基于遥感图像道路提取的全局指导多特征融合网络
2024-03-29宦海盛宇顾晨曦
宦海,盛宇,顾晨曦
(1.南京信息工程大学 人工智能学院,江苏 南京 210044;2.南京邮电大学 集成电路科学与工程学院,江苏 南京 210003)
遥感图像道路分割可以应用于地图生成、汽车自动驾驶与导航等多个场景[1].相较于一般的分割任务,遥感图像道路分割有其独特性和困难性:1)在遥感图像中,目标道路占据的画幅比例普遍偏小;2)如河流、铁路的分类对象与道路过于相似,人眼难以判别;3)道路分岔连通情况较复杂,对道路提取的识别精度有较高要求[2].
运用分割算法提取道路由计算机视觉(computer vision,CV)的图像分割技术发展而来.图像分割方法大致可以分为传统算法和深度学习算法.传统算法主要有Gabor 滤波器[3]、Sobel 算子[4]、分水岭算法[5]等,还有较先进的机器学习方法,如支持向量机[6](support vector machine,SVM)和随机森林[7](random forests,RF).这些方法通过提取遥感图像中的特征,如纹理、边缘、形状等,进行图像分割从而实现目标提取.在遥感图像中,道路表现为具有连通性的狭窄线条,有些线条覆盖整幅图像且多条道路可能存在交叉连通,待提取的特征复杂且丰富,干扰也较多,因此传统的图像分割方法很难用于道路提取.深度学习技术在计算机视觉研究领域发展迅速,该方法自动获取图像的非线性和层次特征,可以更好地解决其他道路提取方法存在的问题.语义分割是深度学习在图像分割领域中的主要研究方向,它能较全面地利用卷积神经网络(convolutional neural networks,CNNs)[8]从输入图像中提取图像的浅层和深层特征,实现端到端的像素级图像分割,具有较高的分割精度和效率.
学者针对高分辨率的道路图像提取提出的深度学习研究方法不少,但类间相似度高、噪声干扰多、狭窄道路难提取等难点仍有待克服[9].Long等[10]提出不包含全连接层的全卷积网络(fully convolutional networks,FCN).FCN 将CNN 最后的全连接层替换为卷积层,称为反卷积,利用反卷积对最后一个卷积层的特征图进行上采样,使最后一个卷积层恢复到输入图像相同的尺寸,在预测每个像素的同时保留空间信息.FCN 可以适应任意尺寸输入图像,并且通过不同层之间的跳跃连接同时确保了网络的鲁棒性和精确性,但是FCN 不能充分提取上下文信息,语义分割精度较差.基于FCN 改进的U-Net[11]采用编解码的网络结构,它可以充分利用像素的位置信息,在训练集样本较少时仍可保持一定的分割精度.残差神经网络(deep residual networks,ResNet)[12]避免了因增加网络深度造成的模型过拟合、梯度消失和梯度爆炸问题,被广泛应用于特征提取网络中.Zhao 等[13]提出的金字塔场景解析网络(pyramid scene parsing network,PSPNet)使用金字塔池化模块,Chen 等[14]提出的DeepLabV3+网络使用空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP)获取并引入解码模块恢复便捷信息,这2 个网络均提取多尺度的语义信息进行融合,提高了分割精度,但它们只关注宏观的空间位置信息,对细节方面的信息关注不足.
注意力机制使神经网络具备专注于输入图像的某些重点部分的能力.Hu 等[15]提出挤压激励网络(squeeze-and-excitation networks,SE-Net),将通道注意力机制加入主干网,提升了特征提取的效率.Woo 等[16]提出卷积块注意模块(convolutional block attention module,CBAM),此模块将全局最大池化加入SE 模块,同时引入空间注意力机制,有效地提取了特征图内的位置相关信息.Fu 等[17]提出的双重注意网络(dual attention network,DANet)使用2 种类型的注意力模块,分别模拟空间维度和通道维度中的语义相互依赖性,通过对局部特征的上下文依赖关系进行建模,显著改善了分割结果.Zhang 等[18]提出上下文先验网络移动语义分割的令牌金字塔转换器,设计金字塔形式的视觉转换器,平衡了分割精度与速度,减少了数据量,完成了困难样本的较快速分割.
在分割道路时使用现有的语义分割网络的效果欠佳,为此本研究提出全局指导多特征融合网络(global guide multi-feature fusion network,GGMNet),并应用于遥感图像的道路提取.GGMNet 包含自适应全局通道注意力模块(adaptive globe channel attention module,AGCA)和多特征融合模块(multifeature fusion module,MFM).
