数据生命周期视角下的医疗健康大数据质量评价研究
2024-01-27翟运开郭瑞芳王宇等
翟运开 郭瑞芳 王宇等










关键词: 医疗健康大数据; 数据质量评价; 数据生命周期; 模糊最优最劣法; 熵权法
DOI:10.3969 / j.issn.1008-0821.2024.01.011
〔中图分类号〕G203 〔文献标识码〕A 〔文章编号〕1008-0821 (2024) 01-0116-14
近年来, 随着信息技术的快速发展, 可穿戴设备、电子健康监测仪器等智能医疗设备在生活中广泛应用, 使得医疗健康相关数据呈指数增长并最终汇聚成医疗健康大数据。医疗健康大数据涵盖与自然人医疗健康相关的多种数据, 涉及个人健康、公共卫生、医药服务等诸多方面, 是互联网、物联网、人工智能等领域与医疗健康相结合的产物[1-2] 。医疗健康大数据是国家重要的基础性战略资源, 它的发展和应用对改进医疗健康服務模式和促进社会经济发展有着重要作用。我国已将医疗健康大数据纳入了国家大数据战略布局, 并出台了《关于促进和规范健康医疗大数据应用发展的指导意见》等相关政策[3] , 成立了国家医疗数据中心、中国健康医疗大数据产业联盟, 启动了健康医疗大数据中心与产业园建设国家试点工程。
然而, 在大数据背景下, 医疗健康大数据快速累积的同时也暴露出了质量差、利用率低等问题。Burnum J F[4] 指出, 电子病历等卫生信息技术的引入提高了医疗健康数据的写入效率, 但同时也记录了更多不良数据导致医疗健康数据质量下降。医疗健康领域的发展直接影响着人们的生活质量和社会稳定, 对服务的精准性要求较高[5] , 数据质量的下降增大了依托医疗健康大数据决策失误的风险。良好的数据质量是高效利用数据、充分挖掘数据价值的前提和基础, 医疗健康大数据的开放共享和深入应用离不开高质量的数据。
数据质量评价是数据质量管理和控制的基础[6] , 通过数据质量评价可以发现我国医疗健康大数据质量的薄弱方面, 进而促进医疗健康大数据质量提升。现有医疗健康数据质量评价相关研究以构建评价指标体系为主, 指标多涉及准确性、完整性、规范性等通用指标, 同一指标的定义存在差别[7-8] , 多以主观方法确定指标权重, 且缺乏完整评价模型的构建与应用[9] 。鉴于此, 本文考虑了医疗健康大数据的自身特点, 结合数据生命周期理论, 构建了医疗健康大数据质量评价指标体系, 并采用主客观相结合的方法确定各指标权重, 最终选取多家单位数据库中真实存储的医疗健康大数据作为评价对象, 验证本文所构建的评价指标体系和综合评价模型的科学性与有效性, 进而为医疗健康大数据的质量控制与提升提供指导, 为医疗健康大数据的深入应用与产业发展打下坚实基础。
1 文献综述
数据质量与实体产品质量不同, 在数据的生产、储存、使用中, 涉及到数据生产者、数据管理者、数据消费者三种角色, 对于每种角色而言数据质量的含义侧重有所不同。数据质量多从消费者的角度进行定义, 对于数据消费者即使用者来说, 有用性和可用性是数据质量的重要方面[10] , 由国家市场监督管理总局、中国国家标准化管理委员会发布的《信息技术数据质量评价指标》将数据质量定义为,在指定条件下使用数据时, 数据的特性满足明确的或隐含的要求的程度[11] 。对数据质量进行评价的视角有数据产品视角、数据平台视角、数据用户视角、数据生命流程或周期视角[12-13] , 现有研究多以用户需求视角和数据生命周期视角为主[14-15] , 评价方法涉及访谈、德尔菲法、层次分析、模糊综合评价等方法[16-17] , 主观性较强且多以提出概念框架为主, 模型理论性强可行性差。
