基于异质信息网络的文本相似性度量方法
2023-12-06马秋微赵书良
马秋微,赵书良,赵 妍
(1. 河北师范大学 计算机与网络空间安全学院,河北 石家庄 050024;2. 供应链大数据分析与数据安全河北省工程研究中心,河北 石家庄 050024;3. 河北省网络与信息安全重点实验室,河北 石家庄 050024)
0 引言
真实世界中的大部分数据主要以非结构化文本的形式存在,从非结构化文本中挖掘结构和知识是数据挖掘任务中的主要挑战之一,具有巨大的潜在影响。传统的文本相似性度量方法使用简单的词袋模型作为文本表示,将文本表示为独热向量的形式,并使用不同的度量方法(如Cosine相似性、Jaccard相似性和Dice系数)计算文本相似性。然而,在文本相似性度量任务中,不能仅仅考虑单词粒度。如果两篇文档中的单词不相同,但其实体所对应的实体类型相同,这两篇文档也具有相关性。基于向量空间模型的文本相似性度量方法仅利用文本中简单的词频信息将文本转化为向量,忽略了文本的语义关系,导致其计算过程复杂且精确度不高。为了结合上下文信息,Nguyen等人[1]提出LF-LDA(Latent Feature-LDA)主题模型,该模型将预先训练好的词向量引入多项式分布模型,提高了相似度计算结果的准确性。除了主题模型,训练神经网络学习文本语料库中的语义信息从而得到文本向量,也成为目前研究的热点。文献[2]结合文本中单词的上下文信息,利用Word2Vec模型将单词表示为低维向量,再利用距离度量方法进行文本相似性度量。Kusner等人[3]提出词移距离算法(Word Mover's Distance,WMD)度量文本距离,该算法利用文本中所有词语转移到另一文本中对应词语所需要的最小距离来度量二者的相似度。Tian等人[4]提出基于特征贡献度的句向量表示模型,得到语义信息集中且任务针对性强的句向量表示,在一定程度上提高了模型的计算效率。上述方法将文本表示为向量的形式度量文本的隐式语义相似性,降低了文本语义的可解释性,忽略了非结构化文本中的结构化信息。
异质信息网络(Heterogeneous Information Network,HIN)[5]作为一种结构化数据能够有效建模和处理多种类型对象及其之间复杂的交互关系,并且在许多不同的数据挖掘任务中得到了广泛应用。Du等人[6]认为元路径可以表示HIN中节点之间的关系,于是通过丰富的路径信息,构造基于元路径的特征矩阵,并对随机森林分类器进行训练,实现HIN中节点的分类。Cao等人[7]提出一种基于异质信息网络的文本聚类框架,将文本建模为异质信息网络,通过文本节点之间的相似度矩阵对给定文本进行聚类。文献[8-9]在HIN上利用元路径丰富的语义信息来产生用户感兴趣的相关推荐。Bai等人[10]在HIN上利用节点的分布式向量表示,将其他节点作为“背景知识”学习目标节点集的向量表示。邱等人[11]提出了一种基于向量的语义特征提取方法,利用向量的空间距离度量节点的相似性。刘等人[12]将文献异质信息网络中的节点属性信息与文本内容信息相结合以量化节点之间的相似性。Wan等人[13]提出一种基于强化学习的元路径挖掘方法,利用多跳推理策略,从网络模式复杂的HIN中挖掘信息丰富的元路径,获取不同对象之间的路径语义信息。文献[14]将文本内容的主题分布作为元路径的属性约束,度量文献异质信息网络中相同类型对象之间的相似性。文献[15-17]基于元路径度量HIN上不同类型对象间的相似性。
结合异质信息网络的结构特性和语义特性,将非结构化文本数据转换为结构化知识,在此基础上挖掘需要的知识具有重要的研究意义。Yao等人[18]建立了一个基于语料库的同质文本网络,利用图卷积网络实现文本分类。Bao等人[19]利用长短时记忆网络度量文本语义相似性。上述方法仅考虑了文本的上下文信息,忽略了背景信息以及背景之外的知识。与上述基于嵌入的方法相比,使用显式的语义特征来计算文本相似性,其度量结果更具有可解释性,更容易被人类理解。Wang等人[20]提出了无监督自动元路径选择方法对元路径进行选择,并定义了一种集成元路径的相似性度量方法。但是该方法没有考虑单词或者实体本身对文本相似性的影响。针对上述不足,本文结合链接权重信息在非结构化文本中使用结构信息及显式语义信息进一步改进文本相似性计算。
本文的主要贡献如下:
(1) 将文本相似性度量问题转化为加权异质信息网络上的基于元路径的节点相似性度量问题。提出基于异质信息网络的文本相似性度量模型HINSim。
(2) 结合世界知识库,构建带有链接权重的文本异质信息网络。其中,文本被表示为一种特定类型的节点。并将点互信息(PMI)值,以及词频-逆文档频率(TF-IDF)作为不同类型节点之间的链接权重。
(3) 挖掘关于文本类型节点的元路径,提出基于元路径的ω-PageRank-Nibble子图划分算法,对网络模式复杂的异质信息网络进行剪枝处理,降低空间成本,并根据子图计算存储元路径的交换矩阵,节约相似性计算的时间成本。
(4) 提出基于元路经集的AllPathSim耦合相似性度量方法。结合多条元路径的权重,综合度量文本类型节点的相似性。
1 加权异质信息网络
1.1 整体解决方案架构
与传统的文本度量方式不同,基于异质信息网络的文本相似性度量方法结合世界知识库,将文本特征粒度扩大化,将单词粒度或短语粒度上升到实体类型粒度。同时,以异质信息网络的结构特性为切入点,从非结构化信息转化为结构化知识的角度出发,将文本类型数据表示为网络模式复杂的且带有链接权重的异质信息网络的形式。利用加权异质信息网络中丰富的显式语义信息进行节点相似性度量。概括来说,基于异质信息网络的文本相似性度量方法将文本相似性度量问题转化为加权异质信息网络上基于元路径的相同类型节点的相似性度量问题。基于异质信息网络的文本相似性度量方法的整体框架主要分为三部分,如图1所示。

