基于多依赖图和知识融合的方面级情感分析模型
2024-03-29何勇禧韩虎孔博
何勇禧,韩虎,孔博
(兰州交通大学 电子与信息工程学院,甘肃 兰州 730070)
方面级情感分析(aspect-based sentiment analysis,ABSA)旨在对文本中给定的方面词进行情感极性分类,包括正面、中立和负面[1],是自然语言处理 (natural language processing,NLP) 领域的重要研究方向.如“The food was great and tasty,but the sitting space was too small.”,ABSA 能够将方面词 “food”和“sitting space”分别分类为积极和消极.
图卷积网络(graph convolutional networks,GCN)[2]因具有有效处理非结构化数据,特别是句子句法依赖树方面的优点,已经被广泛应用于方面情感分析[3-5].Zhang 等[6]证明如依赖树的句法信息在捕获从表面形式看不清楚的长距离句法关系方面非常有效.有许多成功的方法在依赖树上使用GCN 模型进行方面级情感分类,如王汝言等[7]利用依存树中的语法距离特征对GCN 的邻接矩阵进行加权,以减少与方面词语法上不相关的信息干扰;Zhang 等[8]将句子的依存关系树输入GCN,以充分利用句法信息和单词的依存关系;Sun等[9]在句法依赖树上构建GCN,并结合BiLSTM来捕获关于词序的上下文信息;Wang 等[10]提出新型的面向方面的依赖树结构,将方面词作为新的根节点,通过重新构建原始依赖树并进行修剪,消除了不必要的关联,实现了更高效的结构.上述方法表明,句法信息有助于将方面词与相关意见词直接关联,以提高情感分类的鲁棒性;但Wang 等[10]同时发现,现有的方法容易出现解析错误.尽管在标准基准测试上具有很高的边缘解析性能,但先进的依赖解析器通常难以预测完美的解析树.He 等[11]证明深度模型能够恢复远距离依存关系,但会产生明显错误,语法解析器仍有改善的空间;Sachan 注入语法后的Transformer 性能是否提升在很大程度上取决于依存关系解析[12].这对基于依赖的方法提出了巨大挑战,即句法结构的额外好处并不总是能抵消模型句法解析带来的噪声.
尽管GCN 对语法和语义进行了协同开发,但仍存在局限性:GCN 通常用于处理全局语法信息,掩码操作最后用于隐藏上下文单词,决定了方面词的情感分类.增强文本的语义信息须融合外部知识,在实际应用中,上下文噪声的引入可能会导致方面词的重要性下降.为了增强文本的语义信息,部分研究者利用先验信息,如知识图谱、情感词典的外部知识,为模型提供监督信号[13].外部知识在情感分析中被广泛应用,以提升情感特征的表达能力[14].Ren 等[15]利用情感词典来提取句子中的情感信息进行注意力权重计算.对比传统的情感词典,SenticNet 可以更好地捕捉词汇之间的相关性[16].SenticNet 是公开的、用于意见挖掘和情感分析的工具,提供了语义、情感和极性之间的相关概念[17-19].Bian 等[18]使用多头注意力机制有效结合方面词和上下文,将外部知识库中的概念知识整合到模型中,以提升模型的性能.Liang 等[20]将SenticNet 的情感信息与依赖树相结合,增强了文本的情感极性.Microsoft Concept Graph[21]显式知识库丰富了上下文和目标的语义表示.
受上述工作启发,本研究提出基于多依赖图和知识融合的方面级情感分析模型(aspect-based sentiment analysis model based on multi-dependency graph and knowledge fusion,MDKGCN).该模型是基于知识的多依存关系融合方法,能够帮助基于依存关系的模型减轻解析错误带来的影响.由于不同的解析器尤其是具有不同归纳偏差的解析器,往往会以不同的方式出错.为了不对多个解析结果产生干扰,本研究给定来自多个解析器的依赖图,为外部情感知识单独建立情感图,并为每个图分配单独的模型参数和同一输入的模型表示,在应用表示学习器(如GCN)之后,将不同的图的高维特征组合起来.使用概念知识图谱增强方面词的本体信息,为了减少引入概念知识时产生的噪声,使用可视矩阵对经过概念知识图谱增强的句子进行掩码;对融合后的文本特征进行分类.
1 基于多依赖图和知识融合的方面级情感分析模型
如图1 所示,MDKGCN 由嵌入层、语义提取层、双通道图卷积网络层、多特征融合层、掩码层、多交互层以及输出层构成.模型中,s={w1,w2,···,wa1,wa2,···,wam,···,wn-1,wn}表示输入长度为n的句子,包括长度为m的方面词a={wa1,wa2,···,wam},即方面词a是句子s的子序列.

