析。
1.1 输入及输出参数的确定
某炼油企业有20多套生产装置,其中汽油调合组分主要有催化裂化汽油(又分为蜡油催化裂化汽油和重油催化裂化汽油)、重整脱苯汽油、烷基化汽油和少量的MTBE等添加剂。目前,该企业主要采用人工计算不同组分的用量,通过汽油组分倒罐调合的方式生产93号和90号两种汽油产品。存在的主要问题是经常出现产品质量,尤其是辛烷值过剩的现象。
通过对该企业汽油组分历史数据进行分析,发现某些汽油组分的部分参数变化较小,如重整脱苯汽油的烯烃、芳烃、苯的含量,烷基化汽油辛烷值、MTBE组分辛烷值等。基于这一特点,本课题确定了神经网络需要考虑的6个输入参数,分别是:催化裂化汽油产量、重整汽油产量、烷基化汽油产量、MTBE产量、催化裂化汽油辛烷值、重整汽油辛烷值。同时,针对该企业汽油调合需要解决的问题,确定了神经网络需要考虑的6个输出参数,分别是93号汽油调合方案(4个汽油组分用量)、93号汽油的辛烷值和90号汽油的辛烷值。
利用选定的输入参数和建立的神经网络模型,不仅能够得到优化的汽油调合方案,而且能够精确预测调合汽油的辛烷值,从而避免汽油质量过剩,增加企业经济效益。
1.2 拓扑结构的确定
汽油调合模型的关键是要准确预测调合汽油的辛烷值。要实现这一目标,关键是要建立与实际过程相适应的合理的神经网络拓扑结构。
神经网络模型主要由输入层、隐含层和输出层组成。神经网络隐含层和隐含层神经元节点的数量决定着网络的规模和复杂程度。隐含层和隐含层神经元节点的数量越多,神络网络的规模就越大,其自由参数就越多。在利用网络进行优化时,网络规模过小,容易导致拟合能力不足,无法得到合理的汽油调合方案。相反,如果网络规模过大,不仅会导致网络过于复杂,使得网络参数的求解非常困难与费时,而且容易导致过度拟合。在这种情况下,尽管网络具有较强的拟合能力,但其预测能力则往往较弱,同样也无法通过优化得出合理的汽油调合方案。汽油调合是一个连续过程,不存在突发、大幅度跳跃的调合事件。