中文阅读中词语加工与眼动控制整合模型简介 *
2024-01-31陈汝淇包亚倩黄林洁琼李兴珊
陈汝淇 包亚倩 黄林洁琼 李兴珊
(1 中国科学院行为科学重点实验室(中国科学院心理研究所),北京 100101) (2 中国科学院大学心理学系,北京 100049)
1 引言
无论英文还是中文,词都是非常重要的语言单位。基本上所有的基于英文的眼动控制模型,都假定了词间空格在英语阅读中的重要作用,即先依据空格完成词的切分,再进行加工(Reichle et al.,1998)。然而,中文阅读中没有词间空格,因此这些经典的拼音文字阅读模型无法推广到中文阅读中。具体来说,无词间空格使中文眼动控制模型必须回答两个问题:第一,词间无空格,中文读者如何识别词语?第二,没有词间空格来帮助引导眼睛移动的位置,读者如何选择眼跳目标(即扫视后眼睛落在哪个位置)?这些与词切分有关的认知加工机制是近年中文阅读领域的焦点。
词切分问题对构建中文阅读模型来说是一大挑战。在阅读中,在每个注视点能感知的内容非常有限。读者注视一个位置时可以有效加工的信息量叫知觉广度(McConkie & Rayner,1976)。中文阅读中知觉广度的范围是当前注视点的汉字(字n),加上注视点左侧一个汉字(字n-1)和右侧三个汉字(字n+1、n+2 和n+3)(Inhoff & Liu,1998)。因此,中文读者必须逐渐移动眼睛,才能够阅读整个句子或者整个篇章。此外,知觉广度中包含的词语个数是不确定的,可能是两个词、三个词,也可能只包括一个词的一部分。对于这种复杂的情况,模型能帮助读者更好地理解阅读加工过程。
最近,Li 和Pollatsek(2020)提出了中文阅读中词语加工与眼动控制的整合模型(Chinese Reading Model,CRM)。该模型充分考虑中文书写系统的特点,基于以往大量实验研究,采用计算建模技术,建构了模拟中文阅读认知加工过程以及眼动控制机制的计算模型。该模型着重解释了中文读者在阅读过程中如何解决词切分和眼跳目标的选择等重要问题。为了方便读者更好地理解该模型,本文对该模型进行详细介绍,并通过举例更进一步地分析该模型的特点。
本文首先介绍了词切分、眼跳目标选择的以往文献,随后是模型的重要假设、结构以及实现,最后介绍了模型对一些重要的中文阅读眼动研究的模拟结果。在讨论中总结了该模型为了解决词切分问题提出的重要假设。
2 中文阅读研究发现
2.1 中文阅读词切分的研究
即使没有明显的词边界信息,中文读者在阅读中文时也没有表现出任何困难。一些研究表明,流利的中文读者通常在一分钟内阅读400 个汉字(或260 个词),英文读者和中文读者阅读相同内容的文本时所花费的时间是相似的(Liversedge et al.,2016; Sun et al.,1985)。这表明中文读者在阅读过程中有一套非常高效的词切分机制。
已有许多研究揭示了中文词切分的认知机制(Inhoff & Wu,2005; Li et al.,2009; Yen et al.,2012)。本文主要介绍其中的一个研究。Ma 等人(2014)研究了中文读者在句子阅读过程中如何切分重叠歧义字符串(overlapping ambiguous strings,OAS)。OAS 是一种词边界歧义的三字字符串(用ABC 分别表示从左至右的三个字),中间汉字可以分别与左侧和右侧汉字组成一个词(即AB 和BC),比如“学生活”中“学生”和“生活”都是词。在阅读过程中,读者需要决定中间位置的汉字到底属于哪个词。这可能导致两种切分类型:AB-C 或ABC。Ma 等人正交地操纵了句子语境和词频:根据OAS 之后的句子语境,OAS 应被切分为ABC 或A-BC;在OAS 内,第一个词AB 的词频高于或低于第二个词BC,分别产生高-低或低-高的词频条件。因此,基于词频的切分与后文语境可能一致或不一致,Ma 等人发现,在一致条件下,读者对OAS 区域的回视比不一致条件的更少。这表明,最初读者将高词频的词切分出来,随后再利用语境进行整合。
