铁路通信数据HBase 分布式查询系统设计
2024-03-11马雁波
马雁波
(中国铁路济南局集团有限公司,山东济南 250000)
近年来,人们生活水平不断提升,出门旅行日益频繁,随着城市化进程的加快,公共交通工具成为人们生活中密不可分的角色,各大城市铁路交通枢纽的建设愈发重要。铁路通信系统是铁路整体运作系统之间的通信桥梁,其对于整个城市交通体系的发展具有重要作用。铁路通信系统中的查询系统可以满足用户的乘坐需求,根据列车的出行时间利用通信广播等功能为用户提供查询服务,因此铁路通信数据查询系统的设计是至关重要的。
针对铁路通信数据查询这一问题,相关领域学者进行了较为深入的研究。文献[1]针对电力物联网提出一种分布式云数据中心优化选址方法,选取云数据中心作为计算架构,同时筛选核心节点,实现数据查询,但是云数据查询对联网要求较高,使用过程存在一定的局限性。文献[2]利用物联网研究一种分布式通信数据高效压缩方法,确定物联网分布式结构,通过数据转化得到高频系数,根据数据变换结果进行数据查询,但是在查询过程中需要进行多次递归处理,计算量大,计算过程相对复杂。
HBase 本质为一种非关系型分布式数据库,采用Java 编程语言,可在HDFS 查询系统中运行。为了弥补传统方法中存在的问题,该文基于HBase 设计了一种新的铁路通信数据分布式查询系统。
1 系统总体设计
该文设计并搭建一个具有三节点的HBase 分布式系统,通过运行铁路通信数据储存模块、数据查询模块,对铁路通信数据进行分析,使铁路通信数据分布式查询系统达到高效运行的目的[3-4]。
系统硬件部分配置三台服务器,其中一台主机作为HBase 的储存节点,另外两台主机作为HBase的交换节点,根据需求灵活配置三台主机,组成分布式系统[5-6]。分布式部署模式如图1 所示。

图1 分布式部署模式
系统的软件设计主要分为数据储存模块和数据查询模块,不同模块负责的功能如下:
利用数据存储模块得到不同数据源的数据,引入存储模块的同步功能在HBase 集群数据库中记载信息。
2 分布式系统平台
2.1 系统平台组件
分析HBase 生态系统组件的兼容性与集成性,根据分析结果选取该文系统平台组件,以此搭建系统平台。通过Linux 组件构建操作模块,利用Java 语言选取JDK 组件,同时引入Had 组件使系统拥有集群服务,利用组件建立语言服务[7-8]。
2.2 HBase集群
通过HBase 生态模块建立集群。集群采用完全分布式,系统内部文件使用HDFS 目录统计,指定HBase 系统的默认路径,配置目标文献的使用权限,对HDFS 文件进行格式化后,完成HBase 集群的创建[9-10]。
3 数据系统架构
3.1 数据存储模块
数据存储模块结构如图2 所示。

图2 数据存储模块结构
前端输入:主要负责处理用户发起的通信查询信息,由于用户发送的信息种类很多,因此利用不同的设备采集信息,传递到下一单元[11-12]。