1 数据集
采用3 个数据集进行训练与测试,分别为CITY-OSM 数据集[19]、DeepGlobe 道路提取遥感地图数据集[20]和CHN6-CUG 数据集[21].CITYOSM 数据集使用柏林和巴黎的谷歌地图高分辨率RGB 正射影像,共有825 幅图像,每幅图像为2 611×2 453 像素.按照4∶1 的比例随机抽取,其中660 幅图像作为训练集,剩余165 幅图像作为测试集.CITY-OSM 数据集有背景、建筑物和道路3 个类别.DeepGlobe 道路提取遥感地图数据集共有6 226 幅遥感图像,每幅图像为1 500 × 1 500 像素,按照4∶1 的比例随机抽取,其中4 981 幅图像作为训练集,剩余1 245 幅图像作为测试集.该数据集的图像拍摄于泰国、印度、印度尼西亚等地,图像场景包括城市、乡村、荒郊、海滨、热带雨林等,数据集有道路和背景2 个类别.CHN6-CUG 数据集是中国代表性城市大尺度卫星影像数据集,遥感影像底图来自谷歌地球.在该数据集中,根据道路覆盖的程度,标记道路由覆盖道路和未覆盖道路组成;根据地理因素的物理角度,标示道路包括铁路、公路、城市道路和农村道路等.CHN6-CUG数据集共有4 511 幅遥感图像,每幅图像为512×512 像素,按照4∶1 的比例随机抽取,其中3 608 幅图像作为训练集,剩余903 幅图像作为测试集.
2 全局指导多特征融合网络
2.1 网络的整体结构
GGMNet 的整体结构如图1 所示.网络的主干部分采用ResNet-50-C[22]来提取输入图像的特征.网络保留阶段Res-1~Res-4 的4 个结果,并对Res-2~Res-4 的结果进行上采样,获得3 个与Res-1 结果的尺度相同的结果,分别为F1、F2、F3、F4.将Res-4 的结果输入ASPP,以提取深层特征图中的全局信息和多尺度信息.再将ASPP 的输出作为AGCA 的输入,利用AGCA 提取特征图的类别信息.对AGCA 的结果进行上采样并与之前的4 个结果进行融合,得到多层特征(multi-layer features,MF).分别将F1、F2、F3、F4与 M F 作为MFM 的输入,得到4 个结果,分别为.融合这4 个结果并进行上采样,得到最终的分割结果.
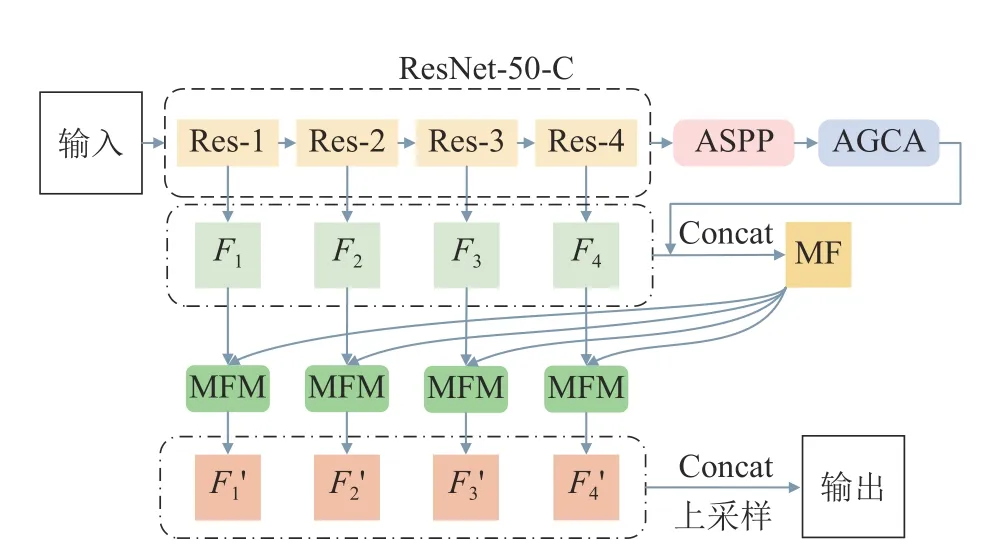
图1 全局指导多特征融合网络的整体结构Fig.1 Overall structure of global guide multi-feature fusion network
2.2 自适应全局通道注意力模块
影响道路分割精度的主要原因在于网络将与道路类似的类别错误识别为道路,降低了道路的交并比(intersection over union,IoU).道路周边的像素对道路影响很大,充分提取道路及其周边的局部信息可以提高分割精度从而降低误分割率.本研究设计全局通道注意力模块,模块针对每个像素的上下文信息,从全局入手,指导局部信息的权重,在保证类别准确的同时,提高每条道路目标的位置准确率.
AGCA 的整体结构如图2 所示.在上分支,对输入特征图X进行全局平均池化,得到全局信息的特征向量Xc,第m个数据Xcm的计算式为

图2 自适应全局通道注意力模块的整体结构Fig.2 Overall structure of adaptive globe channel attention module
式中:Fa为平均池化,Xm为第m列的所有H×W个数据.将此向量进行维度扩展,恢复成H×W×C的尺寸,再与输入特征图X相加.将此结果经过1×1卷积进行通道维度的改变,并经过Sigmoid 激活变为H×W×s2的尺寸,得到X1.再将X1转化成HW×s2的二维矩阵Ac.在下分支中,将输入特征X进行自适应平均池化,得到尺寸为s×s×C的Xs特征图,再将此特征图转化为s2×C的矩阵As.将2 个矩阵相乘得到尺寸为HW×C的矩阵A,再将A转换成尺寸为H×W×C的Xa,利用残差思想,将X与Xa相加,得到自适应全局通道注意力模块的输出Z,此过程表示为上分支的全局平均池化提取特征图X的全局信息,特别是通道中的类别信息;下分支通过自适应平均池化使图像划分为s×s个区域,每个区域包含此区域的位置信息.上分支中的全局信息将HW个s2维的向量作为权重,指导下分支的局部信息,再通过训练可以提升网络对于道路的提取能力,最终预测语义标签.当道路的信息在图像的不同位置时,它周边的地物如建筑物、河流、轨道对其影响不同,导致全局的特征对其影响的权重不一致,为此将图像分为s2个部分进行分割,并且包含全局信息的HW个权重向量分别对这s2个区域进行指导,s为可变参数,在消融实验中进行讨论,以找到最适合道路提取的取值.