根据他们的实验结果,Ma 等人(2014)认为读者使用两阶段策略来加工此类句子。第一阶段(词语竞争阶段):知觉广度范围内所有汉字可能组成的词语都会被激活,所有激活的词语竞争唯一的胜出者。当某个词胜出后,词语被识别的同时,位置在中间的汉字会被切分到胜出词。他们认为词频等因素作用于这个阶段。第二阶段(信息整合阶段):读者会利用语境等信息检查最初的词切分是否正确,如果最初的词切分与后文句子语境不匹配,读者需要回视到歧义区重新切分。CRM 模型主要能模拟词切分的第一阶段,并且采纳了这个阶段中存在词语竞争的假设。
2.2 阅读中的眼跳落点选择
许多研究表明,拼音文字阅读中读者在一个词上的首次注视位置通常会落在词中心偏左的位置,称为偏好注视位置(preferred viewing location,PVL; Rayner,1979)。这在英文阅读中是可行的,因为英文读者可以用副中央凹视觉获取词边界位置,从而将眼睛移动至PVL。但是在没有词间空格的情况下,中文读者如何选择眼跳落点位置?一些研究表明,中文阅读的PVL 曲线呈扁平状,PVL 曲线表示首次注视落在各汉字上的频率(Tsai &McConkie,2003);后来的研究发现PVL 曲线峰值出现在词首位置(Li et al.,2011; Yan et al.,2010),没有研究表明中文阅读中PVL 曲线峰值会出现在词中央,这表明中文读者不像英文读者更偏好将眼跳落到词中央。
为了解释中文阅读中眼跳目标的选择,Li 等人(2011)提出了基于加工的策略(processing-based strategy)。根据这一策略,读者首先试着在给定注视点上加工尽可能多的信息,然后将眼睛移动到未加工的字的位置。一些研究检验了这个策略的重要推论。例如,Wei 等人(2013)发现,离开高频词的眼跳长度要比离开低频词时更长。基于加工的策略推测,一个注视点上能加工的右侧字个数越多,眼跳长度就会越长,读者对高频词的加工效率往往较高。Wei 等人的实验验证了这一策略,当中央凹为高频词时,相对于中央凹为低频词,读者将有更多的认知资源用于加工右侧的信息,因此眼跳长度更长。
此外,根据基于加工的策略,既然眼跳长度取决于右侧文本被加工的程度,那么当读者不能加工右侧的字时,中央凹的词频对眼跳长度的影响将消失。Liu 等人(2015)的研究验证了这一点。他们让中文读者阅读嵌入了高频或低频目标词的句子。其中,在有效预视条件下,读者自然阅读句子;而在无效预视条件下,注视点右侧的每个汉字都被掩蔽符号“※”替代,直到眼睛跨过隐形边界后才显示正常汉字,因此在无效预视条件下读者看不到目标词右侧的汉字。研究结果表明,当限制副中央凹的加工时,词频对眼跳长度的影响减小。
总之,这两项研究结果表明,在注视点右侧加工的汉字越多(从注视点的字开始计算),眼跳长度就会越长,因此简单的词会被快速加工并有更长的眼跳长度。但如果副中央凹视觉加工被阻碍,高频词和低频词之间的眼跳长度不会有显著差异。
3 CRM:假设、结构和实现
3.1 模型的假设
CRM 模型的一个重要假设为词语加工和眼动控制两个系统互相影响。因此该模型有两个模块:词语加工模块和眼动控制模块。两个模块功能相对独立,但通过实时通信互相影响。将词语加工和眼动控制整合在一个模型中,可以帮助理解词语加工和眼动控制之间复杂的交互作用。
CRM 的另一个重要假设是采纳了交互激活模型(Interactive Activation Model,IAM; McClelland &Rumelhart,1981)模拟词语加工过程。IAM 在认知心理学研究中极具影响力,已被广泛用于解释视觉文字加工(McClelland & Rumelhart,1981)、出声阅读(Coltheart et al.,2001)、眼动控制(Reilly &Radach,2006; Snell et al.,2018) 和语音知觉(McClelland & Elman,1986)等认知活动。针对中文阅读的特性,CRM 模型提出了一些新的假设,以确保IAM 可以解释中文句子阅读中的词语加工过程。