图1 基于多依赖图和知识融合的方面级情感分析模型的框架图Fig.1 Framework diagram of aspect-based sentiment analysis model based on multi-dependency graph and knowledge fusion
1.1 嵌入层
使用GloVe[22]或BERT[23]预训练词典,将每个单词映射到低维实值向量空间,构建由低维实数向量组成的词向量:
嵌入完成后的句子表示为V=[v1,v2,···,va1,va2,···,vam-1,vam,···,vn-1,vn].
1.2 语义提取层
BiLSTM 利用反向传播算法,通过句子的正反输入分别建立正向和反向的上下文依存关系,能够比单向LSTM[24]提取出更多的上下文信息.BERT 不再依赖传统的单向语言模型,而是采用掩码语言模型(masked language model,MLM)实现更深层次的双向语言表征.通过将初始化的向量输入BiLSTM 或BERT,提取句子中的隐藏信息,得到双向语言表征H=[h1,h2,···,hn].
1.3 双通道图卷积网络层
为了充分利用句子单词间的依存关系,分别采用句法依赖构建工具spaCy[25]和Stanza[26],为每个输入句子的构建2 个不同的依赖图.相比单个依赖图,2 个依赖图可以在依存关系方面进行互补,使依赖错误问题减少.推导出句子的2 个邻接矩阵D∈Rn×n,∈Rn×n,其中D为spaCy 构建的依赖图,为Stanza 构建的依赖图,相应矩阵元素的表达式为
1.3.1 情感知识 外部情感知识在情感分析任务中被广泛应用[19],以提升特征表示的准确性和可靠性.为了使情感信息不对某个单独的依赖图产生影响,引入SenticNet 的情感评分,使情感评分独立成图:
其中SN(wi)∈[-1,1]表示单词wi在SenticNet 中的情感评分.SN(wi)=0 表示wi为中性词或在SenticNet 中不存在.在句子的依赖树中突出方面词的情感表示,用Ti,j表示,即模型倾向于从方面词中学习相关情感信息.
为了避免模型偏向于识别积极的方面词而忽略消极的方面词,对情感矩阵元素Si,j的值+1,最终得到句子的增强邻接矩阵A的元素表达式为
1.3.2 概念知识 Microsoft Concept Graph[21]使用isA 关系,通过概念化的方法将目标词即实例与实例的相关概念联系起来,称为单实例概念化.本研究将k个概念知识插入对应的方面词后,通过嵌入层可以得到表示V=[v1,v2,···,va1,va2,···,vam,···,vc1,vc2,···,vck-1,vck,···,vn-1,vn],再由语义提取层得到句子的双向语言表征Hc=[h1,h2,···,hn].
如图2 所示,在句子树中,假设k=2,“food”为方面词,即知识图谱中的实例(instance),则可从知识图谱中获得实例“food”的概念知识:“item”与“industry”.知识有导致原句的意思发生变化的风险,即知识噪声问题.在句子树中,概念“item”只修饰了实例“food”,与概念“pedestrian amenity”没有任何关系.因此,概念“item”的特征表示不应受到概念“pedestrian amenity”的影响.本研究使用可见矩阵M来限制每个词元的可见面积,这样“item”和“pedestrian amenity”彼此都不可见.定义矩阵M的元素为
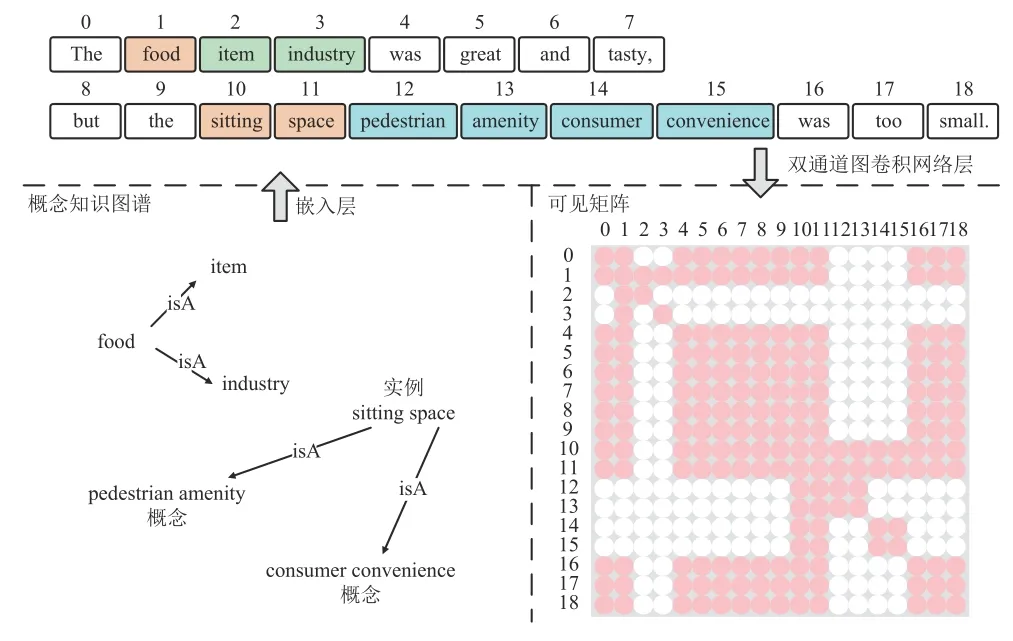
图2 引入概念知识的例句与对应的可见矩阵Fig.2 Example sentences introducing conceptual knowledge and corresponding visible matrix
其中R表示wi和wj是实例和概念的关系,S表示wi和wj都是原句中的词.
