基于DE-MADDPG多智能体强化学习机械臂装配*
2024-01-03苏工兵曾文豪于楚飞
王 晶,苏工兵,袁 梦,曾文豪,于楚飞
(武汉纺织大学a.机械工程与自动化学院;b.湖北省数字纺织装备重点实验室,武汉 430200)
0 引言
轴孔装配是工业生产中常见的任务[1]。近年来,随着以深度学习为核心的智能技术在装配领域得到了飞跃的发展[2-6],但在任务复杂,需要合作或竞争的环境中,需要多个智能体协作[7-9]共同完成目标,如双臂机器人实现抓取装配等[10-11]。其中,MADDPG[12]是处理多智能体合作关系最主要的算法之一,SHEIKH等[13]为了解决多个智能体的相互影响,提出了解耦性多智能体算法(DE-MADDPG),为每个智能体独立设计奖励函数,能有效的加快收敛速度。在串联机器人中,WITT等[14]在连续动作空间中将机器人的每个活动关节作为可观测对象进行了多智能体算法的探索研究。赵毓等[15]提出了一种改进DDPG算法,以各个关节为决策智能体建立多智能体系统,实现空间机械臂的匀速抓取。TAO等[16]将多指机械手的每个手指视为独立个体,并组合训练各自对应的智能体算法,以协同完成机械手操作任务。这些研究拓展了深度强化学习在机器臂装配中有效的应用,现机械臂只能实现较为简单的抓取移动等任务,对于较高精度的装配任务,还是需要进一步探索。
本文以六自由度机械臂Pieper准则构型为基础,将末端的位置和姿态分开独立控制,提出了将DE-MADDPG运用于六自由度机械臂的装配任务中,主要解决单智能体算法训练时间长,难以收敛等,以及多智能体算法在串联机器人中装配精度等问题。对末端位置和姿态独立控制,降低这两部分的耦合性,实现多智能体的协同控制,可以提高装配效率,改善装配稳定性以及环境适应能力。
1 轴孔装配任务分析
轴孔装配任务可分为3个阶段,首先通过寻孔阶段,将轴移动至孔的正上方;再调整轴与孔的相对姿态,完成对准任务;最后在保证姿态稳定后沿孔的中心线插入指定深度。为了使轴孔能正确的装配,主要需要解决轴与孔的位置P和姿态R之间的对应关系。装配模型如图1所示,在基座标下由机械臂正运动学定义的装配轴的接触面位姿为(RM,PM),根据装配孔在机械臂基座标下的位置关系,将装配孔接触面位姿定义为(RG,PG)。Δl为装配轴接触面中心点与孔的中心线之间的距离,Δε、Δω、Δμ分别为装配轴孔在XYZ轴上的姿态偏差。

(a) 圆轴孔装配 (b) 方轴孔装配图1 轴孔装配示意图
在图1a所示的圆孔的装配中,轴在调整姿态时,只需要实现Δμ=0为零,即可完成姿态的匹配,对于Z轴转动引起Δε、Δω误差可以不用考虑,再将轴移动到孔的正上方,满足位置Δl=0,就能达到装配要求。圆轴孔装配有较多的方案和算法可以实现这一目标[4-6],但对于如图1b所示方孔而言,不能只考虑Z轴之间的偏差Δμ,当Δε、Δω出现偏差时,方孔装配过程中还是会发生碰撞,并且是多点多面的复杂接触状态。这就必须要同时满足Δε、Δω、Δμ都为零,才能达到装配对姿态的要求。过多的状态输入使得传统的算法不能很好的适用,且各元素之间的关联会导致算法无法收敛,可以通过将装配任务分解为动作和姿态分别控制,能有效的降低运算复杂程度。
2 DE-MADDPG算法
2.1 多智能体深度强化学习
强化学习算法是一种通过智能体与环境交互来学习决策的方法,在多智能体问题中,智能体的行动和决策互相影响,且需要与其他智能体进行交互通信和协同决策,以达到协同实现任务的目标。多智能体强化学习是以马尔可夫决策过程为基础的随机博弈过程,可以将其定义为一个多元组(S,A1…AN,R1…RN,T,γ)。其中,N为智能体的数量,S为环境状态的集合,Ai为第i个智能体的动作,Ri为智能体动作Ai使St→St+1而获得的奖励回报,T∈[0,1]为状态转移概率,γ为累计奖励衰减系数。