首先,中文词之间没有空格,无法通过低级视觉信息获取词边界信息,因此模型需要进行词切分。模型的输入是汉字序列,其中包含的词语个数和词语长度在识别之前是未知的。为了解决这些问题,CRM 模型假设词语加工和词切分是一个统一的过程。模型平行加工知觉广度范围内的所有汉字,并激活由这些汉字组成的所有可能的词。相互重叠的词会互相竞争。一旦一个词在竞争中胜出,它就被识别出来,并确定其首尾位置,从而将其从汉字串中切分出来。
其次,中文有超过5000 个常用汉字,且这些汉字相对于英文字符来说结构更复杂。IAM 模型中,英文的字母由每个位置上的特征探测器识别,而在CRM 模型中,对汉字的识别通过与汉字模版进行匹配来实现,即将输入的汉字图像与汉字模版进行相似性比较,并将汉字图像识别为与它最匹配的模版。
第三部分的假设与眼动控制有关。之前的研究表明眼睛何时移动和向何处移动的决定往往是独立进行的(Rayner & McConkie,1976; Rayner &Pollatsek,1981),CRM 模型也做出相同的假设。模型假设两种眼动控制机制共同决定了眼睛何时移动。首先,当前注视词的加工情况影响了眼睛移动的时间。对注视词已经加工的程度越深,启动眼动所需的时间就越短。其次,眼动机制中还存在自主控制成分,即使在一个注视点上没有加工任何信息,一段时间后眼睛也会移动。
至于向何处移动眼睛,该模型采用基于加工的策略(Li et al.,2011; Wei et al.,2013)来模拟眼跳目标的选择。根据这个策略,中文读者会先估算在一个注视点上能够加工多少汉字,然后把眼睛移动到这些汉字之后。
3.2 模型的结构
模型主要包括两个模块:词语加工模块和眼动控制模块(见图1)。词语加工模块识别和切分知觉广度范围内的词,眼动控制模块决定眼睛移动的时间和位置。两个模块实时互动,而非独立运作。词语加工模块向眼动控制模块提供词语加工和汉字加工情况的实时信息,使它可以决定眼睛的移动时间和位置。眼动控制模块向词语加工模块提供眼动信号,词语加工模块一旦收到眼动指令,知觉广度范围便移动到由眼动控制模块指定的新位置上。
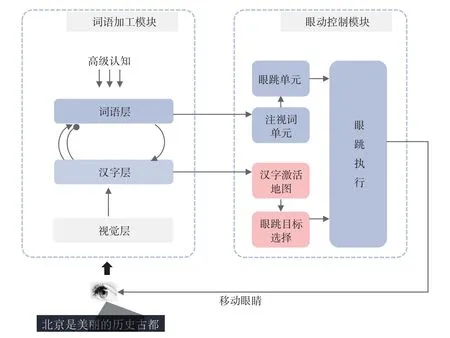
图1 模型结构示意图(Li & Pollatsek,2020)
3.2.1 词语加工模块
词语加工模块采纳了交互激活模型的结构。该模块包含三个加工层级,分别为视觉层、汉字层、词语层。每个层级设置有许多单元(unit)。不同层级的单元代表不同意义,如,词语层的每个单元代表一个词,汉字层的每个单元代表一个汉字。每个单元都有激活值,对应于该单元出现在特定位置的可能性。不同层级单元之间、各个层级内部都设有链接(link)。链接分为前馈、反馈链接,同时又分为兴奋性或抑制性链接。兴奋性链接是指一个单元的激活会增加另一个单元的激活值;抑制性链接是指一个单元的激活会降低另一个单元的激活值。在三个层级中,编码方式具有位置特异性:在词语加工模块中有很多插槽(slot),每个插槽对应文本中一个汉字的位置。在每个插槽中都有一个视觉单元、一组汉字单元和一组词语单元。插槽中的视觉单元和汉字单元只接收来自同一位置的输入。
模型假定词语加工模块在每个注视点上的视觉输入为五个汉字,即注视点附近的知觉广度范围内。尽管每个注视点的视觉输入包含五个汉字,但词语加工模块中正在加工的字数是动态变化的。随着眼睛移动,新的眼跳落点位置所对应的知觉广度范围内的汉字会进入词语加工模块。当一个词语被识别了,它的所有汉字就会从词语加工模块中被移除。同时,如果在之前的注视点上对n-1 到n+3 范围内的一些汉字已经进行了加工,那么在新注视点上将不再对其进行加工。因此,很多注视点上词语加工是从位置n开始的,而不是n-1 位置,因为这个位置上的词已经在上一个注视点上完成了加工。