图1 基于异质信息网络的文本相似性度量方法框架
(1) 构建加权文本异质信息网络。首先,生成实体类型节点,对给定文本进行语义解析和语义过滤,将文本中的实体及关系映射到世界知识库中,得到其对应的实体类型及关系类型。其次,对给定文本进行去除停用词及特征提取操作,得到单词类型节点。最后,利用TF-IDF和PMI方法对链接关系进行加权,实现从文本到加权异质信息网络的转换。
(2) 元路径挖掘及图剪枝。首先,基于加权文本异质信息网络进行元路径挖掘,得到对称元路径。其次,基于每条特定的元路径,利用ω-PageRank-Nibble子图划分算法对网络模式复杂的异质信息网络进行剪枝,得到包含给定文本节点集的局部图,以节省存储空间。最后,根据局部图,计算并存储元路径的交换矩阵,为后续计算节约时间成本。
(3) 文本节点相似性度量。首先,结合元路径交换矩阵,利用基于特定元路径的OnePathSim相似性度量方法,度量单条元路径下文本类型节点的相似性。其次,根据不同元路径的路径实例个数为每条元路径进行加权。最后,结合多条元路径的权重,利用基于元路径集的AllPathSim耦合相似性度量方法度量元路径集下文本类型节点的相似性。
1.2 异质信息网络构建方法
加权文本异质信息网络的构建即实现从文本到带有链接权重的异质信息网络的转化。
定义1 加权异质信息网络网络为加权无向图G(V,W,E),具有节点类型映射函数φ:V→A和关系类型映射函数ψ:E→R,其中,每个对象v∈V属于一个特定的节点类型φ(V)∈A,每个链接e∈E属于一个特定的关系类型ψ(E)∈R且具有相应的权重ω∈W。当满足节点类型数量|A|>1或关系类型数量|R|>1时,该网络为加权异质信息网络。
世界知识库包含多种实体类型和关系类型。本文结合世界知识库,将文本中的实体及关系映射到世界知识库中,得到其对应的实体类型及关系类型。构建带有链接权重的文本异质信息网络,首先,对给定文本进行语义解析,提取候选实体。其次,对语义解析结果进行语义过滤,选取候选实体得分最高的实体,以此生成不同的实体类型节点。然后,通过对给定文本集合的预处理及特征提取等方法生成文本异质信息网络中的单词类型节点。最后,对不同节点间的链接关系进行加权,实现文本到异质信息网络的转换。本文构建的异质信息网络的节点类型包含实体节点类型,单词节点类型,以及文本节点类型。其中,文本节点与实体节点以及文本节点与单词节点之间的权重是该实体或单词在对应文本中的词频-逆文档频率(TF-IDF),本文在后续的实验中证明了使用TF-IDF方法比单纯使用词频(TF)方法效果更好。不同实体节点之间的权重是实体间的点互信息(PMI)值。以两篇短文本为例,加权文本异质信息网络示意图如图2所示。