现有研究中, 与医疗健康数据相关的质量评价涉及电子病历数据、医院信息系统数据、公共卫生信息数据等。袁莎等[9] 基于文献分析和专家咨询的方法, 依据原始质量、过程质量、结果质量3 个维度, 构建了医疗数据评价指标体系。杨善林等[5] 将医疗健康大数据中的医疗健康案例质量把控划分为了入库阶段和使用阶段, 通过人机融合的方法, 分别从信息完整性、典型性、外部特征以及有用性、易用性、总体质量等方面对案例进行评价。在评价指标体系的相关研究中, 美国国立卫生研究院卫生保健系统研究实验室对电子健康档案(EHR)数据质量从完整性、准确性、一致性3 个维度进行了评估。Weiskopf N G 等[7] 通过相关文献分析提出使用完整性、正确性、一致性、可信性、通用性5 个维度和7 类质量评估方法对电子病历数据质量进行评估, 以促进电子病历数据的重用。已有的研究中涉及指标范围较广, 但对于数据质量各个维度和指标缺乏明确、统一的含义[18] , 对医疗健康大数据自身特性考虑不足, 缺少系统的评价程序, 难以全面、准确地对医疗健康大数据的质量进行评价。
此外还有一系列信息化评估工具, 如对EHR 数据质量进行评估的可视化、开源、可拓展的DQe-c工具, 可以生成基于Web 的报告, 通过描述性图表体现EHR 数据库的完整性和一致性[19] ; 使用Hadoop Map/ Reduce 对医疗资源描述框架(RDF)数据集进行质量评估和异常数据检测[20] , 以提供更加准确和可靠的数据集。以上工具多针对某种明确数据源, 对被评价数据要求较高, 普适性较差, 并且多基于西方国家医疗健康大数据发展现状, 难以在我国直接外推使用[21] 。
针对以往数据质量评价指标体系中存在的定义不明确、对医疗健康大数据特点针对性不强等问题,本文基于已有文献中的指标和该领域多位专家意见, 基于数据生命周期视角并充分考虑医疗健康大数据自身特性, 结合医疗健康大数据质量生命周期模型, 对数据质量评价指标进行重新定义和阶段划分, 构建了符合医疗健康大数据特点的质量评价指标体系。为了弥补已有研究中评价方法主观性较强的问题, 在指标权重确定过程中, 本文充分考虑评价过程的模糊性和不确定性, 使用模糊最优最劣法(模糊BWM) 和熵权法(EWM) 综合确定指标主、客观权重, 在考虑专家经验和主观判断的同时又有可量化数据支撑。为了增强评价结果的直观性和综合性, 本文将专家语言变量转化为三角模糊数, 以定性与定量相结合的方法进行评价, 并引入TOP⁃SIS 方法进行综合排序。最后, 对本文所构建的指标体系和综合评价模型进行了实际应用, 获得了具有现实意义的医疗健康大数据质量评价结果。综上所述, 本文构建了较为完善的医疗健康大数据质量评价指标体系和评价模型, 可以全面、系统地对医疗健康大数据的质量进行综合评价。
2 医疗健康大数据质量评价指标体系构建