(1)网络更新
模型中各单元的激活是不断更新的,不同层级内的单元以相似的方式更新,与原始交互激活模型所使用的方式相似。在一个给定的时间点,一个单元收集与之相连的其他单元的所有输入,然后计算所有输入的加权总和,以低级到高级的顺序更新激活值。
在计算单元的更新时,模型用公式1 计算单元的输入。其中ni(t)是网络在给定时间t的输入,wij是和另一个单元j(单元激活为aj(t)) 的链接权重,当链接为兴奋性链接时wij为正值,当链接为抑制性链接时wij为负值。不同的链接的权重是不同的,将在后文介绍。free1 用于为词语单元和眼跳单元添加额外的输入(后文介绍),而对于其他单元(如汉字层的单元),free1 的值被设置为0。
公式2 将一个单元的输入(公式1 计算得到的值)“压缩”为一个值,以使单元激活值落在0 到1 的范围内。
在公式2 中,ai(t)表示一个单元在时间t的激活值。利用公式3 更新单元在时间t+Δt时的激活ai(t+Δt),表示使用公式2 进行压缩后的单元净激活输入。
使用公式4 将单元的激活保持在0 到1 之间。
(2)汉字层
每个插槽中有一组完整的汉字单元。每个汉字单元只从相同插槽的视觉单元获取前馈输入。从视觉单元到汉字单元(插槽i的第j个单元)的输入见公式5。
在公式5 中,similarityij代表输入图像与该汉字单元代表的汉字模版之间的相似性,是一个自由参数,调节视觉单元到相同位置的汉字单元j之间的链接权重(全部自由参数见表1)。相似度等于输入图像和模版之间具有相同灰度的像素个数与图像中所有像素个数的比值。模型的词典中一共有5692 个汉字,然而,为了简洁,模型设置只有相似分数高于一定水平(0.5)的汉字才会被激活。
此外,模型还考虑了视觉离心率对词语加工的影响。离注视点越近感知的效率会越高,离注视点越远感知的效率相应降低。实现方法如下:从视觉层到汉字单元的输入受到视觉离心率的影响。模型使用了一个以注视点为中心的高斯函数,模拟了视敏度的影响如何随距离变化;eccentricityi代表眼睛注视第fix个汉字时第i个插槽处视敏度的影响,由公式6 确定。

图2 注视词为低频词和高频词时eccentricity 与汉字位置的关系
在给定的插槽上,同一个插槽中的汉字单元之间是抑制性链接,其权重为inh_character_character(模型中权重信息如何被纳入计算详见公式1)。这使得同一个位置上的汉字单元之间相互竞争,最后只有一个汉字单元可以赢得竞争。不同插槽位置上的汉字单元之间不存在链接。
(3)词语层
由于中文阅读中没有词间空格,因此在词语识别之前,既不知道词长信息也不知道词边界信息。为了解决这一问题,该模型假设每个插槽上有一组词语单元,每个词的第一个汉字都在这个插槽上。因此,词语单元也是位置特异性的。一个词语单元可以占用多个插槽(假如它代表一个多字词),且占用插槽数与其字数相等。词语加工模块中,很多词语单元在空间上重叠(即,如果两个词语单元占据同一个插槽,那么它们在空间上重叠)。空间上重叠的词语互相竞争唯一胜出者。当词语单元的激活超过阈限值词就被识别出来了,也就同时被成功切分出来。
下面采用一个例子说明词切分的具体过程(见图3)。如果词语单元和汉字单元在空间上重叠(不管是否在同一个插槽),那么词语单元将接收汉字单元的前馈链接。这些词可以从不同的位置开始,长度也可以不同。比如说,如果“大”字出现在插槽n,它就会激活所有的在插槽n上有“大”字的词语单元(“博大”、“大兵”和“大学”等)。
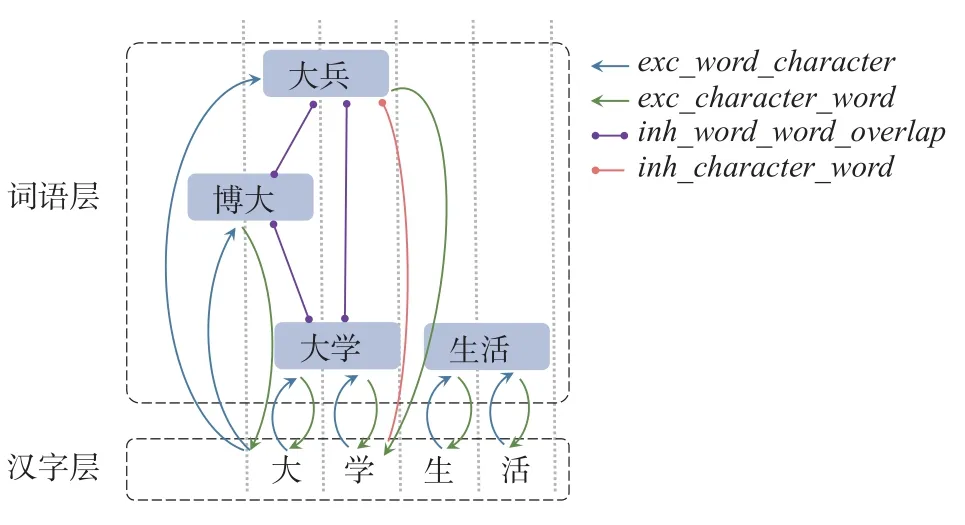
图3 词语加工模块交互激活示例