2.3 多特征融合模块
深层特征和浅层特征具有不同权重的信息,浅层特征的位置信息更加丰富,深层特征的类别信息更加丰富,往往利用注意力融合模块融合深层和浅层特征.GGMNet 采用MFM 融合4 个层的特征图.将4 层的特征图以及被AGCA 处理过的第4 次特征图进行Concat 操作得到多层特征 MF,此操作的目的是收集并进一步提取多层特征图的信息,使这些信息的利用率达到最高,从而提高网络的分割精度.再将4 层的特征图通过MFM分别与 MF 进行融合,这个融合过程使4 层特征图中的局部信息与全局的信息进一步合并,在训练过程中全局信息可以给每张特征图中的信息进行指导.最后将4 个与 MF 融合后的特征图进行Concat 操作,结果包含丰富的位置信息与类别信息,使网络的分割结果中位置更加准确,误分割率降低.
如图3 所示为MFM 的整体结构.将 MF 和第i层的结果Fi进行Concat 操作,经过卷积层和批量标准化(batch normalization,BN)层,然后经过ReLU 层进行激活.再经过Softmax 层得到特征图Y,以更好地进行像素分类.将Y与 M F 相乘后与Fi进行Concat 操作,再经过 1×1 卷积降维,得到多特征融合模块的输出.
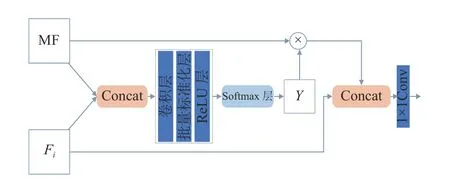
图3 多特征融合模块的整体结构Fig.3 Overall structure of multi-feature fusion module
3 结果与分析
3.1 实验环境及参数设置
实验在Centos7.8 系统的Pytorch 框架下完成,实验平台硬件为Intel I9-9900KF CPU、64-GB 内存和2 张具有11 GB 显存的NVIDIA 2080Ti 显卡,使用Mmsegmentation 语义分割开源工具箱.训练过程使用随机梯度下降优化算法作为优化器,学习衰减策略为Poly 学习率衰减策略,初始学习率为0.01,最低学习率为0.000 4,损失函数为交叉熵,最大迭代次数为120 000.
3.2 试验评价指标
平均交并比(MIoU)是语义分割领域中衡量图像分割精度的重要通用指标,是对每一类交并比求和平均的结果.IoU 为预测结果和实际结果的交集和并集之比,即分类准确的正类像素数和分类准确的正类像素数与被错分类为负类的正类像素数以及被错分类为正类的负类像素数之和的比值.评价指标的计算式分别为
式中:TP 为预测正确的正样本,FP 为预测错误的负样本,FN 为预测错误的负样本,n为类别数.
3.3 结果与分析
3.3.1 超参数的取值对比 超参数s的大小影响局部特征的尺寸,也影响全局特征对局部特征的指导效果.在基准网络的ASPP 模块之后添加取不同数值s的自适应全局通道注意力模块,以测试不同取值s的模块性能.考虑到随机误差的影响,所有消融实验都进行5 次重复实验,文中表格所列数据为平均值.
基于CITY-OSM 数据集设置s的实验结果如表1 所示.可以看出,添加AGCA 后,网络的结果均有提升.在添加s=1 的模块时,道路的IoU 提升了0.76 个百分点,网络的MIoU 提升了1.31 个百分点;在添加s=4 的模块时,网络的提升达到最大,道路的IoU 提升了0.86 个百分点,网络的MIoU 提升了1.95 个百分点.s=2 和s=5 时的提升较小,道路的IoU 分别提升了0.58 个百分点和0.21 个百分点,网络的MIoU 分别提升了1.38 个百分点和1.49 个百分点.实验结果表明,AGCA 可以帮助网络进行更精细的道路提取,对道路周边的类别识别效果有所改善,减少了误分割率;可以观察到,背景类别与建筑物类别在添加模块之后的精度也有所上升,这些提升说明道路周边的类别被识别为道路的概率也有所下降,使道路提取的准确率得到提高.实验的视觉结果对比如图4 所示.可以看出,基准网络对于道路的识别不到位,边缘模糊,且比标签图中的道路细,说明基准网络在受到道路的周围有相似地物影响时,分割性能较差.在添加AGCA 后,道路的分割情况得到明显改善,道路的粗细更加接近标签图,且在s=4 时,道路分割最为准确,误分割率最低,与标签图最接近.这与表1 的数据结果一致.