1.3.3 双通道图卷积网络层 基于方面的情感分类旨在从方面的角度判断情感,需要面向方面的特征提取策略,为此提出双通道图卷积网络层,如图3 所示.

图3 双通道图卷积网络层Fig.3 Dual-channel graph convolutional network layer
对图D、、A、M使用图卷积运算更新每个节点的表示:
式中:Dij、分别为spaCy、Stanza 句法依存分析获得的邻接矩阵D、中的元素,Aij为SenticNet情感分析的邻接矩阵A中的元素,Mij为对概念知识进行掩码操作的可见矩阵M中的元素,di=为依赖树中第i个单词节点的度,为第l层节点vi的网络输出,为前一层图卷积网络输出结果,Wl、bl分别为权重矩阵和偏置项.
式中:pi为第i个单词的位置权重;a+1、a+m分别为方面项开始和结束的位置,若有概念知识,则a+1 和a+m分别是方面项开始和概念知识结束的位置.值得注意的是,本研究没有直接将输入连续GCN 层,每层网络输出都利用式(13)计算句子中单词间的位置距离特征pi,以增强距离方面词较近的单词信息,减弱距离较远的信息.利用位置权重函数F(·)将位置距离特征融入每层图卷积网络的输出向量中,
1.3.4 多特征融合层 由图卷积层得到多个特征向量,由于在原有文本中加入了概念知识,使得的维度和其余向量不同,须进行单独处理.这里将进行特征融合,表达式为
1.4 掩码层
使用掩码矩阵N对融合后的特征进行掩码,在屏蔽非方面词的隐藏状态向量的同时保持方面词的向量ha不变;对于引入知识后的文本hlm,也进行相同的处理.经过掩码层的操作保留方面的特征信息HL:
1.5 交互注意力层
1.5.1 语义交互 经过语义提取层后可以获得文本中隐含语义特征的上下文表示H,与掩码之后的隐藏状态HLm之间进行注意力交互:
基于语义的hse由式(21)~式(23)得到.
1.5.2 语法交互 将经过多特征融合层后隐含语法特征的上下文表示与掩码之后的隐藏状态HLm之间进行注意力交互:
同时对于引入概念知识的分支采用相同的方式进行特征提取,得到语义向量以及语法向量.在经过不同的交互注意力后,得到2 组不同分支的特征向量,将各自的特征向量进行融合,得到2 个分支的结果:
1.6 输出层
将2 个分支的最终输出ha、hc输入多特征融合层,使其平衡不同分支的权重,得到文本向量的最终表示:
再经过全连接层后,由softmax 函数输出情感极性:
式中:Wf为全连接层的权重项,bf为偏置项.通过最小化交叉熵损失函数,对模型的参数进行优化和更新:
式中:λ 为L2正则化的系数,C为情感极性标签的数量,D为训练样本的数量,y为模型预测的极性类别,为方面词真实的极性类别.
2 实验及结果分析
2.1 实验数据
使用Twitter、Restaurant14、Laptop14、Restaurant15、Restaurant16 数据集[27-30]来验证模型有效性.每个数据集都由1 组训练模型和1 组测试模型组成,每个句子都是独立的样本,其中包括评论文本、方面词以及与之相关的情绪标签.训练集和测试集以及标签分布如表1 所示,其中Npos、Nneu、Nneg分别为积极、中性和消极标签的数量.