模型中的链接使得字与词的加工相交互。从字到词层级可以是抑制性或兴奋性链接。假如一个词包含这个字且位置正确,那么汉字到词语单元为兴奋性链接(权重为,即汉字单元的激活增加词语单元的激活值,且汉字激活越高,它对词语单元的输入越大。否则,前馈链接为抑制性(权重为即汉字的激活降低词语单元的激活值,且它的激活值越高,对词语单元的抑制就越大。除了前馈链接,还有从词语到汉字单元的反馈链接。如果一个词语在适当的位置包含该汉字,那么从词语到汉字单元为兴奋性链接(权重是character),例如,“博大”对“大”有兴奋性的反馈链接,促进它的加工。这个从词语层到汉字层的链接可以用来解释以往研究发现的词优效应,即当一个字出现在词语中时,被试识别该字比 它单 独 出 现 时更 快(申 薇,李 兴 珊,2012)。
在词语层中,空间上重叠的两个词单元之间就会有抑制性链接(权重为如,由于位置重叠“大学”和“大兵”之间有着抑制性的链接,而“大学”和“生活”没有位置重叠,就不会竞争而是被平行地识别加工。这些链接使空间重叠的词语相互竞争,最后只有一个词胜出。比如,由于“大兵”和“博大”只受到了汉字层“大”的支持,而“大学”受到“大”“学”两个字的支持,因此这两个词在早期被激活,而到后期就会被“大学”所抑制。最后只有“大学”取得胜利,由于已知词的开始位置以及词长,这个词同时完成了词切分。所以词切分和词激活是一个统一的、不可分的过程。
(4)词频的影响
CRM 模型通过设置词语单元激活公式的常数项来模拟词频效应。对于词语单元,模型将公式1中的free1 变量设置为公式8 所示的频率缩放变量(frequency scaling variable,CFSi)。公 式8 中,frequencyi表示词语单元i的词频,4.0251 是当前模型使用的词里最大对数频率,frequency_gain是调节词频对词语加工影响程度的自由参数。CFSi越大则一个单元激活的速度越快。通过这个设置保证了高频词语加工的时间更快。
(5)预测性影响
模型通过增加相应词语单元的激活来实现词语预测性效应。词语单元的激活增加了公式9 所描述的值,其中predictabilityi是词语i在语境约束下的预测性,是一个自由参数。为简单起见,模型假设,只有收到汉字层输入的词语才被激活。因此,只有语境预测但没有汉字层支持的词语不被激活。此外,因为读者一般会用他们读过的所有词来预测下一个词,模型假设,只有在插槽n的激活值(激活程度最高的词语单元的值)超过阈限时(模拟中为0.3),预测性才影响词n+1 的激活。通过这一公式,模型实现了高预测性的词激活程度也越高,从而可以被更快地识别。
3.2.2 眼动控制模块
眼动控制模块主要控制眼睛移动的时间和位置。包含眼跳单元、注视词单元、汉字激活地图、眼跳目标选择以及眼跳执行单元。
(1)眼睛移动时间控制
在眼动控制模块中,注视词单元(fixated-word unit)和眼跳单元(saccade unit)决定了何时眼动。在当前的模型中,注视词的激活强度是眼睛何时移动的决定性因素。模型采用注视词单元表示当前注视词的加工进度。这个单元的激活强度等于当前插槽上激活值最高的词语单元的激活强度。模型假设眼跳单元控制了眼睛何时移动。眼跳单元接受注视词单元的激活型链接(权重为在注视的时候,眼跳单元的激活持续累积,达到阈限值就会触发眼跳。而在眼睛移动时,眼跳单元的激活恢复为0。
眼跳单元的激活公式中除了来自注视词单元的输入,还包括一个大于零的常量(free1 变量设置为自由参数因此,即使注视词单元的激活为零,眼跳单元的激活仍然会增加。在公式1 中加入这个参数,就为眼动控制模块引入了一个自动控制成分,即使没有感知到任何信息,眼睛也会在一段时间后移动。
需要注意的是,虽然注视词单元的激活会影响眼睛何时移动,但眼睛实际移动的时间并不一定与注视词语的识别时间完全相同。眼跳单元的激活决定了眼睛何时移动(达到阈限值时立即触发眼动),而注视词单元的激活只能通过影响眼跳单元的激活来间接影响眼睛的移动时间。因此,眼睛的移动并不能完全与词语的识别时间保持一致,眼睛可能在注视词被识别之前或之后移动,这取决于眼跳单元的激活情况。
(2)眼跳目标的选择