从数学角度来看,汽油调合过程中辛烷值等参数是相关调合参数的连续函数,采用一个隐含层结构的神经网络可以满足建立模型的要求,因此汽油调合模型确定采用一个隐含层。通过上述分析,确定了该企业汽油调合神经网络的拓扑结构,如图1所示。由图1可以看出,拟构建的汽油调合神经网络模型共三层组成,其中最下面的一层是输入层,共有6个输入参数,分别是催化裂化汽油产量、重整汽油产量、烷基化汽油产量、MTBE产量、催化裂化汽油辛烷值和重整汽油辛烷值,这些参数均是该企业日常生产过程中能够提供的基本数据;最上面一层是模型的输出层,分别是93号汽油调合配方,即催化裂化汽油用量、重整汽油用量、烷基化汽油用量和MTBE用量,以及调合得到的93号汽油的辛烷值和90号汽油的辛烷值,这些输出数据正是汽油调合生产中最为关心的需要优化与预测的重要参数;模型的中间一层是隐含层,它能够从输入层获取汽油调合的初步信息,通过调节输入层与隐含层以及输出层相应神经元阈值或连接权值,使网络的输出值逼近实际生产的期望值,并可根据网络输出值与实际生产数据的差值反向调节相应神经元的阈值或连接权值,通过隐含层将输入层的输入参数与输出层的输出参数合理地映射起来,从而使模型不仅具有较强的拟合能力,同时也具有较强的预测能力。根据该企业汽油调合的实际情况,确定神经网络中输入层、隐含层以及输出层之间正向和反向传递函数均采用单极性Sigmoid函数。
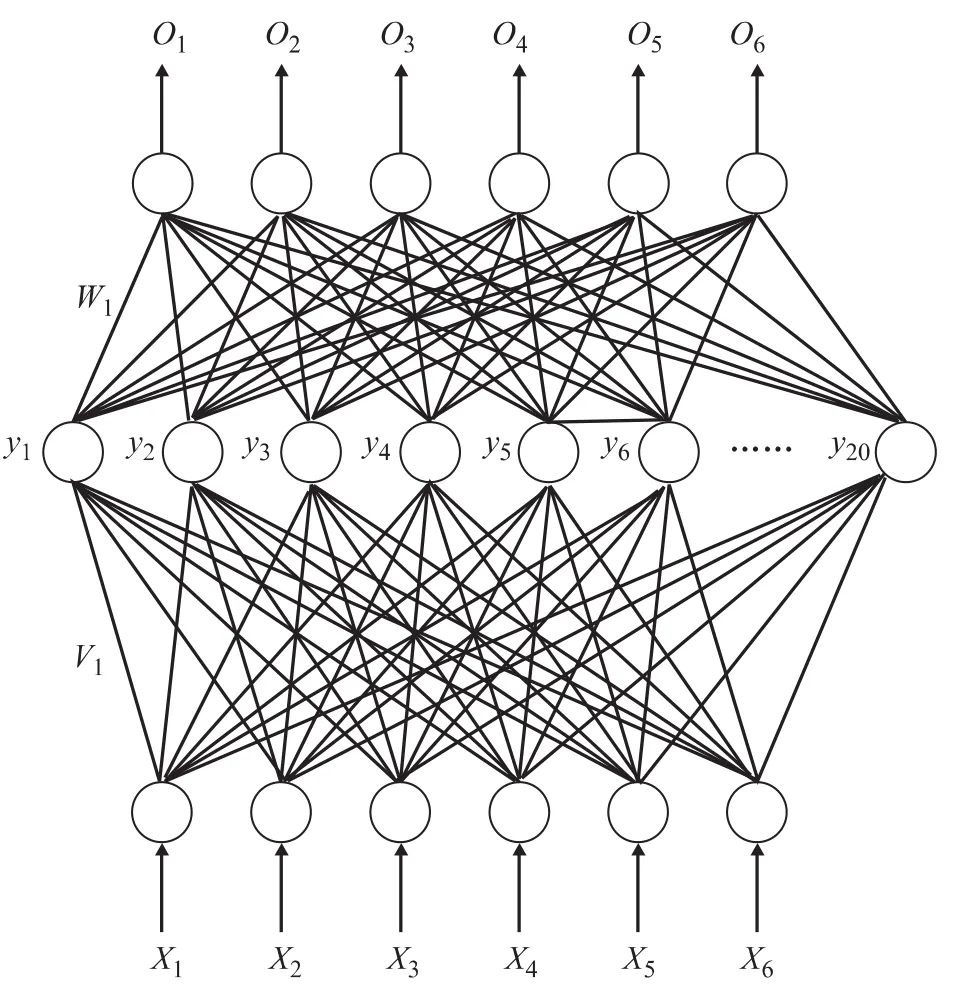
图1 汽油调合神经网络模型拓扑结构
1.3 隐含层神经元节点的数量确定
隐含层神经元节点数量的确定是神经网络设计中非常重要的一个环节。研究发现[9-10],隐含层神经元节点数过少时,网络从样本中获取信息的能力就差,不足以概括和体现训练集中的样本规律,导致网络或是不能收敛到规定误差,或是虽然能够完成学习,但泛化能力不强。相反,隐含层神经元节点数过多,又可能把样本中非规律性的内容(如噪声等)也学会并记牢,从而出现“过度吻合”问题,不仅降低了网络的适应能力,还增加了训练时间。