基于数据生命周期理论, 构建了医疗健康大数据质量生命周期模型, 基于此并结合医疗健康大数据特点, 初步构建了医疗健康大数据质量评价指标体系, 而后根据专家意见对指标进行优化, 形成3个阶段、9 个指标组成的医疗健康大数据质量评价指标体系。
2.1 医疗健康大数据质量生命周期模型
数据生命周期的概念提出于上世纪60 年代,进入21 世纪数据量快速增加, 数据生命周期理论得到进一步重视。数据资产管理组织(Data AssetManagement Association, DAMA)将数据生命周期定义为从创建、采集、使用到消亡的全过程。国内外对于数据生命周期的阶段划分有所不同, 涌现出了大量应用广泛的模型, 如表1 所示。这些模型的阶段划分、适用对象和侧重内容有所不同, 如DCC模型是较为通用的数据生命周期模型[22] ; DDI 模型主要针对社会科学数据[23] ; CSA 模型主要侧重数据安全方面, 考虑了每一个阶段可能会产生的数据安全问题[24] ; 数据质量生命周期模型划分了创建、存储、检索、使用4 个主要周期, 有助于更好地理解数据质量问题且具有很强的通用性[25] 。国内学者周宁[26] 认为, 数据生命周期包括创建、存储、使用、归档、销毁5 个状态, 数据一旦创建,可以在任意两个状态跳转, 不一定经历所有状态。根据研究对象和研究问题的不同, 数据生命周期的阶段划分也会有所不同, 但广泛存在交叉重叠。如研究较多的科研数据生命周期, 存在多种划分方法, 但主要围绕产生、收集、处理与存储、共享与利用4 个阶段。
本文以数据生命周期理论为基础, 借鉴以往研究, 从医疗健康大数据管理者的角度出发, 以数据质量评价为目的, 重点关注医疗健康大数据从产生到利用过程中的质量, 构建了医疗健康大数据质量生命周期模型, 如图1 所示。该模型将其生命周期划分为数据采集、数据预处理与储存、数据分析与使用3 个阶段, 并设定评价指标对医疗健康大数据质量进行全面评价。
数据采集阶段指获取数据的过程, 从不同数据源实时或定时收集数据, 并发送给存储系统或数据中间件系统进行后续处理。采集的医疗健康大数据包括电子病历数据、公共卫生数据、个人健康数据、医院运营数据等, 数据来源包括患者或用户个人、医疗机构、医保部门、公共卫生部门等多种主体。在该阶段, 医疗健康大数据质量会受到数据源、数据采集方式和技术等因素的影响[27] 。
数据预处理与储存阶段指对上阶段采集到的医疗健康大数据按照相关规范、标准进行预处理(ETL 抽取、转换、加载)、存储及更新, 同时采用相关措施确保数据安全存储和访问。采集的数据需要按照相关标准和规范经过清洗、筛选、排序等操作才能进入数据存储系统, 对于隐私数据或敏感数据, 需要有相应的加密和脱敏措施。此外, 医疗健康大数据是时刻产生、动态变化和不断累积的,需要对数据进行更新。在该阶段, 医疗健康大数据质量会受到数据预处理技术、数据存储和访问方式、数据管理机制等因素的影响。
数据分析与应用阶段指使用已经储存在数据库中的医疗健康大数据, 包括业务系统内、外的调用、查看和使用数据进行统计分析、可视化分析与预测, 并将其应用于管理决策、战略规划、科学研究、市场营销等。在该阶段, 医疗健康大数据质量会受到数据系统、数据分析技术、数据应用等因素的影响。
2.2 指标体系初步构建