2.2 参数设置与评价指标
实验采用300 维的预训练GloVe 初始化词嵌入,单向LSTM 输出的隐藏状态维度设置为300;使用BERT 预训练模型时,隐藏状态维度为768.模型中的权重采用均匀分布进行初始化,GCN 的层数设置为2,此时模型的性能表现最好.在模型训练过程中,采用Adam 优化器作为求解算法,以实现对模型参数的高效更新与优化.模型的具体超参数如表2 所示.

表2 所提模型基于2 种词嵌入的实验参数设置Tab.2 Experimental parameter settings for proposed model based on two types of word embeddings
模型采用准确率Acc 与宏平均F1 值MF1 作为评价指标,其中MF1 为分类问题的衡量指标,由精确率与召回率的调和平均数得到.2 项指标的计算式分别为
式中:T为正确预测的样本数量,N为样本总数,P为预测为正的样本中预测正确的概率,R为正样本中预测正确的概率.
2.3 对比实验
对比MDKGCN 与多种情感分析方法探究方法的差异.参与对比的其他方法如下.1)LSTM[24]:使用单向的LSTM 编码上下文信息,用于方面级情感分析.2)IAN[31]:使用BiLSTM 编码上下文信息,利用注意力机制交互学习目标词和上下文之间的关系.3)ASGCN[8]:通过句法依赖树加权的图卷积操作,以学习相关句法信息与依存关系.4)kumaGCN[32]:将依赖图与自我注意力相结合,提出新的门控机制,以发掘潜在的语义依赖,补充受到监管的句法特性.5)SKGCN[33]:使用图卷积融合句法依赖树和常识知识,以提升句子对特定方面的表达能力.6)CDT[9]:将句子的依赖树与图神经网络结合,学习方面特征表示.7)MI-GCN[7]:通过多交互图卷积融合语法与语义特征,同时利用语义信息补充句法结构,以解决依赖解析错误的问题.8)DGAT[34]:利用BiLSTM 提取语义信息,根据句法依赖树构建句法图注意力网络表示依存关系重要程度,建立目标与情感词之间的关系.9)BERT-BASE[23]:使用双向Transformers 网络结构的预训练模型,可以生成融合左右上下文信息的深层双向语言表征.10)SSEMGAT-BERT[35]:引入成分树和方面感知的注意来分配上下文之间特定方面的注意权重,以增强的语法和语义特征.11)WGAT-BERT[36]:根据不同依赖关系的重要程度构造依赖加权邻接矩阵,在图注意力网络中进行特征提取.12)MFSGC-BERT[37]:使用SenticNet增强句法依赖树,并输入GCN 进行特征融合,以丰富情感特征.
2.4 实验结果与分析
如表3 所示,基于不同的词嵌入方法,将对比模型分为GloVe 和BERT 组.在GloVe 组中,对比基线模型(LSTM、IAN),MDKGCN 在5 个数据集上的Acc 均有较大提升,情感分类效果优秀,证明了语义交互和语法交互的有效性;对比其他GCN模型(如ASGCN模型),MDKGCN 在Restaurant15 和Restaurant16 数据集上的MF1 分别提升了4.96 与8.04 个百分点,在其他数据集上也均能提升超过2 个百分点以上.MDKGCN 使用多个依赖解析因此比于单一依赖解析的模型更加优异;此外,MDKGCN 引入外部知识增强相关情感信息,使得模型在一定程度上能够得到更加准确的情感分类.在BERT 组中,相较于原始的BERT-BASE 模型,MDKGCN-BERT 在5 个数据集上的准确率和宏F1 值平均提升了3.15 与6.60 个百分点,尤其在Restaurant15 数据集,MF1 提升了8.97 个百分点.对比引入单一解析器与单一知识的SK-GCN-BERT、MFSGC-BERT,MDKGCN均有所提升;对比图注意力模型WGAT-BERT、SSEMGAT-BERT,MDKGCN 在其中3 个数据集上互有胜负,说明Twitter 数据集对语法依赖关系不敏感,证明了多依赖解析与多知识的有效性.可以看出,MDKGCN 在5 个数据集上的表现均优于新型GCN 模型(MI-GCN、MFSGC-BERT);对比图注意力模型(DGAT),仅在Restaurant14 数据集上Acc 和MF1 较小.实验结果证明了MDKGCN的优越性.