尽管隐含层神经元节点数量对神经网络的成败如此重要,但是,对于如何确定隐含层神经元节点数量,目前理论上还没有一种科学的普遍方法。通常是根据前人设计所得的经验和自己进行试验来确定。考虑到隐含层神经元节点的作用是从样本中提取并存储其内在规律,且每个隐含层神经元节点均有若干个连接权值以表示其从输入层到输出层映射的强弱。另外,考虑到汽油调合的难点与关键是如何准确预测非线性变化的汽油辛烷值,为尽快确定汽油调合神经网络合理的隐含层神经元节点数量,对图1所示汽油调合神经网络模型拓扑结构进行了简化,制定了图2所示辛烷值预测神经网络。
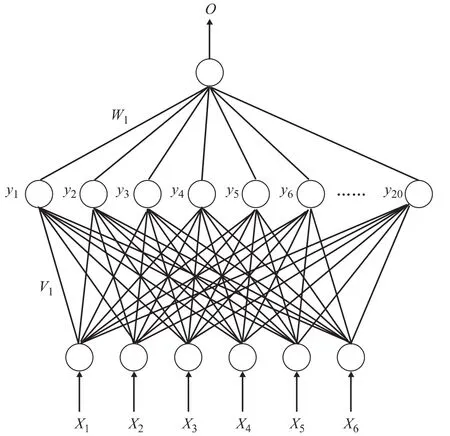
图2 辛烷值预测神经网络模型拓扑结构
与图1所示汽油调合神经网络不同的是,图2所示辛烷值预测神经网络仅有一个输出参数,即不同配方调合的汽油的辛烷值。
以该炼油企业的109组生产数据为基础,编制了相应程序,希望通过试凑的方法,即先设置较低的隐含层神经元节点数量来训练网络,然后逐渐增加隐含层神经元节点数量,并同样采用这109组生产数据训练网络,从中确定预测误差最小时对应的隐含层神经元节点数量。图3为不同隐含层神经元节点数量所对应的网络预测复相关系数及其随隐含层神经元节点数量的变化趋势。
由图3可以看出:当隐含层神经元节点数量较少(为5)时,预测复相关系数较低,仅为0.985 63;随着隐含层神经元节点数量逐渐增加,预测复相关系数呈先增加后降低的变化趋势,当隐含层神经元节点数量为15时,预测复相关系数达到最大值,为0.998 11。这表明对该炼油企业汽油调合模型来说,神经网络预测精度并不是隐含层神经元节点数量越多越好,而是有一个合适的范围,在15左右较合适。考虑到辛烷值预测模型的输出参数只有1个,而本课题所研究的汽油调合神经网络模型输出参数为6个,比上述模型的输出参数多,预测难度也大,因此隐含层神经元节点数量稍多一些可能更为合适。最后确定该企业汽油调合神经网络模型隐含层神经元节点数量为20个。