(1)
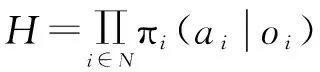
每个智能体的动作价值函数取决于联合动作,其公式为:
(2)
根据多智能体的任务类型,一般可分为完全合作、完全竞争和混合类型。本文在单机械臂中对位置和姿态独立控制的模式属于完全合作类型,即所有智能体对一个共同的目标实现最优控制。
2.2 MADDPG
MADDPG是DDPG在多智能体环境中的扩展,每一个智能体都有完整的DDPG框架。且在训练网络中采用双网络结构设计,即Actor和Critic网络都拥有估计网络和目标网络,其网络参数分别为(θπ,θQ)和(θπ′,θQ′)。其中估计网络实时计算更新网络参数,能更好的反映环境的变化;目标网络通过延迟更新目标Q值和策略,以达到稳定参数更新的目的。
MADDPG核心思想是通过集中训练,分布执行的原理,为多智能体系统寻找最佳的联合策略H。即每个智能体的Critic网络在训练动作价值函数阶段,还会用到其他智能体的观测和动作信息,可以帮助其更好的理解环境,能更好的对当前联合策略的评估,即Q值。计算公式为:
Q=Q(St,a1,a2,…aN)
(3)
式中:输入的参数为环境信息St,每个智能体的动作ai,以及Critic的网络参数θQ。
在多智能体模型中,每个智能体的Critic网络输入都是相同的,则其损失函数为:
(4)
(5)

在执行阶段,每个智能体的Actor网络仅独立根据自己的观测和策略就可以做出决策,不需要其他智能体的信息。其策略依靠对应的Critic网络训练得到的Q值进行梯度更新,策略梯度公式为:
(6)
每一次的迭代训练中,由式(7)更新估计网络参数:
(7)
式中:απ,αQ为Actor和Critic网络的更新率。再估计网络迭代多次后,将其参数以软更新的方式传递给目标网络,软更新方式为:
θ′←τθ+(1-τ)θ′
(8)
式中:τ≪1为更新系数,θ和θ′分别为估计网络和目标网络参数,可以有效的降低策略评估和改进过程中的方差,提高算法的稳定性和收敛速度。
2.3 DE-MADDPG
DE-MADDPG算法是对MADDPG的一种改进算法,在集中训练的基础上,还为每个智能体单独设计局部Critic网络,如图2所示,使每个智能体能够以解耦的方式同时最大化全局奖励和局部奖励。可以有效的避免局部最优的情况,也防止了全局奖励起主导作用,可以使各智能体高效稳定的学习到最优策略。
局部Critic网络只需要对智能体i的动作状态进行评价,得到局部Q值,其损失函数为:
(9)
(10)