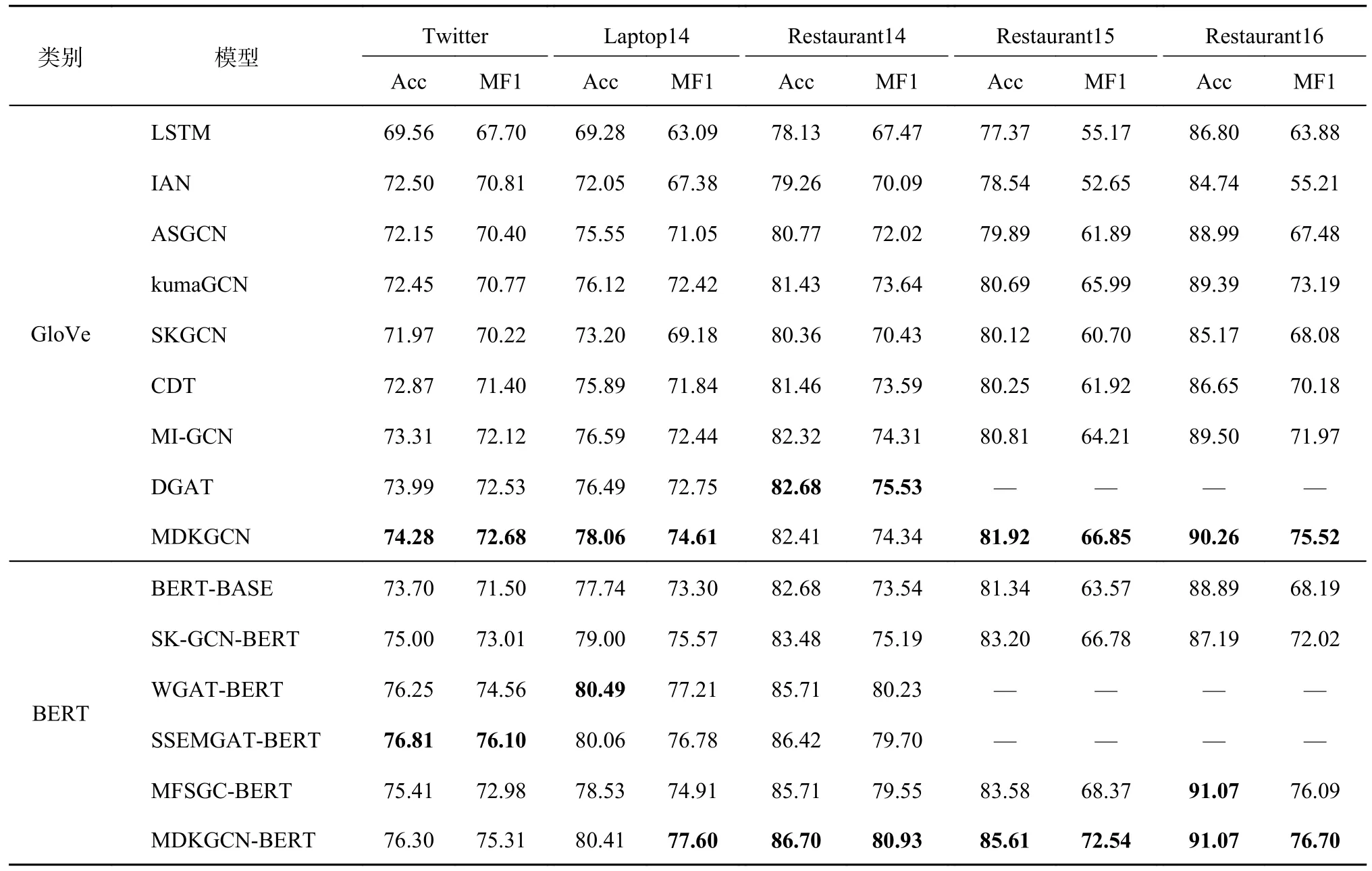
表3 不同模型在5 个数据集上的分类准确率和宏观F1 分数对比Tab.3 Comparison of classification accuracy and macro F1 score of different models in five datasets %
2.5 消融实验
为了明确MDKGCN 中各组件对模型性能的独立影响,设计MDKGCN 组件的拆解实验,并进行双知识的融合对比、概念知识的融合方式对比以及GCN 层数对模型的影响可视化分析.
如表4 所示为所提模型在5 个数据集上的消融实验结果.表中,W/O Concept 表示删除概念知识分支,W/O MS_Matrix 表示不使用可见矩阵对引入的知识进行遮蔽,W/O Stanza 表示仅删除Stanza 依赖解析,W/O spaCy 表示仅删除spaCy依赖解析器,W/O Sentic 表示仅删除SenticNet 情感知识.可以看出,在去除Stanza 依赖图后,准确率与宏F1 值平均下降1.12 和2.13 个百分点;在去除spaCy 依赖图后,准确率与宏F1 值平均下降1.56 和2.32 个百分点.证明spaCy 依赖解析器的性能虽然强于Stanza,但是无法解析出完美的依赖图.在去除其他组件或模块后,模型性能也都有一定程度的下降,表明模型中均为有效组件.