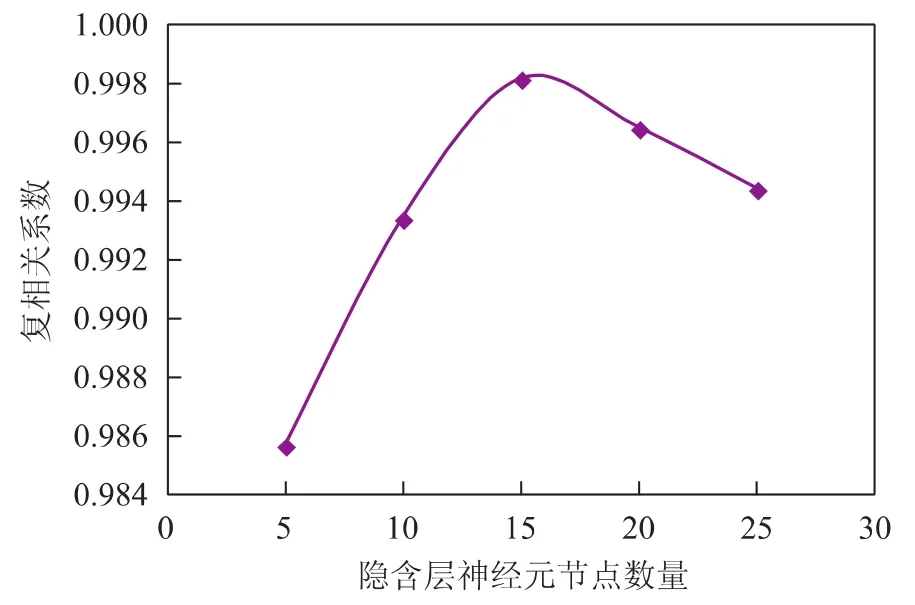
图3 复相关系数随隐含层神经元节点数量变化趋势
2 模型的训练与应用
2.1 训练与应用情况
为了对所建立的神经网络模型进行学习训练,从该炼油企业采集了50组生产数据作为学习训练数据。这些数据包括不同汽油组分的产量、辛烷值、烯烃含量、芳烃含量以及实际生产中最优化的调合方案等。经过50组生产数据的学习训练后,不同神经元的阈值以及神经元之间的连接权值得到了优化调整,生成了拟合度高,预测误差小,输出最优汽油调合方案与实际生产中得到的最优调合方案相符的神经网络。
为检验所建立神经网络的使用性能,对模型进行了测试。为使测试更加接近工艺生产的实际情况,测试时没有采用学习训练时采集的数据,而是另外采集了25组生产数据。神经网络模型输出的调合汽油辛烷值及实际测得的调合汽油辛烷值对比情况如图4和图5所示。神经网络模型输出了调合汽油的最佳配方,即详细的催化裂化汽油用量、重整汽油用量、烷基化油用量以及MTBE用量,图6~图9为神经网络模型输出的调合汽油组成数据与实际生产数据的对比情况。
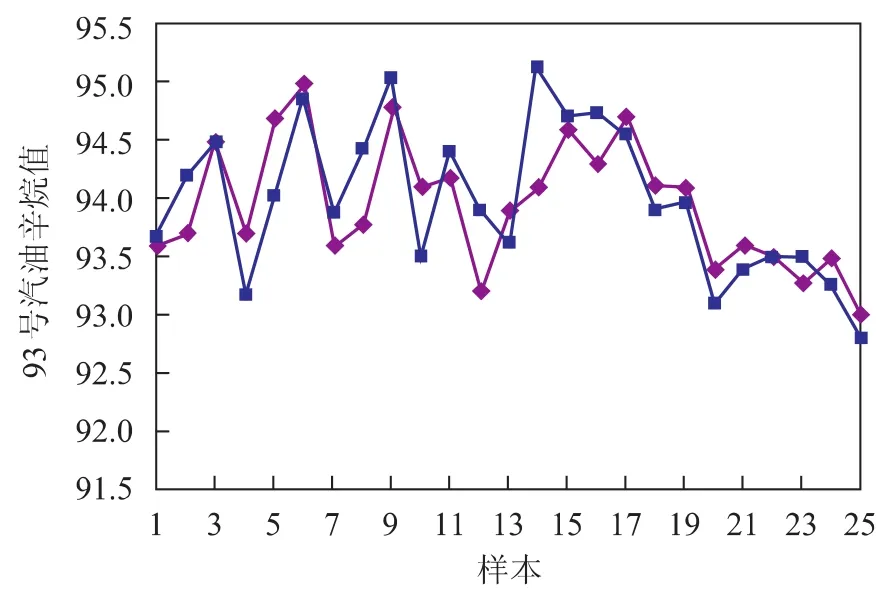
图4 93号汽油辛烷值
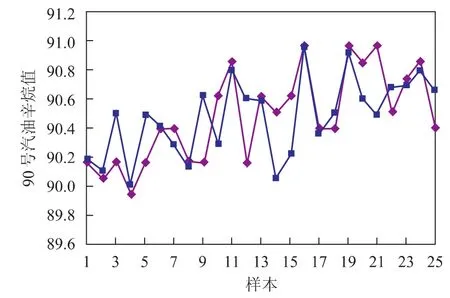
图5 90号汽油辛烷值
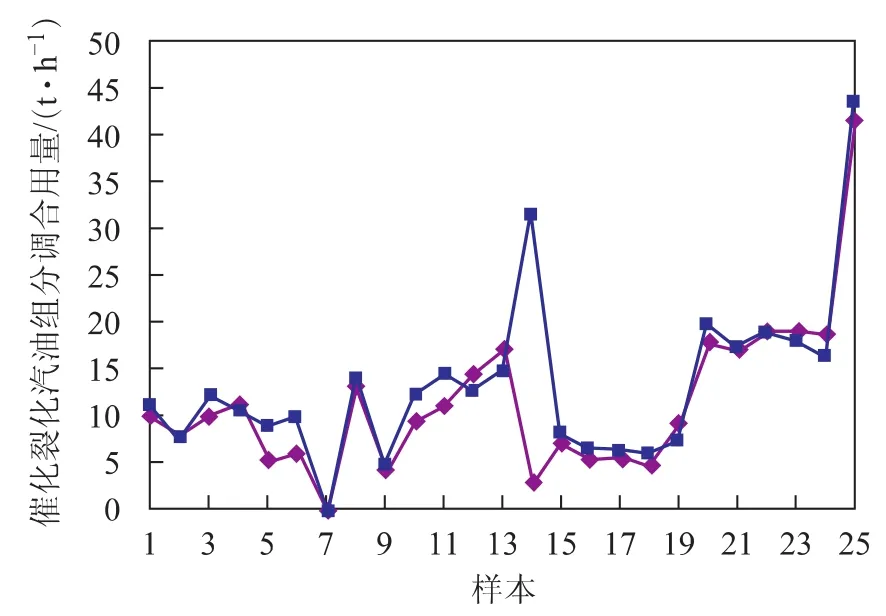
图6 93号汽油中催化裂化汽油用量
从图4~图9可以看出:采用神经网络模型得到的调合方案与实际优化后的数据接近;所预测的93号汽油的辛烷值、90号汽油的辛烷值均与实际生产数据接近。说明构建的BP型汽油调合神经网络模型能较好地模拟生产实际情况,对辛烷值的预测精度、输出的优化调合方案均能满足生产要求。
2.2 模型存在的问题
在模型的数据训练、验证过程中,发现该调合模型也存在若干问题。
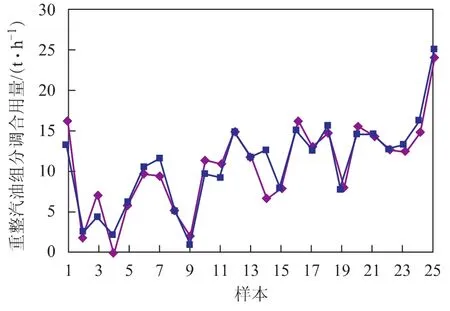