医疗健康大数据在具备大数据“5V” 特点的基础上, 还具有隐私性、冗余性、时效性、不完整性等特点[28-29] 。隐私性表现在电子病历、健康档案等大多包含患者身份信息以及如传染病、遗传病等较为敏感的疾病信息, 一旦发生泄露会给患者带来严重影响。医疗健康大数据中非结构化数据较多, 相似文本和相似图像的重复记录、患者自述中的大量无关信息、疾病症状的多种表达方式等原因使得医疗健康数据产生重复、冗余。时效性表现在医疗健康大数据实时产生并随时间变化, 多数疾病的发病、诊治过程有时间线, 医学检验结果受时间影响, 所以医疗健康大数据采集、存储、使用的及时性也是质量的一个重要方面。不完整性主要表现在由于患者表述不完整、医生水平有限、疾病本身复杂程度高或早期数据缺乏电子化记录等原因导致数据在输入时不完整[29] , 或在数据存储过程中发生损坏、丢失。
基于现有文献中关于数据质量评价指标体系的相关研究, 并结合医疗健康大数据的隐私性、冗余性、时效性、不完整性等特点, 本文从医疗健康大数据质量生命周期模型的3 个阶段出发, 初步建立了医疗健康大数据质量评价指标体系。在数据采集阶段考虑准确性、完整性、可靠性、时效性指标,在数据预处理与存储阶段考虑规范性、安全性、隐私性、一致性指标, 在数据分析与应用阶段考虑流通性、可访问性、价值性指标。
其中, 准确性、完整性、可靠性、时效性、规范性、安全性等指标多次出现在数据质量评价及管理相关文献中, 是较为通用的数据质量评价指标[11,27] 。准确性指标指医疗健康大数据反映数据主体情况的准确程度; 针对医疗健康大数据所具备的不完整性特点, 设置完整性指标从数据规模、数据类型、数据内容三方面对医疗健康大数据质量进行评价; 可靠性指标指医疗健康大数据内容和来源的真实和可靠程度; 时效性指标指医疗健康大数据反映数据主体当前状态以及变化情况的程度, 对应医疗健康大数据时效性强的特点; 规范性指标指医疗健康大数据格式和内容符合国家标准、区域标准的程度; 安全性指标指对医疗健康大数据的加密存储、访问控制、身份验证、备份恢复等措施。
此外, 隐私性、一致性、流通性、可访问性、价值性指标在已有文献基础上进一步考虑了医疗健康大数据自身特点和存储及应用现状。隐私性指标指对医疗健康大数据中所包含隐私信息的保护和匿名化处理[30] , 对应医疗健康大数据隐私性较强且隐私问题贯穿多个生命周期环节的特点; 由于医疗健康大数据储存在多个单位的数据系统或第三方数据库中, 故设置一致性指标[7] , 用以评价不同单位存储的相同或相关数据的内容及格式的一致程度以及数据描述与数据实体的对应程度; 由于医疗机构间存在“数据孤岛”、医疗信息系统建设水平不均衡, 故考虑流通性指标, 评价数据可以在不同系统或不同单位间进行共享、传输的程度[31-32] ; 可访问性指标考虑了医疗健康大数据的冗余性, 指是否可以访问、查看、下載已存储的医疗健康大数据,以确保其是可操作、可用的[32] , 而非无用的垃圾数据; 价值性指标指医疗健康大数据能够为机构、社会、国家等层面带来的价值[34] 。
2.3 指标体系优化