表1 基于CITY-OSM 数据集的自适应全局通道注意力模块超参数取值对比Tab.1 Comparison of hyperparameter values for adaptive globe channel attention module based on CITY-OSM dataset %

图4 基于CITY-OSM 数据集的超参数取值可视化结果对比Fig.4 Comparison of hyperparameter-value visualization results based on CITY-OSM dataset
基于DeepGlobe 数据集设置s的结果如表2所示.可以看出,所有添加AGCA 的网络均优于基准网络.其中s=4 时,道路的IoU=62.80%,比基准网络高0.56 个百分点,网络的MIoU=80.45%,比基准网络高0.30 个百分点,结果最好.实验结果表明,当s=4 时,网络具有最好的性能,全局信息对局部信息的指导最充分,分割精度最高.实验的视觉结果对比如图5 所示.由方框标识的区域可以看出,大部分添加自适应全局通道注意力模块的网络在进行道路分割时,误分割情况得到改善.s=4 的方框区域与标签图最接近,几乎没有误分割的道路,也未将背景类别识别为道路,说明当s=4 时,自适应全局通道注意力模块的效果最好,证明了模块的有效性.这与表2 的数据结果一致.
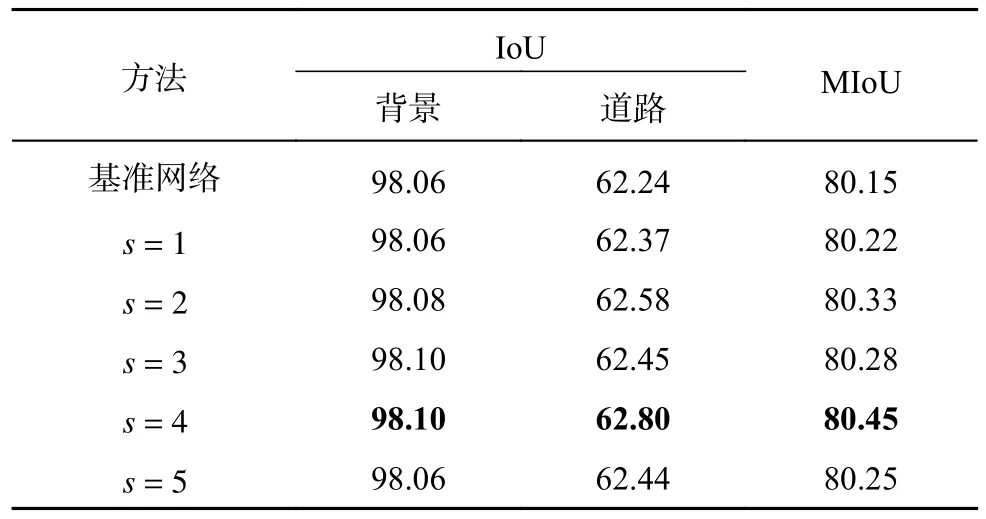
表2 基于DeepGlobe 数据集的自适应全局通道注意力模块超参数取值对比Tab.2 Comparison of hyperparameter values for adaptive globe channel attention module based on DeepGlobe dataset %
基于CHN6-CUG 数据集设置s的结果如表3所示.可以看出,所有添加AGCA 的网络结果均优于基准网络.其中s=4 时,道路的IoU=61.94%,比基准网络高1.81 个百分点;网络的MIoU=79.62%,比基准网络高0.99 个百分点,结果最好.实验结果表明,当s=4 时,网络对道路的提取能力最好,精确度最高.实验的视觉结果对比如图6 所示.可以看出,基准网络分割出的道路边缘不清晰,形状也与标签图相差较大,在添加AGCA 之后,道路的边缘与粗细都与标签图较接近,在s=2、3、5时,都有将背景类别识别为道路的情况,在s=1、4 时误分割率较小.实验结果表明,自适应全局通道注意力模块的有效性,并且在s=4时性能最好,这与表3 的结果一致.
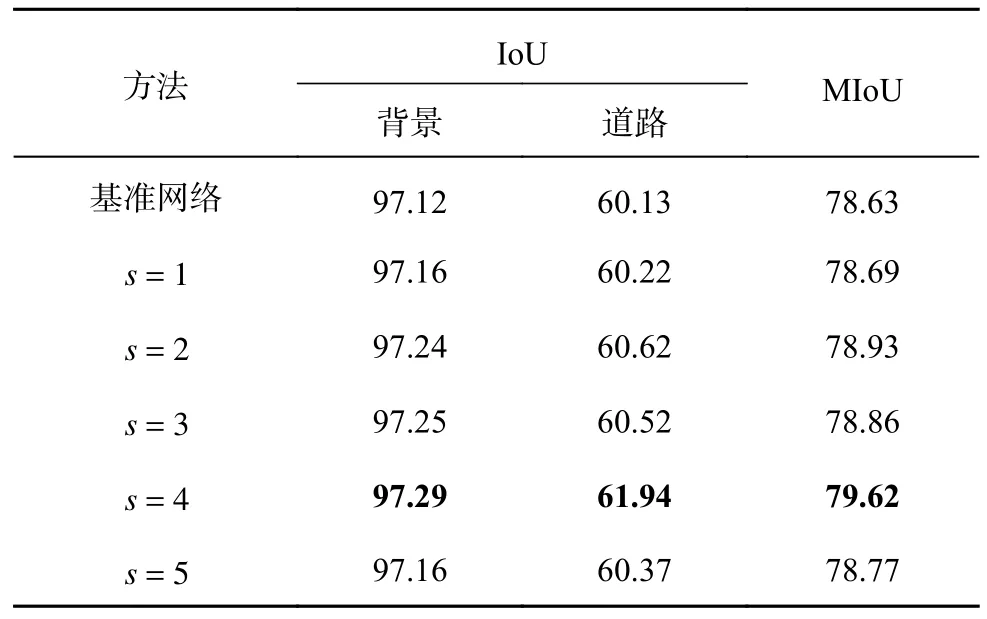
表3 基于CHN6-CUG 数据集的自适应全局通道注意力模块超参数取值对比Tab.3 Comparison of hyperparameter values for adaptive globe channel attention module based on CHN6-CUG dataset %

图6 基于CHN6-CUG 数据集的超参数值可视化结果对比Fig.6 Comparison of hyper parameter-value visualization results based on CHN6-CUG dataset
由3 个数据集的实验结果可以看出,当设置s=4 时,AGCA 拥有最好的性能.此时AGCA 可以帮助网络利用图像的全局信息指导局部信息,并且分析道路周边的像素类别以减少误分割率,提高分割准确率.