数据预处理:数据预处理模块主要负责将采集到的信息数据进行识别分类,分析其内容、时间、类型等信息,提取主要特征并标记关键词存入数据库中,以实现根据关键词对信息进行快速抓取的个性化检索服务。预处理模块对于数据通信十分重要,将数据按预设规则分类;其次进行残值处理,分析数据是否正常,如果得到的通信数据为异常数据,则需要检测数据为缺失数据还是重复数据。如果确定数据为缺失数据,则需要寻找缺失的通信信息,如果缺失十分严重,则需要废弃,并反馈给全系统;若为重复数据,直接删除。利用预处理将信息传输到缓冲区,其过程由式(1)表示:
其中,K表示预处理后数据值;r表示默认值;m表示缺失数据;n表示重复数据,i表示数据量;M表示脏值处理系数。
数据缓冲区:接收所有的缓存数据,建立数据缓冲队列,对队列中数据进行实时监控,并将数据分流与缓存,完成数据归类[13-14]。
数据写入单元:设定阈值,将缓存对立的通信数据与设置的阈值进行比较,如果数值已经达到阈值,则需据启动写入单元,进行相应的写入操作,并生成写入指令。
数据库集群:通过提供支持来确保得到的铁路通信数据能够被长期存储,且所有数据都能存储在HBase 集群中。当收到外部请求时,数据库会启动相应的查询功能,实时查询信息。
3.2 铁路通信数据查询模块
基于HBase 设计了新的铁路通信数据查询模块,其结构如图3 所示。
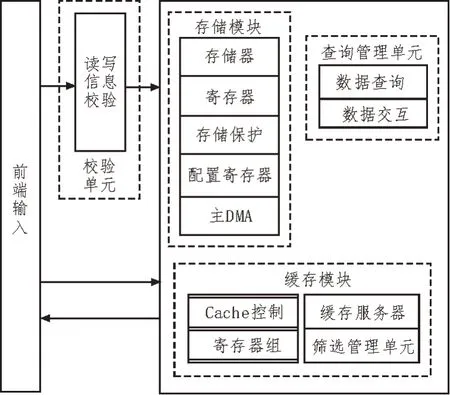
图3 数据查询模块结构
前端输入:在前端输入数据查询关键词,设置查询语言,统一化处理SQL查询语言,并利用Hbase检测相应的查询指令,将查询结果传输给检验单元。
校验单元:利用校验单元判定指标的规范程度,如果达不到规定的输入或者读写方式,则需要取消相应的信息,取消过程如式(2)所示:
其中,R表示语句标准参考值。
铁路信息查询单元:铁路信息查询单元主要负责信息的交互,能够分解信息得到更加准确的指令,从而进行指令处理。
缓存服务器:分析访问频率,根据得到的访问结果进行筛选,将访问频率较高的信息缓存。
存储服务器:利用分布式分析方法对数据进行存储,并保留所有铁路通信信息的存储数据,方便日后铁路通信数据分析[15]。
4 查询关键技术
4.1 HBase存储模型
建立HBase 存储模型,提升检索效率,解决冗余带来的性能问题,提升数据的存储性能。HBase 存储模型通过HBase 存储算法定义主键的检索范围以及主键值的单条记录查询数量,HBase 存储函数如式(3)所示:
其中,f表示HBase 存储算法;d表示主键检索范围;hi表示单条记录查询数量。
根据HBase 数据检索策略,将数据拆分到不同的缓冲队列中,通过并行查询提高铁路通信数据信息的处理策略,利用存储模型进行信息保存,数据存储模型如式(4)所示:
其中,q表示存储模型;a表示缓冲队列数量。
4.2 分布查询策略
数据在管理过程中,负载可能存在问题,通过分布式分析进行负载控制,确保查询过程分布查询系统的运行效率。
分析通信数据的运行逻辑,建立逻辑片段,如式(5)所示:
对于每个逻辑片段SN,均满足:
①完整性:得到的单个逻辑都具有映射性,如式(6)所示:
②可重构性:存在逻辑片段Sa可以被看作全局关系P进行再次分布,如式(7)所示:
