基于改进K-means算法的网络攻击入侵检测方法设计①
2024-01-06狄宏林
吴 瑕, 狄宏林, 周 勇
(东莞开放大学, 广东 东莞 523000)
0 引 言
互联网技术的飞速发展使得我国的网民数量不断上升,网民数量的不断增加使得爆发式的网络数据也随之而来。如何对这些数据进行检测分类从而确保计算机网络的安全性是当前网络安全领域研究的重点[1-2]。为了防御异常数据的入侵行为,保护计算机在安全环境下进行运转,入侵检测技术被提出[3]。当前所使用的入侵检测系统能够实时进行数据监控,并对异常数据进行识别阻拦。然而,网络数据的爆发式增长使得传统的计算机防御技术和当前的数据处理技术已不再能保障计算机网络运行的安全[4]。传统的K-means算法(K-means clustering algorithm,K-means)K-means在进行聚类结果分析时容易陷入局部最优解,研究试图对其进行优化,并将优化后的算法用于网络攻击入侵检测当中,试图提高计算机的安全性能。
1 改进K-means算法在网络攻击入侵检测中的应用与研究
1.1 网络攻击入侵检测系统模型构建
网络入侵检测技术是一种主动的、基于状态的、实时的网络安全技术,它在检测计算机系统和网络中存在的各种安全问题时,采取积极的、主动的方式,并在可能受到攻击时立即作出响应,以防止计算机和网络信息被非法获取、破坏和滥用[5]。入侵检测技术作为一种动态防御系统,它能够动态地识别各种攻击行为并做出响应,及时地阻止或降低其影响。若数据存在攻击等非法行为,入侵检测技术能够进行数据拦截从而保障计算机安全。

图1 入侵检测模型运行流程图
图1所示为入侵检测模型的运行流程图。由图1可知,将收集到的网络数据进行预处理和分析之后判断其是否存在危险入侵,若不存在危险入侵,则对其数据行为特征进行提取,若存在危险入侵,则需要在知识数据库中进行标记并对其进行处理。知识数据库中会保存一些常见的危险入侵特征和异常行为特征,通过比对能够判断输入的网络数据是否存在异常活动。除此之外,知识数据库中还存储了系统的运行日志,管理员可以通过运行日志更好地了解计算机的运行状况并对其进行定期维护,提高计算机的防御性能。当前使用较为广泛的两种检测系统是异常入侵检测系统和误用入侵检测系统。计算机技术的发展使得入侵检测系统不断得到了完善,但网络数据大规模式的增长还是增加了系统的检测难度。传统的机器学习算法只能对数据进行二次分类,不能深入地挖掘数据中的信息,而且还存在着训练周期较长、检测准确率较低等问题。在这一背景下,研究提出了一种改进的K- means聚类算法,该算法可以实现自动匹配数据、自动更新知识库和自动日志审计等功能。
1.2 改进峰值密度的K-means算法研究
K-means算法是一种基于分类器的分类器,它可以随机地选择数据样本作为质量中心,然后通过计算其它样本与质量中心的距离,从而达到对样本进行分类。K-means算法一般使用欧氏距离来对两个样本之间的相似度进行衡量,其数学表达式如式(1)所示。
(1)
假设数据集有n个m维度的样本,那么任意两个样本X和Y之间的距离表达式记作D(X,Y)。其中,i∈1,2,…,m。
(2)
式(2)为K-means算法中质心ui的迭代计算公式。Ci表示第i个划分簇。|Ci|表示第i个划分簇中所包含的样本个数。
(3)
式(3)为误差平方和标准函数SSE的数学表达式。通过误差平方和标准函数的值能够判断算法迭代是否结束。当误差平方和小于设定误差时则终止算法。k表示将样本划分为k类;Xi,j表示第i簇中的第j个样本;d(Xi,j,ui)表示样本到质心的距离。
(4)

尽管K-means聚类分析算法有着操作简单、稳定性高、分析效果好等特点,但在不同的场景中使用时仍然具有一定的局限性,例如:对所划分的样本类别k值具有较强的依赖性,在同一数据集中不同的k值具有不同的分类结果;算法受中心点影响较大;算法具有较高的随机性因此难以收敛至最优解状态。针对上述问题,研究试图改进算法数据集中的样本密度,并利用密度最大原则进行中心点的挑选,最终提出改进峰值密度的K-means算法以此来提高传统K-means算法的稳定性,并加快其收敛速度。