3.3.2 模块有效性分析 以ResNet50-C 加上ASPP 模块的网络作为基准网络进行模块有效性分析.在基准网络以后添加AGCA 和解码器中的MFM 后,测试模块的有效性.设置3 个消融实验来测试模块有效性.实验1 在基准网络的基础上添加AGCA.实验2 在实验1 的基础上添加MFM,但只融合Res-1 和Res-4 的特征图(浅层特征和深层特征).实验3 在实验1 的基础上,将4 个阶段的特征图全部进行融合,形成最终的全局指导多特征融合网络.实验中统一设置s=4,如表4 所示为基于CITY-OSM 数据集对基准网络分别添加不同模块时的分割精度.可以看出,在添加AGCA和MFM 之后,网络的精度变高,道路提取效果变好.实验1 中,相比于基准网络,道路的IoU 提高了0.86 个百分点,网络的MIoU 提高了1.95 个百分点,证明了AGCA 的有效性,也证明该模块可以帮助网络识别与道路类间相似度高的其余类别,提高网络精度.实验2 中,道路的IoU 相较于实验1 提高了0.02 个百分点,网络的MIoU 提高了0.29 个百分点,提升较少,但证明了深层特征与浅层特征融合可以提高网络精度,增加准确率.实验3 中,道路的IoU 相较于实验1 提高了0.52个百分点,网络的MIoU 提高了0.93 个百分点,证明了将ResNet-50-C 的4 个阶段进行特征融合的有效性,也证明了多特征融合模块的有效性.将4 个阶段特征融合可以充分利用每个阶段中包含的位置信息和类别信息,减小误分割率,优化网络性能.实验的可视化结果对比结果如图7 所示.可以看出,随着模块的增加,道路的分割效果逐步变好,基准网络的误分割率很高,网络常将背景类别与建筑物类别识别为道路,使分割效果变差,在模块添加后误分割的情况明显改善,道路的完整度与粗细也与标签图更加接近.这与表4 的数值结果一致.

表4 基于CITY-OSM 数据集的模块有效性分析Tab.4 Module validity analysis based on CITY-OSM dataset %
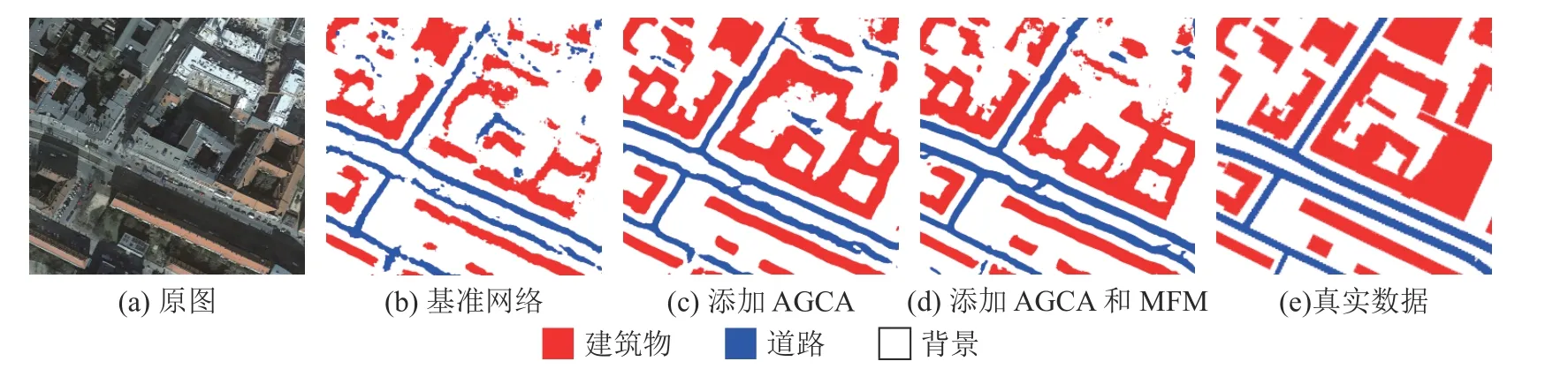
图7 基于CITY-OSM 数据集的模块有效性分析可视化结果对比Fig.7 Comparison of visualization results for module validity analysis based on CITY-OSM dataset
如表5 所示为基于DeepGlobe 数据集对基准网络分别添加不同模块时的分割精度.实验1 中,在添加AGCA 后,相比于基准网络,道路的IoU提高了0.56 个百分点,网络的MIoU 提高了0.30 个百分点,证明了AGCA 的有效性.实验2中,道路的IoU 相较于实验1 提高了0.12 个百分点,网络的MIoU 提高了0.06 个百分点,证明了融合深层特征与浅层特征可以帮助网络提高精度.实验3 中,道路的IoU 相较于实验1 提高了0.31 个百分点,网络的MIoU 提高了0.18 个百分点,此结果说明多特征融合可以充分利用特征图中的位置信息和类别信息,提升网络的分割性能.实验的可视化结果对比结果如图8 所示,在添加AGCA 后,道路更加鲜明,边缘更加清晰,道路误分割率降低;在添加MFM 后,分割结果更接近标签图,误分割比重进一步减少,这与表5 的数值结果一致.