③不可相交性:通信数据逻辑记录t与铁路通信数据逻辑片段Sa为映射关系,具有伪异性[16]。
5 实验研究
为了验证该文设计的基于HBase 的铁路通信数据分布式查询系统的实际应用效果,设计实验,同时选用传统的电力物联网分布式查询系统和数据压缩查询系统进行实验对比。
实验选取的数据来源于两个MySQL 数据库,设定集群在写入过程中产生的单条记录查询数量逐步增加,设置为200 条、400 条、600 条……2 000 条,设定缓冲队列数量为200 个,建立缓冲区域,得到的阈值为8 MB,随着数据发送响应延迟时间的逐渐增加,数据写入性能响应延迟时间和缓冲性能写入延迟时间,也在不断增加。根据上述实验环境,进行数据调度,将二进制字符数据通过计算映射成固定长度的值,基于线性哈希算法的存储调度过程如式(8)所示:
其中,b表示哈希值;A表示线性哈希算法函数;N表示全部等待队列的个数。
同时使用传统系统和该文系统分析不同环节的数据响应时间,设定最大通信数据量为600 GB,得到的数据写入性能响应延迟时间实验结果如图4所示。
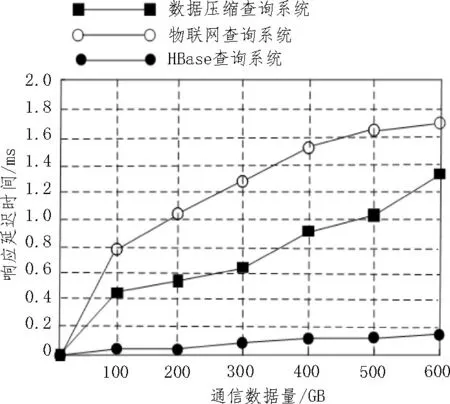
图4 数据写入性能响应延迟时间
数据写入性能对于整体通信效果有极强的影响,根据图4 可知,随着通信数据量的增加,系统的响应延迟时间也在不断增加,铁路通信效果越来越差,但是该文提出的分布式查询系统的延迟时间最短,当达到最大通信数据量600 GB 时,系统的响应延迟时间仍然低于0.2 ms,具有实时通信能力,能够满足用户的通信要求,而传统的数据压缩查询系统在通信数据量达到600 GB 时,响应延迟时间已经达到1.38 ms,物联网查询系统响应延迟时间达到1.7 ms,响应时间过长,通信质量严重下降,无法满足用户的整体通信要求。
缓冲性能写入延迟时间如图5 所示。
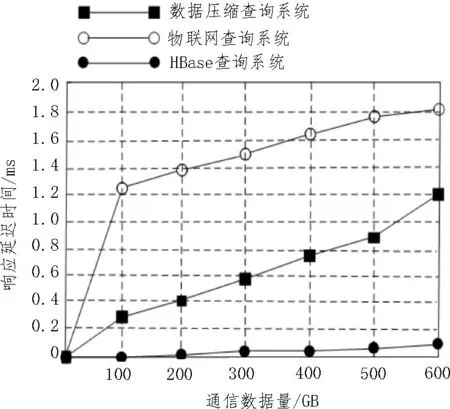
图5 缓冲性能响应延迟时间
根据图5 可知,在缓冲性能方面,该文提出的基于HBase 的铁路通信数据分布式查询系统的延迟时间与传统系统有极大的差异,随着通信数据量的增加,传统系统显现出极大的局限性,物联网查询系统响应时间达到1.8 s,压缩查询系统响应时间达到1.2 s,无法达到正常通过要求,而该文提出的查询系统响应时间为0.1 s,在响应方面上具有极大的操作空间,确保通信结果的实时性。
综上所述,在数据写入性能和缓冲写入性能方面,传统的分布式查询系统的查询能力相对较差,响应时间过长,该文提出的系统能够在短时间内实现响应,具有极强的实时性。
6 结束语
该文基于HBase 设计了铁路通信数据分布式查询系统,硬件部分通过组合系统组件以及建立HBase集群构建分布式系统平台,软件部分由数据查询模块以及数据储存模块组成的数据系统架构和三种查询技术组成。经实验表明,该文设计的分布式查询系统查询速度快,查询准确率高,适用于如今的铁路通信中。但该文在设计系统时未考虑系统在长时间高速运行时的可持续时间,后续将围绕此方面进行研究。