图2 加权文本异质信息网络示意图
1.2.1 实体节点生成
(1) 语义解析
语义解析是将一段自然语言文本映射成逻辑形式表示的任务[20]。世界知识库由形式为<实体,关系,实体>的三元组集构成。简单来说,语义解析就是将文本中的实体以及关系短语映射到世界知识库并得到其类型的过程。将世界知识Freebase加载到Virtuoso图数据库中,通过SPARQL语句查询得到相应的实体类型。例如,给定一段文本“Obama is the president of United States of America.”。使用Accurate Online Disambiguation of Entities(AIDA)工具来识别文本中的实体。将识别的实体“Obama”和“United States of America”映射到知识库中得到一元逻辑形式“People.BarackObama”和“Country.USA”,其中“People”和“Country”是知识库中的实体类型信息。关系短语“president”映射成二元逻辑形式“PresidentofCountry”,该形式是知识库中的关系类型信息。然后,使用语法规则组合基本逻辑形式进而生成逻辑形式People.BarackObama∧President.USA来表示其语义信息。语义解析的结果是将给定文本解析为不同的逻辑形式,该形式包含该实体以及对应的候选实体类型。
(2) 语义过滤
对于给定文本中的每个句子,语义解析之后得到对应文本的一组表示语义信息的逻辑形式。然而,语义解析过程所提取的实体可能具有多层含义。例如: “Apple”的实体类型可能是水果或者公司。这就需要针对语义解析的结果进行语义过滤,即对具有多种实体类型的实体进行消歧处理。假设文档的所有句子中最常见的实体类型是含有正确语义的实体类型。以文档中出现的实体的类型频率为标准,选取在文本中出现次数最多即得分最高的实体类型作为该实体的正确语义。
1.2.2 单词节点生成
文本中存在的某些单词并非是实体,即在世界知识库中不存在其相应类型,但是这些单词也是文本异质信息网络的重要组成部分。这些单词在构建的文本异质信息网络中只具有一种节点类型,统称为单词类型节点。与实体类型节点不同,单词类型节点仅仅与文本类型节点具有相应链接,表示包含与被包含的关系。单词类型节点的生成包含文本预处理和文本特征提取两个步骤。首先,以空格作为分隔符对给定文本进行分词处理;其次,去除停用词,删除对内容影响较小或毫无意义的词;最后,利用TF-IDF加权方法得到特征词汇。该特征词汇即为文本异质信息网络中的单词类型节点。
1.2.3 链接加权
考虑到不同实体或单词在文本中的重要程度以及不同实体之间的相关性不同,本文将该实体或单词在对应文本中的TF-IDF值作为文本节点和单词节点或实体节点之间的链接权重。另外,本文采用PMI单词关联度量方法,计算不同实体节点之间的链接权重。链接权重wij的计算如式(1)所示。
(1)
加权文本异质信息网络构建算法伪代码如算法1所示。

算法1: 加权文本异质信息网络构建算法
2 元路径挖掘与图剪枝
2.1 相关定义
定义2 网络模式网络模式是对异质信息网络G(V,W,E)的一种元描述,其是定义在节点类型A、关系类型R上的无向图,记为SG=(A,R),包含节点类型的映射φ:V→A和关系类型的映射ψ:E→R。
本文构建的文本异质信息网络的网络模式如图3所示。