图2 改进峰值密度的K-means算法流程图
图2所示为改进峰值密度的K-means算法流程图。整个算法的输入包括原始数据集D、半价参数q、聚类个数k和误差参数e,输出结果为划分好的聚类结果。首先设定好r并计算样本密度,将密度最大的样本记作xi,样本对应的密度值记作p(xi)。将xi放进集合x中并在数据集中删除其半径范围内的其他样本值,对数据集中所有的样本均执行该操作直到得到初始聚类中心集合x。选取密度最大的样本作为第一个聚类中心,然后将距离最远的第二个样本作为第二个聚类中心,以此类推选取剩下的初始中心。接着使用上述距离公式计算样本和中心之间的距离,并根据距离最小原则划分样本。然后对划分后的数据集中每一个分类簇采用式(2)计算新质心。最后根据收敛判定公式判定输出结果是否小于误差参数e,若成立则终止算法。
2 改进K-means算法在网络攻击入侵检测中的应用结果分析
为了证明研究提出的算法模型的有效性,选用KDD Cup99和CIC-IDS2017两种入侵数据集作为此次实验的数据对象,对数据进行预处理和归一化操作。采用64位的Windows 10作为实验所需的计算机系统,采用AMD Ryzen 7 4800H with Radeon Graphics作为显卡配置,硬盘采用2.0T规格,内存为32GB,最终在MATLAB上搭建实验环境,并对比K-means算法和改进峰值密度的K-means算法用于网络攻击入侵检测模型中的性能。
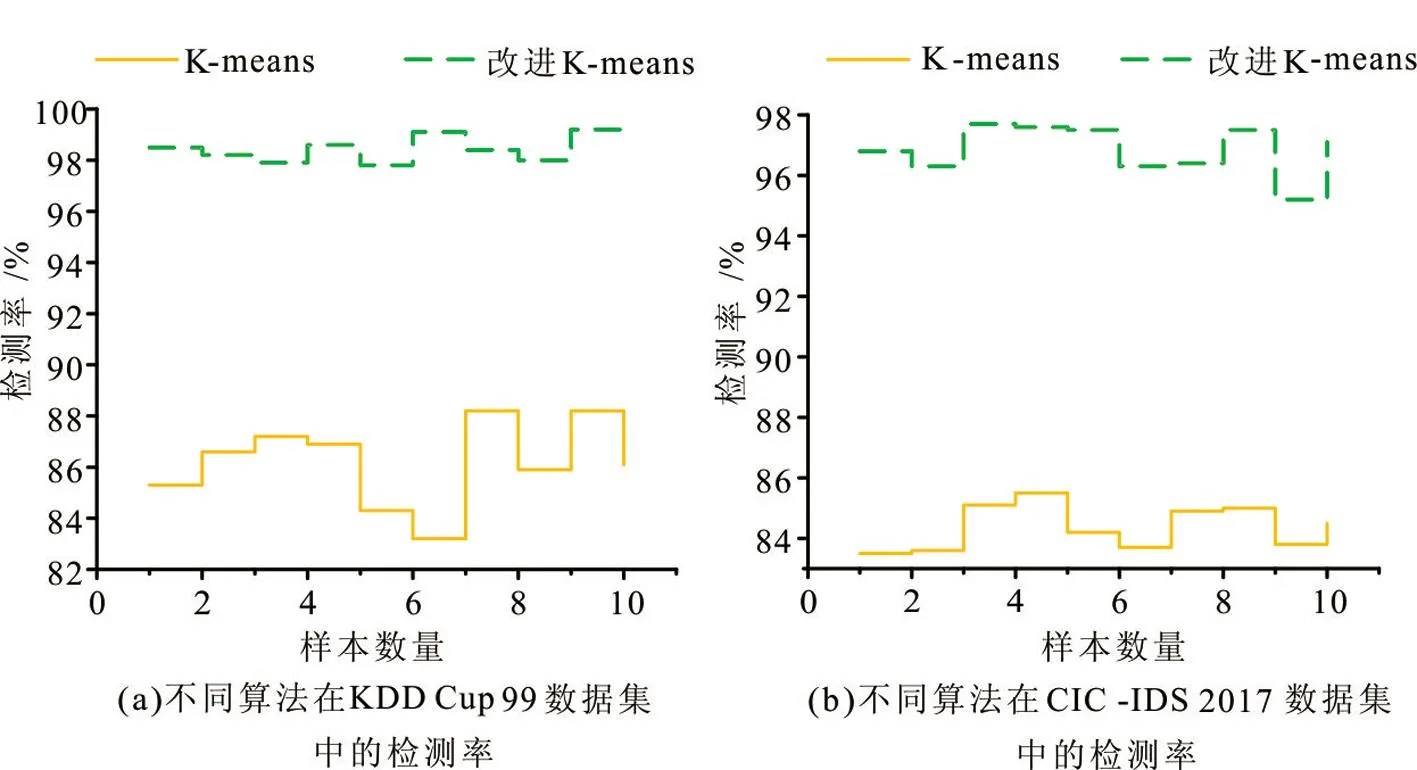
图3 两种算法的样本检测率情况
图3(a)为K-means算法和改进算法在数据集KDD Cup99中的检测率变化情况。随机抽取数据集中的数据进行检测,K-means算法的检测率在82%~83%之间,改进算法的检测率在96%~99%之间。图3(b)为两种算法在数据集CIC-IDS2017中的检测率变化情况。K-means算法的检测率在83%~86%之间,改进算法的检测率在94%~98%之间。由此可见,改进算法在两种入侵数据集中拥有更好的数据检测表现。