表5 基于DeepGlobe 数据集的模块有效性分析Tab.5 Module validity analysis based on DeepGlobe dataset %
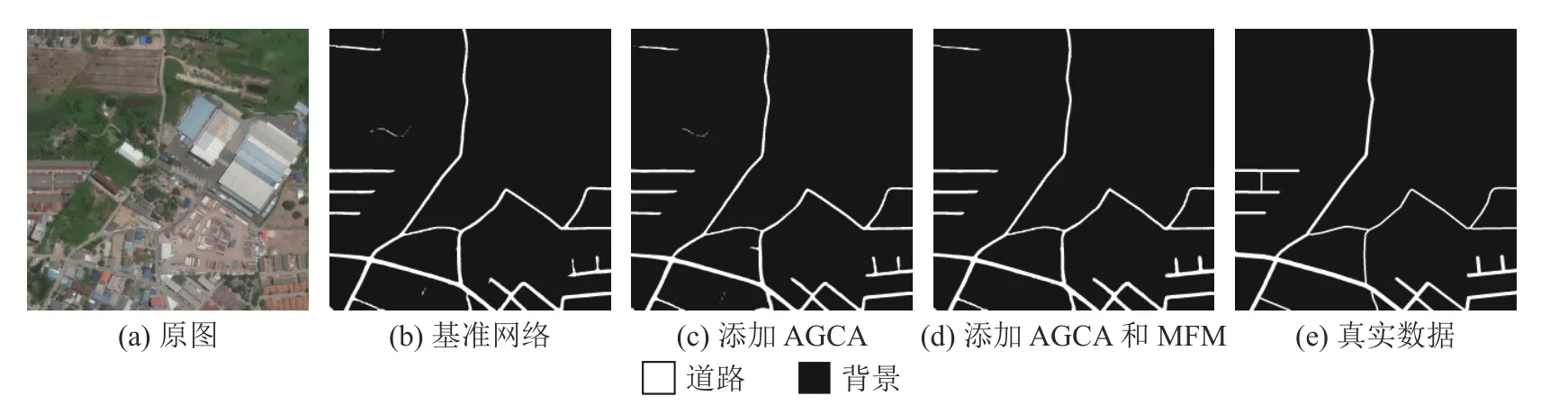
图8 基于DeepGlobe 数据集模块的有效性分析可视化结果对比Fig.8 Comparison of visualization results for module validity analysis based on DeepGlobe dataset
如表6 所示为基于CHN6-CUG 数据集对基准网络分别添加不同模块时的分割精度.实验1 中,在添加AGCA 后,相比于基准网络,道路的IoU提升了1.81 个百分点,网络的MIoU 提高了0.99个百分点,证明了此模块的有效性.实验2 中,道路的IoU 相较于实验1 提高了0.22 个百分点,网络的MIoU 提高了0.10 个百分点,证明了深层特征与浅层特征的有效性,也证明了MFM 的有效性.实验3 中,道路的IoU 相比于实验1 提高了1.27 个百分点,网络的MIoU 相比于实验1 提高了0.67 个百分点,证明了融合4 个阶段的特征可以帮助网络收集更丰富的位置信息与类别信息,提升分割的精确度.实验的可视化结果对比结果如图9 所示.可以看出,基准网络的道路比标签图粗,误分割道路较高,在添加AGCA 后,道路形状更接近标签图,道路边缘更清晰;在添加MFM后,误分割情况更少,这与表6 的数值结果一致.