图3 文本异质信息网络的网络模式

基于上述定义,元路径还延伸出对称元路径的定义。如果元路径中的关系R是对称的,即P和P-1相等,那么该元路径即为对称元路径。
定义4 交换矩阵给定加权异质信息网络G(V,W,E)及其网络模式SG,基于元路径P=A1→A2→…→Al+1的交换矩阵MP=(WA1A2,WA2A3,…,WAlAl+1),其中WAkAk+1是类型Ak和Ak+1之间的邻接矩阵。MP(i,j)是节点i和节点j之间的链接权重的值。
2.2 元路径挖掘
在带有链接权重的文本异质信息网络中,两个文本类型节点之间存在多条元路径。假设相似的文本在结构上由对称元路径定义[21],本文只探索两个文本类型节点之间的对称元路径。
不同于结构简单的异质信息网络,例如: DBLP,本文所构建的文本异质信息网络的网络模式较为复杂,其中包含的实体节点类型多样化,本文选取简单的元路径挖掘方法。首先定义对称元路径的最大长度L,枚举L/2个不同的实体类型并进行简单的排列组合。然后,存储每两种不同节点类型的交换矩阵。最后,选取对称的且具有语义意义的元路径。本文在4.3.1节实验部分进行了不同路径长度影响相似性度量结果的实验,实验结果表明,最佳路径长度为4。
2.3 图剪枝
由交换矩阵的定义可知,需要利用矩阵乘法来计算路径中每两个相邻实体之间邻接矩阵的乘积。计算具有多种实体类型的元路径的交换矩阵花销巨大[22]。另外,在网络模式复杂的异质信息网络中,并非所有实体都是相关的。为了节省存储空间,提高度量效率,本文提出基于元路径的ω-PageRank-Nibble子图划分算法,基于每一条特定的元路径,采用剪枝策略,对大规模异质信息网络进行修剪,从而得到包含给定文本节点集的局部图。根据局部图,计算并存储基于每一条特定元路径的交换矩阵,为后续的相似性度量节约时间以及空间成本。本文在4.3.2节实验部分证明了基于元路径的ω-PageRank-Nibble子图划分算法的可行性和有效性。
传统的PageRank-Nibble算法是从一个节点开始,在给定图上进行随机游走,以一定的概率游走到其他的邻居节点。不同于传统的PageRank-Nibble算法,基于元路径的ω-PageRank-Nibble子图划分算法针对每条元路径进行随机游走,从多个不同的文本节点开始,并根据不同的链接权重跳转到其他邻居节点。基于加权文本异质信息网络G(V,W,E),给出本方法中的相关定义。
定义5 节点i的加权度dw(i)式中,N(i)表示节点i的邻居节点个数。wij为节点i和邻居节点j之间的链接权重。
dw(i)=∑j∈N(i)wij
(2)
定义6 整张图G的所有节点的加权量Dw(V)式中,V代表图G的所有节点的集合。
Dw(V)=∑i∈Vdw(i)
(3)
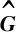
Dw(S)=∑i∈Sdw(i)
(4)
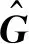
(5)
基于元路径的ω-PageRank-Nibble子图划分算法维护了一个剩余向量r和一个ε近似的PageRank向量。以给定文本节点集为初始节点,进行一系列的push操作,若r[v]/dw(v)≥ε,则执行下一步游走操作。将r[v]*α赋给p[v],r[v]的值等于剩余的r[v]×(1-α)的值,一直重复此过程选择满足条件的节点,直到r[v]/dw(v)<ε则停止迭代。其中α和ε的值如文献[20]中一样分别设置为0.45,10-5。该算法的伪代码如算法2所示。