表4 所提模型在5 个数据集上的消融实验结果Tab.4 Ablation experimental results of proposed model in five datasets %
对基于BERT 的MDKGCN 进行模块消融实验,如表5 所示.表中,GCN 表示将多通道GCN层的换为普通GCN 模块,只使用基于spaCy 的依赖树.S 表示模型不引入概念知识的单分支模型,D 代表引入概念知识的双分支模型.相较于不引入概念知识的单分支BERT,引入GCN 后准确率和宏F1 值平均提升0.96 与3.07 个百分点;引入MDKGCN 后准确率和宏F1 值平均提升2.04 与5.05 个百分点.对比引入概念知识后的双分支BERT,引入GCN 后的准确率和宏F1 值平均提升0.26 与2.59 个百分点;引入MDKGCN 后的准确率和宏F1 值平均提升1.78 与4.56 个百分点.对比2 种结构的MDKGCN-BERT 模型,双分支比单分支在准确率与宏F1 值上平均提升1.10 与1.55 个百分点.结果表明了多依赖信息以及多知识的有效性.
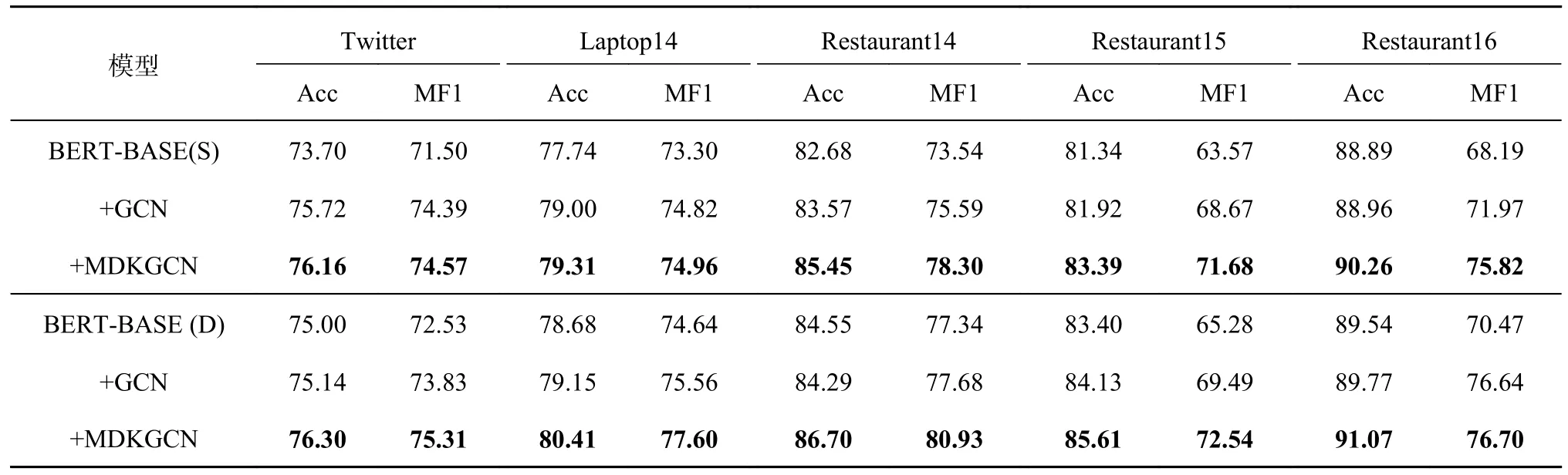
表5 所提模型使用BERT 时在5 个数据集上的消融实验结果Tab.5 Ablation experimental results for proposed model with BERT in five different datasets %
如表6 所示,跟踪GPT-3 系列大型语言模型,对Davinci[38]、Text-Davinci-001[39]、Code-Davinci-002[40]、Text-Davinci-002、Text-Davinci-003 和GPT-3.5-Turbo进行对比分析.可以发现,尽管大语言模型的优势较为明显,但两者的参数量级不在同一水平线上.BERT 拥有1.10×108的参数量,仅为情感分析能力最强的Code-Davinci-002 模型1.75×1013参数量的0.63‰,在情感分析任务中拥有其超过85%的性能,微调后的MDKGCN-BERT 更是拥有其超过88%的性能.