图7 93号汽油中重整汽油用量
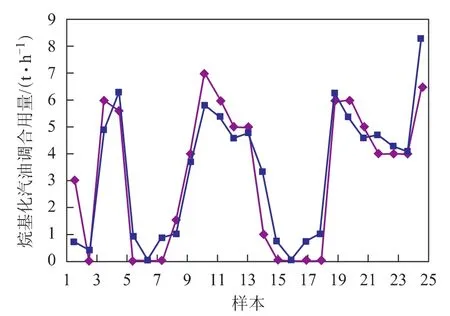
图8 93号汽油中烷基化汽油用量
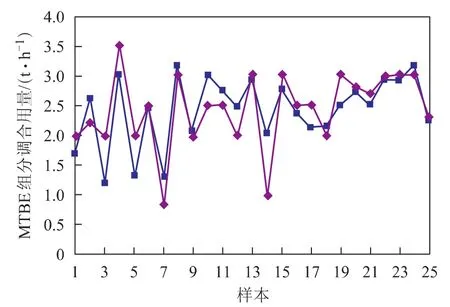
图9 93号汽油中MTBE用量
2.2.1 训练样本的输入顺序对结果有一定的影响 在对调合模型的训练算法中采用了即时调整神经元连接权值的方法,即每输入一个学习样本后,根据其误差立即调整各神经元节点的连接权值。这种方法具有存储空间小、训练速率快等优点,但也存在着误差收敛条件难以满足等问题。在采用大量数据训练过程中,神经元节点的连接权值容易受后来输入数据的影响,某些顺序下,该网络模型误差较大,无法得出有效解。经过大量的分析研究,认为这一缺陷可以采用批处理学习的方法来消除。方法是将一个训练周期的全部样本一次性输入神经网络,以总的平均误差为学习目标函数来修正神经元节点的连接权值。改进后的模型可以较好地避免样本输入顺序造成的影响,但收敛速率稍有降低。
2.2.2 与实际相比,模型优化结果有一定的误差 实际验证过程中部分结果与实际生产的误差较大,这是建模过程的简化处理所致:①忽略了辛烷值的配伍性。模型假定烷基化汽油、MTBE组分的辛烷值基本不变,实际上这些参数相互间存在配伍性,各组分辛烷值在配比不同时会略有变化,这种简化导致了神经网络模型的预测误差增加。②忽略了其它制约因素的影响。在实际汽油调合过程中,硫含量、烯烃含量、氧含量等因素也会制约总的调合方案,而建模过程中对上述因素进行了简化,这些也对模型预测结果造成影响。
虽然存在上述问题,但研究结果表明BP神经网络可以适用于清洁汽油生产的调合优化过程。如果进一步完善模型,考虑配伍性及其它制约因素,可以采用更大规模的神经网络,用更多的输入参数、更多的隐含层、更多的神经元节点,同时采用更多的训练数据,理论上可以减小上述误差。
3 结 论