算法2: 基于元路径的ω-PageRank-Nibble子图划分算法
3 节点相似性度量方法
3.1 基于特定元路径的OnePathSim相似性度量方法
在异质信息网络上,元路径可以用来计算源节点和目标节点之间的相似性。受PathSim[22]启发,在构建的加权文本异质信息网络上,基于给定的一条特定元路径,结合该元路径下不同对象之间的链接权重,度量两个不同文本节点的相似性。
定义9给定一条特定元路径,文本节点i和文本节点j之间基于特定元路径的OnePathSim相似性度量定义如式(6)所示。
(6)
由定义4可知,元路径p的交换矩阵MP=(W12,W23,…,Wl-1l),其中W12为元路径p下第一个节点类型和第二个节点类型之间的邻接矩阵。邻接矩阵中的值为该节点类型中不同对象之间的链接权重ω,ω的值根据式(1)计算得到。式(6)中,Mp(i,j)为节点i和节点j在交换矩阵中的权重值,即交换矩阵中第i行第j列对应位置的值。Mp(i,i)为节点i与其自身在交换矩阵中的权重值,即交换矩阵中第i行第i列对应位置的值。Mp(j,j)为节点j与其自身在交换矩阵中的权重值,即交换矩阵中第j行第j列对应位置的值。
3.2 基于元路径集的AllPathSim耦合相似性度量方法
源节点和目标节点之间可能包含多条元路径,某一元路径下的路径实例越多,表明该元路径对相似性度量更重要。本文结合多条元路径,将基于某一特定的元路径的实例数与所有路径实例数的比值作为该元路径的相应权重。结合每条元路径的权重,综合度量文本类型节点之间的相似性。由于提前存储了所有元路径的交换矩阵,所以在进行相似性度量时节约了大量的时间与空间成本。
定义10给定对称元路径集合P{P1,P2,…,PN},文本节点i和文本节点j之间基于元路径集的AllPathSim耦合相似性度量定义如式(7)所示。
AllPathSim(i,j)
(7)

AllPathSim耦合相似性度量满足以下性质,具有度量有效性。
(1) 正定性
AllPathSim(i,j)≥0,且AllPathSim(i,i)=1
(2) 对称性
AllPathSim(i,j)=AllPathSim(j,i)
(3) 三角不等式
AllPathSim(i,j)≤AllPathSim(i,k)+AllPathSim(j,k)
算法3描述了基于元路径集的耦合相似性度量算法的伪代码。

算法3: 基于元路径集的耦合相似性度量算法
4 实验验证与分析
4.1 数据集
本文采用20Newsgroups(20NG)和GCAT两个短文本数据集来评估基于元路径集AllPathSim耦合相似性度量方法的有效性和可行性。其中GCAT是从RCV1中选取的部分文档的集合[20]。每个数据集的文档个数,以及提取的特征个数和类别个数不尽相同。上述两个数据集基本情况如表1所列。

表1 数据集相关信息
本文采用SICK数据集和MSRP数据集对本文提出的基于异质信息网络的文本相似性度量方法进行综合性评估。SICK数据集[23]包含9 927个英文句子对,每个句子对标注有语义关系和蕴含关系。
MSRP数据集[24]包含5 081个英文句子对,每个句子对具有人工注释,指示每对句子之间的相关性。
将世界知识库Freebase作为实体映射的外部知识库,Freebase数据库是不同三元组的集合,由不同的实体和关系组成。Freebase中包含1 500+种实体类型和3 500+种关系类型。将Freebase加载到Virtuoso数据库中,将文本解析后生成的逻辑形式转换为SPARQL查询,以找到相应的实体类型和关系类型。
4.2 评价指标
本文采用相关系数作为度量结果的评价指标。相关系数计算如式(8)所示。
(8)

另外,为了更直观地观察文本相似性度量的有效性,在评估文本相似性结果时,往往将文本相似性问题看作文本是否相似的二分类问题。本文将分类实验中常用的准确率、召回率和F1-Score作为评价本文提出的模型性能的标准。
4.3 实验
4.3.1 最佳元路径长度
在异质信息网络上,利用元路径进行节点的相似性度量时,较长的路径并不会对结果产生良好的影响[20]。本文探究了不同的元路径长度对文档相似性度量结果的影响,分别在20NG和GCAT数据集上进行了实验。探究了元路径长度分别为2、4、6、8时的相似性度量结果,如图4所示。结果表明,对称元路径长度为4时,相关系数最高,相似性度量结果最好。