表6 所提模型与大型语言模型的对比实验结果Tab.6 Comparative experimental results between proposed model and large language models %
2.5.1 GCN 层数对实验结果的影响 实验将GCN 层数分别设置为L={1,2,3,···,10},在5 个公开数据集上对应的准确率和宏F1 如图4 所示.从总体效果看,MDKGCN 在GCN 层数L=2 时达到最优的性能,当GCN 网络深度增加,准确率与宏F1 值随之波动,但整体性能呈现下降趋势.当L=10 层时,相较于最佳性能,准确率平均下降了2.13 个百分点,宏F1 值平均下降了3.09 个百分点,由于网络层数增加,模型引入过多参数,产生过拟合现象.

图4 图卷积网络层数对准确率和宏F1 值的影响Fig.4 Effect of graph convolutional networks layers on accuracy and macro F1 score
2.5.2 双知识的融合对比实验 为了验证外部知识对所提模型的影响,针对MDKGCN 引入的SenticNet 情感知识、概念知识设计对比实验,结果如图5 所示.图中,S_C 表示融合概念知识,S_S 表示融合SenticNet 情感知识;S_C+S_S 表示融合双知识.可以看出,单独引入SenticNet 情感知识比单独引入概念知识有接近或更好的性能,准确率和宏F1 值平均提升0.74 与0.24 个百分点,表明对方面词进行解释比赋予情感词相关情感得分能够更好地解决一词多义问题.在引入双知识后,模型性能有明显提升.对比单情感知识,准确率和宏F1 值平均提升0.58 与1.60 个百分点;相较于单概念知识,准确率和宏F1 值平均提升1.32与1.84 个百分点.证明引入双知识可以有效提升模型性能.
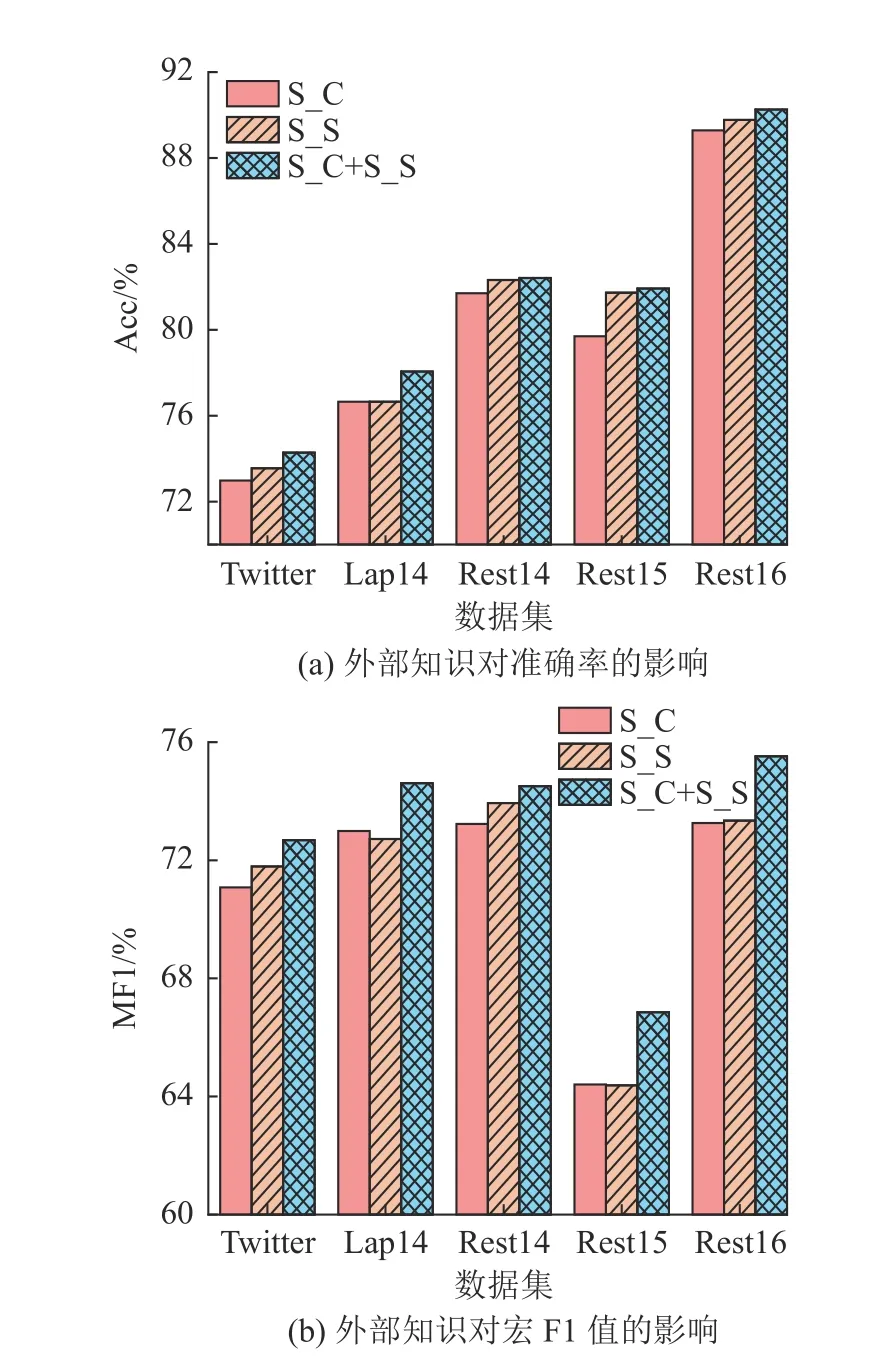
图5 外部知识对准确率和宏F1 值的影响Fig.5 Effect of external knowledge on accuracy and macro F1 score
2.5.3 概念知识的融合方式对比实验 为了验证概念知识融合方式的有效性,比较3 种经典的信息融合方式,结果如图6 所示.图中,S_Ma 表示在掩码层只对方面词进行掩码操作,之后不使用可见矩阵对其特征进行掩码;S_Mu 表示只使用可见矩阵对特征进行筛选,不使用掩码层对方面词进行掩码;Ma_Mu 表示引入概念知识的文本与概念知识可见矩阵直接做矩阵乘法;GCN 表示将引入概念知识的文本与遮蔽概念知识的可见矩阵输入GCN.可以看出,与其他融合策略相比,本研究使用的GCN 方式在准确率与宏F1 指标上均优于其他3 种融合方式.分别对比S_Ma、S_Mu、Ma_Mu,准确率平均提升0.87、0.71、1.10 个百分点;宏F1 值平均提升1.56、1.48、2.36 个百分点.该实验结果证明了GCN 在处理非结构化数据的优势.