在眼动控制模块中,汉字激活地图(character activation map)和眼跳目标单元(saccade target unit)决定了向何处眼动。关于眼跳位置的选择,模型采用了基于加工的假设。前文提到过,根据这个策略,读者估计他们在一个注视点上能够加工的汉字数量,然后选择这些汉字之后的字作为眼跳目标。这是通过汉字激活地图实现的。在地图中,句子中所有汉字的位置都有一个对应的单元。这些单元的激活初始值为0,当一个汉字被识别时,激活值为1。当词语加工模块中的汉字被加工,它们的激活值会实时同步更新到汉字激活地图中,地图中的汉字激活单元(character-activation unit)的激活值等于对应插槽位置上激活程度最高的汉字单元。为了实现这个基于加工的假设,在一个眼跳被触发后,眼动控制模块会从左到右依次搜索汉字激活地图,找到第一个激活小于某一阈值的汉字单元,这个汉字则被选择为眼跳的落点。
3.3 模型实现和参数搜索
3.3.1 模型实现
CRM 是一个计算模型,所有关于词语加工和眼动控制的假设通过计算机程序来实现。模型的输入由一系列组成句子的汉字图像构成。该模型模拟了每一个注视点上词语加工的动态过程,并模拟了整个句子完全加工前的眼动过程。模型的输出是一系列被识别的词语,以及句子加工过程中每个注视点的位置、起始时间和结束时间。
3.3.2 模型的初始化
模型启动时随机选择句子的第一个或第二个汉字作为注视点,然后启动词语加工模块注视该汉字,并从注视点左侧一个汉字右侧三个汉字的范围内获取新信息。所有单元的激活初始值为0。
3.3.3 眼动指标度量
为了模拟眼动指标,模型需要一个时间系统来记录眼睛移动的时间。CRM 模型参照交互激活模型的实现方式,以离散的时间单位的方式运行。程序每循环一次称为一个迭代。在每次迭代中,网络中的所有单元的激活都会更新一次。模型使用一次迭代的持续时间作为模型计时系统的单位。为了将模拟数据与眼动实验数据进行比较,CRM 模型将迭代次数乘以一定的比例以转换为注视时间,使得模型预测的平均注视时间与观察数据的平均注视时间一致。为了计算基于词的眼动测量,CRM 模型使用与眼动研究相同的方法,计算首次注视时间、凝视时间和再注视概率来表示眼睛移动的时间,计算跳读率和眼跳长度来表示位置信息。在一些模拟中,模型还计算了词内眼跳落点位置。注意,由于模型没有实现高级认知加工,而高级认知语言加工又被认为是回视的主要因素(Rayner,1998),因此模型只计算了首遍阅读(first-pass reading)眼动指标,而没有考虑回视。
3.3.4 用于寻找最佳参数的数据集
通过拟合Wei 等人(2013)的数据来寻找最佳参数。这项研究记录了21 名被试阅读72 个句子时的眼动数据,其中36 个句子包含高频两字词(每百万出现50 次以上),36 个句子包含低频双字词(每百万出现不到5 次)。这些目标词的预测性接近于0。该研究发现了词频效应:在低频词条件下,首次注视时间和凝视时间显著长于高频词条件。另外,离开高频词的眼跳长度显著长于离开低频词条件,低频词的注视概率和再注视概率显著高于高频词条件。
3.3.5 模型拟合方法
CRM 模型寻找最佳模型参数的方法如下。模型加工了Wei 等人(2013)实验中的句子材料。采用目标词的首次注视时间、凝视时间、注视概率和再注视概率,离开目标词的眼跳长度和汉字识别准确率作为拟合偏差的计算指标。模型使用归一化均方根偏差(nRMSD)来计算拟合偏差(公式 10)。
在公式10 中,yipredicted是模型预测数据,yiobserved是观测数据,stdiobserved是观测数据的标准差,n是模型拟合的数据点数。nRMSD值越小,模型拟合越好。在整个参数空间中搜索最佳参数,使nRMSD最小。
因为参数空间非常大,采用并行遗传算法(parallel genetical algorithm)寻找最佳拟合参数。找到最佳参数后,将这些最佳参数用于其他所有模拟中。正如接下来的模拟结果所示,使用相同的参数能较好地模拟不同的实验结果,表明CRM 模型的通用性很好。模型采用的参数如表1 所示。