采用专家意见法, 邀请医疗健康大数据领域的研究人员、技术人员、管理人员共9 位专家对初步构建的指标体系发表修改意见。综合专家意见, 将具有交叉重叠的指标进行合并或剔除。将9 位专家的修改意见综合如下: ①剔除可靠性指标, 将可靠性指标侧重的数据真实可靠性合并到准确性指标;②将时效性指标修改为及时性, 主要关注医疗健康大数据记录和更新的及时性; ③将隐私性指标合并到安全性指标, 除对医疗健康大数据的安全保障措施进行评价外, 还关注其隐私保护措施; ④将流通性指标修改为互联互通性指标, 关注医疗健康大数据在不同系统间进行流动、传输、兼容的程度; ⑤将可访问性指标修改为可用性, 指医疗健康大数据中包含有用信息并且可用于下载、查看、统计分析,并且可以进行可视化分析、实现大数据分析与应用的程度。
根据本文提出的医疗健康大数据质量生命周期模型的3 个阶段并结合专家意见, 对确定的9 个评价指标进行阶段划分, 指标处于某个阶段代表该指标所包含的内容在该阶段需重点关注。指标说明和阶段划分如表2 所示。
本文所构建的医疗健康大数据质量评价指标体系是在已有相关研究和标准的基础上提出的, 涵盖了通用的数据质量评价指标。因此, 如要对一般领域的数据质量进行评价, 可在本文提出的评价指标体系的基础上进行调整, 剔除与所评价数据相关性较低或不相关的指标, 并对指标权重进行调整, 以更加符合所评价数据的特点, 进而获得更为科学合理的数据质量评价结果。
3 医疗健康大数据质量综合评价模型构建
采用主、客观相结合的方法, 使用模糊BWM和EWM 两种方法综合确定指标权重, 邀请专家对医疗健康大数据质量进行评价, 并将专家语言变量转化为三角模糊数进行定量分析, 最后使用TOP⁃SIS 方法进行综合排序, 构建了医疗健康大数据质量综合评价模型。
使用以上两种方法相结合确定指标权重具有以下几点优势: 首先, 模糊BWM 属于主观方法, 而EWM 属于客观方法, 两种方法相结合可以综合考虑专家经验和主观判断以及可量化的数据信息, 减少使用单一方法存在的局限性, 得到更为全面、准确的权重结果; 其次, 模糊BWM 方法相较于传统主观权重确定方法如AHP, 其一致性和可靠性更强, 而EWM 方法又为权重计算结果提供了数据支持, 两种方法结合可以增强权重计算结果的可信度; 最后, 主客观相结合的权重计算方法可以根据不同决策场景进行调整, 以适应实际需求, 并且可以对权重结果进行解释, 提高权重计算的灵活性和可解释性。因此, 采用模糊BWM 和EWM 两种方法综合确定指标权重, 与传统方法相比更具综合性、可信性以及可解释性。
3.1.1 模糊BWM 方法
2015 年, Razaei J[36-37]提出了最优最劣法(BWM,Best-worst Method), 该方法的主要步骤是专家确定最优和最劣的两个属性, 并将最优属性与其他属性、其他属性与最劣属性分别进行比较, 获得两组偏好向量, 然后建立并求解数学规划模型获得指标最优权重, 为了提高结果的准确性还需进行一致性检验。三角模糊数由Zadeh L A[38] 于1965 年为了解决不确定环境下的问题而提出, 被广泛应用于质量管理、风险管理等领域, 通过将模糊的、不确定的语言变量转化为三角模糊数, 可以很好的解决由于被评价对象的模糊性和复杂性所导致的只能用自然语言进行模糊评价的问题。以BWM 方法为基础,Guo S 等[39] 将三角模糊数引入其中, 建立了模糊BWM 模型, 并通过3 个实例验证了模糊BWM 方法的可行性和有效性。