图4 不同元路径长度对度量结果的影响
4.3.2 ω-PageRank-Nibble子图划分算法
为了证明基于元路径的ω-PageRank-Nibble子图划分算法的有效性,本文与传统的PageRank-Nibble算法在20NG数据集上进行了对比实验。首先,随机选取10条对称元路径,如表2所示。然后,针对每条元路径,分别采用传统的PageRank-Nibble算法和ω-PageRank-Nibble子图划分算法生成不同的交换矩阵。最后,对不同方法的交换矩阵进行结果分析。

表2 元路径示例
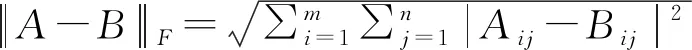

图5 两种交换矩阵的Frobenius范数盒图
通过比较度量结果的相关系数,间接证明基于元路径的ω-PageRank-Nibble子图划分算法的有效性。基于上述10条对称元路径,利用两种不同的子图划分算法生成两种不同的近似交换矩阵,通过AllPathSim方法在20NG数据集上得出三种不同的相似性度量结果。同时,也对比了三种方法所消耗的空间以及时间成本,结果如表3所示。实验结果表明,基于元路径的ω-PageRank-Nibble子图划分算法相比于传统PageRank-Nibble算法与不进行剪枝的结果更为相近,空间成本节约20.6%,时间成本节约20.8%。
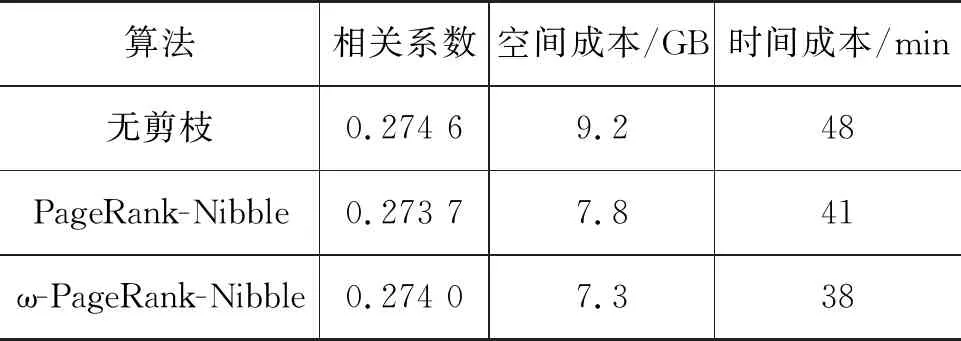
表3 不同子图划分算法的比较
4.3.3 文本相似性度量
基于异质信息网络的文本相似性度量方法针对文本特征稀疏的问题,扩大文本特征粒度,结合外部知识库,将单词或短语粒度扩大到实体类型粒度,提高了度量结果的准确性。另外,针对忽略文本结构特征的问题,本文结合异质信息网络的结构特性,将非结构化文本以结构化形式表示出来,充分利用元路径的丰富语义信息,度量文本的显式语义相似性,从而增强度量结果的可解释性。总结来说,基于异质信息网络的文本相似性度量方法从两个方面提高了度量结果的相关系数。一是利用异质信息网络的结构信息、语义信息和链接权重信息。二是扩大了文本特征粒度。分别用BOW、Entity和BOW+Entity表示三种不同的文本特征。
BOW传统的词袋模型,以文本中的单词作为文本特征。分别将单词在文本中的TF值和TF-IDF值作为其权重。
Entity结合世界知识库提取实体类型作为文本特征。分别将该实体在文本中的TF值和TF-IDF值作为其权重。另外,利用PMI值实现实体与实体之间的链接加权。
BOW+Entity文本中的单词与不同类型的实体作为文本的集成特征,分别将单词或实体在文本中的TF值和TF-IDF值作为该单词或实体的权重。
PathSim[22]基于单条元路径的相同类型节点的相似性度量方法,度量结果仅与单条路径上的实例个数相关。
KnowSim[20]基于多条元路径的相同类型节点的相似性度量方法,度量结果为多个PathSim计算结果的加权和。
基于特定元路径的OnePathSim相似性度量方法,充分利用了元路径的语义信息并结合了特定元路径下的不同路径实例的链接权重信息。基于元路径集的AllPathSim耦合相似性度量方法不仅结合了链接权重信息,同时也将不同元路径间的路径实例个数作为相似性结果的影响因子。以BOW+Entity集成文本特征和TF-IDF加权方法为基础,本文将OnePathSim相似性度量方法、AllPathSim耦合相似性度量方法和与具有代表性的相似性度量方式: Cosine相似性、Jaccard相似性和Dice系数,同时与PathSim和KnowSim相似性度量方法进行了对比。
图6表示了不同相似性度量方法在同一文本特征下的相关系数。表4汇总了不同特征粒度、不同特征加权方法的不同相似性度量方法的相关系数。由图6和表4可知,在20NG数据集上,OnePathSim相似性度量方法与传统的度量方法中效果最好的Cosine相似性相比,相关系数提高了15.1%;与PathSim度量方法相比,相关系数提高了5.2%。在GCAT数据集上,与传统的度量方法中效果最好的Dice系数相比,相关系数提高了16.6%;与PathSim度量方法相比,相关系数提高了9.4%。另外,在相同文本特征粒度下,基于特定元路径的OnePathSim度量方法的相关系数低于KnowSim方法,出现此情况的原因是,即使OnePathSim度量方法结合了异质网络中的不同类型节点之间的链接权重信息,但其忽略了其他元路径的显式语义信息,所以其度量效果略差于KnowSim方法。AllPathSim耦合相似性度量方法则解决了PathSim和OnePathSim方法的多路径语义忽略问题,并且结合了不同节点间的链接关系,有效提高了度量结果的相关系数。