(11)
3 轴孔装配策略设计
根据轴孔装配的任务设计,由两个智能体分别控制位置和姿态,对于一个六自由度机械臂而言,虽能通过控制不同关节的运动分开进行描述,但在串联系统中仍具有一定的耦合性。通过DE-MADDPG算法来弱化影响,根据机械臂的不同结构特性,为两个智能体设计独立的奖励函数,协同完成精准装配这一共同目标。
3.1 机械臂动作状态设计
轴孔装配示意图如图3所示,将控制末端位置信息的关节1、2、3定义为智能体1,控制末端姿态的关节4、5、6定义为智能体2。
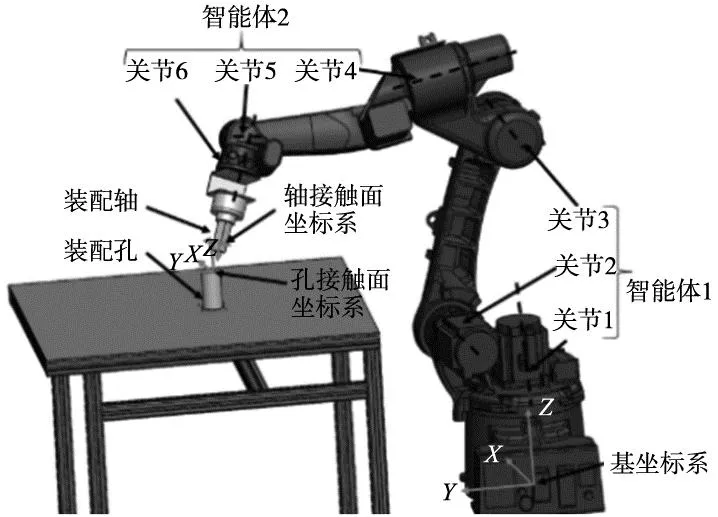
图3 机械臂轴孔装配
3.1.1 机械臂联合状态空间
在装配任务中,主要通过比较轴孔接触面之间的位姿状态来判断装配是否完成,同时还需要实现插入指定的深度h,将智能体的状态空间定义为:
(12)

3.1.2 机械臂联合动作空间
机械臂通过输入6个关节的转动角度实现对末端位姿的控制,根据智能体的设计,定义各智能体的动作空间为:
(13)

3.2 奖励回报函数设计
奖励函数的设计是强化学习系统能在环境中不断试错,学习到高效稳定策略的关键。设置合适的奖励函数能准确的表征模型任务目标,提高系统的性能,它的好坏直接决定着算法的收敛速度和程度。本文根据每个智能体的独立特征以及多智能体系统的任务目标来设计奖励函数,以提高训练的效率和稳定性。
3.2.1 全局奖励函数设计
智能体在t时刻执行联合动作At,并由机械臂运动学得到此时的联合状态St,计算轴孔接触面的位置距离Δl和姿态偏差Δε、Δω、Δμ,如未满足轴孔装配精度要求,则进行下一时间步的循环。在满足精度要求后进行插入阶段,当插入深度h达到指定深度hs后即为装配完成。在装配探索过程中,依靠轴与机械臂之间的六维力传感器判断轴与环境之间的接触力F,当力或力矩超过突变阈值Flim,则判定发生碰撞。当轴孔装配完成或发生碰撞时,才给予系统奖励反馈,并结束本轮循环。以任务目标设计奖励函数Rg:
(14)
式中:rvc为成功装配时获得的奖励值,即在位置偏差Δl和姿态偏差Δε、Δω、Δμ都在误差允许范围内趋近于0时,轴插入指定深度hs后获得奖励;rfl为发生碰撞时给予智能体的惩罚值,在其他情况下反馈为智能体的值都为0。在每一轮的训练中,目标奖励Rg只会获得一次,并在获得后完成本轮训练。在训练中设置rvc=100,rfl=-100。
为了提高智能体的探索效率,同时避免稀疏奖励导致局部震荡,无法收敛等状态,将各关节的转动角度作为惩罚值,驱使机械臂能够以最短的运动路径完成装配。其角度惩罚函数定义为Rθ:
(15)
式中:θi对应的是6个关节在一个步长内的旋转角度,单位为弧度。
3.2.2 局部奖励函数设计
对于分别控制位置和姿态的两个智能体,根据各自的任务特性设置独立的奖励函数,能提高多智能体的协作性能。为了提高探索初期的效率,以装配孔接触面中心点为圆心,设置半球形虚拟空间如图4所示,其半径为Rd=σRφ。在轴孔装配过程中,监测轴接触面中心点PM与圆心PG之间的距离Ls,当Ls≤Rd后,才开始对累计各智能体的奖励。