4 模型模拟表现
首先CRM 模型模拟了眼动控制模型的经典效应(词频效应、预测性效应和词长效应),大多数拼音文字书写系统的眼动控制模型都模拟了这些效应(Engbert et al.,2005; Reichle et al.,1998)。学界普遍认为眼动控制模型都应该能模拟这些效应(Engbert et al.,2005)。除此之外,CRM 模型还模拟了由于词间空格的缺失中文读者面临的两个独特的问题,而中文眼动阅读模型都需要解释这两个问题:中文读者在没有词间空格的帮助下如何进行眼跳目标的选择;读者如何处理词边界歧义的两种情况(重叠歧义字符串和组合歧义词)。
4.1 眼动控制模型的传统基准数据
CRM 模型成功地模拟了中文句子阅读中眼动研究的重要发现,如词频效应、预测性效应和词长效应等。
4.2 眼跳目标选择
模型也能拟合以往关于眼跳目标选择的研究:被注视词的词频越高,离开注视词的眼跳长度就越长(Wei et al.,2013);而且被注视词的词频是通过影响副中央凹的加工程度来影响眼跳长度:在副中央凹信息正常呈现时,词频影响眼跳长度,而在副中央凹信息被掩蔽时,这种词频效应减弱(Liu et al.,2015)。
之所以能成功模拟这些效应,是因为模型采用了基于加工的策略。模型通过公式7,令副中央凹的位置上的视觉层对汉字层的输入强度受中央凹词频的影响,从而实现副中央凹加工的视觉效率受到注视词词频的影响。当副中央凹信息可见时,高频词导致右侧汉字更多加工,从而使离开高频词的眼跳比离开低频词更长;当副中央凹信息不可见时,副中央凹的加工受掩蔽符号影响,降低了目标词词频对眼跳的影响。
4.3 副中央凹预视效应
模型还能模拟副中央凹预视效应,即副中央凹的词语在注视中央凹时会被加工。在Gu 和Li(2015)的实验2 中,中文读者阅读了嵌入两字目标词的句子。在目标词之前的隐形边界之前,显示了预视词,当眼睛跨过边界时,预视词变为目标词。有效预视条件下,目标词与预视词一致;无效预视条件下,目标词与预视词不一致,且预视词为随机的两个汉字,不能组成词语。模型的结果与实验一致,即无效预视条件的首次注视时间和凝视时间长于有效预视条件。模型能够模拟预视效应是因为它假设知觉广度范围内的汉字是平行加工的。因此副中央凹的信息在有效预视条件下可以被加工到一定程度,因此在随后被注视时花费的时间相对于无效预视条件更少。
4.4 词切分
4.4.1 重叠歧义字符串
首先,它能够拟合左侧优势和词频对词切分的影响。前人研究发现了左侧词在词切分中的优势(Huang & Li,2020; Li et al.,2009; Ma et al.,2014):在其他条件相同的情况下,左侧的单词更有可能被切分成一个单词。此外,如前文所述,Ma 等人的研究表明,词频高的词更容易被切分出来,且词切分的过程可能分为两个阶段(词语竞争阶段和随后的信息整合阶段)。
当前的模型能模拟词切分的第一阶段,词语竞争阶段。模型的模拟采用了Huang 等人(2021)的实验材料。该研究将重叠歧义字符串嵌入了句子中,操纵条件之一是左右侧词的相对频率,具体而言操纵OAS 左侧词的词频高于右侧词(高-低频条件),或左侧词的词频要低于右侧词(低-高频条件)。模型模拟结果表明,高-低频条件下,98.3% 的试次中将中间位置的汉字切分到了左侧词;低-高频条件下,51.7%的试次中将中间位置的汉字切分到左侧,48.3%的试次中将中间位置的汉字切分到了右侧。这一模拟结果与实验中左侧优势和词频对词切分的影响一致。
4.4.2 组合歧义词