图4 两种算法的样本分类准确率情况

图5 两种算法的误报率情况
在图4(a)中,两种算法在数据集KDD Cup99中的分类准确率最大值分别为93.2%和99.5%。在图4(b)中,两种算法在数据集CIC-IDS2017中的分类准确率最大值分别为91.7%和98.6%。由此可见,改进算法在不同数据集中的分类准确率均远大于传统K-means算法,分类效果更好。
图5(a)所示为K-means算法和改进峰值密度的K-means算法在数据集KDD Cup99中的样本误报率情况。随着样本数量的改变,K-means算法的误报率在3.0%~4.5%之间,并且误报率上下浮动较大,而改进算法的误报率在0.1%~0.5%之间,不仅整体的误报率值较小并且浮动范围也远小于传统K-means算法。图5(b)所示为K-means算法和改进峰值密度的K-means算法在数据集CIC-IDS2017中的样本误报率变化情况。随着样本数量的改变,K-means算法的误报率在5%~7%之间浮动,改进算法的误报率则是在0.1%~0.8%之间浮动。由此可见,改进算法的误报率更低,因此更具备实用性。

图6 两种算法的检测时间曲线图
图6所示为两种算法所花费的样本检测时间曲线图。图6(a)所示为K-means算法和改进峰值密度的K-means算法在数据集KDD Cup99中的样本检测时间曲线图变化情况。随着样本数量的不断增加,两种算法的检测时间均有所上升。其中,当样本数量为10的时候,K-means算法的检测时间为7.9s,改进算法的检测时间为5.6s。当样本数量增加到50的时候,K-means算法的检测时间为20.7s,改进算法的检测时间为7.2s。图6(b)所示为K-means算法和改进峰值密度的K-means算法在数据集CIC-IDS2017中的样本检测时间曲线图变化情况。当样本数量为10的时候,K-means算法和改进算法的检测时间分别16.8s和6.3s。当样本数量增加到50的时候,K-means算法和改进算法的检测时间分别23.6s和8.5s。
3 结 语
研究对传统的聚类分析方法进行了改进,提出了一种基于峰值密度的改进K-means算法并将其运用到网络入侵检测模型当中。实验结果表明,在两种入侵数据集中,改进算法均拥有更好的性能表现。传统算法的检测率在82%~86%之间,误报率在3%~7%之间,准确率最大值为93.2%。当样本数量为50时,传统K-means的检测时间高达23.6s。相反,改进算法检测率在94%~99%之间,误报率在0.1%~0.8%之间,准确率最大值为99.5%,检测所花费的时间在10s以内。因此,将此次研究所改进的K-means算法应用到网络入侵检测模型中能够拥有较好的入侵数据检测性能,进一步保护计算机抵御外界数据的入侵,保证网络安全。