图4 位置奖励示意图
图4中,Rφ为装配孔基本尺寸;σ为比例系数,其值根据轴孔装配尺寸以及机械臂装配环境而定。通过仿真实验,当系数较大时,初始奖励较高,但学习进步较慢,且最终收敛奖励值较低,不是最优策略;当系数过小后,前期的目标探索时间过长,而且在进入范围后无法及时的调整位姿就发生碰撞,最终难以收敛。经测试,比较稳定的虚拟范围是σ∈(1,3),在此范围内机械臂可以较快的找到目标区域,且有充足的时间来调整位置和姿态。
(1)基于位置的奖励函数。为了保证在姿态在为正确匹配前不发生碰撞,对空间三维坐标的接近阶段采用不同的奖励策略。如图4所示,将PM沿孔的中心线投影在X-Y平面内,计算轴与孔之间的水平距离。在Z轴方向上的位置接近设置不同的权重系数,减缓匹配速度,并以虚拟空间半径为基准将奖励函数归一化,使奖励值不会因轴孔装配尺寸的不同以及虚拟空间大小而改变。在接近阶段,其奖励函数为:
(16)

在接触面达到装配精度后执行插入阶段,此时只需要沿Z轴方向的运动即可,以插入指定深度hs为目标,设计插入阶段奖励函数:
(17)
对于控制位置的智能体,其局部奖励为:
(18)

(2)基于姿态的奖励函数。用于描述姿态的旋转方式有旋转矩阵、欧拉角和四元数等,相较于旋转矩阵的较多元素运算以及欧拉角的万向锁,四元数只需要一个4维向量即可描述姿态的旋转,效率更高,且在连续的变换中更为平滑准确。一般机械臂由DH法得到的末端姿态为旋转矩阵形式,为了更好的计算装配轴孔姿态之间的偏差,通过式(19)将轴孔的姿态(RM,RG)转变为单位四元数的形式(qM,qG)进行描述。
(19)
式中:mij为姿态矩阵中的各个元素,(q0,q1,q2,q3)为四元数中的4个参数,且两个向量相向时夹角最大为π。为了使轴在朝着目标姿态修正后得到正向奖励,满足偏差越小,奖励越高。以四元数之间的夹角定义姿态奖励函数r2为:
r2=π-cos-1(|qM·qG|)
(20)
综上所述,对于全局Critic网络中使用的奖励函数Rt为:
(21)

4 实验设计及验证
4.1 仿真训练
在Gazebo仿真训练环境中搭建装配模型,装配实验对象采用直径40 mm圆轴和边长25 mm方轴,装配间隙为0.8 mm,装配深度hs=100 mm。训练硬件为Inter i9-10900k,RTX 3070 8 G显存,内存32 GB。主要的训练参数如下:网络折扣因子γ=0.99;目标网络软更新率τ=0.01;Actor网络学习率απ=0.001,Critic网络学习率αQ=0.002;决策周期ΔT=0.1 s,批样本数为64,最大训练回合数15 000,虚拟空间比例σ=2。
以相同的性能参数将DE-MADDPG算法与MADDPG算法和DDPG算法进行圆孔装配和方孔装配对比训练,总体平均奖励值如图5所示。