(1)采用BP型神经网络建立汽油调合优化模型具有可行性,预测精度较高,工程适应性较好。实际应用结果表明,构建的BP调合网络模型可以提供满足生产要求的优化调合方案,对非线性参数预测误差小,对汽油调合过程具有较好的优化指导作用,具有一定的工业实用性。
(2)基于神经网络技术开发的汽油调合优化模型的适应性强,不需要建立调合机理模型,可以适合不同的炼油企业,具有较好的工业适应性。
(3)通过增加输入参数、增加隐含层的节点数量、改进样本的训练算法、采用较快计算能力的硬件系统,建立的神经网络模型可以进一步减少误差,输出更高精度的优化方案。
[1]Zahed A H,Mulla S A,Bashir M D.Predict octane number for gasoline blends[J].Hydrocarbon Processing,1993(5):85-87
[2]薛美盛,李祖奎,吴刚,等.成品油调合调度优化模型及其应用[J].石油炼制与化工,2005,36(3):64-68
[3]王继东,王万良.基于遗传算法的汽油调合生产优化研究[J].化工自动化及仪表,2005,32(1):6-9
[4]李为民,徐明春,许志伟.基于红外光谱——神经网络预测汽油辛烷值[J].炼油技术与工程,2005,35(12):45-47
[5]秦秀娟,陈宗海.汽油辛烷值神经网络预测模型的设计[J].控制与决策,1999,14(2):151-155
[6]郑培,黎建强.基于BP神经网络的供应链绩效评价方法[J].运筹与管理,2010,19(2):26-32
[7]胡明霞.基于BP神经网络的入侵检测算法[J].计算机工程,2012,38(6):148-150
[8]黎小辉,朱建华,武本成,等.基于BP神经网络的液化石油气芳构化反应体系的预测模型[J].化学工业与工程,2012,29(1):39-42
[9]韩力群.人工神经网络理论、设计及应用[M].北京:化学工业出版社,2002:17-60
[10]朱双东.神经网络应用基础[M].沈阳:东北大学出版社,2000:55-75