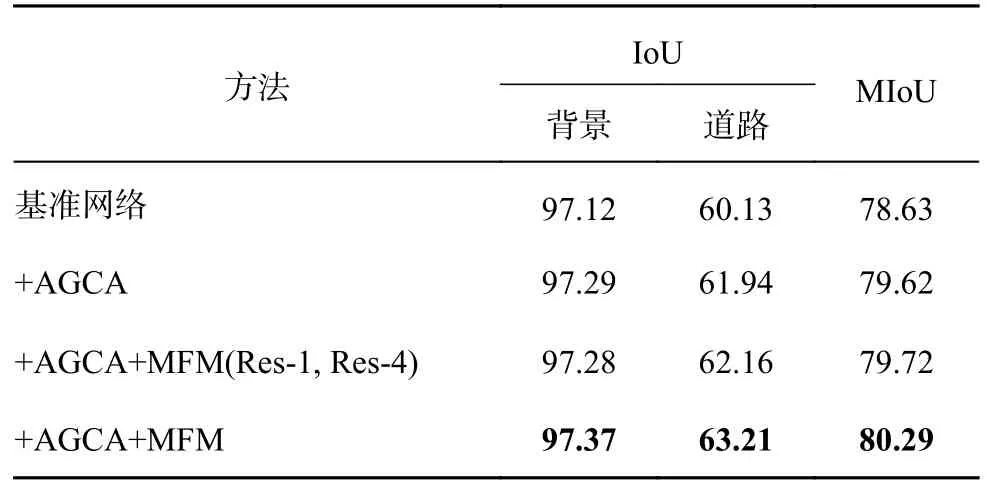
表6 基于CHN6-CUG 数据集的模块有效性分析Tab.6 Module validity analysis based on CHN6-CUG dataset %

图9 基于CHN6-CUG 数据集模块的有效性分析可视化结果对比Fig.9 Comparison of visualization results for module validity analysis based on CHN6-CUG dataset
由以上3 个数据集的实验结果可以看出,AGCA可以利用全局信息指导局部信息,减少误分割率;MFM 可以融合4 个阶段的特征以利用特征图中的位置信息和类别信息提升网络的分割准确率.
3.3.3 网络对比与分析 对比不同网络在道路提取中的性能,使用DeepLabV3[23]、APCNet[24]、CCNet[25]、DANet、EMANet[26]、DNLNet[27]、CRANet[28]、SANet[29]与所提网络进行对比.APCNet 融合多尺度、自适应和全局指导局部亲和力3 个要素设计网络,道路分割性能较好;DANet 通过建模通道注意力和空间注意力来提取特征;EMANet 设计期望最大化注意力机制(EMA),摒弃在全图上计算注意力图的流程,转而通过期望最大化(EM)算法迭代出一组紧凑的基,在这组基上运行注意力机制,大大降低了复杂度;DNLNet 设计解耦non-local 模块,增加通道间的位置信息的交互,增加了道路分割的精确度和效率;CRANet 通过使用级联的残差注意力模块来提取遥感图像中边界细化的道路,该结构利用多尺度特征上的空间注意残块来捕获长距离关系,并引入通道注意里模块来优化多尺度特征融合,并且设计轻量级编码器-解码器网络,以自适应优化提取的道路边界.
基于CITY-OSM 数据集的网络分割性能对比结果如表7 所示.GGMNet 的道路IoU=77.68%,MIoU=72.33%,优于其他的语义分割网络,与SANet 的分割效果接近.GGMNet 的另外2 个类别的IoU 也高于其他网络.GGMNet 的道路IoU 比DNLNet 的高0.56 个百分比,比EMANet 高0.65 个百分比,证明了网络在道路提取方面的有效性.实验结果表明,网络整体分割效果好,从图像中提取的信息丰富,可以更好地进行特征融合.实验的可视化对比结果如图10 所示.可以看出,GGMNet的道路分割情况优于其他网络,比SANet 的分割情况略好.在参与对比的网络中,GGMNet 的道路最为清晰,连通状况最好,其余网络的误分割情况较为严重,将零散的背景类中颜色较深的阴影错误识别为道路,GGMNet 的误分割情况最少,分割结果最好,这与表7 的数据结果一致.

表7 基于CITY-OSM 数据集不同网络的分割性能对比Tab.7 Segmentation performance comparison of different networks based on CITY-OSM dataset %

图10 不同网络基于CITY-OSM 数据集的分割结果对比Fig.10 Segmentation results comparison of different networks based on CITY-OSM dataset
基于DeepGlobe 数据集的网络分割性能对比结果如表8 所示.可以看出,GGMNet 的MIoU=80.63%,是最优结果,道路的IoU=63.11%,也是最优结果;SANet 的道路MIoU 次优,道路的IoU 也为次优.这些结果证明了GGMNet 的有效性,GGMNet在道路提取方面比其他网络精度更高,通过全局信息指导局部信息,并融合位置信息与类别信息使分割结果更准确.实验的可视化对比结果如图11 所示.在标签图中,方框区域没有道路,观察原图可以发现,此区域为农田与农田边界,农田边界与道路的相似度极高,极易被误分割为道路.在其他网络的分割结果中,农田边界都被判定为道路,而GGMNet 未出现误分割情况.GGMNet中的AGCA 通过全局信息对局部信息的指导,识别出农田边界为背景类别而非道路类别,提高了分割精确性.这与表8 的数据结果一致.