中文中词边界模糊的情况,除了重叠歧义字符串以外还有组合歧义词(incremental words),即一种内部的汉字本身也构成词的词语。比如汉字“不断”,可以切分为“不”“断”“不断”。以前的研究发现,在加工这种词时存在整词优势,即读者更倾向于将它们识别为更长的词。例如,Yang 等人(2012)的研究发现,双字组合歧义词的第一个字在句子语境中的合理性对阅读时间没有影响。这表明中文读者更倾向于将组合歧义词作为一个整体加工,而不是逐字加工。
模型采用了Wei 等人(2013)研究中实验2 的材料,在该实验中,中文读者阅读包含高频目标词和低频目标词的句子。其中,72 个目标词中有70 个词的汉字本身可以成词。对于这些目标词,模拟结果显示,目标词是高频词时,整词切分在99.4%的试次中胜出,目标词是低频词时整词切分在99.2%的试次中胜出。在这次模拟中整词切分具有绝对的竞争优势,词频的影响非常微弱。这些结果与Yang 等人(2012)的结果一致,表明中文阅读中组合歧义词通常作为一个整体进行加工。
模型中,组合歧义词的加工机制如下。在词语层,“不”、“断”和“不断”都会被激活,这些词相互竞争唯一的胜出者。在竞争中谁能胜出取决于以下两点:第一,竞争会受到词频的影响,高频词更有可能胜出;第二,整词在竞争中有优势,因为它可以收到更多汉字单元的前馈激活,当单字词和整词的词频相似时,整词胜出的可能性更大。
5 讨论
Li 和Pollatsek(2020)构建了中文阅读过程中词语加工和眼动控制的整合模型,着重解释了中文读者在阅读过程中如何解决词切分和眼跳目标的选择等重要问题。基于前人研究,CRM 模型提出了几个重要假设,使研究者能解决这些关键的问题。
5.1 词切分机制
词语加工模块中最重要的假设是,词切分和词语识别是一个统一的过程,它们同时发生。首先,知觉广度范围内的所有汉字都(在视敏度的约束下)被平行激活。这些汉字构成的所有词语都被激活。在空间上有重叠的词语会相互竞争,在每一轮竞争中,只有一个词可以获得胜利。中文阅读中词切分的机制与英文阅读词切分的机制有很大不同。英文阅读中,先依赖词间空格将词切分出来,再进行词的识别。而中文阅读中,词切分和词识别是一个统一的、不可分的过程,没有先后。
5.2 眼动控制
对于何时移动眼睛,CRM 模型假设,注视词的激活会影响眼睛移动的时间,但是眼睛移动的时间和完成词语识别的时间并不完全一致。而对于向何处移动眼睛,CRM 模型实现了基于加工的眼跳目标选择策略,在一个注视点上读者尽可能多地加工注视点右侧的字,将下一个眼跳落点选择为未加工信息位置。CRM 模型假设,汉字的激活是决定眼睛移动的位置的主要因素。具体来说,模型主要用汉字激活地图来确定眼跳落点的位置,先评估在给定注视点上能加工的字数,然后执行眼跳。可以看出,模型中词语单元的激活并不直接影响眼睛移动的位置,因此中文读者不会将眼跳指向词语内部的特定位置。然而值得注意的是,由于词语加工和字的加工本身是交互的,词单元会通过反馈链接影响相应的汉字单元的激活。因此词语加工也会间接影响眼跳目标的选择。
5.3 模型的局限
尽管模型成功地模拟了中文句子阅读中的词语加工和眼动控制,但仍然具有局限性。第一,出于简化的目的,模型只考虑了词语加工,而没有考虑句法加工、语义加工和篇章加工等高级认知加工过程。这些加工过程也会影响眼动行为。第二,模型没有语音加工模块和语义加工模块,因此无法模拟与语音预视效应和语义预视效应相关的研究发现。同时,由于模型缺乏语义加工模块,因此无法模拟在加工重叠歧义字段时的回视眼动行为。当模型在加工的初始阶段出现错误时,无法像人类读者一样进行检测和纠正。未来的工作可以考虑这些影响并进一步发展模型。第三,当前的模型假设汉字受到插槽的限制,即一个汉字只能链接到一个插槽。然而,一些研究表明汉字位置的编码可能没有那么严格,即使改变了位置,读者仍然能够识别词语。对于这一发现,需要进一步研究并修改模型以做出解释。
6 结论
CRM 模型实现了一个模拟中文阅读中词语加工和眼动控制之间关系的计算模型。模型解释了中文阅读中有关读者如何进行词切分,如何进行眼跳目标的选择等重要问题。模型成功地模拟了中文阅读中一些重要的眼动研究发现。