在定性比较的过程中, 存在着模糊性和无形性。常用的权重确定方法AHP 需对比n∗(n-1) / 2 次才可获得判断矩阵, 而BWM 方法只需要比较2n -3次, 具有较少的冗余, 减小了评价过程中的误差,提高了结果的一致性、可靠性以及决策效率。由于用以评价医疗健康大数据质量的指标较多, 在进行指标重要程度比较的过程中存在不确定性和模糊性, 所以使用三角模糊数来代替清晰值可以获得更符合实际情况的特点。因此, 本文使用模糊BWM方法进行指标主观权重确定, 重要程度对比以语言变量呈现, 分别对应不同三角模糊数, 对应规则如表3 所示。该方法的主要步骤如下:
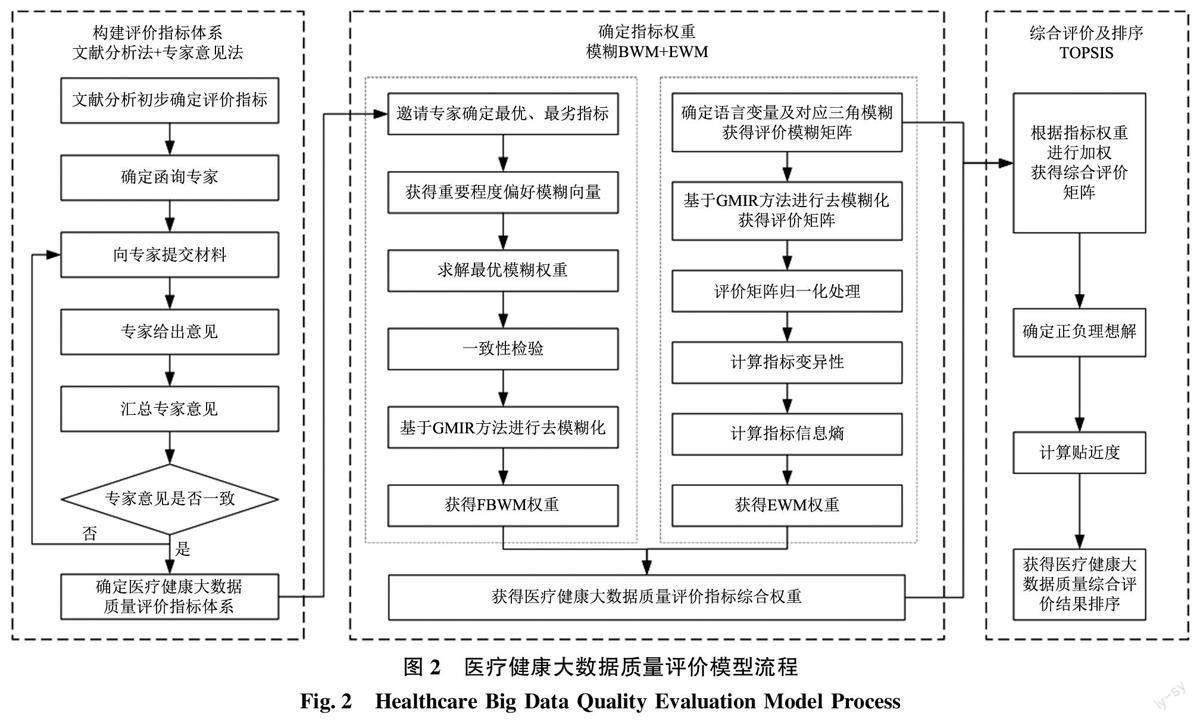
综上, 本文采用文献分析法和专家意见法构建医疗健康大数据质量指标体系, 使用模糊BWM 与EWM 结合确定指标权重, 最后使用TOPSIS 方法获得医疗健康大数据质量评价结果, 构建了一个医疗健康大数据质量综合评价模型, 模型流程如图2所示。
4 医疗健康大数据质量评价实证研究
受医疗健康数据采集方式和数据特点的限制及影响, 当前医疗健康大数据多储存于医院、医疗数据相关公司各自的系统或第三方数据库中。为了验证本文所构建的评价指标体系和综合评价模型的合理性及有效性, 并全面了解医疗健康大数据的质量现状, 本文共选取了9 个医疗健康大数据存储单位, 其中包括多家三甲医院、知名大数据公司、医疗数据实验室等, 应用本文构建的评价指标体系及评价模型进行实证研究。
4.1 指标权重确定
本研究邀请了9 位医疗健康大数据领域的专家对本文所构建的指标体系中的9 个指标进行重要程度偏好比较, 得到的偏好向量如表5 所示。
根据专家的偏好向量, 求解模糊BWM 模型,获得各专家对应的指标最优模糊权重, 并通过GMIR方法进行去模糊化, 结果如表6 所示。
本文所邀请的医疗健康数据领域的9 位专家包括了多家医院信息科(处)负责人、医疗大数据实验室和企业负责人、医疗健康领域科技公司总经理、医疗信息化科研人员, 考虑了医疗健康大数据在医疗、商业、科研等不同产生和应用场景中的质量, 因此获得的指标权重是较为全面的, 可以适用于不同领域的医疗健康大数据质量。如若对較为特殊的医疗健康大数据进行质量评价, 如关于某项疾病的医疗健康大数据的质量, 可以使用本文的权重确定方法邀请与评价对象相关的细分领域专家进行指标权重确定。
4.2 质量结果排序
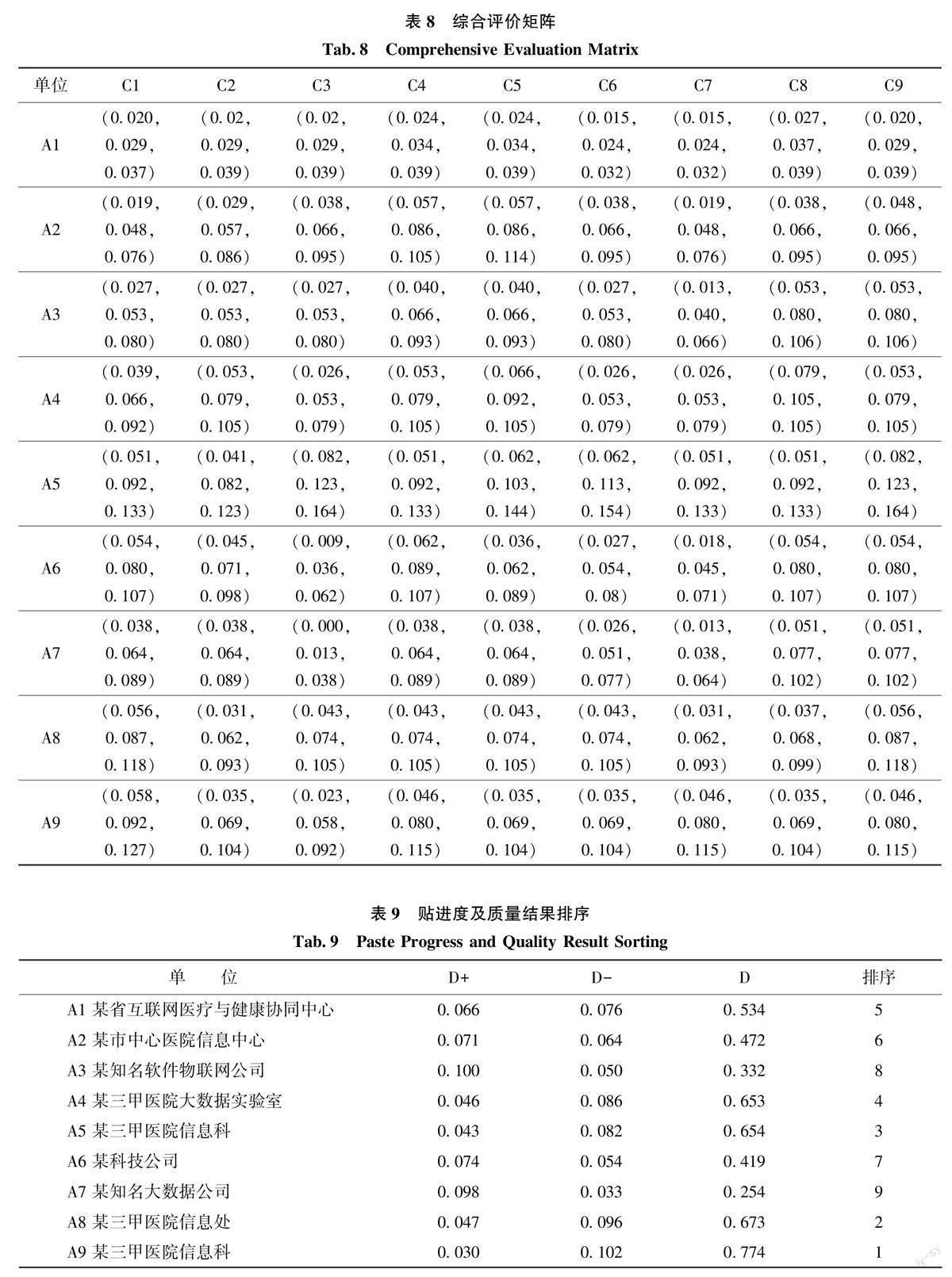
根据上节中确定的指标权重, 将专家初始评价矩阵进行加权, 获得综合评价矩阵如表8 所示。确定PIS、NIS 如下: PIS = [(0.027,0.037,0.039)(0.057, 0.086, 0.114 ) (0.053, 0.080, 0.106 )(0.079, 0.105, 0.105 ) ( 0.082,0.123, 0.164 )(0.054, 0.080, 0.107 ) ( 0.051, 0.077, 0.102 )(0.056, 0.087, 0.118) ( 0.058,0.092, 0.127)],PIN = [(0.015, 0.024, 0.032 ) (0.019, 0.048,0.076) (0.013, 0.040, 0.066 ) (0.026, 0.053,0.079) (0.041, 0.082, 0.123 ) (0.018, 0.045,0.071) (0.000, 0.013, 0.038 ) (0.031, 0.062,0.093)(0.023,0.058,0.092)]。