表4 特征粒度不同的相似性度量方法在20NG和GCAT数据集上的相关系数

图6 特征粒度相同的相似性度量方法在20NG和GCAT数据集上的相关系数
AllPathSim耦合相似性度量方法与传统的度量方法中效果最好的Cosine相似性相比,相关系数提高了23.8%;与KnowSim度量方法相比,相关系数提高了6.1%。在GCAT数据集上,与传统的度量方法中效果最好的Dice相似性相比,相关系数提高了45.6%;与KnowSim度量方法相比,相关系数提高了6.9%。另外,通过将基于元路径集AllPathSim度量方法与基于特定元路径的OnePathSim度量方法比较,前者相关系数在两个数据集上都高于后者,证明了对具有不同路径实例数的元路径的耦合有效性和可行性。由此分析可知,基于元路径集的AllPathSim度量方法的度量效果在利用元路径结构特性、语义特性以及异质信息网络链接权重方面要优于以上其他方法。
为了证明结合外部知识库提取实体类型,以扩大文本特征粒度对文本相似性度量的重要性,本文从特征粒度和特征权重两种不同角度的分别进行了实验分析。本文将BOW、Entity以及BOW+Entity分别作为文本特征,以及利用不同的特征加权方法进行了不同的相似性度量实验。图7和图8分别是具有不同特征粒度的各个度量算法在20NG和GCAT数据集上的相关系数。由图7、图8分析可知,一方面,在每种不同的相似性度量方法中,当以BOW+Entity作为文本的集成特征时,相关系数最高,度量结果最好。另一方面,在每种不同的文本特征基础上,AllPathSim相似性度量方法的结果都要优于其他的度量方法。另外,相同特征粒度下,以TF-IDF值作为链接权重比单纯使用TF值作为权重,相似性度量效果更好。由此分析可以得出,AllPathSim相似性度量方法,在结合外部知识库中的结构特征,扩大文本特征粒度方面比只利用文本中的扁平特征进行相似性度量更具有效性。
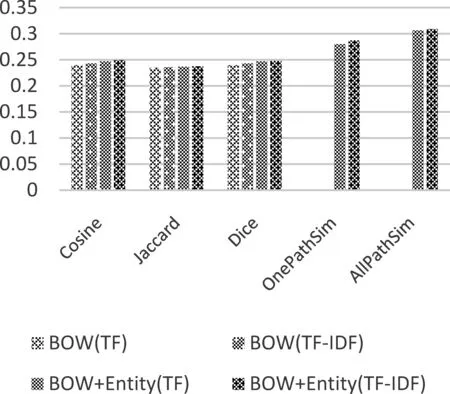
图7 不同文本特征的相似性度量方法在20NG上的相关系数