图6 概念知识融合方式对准确率和宏F1 值的影响Fig.6 Effect of concept knowledge fusion method on accuracy and macro F1 score
2.6 样例分析
选取评论语句,对所提模型进行注意力可视化分析.颜色深浅反映该词在句子中的重要性,颜色越深表明该词越重要.在句子“The food was great and tasty,but the sitting space was too small.”中,有2 个方面词,分别为“food”和“sitting space”.如图7 所示,对于“food”,在不引入概念知识时,注意力完全在“great”上,“tasty”理应分得部分注意力,这样更符合人类的正常思维;引入概念知识后,注意力分别给了“great”和“tasty”,符合现实情况.如图8 所示,对于方面词“sitting space”,在没有概念知识时注意力更多在“was”上,按照正常逻辑,“too”这个词也应该分到不小的注意力分值,而且将“sitting space”割裂开来,使注意力分布不同;在引入概念知识后,更符合现实的注意力得分.

图7 方面词“food”注意力权重对比Fig.7 Comparison of attention weights for aspect word "food"

图8 方面词“sitting space”注意力权重对比Fig.8 Comparison of attention weights for aspect word “sitting space”
综上所述,使用MDKGCN 可以得到更符合常识的注意力得分.即使在含有多个方面词的文本中,该模型仍然能够计算出正确的注意力权重,判断方面词的情感极性.
3 结语
本研究使用2 种不同的句法解析方式对句子构建2 种句法关系依赖图,依据SenticNet 情感知识图谱构建情感关系图,使用图卷积神经网络将2 种依赖图与情感关系图相融合.引入概念知识图谱增强句子中的方面词本体,构建对应的可视矩阵,遮蔽引入的概念知识,避免由于大量知识后引入导致句子偏离其本意的情况.将这2 种融合后的特征表示进行语义、语法双交互,融合多种不同的特征表示,有效地利用所有信息实现了多特征的共享与互补.通过5 个基准数据集的验证,所提模型的准确率和宏F1 值都显著优于传统的单解析模型和当前的主流模型.也应注意到,虽然SenticNet 和概念知识图谱为模型提供了丰富的语义和情感信息,但知识图谱本身的完备性和时效性可能会影响最终结果.此外,本研究对知识图谱中实体关联关系的深度挖掘和利用不够充分,未来将引入更多类型和更全面的知识图谱,并探索更为有效的知识融合和推理机制,以提高模型对复杂文本的理解能力和泛化性能.