计算贴进度并进行排序, 结果如表9 所示, 9 个单位医疗健康大数据质量排序为A9>A8>A5>A4>A1>A2>A6>A3>A7。通过质量结果排序发现, 医院存储的医疗健康大数据相较于其他机构质量较高, 且三甲医院存储的医疗健康大数据质量综合排序靠前。
4.3 医疗健康大数据质量结果分析
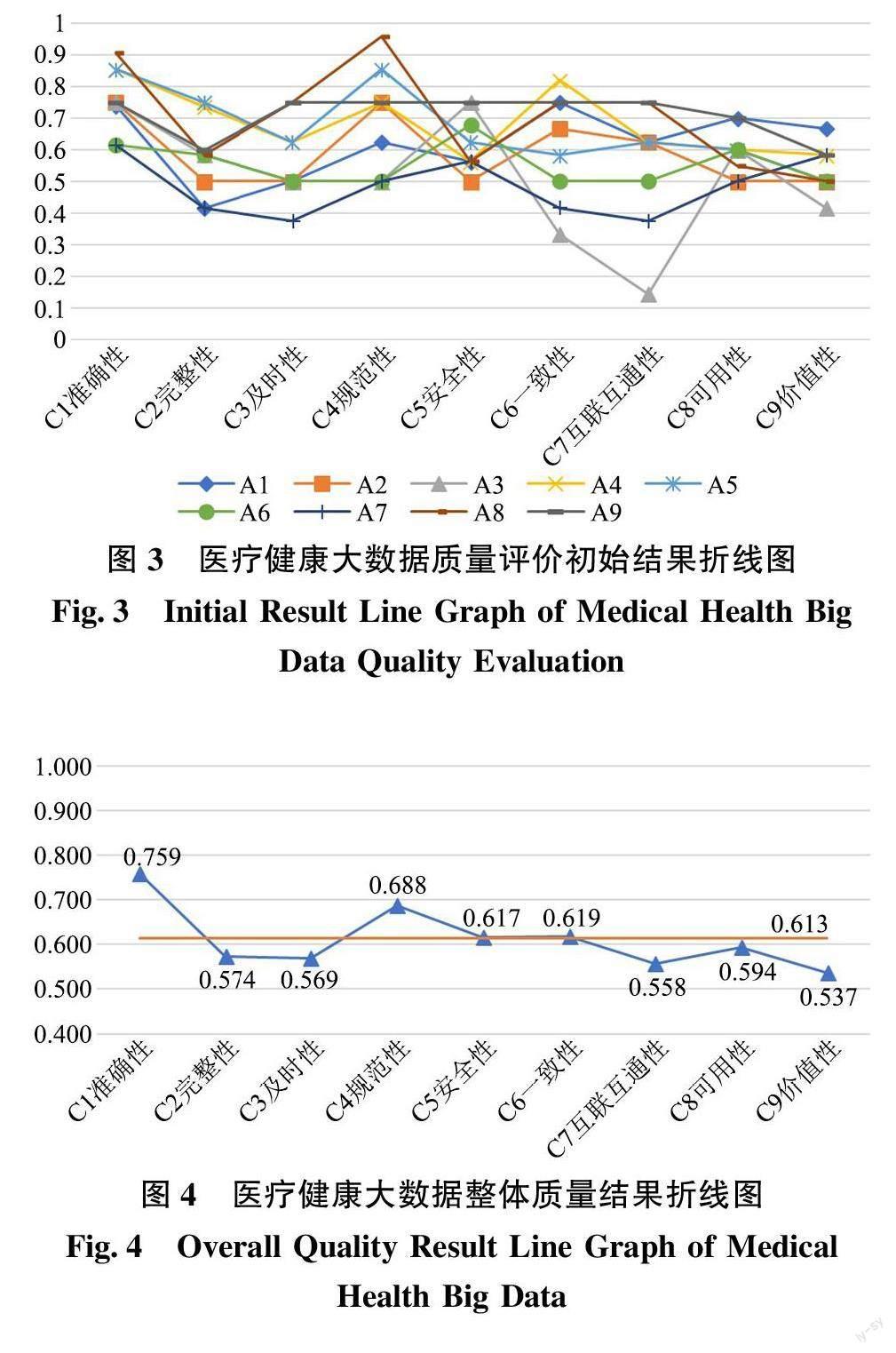
将专家评价获得的初始模糊矩阵通过GMIR 方法进行去模糊化, 得到各个评价对象的医疗健康大数据质量在各个指标下的初始未加权评价结果如图3 所示, 以更好地分析医疗健康大数据在各个指标下的质量。此外, 为更直观地获得医疗健康大数据的整体质量, 计算每个指标下9 个评价对象的得分平均值以及9 个指标得分均值, 获得整体质量结果如图4 所示。
据图4 显示, 得分相对较高的指标有准确性(C1)、规范性(C4), 均明显高于总体均值, 得分相对较低的指标有完整性(C2)、及时性(C3)、互联互通性(C7)、价值性(C9), 均明显低于总体均值。
在数据采集阶段, 医疗健康大数据的准确性(C1)较好, 完整性(C2)和及时性(C3)较差。医疗健康大数据多来源于医疗信息系统、公共卫生系统等, 数据来源可靠, 数据准确性较好。医疗健康大数据中包含的数据类型多且结构复雜, 受数据采集方式及能力限制, 无法涵盖所有数据, 数据完整性较差。医疗健康数据本身具有较好的时效性[44] ,由于系统延迟、数据库效率低、管理落后等原因,导致数据采集或更新不及时, 因此及时性较差。
在数据预处理与储存阶段, 医疗健康大数据的规范性(C4)较好, 安全性(C5)和一致性(C6)一般。医疗健康大数据在采集录入和存储时都要遵循相关的规范、标准, 因此规范性较好。据图3 可得医疗健康大数据在安全性指标上得分差异较小, 在一致性指标上的得分差异较大。医疗健康大数据隐私性较强, 《数据安全保护法》等相关法律法规为各个单位在数据安全保障方面提出了硬性要求, 因此数据安全性差异较小。由于各个单位采用的数据系统不同, 信息化程度不一, 对于同种类数据的采集方法、存储形式、更新频率等存在差异, 因此数据的一致性一般, 并在各个单位间呈现较大差异。
在数据分析与使用阶段, 互联互通性(C7)和价值性(C9)较差, 可用性(C8)一般。医疗健康大数据分散地储存在各个医疗机构或第三方数据库中, 缺少统一平台对数据进行整合, 受限于数据格式、隐私保护和权属划分等原因, 在数据整合和共享等方面存在困难, 互联互通性较差, 并且在不同单位之间存在较大差异。医疗健康大数据中所含信息的有用性已经得到了广泛认可, 但受限于数据权属、隐私安全以及大数据利用能力, 医疗健康大数据的可用性一般。目前, 基于医疗健康大数据进行的医疗决策占比较小, 公众对于医疗健康大数据缺乏清晰认知[18] , 其应用尚处于落地实践初始阶段,价值挖掘仍不够深入, 价值性较差。