图8 不同文本特征的相似性度量方法在GCAT上的相关系数
为了进一步评估基于异质信息网络的文本相似性度量方法的性能,本文将文本相似性度量问题转化为文本是否相似的二元分类问题,利用4.2节给出的分类问题中的评价指标进一步评估本文方法的有效性。本文以经验值0.7作为相似度阈值,以单词和实体作为文本的集成特征,以TF-IDF加权方法和PMI单词关联度量方法作为文本异质信息网络的链接权重的加权方法,将本文提出的基于异质信息网络的文本相似性度量方法(HINSim)分别与不同的隐式语义相似性度量方法进行对比。计算不同文本相似性度量算法在英语句子对数据集SICK和MSRP上的准确率、召回率及F1-Score的值,利用上述三个不同的评价指标评估本文度量算法的性能。
LF-LDASim[1]基于LF-LDA主题模型的相似度计算方法。该模型生成的文本表示向量为服从概率分布的隐藏主题向量。
WMDSim[3]典型的基于词移距离的文本相似性度量方法。利用文本A中所有的词语转移到文本B中对应词语需要的最小距离来度量两篇文本的相似度。
Word2VecSim+TF-IDF[2]利用Word2Vec模型得到每个词的向量表示,利用TF-IDF方法提取出的每个文本数据的关键词,求其平均值得到每个文本数据的向量表示。
IIGSIFSim[4]基于IIG-SIF句向量的相似度计算算法。利用特征贡献度的句向量表示模型将文本中的句子表示为向量形式,计算向量的余弦相似度作为文本相似性计算结果。
表5为五种不同文本相似性度量方法在不同数据集上的准确率、召回率及F1-Score的值。由表5得出,本文提出的基于异质信息网络的文本相似性度量方法(HINSim)在准确率、召回率和F1-Score三个评价指标上的实验效果均优于其他对照算法。从五种算法在两类数据集上的对比实验结果数据来看,在SICK数据集上,HINSim模型较其他文本相似性度量算法准确率提升3.78%~14.68%;召回率提升2.55%~9.5%;F1-Score提升2.63%~10.67%。在MSRP数据集上,HINSim模型较其他文本相似性度量算法准确率提升3.64%~10.09%;召回率提升4.08%~10.55%;F1-Score提升6.62%~12.46%。总体而言,基于异质信息网络的文本显式语义相似性度量方法与其他四种隐式语义相似性度量方法相比,可以更有效且更准确地计算文本之间的相似性。HINSim模型充分考虑了非结构化文本数据中的结构化信息,并且为不同的文本特征增加了相应的权重属性,利用元路径充分挖掘了文本的语义和结构信息,从而得到准确且有效的相似性度量结果。

表5 不同相似性度量方法在SICK和MSRP数据集上的准确率、召回率及F1-Score (单位: %)
5 结束语
目前现有的文本相似性度量方法侧重于文本中的“扁平特征”,忽略了文本中的结构信息。本文实现了非结构化文本数据的结构化表示,将文本表示为异质信息网络中的一种特定类型的节点,从而将文本相似性度量问题转化为异质信息网络上的节点相似性度量问题,并利用元路径丰富的语义信息,度量文本类型节点的显式语义相似性。首先,结合丰富的世界知识,生成与领域相关的特征。将文本特征粒度扩大化,从单词或短语粒度转变为实体类型粒度,提高度量结果的准确性。另外,考虑到这些特征对文本的重要性不同,利用特征加权方法为其赋予不用的权重,从而构建加权文本异质信息网络。其次,采用剪枝策略,实现对大规模异质信息网络的修剪,提出基于元路径的ω-PageRank-Nibble算法划分子图,节省存储空间。根据子图,计算并存储元路径的交换矩阵,为相似性度量任务降低时间成本,提高度量效率。最后,提出基于元路径集的AllPathSim耦合相似性度量方法,结合链接权重信息和不同元路径下的路径实例个数,综合度量加权文本异质信息网络中的文本节点的相似性。
虽然基于元路经集的AllPathSim耦合相似性度量方法在相同类型节点的相似性度量方面效果很好,但是元路径的权重并没有通过自学习的方式得到。如何通过自学习的方法学习不同元路径的权重,是我们今后的研究方向。