(a) 圆轴装配 (b) 方轴装配图5 智能体装配平均奖励
根据仿真数据分析,3种算法都能实现稳定收敛。多智能体算法(MADDPG和DE-MADDPG)比单智能体算法(DDPG)在收敛速度上有明显的优势。在两种装配轴孔中,多智能体算法在8000回合之前基本开始趋于稳定,而DDPG在11 000回合左右才开始收敛,这也验证了在单个机械臂中应用多智能体算法的可行性,并且在训练速度上有较大的提升。在方轴孔装配中,由于接触状态的复杂性,使得装配精度要求更高,相比于圆轴孔装配,多智能体采取的最优策略获得的奖励都稳定在200左右,而DDPG的平均奖励值从196.2降低到了164.6,多智能体在面对不同形状、不同精度的装配任务使,都能表现出良好的稳定性。
由于DE-MADDPG算法在训练中同时兼顾了整体目标和局部目标,与MADDPG算法相比,在初期的探索中能让多智能体系统更快的找到正确的学习方向,其奖励值在较少的训练回合中能得到较大的提升。在圆轴孔装配中,DE-MADDPG在4500回合左右时其奖励值开始趋于稳定,比MADDPG减少了近3000回合的训练次数。而在方轴孔装配中,其收敛速度只有少量的提升,但在训练过程中的奖励值波动明显弱于MADDPG,当DE-MADDPG遇到错误的优化方向后及时的修正自身的策略,使得其比MADDPG更加适用于复杂的任务。
为了验证算法的有效性,分别对DE-MADDPG、MADDPG和DDPG进行500次的圆孔和方孔的装配测试,孔的位置在工作平台上随机生成,结果如表1所示。

表1 圆孔与方孔装配时长分析
表1中的总体标准差反映了当前算法在执行装配任务中,每一次用时长短的偏差,数值越小,则表明该算法在面对不同环境下的装配更加的稳定。在圆孔装配中,多智能体算法(DE-MADDPG和MADDPG)与DDPG算法相比,总体用时分别提升了8.7%和6.6%,而且对于平均单次装配用时标准差,多智能体算法相对于DDPG有较大的提升,装配过程更加的稳定。在方孔的装配中,DE-MADDPG算法学习到的策略明显由于DDPG算法,总装配时间缩短了1.15 h,提高了13.2%的装配效率,且相较于MADDPG,其总体标准差和总时长也反映了此算法更加的稳定高效。
4.2 装配实验验证
搭建如图6所示的装配环境,选用川崎BA006N型机械臂,并配置力/力矩传感器,以方轴孔的装配作为实验对象,装配轴固定在机械臂末端,装配孔在训练阶段固定在工作平台已知坐标上。实验采用DE-MADDPG算法通过控制器对机械臂进行了10 000次装配训练,其平均奖励值如图7所示。

图6 装配实验示意图 图7 实验训练奖励曲线图
实验环境与仿真理想环境有一定差距,在初期探索过程中提升较慢,后期的收敛稳定性也有较大的波动,但仍在8500回合左右奖励值收敛稳定,平均奖励值与仿真结果基本一致。
为验证训练结果的可行性以及泛化性,通过改变装配孔在工作空间中的位姿坐标,对机械臂进行了100次方孔轴装配测试。为了检验训练模型处理不同任务的能力,将孔倾斜15°和30°进行圆孔和方孔的100次装配测试。测试结果如表2所示。

表2 DE-MADDPG算法装配成功率测试
在实际装配过程中,机械臂动力学参数配置的误差以及本体结构的系统误差是影响装配成功率的主要原因。从实验结果中可以看出,改变装配孔的倾斜角度会降低装配成功的准确率,但倾斜角度的大小对实验的结果没有明显的影响。在15°和30°倾角装配中主要失败在插入过程中,由于装配角度的变化,运动策略也更复杂,很容易与孔壁发生摩擦碰撞。而对于姿态精度不高的圆孔装配仍能达到预期结果。可见该算法在机械臂装配上具有一定的泛化性。
5 结论
本文对轴孔装配提出了基于DE-MADDPG的装配方案,将六自由度机械臂分解为两个智能体分别对位置和姿态控制,并引入了局部评价函数,根据装配动作设计了分别用于控制位置和姿态的局部奖励函数,在训练中能有效的提高收敛速度。并在圆轴孔和方轴孔装配任务中与DDPG算法和MADDPG算法进行对比实验,相较于单智能体算法(DDPG)提高了13.2%的装配效率,且比MADDPG在准确度和稳定性都得到了提升。最后在实体装配检验了DE-MADDPG算法的可行性,同时其在处理不同姿态和位置的任务目标时也具有较好泛化能力。