表8 基于DeepGlobe 数据集不同网络的分割性能对比Tab.8 Segmentation performance comparison of different networks based on DeepGlobe dataset %

图11 不同网络基于DeepGlobe 数据集的分割结果对比Fig.11 Segmentation results comparison of different networks based on DeepGlobe dataset
基于CHN6-CUG 数据集的网络分割性能对比结果如表9 所示.可以看出,GGMNet 的表现最好,拥有最优的分割结果.GGMNet 的道路IoU=63.21%,MIoU=80.29%,比次优的SANet 稍好,优于其他分割网络的结果.说明针对道路提取,GGMNet 可以充分利用特征图的信息以获得更精确的分割结果.实验的可视化对比结果如图12 所示.可以看出,SANet,DNLNet,GGMNet 的分割效果较好,其余道路都有较严重的道路断连情况和形状问题.GGMNet 中的道路连通性最好、最完整,也与标签图中的道路形状最接近,证明了GGMNet 在道路提取方面的有效性与优越性.这与表9 的数据结果一致.
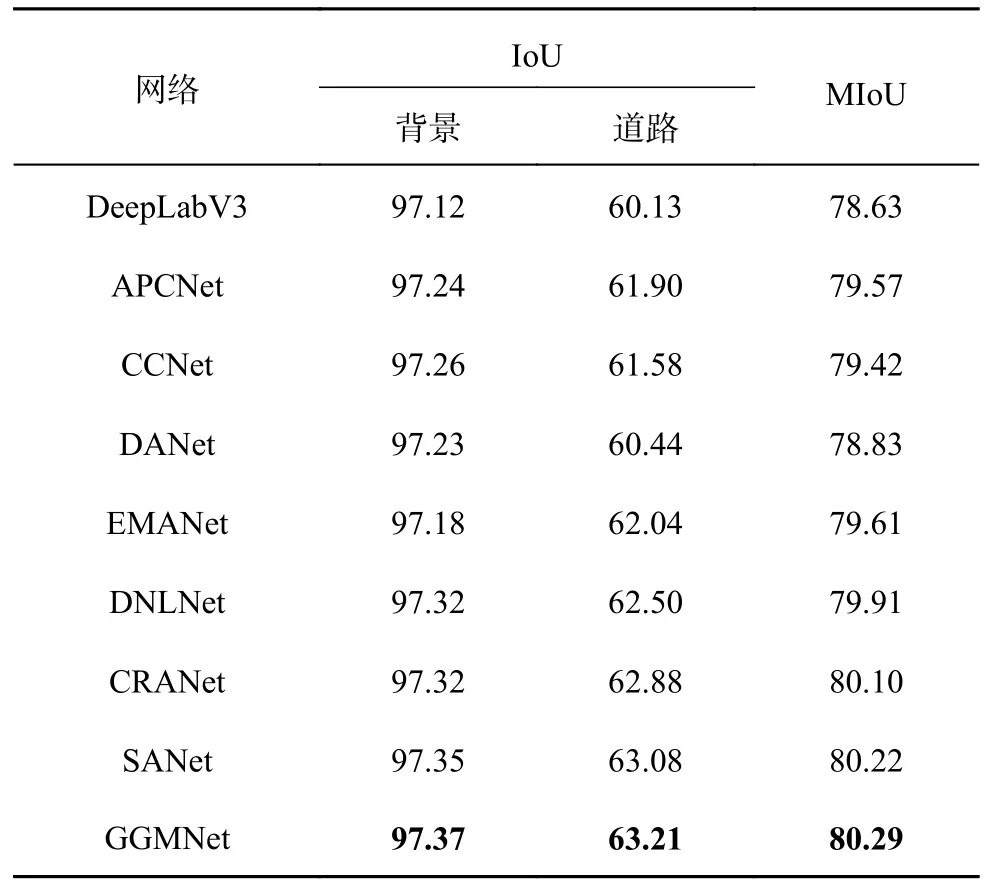
表9 基于CHN6-CUG 数据集不同网络的分割性能对比Tab.9 Segmentation performance comparison of different networks based on CHN6-CUG dataset %

图12 不同网络基于CHN6-CUG 数据集的分割结果对比Fig.12 Segmentation results comparison of different networks based on CHN6-CUG dataset
通过以上3 个数据集的实验结果可以看出,在参与对比的网络中,GGMNet 可以在其他网络误分割率较高的情况下,维持较低的误分割率,并且保证道路的连通性,道路尺度也更接近标签图,可以完成分辨率较高的遥感图像道路提取任务.
4 结语
本研究就遥感图像道路提取任务提出全局指导多特征融合网络GGMNet,有效解决了道路提取误分割率高的问题.详细介绍了GGMNet 的网络结构和设计思路,以及各个模块的主要作用.设计了自适应全局通道注意力模块(AGCA),利用全局上下文信息指导局部特征对各类别地物的特征提取;设计了多特征融合模块(MFM)来融合多阶段特征图的特征.将多阶段特征图与被AGCA处理后的Res-4 阶段的特征图用MFM 进行融合,使每阶段的位置信息与类别信息得到充分利用,提高分割精度.在CITY-OSM 数据集、DeepGlobe道路提取数据集和CHN6-CUG 道路数据集上的实验结果表明,GGMNet 的分割性能优秀,可以将图片中道路较为完整地提取出来,误分割率低,在参与对比的网络中分割性能最好.本研究在训练语义分割网络时,对输入图像进行了简单的预处理(如旋转、翻折),在处理道路相关的数据时,这些操作有可能使特征没有被充分利用.在未来的工作中,将尝试利用如形态学、图像直方图的图像处理算法进行训练图像的预处理,提升特征提取网络对特征的利用效率,以提高分割精度.