本研究中选取的评价对象涉及了医院、实验室、企业等多类型的医疗健康大数据储存单位, 通过对其所存储的医疗健康大数据的质量从3 个阶段、9个指标出发做出综合评价, 较为全面地揭示了医疗健康大数据质量的现状。从整体来看, 我国医疗健康大数据质量水平一般, 在完整性、及时性、互联互通性、价值性上仍有待提高。
5 结论与展望
本文从数据生命周期视角出发, 构建了医疗健康大数据质量评价指标体系和综合评价模型, 为医疗健康大数据质量问题发现和数据质量提升提供了指导。首先, 建立了医疗健康大数据质量生命周期模型, 参考国内外文献、结合医疗健康大数据特点构建指标体系并进行优化, 采用模糊BWM 法和EWM 综合确定指标权重, 形成了完善、科学的指标体系。其次, 使用专家语言评价结合三角模糊数将定性评价转化为定量评价, 并使用TOPSIS 方法进行综合排序, 构建了一个综合评价模型。最后,应用本文构建的指标体系和综合评价模型, 获得了医疗健康大数据质量现状, 发现其完整性、及时性、互联互通性、价值性还需进一步提升。为了促进医疗健康大数据的质量提升和深入开发应用, 本文提出如下建议:
1) 加强数据采集阶段的质量控制, 从源头上提高医疗健康大数据质量。要从技术上优化数据采集系统, 提高数据采集的完整性, 改进数据收集传输流程, 减少数据延迟和滞后。要制定数据采集和录入的标准和流程, 加强对数据采集范围和内容的把控, 减少低质量数据进入数据库, 同时减轻数据库的储存压力。建立数据质量检测和反馈机制, 对医疗健康数据进行定期检查和评估, 同时设定激励机制, 鼓励医疗机构、个人等数据主体更好地记录和报告数据, 减少数据遗漏或丢失。
2) 进一步推动医疗健康大数据多平台协同建设, 提升医疗健康大数据的互联互通性。要推进医疗健康大数据国内、国际标准和规范的统一, 建立统一的数据接口和数据交换平台, 促进医疗健康大数据跨单位、跨平台互联互通和数据整合, 打破数据孤岛, 形成成熟完善的应用体系。要持续加强医疗健康大数据平台监管、细化隐私保护粒度, 保障医疗健康大数据互联互通过程中的安全性和隐私保护。要建立健全数据治理机制, 完善数据共享机制和协议, 提升医疗健康大数据的流通和应用水平。
3) 深入挖掘医疗健康大数据价值, 提升医疗健康大数据的利用水平。要加强医疗健康大数据分析人才培养, 通过可实现、可落地的应用提高数据利用率, 充分挖掘医疗健康大数据的价值, 增强医疗健康大数据的活性。要积极推广医疗健康大数据的重大价值和重要作用, 形成价值认同, 为医疗健康大数据深入应用发展打下坚实基础。要继续推进医疗健康大数据中心及产业园建设, 充分利用已建成的数据中心及平台, 推动医疗机构、企业、高校等元多主体协同参与, 营造良好的产业环境。
本文还存在一些局限: 本研究的评价视角为数据生命周期视角, 后续应当从多视角出发, 获得对医疗健康大数据质量更为全面、客观、真实的评价。此外, 受限于医疗健康数据的复杂性, 目前尚无法直接对评价指标进行量化, 后续研究中应当寻求合适的医疗健康大数据质量评价指标量化方法。良好的数据质量是实现医疗健康大数据更深层次应用的重要前提, 后续可以从医疗健康大数据共享、资产管理、再利用等多个方面进行医疗健康大数据治理的相关研究, 促进医疗健康大数据的价值实现与增值。
